

Параграф 2.2: Теорема Шеннона для канала без шума
Предельные возможности статистического кодирования раскрывается в теореме Шеннона для канала без шума, которая является одним из основных положений теории передачи информации. Эта теорема может быть сформулирована следующим образом (обозначения те же, что и в пункте 2.1). Пусть источник сообщений имеет производительность H’ (U) = Vc H(U), а канал имеет пропускную способность C =Vklog M. Тогда можно закодировать сообщения на выходе источника таким образом, чтобы получить среднее число кодовых символов приходящихся на элемент сообщения
η = Vk / Vc = (H(U) / log M) + ε (2.2),
где ε - сколь угодно мало (прямая теорема).
Получить меньшее значение η невозможно (обратная теорема). Обратная часть теоремы утверждающая, что невозможно получить значение
η = Vk / Vc < H(U) / log M (2.3),
может быть доказана если учесть, что неравенство (2.3) эквивалентно неравенству u Vc H (U) > Vk log M и H’ (U) > C. Последнее неравенство не может быть выполнено, т.к. рассматриваемое кодирование должно быть обратимым преобразованием (т.е. без потерь информации). Энтропия в секунду на входе канала или производительность кодера не может превышать пропускную способность канала (см. пункт 1.6).
Докажем прямую теорему двумя различными способами при этом источник сообщений будем полагать источником без памяти, имея в виду, что к нему со сколь угодно высокой степенью точности может быть сведен любой источник, если блоки элементов сообщения достаточно большой длинны К1 рассматривать, как элементарные сообщения Ui с объемом алфавита Nблока. Первый способ доказательства состоит в рассмотрении множества сообщений из К символов создаваемых источником. Каждую из таких последовательностей содержащую К элементарных сообщений ui выбираемых из алфавита объемом 0 … Nu – 1 будем считать сообщением α =(uk-1, …, u0). Вероятность этих сообщений для источников без памяти P(α) = P(uk-1) P(uk-2) … P(u0). При этом количество L отличных друг от друга сообщений a будет равно L = Nuk. При достаточно большой длине сообщения К все множество L возможных сообщений может быть разбито на 2 подмножества. Одно из них (назовем его высоко вероятным или типичным) содержит К1 наиболее вероятных сообщений, сумма вероятностей которых 1-δ близка к единице, второе содержит остальные К2=L-K1 сообщений (мало вероятных или нетипичных), суммарная вероятность которых δ близка к нулю. Увеличивая К можно сделать δ сколь угодно малым. Сказанное следует из закона теории вероятностей, согласно которому при достаточно большом числе испытаний количество каждого из возможных исходов близко к своему математическому ожиданию (закон больших чисел). В данном случае числом испытаний является число К элементов сообщений, исходом являются значения элементов ui и математическое ожидание количества исходов ui = K P(ui) . Поэтому достаточно длинное сообщение содержит близкое к K P(0) число элементов 0, K P(1) число элементов 1, …, к K P(Nu-1) число элементов Nu-1. Такие сообщения и составляют высоко вероятное подмножество. Вероятность того, что сообщения содержат другие числа элементов при К → ∞ ничтожно мала. Поскольку при отсутствии памяти у источника вероятность того или иного сочетания различных элементов сообщения зависит только от их количества, то все сообщения принадлежащие к высоко вероятному подмножеству т.е. содержащие примерно одно и тоже количество разных элементов и отличающихся только расположением этих элементов в последовательности, имеют одну и туже вероятность близкую к P(0)K P(0) * P(1)KЧ P(1) * P(Nu-1)KP(Nu-1) = P. Прологарифмируем полученное равенство:
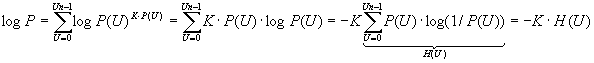
В силу равновероятности число сообщений в высоко вероятном подмножестве К1>1/P, учитывая полученное выражение для логарифма P, К1 можно выразить через энтропию источника.
P=2-K H(U), K1=1/P=2K H(U) (2.4)
Поскольку L=NuK=2K log(Nu)
|
( (2.5) |
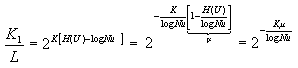
где m - избыточность источника. Анализ выражения (2.5) показывает, что при любой не нулевой избыточности источника m число сообщений высоко вероятного подмножества составляет сколь угодно малую часть от всех возможных сообщений если длина сообщения К достаточно велика (сколь угодно малую вероятность имеет большая часть достаточно длинных сообщений). Это большинство и позволяет добиться близкого к минимуму числа h кодовых символов на элемент сообщения, применен следующий способ кодирования. Высоко вероятной группе сообщений поставим в однозначное соответствие различные короткие (их мало) кодовые комбинации равномерного кода длинны n1, оставив одну для использования в качестве разделительного сигнала. Для остальных К2=L-K1 >L сообщений, составляющих мало вероятное подмножество. Используем более длинные кодовые комбинации, содержащие n2 символов, начинающихся с упомянутой выше разделительной комбинации длинны n1 (для того, чтобы при декодировании можно разграничить принимаемые сообщения). Длины кодов n1 и n2 определим из условия
![]() (2.6),
(2.6),
где S - число различных кодовых комбинаций
равномерного кода, m - объем
алфавита кодовых символов, n - число
символов (длинна кодовой комбинации).
Полагая в (2.6) S=K1+1+l, n=n1, где l - число
дополняющее К1+1 до
![]() можно
записать
можно
записать
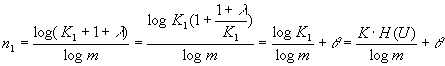 ,
где
,
где
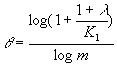 .
Увеличивая, число К можно сколь угодно
уменьшить число q по сравнению с тем
числом, с которым оно суммируется (при
КR ? и К1R ?). Рассуждая, аналогично получим
выражение для n2 с учетом разделительной
комбинации.
.
Увеличивая, число К можно сколь угодно
уменьшить число q по сравнению с тем
числом, с которым оно суммируется (при
КR ? и К1R ?). Рассуждая, аналогично получим
выражение для n2 с учетом разделительной
комбинации.
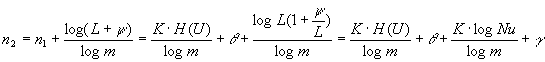 ,
,
![]() ,
(про y и g можно сказать тоже самое, что
про l и q).
,
(про y и g можно сказать тоже самое, что
про l и q).
Поскольку средняя длинна кодовой
комбинации при этом равна
![]() ,
то среднее число кодовых символов
приходящихся на один элемент сообщения
равно
,
то среднее число кодовых символов
приходящихся на один элемент сообщения
равно
![]() ,
где
,
где
![]() .
Где x становится сколь угодно малым при
больших К. Это и доказывает прямую
теорему.
В приведенном доказательстве
мы полагали, что множество мало вероятных
последовательностей кодируется длинными
кодовыми комбинациями (длину n2+n1), делает
возможным их однозначное декодирование.
Однако в принципе всем сообщениям этой
группы можно поставить в соответствие
одну и туже разделительную комбинацию
длиной n1 , и, определив по ней принадлежность
принятого сообщения
к мало вероятной группе отбрасывать их
как ошибочные. Поскольку с ростом К
вероятность нетипичных сообщений
становится сколь угодно малой, сколь
угодно малой будет вероятность ошибки.
Данное замечание не меняет существа
приведенного доказательства, но позволяет
назвать рассмотренный в нем вариант
кодирования равномерным кодированием.
.
Где x становится сколь угодно малым при
больших К. Это и доказывает прямую
теорему.
В приведенном доказательстве
мы полагали, что множество мало вероятных
последовательностей кодируется длинными
кодовыми комбинациями (длину n2+n1), делает
возможным их однозначное декодирование.
Однако в принципе всем сообщениям этой
группы можно поставить в соответствие
одну и туже разделительную комбинацию
длиной n1 , и, определив по ней принадлежность
принятого сообщения
к мало вероятной группе отбрасывать их
как ошибочные. Поскольку с ростом К
вероятность нетипичных сообщений
становится сколь угодно малой, сколь
угодно малой будет вероятность ошибки.
Данное замечание не меняет существа
приведенного доказательства, но позволяет
назвать рассмотренный в нем вариант
кодирования равномерным кодированием.