

malyshkin_ve_korneev_vd_-_parallelnoe_programmirovanie_multikompyuterov
.pdfК примеру, расписание ({p1, p2, p3}, { p5, |
p9}, {pn-5}, |
…,{ pn}) показывает, что назначенные на процессор B1 |
процессы |
{p1, p2, p3} будут и исполняться в порядке перечисления, а
именно: сначала исполнится процесс p1, затем, по его завершении, стартует процесс p2, и затем только выполнится процесс p3.
Стратегия конструирования расписания должна учесть свойства задачи. Для сформулированной задачи ясно, что нехорошо оставлять назначение процессов, требующих для своего исполнения большого объема памяти, на конец – они могут не поместиться в памяти никакого процессора из-за того,
что часть памяти процессоров уже занята ранее назначенными процессами. Так же нехорошо откладывать в конец назначение долго исполняющихся процессов – может получиться так, что все прочие процессы закончили исполнения, а последний процесс ещё долго будет работать, задерживая завершение всего множества процессов. В обоих случаях могут построиться неудачные расписания. Потому разумно для построения расписания использовать такую стратегию:
∙Строятся два списка процессов:
-L1 - список процессов, упорядоченных по убыванию объёма запрашиваемой памяти
-L2 - список процессов, упорядоченных по убыванию времени исполнения,
198
∙Процессы из первой трети списков L1 и L2 (они содержат процессы с самыми большими запросами ресурсов)
назначаются на процессоры, более или менее равномерно заполняя память и потребляя время процессоров.
∙Затем аналогично назначаются процессы из второй, а
затем и последней трети списков L1 и L2.
Построенное расписание на практике может быть и очень хорошим и не очень, но вряд ли оно будет совсем уж плохим.
Определить понятие приемлемое (хорошее) расписание не просто, однако часто можно построить оценку стратегии и доказать, насколько построенное решение будет отличаться от оптимального, например, будет хуже оптимального не более чем на 30%. Решения в пределах этих 30% и могут считаться приемлемыми.
Это практически полезная и часто используемая стратегия, которая позволяет строить приемлемые расписания. Её часто применяют и в жизни. Если надо оптимально упаковать чемодан (максимально использовать его пространство), то практичные люди сначала укладывают в чемодан самые крупные и самые тяжёлые вещи, а затем все остальное, и получается неплохо. Однако, если размеры и вес укладываемых вещей не соответствуют размерам и прочности чемодана, то никакая стратегия назначения не приведет к хорошему результату. А вот если загружать чемодан песком (каждая песчинка намного
199
меньше чемодана и все они одного размера и веса), то при любой стратегии укладки песчинок чемодан будет загружен оптимально.
Так что построение хорошего расписания зависит не только (а
скорее не столько) от методов построения расписания, сколько от свойств задачи (процессов, процессоров).
Можно сделать еще несколько существенных замечаний,
но и из приведенных примеров видны трудности использования статических методов конструирования отображения М в системах параллельного программирования. Потому статические методы конструирования отображения М в широкой практике становятся все менее интересными, хотя для них есть важные специальные приложения. В последнее время статические методы в параллельном программировании больших численных моделей вытесняются динамическими, которые на практике оказались значительно более технологичными. А потому далее обсуждаются методы динамического конструирования отображения М. Один динамический способ конструирования отображения М уже обсуждался в главе 5. Другой способ будет демонстрироваться далее на примере параллельной реализации метода частиц в ячейках (Particle-In-Cell, PIC) в сборочной технологии параллельного программирования мультикомпьютеров.
200
6.2.Идеи параллельной реализация PIC
Сборочная технология параллельного программирования разрабатывалась для поддержки параллельной реализации численных моделей большого размера в физике [5]. Прежде чем обсуждать общие принципы сборочной технологии параллельного программирования мультикомпьютеров,
рассмотрим конкретный пример её применения для решения конкретной задачи – разработки параллельной программы,
реализующей метод частиц в ячейках (кратко – метод частиц либо PIC – Particle-In-Cell ) для крупномасштабного моделирования обмена энергией в облаке плазмы. Это позволит накопить конкретный материал для обсуждения.
Рассмотрим вначале вычислительную суть метода частиц
(структуру вычислений, а не математическую модель) и
проблемы его параллельной реализации, а затем обсудим способ распараллеливания алгоритмов реализации PIC. Детальное математическое описание метода частиц в его разных приложениях можно найти в [14].
6.2.1.Краткое описание метода
При моделировании физического явления методом частиц исходное физическое пространство представляется в компьютере
пространством моделирования (ПМ). Часто ПМ имеет форму прямоугольного параллелепипеда (рис. 6.3).
Для дискретизации значений электрического E и магнитного B
201
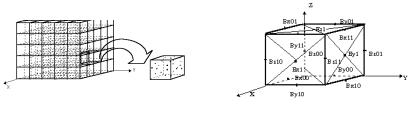
полей все пространство моделирования разбивается прямоугольной сеткой на ячейки. В вершинах ячеек определяются значения электрического E и магнитного B полей
(сеточные значения). На самом деле, для обеспечения вычислительной устойчивости счета, дискретизация полей производится более сложным образом (см. рис. 6.4), но для наших целей эта деталь не очень важна и её обсуждение, как и многих других, опускается. Чем меньше шаг сетки, то есть чем больше ячеек, тем точнее представление полей.
Плазма представляется множеством модельных частиц,
характеризующихся координатами, массой, скоростью и величиной заряда. Частицы распределены в пространстве моделирования в соответствии с некоторым законом, который изменяется во времени. Частицы влияют друг на друга, изменяя значения электромагнитных полей. Допускается наличие частиц существенно разного рода (ионы, электроны) и они обрабатываются разными алгоритмами.
Рис. 6.3 |
Рис. 6.4 |
С каждой ячейкой связаны |
частицы, находящиеся в этой |
202
ячейке в данный момент времени. Электромагнитные поля,
заданные в вершинах ячейки, действуют на частицы внутри нее,
и за малое время t их скорости и координаты изменяются
(частицы передвигаются в новую точку ПМ).
В свою очередь «перелетевшие» за время t в новую точку ПМ заряженные частицы влияют на значения электрического и магнитного полей в вершинах ячейки. Для учета этого влияния заряды частиц внутри ячейки интерполируются в вершины ячейки, таким способом вычисляются значения средней плотности тока и заряда в узлах сетки. Эти значения используются для пересчета значений электромагнитных полей.
Процесс моделирования состоит из серии временных шагов.
На каждом шаге по времени:
1)на основе текущих значений электромагнитных полей вычисляется сила, действующая на частицу;
2)вычисляются новые скорости и координаты частиц;
3)из новых координат и скоростей частиц вычисляются значения средней плотности тока и заряда в узлах сетки;
4)из полученных значений средней плотности тока и заряда в узлах сетки, пересчитываются значения электромагнитных полей.
Количество шагов моделирования определяется условиями
203
физического эксперимента. Так как координаты частиц изменяются в процессе моделирования, то время от времени частицы «перелетают» из ячейки в ячейку. Для устойчивости решения размер временнόго шага выбирается таким образом,
чтобы в течение одного шага моделирования частица улетала не далее соседней ячейки.
6.2.2. Особенности параллельной реализации метода частиц
Обычно задачи, решаемые с использованием метода частиц,
характеризуются большим объемом данных и вычислений.
Например, в одном из простейших экспериментов для моделирования процесса обмена энергией в облаке плазмы использовалось 12 миллионов частиц (а надо несколько миллиардов для изучения особенностей поведения плазмы),
размер вычислительной сетки - 64×64×96 ( а надо бы
1000×1000×1000). Только для хранения этих данных требуется
400 Мб памяти. На каждом временнò м шаге для вычисления новых скоростей и координат одной частицы требуется порядка ста арифметических операций. До того момента, когда можно наблюдать интересные физические результаты, требуется провести более 1000 временных шагов, то есть произвести не менее 12*1011 арифметических операций. И это очень маленькая лабораторная задача. Реальное моделирование потребует произвести многократно большие вычисления, представляя плазму несколькими миллиардами частиц, а электромагнитные
204
поля – большими сетками.
В алгоритме реализации PIC заложен большой внутренний параллелизм. Так как частицы между собой непосредственно не взаимодействуют, то действия, связанные с перевычислением координат и скоростей частиц можно проводить независимо друг от друга.
При решении задач на мультикомпьютерах возникает вопрос -
каким образом распределить данные между ПЭ. Так как в каждый момент времени частица находится в некоторой ячейке и для обработки частицы используются сеточные значения, то для уменьшения коммуникационных издержек в процессе моделирования необходимо так распределять данные, чтобы сеточные значения, заданные в вершинах ячейки, хранились в том же ПЭ, что и атрибуты частиц.
Чтобы удовлетворить этим условиям можно:
∙дублировать массивы всех сеточных значений (во всех узлах сетки) в памяти каждого ПЭ. В этом случае частицы равномерно распределяются между ПЭ, вне зависимости от их расположения в ПМ. В этом случае, однако, на каждом временнόм шаге потребуется обмениваться массивами сеточных значений между всеми ПЭ. Да и память ПЭ используется нерационально из-за дублирования больших массивов данных, что быстро приведет к ее исчерпанию и катастрофическому
205
уменьшению размера решаемой задачи.
∙применить пространственную декомпозицию - разрезать ПМ на подобласти по числу ПЭ. В этом случае массивы сеточных значений также разрезаются на части (с
дублированием граничных строк и столбцов). Тогда в каждый ПЭ помещаются части массивов сеточных значений и те частицы, которые находятся в соответствующей подобласти ПМ. Пространство моделирования разрезается на подобласти таким образом,
чтобы в каждом ПЭ находилось примерно одинаковое количество частиц. Таким образом, в начальный момент времени достигается хороший баланс загрузки ПЭ.
Однако в процессе моделирования частицы изменяют свое местоположение в ПМ, перелетая из ячейки в ячейку. Для того,
чтобы частицы по-прежнему находились в том же ПЭ, что и соответствующие ячейки, иногда приходится передавать атрибуты частицы из одного ПЭ в другой. Таким образом, в
процессе моделирования может накопиться большой дисбаланс загрузки ПЭ - в некоторые ПЭ прилетит много бó льше частиц,
чем в другие (возможно что и все). Поэтому необходимо время от времени производить динамическую балансировку загрузки ПЭ
(перебалансировку), выравнивая число частиц в процессорах мультикомпьютера.
206
Нужно сказать, что даже начальная сбалансированная загрузка не всегда может быть сконструирована, как это справедливо для случая моделирования взрыва облака плазмы. В
этой задаче все частицы в исходный момент сконцентрированы внутри одной ячейки и, следовательно, должны размещаться в одном ПЭ, что невозможно для задачи большого размера - все частицы попросту не поместятся в памяти одного ПЭ, хотя памяти всех ПЭ достаточно для решения задачи.
6.2.3. Сборочный подход к конструированию программы
Второй подход и следует использовать для параллельной реализации метода частиц. Реализация основана на применении сборочной технологии (СТ) к конструированию программы.
Основная идея СТ состоит в том, что вначале определяются неделимые (атомарные) фрагменты вычислений, а вся программа собирается затем из этих атомарных фрагментов.
Фрагментарная структура сборочной программы сохраняется и в исполняемом коде, что позволяет при необходимости передавать фрагменты на исполнение из одного ПЭ в другой (перелет
процесса из одного ПЭ в другой). Для метода частиц таким естественным атомарным фрагментом является ячейка (вместе с частицами и сеточными значениями, необходимыми для вычисления силы, действующей на частицу, а также со всеми вычислениями (кодом, процедурой) над этими данными).
Поэтому частицы и сеточные переменные, заданные в вершинах
207