

Параграф 2.5. Теорема Шеннона для дискретного канала с шумом
Данная теорема является фундаментальным положением Теории Информации и называется так же основной теоремой кодирования Шеннона. Она может быть сформулирована следующим образом: если производительность источника сообщений H(U) меньше пропускной способности канала С т.е. H(U) < C, то существует такая система кодирования которая обеспечивает возможность передачи сообщений источника со сколь угодно малой вероятностью ошибки (или со сколь угодно малой ненадежностью). Если H(U) > C, то можно закодировать сообщение таким образом, что ненадежность в единицу времени будет меньше, чем H(U) – C+ ε, то H’(U / U*) < H’(U) – C+ ε (прямая теорема). Не существует способа кодирования обеспечивающего ненадежность в единицу времени меньшую, чем H(U)-C (обратная теорема).
В такой формулировке эта теорема была дана самим Шенноном. В литературе часто вторая часть прямой теоремы и обратная теорема объединяются в виде обратной теоремы сформулированной так: если H(U) > C, то такого способа кодирования не существует. Для доказательства первой части прямой теоремы воспользуемся результатами рассмотрения (см. п.2.2) множества длинных последовательностей элементарных дискретных сообщений источника, распадающегося как показано в п.2.2 на подмножества высоко вероятных или типичных и мало вероятных или нетипичных последовательностей. Пусть при некотором ансамбле входных сигналов дискретного канала Z обеспечивается пропускная способность канала C = I(Z,Z*)=H(Z) – H (Z/Z*) (2.16).
В соответствии с равенством (2.4) число типичных последовательностей входных сигналов канала достаточно большой длительности Т (содержащих большое число символов К) равно K1(Z)=2K H(Z) (2.17).
Поскольку H’(Z)= Vk H(Z), где Vk количество символов кода Z переданных в единицу времени Т=К/Vk, то
![]() ,
,
поэтому равенство (2.17) можно записать в виде
![]() (2.18).
(2.18).
Передаче подлежат сообщения выдаваемые дискретным источником U с производительностью меньше H’(U)< C= H’(Z) – H’ (Z/Z*), откуда следует
H’(U)+H’ (Z/Z*)< H’(Z) (2.19).
Поскольку H’(Z/Z*) > 0 из (2.19) вытекает, что H’(U)< H’(Z) (2.20). При этом число типичных последовательностей источника достаточно большой длительности Т, аналогично (2.18) можно определить так
![]() (2.21).
(2.21).
Вследствие условия (2.20) число типичных последовательностей канала значительно превосходит типичное число последовательностей источника
|
(2.22). |
Осуществим кодирование
типичных последовательностей источника.
В процессе кодирования каждой типичной
последовательности источника поставим
в соответствие одну из типичных
последовательностей канальных сигналов.
Нетипичные последовательности сообщений
длительности Т (если источник все же
выдаст одну из них) передавать не будет,
соглашаясь с тем, что каждая такая
последовательность будет принята
ошибочно. Выполним указанное кодирование
всеми возможными способами и усредним
вероятность ошибок по всему этому
большому (вследствие (2.22)) классу возможных
систем кодирования. Это равносильно
вычислению вероятности ошибок при
случайном связывании типичных
последовательностей источника сообщений
и канальных сигналов. Очевидно, что
число возможных кодов М равно числу
размещений из K1(Z) числу элементов по
K1(U)
![]() .
Для того, чтобы оценить среднюю вероятность
ошибки отметим следующее. Пройдя через
канал каждая из типичных последовательностей
канала может в следствии воздействия
помех преобразоваться в такое количество
.
Для того, чтобы оценить среднюю вероятность
ошибки отметим следующее. Пройдя через
канал каждая из типичных последовательностей
канала может в следствии воздействия
помех преобразоваться в такое количество
![]() типичных
последовательностей выхода (образованием
маловероятных нетипичных последовательностей
выхода будем пренебрегать). В свою
очередь в следствии ненадежности канала
H(Z/Z*) каждая типичная выходная
последовательность может быть обусловлена
одной из
типичных
последовательностей выхода (образованием
маловероятных нетипичных последовательностей
выхода будем пренебрегать). В свою
очередь в следствии ненадежности канала
H(Z/Z*) каждая типичная выходная
последовательность может быть обусловлена
одной из
![]() (2.23)
типичных входных канальных
последовательностей. Данная ситуация
иллюстрируется на рисунке 2.2. П
(2.23)
типичных входных канальных
последовательностей. Данная ситуация
иллюстрируется на рисунке 2.2. П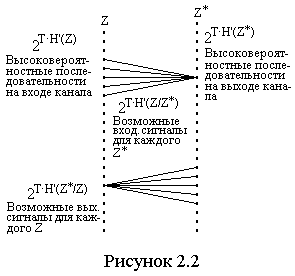 редположим,
что наблюдается некоторая входная
последовательность Z* которая могла
быть образована K1(Z/Z*) типичными
входными последовательностями канала.
Если среди этой совокупности входных
последовательностей канала содержится
только одна из числа использованных
при кодированных источника сообщений,
то очевидно она и передавалась, и
следовательно соответствующая ей
последовательность сообщений может
быть принята верно. Ошибочный прием
типичной последовательности передаваемых
сообщений неизбежен лишь тогда, когда
среди количества K1(Z/Z*)
последовательностей сигналов имеются
две или более использованные при
кодировании. Средняя вероятность
правильного приема типичной
последовательности
редположим,
что наблюдается некоторая входная
последовательность Z* которая могла
быть образована K1(Z/Z*) типичными
входными последовательностями канала.
Если среди этой совокупности входных
последовательностей канала содержится
только одна из числа использованных
при кодированных источника сообщений,
то очевидно она и передавалась, и
следовательно соответствующая ей
последовательность сообщений может
быть принята верно. Ошибочный прием
типичной последовательности передаваемых
сообщений неизбежен лишь тогда, когда
среди количества K1(Z/Z*)
последовательностей сигналов имеются
две или более использованные при
кодировании. Средняя вероятность
правильного приема типичной
последовательности
![]() равна
вероятности того, что среди количества
K1(Z/Z*) входных последовательностей
канала K1(Z/Z*) – 1 не использовано
при кодировании, а одна использована.
Вероятность того, что какая-то одна
типичная последовательность канальных
сигналов использована при кодировании,
в силу равно вероятности выбора равна
равна
вероятности того, что среди количества
K1(Z/Z*) входных последовательностей
канала K1(Z/Z*) – 1 не использовано
при кодировании, а одна использована.
Вероятность того, что какая-то одна
типичная последовательность канальных
сигналов использована при кодировании,
в силу равно вероятности выбора равна
![]() (2.24),
(2.24),
а вероятность того, что она не использована, определяется как
![]() ,
,
поскольку вероятность того, что один
из канальных сигналов выбран, при
кодировании равна единице. Следовательно
средняя вероятность того, что при
кодировании не использована K1(Z/Z*)-1
входных последовательностей
![]() .
Полагая K1(Z/Z*) >> 1 (что справедливо
при большом Т) можно записать
.
Полагая K1(Z/Z*) >> 1 (что справедливо
при большом Т) можно записать
![]() (2.25).
(2.25).
Разлагая (2.25) в бином Ньютона и с учетом условия (2.24), ограничиваясь двумя первыми членами разложения, можно записать
![]() (2.26).
(2.26).
Средняя вероятность ошибочного приема
типичной последовательности при
достаточно больших Т
![]() или
с учетом (2.21, 2.17, 2.23, 2.16).
или
с учетом (2.21, 2.17, 2.23, 2.16).
![]() (2.27).
(2.27).
Результирующая средней вероятности ошибки с учетом возможности появления и нетипичных последовательностей с суммарной вероятностью δ она равна
![]() (2.28).
(2.28).
Поскольку по условию теоремы (2.15) C–H’(U)
> 0, то как следует из (2.27 и 2.28) с ростом
Т
![]() ,
так как при этом стремятся к нулю как
,
так как при этом стремятся к нулю как
![]() (см.2.27)
так и δ (см. п.2.2). Следовательно, при любом
заданном ε0 > 0 можно выбрать
столь большое Т, что будем иметь
(см.2.27)
так и δ (см. п.2.2). Следовательно, при любом
заданном ε0 > 0 можно выбрать
столь большое Т, что будем иметь
![]() ,
но если среднее некоторого множества
чисел не больше чем ε0, то в этом
множестве должно существовать по крайней
мере одно число меньше ε0. Поэтому
среди всех возможных М кодов обеспечивающих
среднее значение
,
но если среднее некоторого множества
чисел не больше чем ε0, то в этом
множестве должно существовать по крайней
мере одно число меньше ε0. Поэтому
среди всех возможных М кодов обеспечивающих
среднее значение
![]() обязательно
существует хотя бы один у которого
вероятность ошибки не превышает
.
Таким образом первая часть теоремы
Шеннона доказана.
обязательно
существует хотя бы один у которого
вероятность ошибки не превышает
.
Таким образом первая часть теоремы
Шеннона доказана.
Вторую часть прямой теоремы легко доказать исходя из того, что можно просто передавать С бит в секунду от источника сообщений совсем пренебрегая остатком создаваемой информации. В приемнике это не учитываемая часть создаст ненадежность в секунду времени H’(U)-C, а передаваемая часть в соответствии с доказанным выше добавит ε. Доказательство обратной теоремы произведем методом от противного. Рассмотрим сначала ее формулировки предложенные Шенноном. Предположим, что производительность источника сообщений равна H’(U)=C+а, где а > 0 . По условию теоремы минимально достижимое в этом случае значение ненадежности
![]() .
.
Мы же будем считать, что существует
способ кодирования,
обеспечивающий значение
![]() ,
где ε > 0. Однако при этом оказывается
реализованной скорость
передачи информации
,
где ε > 0. Однако при этом оказывается
реализованной скорость
передачи информации
![]() ,
,
это противоречит определению пропускной способности как максимальной скорости передачи информации по каналу, что и доказывает теорему. Рассмотрим вторую формулировку обратной теоремы. Положим, что источник сообщений имеет производительность H’ (U)=C+ ε > C, где ε > 0. И с помощью некоторого способа кодирования достигается ненадежность равная H’ (U/U*)= ε /2. Опять же это эквивалентно реализации скорости передачи информации
![]()
превышающей пропускную способность, что невозможно. Это противоречие доказывает теорему.
Физический смысл эффекта повышения вероятности при увеличении длительности кодируемых сообщений вытекающего из доказательства прямой теоремы заключается в том, что с ростом Т увеличивается степень усреднения шума действующего в канале и, следовательно, уменьшается степень его мешающего воздействия. Кодирование сообщений длительности Т способом предполагаемым при доказательстве теоремы Шеннона может начаться лишь тогда, когда сообщение целиком поступило на кодирующее устройство. Декодирование же может начаться, когда вся принятая последовательность поступила на декодирующее устройство. Поэтому задержка сообщений во времени между пунктами связи tсвязи=2T+t0, где t0 - время затрачиваемое на кодирование. Декодирование и прохождение по каналу. При большом Т можно принять, что tсвязи=2Т. Из (2.27) следует важный результат: верность связи тем выше (меньше вероятность ошибки), чем длиннее блок кодированной последовательности (т.е. тем больше разность С-H’(U) определяющей запас пропускной способности канала). Итак, следует принципиальная возможность обмена между вероятностью, задержкой и скоростью передачи информации. На практике сложность кодирования и декодирования существенно возрастают с ростом Т поэтому в современных условиях чаще предпочитают иметь умеренное значение Т и добиваться увеличения вероятности за счет менее полного использования пропускной способности канала.