

Принципы сжатия данных
В основе любого способа сжатия лежит модель источника данных, или, точнее, модель избыточности. Иными словами, для сжатия данных используются некоторые априорные сведения о том, какого рода данные сжимаются. Не обладая такими сведениями об источнике, невозможно сделать никаких предположений о преобразовании, которое позволило бы уменьшить объём сообщения. Модель избыточности может быть статической, неизменной для всего сжимаемого сообщения, либо строиться или параметризоваться на этапе сжатия (и восстановления). Можно выделить две группы режимов сжатия данных: статический и динамический; различают также физическое и логическое сжатие; симметричное и асимметричное сжатие; адаптивное, полуадаптивное и неадаптивное кодирование; сжатие без потерь, с потерями и минимизацией потерь. Способы (виды) сжатия данных:
Статическое сжатие данных (static data compression) — используется для длительного хранения и архивации; выполняется при помощи специальных сервисных программ-архиваторов, например ARJ, PKZIP/PKUNZIP. После восстановления (декомпрессии) исходная запись восстанавливается.
Динамическое сжатие (сжатие в реальном времени; dynamic compression, compression in real time) — предназначено для сокращения занимаемой области дисковой памяти данными, требующими оперативного доступа и вывода на внешние устройства ЭВМ (в том числе на экран монитора). Динамическое сжатие данных и их восстановление производится специальными программными средствами автоматически и «мгновенно».
Физическое сжатие (physical compression) — методология сжатия, при которой данные перестраиваются в более компактную форму «формально», то есть без учета характера содержащейся в них информации.
Логическое сжатие (logical compression) — методология, в соответствии с которой один набор алфавитных, цифровых или двоичных символов заменяется другим. При этом смысловое значение исходных данных сохраняется. Примером может служить замена словосочетания его аббревиатурой. Логическое сжатие производится на символьном или более высоком уровне и основано исключительно на содержании исходных данных. Логическое сжатие не применяется для изображений.
Симметричное сжатие (symmetric compression) — методология сжатия, в соответствии с которой принципы построения алгоритмов упаковки и распаковки данных близки или тесно взаимосвязаны. При использовании симметричного сжатия время, затрачиваемое на сжатие и распаковку данных, соизмеримо. В программах обмена данными обычно используется симметричное сжатие.
Асимметричное сжатие (asymmetric compression) — методология, в соответствии с которой при выполнении работ «в одном направлении» времени затрачивается больше, чем при выполнении работ в другом направлении. На сжатие изображений обычно затрачивается намного больше времени и системных ресурсов, чем на их распаковку. Эффективность этого подхода определяется тем, что сжатие изображений может производиться только один раз, а распаковываться с целью их отображения – многократно. Алгоритмы асимметричные «в обратном направлении» (на сжатие данных затрачивается меньше времени, чем на распаковку) используется при выполнении резервного копирования данных.
Адаптивное кодирование (adaptive encoding) — методология кодирования при сжатии данных, которая заранее не настраивается на определенный вид данных. Программы, использующие адаптивное кодирование, настраиваются на любой тип сжимаемых данных, добиваясь максимального сокращения их объема.
Неадаптивное кодирование (nonadaptive encoding) — методология кодирования, ориентированная на сжатие определенного типа или типов данных. Кодировщики, построенные по этому принципу, имеют в своем составе статические словари «предопределенных подстрок», о которых известно, что они часто появляются в кодируемых данных. Примером может служить метод сжатия Хаффмена.
Полуадаптивное кодирование (half-adaptive coding) — методология кодирования при сжатии данных, которая использует элементы адаптивного и неадаптивного кодирования. Принцип действия полуадаптивного кодирования заключается в том, что кодировщик выполняет две группы операций: вначале — просмотр массива кодируемых данных и построение для них словаря, а затем — собственно кодирование.Сжатие без потерь
Сжатие с потерями
Если при сжатии данных происходит изменение их содержимого, то метод сжатия называется необратимым, то есть при восстановлении (разархивировании) данных из архива не происходит полное восстановление информации. Такие методы часто называются методами сжатия с регулированными потерями информации. Понятно, что эти методы можно применять только для таких типов данных, для которых потеря части содержимого не приводит к существенному искажению информации. К таким типам данных относятся видео- и аудиоданные, а также графические данные. Методы сжатия с регулированными потерями информации обеспечивают значительно большую степень сжатия, но их нельзя применять к текстовым данным. Примерами форматов сжатия с потерями информации могут быть:
JPEG - для графических данных;
MPG - для для видеоданных;
MP3 - для аудиоданных.
Сжатие без потерь
Если при сжатии данных происходит только изменение структуры данных, то метод сжатия называется обратимым. В этом случае, из архива можно восстановить информацию полностью. Обратимые методы сжатия можно применять к любым типам данных, но они дают меньшую степень сжатия по сравнению с необратимыми методами сжатия. Примеры форматов сжатия без потери информации:
GIF, TIFF - для графических данных;
AVI - для видеоданных;
ZIP, ARJ, RAR, CAB, LH - для произвольных типов данных.
Существует много разных практических методов сжатия без потери информации, которые, как правило, имеют разную эффективность для разных типов данных и разных объемов. Однако, в основе этих методов лежат три теоретических алгоритма:
алгоритм RLE (Run Length Encoding);
алгоритмы группы KWE(KeyWord Encoding);
алгоритм Хаффмана.
Перед тем как, подробно рассматривать основные алгоритмы следует уяснить, что такое коэффициент сжатия.
Коэффициент сжатия — основная характеристика алгоритма сжатия. Она определяется как отношение объёма исходных несжатых данных к объёму сжатых, то есть:
k = So/Sc
где k — коэффициент сжатия, So — объём исходных данных, а Sc — объём сжатых. Таким образом, чем выше коэффициент сжатия, тем алгоритм эффективнее. Следует отметить:
если k = 1, то алгоритм не производит сжатия, то есть выходное сообщение оказывается по объёму равным входному;
если k < 1, то алгоритм порождает сообщение большего размера, нежели несжатое, то есть, совершает «вредную» работу.
Ситуация с k < 1
вполне возможна при сжатии. Принципиально
невозможно получить алгоритм сжатия
без потерь, который при любых данных
образовывал бы на выходе данные меньшей
или равной длины. Обоснование этого
факта заключается в том, что поскольку
число различных сообщений длиной n бит
составляет ровно
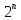 ,
число различных сообщений с длиной
меньшей или равной n (при наличии хотя
бы одного сообщения меньшей длины) будет
меньше
,
число различных сообщений с длиной
меньшей или равной n (при наличии хотя
бы одного сообщения меньшей длины) будет
меньше
 .
Это значит, что невозможно однозначно
сопоставить все исходные сообщения
сжатым: либо некоторые исходные сообщения
не будут иметь сжатого представления,
либо нескольким исходным сообщениям
будет соответствовать одно и то же
сжатое, а значит их нельзя отличить.
.
Это значит, что невозможно однозначно
сопоставить все исходные сообщения
сжатым: либо некоторые исходные сообщения
не будут иметь сжатого представления,
либо нескольким исходным сообщениям
будет соответствовать одно и то же
сжатое, а значит их нельзя отличить.