

5.3. Файловая модель
представления данных
Основные компоненты модели
Исторически первыми системами хранения и обработки данных на ЭВМ была файловая организация данных. При такой модели внутримашинная система размещения данных представляет собой совокупность не связанных между собой обычных компьютерных файлов из однотипных записей с линейной (одноуровневой)структурой.
Основные компоненты структуры данных файловой модели - поле, запись, файл (рис. 5.10).
Поле - элементарная единица логической организации данных, которая соответствует отдельной, неделимой единице информации - реквизиту.
Запись - совокупность полей, соответствующих логически связанным реквизитам. Структура записи определяется составом и последовательностью входящих в нее полей, каждое из которых содержит элементарные данные.
270
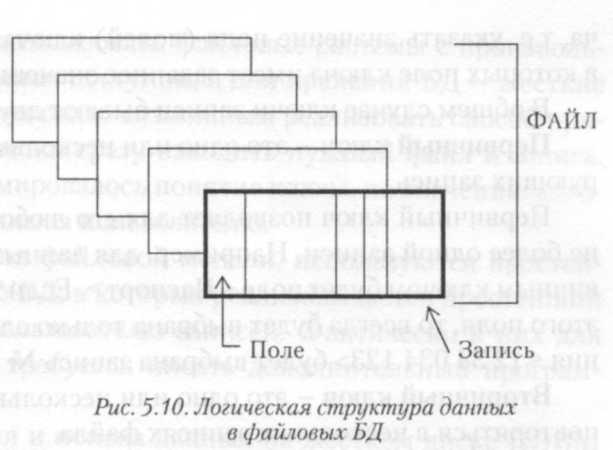
Агрегат - несколько функционально связанных полей данных.
Так, поля со значениями года, месяца и дня можно рассматривать как некоторый агрегат.
Экземпляр записи представляет собой описание некоторого конкретного объекта типовой структуры.
Допустим, надо создать БД файлового типа, содержащую сведения о сотрудниках некоторой организации (табл. 5.2). Тогда в качестве отдельной записи будет рассматриваться информация каждой из строк табл. 5.2, в качестве k-го поля - данные к-го столбца в соответствующей строке (т.е. первое поле каждой записи будет содержать номер отдела, второе - фамилию, третье - год рождения и т.д.). Таким образом, БД будет содержать 7 записей одного типа, каждая из 6 полей.
Таблица 5.2
Информация о сотрудниках
|
Отдел |
Фамилия |
Год рождения |
Должность |
Паспорт |
Номер записи |
|
10 |
Иванов |
1949 |
Нач.отдела |
05 03 072072 |
1 |
|
10 |
Поддубный |
1971 |
Ст. инспектор |
05 03 072081 |
2 |
|
20 |
Петров |
1972 |
Вед. инспектор |
02 78 123123 |
3 |
|
20 |
Кац |
1953 |
Нач. отдела |
12 34 034123 |
4 |
|
20 |
Могильный |
1961 |
Инспектор |
03 06 035321 |
5 |
|
30 |
Иванов |
1971 |
Инспектор |
02 35 088456 |
6 |
|
30 |
Ковтун |
1953 |
Нач. отдела |
05 03 178098 |
7 |
В принципе в файловой БД могут быть записи нескольких типов, различающихся числом и составом полей. Тогда каждый тип записей организуется в свой файл.
Ключи для выбора записей
Выбор из БД записей, необходимых пользователю, требует формирования соответствующего запроса. Этот запрос выполняется с помощью ключа. Поэтому для выбора нужной информации необходимо задать значение клю-
271
ча, т.е. указать значение поля (полей) ключа. После этого СУБД ищет записи, в которых поле ключа имеет заданное значение.
В общем случае ключи записи бывают двух видов: первичный и вторичный.
Первичный ключ - это одно или несколько полей, однозначно идентифицирующих запись.
Первичный ключ позволяет для его любого значения всегда находить в БД не более одной записи. Например, для данных, представленных в табл. 5.2, первичным ключом будет поле <Паспорт>. Если задать любое допустимое значение этого поля, то всегда будет выбрана только одна запись. Так, при задании значения <12 34 034 123> будет выбрана запись № 4.
Вторичный ключ - это одно или несколько полей, значение которых может повторяться в нескольких записях файла.
Такой ключ используется, когда указанному в запросе требованию в БД могут соответствовать несколько записей. Допустим, нам надо выбрать сотрудников, родившихся в некотором году. Для рассматриваемого выше примера поле <Год рождения> будет вторичным ключом, так как для значения ключа «1953» в БД будет найдено две записи: № 4 и № 7.
Заметим, что может быть несколько разных первичных и (или) вторичных ключей. Так, в табл. 5.2, кроме поля <Паспорт>, первичным ключом является и поле < Номер записи>.
Если ключ состоит из одного поля, то называется простым, если из нескольких полей - составным.
Организация поиска записей
При создании БД нужно определить структуру записи, перечень входящих в нее полей и их порядок внутри записи. Для каждого поля и самой записи требуется установить длину в байтах, форматы представления в полях числовых и других данных (стандарты допускают использование ЭВМ нескольких разных форматов представления данных в ячейках памяти). В соответствии с этим разрабатываются программные средства для формирования и хранения файлов и записей в памяти ЭВМ, а также для выбора и обработки данных по запросам пользователей.
Возможности БД файлового типа в значительной мере определяются возможностями файловой системы ЭВМ.
Первоначально, когда жесткие диски и оперативная память имели небольшую емкость, файлы БД располагались на магнитных лентах. Особенность работы с магнитными лентами состоит в том, что файлы располагаются на ленте последовательно друг за другом и для доступа к нужной записи необходимо прокрутить ленту до места ее расположения. Иными словами, в файловых системах ЭВМ первых поколений реализовывался последовательный метод доступа к данным, когда для извлечения нужной записи надо было прочитать все предыдущие. Поэтому первые файловые БД требовали длительного времени поиска данных.
272
В последующем ЭВМ стали использовать файловые системы с произвольным или индексно-последовательным доступом, а для хранения БД - жесткие диски и оперативную память. В них стало возможным реализовать способ прямого доступа к памяти и практически сразу находить нужный файл и запись. Именно тогда окончательно сформировалось понятие ключа, по значению которого определяется запись, необходимая пользователю.
В базах данных, основанных на файловой модели, используются простейшие по современным понятиям СУБД, в которых реализовывается простейший механизм поиска необходимых пользователю записей. Фактически в них для реализации запроса нового типа требуется писать дополнительный программный модуль.
Заметим, что система хранения и поиска данных на жестком диске ПЭВМ и есть некоторый вариант БД файлового типа.
Рассмотрим, например, как физически располагаются записи на жестком диске и организуется выборка нужной записи при использовании файловой системы с индексно-последовательным доступом [10].
Жесткий диск состоит из пакета дисков с магнитным покрытием. Данные записываются на дорожки в виде сегментов фиксированной длины, которые пронумерованы и располагаются по кругу с радиусом, отсчитываемым от центра диска. Сегменты, в свою очередь, могут состоять из нескольких записей. Набор дорожек с одинаковыми номерами со всех дисков пакета называют цилиндром. Данные могут записываться или считываться с помощью блока специальных головок одновременно со всех дорожек некоторого цилиндра.
Записи при их большом числе требуют для размещения несколько сегментов, дорожек и (или) цилиндров; в одном сегменте может быть несколько записей. Для простоты понимания предположим, что каждая запись на диске представлена одним сегментом, а дорожки в цилиндре пронумерованы числами 1, 2,....
Очевидно, что для поиска записи следует указать номера цилиндра и дорожки, а также сегмента. Для ускорения поиска создаются индексные таблицы цилиндров и дорожек (рис. 5.11).

273
Допустим, что записи пронумерованы и значение номера сегмента есть первичный ключ для выборки нужной записи. При запросе «Выбрать запись со значением ключа 64» будут выполнены определенные действия. Сначала ЭВМ найдет на диске индексную таблицу (далее индекс) цилиндров.
В ней для каждого цилиндра указывается максимальный ключ - максимальный номер записи (сегмента) на данном цилиндре (рис. 5.11). Далее определяется, что нужная запись находится на втором цилиндре, производится обращение к индексу дорожек цилиндра 2 и определяется, что запись 64 находится на дорожке 3. После этого производится чтение с дорожки 3 второго цилиндра сегмента (записи) с нужным номером. Эта запись будет четвертой на дорожке 3 второго цилиндра.
Базы данных, в основе которых лежит файловая организация данных, до сих пор довольно широко используются. Однако оказалось, что они обладают серьезными недостатками. Основная проблема состоит в том, что файлы независимы и могут иметь повторяющиеся данные. Повторение данных в разных файлах приводит, во-первых, к избыточному объему, во вторых, усложняется процесс редактирования, так как одинаковые поля надо изменять в нескольких файлах, а при этом можно ошибиться. Кроме того, одни и те же данные могут размещаться в полях с разными именами, что приводит к проблемам выбора логически связанных записей из нескольких файлов.
Следует отметить, что файловые модели не предполагают установления связей между файлами, что и явилось одной из причин появления специальных прикладных программ, получивших название СУБД.