ЛЕКЦИИ “ОРГАНИЗАЦИЯ ЭВМ”
( ОСЕННИЙ СИМЕСТР)
РАЗДЕЛЫ: СИСТЕМА ВВОДА ВЫВОДА
И СИСТЕМНАЯ ШИНА
Лекция N 18
Тема лекции: Организация ввода вывода. Общие положения.
1.Введение.
2.Требования и задачи, решаемые при проектировании системы ввода вывода.
Система ввода вывода, являясь неотъемлемой частью любой вычислительной системы, также как процессор и память прошла эволюционный путь развития.
Структура системы ввода вывода, представляющая программно-аппаратный комплекс, определяется и проектируется с учетом выполняемых задач то есть назначения вычислительной системы .
В состав аппаратной части системы ввода вывода в зависимости от концепции, положенной в ее организацию входят: периферийные устройства (ПФУ), интерфейсы, часть оборудования процессора или каналы ввода вывода. Каналы ввода вывода по сути являются специализированными процессорами назначение которых- это управление операциями ввода вывода в системе, включая не только передачу данных но и анализ состояния устройств до начала и после операций ввода вывода и передача информации о состоянии устройств через механизм прерывания программному обеспечению системы.
По мере смены поколений ЭВМ изменялась элементная база, состав и назначение ПФУ, виды носителей информации и методы доступа к ним.
На смену бумажным носителям в виде перфокарт и перфолент пришли носители в виде магнитных лент и дисков, последние дали возможность прямого доступа к данным, замены последовательного метода, применяемого при использовании магнитных лент.
C появлением многопрограммного режима и внедрением операционных систем для управления вычислительным процессом появился класс активных внешних устройств, предназначенных для работы оператора ЭВМ.
С внедрением режима диалога, пришедшего на смену пакетной обработке информации, появились внешние устройства, дающие возможность программисту (пользователю) непосредственно иметь связь с системой а не через оператора, как это делалось при пакетной обработке, предоставляя ему инструкции по выполнению задания и исходные данные на носителях.
Таким образом было расширено операционное поле класса активных внешних устройств.
Для вычислительных систем, работающих в реальном режиме времени, используемых для управления технологическими процессами были разработаны устройства с преобразованием аналоговых сигналов в цифровые и наоборот. А для создания распределенных вычислительных систем были разработаны устройства ,осуществляющие прием и передачу информации в ЭВМ из каналов связи. В дальнейшем на их базе были созданы телепроцессоры ,которые кроме преобразования и согласования интерфейсов ЭВМ с каналами связи стали выполнять и программную обработку данных.
Несколько слов следует сказать о классе внешних запоминающих устройств ,которые в качестве носителей используют магнитные ленты и диски. От начала использования этого вида внешних устройств до настоящего времени произошли большие изменения как в объеме хранимой информации ,так и в скоростях обмена ей между внешними устройствами с процессором и памятью
Если ,например, плотность записи на магнитную ленту была в начале только десятки символов на 1мм при использовании технологии NRZ и достигла значения 256 символов на 1мм при фазовом кодировании и за счет аппаратных преобразований дополнительно при методе группового кодирования до ……. То современные методы записи и соответствующая технология изготовления носителей позволяет размещать на 1мм единиц(бит) информации что позволяет на катридже с размером
и длиной носителя в метров размещать 500Гбт.
А емкость одного жесткого диска входящего в состав дисковой подсистемы DS8300 равна146Гбт общее количество в подсистеме может достигать до и соответственно емкость всей системы может составлять до
Естественно, с увеличением объемов хранимой информации на внешних носителях и увеличения частоты работы процессора и памяти потребовалось увеличения пропускной способности системы ввода вывода ,которую не могли обеспечить интерфейсы, базирующиеся на передаче электрических сигналов по параллельным линиям связи . Так на смену параллельным каналам, связывающим периферийные устройства с остальными частями вычислительной системы , пришли последовательные с использованием оптических линий связи.
Многообразие функциональных устройств различных по принципу действия и назначению потребовало внедрения специальных промежуточных аппаратных средств, которые должны были функционировать по единым правилам и протоколам, определяющим как физические параметры сигналов, поступающих во внешние устройства и выходящих из них и алгоритмы, определяющие логические связи внешних устройств с вычислительной системой. Эти промежуточные аппаратные средства называются контроллеры внешних устройств, которые конструктивно выполняются или в отдельных стойках или могут быть реализованы в виде функциональных блоков, входящих в состав ПФУ.
По своим функциональным возможностям ПФУ можно разделить на “ быстрые”и “медленные”c точки зрения скорости приема и передачи данных в вычислительной системе. Поэтому при организации системы ввода вывода учитывается этот фактор. Внешние устройства объединяют в группы с соизмеримыми скоростями приема/передачи данных, разрабатывая для каждой группы свой протокол, представляющий комплекс аппаратных и микропрограммных средств.
Одной из основных концепций организации вычислительной системы - выбор управления основными информационными потоками. Это двунаправленные потоки: процессор-память, внешнее устройство-память и процессор -внешнее устройство.
В зависимости от выбранной стратегии первоначально исторически сложились две структуры организации ввода вывода.
1.Процессор ввода вывода.
2.Общая шина.
Эти два альтернативных направления организации ввода вывода использовались первоначально в вычислительных системах различного назначения.
Процессор ввода вывода или по другому каналы ввода вывода стали использовать в системах с большим количеством разнотипных внешних устройств. В системах в основном коллективного пользования с большими объемами обрабатываемых данных и работающих в многопрограммном режиме.
Системы с “общей шиной”были характерны для малых и микромашин с малым набором устройств.
Суть различия заключалась в следующем.
Все функции по управлению потоками в системах с “общей шиной” осуществляются процессором.
В системах с канальной организацией функции управления потоками распределены между процессором и каналами.
Концепция каналов ввода вывода состоит в том ,что процессор участвует только в инициализации операции ввода вывода, передавая основные функции по управлению и передачи информации в потоке внешнее устройство <->память специализированному процессору ввода вывода, освобождая себя на момент обмена внешнего устройства с памятью для других работ.
Канал осуществляет прием/передачу данных в память, контролирует ход выполнения операции ввода вывода согласно канальной программе, расположенной в оперативной памяти, на местонахождение которой указывает ему процессор. Контролируя ход выполнения операций ввода вывода, по ее окончанию канал формирует признак результата в виде байт состояний канала и устройства ,организуя запрос на прерывание ввода вывода в процессор ,который в свою очередь должен это прерывание обработать.
Что касается объединения разных устройств по скорости обмена данных в группы, то канальной системе это реализуется путем организации каналов разного типа, работающих соответственно по своим алгоритмам или выбором режима канала.
Структура системной шины, как было отмечено выше, первоначально была характерна для систем с малым набором ПФУ. В таких системах всеми операциями ввода вывода управлял процессор, используя для этого циклы шины обращения к внешним устройствам и останавливая выполнение программы на время обмена с внешним устройством. Обмен производился побайтно то есть для передачи приема каждого байта из процессора во внешнее устройство или приема из него инициировалась соответствующая команда обмена.
В дальнейшем для ускорения процесса обмена стали применять так называемые строчные команды , реализующие обмен массива данных и технологию прямого доступа к памяти , используя в последнем случае специальный контроллер прямого доступа к памяти на шине, который в общем то выполнял функции каналов ввода вывода только в приеме передачи данных. Контроль же за окончанием и ходом выполнения операций ввода вывода оставался за процессором.
Характеризуя современное состояние системы ввода вывода в вычислительных системах можно отметить следующее.
Системы, родоначальники которых имели организацию ввода вывода ‘общая шина’, в настоящее время, используя технологию прямого доступа к памяти, имеют возможность организации множественных потоков информации без непосредственного участия процессора, оставляя ему функцию инициализации.
Что же касается контроля за выполнением операции ввода вывода он возложен на контроллеры шины, которые контролируют текущее состояние операции и формируют запросы на прерывание в процессор в случае сбойных ситуаций и по ходу выполнения операции, принимая от внешних устройств соответствующие сигналы..
По сути ‘общая шина’ трансформировалась в канальную архитектуру только с распределенными аппаратными ресурсами на шине и не используя технологию канальных программ для обмена.
Что касается организации канальной системы, то она подверглась также модернизации и эта модернизация коснулась в первую очередь способу адресации внешних устройств, используя при этом принцип логической адресации благодаря вводу сетевых технологий для связи процессорного ядра с внешними устройствами.
В канальную систему стали внедрять технологию прямого доступа к системной памяти таким образом освободив канал от выбора канальной программы и дав возможность использовать очереди запросов за данными, сформированными процессором ввода вывода под управлением супервизора операционной системы.
Информацию о расположении очередей запросов канал берет из подканала, содержимое которого формируется для каждого конкретного устройства в памяти процессора.
Канальная система не отказалась полностью от применения канальных программ и продолжает их использовать для анализа состояния внешнего устройства и передачи в него управляющей информации а передачу и прием данных осуществляет как сказано выше через технологию прямого доступа к памяти
Сохранив структуру подканалов канальная система стала использовать их , для хранения адресов ячеек памяти, в которых хранятся адреса данных для обмена с внешними устройствами как это было ранее с той лишь разницей, что раньше чем загрузить адрес данных в подканал необходимо было выбрать командное слово канала каждый раз при цепочке команд, а при прямом доступе к памяти этого не надо делать
2.Требования и задачи , решаемые при проектировании ввода вывода.
При проектировании системы ввода вывода необходимо решить следующие задачи:
- должна быть обеспечена реализация системы с переменным составом оборудования
- для высокопроизводительного использования оборудования целесообразно организовать параллельную работу процессора и устройств ввода вывода
-необходимо упростить для пользователя и стандартизировать программирование операций ввода вывода ; обеспечить независимость программирования от особенностей того или иного оборудования
-необходимо обеспечить автоматическое распознавание и реакцию процессора на многообразие ситуаций возникающих в устройстве
Способы и пути решения задач.
Для упрощения и стандартизации программирования операций ввода вывода необходимо использовать унифицированный формат данных, передаваемых в устройство, а преобразование унифицируемого формата в индивидуальные для каждого внешнего устройства осуществлять в самом устройстве, что дает возможность шинной организации интерфейса, связывающего внешнее устройство с процессором
Модульность, которая обеспечивает присоединение новых устройств .без существенных изменений, кроме кабельных соединений и некоторых изменений в конфигурации системы решает вопрос о возможности масштабировании системы.
Использование прямого доступа к памяти со стороны внешнего устройства и каналов ввода вывода решает вопрос о параллельной работе процессора и системы ввода вывода.
Автоматический контроль за ходом выполнения операций ввода вывода решается как аппаратными так программными средствами с и использованием системных команд и механизма прерываний.
3.Основные характеристики системы ввода вывода
Основными характеристиками системы ввода вывода являются:
-время выполнения операции
-пропускная способность
Время выполнения операции ввода вывода может быть разделено на четыре составляющие:
-время доступа
-время устройства или контроллера
-время передачи данных
-время завершения операции
Время доступа- время необходимое каналу контроллеру и устройству стать доступным иначе это время необходимое каналу или системе для посылки команды в устройство
Время контроллера и устройства- время необходимое контроллеру и устройству для подготовки операции передачи данных Например, для дискового контроллера ,не имеющего кэш, это время будет определяться временем установки головки записи / считывания перед тем как начать чтение или запись данных.
Последние две составляющие комментарий не требуют.
Факторы влияющие на составляющие времени выполнения операции ввода вывода:
-синхронный или асинхронный режим работы системы ввода вывода
-скорость передачи данных
-расстояние
-характеристики подключаемого устройства
-характеристики канальных программ для организации операций ввода вывода
Синхронный тип операций требует чтобы канал , контроллер и устройство были активными в одно и тоже время
Например, в дисковой подсистем все действия связанные с окончанием операции и получением следующих данных должны быть завершены перед тем как головка дисковода достигнет следующей записи. Если этого не произойдет, синхронизатор позиционера сгенерирует промах или переполнение. Выполнение следующей операции будет задержано.
Асинхронный тип операций.
В этом режиме канал, контроллер и устройство могут быть не активными в одно и то же время для выполнения операции ввода вывода ,этот режим дает возможность разнесение каналов и контроллеров на более дальние расстояния, уменьшать время ответа, разрешать каналу выполнение других операций в течение времени ожидания для устройства.
Характеристики устройств- к в ним относят дополнительные аппаратные средства в виде буферов для хранения данных и КЭШей, которые позволяют увеличить скорость передачи данных.
Характеристики канальных программ влияют на время выполнения операций ввода вывода. Так, например, канальные программы, в которых используется косвенная адресация , команды перехода в канале или цепочки команд увеличивают время ответа в подканале.
Цепочки команд увеличивают время ответа за счет увеличения времени передачи данных из за блокировки в канале между
состояниями “ канал кончил”и “устройство кончило “




 время доступа время устройства
время передачи время завершения
время доступа время устройства
время передачи время завершения
 и контроллера
данных операции
и контроллера
данных операции




время время
о

 жидания
обнаружения
жидания
обнаружения





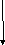 критическое время
критическое время


задержка
доступа
д
Время
формирования последовательности
выборки устройства Время
распространения сигналов по интерфейсу

Устройство
1класса Устройство 3класса Устройство 2класса
Устройствоожидает
передачу данных Запрос
на прерывание Повтор
канальной прграммы Отключение
от интерфейса, формирование аварийного
случая при обращении со стороны канала Ожидание
обслуживания каналом и формирование
байта состояния с указателем ‘сбой
интерфейса

ВРЕМЯ ВЫПОЛНЕНИЯ ОПЕРАЦИИ ВВОДА/.ВЫВОДА
Структуры
системы ввода/вывода

Канальная
система характеризуется большим
количеством устройств и параллельной
работой каналов с программой процессора Общая
шина характерна для систем с малым
количеством устройств, характерна
приостановкой работы процессора во
время выполнения операции в/вывода





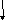
Радиальная
сеть Последовательное
соединение Инициализация
связи с устройством Команда
ввода/вывода Механизм
прерывания мультиплексный
Блок-мультиплексный
Фрейм-мультиплексный Организация
и виды обмена Прямой
доступ к памяти с формированием очередей
запросов Цепочки
команд и данных Формирование
кадров Организация
и виды обмена Циклы
шины Устройство-процессор Устройство-память побайтно Массив
слов Топология Связи
с устройством Режим
работы Канальная
программа













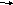
Лекция N19
Тема лекции: Системная шина.
-
Состав, характеристики системной шины и способы организации межблочных связей в ЭВМ.
2. Функционирование системной шины и эволюционное развитие ее архитектуры
1. Системная шина включает в себя:
- кодовую шину данных (кшд), содержащую провода и схемы сопряжения для параллельной передачи всех разрядов числового кола (команды, операции).
- кодовую шину адреса (кша) для передачи всех разрядов кода адреса ячейки основной памяти и порта в/выв В.У.
- кодовую шину инструкции содержащую провода и схемы для передачи управляющей информации между блоками ЭВМ (процессор – память, процессор – В.У.).
- шину питания.
Системная шина обеспечивает следующие направления связи:
Процессор ↔ память
Процессор ↔ в/выв
Память ↔в/выв
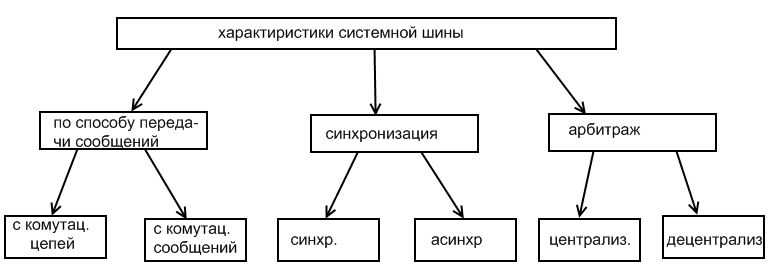
Вычислительная система (ЭВМ) компьютер состоит из множества отдельных подсистем (блоков, узлов, между которыми постоянная в процессе функционирования информационная связь. Так вот для осуществления этой связи существует совокупность средств сопряжения, которая называется интерфейсом или системой интерфейсов.
Различают внутри машинный интерфейс и внешний.
Внутри машинный интерфейс – система связи и сопряжения узлов и блоков компьютера между собой. Представляет из себя совокупность микросхем, линий связей, схем сопряжения, компонентов ЭВМ протоколов передачи и преобразования информации.
Существуют два варианта организации внутри машинного интерфейса.
а) многосвязный интерфейс – каждый отдельный функциональный блок соединен с другим локальными линиями связи. Такой тип связи был характерен для ЭВМ на начальном этапе и в последующем использовался в мэйнфреймах (больших машинах) для организации межблочных связей. Присутствует также в и в П.К. для высокоскоростной связи между процессором и КЭШ. Применялся в свое время в машинах 1ых, 2ых, 3их поколений для связи с внешним устройством.
Радиальный интерфейс (М32, CDC SYBER).
Односвязный интерфейс – все блоки связаны друг с другом через общую шину. Такая связь характерна была для микро и мини ЭВМ. В дальнейшем была использована в архитектуре П.К. имеющих малые количества агентов (включая В.У.), которые поддерживают общий протокол передачи информации.
В части функционирования, шины делятся на две подгруппы связанные с передачей данных:
-
Шины с коммутацией пакетов (мультипл. режим).
-
Шины с коммутацией цепей (монопольный селектор. режим).
Режим с коммутацией пакетов характеризуется разделением транзакций на две части (фазы). Во времени: фазы запроса и фазы передачи информации. Шины с коммутацией цепей характерны тем, что транзакция не разделяется на фазы и остаётся в распоряжение приемника и передатчика на весь временной цикл обмена.
Данная схема представляет реализацию последовательного опроса, где приоритетом пользуется устройство, расположенное ближе к арбитру.
Чтобы обойти такую систему в некоторых шинах устраивают несколько уровней приоритетов. На каждом уровне есть линия запроса шины, и линия представления шины. Если одновременно запрашиваются несколько уровней приоритета, арбитр представляет шину самому высокому уровню. Среди устройств одинакового приоритета используется система последовательного опроса.
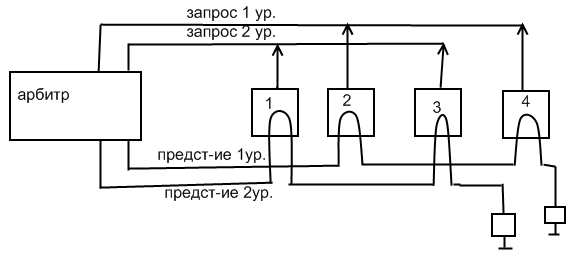
На этой схеме приоритет 2,4>1,3
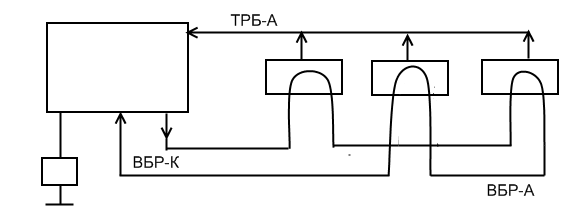
Арбитраж.
Как следует из вышесказанного, когда на шине присутствует несколько устройств, обладающих способностью выступать в качестве задающих, и появляется несколько запросов от них на владение шиной необходим механизм арбитража, т.е. необходима схема, узел, блок, устройство, которое выполняло бы эту функцию.
Существует 2 метода решения этой проблемы- централизованный и децентрализованный
Централизованный арбитраж.
Функцию арбитража берет на себя отдельное выделенное устройство( блок внедренный в процессор или контроллер на шине). Все абоненты шины выставляют запросы, а арбитр согласно алгоритму представляет право на владение шиной. Примером централизованного арбитража можно привести шину PCI, прерыв. на ISA обработка запросов на прерыв и обмен данных в интерфейсе в/выв ЭВМ.
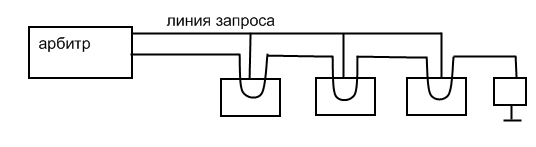
Децентрализованный арбитраж.
В этом случае, если устройству нужна шина он запускает свою линию запроса. Все устройства контролируют все линии запроса, поэтому в конце каждого цикла шины, каждое устройство может определить, обладает ли оно в данный момент высшим приоритетом и следовательно разрешено ли ему пользоваться шиной в следующем цикле.

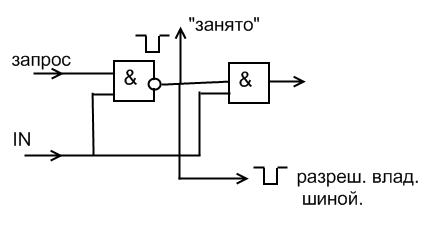
При другом типе арбитража используется только 3 линии независимо от устройств

Чтобы получить доступ к шине, устройство проверяет, свободна ли шина и наличие 1 на вх. IN, если IN = 0, устройство не может стать задающим, в этом случае устанавл. свой выход. сигнал OUT:=0. Если IN=1, то в этом случае OUT:=0 и устанавливается сигнал «Занято». Данная схема подобна системе последовательного опроса, где сигнал представления шины арбитром заменен нач.1 (+5в) приоритетней будет устройство польз. крайнее левое устройство.
2. Как было указано ранее шинная организация межблочных связей в архитектуре ЭВМ проявилась как альтернативный вариант многосвязному интерфейсу и была применена в системах относительно простых с малым количеством агентов в мини и микро ЭВМ . Эта технология была использована в архитектуре ПК. Следует помнить, что системная шина или “общая шина” это не просто набор проводников по которым передаются данные, адрес, управляющие информацией. Это целый комплекс аппаратных средств, предназначенных для управления движением этих потоков и надежной их передачи от задающего устройства к приемнику и наоборот. В состав этих аппаратных средств входят усилители, приемники, буферные регистры (защелки) и коммутаторы, управляющие информационными потоками во время цикла шины. Компьютер (ЭВМ) или В.С. представляет комплекс подсистем различного характера (устройств) поэтому системная шина “разбита” на группы локальных шин, отделяющих группы однородных устройств. Системная шина представляла набор локальных шин. Локальная шина процессора, системная шина для подключения ВУ и локальная шина памяти.
Для управления транзакцией на шине в комплексе аппаратных средств имеется контролер шины, т.е. процессор не формирует управляющие сигналы шины, он только выдает код транзакции (тип цикла), а контролер шины реализует его на шине. Такова была архитектура шины ISA в первых компьютерах и шинах «МУЛЬТИБАС».
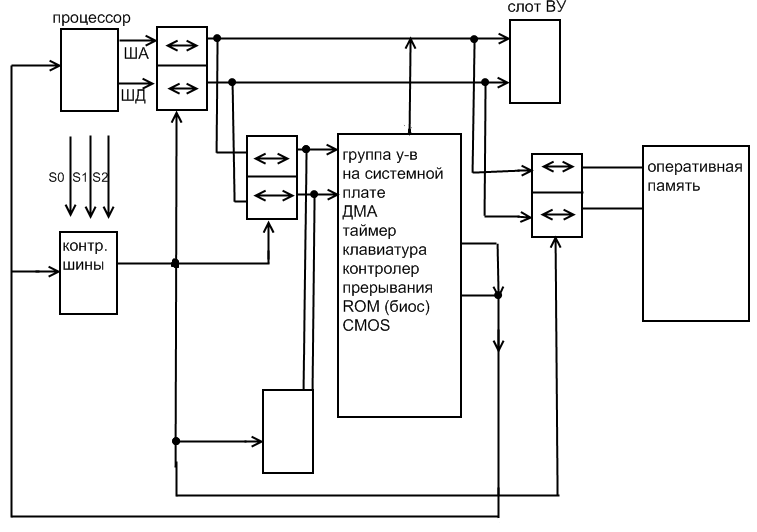
Функционирование системной шины
Функционирование системной шины определяется ее протоколом, устанавливающим правила, по которым которые должны выполнять все агенты шины. Правила эти устанавливают нормы и требования, представляемые как физическому, так и микроархитектурному уровню. Требования к физическому уровню определяют физическую среду и параметры передаваемых сигналов: амплитуда, длительность, частота, временная задержка.
Микроархитектурный уровень определяет структуру шины, это аппаратные средства реализующие логику взаимодействий агентов при обмене информацией (протокол).
функционирование во времени шины представляет из себя циклы, которые определяют вид и характер взаимодействия и агентов, участвующих в этот промежуток времени. Чем шире функциональные возможности шины, тем больше набор всевозможных циклов, называемых транзакциями. Как мы увидим, в дальнейшем эволюционное развитие структуры шины привело к ее конвейерной организации и внедрения многопотокового режима . Примером является шина pentium 2 с ее конвейерной организацией, заключающейся в том, что все управляющие сигналы разделены на независимые группы, которые позволили разделить циклы шины на отдельные фазы, что и позволило совмещать во времени выполнение последовательность циклов.
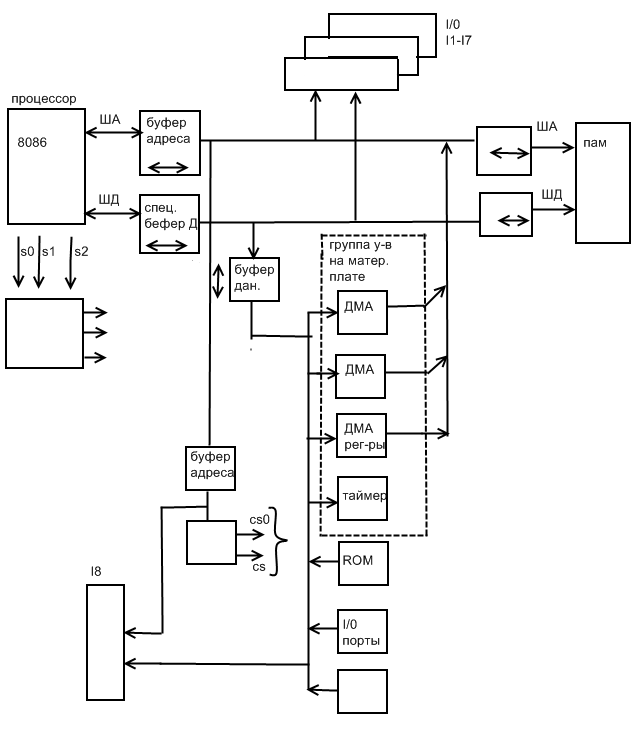
Данная структура системной шины (ISA) позволила организовать обмен
Процессор - память
Процессор – ВУ
Память – ВУ
Для осуществления последней связи в группе устройств на системной плате присутствует контролер ДМА 8237. Основная его задача - управлять обменом между памятью и ВУ, «подменяя» контролер шины для циклов процессор – ВУ, чтобы выдавать управляющие сигналы в память и ВУ во время обмена, при этом активизация этого контролера ДМА и передача шины под его управлении возможна только с разрешения процессора.
Для организации связи процессор – ВУ, помимо использования команд в/выв (программируемый в/выв), на шине функционирует механизм прерываний, реализованный в контроллере прерываний, находящемся в группе устройств на системной шине.
Именно этот контролер после его инициализации со стороны процессора берет на себя функции обработки запросов на прерывания от ВУ к процессору, формируя «вектора прерываний», представляющих из себя адреса памяти в которых находятся адреса обработчиков прерываний.
Эволюция системной шины была связана не только с технологическими аспектами, которые позволили объединить отдельные микросхемы в СБИС с целью повышения производительности системы за счет увеличения частот (связи СБИС), а в основном за счёт изменения концепции протокола системной шины, а именно организация параллельных процессов передачи и обработки информации в системе. Главная концепция - прямой доступ к памяти, заложенная ещё в ISA нашла своё дальнейшее развитие в протоколе шины PCI, первоначально спроектированной как шина для периферийных устройств, которая в дальнейшем заняла ведущее место на системной шине за счёт технологии ДМА, и так называемой PnP, с использованием циклов конфигурации (настройка системы во время инициализации) в современных архитектурах. а также и за счет организации многопоточного режима на шине
ЛекцияN20
Тема лекции: Системная шина(продолжение)
1.Конвейерная организация работы системной шины.
2.Технология организации ввода вывода на системной шине.
Конвейерная организация работы системной шины на примере с использованием процессора Pentium 2
Основной принцип организации конвейера на системной шине заключается в разделении циклов шины на отдельные фазы ,которые управляются группами сигналов, соответствующих каждой фазе. Таких групп и соответственно им фаз на шине процессора Pentium2 – шесть.
-
фаза арбитража
-
фаза запроса
-
фаза контроля
-
фаза отслеживания
-
фаза ответа
-
фаза передачи данных
Наличие фазы арбитража обусловлено возможностью организацией SMP-симметричной мультипроцессорной системы на базе процессоров этого класса, в которой каждый процессор является одним из равноправных агентов системы, поэтому каждый раз, когда процессору необходима шина он участвует в этой фазе.
Как мы увидим далее, протокол арбитража поддерживает кольцевую схему то есть каждый раз приоритетный агент, уходя с шины, ‘падает на дно’ – ему присваивается низший приоритет, причем все остальные агенты следующие по кольцу увеличивают свои приоритеты на единицу.
BRQ0:=0 0111 1110 1101 1011
BRQ1:=0 1011 0111 1110 1101
BRQ2:=0 1101 1011 0111 1110
BRQ3:=0 1110 1101 1011 0111
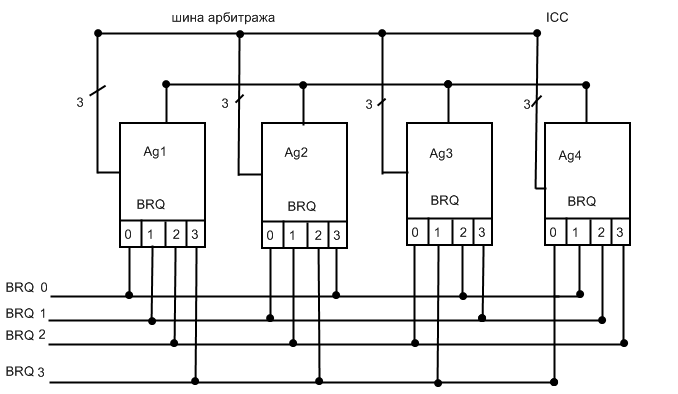
Для арбитража в процессоре используется шина BRQ[0-3] соединяющая таким образом контакты в процессоре BR0,1,2,3 чтобы организовать кольцевую схему приоритета, причем контакт ВR0 является двунаправленным , а контакты BR1,2,3 однонаправленные, функционирующие как входные.
Агент выигравший шину обязан на свой контакт BR0 выставить нулевой уровень сигнала, то есть логический ноль таким образом ’ опустив’ себя на дно и увеличивая приоритеты остальных агентов на единицу.
Арбитраж осуществляется на шине ICC одновременной выдачей всеми агентами, участвующими в арбитраже своих арбитражных номеров. Выдача осуществляется побитно слева направо в инверсном коде. Идея арбитража заключается в том, что на шине после выдачи одноименных битов формируется монтажное ИЛИ и результат анализируется каждым из агентов, те агенты, которые получают результаты равные значению выданного бита продолжают цикл арбитража, другие обязаны уйти из цикла, таким образом, выявляется
Победитель им окажется агент, имеющий наибольшее значение арбитражного номера в данном цикле. Как видно из диаграммы цикл арбитража может занимать от одного до трех тактов .
Например, в арбитраже участвуют агенты с арбитражными номерами 0111 и 1110 - цикл занимает один такт. Если ,к примеру, номера будут 0111и 1011 ,то арбитраж займет три такта.
После цикла арбитража кроме выдачи нулевого уровня сигнала на контакт BR0,сигнал низкого уровня подается на контакт BPR приоритетным агентом для удержания шины в своем распоряжении до момента, когда он выставит на этот контакт сигнал высокого уровня . После чего может начаться новый цикл арбитража.
Завладев шиной агент начинает реализацию транзакций выполнение которых имеет конвейерный характер.
Фаза запроса.
К сигналам фазы запроса относятся:
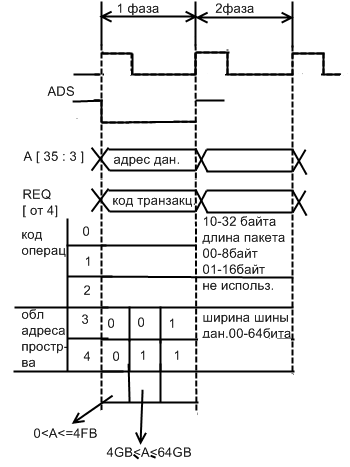
-ADS строб адреса, сигнал указывающий начало транзакции.
-REQ[0-4] сигналы ,передающие код транзакции.
- A[3-31] шина адреса
Все транзакции на шине начинаются с фазы запроса. Эта фаза предназначена для передачи кода транзакции, адреса памяти в случае обращения за данными и дополнительной информации характеризующую ту или иную транзакцию.
Так как фаза запроса является информационно емкой ,она занимает по времени два такта системной шины. В первом такте передается код транзакции и адрес данных.
Во втором такте по адресным шинам передается дополнительная информация о транзакции и код длины пакета данных при обращении к памяти. Для транзакций, предназначенных для управления системой, которые кодируются специальным кодом в первом такте, во втором такте по шине адреса для них передается вся управляющая информация.
Рассмотрим подробнее структуру дополнительной информации передаваемой во втором такте фазы запроса характеризующей режим работы системной шины . Так в разрядах с восьмого по пятнадцатый шины адреса передаются маркера байтов, указывающих на конкретные данные необходимые инициатору, для установки режима обращения к области памяти используют разряды с 24 по 31 шины адреса. Таким образом, операционная система имеет возможность управлять областями системной памяти, на пример, запрещая запись в обращаемую область или ее кэширование указывая соответствующим кодом в байте атрибута, передаваемого по выше указанным разрядам.
Так как системная шина поддерживает режим симметричной мультипроцессорной системы, который в свою очередь требует поддержки когерентности кэш агентов с системной памятью и кроме того контроллеру памяти необходимо знать от какого агента пришел запрос за данными, то каждая транзакция ,которая может быть отложена с разрешения агента сопровождается идентификатором задержки , в котором агент(процессор)указывает свой идентификатор и номер транзакции из своей очереди . Выше указанная информация передается в разрядах с 16 по 23 шины адреса.