

7.3. Двоичное кодирование звука
Развитие способов кодирования звуковой информации, а также движущихся изображений – анимации и видеозаписей – происходило с запаздыванием относительно рассмотренных выше разновидностей информации. Заметим, что под анимацией понимается похожее на мультипликацию “оживление” изображений, но выполняемое с помощь средств компьютерной графики. Анимация представляет собой последовательность незначительно отличающихся друг от друга, полученных с помощью компьютера картинок, которые фиксируют близкие по времени состояния движения какого-либо объекта или группы объектов. Приемлемые способы хранения и воспроизведения с помощью компьютера звуковых и видеозаписей появились только в девяностых годах двадцатого века. Эти способы работы со звуком и видео получили название мультимедийных технологий. Звук представляет собой достаточно сложное непрерывное колебание воздуха. Оказывается, что такие непрерывные сигналы можно с достаточной точностью представлять в виде суммы некоторого числа простейших синусоидальных колебаний. Причем каждое слагаемое, то есть каждая синусоида, может быть точно задана некоторым набором числовых параметров – амплитуды, фазы и частоты, которые можно рассматривать как код звука в некоторый момент времени. Такой подход к записи звука называется преобразованием в цифровую форму, оцифровыванием или дискретизацией, так как непрерывный звуковой сигнал заменяется дискретным (то есть состоящим из раздельных элементов) набором значений сигнала в некоторые моменты времени. Количество отсчетов сигнала в единицу времени называется частотой дискретизации. В настоящее время при записи звука в мультимедийных технологиях применяются частоты 8, 11, 22 и 44 кГц. Так, частота дискретизации 44 килогерца означает, что одна секунда непрерывного звучания заменяется набором из сорока четырех тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука.
Как отмечалось выше, каждый отдельный отсчет можно описать некоторой совокупностью чисел, которые затем можно представить в виде некоторого двоичного кода. Качество преобразования звука в цифровую форму определяется не только частотой дискретизации, но и количеством битов памяти, отводимых на запись кода одного отсчета. Этот параметр принято называть разрядностью преобразования. В настоящее время обычно используется разрядность 8,16 и 24 бит. На описанных выше принципах основывается формат WAV (от WAVeform-audio – волновая форма аудио) кодирования звука. Получить запись звука в этом формате можно от подключаемых к компьютеру микрофона, проигрывателя, магнитофона, телевизора и других стандартно используемых устройств работы со звуком. Однако формат WAV требует очень много памяти. Так, при записи стереофонического звука с частотой дискретизации 44 килогерца и разрядностью 16 бит – параметрами, дающими хорошее качество звучания, – на одну минуту записи требуется около десяти миллионов байтов памяти.
Кроме волнового формата WAV, для записи звука широко применяется формат с названием MIDI (Musical Instruments Digital Interface – цифровой интерфейс музыкальных инструментов). Фактически этот формат представляет собой набор инструкций, команд так называемого музыкального синтезатора – устройства, которое имитирует звучание реальных музыкальных инструментов. Команды синтезатора фактически являются указаниями на высоту ноты, длительность ее звучания, тип имитируемого музыкального инструмента и т. д. Таким образом, последовательность команд синтезатора представляет собой нечто вроде нотной записи музыкальной мелодии. Получить запись звука в формате MIDI можно только от специальных электромузыкальных инструментов, которые поддерживают интерфейс MIDI. Формат MIDI обеспечивает высокое качество звука и требует значительно меньше памяти, чем формат WAV.
Кодирование видеоинформации еще более сложная проблема, чем кодирование звуковой информации, так как нужно позаботиться не только о дискретизации непрерывных движений, но и о синхронизации изображения со звуковым сопровождением. В настоящее время для этого используется формат, которой называется AVI (Audio-Video Interleaved – чередующееся аудио и видео). Основные мультимедийные форматы AVI и WAV очень требовательны к памяти. Поэтому на практике применяются различные способы компрессии, то есть сжатия звуковых и видео- кодов. В настоящее время стандартными стали способы сжатия, предложенные MPEG (Moving Pictures Experts Group – группа экспертов по движущимся изображениям). В частности, стандарт MPEG описывает несколько популярных в настоящее время форматов записи звука. Так, например, при записи в формате МР3 при практически том же качестве звука требуется в десять раз меньше памяти, чем при использовании формата WAV. Существуют специальные программы, которые преобразуют записи звука из формата WAV в формат МР3. Совсем недавно был разработан стандарт MPEG-4, применение которого позволяет записать полнометражный цветной фильм со звуковым сопровождением на компакт-диск обычных размеров и качества.
Перед завершением обсуждения общих принципов кодирования информации хотелось бы обратить внимание на один важный момент. Возьмем какой-либо двоичный код, например 1000 1100(2). Если обратиться к приведенному выше фрагменту кодовой таблицы, то можно утверждать, что это код буквы “М”. С другой стороны, можно сказать, что этим кодом задается цвет одного из пикселов монохромного изображения. Наконец, если воспользоваться правилами перевода из двоичной системы в десятичную, то можно утверждать, что это код числа +14010 (в другой интерпретации это код числа –12010). Что же это на самом деле? Интерпретация, то есть истолкование смысла одного и того же машинного кода, может быть самой разной. Один и тот же код разными программами может рассматриваться и как число, и как текст, и как изображение, и как звук. Другими словами, как именно трактуется тот или иной машинный код, определяется обрабатывающей этот код программой.
КОЛИЧЕСТВЕННЫЕ ИНФОРМАЦИОННЫЕ ХАРАКТЕРИСТИКИ ДИСКРЕТНЫХ ИСТОЧНИКОВ СООБЩЕНИЙ И КАНАЛОВ
Количество информации в дискретном сообщении. Энтропия
Предположим, что источник сообщений может в каждый момент времени случайным образом принять одно из конечного множества возможных состояний. Такой источник называют дискретным источником сообщений. При этом принято говорить, что различные состояния реализуются вследствие выбора их источника. Каждому состоянию источника U ставиться в соответствие условное обозначение в виде знака. Совокупность знаков u1, u2,:,ui,:,uN соответствующих всем N возможным состояниям источника называют его алфавитом, а количество состояний N объемом алфавита. Формирование таким источником сообщений сводиться к выбору им некоторого состояния ui и выдачи соответствующего знака. Таким образом, под элементарным дискретным сообщением будем понимать символ ui выдаваемое источником, при этом в течение некоторого времени Т источник может выдать дискретное сообщение в виде последовательности элементарных дискретных сообщений, представляющей сбой набор символов ui (например, u5, u1, u3) каждый из которых имеет длительность ti секунд. В общем случае необязательно одинаковую для различных i. Такая модель источника сообщений соответствует реальной ситуации имеющей место в телеграфии (ticonst) и передаче данных (ti=const). Отдельные состояния источника могут выбираться им чаще, другие реже. Поэтому в общем случае он храниться дискретным ансамблем U т.е. полной совокупностью состояний с вероятностями их появления, составляющими в сумме 1.
 ,
,
![]() (1.0),
(1.0),
где P(ui) это вероятность выбора источником состояния ui. При выдаче источником сообщений в виде последовательности элементарных дискретных сообщений, полным вероятностным описанием является вероятность совместного появления набора различных символов ui в момент t1, t2,...,tn, где n - длина последовательности
![]() .
.
Располагая
такими сведениями об источнике можно
вычислить вероятность любого отрезка
сообщения длиной меньше n.
Если функция
![]() не
меняется во времени, если она
не
меняется во времени, если она
![]() при
любых ,
то источник называется стационарным.
Если при определении вероятностных
характеристик стационарного источника
усреднение по ансамблю можно заменить
усреднением по времени, то такой источник
называется эргодическим. Вероятностные
свойства эргодического источника можно
оценить, рассматривая лишь одну его
достаточно длинную реализацию. В каждом
элементарном сообщении содержится для
его получателя определенная информация
совокупность сведений о состоянии
дискретного источника сообщения.
Определяя количественную меру этой
информации, мы совершенно не будем
учитывать ее смыслового содержания,
так же ее значения для конкретного
получателя. Очевидно, что при отсутствии
сведений о состоянии источника имеется
неопределенность относительно того,
какое сообщение ui
из числа возможных им выбрано, а при
наличии этих сведений данная
неопределенность полностью исчезает.
Естественно количество информации
содержащейся в дискретном сообщении
измерять величиной исчезнувшей
неопределенности. Введем меру этой
неопределенности, которую можно
рассматривать и как меру количественной
информации. Мера должна удовлетворять
ряды естественных условий, одним из них
является необходимость ее монотонного
возрастания с увеличением возможности
выбора, т.е. объема алфавита источника
N.
Кроме того, желательно, чтобы вводимая
мера обладала свойством аддитивности
заключающееся в следующем: если 2
независимых источника с объемами
алфавита N
и M
рассматривать как один источник,
одновременно реализующий пары состояний
ni
и mi
то в соответствии с принципом аддитивности
полагают, что неопределенность
объединенного источника равна сумме
неопределенностей исходных источников.
Поскольку объемы алфавита объединенного
источника =N
M
то искомая функция при равной вероятности
состояний источников должна удовлетворять
условию f(N
M)=f(N)+f(M).
Можно математически строго показать,
что единственной функцией, при перемножении
аргументов которой значение функций
складываются, является логарифмическая
функция. Поэтому перечисленные требования
выполняются, если в качестве меры
неопределенности источника с
равновероятными состояниями и
характеризующего его ансамбля U
принять логарифм объема алфавита
источника
при
любых ,
то источник называется стационарным.
Если при определении вероятностных
характеристик стационарного источника
усреднение по ансамблю можно заменить
усреднением по времени, то такой источник
называется эргодическим. Вероятностные
свойства эргодического источника можно
оценить, рассматривая лишь одну его
достаточно длинную реализацию. В каждом
элементарном сообщении содержится для
его получателя определенная информация
совокупность сведений о состоянии
дискретного источника сообщения.
Определяя количественную меру этой
информации, мы совершенно не будем
учитывать ее смыслового содержания,
так же ее значения для конкретного
получателя. Очевидно, что при отсутствии
сведений о состоянии источника имеется
неопределенность относительно того,
какое сообщение ui
из числа возможных им выбрано, а при
наличии этих сведений данная
неопределенность полностью исчезает.
Естественно количество информации
содержащейся в дискретном сообщении
измерять величиной исчезнувшей
неопределенности. Введем меру этой
неопределенности, которую можно
рассматривать и как меру количественной
информации. Мера должна удовлетворять
ряды естественных условий, одним из них
является необходимость ее монотонного
возрастания с увеличением возможности
выбора, т.е. объема алфавита источника
N.
Кроме того, желательно, чтобы вводимая
мера обладала свойством аддитивности
заключающееся в следующем: если 2
независимых источника с объемами
алфавита N
и M
рассматривать как один источник,
одновременно реализующий пары состояний
ni
и mi
то в соответствии с принципом аддитивности
полагают, что неопределенность
объединенного источника равна сумме
неопределенностей исходных источников.
Поскольку объемы алфавита объединенного
источника =N
M
то искомая функция при равной вероятности
состояний источников должна удовлетворять
условию f(N
M)=f(N)+f(M).
Можно математически строго показать,
что единственной функцией, при перемножении
аргументов которой значение функций
складываются, является логарифмическая
функция. Поэтому перечисленные требования
выполняются, если в качестве меры
неопределенности источника с
равновероятными состояниями и
характеризующего его ансамбля U
принять логарифм объема алфавита
источника
![]() (1.1).
(1.1).
Легко видеть, что:
1) с ростом N величина H(U) монотонно возрастает. 2) в случае если объем алфавита источника N равен 1, т.е. когда неопределенность отсутствует,
![]() .
.
3) величина H(U) обладает свойством адетивности, поскольку
![]() .
.
Информационные характеристики дискретных сообщений. Краткие теоретические сведения.
Системы
передачи дискретной информации –
системы, в которых реализации сообщений
представляют собой последовательности
символов алфавита источника. Если m
– объем алфавита источника дискретных
сообщений, то совокупность элементарных
сообщений (символов)
 - алфавит источника. Априорная вероятность
появления символа
- алфавит источника. Априорная вероятность
появления символа
 при независимость его от предыдущих –
при независимость его от предыдущих –
 .
.
В общем
случае априорная вероятность появления
 будет условной:
будет условной:

 ,
где
,
где
 -
символы, сформированные источником до
символа
-
символы, сформированные источником до
символа
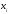 .
Количество информации, которое несет
символ
.
Количество информации, которое несет
символ ,
определяется формулой:
,
определяется формулой: .
.
Масштабный
коэффициент
 зависит от выбора единицы измерения
количества информации. Если единица
количества информации выбирается
двоичной, то
зависит от выбора единицы измерения
количества информации. Если единица
количества информации выбирается
двоичной, то
 и соответственно
и соответственно
 (бит)
(бит)
Основные информационные свойства дискретных сообщений:
1.Свойство аддитивность:
 ,
,
где q
– количество символов
 в сообщении,
в сообщении,
а
 принимает
одно из значений в пределах от 1 до m.
принимает
одно из значений в пределах от 1 до m.
2.
Среднее количество информации,
приходящейся на один символ источника
сообщений, при условном характере
априорной вероятности:

3.
Среднее количество информации,
приходящейся на один символ источника
сообщений, при зависимости вероятности
появления очередного символа
 только от вероятности появления
предыдущего символа
только от вероятности появления
предыдущего символа :
:

4. Среднее количество информации, приходящейся на один символ, при независимости символов источника сообщений:

является определением энтропии источника дискретных сообщений.
5.
Максимальная энтропия источника имеет
место при независимости и равновероятности
символов сообщения ( ):
):

6. Коэффициент избыточности:
 ,
,
где
 и
и
 – относительная скорость передачи
информации, характеризует возможность
оптимизации скорости передаваемой
информации.
– относительная скорость передачи
информации, характеризует возможность
оптимизации скорости передаваемой
информации.
Устранение избыточности позволяет сократить объем сообщения, а следовательно, повысить скорость передачи информации.
В канале с помехой передаваемая информация частично искажается.

Рис. 1
Как
показано на рис. 1, передаваемой сообщение
 под влиянием помехи n(t)
на выходе канала связи преобразуется
в сообщение
под влиянием помехи n(t)
на выходе канала связи преобразуется
в сообщение
 .
Если дискретный стационарный канал без
памяти, то
.
Если дискретный стационарный канал без
памяти, то
 и длительности символов
и длительности символов
 на выходе и входе канала одинаковы.
Тогда скорость передачи информации как
среднее количество информации, получаемое
в единицу времени, определяется
выражением:
на выходе и входе канала одинаковы.
Тогда скорость передачи информации как
среднее количество информации, получаемое
в единицу времени, определяется
выражением:
 ,
,
где
 – частота посылки символов, а
– частота посылки символов, а
 –
среднее количество взаимной информации
в множестве символов
–
среднее количество взаимной информации
в множестве символов
 относительно множества символов
относительно множества символов
 :
:

В
формуле
 –
условная энтропия множества символов
X
при данном множестве Y,
определяющая среднее количество
потерянной информации из-за влияния
помех;
–
условная энтропия множества символов
X
при данном множестве Y,
определяющая среднее количество
потерянной информации из-за влияния
помех;
 -
условная энтропия множества символов
Y
при данном множестве X,
определяющая шумовую энтропию;
-
условная энтропия множества символов
Y
при данном множестве X,
определяющая шумовую энтропию;
 - энтропия множества символов Y:
- энтропия множества символов Y:
 ,
,
 ,
,
 ,
,
Где

 -
вероятность ошибки воспроизведения
символа
-
вероятность ошибки воспроизведения
символа
 .
.
Скорость передачи информации определяется формулой:
 (бит/с)
(бит/с)
Пропускная способность дискретного канала связи определяется следующим выражением:
 ,
,
где

В
каналах без помех
 .
.
Информационные характеристики непрерывных сообщений. Краткие теоретические сведения.
Источник
непрерывных сообщений характеризуется
тем, что в каждый момент времени
 сообщение
сообщение
 может принимать бесконечное множество
значений с бесконечно малой вероятностью
каждого и них, и, если бы сообщение могло
передаваться абсолютно точно без
искажений, оно несло бы бесконечное
количество информации. Однако на практике
при передаче информации всегда имеют
место искажения и количество информации,
содержащееся в принятом непрерывном
сообщении, определяется разностью
значений энтропий сообщения до и после
получения информации. Эта разность
является конечной величиной.
может принимать бесконечное множество
значений с бесконечно малой вероятностью
каждого и них, и, если бы сообщение могло
передаваться абсолютно точно без
искажений, оно несло бы бесконечное
количество информации. Однако на практике
при передаче информации всегда имеют
место искажения и количество информации,
содержащееся в принятом непрерывном
сообщении, определяется разностью
значений энтропий сообщения до и после
получения информации. Эта разность
является конечной величиной.
Пусть
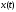 - реализация непрерывного сообщения на
входе канала связи,
- реализация непрерывного сообщения на
входе канала связи,
 – реализация выходного сообщения;
– реализация выходного сообщения;
 -
одномерная плотность вероятности
входных сообщений,
-
одномерная плотность вероятности
входных сообщений,
 -
одномерная плотность вероятности
выходных сообщений,
-
одномерная плотность вероятности
выходных сообщений,
 -
условная плотность вероятности
-
условная плотность вероятности
 при известном
при известном
 (апостериорная вероятность);
(апостериорная вероятность);
 -
условная плотность вероятности
-
условная плотность вероятности
 при
известном
при
известном
 ,
,
 - совместная плотность вероятности.
Тогда будут иметь место следующие
выражения:
- совместная плотность вероятности.
Тогда будут иметь место следующие
выражения:
-
Энтропия источника непрерывных сообщений:
 ,
,
где
 -
интервал квантования (точность измерения);
-
интервал квантования (точность измерения);
-
Дифференциальная энтропия источника непрерывных сообщений:
 б,
б,
Определяющая количество информации в битах, приходящейся в среднем на один отсчет.
-
Максимальная дифференциальная энтропия источника непрерывных сообщений:

Которая имеет место при нормальной плотности распределения случайного процесса:
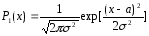 ,
,
 -
математическое ожидание случайной
величины,
-
математическое ожидание случайной
величины,
 - дисперсия этой величины,
- дисперсия этой величины,
 -
основание натурального логарифма.
-
основание натурального логарифма.
-
Полная средняя взаимная информация:
 ,
,
где
 - дифференциальная энтропия сообщения
- дифференциальная энтропия сообщения
 на выходе канала связи:
на выходе канала связи:
 -
-
дифференциальная условная энтропия, характеризующая действие шумового процесса.
-
Для аддитивной смеси
 при статистической независимости
нормальных процессов
при статистической независимости
нормальных процессов
 и помехи
и помехи :
:
 ,
,
 ,
,
 ,
,
где
 и
и
 - соответственно дисперсии процессов
- соответственно дисперсии процессов
 и
и
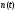 .
.
-
Пропускная способность канала связи для нормально распределенных сообщения и помехи:
 ,
(бит/с)
,
(бит/с)
где
 -
полоса пропускания канала.
-
полоса пропускания канала.
-
Пропускная способность канала связи при
 :
:
 ,
(бит/с)
,
(бит/с)
Где
 -
спектральная плотность аддитивной
помехи.
-
спектральная плотность аддитивной
помехи.
-
Пропускная способность канала связи при спектральной плотности
 гауссовского сигнала
гауссовского сигнала и спектральной плотности
и спектральной плотности
 аддитивной гауссовой помехи
аддитивной гауссовой помехи определяется:
определяется:
 ,
,
где
 - полоса пропускания канала.
- полоса пропускания канала.
-
Скорость передачи информации для гауссовских сигнала и аддитивной помехи:
 (бит/с),
(бит/с),
где
 -
эффективная полоса частот, занимаемая
информационным сигналом,
-
эффективная полоса частот, занимаемая
информационным сигналом,
 .
.
Многоканальные системы передачи информации. Обобщенная структурная схема, классификация, особенности применения.
Многоканальные системы передачи - которые имеют несколько каналов передачи информации. Каждый канал приемник - передатчик.

ГКИ - генератор канальных импульсов, УУ - устройство уплотнения, КФ – канальный модулятор.

ФУ - формирующее устройство, М – модулятор, ГН – генератор несущей, ДМК – демодулятор канальный.
В зависимости от видов уплотнения:
1) линейное уплотнение;
2) нелинейное уплотнение;
3) уплотнение логического типа.
4) мажоритарное
5) компенсационное
Соответственно линейное и нелинейное разделение.
При линейном уплотнении - канальные сигналы должны быть линейно независимы. Каждый из этих сигналов не может быть получен из сигналов
этой же системы - ортогональные.
Три вида ортогональности:
1) частотная ортогональность (ЧРК);
2) временная ортогональность (ВРК);
3) структурная ортогональность - кодовая (СУ),(СРК).
Многоканальная РТС ПИ с временным уплотнением канальных сигналов.
Для организации многоканальной передачи по одной линии связи необходимы операция уплотнения каналов на передающей части системы связи и операция разделения на приемной. Информация от нескольких источников передается в многоканальной радиолинии по общему ВЧ-тракту. В результате предварительного преобразования, кодирования выходных сигналов датчика формируются канальные сигналы. Канальные сигналы объединяются по определенному правилу, в результате чего образуется суммарный групповой сигнал (уплотнение).
Два метода объединения: линейный - простое суммирование канальных сигналов, мажоритарный - использование различных функций, применяется для передачи цифровой информации. При линейном уплотнении используются ортогональные сигналы.
На основании т. Котельникова можно передавать всю информацию, содержащуюся в сигнале с ограниченным спектром в виде выборок этого сигнала через равные интервалы времени. Для передачи выборок канал используется не полностью, и поэтому, используя временное разделение, можно передавать несколько сигналов.
В приемнике отсчеты, принадлежащие каждому сигналу выделяются с помощью соответствующих устройств. Частота выборок не меньше 2Фм, Фм– максимальная частота спектра передаваемого сообщения. Если выборку делать с более высокой частотой появятся защитные интервалы.

Величины С1, С2, С3, Сн преобразуются датчиками (Д), вх. сигналы датчиков поступают на первичные модуляторы (М – АИМ, ШИМ, ФИМ, КИМ).
Эти импульсы возникают в заданные моменты времени каждого канала. Работой коммутатора управляет ГТИ.
Такт. Импульсы также подаются на синхронизатор (С), синхроимпульсы должны по какому-либо параметру отличаться от канальных импульсов.
Коммутаторы в приемной и передающей частях должны работать синхронно. В синхронизаторе на приемной стороне синхронизатора. Импульсы отделяются и формируются. Напряжение, используемое для управления коммутатором. Он подключает канальные импульсы к соответстсвующим демодуляторам.
Многоканальная РТС ПИ с частотным уплотнением канальных сигналов.
В системах с ЧРК используются канальные сигналы, частотные спектры которых располагаются в не перекрывающихся частотных полосах. Формирование канальных сигналов при помощи АМ, ЧМ, ФМ, чтобы средние частоты спектров канальных сигналов соответствовали средним частотам отведенных полос каждого канала. Разделение с помощью частотных фильтров.

ГН – генератор несущей, ЛПР – производится выделение группового сигнала с помощью демодулятора.

Ф – фильтра, П – получатель.
Многоканальная РТС ПИ с уплотнением канальных сигналов по форме (кодовое линейное уплотнение).
I——|

Достоинства:
1) высокая потенциальная помехоустойчивость;
2) высокая информационная защищенность;
3) энергетическая скрытность системы;
4) возможно специальное помехоустойчивое кодирование группового сигнала;
5) универсальность. Недостатки:
1) повышенная сложность системы;
2) многоуровневый сигнал сложнее обрабатывается цифровым образом;
3) требуется время для выхода системы в синхронный режим;
4) количество уплотняемых каналов не превышает сотни.
Распознаватель адресов. Пусть ставится задача создания автомата, распознающего допустимые адреса электронной почты, которые представлены регулярным выражением:
Входная лента содержит строки: enin@moskou и enin@moskou.ru, которые проверяются на корректность.
На рисунке представлен конечный автомат, принимающий входные цепочки и принимающий решение о том, принадлежит ли входная цепочка множеству допустимых адресов электронной почты.
Начальное состояние – 1, конечное (допустимое) - К. Говорят, что автомат допускает цепочку (строку), если эта цепочка переводит его в одно из допустимых состояний. В противном случае – автомат отвергает строку. Множество всех строк, допускаемых автоматом, образуют язык, им распознаваемый.

Элементы регулярных выражений, использованные для описания строк языка адресов электронной почты, приведены в приложении к тексту лекции: таблица А. Элементы регулярных выражений в Microsoft.NET
Компиляция - лексический анализ. Этап лексического анализа при компиляции заключается в том, что текст исходной программы разбивается на последовательность лексем.
Теперь мы рассмотрим этот процесс не с позиции его описания средствами НФБ - грамматики, а опишем машинную модель распознавателя лексем.
-
Любой идентификатор должен начинаться с буквы; пока символы, следующие за ней, являются цифрами или буквами, они входят в имя этого идентификатора;
-
Целое число – просто последовательность цифр;
-
Зарезервированное слово if – это последовательность из двух символов;
Во всех этих случаев для распознавания лексем применяется простая модель под названием КОНЕЧНЫЙ АВТОМАТ (КА) или машина состояний. Пока мы знаем, в каком из состояний находимся, мы можем определить, является ли очередной вводимый символ частью лексемы, которую мы ищем.
Рассмотрим простой КА, задача которого – распознавать двоичные цепочки с нечетным количеством единиц (рис. 5.1). Процесс начинается с состояния А (содержащего дугу ввода, не выходящую из другого состояния), затем в зависимости от следующего введенного символа автомат переходит в одно из состояний, А или В, двигаясь вдоль дуги, помеченной этим символом. Очевидно, что состояние В (конечное состояние, обозначенное двойным кружком) соответствует нечетному количеству единиц во введенной цепочке. Поэтому, пока автомат находится в состоянии В, введенная на данный момент цепочка удовлетворяет предъявленному требованию и допускается автоматом. Когда автомат находится в состоянии А, такая цепочка не допускается.
Пусть на входе имеем цепочку 100101. Рассмотрим последовательность действий КА.
|
Ввод |
Текущее состояние |
Допускается ли цепочка |
|
Null |
А |
Нет |
|
1 |
В |
Да |
|
10 |
В |
Да |
|
100 |
В |
Да |
|
1001 |
А |
Нет |
|
10010 |
А |
Нет |
|
100101 |
В |
Да |

Рис. 5.1. КА, распознающий битовые цепочки с нечетным количеством единиц.
На рис. 5.2 изображен другой КА, распознающий целые числа со знаком. В расширенной нотации мы определили такие числа как: <целое со знаком>::=[+|-]<целое> {<целое>}*. Этот пример иллюстрирует еще одно важное свойство КА: между абстрактными машинами и грамматиками существует взаимное соответствие или КА может быть смоделирован при помощи грамматики.

Рис. 5.2. КА, распознающий целые числа с необязательным знаком
1. Введение
В настоящем реферате будут даны определения детермини-
рованных и недетерминированных конечных автоматов, приведе-
ны их графы. Далее будет рассмотрен случай преобразования
недетерминированного конечного автомата в детерминированный
с рисунками и графами.
Все рассмотренные здесь автоматы представлены как маши-
ны, распознающие цепочки символов.
2. Детерминированные конечные автоматы.
В различных источниках приводятся несколько отличающие-
ся друг от друга определения детерминированного конечного
автомата. Приведем здесь определение из источника [2].
Детерминированным конечным автоматом (ДКА) называется
машина, распознающая цепочки символов. Она имеет входную
ленту, разбитую на клетки, головку на входной ленте (вход-
ную головку) и управляющее устройство с конечным числом
состояний (рис. 1). Конечный автомат М можно представить в
виде пятерки (S, I, я1бя0, я1s0я0, F), где
1) S - множество состояний я1управляющего устройствая0,
2) I - я1входной алфавит я0(каждая клетка входной ленты со-
держит символ из I),
3) я1бя0 - отображение из S x I в S (если я1бя0(я1sя0, я1aя0) = я1s'я0, то
всякий раз, когда М находится в состоянии я1sя0, а входная
головка обозревает символ я1aя0, М сдвигает входную головку
вправо и переходит в состояниея1 s'я0),
4)я1 s0я0 - выделенное состояние в S, называемое я1начальнымя0,
5) F - подмножество в S, называемое множеством я1допуска-
я1ющихя0 (илия1 заключительныхя0)я1 состоянийя0.
ЪДДДДДВДДДДДВДДДДДї
і я1bя0 і я1aя0 і я1cя0 і Входная лента
АДДДДДБДДДДДБДДДДДЩ
^
і Головка
ЪДДБДДї
і я1sя0 і Управляющее устройство
АДДДДДЩ
Рис. 1. Конечный автомат
ДКА выполняет шаги, определяемые текущим состоянием его
блока управления и входным символом, обозреваемым входной
головкой. Каждый шаг состоит из перехода в новое состояние
и сдвига входной головки на одну клетку вправо. Оказывает-
ся, что язык представим регулярным [2] выражением тогда и
только тогда, когда он допускается некоторым конечным авто-
матом.
Далее будет приведено определение ДКА через определение
недетерминированного конечного автомата (НКА), то-есть
можно будет рассматривать ДКА в качестве подмножества НДКА.
2. Недетерминированные конечные автоматы
Для каждого состояния и каждого входного символа НКА
имеет нуль или более вариантов выбора следующего шага. Он
может также выбирать, сдвигать ему входную головку при из-
менении состояния или нет.
Приведем определение недетерминированного конечного ав-
томата.
Недетерминированным конечным автоматом называется пя-
терка (S, I,я1 бя0,я1 s0я0, F), где
1) S - конечное множество состояний устройства управле-
ния;
2) I -я1 алфавитя0 входных символов;
3) я1б я0- я1функция переходовя0, отображающая S x (I U {я1eя0}) в
множество подмножеств множества S;
4)я1 s0я0 (- S -я1 начальное состояниея0 устройства управления;
5) F я_( я.S - множество я1заключительных (допускающих) я0сос-
тояний.
С каждым НКА связан ориентированный граф, естественным
образом представляющий функцию переходов этого автомата.
Приведем определение для графа ( или диаграммы) перехо-
дов автомата М = (S, I, я1бя0, я1s0я0, F).
Графом переходов автомата М называют ориентированный
граф G = (S, E) с помеченными ребрами. Множество ребер Е и
метки определяются следующим образом. Если я1б(s, a) я0содержит
я1s' я0для некоторого я1a я0(- I U {я1eя0}, то ребро я1(s, s') я0принадле-
жит Е. Меткой ребра я1(s, s') я0служит множество тех я1b я0(- I U
{я1eя0}, для которыхя1 б(s, b)я0 содержитя1 s'я0.
Например на рис. 2. изображен граф переходов для неко-
торого НКА. Заключительное состояние обведено двойной рам-
кой.