

malyshkin_ve_korneev_vd_-_parallelnoe_programmirovanie_multikompyuterov
.pdfТогда P(A,S1)É P(A,S2), так как в силу сделанного распределения памяти для вычисления f прямое управление в С2
должно теперь содержать требование, чтобы операция h
выполнялась раньше g, то есть управление C2 в представлении
S2 - это множество {(g<f), (h<f), (h<g)}. При этом операция h,
начав исполняться, использует значение переменной z1 до того,
как в ту же ячейку памяти будет записано значение переменной x1, вычисленное операцией g.
Очевидно, что представление S алгоритма A с потоковым управлением C и тождественным распределением ресурсов R
является максимально непроцедурным представлением A. Такое представление будем называть просто непроцедурным.
Рассмотрим еще несколько примеров программ,
иллюстрирующих введенные определения.
П3. Алгоритм A задан в форме программы P, записанной на некотором последовательном языке программирования.
Операторы языка, вычисляющие значения переменных, есть операции. Прямое управление задается последовательностью операторов в программе либо специальными операторами управления типа go to.
Порядок выполнения операций полностью фиксирован.
Распределение памяти задаётся идентификаторами переменных программы, которые фактически есть имена ячеек памяти, имена переменных алгоритма в программе не сохраняются.
48
Предполагается, что для выполнения алгоритма может быть использован только один процессор.
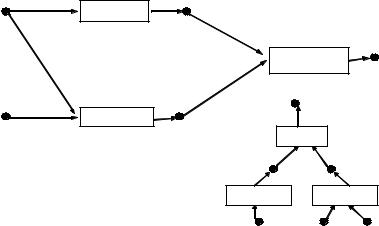
П4. На рис. 2.4. приведен пример представления S=(X,F,C,M)
алгоритма A и одного из его возможных представлений в форме программы P. Здесь X={x,y,z,x1,z1}, F={a,b,c}. C - потоковое управление (показано стрелками), M - тождественное распределение ресурсов.
x |
|
y := x−2 |
y |
алгоритм A |
|
|
|
|
|||
|
|
a |
|
c |
|
|
|
|
|
|
|
|
|
|
|
z1 := y - x1 |
z1 |
|
|
|
|
|
|
|
|
b |
|
z1 |
|
z |
|
x1 := x + z |
|
|
|
|
|
x1 |
|
t |
|
|
|
|
c |
||
|
|
|
|
|
|
P: |
real |
x, z; |
y |
x1 |
|
|
|
z := x + z; |
|
|
|
|
|
x := x−2; |
a |
b |
|
|
|
x := x - z; |
|
||
|
|
|
|
|
|
|
|
|
x |
x |
z |
Рис. 2.4.
Программа P может быть построена следующим регулярным способом. Вначале строится функциональный терм t
(рис.2.4.), определяющий алгоритм решения задачи. Устройство терма показывает, что после выполнения операции b значение переменной z более не используется, а значение переменной x
еще будет нужно для корректного исполнения операции a.
49
Поэтому переменной x1 может быть назначена та же ячейка памяти, что и для переменной z (что и сделано в программе P).
После исполнения операции a значение переменной x
тоже становится не нужным и потому для хранения значения
переменной y может быть назначена та же самая ячейка, что и для переменной x.
После исполнения операции c сразу две переменные - y
и x1 - становятся не нужными (их значения полностью
использованы) и потому значение переменной z1 может быть положено как в ячейку, где хранится значение y, так и в ячейку,
где хранится значение переменной x1 (в программе P значение
переменной z1 положено в ту же ячейку, где хранилось значение переменной y, а еще ранее хранилось значение переменной x).
Таким образом, в программе P переменная программы,
помеченная идентификатором x (имя ячейки памяти),
последовательно хранит значения переменных алгоритма x, y, z1
(т.е. задано отображение M(x)= M(y)=M(z1)=x, последний x есть имя ячейки), порядок выполнения операторов программы не
может быть изменен в силу выбранного распределения памяти.
При необходимости реализовать алгоритм A на
мультикомпьютере |
программа P |
распараллеливается, т.е. |
||
преобразуется |
в функционально эквивалентную |
программу P1 |
||
(вычисляющую |
ту |
же функцию |
FA), но |
допускающую |
параллельное выполнение некоторых операторов. Таким образом,
50
задача распараллеливания программы заключается в нахождении параллельного представления A (конструировании новых C и M)
на основе анализа P.
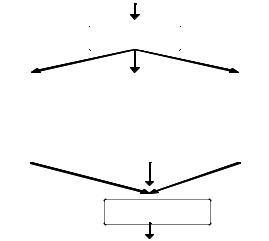
П5. Алгоритм A задан в форме программы P, записанной на некотором параллельном языке, использующем конструкции типа fork и join для задания параллельных ветвей.
Например fork V1, V2, V3 join, где V1 , V2 , V3 -
последовательные участки программы, которые могут выполняться независимо. Участки V1 , V2 , V3 формируются таким образом, чтобы объём вычислений в них (а значит и время их выполнения) был одинаковым. Схематично исполнение программы показано на рис. 2.5, стрелки показывают поток управления. После оператора fork ветви V1, V2, и V3 могут исполняться в произвольном порядке, независимо друг от друга.
Оператор join ожидает завершения всех ветвей.
Программа хорошо выполняется на трех одинаковых процессорах и вдвое хуже на двух в силу излишне жестко заданного прямого управления. Во втором случае вначале будут выполнены две (доступны два процессора) любые ветви,
например V1 и V3, затем ветвь V2 (один процессор простаивает) и
лишь после этого оператор join разрешит продолжить исполнение программы P далее. Программа P должна преобразовываться при изменении числа доступных процессоров
51
мультикомпьютера для достижения хорошего качества исполнения.
f o rr kk
V 11 |
|
V 2 2 |
|
V 3 3 |
|
|
|
|
|
jj oo iinn
Рис. 2.5.
П6. Алгоритм A задан асинхронной программой P (см. параграф
4.1). Управление C задается спусковыми функциями и/или
сетями Петри (см. параграф 3.3). Распределение ресурсов находит отражение в устройстве C, поэтому, хотя P и в меньшей степени зависит от изменений в структуре мультикомпьютера в силу недетерминированности управления, ее также часто необходимо преобразовывать (конструировать новые C и M) при изменении структуры мультикомпьютера для получения хороших рабочих характеристик реализации A.
52
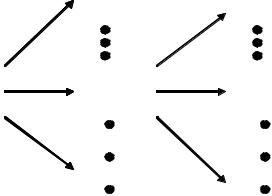
Обращаем внимание читателя на диаграмму (рис. 2.6).
Она показывает, что для каждой вычислимой функции FA
существует счетное множество различных алгоритмов A1, ... An, ...,
вычисляющих FA, и для каждого алгоритма An существует счетное множество различных программ P1, ... , Pт, ...,
реализующих An.
A1
Pn1
FA |
An |
Pnm |
Рис. 2.6.
Эта диаграмма проясняет вопрос о том, какие операции реализуемы в оборудовании и/или в языках программирования.
Например, во всех процедурных языках программирования и в оборудовании есть хорошо реализуемые операции умножения целых и вещественных чисел, но нет операции умножения матриц. Дело в том, что в ограничениях оборудования для реализации функций умножения любых представимых в оборудовании целых и вещественных чисел существуют
53
субоптимальные алгоритмы, которые незначительно отличаются друг от друга по сложности. Поэтому эти алгоритмы можно встраивать в оборудование и/или в компилятор. Алгоритмы же умножения матриц имеют существенно разное качество реализации в зависимости от свойств перемножаемых матриц,
почему эти алгоритмы и невозможно встраивать ни в оборудование, ни в языки программирования без неприемлемо больших потерь в производительности программы.
Эта же диаграмма вносит разъяснения в вопрос о том, чем опытный квалифицированный программист отличается от начинающего. Опытный программист на основании своего опыта в состоянии сконструировать (скомпоновать) хороший алгоритм решения задачи с использованием широкого множества известных ему алгоритмов, тогда как неопытный программист делает выбор из того сравнительно небольшого числа алгоритмов, что он успел узнать. Так как этот выбор у начинающего невелик, то и качество программы получается похуже, и программирование нередко кажется начинающему простым делом.
Ситуацию образно демонстрирует процесс создания романа Л.Толстого «Война и мир». Любой русскоязычный читатель знает все слова в романе. Теоретически он мог бы взять эти слова и без проблем составить из них текст знаменитого романа. Однако только Льву Толстому это удалось.
54
Конструирование алгоритмов и программирование, в этом смысле, мало отличаются от писательства. Здесь тоже есть простейшие вычислимые функции и три оператора для конструирования новых алгоритмов. Надо только применить их в должном порядке, и задача решена.
В приведенном определении представления алгоритма использовано лишь конечное число операций, при этом в реализующей программе отсутствуют циклы. Для обсуждения и определения новых введенных понятий это было не существенно.
Использование массовых операций легко исправляет этот недостаток.
Не вдаваясь в детали определения массовых операций
(более детально см. в [5]), рассмотрим алгоритм Afile ввода записей файла f в память (в массив y), затем обработку всех его компонент операцией a, посылку результата в компоненты массива z. С учетом того, что в максимально непроцедурном представлении должен быть указан каждый вычислительный акт,
каждое возможное выполнение операции, алгоритм будет иметь вид, показанный на рис. 2.7. Здесь операция read(f, i) считывает i-
ю запись файла в i-й компонент массива y[i], операция ai
обрабатывает i-ю запись массива y[i], а результат записывает в i-
ю запись файла z.
55

. |
|
. |
|
. |
. |
|
. |
|
. |
. |
|
. |
|
. |
i |
read(f, i) |
i |
ai |
i |
. |
|
. |
|
. |
. |
|
. |
|
. |
. |
|
. |
|
. |
2 |
read(f, 2) |
2 |
a2 |
2 |
1 |
read(f, 1) |
1 |
a1 |
1 |
`f |
|
`y |
|
`z |
Рис. 2.7.
Если отображение M сопоставляет массиву y участок памяти, в котором может быть размещена лишь одна запись, и
доступен только один процессор, тогда прямым управлением C
должен быть задан следующий жестко определенный порядок выполнения операций: read(f,1), a1, read(f,2), a2, ... (обычно в программе задается с использованием оператора цикла).
При таком порядке исполнения считанная запись файла будет потреблена операцией a, память освобождена, и следующая запись может быть считана в тот же участок памяти, что и предшествующая запись. Алгоритм Afile будет правильно реализован, т.е. будет вычислена функция FAfile.
56
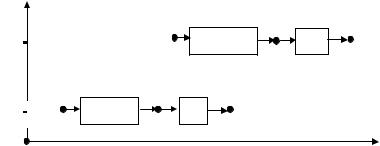
Если при тех же условиях на размещение массива y для исполнения алгоритма доступны два процессора, тогда, кроме последовательного, может быть ещё организовано конвейерное исполнение алгоритма (другая его реализация), при котором обработка i-ой записи файла делается одновременно со считыванием (i+1)-ой записи файла (рис. 2.8).
Итерации
цикла
|
|
|
|
|
y[i+1] |
z[i+1] |
i+1 |
|
|
f[i+1] |
read(f,i+1) |
a i+1 |
|
|
|
|
|
|
|
|
|
|
|
y[i] |
|
|
|
i |
f[i] |
read(f, i) |
ai |
z[i] |
|
|
|
|
|
|
|
||
|
|
ti |
ti+1 |
|
|
t |
|
|
|
|
|
Рис. 2.8.
Если разрешается разместить в памяти две записи, тогда может быть использован режим ввода с двумя буферами и две операции – a2i-1 и a2i - смогут выполняться одновременно, когда есть доступные процессоры и т.д.
Языки программирования, которые содержат лишь средства задания алгоритма, т.е. множества функциональных термов, можно назвать функциональными языками. В них должны быть средства для задания множества операций и
57