

Опциональность сегментов
Сегменты в документе имеют два типа опциональности:
M (mandatory) – обязательный сегмент. Обычно такие сегменты несут основную информацию в документе (без него документ или другие, зависимые сегменты, не могут быть поняты полностью и/или правильно). Если стандарт для данного документа определяет сегмент как обязательный, то он не может быть пропущен в документе. Примеры обязательных сегментов:
BEG*00*SA*ASNTESTORD**20060615~
Это (BEG) сегмент заголовка (см ниже, пункт Структура документа). Он содержит общую информацию документа (как «читать» сегменты – см. ниже):
-
назначение (00 – Original)
-
тип (SA - Stand-alone Order)
-
номер ордера (ASNTESTORD)
-
(20060615 – 6 Июня 2006)
Без этого сегмента нельзя было бы идентифицировать данный ордер.
PO1*001002003*10*EA*15**BP*123456411~
Это (PO1) сегмент деталей (см. ниже, пункт Структура документа). Он содержит базовые данные товара. Ордер заказа (PO) используется для заказа товара, и данные о товаре очевидным образом – основные данные этого документа, поэтому данный сегмент так же является обязательным.
O (optional) – необязательный, опциональный сегмент. Обычно это сегменты, содержащие второстепенную/вспомогательную информацию. Если стандарт определяет сегмент в документе как опциональный, то он может как присутствовать, так и отсутствовать, и при этом отсутствие опционального сегмента не будет являться ошибкой. Пример опционального сегмента:
PER*DC**TE*(123) 456-7890~
Это (PER) сегмент Administrative Communications Contact, т.е. «контактная информация». Он содержит следующую информацию (как «читать» сегменты – см. ниже):
-
контактное лицо по вопросам доставки (DC - Delivery Contact)
-
телефон (TE - Telephone)
-
собственно сам номер телефона - (123) 456-7890
Данная информация является опциональной, без нее данный документ может быть прочитан – что заказано, количество, стоимость и т.д.
Порядок следования сегментов
В документе сегменты идут друг за другом в порядке, определенном стандартом.
Повторение сегментов
Как вы могли заметить, в примере документа некоторые сегменты повторяются. Некоторые из них идут сразу друг за другом (DTM, PER), некоторые повторяются в составе групп (PO1/PID/ITA и N1/(N2)/N3/N4). Существует два типа «повторения» сегментов:
Возможность многократного использования сегмента.
В данном случае сегмент может повториться несколько раз, но при этом каждый сегмент имеет различное значение, т.е. несет разную информацию (сходную по смыслу, но разную по содержанию). Например, два DTM сегмента в примере документа определяют даты, но первый из них (DTM*002*20060625~) определяет дату поставки, а второй (DTM*010*20060618~) – дату погрузки. Аналогично PER сегменты – каждый определяет контактную информацию, при этом первый (PER*BD*DON SMITH~) определяет имя или название покупателя, а второй (PER*DC**TE*(123) 456-7890~) – телефон контактного лица по вопросам доставки. В документе для печати (который используется людьми) это могло бы выглядеть так:
Отдел продаж: +7 812 765 4321, Василий Смирнов Отдел доставки: +7 812 123 4567, Иван Иванов Склад: +7 812 321 7654, Петр Петров
Следует отметить, что часто уникальность сегмента заключается в использовании различных значений элемента (одного или иногда больше) идентификатора. В большинстве случаев в сегменте есть специальный элемент, который идентифицирует содержание сегмента. В сегменте DTM это, например, элемент DTM-01, в сегменте PER – PER-01.
Стандарт определяет максимально возможное количество таких повторений (max use).
Пример:
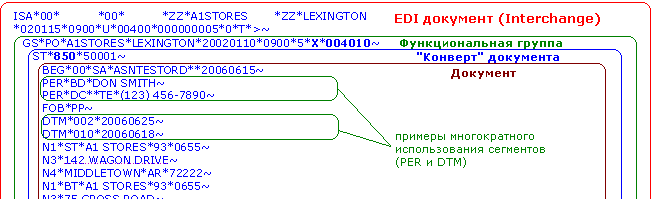
рис 4.
Циклическое повторение данных (Loops).
Циклическая группа сегментов (loop) – это набор связанных друг с другом сегментов, которые повторяются в EDI документе в определенной последовательности. Например, группа сегментов N1/N2/N3/N4 представляет информацию об адресе, причем N1 несет информацию об этом адресе, N3 – непосредственно сам адрес, и N4 – географическое расположение.
N1*ST*A1 STORES*93*0655~ N3*142 WAGON DRIVE~ N4*MIDDLETOWN*AR*72222~ N1*BT*A1 STORES*93*0655~ N3*75 CROSS ROAD~ N4*MIDDLETOWN*AR*72222~
Группа PO1/PID/ITA несет информацию о заказанном товаре, его цене и количестве (PO1), описание этого товара (PID) и скидке/наценке (ITA).
PO1*001002003*10*EA*15**BP*123456411~ PID*A****ADIDAS BLUE T-SHIRT~ ITA*A***CC***1000~ PO1*002003004*20*EA*20**BP*123456817~ PID*A****NIKE RED T-SHIRT~ ITA*A***CC***1500~
Такие циклические группы в свою очередь могут включать в себя другие циклические группы.
Пример:
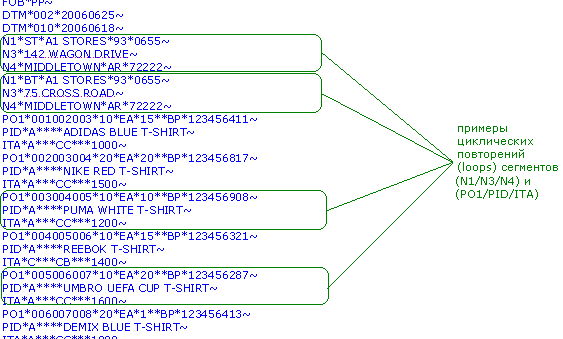
рис 5.
X12 определяет два типа циклических повторений (loops) – связанные (Bounded) и несвязанные (Unbounded).
Несвязанные повторения имеют стартовый сегмент, который определяет всю группу. «Внутри» этой группы находятся остальные сегменты, их опциональность определяется, как указано выше, однако эти «дочерние» сегменты группы не могут существовать отдельно от стартового сегмента. В нашем примере PO1/PID/ITA сегменты PID и ITA не могут присутствовать в документе, если им не предшествует сегмент PO1. Может быть ситуация когда либо сегмент PID, либо сегмент ITA отсутствуют в группе (так как они опциональны), но ситуации когда PID и/или ITA присутствуют но нет сегмента PO1 быть не может. Это верно, даже если сама группа является опциональной. Следующая группа определяется стартовым сегментом, например N1/N2/N3/N4/N1/N2/N3/N4/N1/N2/N3/N4/… (стартовый сегмент - N1) илиPO1/PID/ITA/PO1/PID/ITA/PO1/PID/ITA/PO1/PID/ITA… (стартовый сегмент – PO1) – тоесть, если в документе появляется стартовый сегмент, то он указывает на очередную группу.
Связанные повторения очень похожи на несвязанные, однако имеют отличие – такие группы сегментов ограничены «сверху» и «снизу» специальными сегментами – LS (Loop Start) и LE (Loop End). Такой подход используется стандартом, когда может быть невозможно определение начала и конца группы. В таких случаях начало и конец группы определяется не по стартовому сегменту собственно самой и следующей групп, а специальными сегментами LS и LE соответственно.
Как и в предыдущем случае, стандарт указывает максимальное количество повторений (Max Use) групп сегментов.