

5.6. Системы управления базами данных
Основные компоненты и их функции
Для создания и ведения БД, предполагающих их обновление, обеспечение доступа по запросам и выдачи по ним данных пользователю, используется набор языковых и программных средств - СУБД.
Современная СУБД - это некоторая программная оболочка, с помощью которой можно создать и далее эксплуатировать БД. В настоящее время существует, широко распространяется и используется, особенно коммерческими структурами, целый ряд различных по возможностям СУБД.
Выбор пользователем конкретной СУБД определяется имеющимся техническим и базовым программным обеспечением; спецификой предметной области; видом и объемом требуемой для БД памяти; необходимой производительностью обработки данных и т.д.
После установки (инсталляции) СУБД конкретизируется структура данных, производится наполнение БД, а также выполняются другие действия, предусмотренные ее функциональными возможностями. Современные СУБД обладают достаточной гибкостью и позволяют пользователю на самых ранних этапах разработки приложений создавать отдельные части БД и по мере разработки легко их модифицировать, облегчая и упрощая практическую реализацию и технологию работы с ними.
К важнейшим характеристикам современных СУБД относятся:
-
среда функционирования - класс ЭВМ и операционных систем (платформа), на которых базируется СУБД;
-
тип поддерживаемой модели данных (сетевая, иерархическая, реляционная и др.);
-
возможности встроенного языка, его совместимость с другими приложениями;
293
-
наличие развитых диалоговых средств конструирования (таблиц, форм, запросов, отчетов, макросов) и средств работы с БД;
-
возможность работы с нетрадиционными данными в корпоративных сетях (страницы HTML, сообщения электронной почты, изображения, звуковые файлы, видеоклипы и т. п.);
-
уровень использования: локальная (для настольных систем), архитектура «клиент-сервер», параллельная обработка данных и т.п.;
-
использование объектной технологии OLE (Object Linking and Embedding -связывание и внедрение объектов; стандарт, описывающий правила интеграции прикладных программ, что позволяет использовать приложения, созданные в разных операционных средах);
-
степень поддержки языка SQL и возможности работы с сервером баз данных (SQL-сервером) и др.;
-
возможности интеграции данных из разных СУБД. В частности, использование технологии ODBC (Open Database Connectivity - открытый доступ к БД), позволяющей работать с данными других БД при помощи средств SQL.
Вновь создаваемые БД - это, как правило, реляционные или объектно-ориентированные БД. В их СУБД можно выделить внутреннюю часть - ядро СУБД (часто его называют Data Base Engine), компилятор языка СУБД (обычно SQL) и подсистему поддержки выполнения запросов, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но такое разделение можно провести во всех современных СУБД. Компилятор преобразует операторы языка БД (языка, с помощью которого пользователь работает с БД, формулирует свои запросы) в выполняемую программу, а утилиты реализуют некоторые типовые процедуры, которые сложно реализовать с помощью языка БД (загрузка и выгрузка данных, сбор статистики, глобальная проверка целостности и т. д.).
Ядро СУБД управляет данными внешней памяти, буферами оперативной памяти, транзакциями и журнализацией, осуществляет поддержку языков БД. Ядро СУБД обладает собственным интерфейсом, обычно недоступным пользователям. В архитектуре «клиент — сервер» ядро является основной составляющей серверной части системы. Такие компоненты ядра в явном или неявном виде можно выделить в каждой системе.
К числу основных функций языковых и программных средств, предполагающих их обновление, относится обеспечение доступа по запросам и выдачи данных по ним пользователю, использующих набор СУБД, выполняющий ряд функций, рассмотренных ниже.
Непосредственное управление данными внешней памяти предусматривает размещение данных на устройствах внешней памяти с соответствующей служебной информацией, позволяющей вести контроль правильности записи и считывания, защиту от несанкционированного доступа; обеспечивать создание и модифицирование индексных таблиц для ускорения доступа к данным и др.
Управление буферами оперативной памяти. Одна из особенностей работы ЭВМ состоит в том, что выполняемая программа и обрабатываемые данные должны быть предварительно загружены в оперативную память. Посколь-
294
ку СУБД работают с БД значительного размера (превышающего доступный объем активной памяти), то приходится часто обращаться к внешнему устройству памяти, определяющему скорость решения задачи, что существенно замедляет выполнение программы. Эффективным способом решения этой проблемы является буферизация данных в оперативной памяти. В эти буферы предварительно помещаются данные, которые в будущем могут потребоваться программе для вычислений. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
Управление транзакциями необходимо для поддержания логической целостности БД. Транзакция рассматривается как последовательность операций над БД, которые СУБД оценивает как единое целое. СУБД фиксирует изменения БД, произведенные этой транзакцией во внешней памяти, отслеживает правильность выполнения транзакций, принимает соответствующие меры в сбойных ситуациях и др.
Ведение журналов изменений представляет собой систему восстановления утраченной информации на основе избыточности хранения данных. Ее основная цель - обеспечение одного из основных требований к СУБД, т.е. надежности хранения данных во внешней памяти, где регистрируются все изменения при проведении транзакций, запросы пользователей и т.д. Здесь под надежностью хранения понимается способность СУБД восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Одним из направлений поддержания заданного уровня надежности хранения БД является избыточность хранения данных. Информация, содержащаяся в журналах (иногда ведутся две копии журнала на разных физических дисках), позволяет проводить восстановление данных при аппаратных или программных сбоях, вести контроль действий пользователей и т.п.
Поддержка языковых средств СУБД предусматривает формирование запросов и диалогового взаимодействия, обеспечивающего необходимые условия и базовый пользовательский интерфейс для работы с БД.
Кроме языковых средств запросов и манипулирования данными, в состав СУБД часто включают встроенный алгоритмический язык и другие средства. Это позволяет не только вводить, удалять или редактировать данные БД, но и создавать самому пользователю дополнительные специальные программы-приложения для выполнения сложных вычислений и преобразований данных, формирования необходимых выходных форм документов и т.п.
Для создания дополнительных приложений СУБД может поддерживать работу с языками типа Pascal, С и т.п. Прикладная программа, написанная на этом языке, может инициировать команды СУБД. Стандартным языком запросов (базовым языком) в реляционных БД является язык структурированных запросов SQL (Structured Query Language). Реализация запросов может также обеспечиваться диалоговой системой команд с меню или запросами по примеру QBE (Query By Example). В последнем случае для выполнения запроса пользователь выбирает последовательно один или несколько пунктов меню или указывает в запросе образец (пример), по которому составляется запрос, а также
295
при необходимости условия выбора и операции вычисления, которые необходимо выполнять с данными (СУБД Paradox, Access). Последовательность команд меню и запросов может быть запомнена в программе-макросе и в дальнейшем выполнена так же, как командный файл.
Индексные таблицы и хэширование
В СУБД применяются специальные способы ускорения выполнения запросов.
Средством эффективного быстрого доступа к данным является использование индексов, которые представляют собой вспомогательные структуры (таблицы), позволяющие ускорить поиск данных путем уменьшения числа выполняемых при поиске операций.
При индексировании создается дополнительный файл, содержащий в упорядоченном виде все значения некоторого ключа, для каждого значения которого в индексном файле (таблице, списке) содержится указатель места соответствующей записи данных. При наличии индексного файла по заданному ключу быстрее отыскивается запись, причем индексирование может производиться не только по первичному, но и по вторичному ключу. Современные СУБД для ускорения поиска могут формировать несколько индексов.
 Если,
например, в БД информация о поставках
товара представлена табл. 5.14, из которой
необходимо выбрать сведения, касающиеся
некоторой фирмы или товара, тогда
для ускорения поиска нужных данных
создаются два разных индекса по
наименованиям фирм и по виду товаров
(табл. 5.15).
Если,
например, в БД информация о поставках
товара представлена табл. 5.14, из которой
необходимо выбрать сведения, касающиеся
некоторой фирмы или товара, тогда
для ускорения поиска нужных данных
создаются два разных индекса по
наименованиям фирм и по виду товаров
(табл. 5.15).
При этом значения полей в индексах «Товар» и «Фирма» отсортированы по алфавиту, что существенно ускоряет поиск нужных значений. Если, например, нужно выбрать все записи с наименованием товара «Сахар», то при наличии индекса не нужно просматривать все записи исходной БД. Достаточно найти в столбце «Товар» соответствующего индекса строку «Сахар» и получить список номеров всех записей, содержащих сведения
296
 о
данном товаре. Заметим, что для
ускорения поиска можно сделать еще и
индекс, указывающий на место начала
названий с каждой буквы алфавита. Тогда
сначала надо обратиться к «алфавитному»
индексу и найти место в индексе по товару
слов, начинающихся с буквы «С». Затем,
просматривая с указанного места
наименования товаров, найти строку
«Сахар», в которой второе (правое) поле
содержит номера искомых записей.
о
данном товаре. Заметим, что для
ускорения поиска можно сделать еще и
индекс, указывающий на место начала
названий с каждой буквы алфавита. Тогда
сначала надо обратиться к «алфавитному»
индексу и найти место в индексе по товару
слов, начинающихся с буквы «С». Затем,
просматривая с указанного места
наименования товаров, найти строку
«Сахар», в которой второе (правое) поле
содержит номера искомых записей.
Возможны разные способы организации индексирования. Часто индекс имеет древоподобную структуру, корень дерева которой содержит некоторый первичный список ссылок (значений ключа). Из корня «выходят» ветви к индексам (спискам) следующего - второго уровня. Каждая ссылка списка указывает на адрес расположения в памяти ЭВМ списка соответствующего индекса следующего уровня. Если некоторый индекс не имеет исходящих ветвей, то его называют «листом».
В качестве примера иерархической (древовидной) системы индексирования можно привести файловую систему ЭВМ, в которой используется иерархическая система индексов для определения места расположения папок (каталогов) на диске. Иерархичность является следствием того, что в любой папке могут регистрироваться и другие папки.
В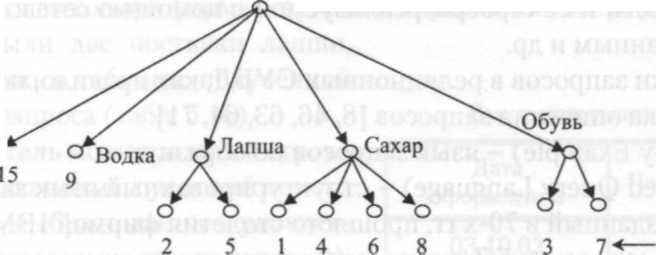 рассмотренном примере (см. табл. 5.14 и
5.15) индексы также можно представить в
виде древовидной структуры. Дерево
индекса по товару приведено на рис
5.18.
рассмотренном примере (см. табл. 5.14 и
5.15) индексы также можно представить в
виде древовидной структуры. Дерево
индекса по товару приведено на рис
5.18.
Сало о'
№ записей БД
Корневая вершина
Рис. 5.18. Дерево индекса по товару
Поиск данных с помощью индекса ведется путем последовательного задания значений ключей до тех пор, пока не будет определено место (адрес) искомых данных, обычно это «лист» дерева индекса.
297
Еще один способ ускорения поиска записи получил название «метод хэширования», идея которого базируется на том, что при заполнении БД с помощью специальной хэш-функции значение ключа преобразуется непосредственно в адрес, указывающий сегмент памяти, куда помещается соответствующая запись [8, 14, 64]. Когда пользователю надо выбрать данные из БД, он задает значение ключа, по которому с помощью той же хэш-функции формирует число - адрес сегмента. После чего в этом сегменте ЭВМ находит искомые данные.
Возможны разные варианты хэш-функции. В простейшем случае ее значение определяется как остаток деления числового значения ключа на число сегментов. Например, если значение ключа в некоторой записи эквивалентно десятичному числу 1000, а число сегментов БД равно 30, то значение хэш-функции для такого ключа будет равно остатку от деления 1000 на 30, т.е. будет равно 10. Следовательно, искомая запись располагается в 10-м сегменте БД.
Современные СУБД имеют средства автоматического построения индексов по определениям ключей. Так, в СУБД MS SQL Server 7.0 индексный файл можно создать с помощью программного средства Enterprise Manager или команды CREATE INDEX языка запросов T-SQL.
Языки запросов QBE и SQL
Хранимые в базе данные можно обрабатывать (выбирать, просматривать, редактировать и т.п.) с помощью имеющихся в каждой СУБД языковых и программных средств, для чего требуется создать запрос на этом языке.
Запрос представляет собой специальным образом описанное требование, определяющее состав производимых над БД операций обработки данных. Время выполнения запроса - важнейшая характеристика для пользователя СУБД, так как она определяет время ожидания пользователем ответа на его запрос. Очевидно, что время выполнения запроса зависит не только от модели представления данных, но и от параметров рабочей станции пользователя, вычислительной сети и ее сервера, реализуемой с помощью сетевой ОС технологии доступа к данным и др.
Для подготовки запросов в реляционных СУБД, как правило, используются два основных языка описания запросов [8, 46, 63, 64, 71]:
QBE (Query By Example) - язык запросов по образцу;
SQL (Structured Query Language) - структурированный язык запросов.
Язык QBE, созданный в 70-х гг. прошлого столетия фирмой IBM, позволяет задавать сложные запросы к БД путем заполнения предлагаемого пользователю шаблона, например, в форме таблицы. Поэтому его иногда называют графическим языком. Такой способ задания запросов обеспечивает высокую наглядность и не требует указания алгоритма выполнения операции - достаточно описать образец ожидаемого результата. Часто СУБД позволяют пользователю создавать запросы с помощью обоих типов языков (QBE и SQL). Обычно каждая
298
из современных реляционных СУБД имеет свой вариант языка QBE, который позволяет:
- формировать запросы с помощью шаблонов в виде таблиц и задавать форму вывода результатов;
- добавлять новые строки, изменять или удалять данные в реляционной БД. С помощью языка QBE можно задавать запросы для выбора данных из одной
или нескольких таблиц реляционной БД. Результатом выполнения запроса может быть новая или обновленная исходная таблица.
Выборка, вставка, удаление и модификация данных и записей могут выполняться с использованием условий, задаваемых с помощью логических выражений. Вычисления над данными в процессе выполнения запроса могут задаваться с помощью арифметических выражений.
В ряде современных СУБД, например в Access и Visual FoxPro, многие действия по подготовке запросов с помощью языка QBE выполняются визуально с помощью манипулятора типа «мышь». В частности, «связывание» таблиц при подготовке запроса выполняется «протаскиванием» мышью поля одной таблицы к полю другой. Такой язык используется в СУБД PARADOX for WINDOWS, Lotus 1-2-3 и др.
 На
рисунке 5.19
показан
пример запроса, где с помощью табличного
шаблона пользователь находит в реляционной
таблице (см. табл. 5.14)
фирмы,
поставляющие лапшу, и выводит на
печать их наименования и даты оформления
товара.
На
рисунке 5.19
показан
пример запроса, где с помощью табличного
шаблона пользователь находит в реляционной
таблице (см. табл. 5.14)
фирмы,
поставляющие лапшу, и выводит на
печать их наименования и даты оформления
товара.
Запросная форма (шаблон) представляет собой таблицу с атрибутами соответствующего отношения из БД и первоначально ее строки пустые. Пользователь формирует запрос, заполняя клетки формы в соответствии с требуемыми ему данными. Символы «р» в клетке формы (см. рис. 5.19) показывают, какие сведения надо показать в выходной форме результата выполнения запроса. Судя по данным табл. 5.14, были две поставки лапши,
что и отражено в таблице, полученной Таблица 5.16
в результате запроса (табл. 5.16). Результат выполнения запроса
|
Дата оформления |
Наименование фирмы |
|
03.10.02 |
Флагман |
|
07.10.02 |
Петрович |
Пользователь может задать в строке несколько независимых условий поиска (потребовать выбрать данные, удовлетворяющие каждому из таких условий), которые должны выполняться одновременно. В таком случае каждое из условий обычно указывается в отдельной строке запросной формы.
Если атрибут исходного отношения характеризуется числовыми значениями, то можно задать поиск кортежей или отдельных атрибутов, имею-
299
щих величину больше или меньше указанного значения. Тогда в соответствующей клетке запросной формы указывается число со знаком больше (меньше).
Язык QBE может поддерживать встроенные функции для нахождения наибольшего или наименьшего значения в столбце, подсчета среднего значения или суммы столбца и др.
Язык SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблиц (выборка, изменение, добавление и удаление), а также некоторых сопутствующих операций. Он закреплен стандартами, в частности американским ANSI SQL-92 и международным ISO SQL-92, часто используется в интеграции с встроенным в СУБД языком программирования.
Язык постоянно развивается, и в разных СУБД применяются свои особенности. Так, в широко используемой СУБД Microsoft SQL Server 7.0 употребляется диалект, получивший название Transact-SQL (Т- SQL) [63].
В современных СУБД с интерактивным интерфейсом можно создавать запросы, не прибегая к SQL, однако его применение во многих случаях позволяет расширить возможности использования СУБД. Так, при подготовке запроса в среде Access можно перейти из окна конструктора запросов (задания запроса по образцу) в окно с эквивалентным оператором SQL.
В составе SQL может быть выделено не менее трех групп инструкций (команд):
-
описание данных (DDL - Data Definition Language);
-
манипулирование данными (DML - Data Manipulation Language);
-
управление транзакциями.
Создание, удаление, изменение объектов БД осуществляется с помощью инструкций DDL, к которым относятся:
CREATE TABLE - создание таблицы;
DROP TABLE - удаление таблицы;
CREATE INDEX - создание индекса;
DROP INDEX - удаление индекса;
ALTER TABLE - изменение структуры таблицы;
CREATE DATABASE - создание базы данных;
SHOW DATABASE - просмотр базы данных и др.
Инструкции DML применяются для выборки, изменения, вставки и удаления отдельных записей таблиц. К ним относят:
SELECT - выбор записей, удовлетворяющих заданным
UPDATE
INSERT
DELETE
критериям;
-
изменение отдельных полей и записей;
-
добавление записей;
-
удаление записей.
300
Инструкция, кроме собственно имени команды, включает ряд операторов, которые определяют конкретные параметры и условия манипуляций с данными. Например, оператор SELECT имеет следующий формат:
SELECT [ALL/DISTINCT] <список данных>;
FROM <список таблиц>;
[WHERE <условие выборки>];
[GROUP BY <имя столбца> [,< имя столбца>]...];
[HAVING < условие поиска>];
[ORDER BY <спецификация сортировки> [< спецификация сортировки>]....].
Инструкция SELECT позволяет выбирать и вычислять данные одной или нескольких таблиц. Результатом ее выполнения является таблица, которая может иметь (ALL) или не иметь (DISTINCT) повторяющиеся строки.
В списке данных можно задавать имена столбцов и выражения над ними (арифметические и логические). Если записи отбираются из нескольких таблиц, то используют составные имена <имя таблицы>, <имя столбца>. При описании полей таблиц указываются типы данных (формат данных), которые будут храниться в этом поле.
Рассмотрим два примера формирования запросов на языке Т- SQL.
1. Создать в БД с именем bazal таблицу Gtd с полями Number, Goods, Code и Cost. В поля Number и Goods будут заноситься данные символьного типа длиной 20 байт, в поля Code и Cost - числа с плавающей точкой.
USE bazal
CREATE TABLE Gtd
Number char (20),
Goods char (20),
Code real,
Cost real GO
2. В БД с именем bazal находится таблица Gtd с полями: Number (номер ГТД), Goods (товар), Code (код товара), Cost (стоимость товара). Требуется выбрать группы (строки) полей Number, Goods и Cost, в которых поле Goods имеет значение Land Cruiser.
Такой запрос на языке SQL с использованием инструкции SELECT будет записан:
USE bazal
SELECT Number, Goods и Cost FROM Gtd
WHERE Goods = "Land Cruiser" GO
301
Инструкции третьей группы призваны управлять обработкой данных. Объектом управления являются транзакции, т.е. логически завершенные единицы работы с данными. К их числу относят, в частности, инструкции:
COMMIT - фиксация изменений при выполнении текущей транзакции;
SAVEPOINT - установка точки сохранения данных;
ROLLBACK - отмена изменений, сделанных в прошедшей транзакции, и др.
Следует отметить, что языковые и программные средства современных СУБД позволяют организовывать запросы по принципам обоих из вышерас-смотренных языков - QBE и SQL. Так, СУБД Microsoft SQL Server 7.0 позволяет создавать на основе языка Т- SQL сценарии. Каждый сценарий - это файл с набором инструкций языка по выполнению некоторой типовой процедуры работы с БД. Для выполнения сценария достаточно запустить файл на выполнение (полная аналогия с командным файлом MS - DOS).
Кроме QBE и SQL, существуют и другие языки запросов. В частности, к числу относительно новых относится XQuery - язык запросов для поиска документов в файлах и базах данных с тегами XML.
К числу важнейших характеристик БД и СУБД относят: время выполнения запроса (поиск необходимой информации), избыточность, независимость данных и обрабатывающих программ (независимость предполагает, что изменение данных не потребует изменения программ) и др.
Очевидно, что время выполнения запроса зависит не только от модели представления данных, но и от параметров PC, сервера и реализуемой с помощью сетевой ОС технологии доступа к данным.
Организация запросов в СУБД Microsoft Access
В настоящее время СУБД является неотъемлемой составляющей информационных систем. Без использования СУБД невозможно представить функционирование ЕАИС ФТС России. LlMeHHO поэтому уже в начале 2005 г. таможенными органами России наиболее широко применялись СУБД: Oracle - 53%, Access - 11%, MS SQL - 1%, DBF - 27%, Inter Base - 8%,
Рассмотрим организацию запросов на примере реляционной СУБД Microsoft Access, которая имеется на каждой ЭВМ с операционной системой корпорации Microsoft.
В этой СУБД результат обработки запроса представляет собой таблицу, называемую Dynaset. В эту таблицу включены выбранные из основной таблицы (или нескольких таблиц) блоки данных, которые удовлетворяют критериям запроса. Dynaset - динамический, временный набор данных, поэтому при каждом выполнении запроса он строится вновь на основе обновленных табличных данных.
Запросы, сформулированные в СУБД Microsoft Access, позволяют:
- выбрать отдельные поля таблиц;
302
- выбрать записи (специфицировать запрос для получения данных определенного вида);
- отсортировать записи (просматривать записи в определенном порядке);
-
запрашивать данные из нескольких таблиц, которые могут обрабатываться вместе, и просмотреть совмещенные данные;
-
запрашивать данные из других БД, таких как Microsoft Fox Pro, Paradox, dBASE, Betrive и Microsoft или Sybase SQL-серверы;
-
выполнять вычисления и создавать новые поля, содержащие результаты вычислений;
-
использовать запрос в качестве источника данных для формуляров, отчетов и других запросов;
-
изменять данные в таблицах (обновлять, удалять, добавлять группы записей все сразу);
- создавать новую таблицу на базе существующей или группы таблиц. Запрос можно создавать с помощью «Конструктора запросов» (т.е. по образцу), ускоряющего проектирование нескольких специальных типов запросов:
-
запросы кросс-таблиц позволяют представить данные в компактном интегрированном формате;
-
запросы нахождения дубликатов находят дубликатные записи в выбранной таблице или запросе;
-
запросы нахождения несоответствия находят все записи в таблице, которые не связаны с записями в других таблицах;
-
запросы архивов копируют записи из существующей таблицы в новую и затем по необходимости удаляют эти записи из таблицы оригинала.
Можно воспользоваться запросом для проведения вычислений с блоками данных. Этот запрос может задать в каждом поле некоторую функцию, обрабатывающую содержимое этого поля. Результат обработки выдается в виде таблицы Dynaset. При этом функция обработки задается в строке Total, которая появляется после нажатия в пиктографическом меню кнопки с греческой литерой «сигма». Функцию выбирают в этой строке, развернув список возможных значений.
С помощью структурированного языка запросов SQL в рамках Microsoft Access пользователь может сформулировать сколь угодно сложные по структуре критериев и вычислений запросы и управлять их обработкой.
Наряду с запросами выбора с помощью MS Access можно реализовать также запросы действий, параметрические запросы и запросы кросс-таблиц.
С помощью запроса действия можно изменять или переносить данные таблицы, а также актуализировать, добавлять или удалять группы блоков данных, создавать новые таблицы из набора Dynaset. Различают четыре типа запросов действий: запрос добавления, запрос удаления, запрос актуализации и запрос создания таблицы.
Часто используются запросы, которые представляют собой незначительно видоизмененные варианты ранее подготовленного базового запроса. Такие запросы называются параметрическими, они могут видоизменяться, но незна-
303
чительно. Для их реализации предварительно проектируется параметрический запрос, в котором указывается критерий (критерии), изменяемый по заказу пользователя.
Если необходимо объединить данные в формате строк-столбцов (двумерная таблица), то следует формировать запрос типа кросс-таблицы. При его проектировании можно указать в качестве заголовков столбцов значения некоторых полей или выражений.
Система управления базами данных Oracle
К концу 2006 г. в таможнях России наиболее широко применялись СУБД Fox Pro, Access, SQL Server, Clipper, dBase. В то же время еще в середине 90-х гг. региональные и центральная БД были переведены на СУБД Oracle. Многие новые программные разработки (даже для таможен) также используют СУБД Oracle в качестве основной. Создаваемые программные комплексы для электронного декларирования также ориентированы на использование СУБД Oracle.
Ее ядром является программный сервер базы данных, который поставляется в одной из четырех редакций в зависимости от масштаба информационной системы, в рамках которой предполагается его применение. Для систем масштаба крупной организации предлагается продукт Oracle Database Enterprise Edition (корпоративная редакция), который и используется для работы с данными в таможенных органах. Одной из основных характеристик СУБД Oracle является функционирование системы на большинстве платформ, в том числе на больших ЭВМ, UNIX-серверах, персональных компьютерах и т.д.
Другой важной характеристикой системы Oracle является поддержка всех возможных вариантов архитектур, в том числе симметричных многопроцессорных систем, кластеров, систем с массовым параллелизмом и т.д. Очевидна значимость этих характеристик для крупномасштабных организаций (к которым относится и ФТС России), где эксплуатируется множество компьютеров различных моделей и производителей. Основным средством доступа к базам данных Oracle из программ является (как и для других баз данных) декларативный язык запросов SQL. Этот язык по определению является платформо-независи-мым. На практике при разработке приложений используется процедурное расширение SQL, язык программирования PL/SQL, прототипом которому послужил язык Ада. В Oracle поддерживается также и язык Java [80].
СУБД Oracle имеет довольно совершенные средства обеспечения информационной безопасности, в частности предусмотрен учет и идентификация пользователей, определение и отслеживание их ролей, привилегий и профилей.
304
Отказоустойчивость баз данных
Кратковременные отказы или сбои ЭВМ (серверов) могут привести к нарушению целостности данных и, как следствие, к серьезным последствиям. Поэтому современные СУБД оцениваются по такому свойству, как отказоустойчивость.
Отказоустойчивость информационной системы - это способность сохранять работоспособность как при отказах некоторых ее элементов, так и при нарушении целостности части данных.
Так, в современных СУБД предусмотрены три специальных технологии восстановления данных:
-
создание резервного сервера;
-
кластеризация;
-
использование технологии RAID.
На практике часто в вычислительной сети создается дополнительный (резервный) сервер, который имеет свое имя, сетевой адрес и дублирует информацию основного сервера. С заданной периодичностью данные копируются с основного сервера на дополнительный. При этом пользователи могут обращаться к обоим серверам, однако к резервному доступ возможен только в режиме чтения. Нарушение работоспособности основного сервера переводит дополнительный из резервного режима в режим, полностью замещающий основной сервер. Это позволяет администратору сети в дальнейшем восстановить данные, утраченные основным сервером (копируя их с дополнительного).
Использование кластеризации предполагает создание виртуального сервера на основе нескольких ЭВМ. При этом пользователь обращается к серверу как единой ЭВМ. Понятно, что при отказе отдельных (одной из нескольких) ЭВМ остальные продолжают нормально функционировать.
Под технологией RAID понимается совокупность независимых и недорогих дисков с избыточным хранением данных (redundant array of inexpensive/ independent disks). Поскольку данные хранятся не на одном, а на нескольких жестких дисках, это, с одной стороны, создает проблемы координации их работы, а с другой - позволяет создавать отказоустойчивые дисковые системы хранения больших объемов данных.
Подключение нескольких дисков через специальный контроллер RAID позволяет создать логический (виртуальный) диск, который для ЭВМ и пользователей воспринимается как один большой (быстрый и надежный) диск.
Технология RAID основана на применении:
-
дублирования (mirroring) одних и тех же данных на двух разных дисках;
-
распределения (striping) по разным дискам порций данных (в том числе с кодами обнаружения и исправления ошибок), обеспечивающих полное восстановление данных при их частичной потере из-за отказа отдельных дисков.
При записи данные разбиваются на порции фиксированного размера и распределяются по дискам в порядке, определяемом схемой RAID. При этом возможна
20 Ю. В. MiL'ibiiueiiKO
305
одновременная запись на разные диски, что ускоряет запись данных. Считывание выполняется в обратном порядке - путем сбора порций данных с разных дисков.
Распределение данных малыми порциями по разным дискам позволяет увеличить пропускную способность операций чтения и записи; при соответствующем размещении исключаются частые обращения к одному диску, что существенно повышает отказоустойчивость и надежность функционирования.
Возможно аппаратное или программное управление RAID-дисками.
В первом варианте - это специальный комплекс, состоящий из набора дисков со специальным аппаратурным контроллером, который распределяет данные по дискам, контролирует и при повреждении одного из них в автоматическом режиме восстанавливает весь массив данных.
Во втором случае - это множество самостоятельных дисков, работу с которыми организует операционная система. Именно этот вариант реализован для хранения файлов SQL Server 2000.