

6.3. Рекомендации преподавателям
1. Практические занятия.Изучая данную тему необходимо обратить особое внимание на специфику расчета средних по рядам динамики. Необходим также остановиться на следующих вопросах: сопоставимости уровней рядов динамики; сглаживание уровней динамических рядов; экстраполяции тренда на будущее.
2. Задание для самостоятельной работы студентов может включать решение индивидуальных задач по расчету и анализу показателей динамики, по аналитическому выравниванию динамических рядов и прогнозирование на их основе экономических показателей.
3. Контрольная аудиторная работаможет включать решение типовых задач из данного сборника, а также промежуточное тестирование по данной теме.
Тема 7. Исследование связей между явлениями
7.1.Методические указания и решение типовых задач
Исследование зависимостей и взаимосвязей между объективно существующими явлениями и процессами играет в развитии экономики значительную роль. Оно позволяет глубже понять сложный механизм причинно-следственных отношений. В настоящее время важно уметь количественно измерить тесноту причинно-следственных связей и выявить форму связи между экономическими процессами. Для исследования интенсивности, вида и формы причинных связей широко применяется корреляционный и регрессионный анализ. Выявление количественных соотношений дает возможность лучше понять природу исследуемого явления. Это, в свою очередь, позволяет воздействовать на изученные факторы, вмешиваться в соответствующий процесс с целью получения нужных результатов.
Но, чтобы глубоко и основательно проникнуть в суть явления, необходимо исследовать и раскрыть его причинные связи, его отношения с другими явлениями. Под причинной связью понимают такую связь, когда изменение одних процессов есть следствие изменения других. Обычно одно и то же экономическое явление выступает как результат, следствие, эффект одной или нескольких причин. Вместе с тем оно служит причиной наступления других явлений или процессов. Раскрытие объективно существующих причинных зависимостей приводит исследователя к источнику зарождения отдельных процессов.
Признание факта множественности причин и следствий в реальной действительности нашло свое отражение и при исследовании закономерностей в экономике. Так, на величину себестоимости единицы продукции влияют объем производства, используемая технология и уровень производительности труда. Производительность труда, которая служит причиной формирования себестоимости, в свою очередь является следствием таких причин, как уровень развития техники и подготовки работников, эффективность использования парка оборудования и т. д. Урожайность сельскохозяйственных культур зависит от состояния почвы, состава и количества внесенных удобрений, метеорологических условий и других не менее важных причин.
Один из важных признаков причинной связи - это соблюдение временной последовательности причины и следствия. Причина всегда предшествует следствию. Однако не всякое предшествующее событие служит подлинной причиной появления последующего. Поэтому для правильного понимания причинно-следственных отношений большую опасность представляют совпадения явлений и одновременно развивающиеся процессы. Например, увеличение числа онкологических заболеваний за последние 10 лет ни в коей мере не является причиной спада промышленного производства за тот же период времени.
Следует также отметить, что статистический анализ требует такого обязательного условия, как повторяемость явления. Ведь только наличие достаточно большого числа наблюдений обеспечивает практическую возможность выявления связи. Это обусловлено тем, что причинному действию и определяемому им следствию присуща в той или иной степени случайность. Большинство экономических процессов представляют собой результат множества одновременно действующих причин. Каждый процесс при повторении его причинного комплекса за счет случайности реализуется с отклонением от закона, лежащего в его основе.
Различают
два вида зависимости между экономическими
явлениями:
функциональную и статистическую.
Зависимость между двумя
величинами
![]() отображающими
соответственно два явления,
называется функциональной,
если
каждому значению величины X
соответствует
единственное значение величины Y
и наоборот. Примером
функциональной связи в экономике может
служить зависимость
производительности труда от объема
произведенной продукции
и затрат рабочего времени. При этом
следует отметить, что если Х-
детерминированная,
не случайная величина, то и функционально
зависящая от нее величина У тоже является
детерминированной. Если же
Х-величина
случайная, то и Y
также случайная величина.
отображающими
соответственно два явления,
называется функциональной,
если
каждому значению величины X
соответствует
единственное значение величины Y
и наоборот. Примером
функциональной связи в экономике может
служить зависимость
производительности труда от объема
произведенной продукции
и затрат рабочего времени. При этом
следует отметить, что если Х-
детерминированная,
не случайная величина, то и функционально
зависящая от нее величина У тоже является
детерминированной. Если же
Х-величина
случайная, то и Y
также случайная величина.
Однако гораздо чаще в экономике имеет место не функциональная, а статистическая зависимость, когда каждому фиксированному значению независимой переменой X соответствует не одно, а множество значений зависимой переменной Y, причем заранее нельзя сказать, какое именно значение примет Y. Это связано с тем, что на Y кроме переменной X влияют и многочисленные неконтролируемые случайные факторы. В этой ситуации Y является случайной величиной, а переменная X может быть как детерминированной, так и случайной величиной. Частным случаем статистической зависимости является корреляционная зависимость, при которой функциональной зависимостью связаны фактор X и среднее значение (математическое ожидание) результативного показателя Y. Статистическая зависимость может быть выявлена лишь по результатам достаточно большого числа наблюдений. Графически статистическая зависимость двух признаков может быть представлена с помощью поля корреляции, при построении которого на оси абсцисс откладывается значение факторного признака X, а по оси ординат - результирующего Y.
В качестве примера на рис. 7.1 представлены данные, иллюстрирующие прямую зависимость между х и у (рис. 7.1, a) и обратную зависимость (рис. 7.1, б). В случае «а» это прямая зависимость между, к примеру, среднедушевым доходом (х) и сбережением (у) в семье. В случае «б» речь идет об обратной зависимости. Такова, например, зависимость между производительностью труда (х) и себестоимостью единицы продукции (у).
y

 y
y




x x
а б
Рис. 7.1. Поле корреляции
На рис. 7.1 каждая точка характеризует объект наблюдения со своими значениями х и у.
На
рис. 7.1 также представлены прямые линии,
линейные уравнения
регрессии типа
![]() ,
характеризующие
функциональную
зависимость между независимой переменной
,
характеризующие
функциональную
зависимость между независимой переменной
![]() и средним значением
результативного показателя у.
Таким
образом, по уравнению регрессии,
зная х,
можно
восстановить лишь среднее значение у.
и средним значением
результативного показателя у.
Таким
образом, по уравнению регрессии,
зная х,
можно
восстановить лишь среднее значение у.
Ставя
задачу статистического исследования
зависимостей, важно
хорошо представлять конечную прикладную
цель построения моделей статистической
зависимости между результативным
показателем
у
с
одной стороны и объясняющими переменными
![]() ,с
другой (до сих пор рассматривалась
только одна объясняющая
переменная х).
Отметим
две основных цели подобных
исследований.
,с
другой (до сих пор рассматривалась
только одна объясняющая
переменная х).
Отметим
две основных цели подобных
исследований.
Первая
из них состоит в установлении самого
факта наличия
(или
отсутствия)
статистически
значимой связи между У
и
X.
При
такой
постановке задачи статистический вывод
имеет альтернативную
природу - «связь есть» или «связи нет».
Он обычно сопровождается
лишь численной характеристикой -
измерителем степени
тесноты
исследуемой
зависимости. Задача оценки степени
тесноты
связи между показателями решается
методами
корреляционного анализа. При
этом выбор
формы
связи между
результативным показателем
у
и
объясняющими переменными
![]() ,а
также выбор
состава последних играет вспомогательную
роль, призванную максимизировать
характеристику степени тесноты связи.
,а
также выбор
состава последних играет вспомогательную
роль, призванную максимизировать
характеристику степени тесноты связи.
Вторая цель сводится к прогнозу, восстановлению неизвестных индивидуальных или средних значений результативного показателя «y» по заданным значениям объясняющих переменных.
Задача
восстановления средних значений
результативного показателя
«у» по заданным значениям объясняющих
переменных решается
методами
регрессионного
анализа.
При
этом выбор формы и вида
зависимости «у» от объясняющих переменных
![]() нацелен
на минимизацию суммарной ошибки, т. е.
отклонений наблюдаемых
значений у
от
значений, полученных по регрессионной
модели.
нацелен
на минимизацию суммарной ошибки, т. е.
отклонений наблюдаемых
значений у
от
значений, полученных по регрессионной
модели.
Таким образом, в задачах исследования зависимостей используются методы корреляционного и регрессионного анализов. При этом методы корреляционного анализа применяют на этапе предварительной обработки информации, результаты которого используют в регрессионном анализе при построении и анализе свойств уравнения регрессии. Выбор тех или иных методов анализа во многом определяется природой изучаемых переменных, шкалой в которой они измерены.
Количественные переменные позволяют измерять степень проявления изучаемого свойства объекта (денежный доход и сбережения семьи, объем валовой продукции, численность работников на предприятии и т. п.). Порядковые (или ординальные) переменные позволяют упорядочивать анализируемые объекты по степени проявления в них изучаемого свойства (уровень жилищных условий семьи, квалификационный разряд рабочего, уровень образования работника и т. п.). Наконец, классификационные (или номинальные) переменные дают возможность разбивать обследованную совокупность объектов на не поддающиеся упорядочиванию однородные классы (профессия работника, мотив миграции семьи, отрасль промышленности и т. п.).
Теперь рассмотрим приемы и методы, позволяющие установить наличие связи между исследуемыми переменными, выявить структуру этих связей и измерить их тесноту. Поскольку перечисленные задачи решаются с помощью вычисления и анализа соответствующих корреляционных характеристик, совокупность используемых для этих целей методов называют корреляционным анализом.
Корреляционный
анализ
разработан К. Пирсоном и Дж. Юлом. Он
призван прежде всего ответить на вопрос,
как выбрать с учетом специфики
и природы анализируемых переменных
подходящий
измеритель
статистической связи (коэффициент
корреляции, корреляционное
отношение, ранговый коэффициент
корреляции и т. д.) Далее
предстоит решить задачу, как оценить
его числовые значения
по имеющимся выборочным данным.
Корреляционный анализ позволяет
найти методы проверки того, что полученное
числовое значение анализируемого
измерителя связи действительно
свидетельствует
о наличии статистической связи. Наконец,
он помогает определить структуру связей
между исследуемыми k
признаками
![]() ,сопоставив
каждой паре признаков ответ («связь
есть» или
«связи нет»).
,сопоставив
каждой паре признаков ответ («связь
есть» или
«связи нет»).
Корреляционный анализ количественных признаков. Одним из основных показателей взаимозависимости двух случайных величин является парный коэффициент корреляции, служащий мерой линейной статистической зависимости между двумя величинами. Этот показатель соответствует своему прямому назначению, когда статистическая связь между соответствующими признаками в генеральной совокупности линейна. То же самое относится к частным и множественным коэффициентам корреляции.
Парный коэффициент корреляции, характеризующий тесноту связи между случайными величинами х и у, определяется по формуле:
 (7.1)
(7.1)
где
![]() и
и
![]() -
математические
ожидания величин х
и
у,
а
-
математические
ожидания величин х
и
у,
а
![]() их
среднеквадратические отклонения.
их
среднеквадратические отклонения.
Парный
коэффициент корреляции изменяется в
пределах от -1
до +1, то есть -1 < ![]() < +1. При этом между величинами х
и
у
связь
функциональная
(прямая - при
< +1. При этом между величинами х
и
у
связь
функциональная
(прямая - при![]() =+1
и обратная - при
=+1
и обратная - при ![]() =
-1). Если же
=
-1). Если же![]() = 0, то между величинами х
и
у
линейная
связь отсутствует и они
называются некоррелированными.
= 0, то между величинами х
и
у
линейная
связь отсутствует и они
называются некоррелированными.
Содержательная интерпретация коэффициента корреляции приведена в
табл. 7.1.
Таблица 7.1 Содержательная интерпретация коэффициента корреляции
|
Значение
|
Связь |
Интерпретация связи |
|
ρ = 0 |
Отсутствует |
Отсутствует линейная связь между величинами х и у |
|
0 < ρ < 1 |
Прямая |
С увеличением х величина у в среднем увеличивается и наоборот |
|
-1 < ρ < 0 |
Обратная |
С увеличением х величина у в среднем уменьшается и наоборот |
|
ρ = +1 ρ = -1 |
Функциональная |
Каждому значению х соответствует одно строго определенное значение величины у и наоборот |
Коэффициент корреляции, определяемый (7.1), относится к генеральной совокупности и как всякий параметр генеральной совокупности нам не известен. Его можно лишь оценить по результатам выборочных наблюдений.
Выборочный
парный коэффициент корреляции, найденный
по выборке
объемом п,
где
![]() результат
i-го
наблюдения i
= 1, 2, ..., п,
определяется
по формуле:
результат
i-го
наблюдения i
= 1, 2, ..., п,
определяется
по формуле:
 (7.2)
(7.2)
где
![]() ;
;![]() ,a
,a ;
; (7.3)
(7.3)
Формула (7.2) симметрична, т.е. rху= rух =r. Если в ее числителе раскрыть скобки, то после несложных преобразований получим формулу, которую широко используют при вычислении коэффициента корреляции.
 (7.4)
(7.4)
где
![]() -
средняя
арифметическая произведения двух
величин, т. е.
-
средняя
арифметическая произведения двух
величин, т. е.
![]() (7.5)
(7.5)
Выборочный коэффициент корреляции r, как всякая выборочная характеристика, является случайной величиной, и по отдельным его значениям нельзя делать окончательные выводы о степени тесноты линейной связи между двумя величинами. Здесь речь может идти о некоторых практических, качественных рекомендациях (табл. 7.2) при достаточно больших n (n > 40).
В табл. 7.2 значения r рассматриваются по модулю, так как степень тесноты связи зависит от близости r к единице без учета знака.
Таблица 7.2. Качественные характеристики связи
|
Значение
|
Связь |
|
От 0 до ±0,3 От ±0,3 до ±0,5 От ±0,5 до ±0,7 От ±0,7 до ±1 |
Практически отсутствует Слабая Умеренная Сильная |
Степень зависимости между х и у существенно выше в случае, когда r = -0,8 по сравнению со случаем когда r = 0,5.
Оценка
существенности линейного коэффициент
корреляции при большом объеме выборки
(свыше 500) проводится с использованием
отношения коэффициента корреляции (![]() )
к его средней квадратической ошибке
)
к его средней квадратической ошибке![]() :
:
![]() ,
(7.6)
,
(7.6)
где
![]() .
.
Если это отношение окажется больше значения t – критерия Стьюдента, определяемого по специальным таблицам теории вероятностей, то коэффициент корреляции значимо отличается от нуля.
При недостаточном большом объеме выборки величину средней квадратической ошибки коэффициента корреляции определяют по формуле:
 .
(7.7)
.
(7.7)
В этом случае:
 .
(7.8)
.
(7.8)
Полученные
значения ![]() сравнивается
с табличным значением t
– критерия Стьюдента.
сравнивается
с табличным значением t
– критерия Стьюдента.
В
тех случаях, когда ![]() получен
по данным малой выборки, для проверки
его существенности целесообразно
использовать метод преобразованной
корреляции, предложенный Р. Фишером.
получен
по данным малой выборки, для проверки
его существенности целесообразно
использовать метод преобразованной
корреляции, предложенный Р. Фишером.
Средняя квадратическая ошибка Z – распределения зависит только от объема выборки и определяется по формуле:
![]() .
(7,9)
.
(7,9)
По
таблице соотношений между
![]() и
и![]() (приложение 9)находят значение
(приложение 9)находят значение ![]() ,соответствующее
рассчитанному коэффициенту корреляции.
,соответствующее
рассчитанному коэффициенту корреляции.
Если
соотношения ![]() к средней
квадратической ошибке (
к средней
квадратической ошибке (![]() :
:![]() )
окажется больше табличного значения
критерия Стьюдента при определенном
уровне значимости, то можно говорить о
наличии связи между признаками в
генеральной совокупности.
)
окажется больше табличного значения
критерия Стьюдента при определенном
уровне значимости, то можно говорить о
наличии связи между признаками в
генеральной совокупности.
В практических исследованиях могут быть использованы и другие показатели для определения степени тесноты связи.
Элементарной характеристикой степени тесноты связи является коэффициент Фехнера:
 ,
(7.10)
,
(7.10)
где
![]() количество
совпадений знаков отклонений индивидуальных
величин факторного признака
количество
совпадений знаков отклонений индивидуальных
величин факторного признака ![]() и
результативного признака
и
результативного признака ![]() от их средней
арифметической величины (например,
«плюс» и «плюс», «минус» и «минус»,
«отсутствие отклонения» и «отсутствие
отклонения»);
от их средней
арифметической величины (например,
«плюс» и «плюс», «минус» и «минус»,
«отсутствие отклонения» и «отсутствие
отклонения»); ![]() количество несовпадений знаков отклонений
индивидуальных значений изучаемых
признаков от значения их средней
арифметической.
количество несовпадений знаков отклонений
индивидуальных значений изучаемых
признаков от значения их средней
арифметической.
Коэффициент
Фехнера целесообразно использовать
для установления факта наличия связи
при небольшом объеме исходной информации.
Он изменяется в пределах
![]() .
.
Для определения тесноты связи как между количественными, так и между качественными признаками, при условии, что значения этих признаков могут быть проранжированы по степени убывания или возрастания, используется ранговый коэффициент корреляции Спирмена:
![]() ,
(7.11)
,
(7.11)
где
![]() разность
между величинами рангов признака –
фактора и результативного признака;
разность
между величинами рангов признака –
фактора и результативного признака;
![]() число
показателей (рангов) изучаемого ряда.
число
показателей (рангов) изучаемого ряда.
Он варьирует в пределах от – 1,0 до + 1,0.
Ранговый коэффициент корреляции Спирмена обычно исчисляется на основе небольшого объема исходной информации, поэтому необходимо выполнить проверку его существенности. В приложении 7 приводится таблица предельных значений коэффициента корреляции рангов Спирмена при условии верности нулевой гипотезы об отсутствии корреляционной связи при заданном уровне значимости и определенном объеме выборочных данных.
Если
полученное значение ![]() превышает критическую
величину при данном уровне значимости,
то нулевая гипотеза может быть отвергнута,
т. е. величина
превышает критическую
величину при данном уровне значимости,
то нулевая гипотеза может быть отвергнута,
т. е. величина ![]() не является
результатом случайных совпадений
рангов.
не является
результатом случайных совпадений
рангов.
Для исследования степени тесноты связи между качественными признаками, каждый из которых представлен в виде альтернативных признаков, может быть использован коэффициент ассоциации Д. Юла или коэффициент контингенции К. Пирсона.
Расчетная таблица в этом случае состоит из четырех ячеек («таблица четырех полей»), статистическое сказуемое которой схематически может быть представлено в следующем виде:
|
Признак |
А (да) |
|
Итого |
|
В (да) |
a |
b |
a+b |
|
|
c |
d |
c+d |
|
Итого |
a+c |
b+d |
n |
В расчетной таблице:
a,
b,
c,
d
– частоты взаимного сочетания (комбинации)
двух альтернативных признаков – A
–![]() и B
–
и B
– ![]() ; n
– общая сумма частот.
; n
– общая сумма частот.
Коэффициент ассоциации исчисляется по формуле:
![]() .
(7.12)
.
(7.12)
Коэффициент контингенции:
![]() ,
(7.13)
,
(7.13)
где
![]() ,
,![]() ,
,
![]() ,
,
![]() числа
в четырехклеточной таблице.
числа
в четырехклеточной таблице.
Коэффициент контингенции также изменяется от – 1,0 до + 1,0, но всегда его величина для тех же данных меньше коэффициента ассоциации.
Рассмотрим теперь на примере трехмерной генеральной совокупности
(![]() )
понятия и правила вычисления
частных
и множественных коэффициентов
корреляции. Пусть
каждый экономический
объект, элемент генеральной совокупности
характеризуется
тремя показателями
)
понятия и правила вычисления
частных
и множественных коэффициентов
корреляции. Пусть
каждый экономический
объект, элемент генеральной совокупности
характеризуется
тремя показателями ![]() .
Требуется по данным выборки объемом
п
из
генеральной совокупности исследовать
взаимосвязь между этими показателями.
.
Требуется по данным выборки объемом
п
из
генеральной совокупности исследовать
взаимосвязь между этими показателями.
В этом случае выборка объемом п будет представлять собой матрицу наблюдений х:

В
ней каждая
i-я
строка
(i
= 1, 2, ..., n)
характеризует
i-и
экономический объект, а столбец,
например первый, содержит значение для
1-го показателя для всех п
объектов.
По данным первого столбца
матрицы X
можно
определить среднее значение![]() ,
и выборочную
дисперсию S12,
первого показателя.
,
и выборочную
дисперсию S12,
первого показателя.
 ;
;

Аналогичным
образом определяются выборочные
характеристики
![]() ,
,![]() и
и![]() ,
,![]() .
.
Отсюда,
согласно (7.4), рассчитаем выборочные
парные коэффициенты
корреляции ![]() .
.
Частный
коэффициент корреляции ρ12/3
характеризует
степень линейной
зависимости между двумя величинами,
например ![]() и
и ![]() при
исключенном
влиянии остальных величин, включенных
в модель (в
нашем случае - это
при
исключенном
влиянии остальных величин, включенных
в модель (в
нашем случае - это ![]() ).
).
Выборочный частный коэффициент корреляции, как выборочный аналог определяется по формуле:
![]() ,
(7.14)
,
(7.14)
где
![]() выборочные парные коэффициенты
корреляции.
выборочные парные коэффициенты
корреляции.
В трехмерной модели имеются еще два частных коэффициента корреляции r12/3 и r23/1 которые рассчитываются аналогично.
Мы
имеем два коэффициента корреляции:
парный r12
и частный r12/3
которые
характеризуют степень линейной
зависимости между величинами
![]() и
и ![]() .
Однако
если парный коэффициент r12
оценивает
степень зависимости на фоне влияния
.
Однако
если парный коэффициент r12
оценивает
степень зависимости на фоне влияния ![]() ,
то частный коэффициент
корреляции r12/3
- при исключенном влиянии
,
то частный коэффициент
корреляции r12/3
- при исключенном влиянии ![]() .
.
Таким образом, частный коэффициент корреляции более точно характеризует степень линейной зависимости.
Частный коэффициент корреляции обладает всеми свойствами парного, т.е. изменяется в пределах от-1 до+1. Если частный коэффициент корреляции равен ±1, то связь между двумя величинами функциональная, а равенство его нулю свидетельствует о линейной независимости этих величин.
Множественный
коэффициент корреляции,
например
ρ12/3,
характеризует
степень линейной зависимости между
величиной ![]() ,
и остальными
переменными (
,
и остальными
переменными (![]() ,
,
![]() ),
входящими в модель. Он изменяется
в пределах от 0 до 1. Равенство его единице
свидетельствует о функциональной
зависимости между, например,
),
входящими в модель. Он изменяется
в пределах от 0 до 1. Равенство его единице
свидетельствует о функциональной
зависимости между, например, ![]() ,
и остальными переменными
(
,
и остальными переменными
(![]() ,
,
![]() ),
входящими в модель, а равенство его 0
свидетельствует
об отсутствии линейной зависимости
между
),
входящими в модель, а равенство его 0
свидетельствует
об отсутствии линейной зависимости
между ![]() ,
и переменными
(
,
и переменными
(![]() ,
,
![]() ).
).
Выборочный множественный коэффициент корреляции, выборочный аналог генерального коэффициента ρ1/23, можно выразить через парные коэффициенты:
 (7.15)
(7.15)
В трехмерной модели имеются еще два множественных коэффициента корреляции r2/13 и r3/12, которые рассчитываются аналогично.
Квадрат
коэффициента корреляции называют
коэффициентом
детерминации.
При
этом
множественный
коэффициент
детерминации, например r1/23,
характеризует долю дисперсии ![]() объясняемую влиянием
показателей
объясняемую влиянием
показателей ![]() и
и
![]() .
Например, если
.
Например, если
![]() =
0,85, то это свидетельствует,
что 85% дисперсии
=
0,85, то это свидетельствует,
что 85% дисперсии ![]() объясняется влиянием показателей
объясняется влиянием показателей
![]() и
и
![]() ,
а 15% дисперсии
,
а 15% дисперсии ![]() объясняется
влиянием факторов, которые
не вошли в модель.
объясняется
влиянием факторов, которые
не вошли в модель.
Таким
образом, коэффициент детерминации
характеризует
долю
дисперсии одной величины, например у,
объясняемой
влиянием
фактора ![]() .
.
Методы
регрессионного анализа.
После
того как с помощью корреляционного
анализа выявлено наличие
статистических связей между переменными
и оценена степень
их тесноты, обычно переходя к математическому
описанию конкретного
вида зависимостей с использованием
регрессионного анализа.
С этой целью подбирают класс функций,
связывающий результативный
показатель у
и
аргументы ![]() ,
отбирают наиболее информативные
аргументы, вычисляют оценки неизвестных
значений параметров уравнения связи и
анализируют свойства полученного
уравнения.
,
отбирают наиболее информативные
аргументы, вычисляют оценки неизвестных
значений параметров уравнения связи и
анализируют свойства полученного
уравнения.
Функция
![]() ,
описывающая
зависимость среднего значения
результативного признака у
от
заданных значений аргументов,
называется функцией
(уравнением) регрессии.
Термин
«регрессия» (лат. -
отступление,
возврат к чему-либо) введен английским
психологом и антропологом Ф. Гальтоном
и связан исключительно
со спецификой одного из первых конкретных
примеров,
в котором это понятие было использовано.
Так, обрабатывая
статистические данные в связи с анализом
наследственности роста,
Ф. Гальтон нашел, что если отцы отклоняются
от среднего роста
всех отцов на х
дюймов,
то их сыновья отклоняются от среднего
роста всех сыновей меньше, чем на х
дюймов.
Выявленная тенденция
была названа
«регрессией
к среднему состоянию».
С
тех
пор термин
«регрессия» широко используется в
статистической литературе,
хотя во многих случаях он недостаточно
точно характеризует понятие
статистической зависимости.
,
описывающая
зависимость среднего значения
результативного признака у
от
заданных значений аргументов,
называется функцией
(уравнением) регрессии.
Термин
«регрессия» (лат. -
отступление,
возврат к чему-либо) введен английским
психологом и антропологом Ф. Гальтоном
и связан исключительно
со спецификой одного из первых конкретных
примеров,
в котором это понятие было использовано.
Так, обрабатывая
статистические данные в связи с анализом
наследственности роста,
Ф. Гальтон нашел, что если отцы отклоняются
от среднего роста
всех отцов на х
дюймов,
то их сыновья отклоняются от среднего
роста всех сыновей меньше, чем на х
дюймов.
Выявленная тенденция
была названа
«регрессией
к среднему состоянию».
С
тех
пор термин
«регрессия» широко используется в
статистической литературе,
хотя во многих случаях он недостаточно
точно характеризует понятие
статистической зависимости.
Для
точного описания уравнения регрессии
необходимо знать закон
распределения результативного показателя
у.
В
статистической
практике обычно приходится ограничиваться
поиском подходящих
аппроксимаций для неизвестной истинной
функции регрессии
![]() ,
так как исследователь не располагает
точным знанием условного закона
распределения вероятностей анализируемого
результирующего показателя у
при
заданных значениях аргумента
х.
,
так как исследователь не располагает
точным знанием условного закона
распределения вероятностей анализируемого
результирующего показателя у
при
заданных значениях аргумента
х.
Рассмотрим
взаимоотношение между истинной ![]() =
=![]() ,
модельной
регрессией
,
модельной
регрессией
![]() и
оценкой
и
оценкой ![]() регрессии.
Пусть результативный показатель у
связан
с аргументом х
соотношением:
регрессии.
Пусть результативный показатель у
связан
с аргументом х
соотношением:
![]() ,
,
где
ε
- случайная величина, имеющая нормальный
закон распределения,
причем Mε=0
и
Dε=σ2.
Истинная функция регрессии в этом
случае
имеет вид: ![]() =
=![]() =
=![]() .
.
Предположим,
что точный вид истинного уравнения
регрессии нам
не известен, но мы располагаем девятью
наблюдениями над двумерной
случайной величиной, связанной
соотношением ![]() и
представленной на рис. 7.2.
и
представленной на рис. 7.2.


у
70-60-50-40-30-20-
10-
О |2
|4
|6
|8 |10
x
|2
|4
|6
|8 |10
x
Рис. 7.2. Взаимное расположение истинной f(x) и
теоретической
![]() модели
регрессии
модели
регрессии
Расположение
точек на рис. 7.2 позволяет ограничиться
классом линейных зависимостей вида:
![]() =
=![]() +
+
![]()
![]() .
С помощью метода наименьших
квадратов найдем оценку уравнения
регрессии
.
С помощью метода наименьших
квадратов найдем оценку уравнения
регрессии ![]() =
=![]() +
+
![]()
![]() .
Для
сравнения на рис. 7.2 приводятся графики
истинной функции регрессии
.
Для
сравнения на рис. 7.2 приводятся графики
истинной функции регрессии
![]() =
=![]() ,
теоретической аппроксимирующей функции
регрессии
,
теоретической аппроксимирующей функции
регрессии
![]() =
=![]() +
+
![]()
![]() .
.
Поскольку
мы ошиблись в выборе класса функции
регрессии, а это достаточно часто
встречается в практике статистических
исследований,
то наши статистические выводы и оценки
окажутся ошибочными. И как бы мы ни
увеличивали объем наблюдений, наша
выборочная оценка ![]() не
будет близка к истинной функции регрессии
не
будет близка к истинной функции регрессии
![]() .
Если бы мы правильно выбрали класс
функций регрессии, то не точность в
описании
.
Если бы мы правильно выбрали класс
функций регрессии, то не точность в
описании ![]() с помощью
с помощью ![]() объяснялась бы только ограниченностью
выборки.
объяснялась бы только ограниченностью
выборки.
Тип модели выбирается на основе сочетания теоретического анализа и исследования эмпирических данных посредством построения эмпирической линии регрессии. Чаще других встречаются следующие виды уравнений регрессии:
а) линейная функция:
![]() =
=![]() +
+
![]()
![]() ;(7.16)
;(7.16)
б) гиперболическая функция:
![]() ;
(7.17)
;
(7.17)
в) параболическая функция:
![]() ;
(7.18)
;
(7.18)
г) показательная функция:
![]() ;
(7.19)
;
(7.19)
д) степенная функция:
![]() ;
(7.20)
;
(7.20)
е) линейная многомерная функция:
![]() .
(7.21)
.
(7.21)
Для определения численных значений параметров уравнения связи (линии регрессии) используется метод наименьших квадратов и решается система нормальных уравнений.
Применение метода наименьших квадратов к линейной функции (7.16) дает нам систему нормальных уравнении:
 .
(7.22)
.
(7.22)
Применив метод наименьших квадратов к функции гиперболы (7.17) переходят к системе нормальных уравнений:
 .
(7.23)
.
(7.23)
Для определения параметров параболы второго порядка система нормальных уравнений такова:
 .
(7.24)
.
(7.24)
Прежде чем применить метод наименьших квадратов к показательной и степенной функциям их приводят к линейному виду путем логарифмирования. Далее применяют метод наименьших квадратов и переходят к системе нормальных уравнении.
Пример 7.1. На основании выборочных данных (табл. 7.3) о деятельности
п = 6 коммерческих фирм оценить тесноту связи между прибылью (млн руб.) (у) и затратами на 1 руб. произведенной продукции (х).
Таблица 7.3. Исходные и расчетные данные для определения r
|
Номер наблюдения i |
|
|
|
|
|
|
1 |
96 |
0,22 |
21,12 |
9216 |
0,049 |
|
2 |
78 |
1,07 |
83,46 |
6084 |
1,145 |
|
3 |
77 |
1,00 |
77,00 |
5929 |
1,000 |
|
4 |
89 |
0,61 |
54,29 |
7921 |
0,372 |
|
5 |
81 |
0,78 |
63,18 |
6561 |
0,608 |
|
6 |
82 |
0,79 |
64,78 |
6724 |
0,624 |
|
Сумма |
503 |
4,47 |
363,83 |
42435 |
3,798 |
|
Средняя |
83,833 |
0,745 |
60,638 |
7072,5 |
0,633 |
Используем
формулу (7.4):
![]() Прежде
всего определимSx
и Sy:
Прежде
всего определимSx
и Sy:
![]() ;
;![]()
Тогда
![]()
Следовательно,
между прибылью (![]() )
и
затратами на 1 руб. произведенной
продукции (
)
и
затратами на 1 руб. произведенной
продукции (![]() )
существует
достаточно тесная обратная
зависимость, т.е. фирмы, имеющие большую
прибыль, имеют,
как правило, меньшие затраты на 1 руб.
произведенной продукции.
)
существует
достаточно тесная обратная
зависимость, т.е. фирмы, имеющие большую
прибыль, имеют,
как правило, меньшие затраты на 1 руб.
произведенной продукции.
Средняя квадратическая ошибка коэффициента корреляции рассчитаем по формуле (7.7):
 .
.
Необходимо получить по формуле (7.8) расчетный коэффициент Стьюдента:
 .
.
По
таблице приложения 6 найдем табличное
значение критерия Стьюдента при P=0,95
и k=6-2;
![]()
Так
как ![]()
![]() ,
то можно утверждать существенность
коэффициента корреляции.
,
то можно утверждать существенность
коэффициента корреляции.
Пример 7.2. По группе однородных предприятий имеются данные об объеме выпущенной продукции и уровне механизации трудоемких и тяжелых работ:
-
№ предприятия
Уровень механизации трудоемких и тяжелых работ, %

Объем продукции, млн. руб.

1
2
3
4
5
6
7
8
9
10
11
12
22
85
67
36
21
40
39
39
31
62
36
50
117
186
86
112
52
132
141
158
120
197
106
189
Требуется оценить степень тесноты связи между показателями механизации трудоемких и тяжелых работ и объемом продукции при помощи коэффициент Фехнера.
Предварительно вычислим среднеарифметические значения признаков:
![]() млн.
руб.;
млн.
руб.; ![]()
Для расчета коэффициента Фехнера составляется вспомогательная таблица, которая имеет вид:
-
Уровень механизации работ, %



Объем продукции, млн. руб.



22
85
67
36
21
40
39
39
31
62
36
50
-22
41
23
- 8
-23
- 4
- 5
- 5
-13
18
- 8
6
117
186
86
112
52
132
141
158
120
197
106
189
-16
53
-47
-21
-81
- 1
8
25
-13
64
-27
56
Коэффициент Фехнера вычислим по формуле (7.10):

Полученное значение коэффициента свидетельствует о наличии связи между уровнем механизации работ и объемом продукции.
Пример 7.3. По группе акционерных коммерческих банков региона имеются следующие данные:
-
№ банка
Активы банка, млн. руб. x
Прибыль, млн. руб. y
1
2
3
4
5
6
7
8
9
10
866
328
207
185
109
104
327
113
91
849
39,6
17,8
12,7
14,9
4,0
15,5
6,4
10,1
3,4
13,4
Исчислить ранговый коэффициент корреляции Спирмена для оценки тесноты связи между суммой прибыли и размером его активов.
Решение
Для расчета коэффициента корреляции рангов предварительно выполняется ранжирование банков по уровню каждого признака (табл. 7.4).
Таблица 7.4
-
№ банка
Активы банка, млн. руб.
Ранг по x
№ банка
Прибыль, млн. руб.
Ранг по y
9
6
5
8
4
3
7
2
10
1
91
104
109
113
185
207
327
328
849
866
1
2
3
4
5
6
7
8
9
10
9
5
7
8
3
10
4
6
2
1
3,4
4,0
6,4
10,1
12,7
13,4
14,9
15,5
17,8
39,6
1
2
3
4
5
6
7
8
9
10
Дальнейшие расчеты приведем в табл. 7.5.
Таблица 7.5
Расчет коэффициента корреляции рангов
-
№ п/п
Активы банка, млн. руб. x
Прибыль, млн. руб. y
Ранги

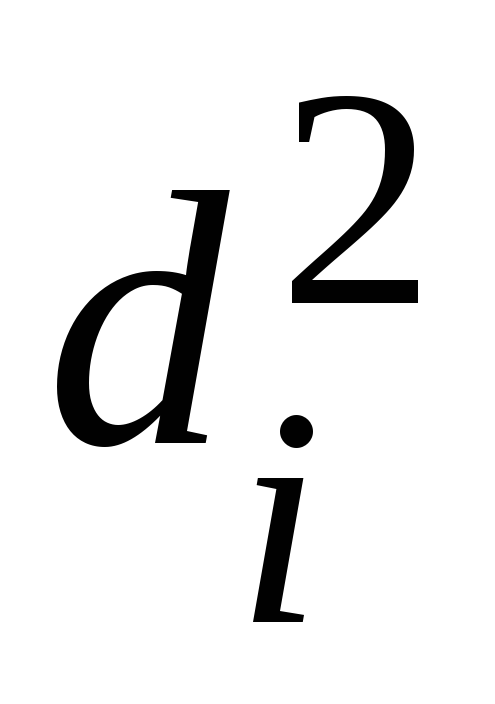


1
2
3
4
5
6
7
8
9
10
866
328
207
185
109
104
327
113
91
849
39,6
17,8
12,7
14,9
4,0
15,5
6,4
10,1
3,4
13,4
10
8
6
5
3
2
7
4
1
9
10
9
5
7
2
8
3
4
1
6
0
-1
1
-2
1
-6
4
0
0
3
0
1
1
4
1
36
16
0
0
9
Итого
-
-
-
-
0
68
На основании данных табл. 7.5 по формуле (7.11) получим коэффициент корреляции рангов:
![]()
По
таблице (приложение 7) определяется при
объеме выборки 10 единиц (n=10)
и уровне значимости 5%
![]() критическая
величина для рангового коэффициента
корреляции. Она составляет
критическая
величина для рангового коэффициента
корреляции. Она составляет
![]() 0,6364.
Поэтому общий вывод по результатам
анализа: есть необходимость увеличивать
объем выборки.
0,6364.
Поэтому общий вывод по результатам
анализа: есть необходимость увеличивать
объем выборки.
Пример 7.4. В результате обследования работников предприятия получены следующие данные (чел.):
|
Образование
|
Удовлетворены своей работой |
Не удовлетворены своей работой |
Итого |
|
Высшее и среднее |
300 |
50 |
350 |
|
Незаконченное среднее |
200 |
250 |
450 |
|
Итого |
500 |
300 |
800 |
Решение
Коэффициент ассоциации –
![]()
Коэффициент контингенции –
![]()
Полученные коэффициенты подтверждают наличие существенной связи между исследуемыми признаками. Однако коэффициент контингенции всегда бывает меньше коэффициента ассоциации и дает более корректную оценку тесноты связи.
Пример
7.5. Деятельность
коммерческих фирм (n
=
6) характеризуется тремя показателями:![]() прибыль
(млн руб.),
прибыль
(млн руб.), ![]() затраты
на
1 руб. произведенной продукции (коп./руб.)
и
затраты
на
1 руб. произведенной продукции (коп./руб.)
и ![]() стоимость
основных
фондов (млн руб.). По данным табл. 7.4
требуется определить
частный r12/3
и множественный r1/23
коэффициенты
корреляции.
стоимость
основных
фондов (млн руб.). По данным табл. 7.4
требуется определить
частный r12/3
и множественный r1/23
коэффициенты
корреляции.
Таблица 7.4. Исходные и расчетные данные
|
Номер фирмы (i) |
|
|
(млн руб.) |
|
|
|
|
|
1 2 3 |
0,22 1,07 1,00 |
96 78 77 |
4,3 5,9 5,9 |
18,49 34,81 34,81 |
21,12 83,46 77,00 |
0,946 6,313 5,900 |
412,8 460,2 454,3 |
|
4 5 6 |
0,61 0,78 0,79 |
89 81 82 |
3,9 4,9 4,3 |
15,21 24,01 18,49 |
54,29 63,18 64,78 |
2,379 3,822 3,397 |
347,1 396,9 352,6 |
|
Сумма |
4,47 |
503 |
29,2 |
145,82 |
363,83 |
22,757 |
2423,9 |
|
Средняя |
0,745 |
83,833 |
4,867 |
24,303 |
60,638 |
3,793 |
403,983 |
Воспользовавшись результатами решения примера 7.1, будем иметь:
S1=0,279; S2=6,673 и r12=-0,976.
Найдем
![]() .С учетом
(7.4)
.С учетом
(7.4)![]()
определим:
![]() ,
,![]()
Согласно
(7.6) частный коэффициент корреляции
равен:

Сравнивая значения парного r12 = -0,976 и частного r12/3 = = -0,948 коэффициентов корреляции (они достаточно близки), можно утверждать, что х3 слабо влияет на степень зависимости между величинами х1 и х2
Определим теперь с учетом (7.7) множественный коэффициент корреляции:


Пример 7.6. По данным годовых отчетов десяти (n = 10) машиностроительных предприятий провести регрессионный анализ зависимости производительности труда у (тыс. руб. на чел.) от объема производства х (млн руб.). Предполагается, что уравнение регрессии линейно и имеет вид. Исходные данные для анализа представлены в табл. 7.5.
Решение.
Таблица 7.5. Исходные данные и результаты расчетов
|
Номер |
|
|
|
|
|
|
|
|
предприятия |
|
|
|
|
|
|
|
|
(i) |
|
|
|
|
|
|
|
|
1 |
2,1 |
3 |
9 |
20,25 |
2,77 |
-0,67 |
-31,9 |
|
2 |
2,8 |
4 |
16 |
12,25 |
3,52 |
-0,72 |
-25,7 |
|
3 |
3,2 |
5 |
25 |
6,25 |
4,27 |
-1,07 |
-33,4 |
|
4 |
4,5 |
5 |
25 |
6,25 |
4,27 |
0,23 |
5,1 |
|
5 |
4,8 |
5 |
25 |
6,25 |
4,27 |
0,53 |
11,0 |
|
6 |
4,9 |
5 |
25 |
6,25 |
4,27 |
0,63 |
12,9 |
|
7 |
5,5 |
6 |
36 |
2,25 |
5,02 |
0,48 |
8,7 |
|
8 |
6,5 |
7 |
49 |
0,25 |
5,77 |
0,73 |
11,2 |
|
9 |
12,1 |
15 |
225 |
56,25 |
11,75 |
0,35 |
2,9 |
|
10 |
15,1 |
20 |
400 |
156,25 |
15,50 |
-0,4 |
-2,6 |
|
Сумма |
61,5 |
75 |
835 |
272,5 |
- |
- |
- |
|
Средняя |
6,15 |
7,5 |
83,5 |
- |
- |
- |
- |
Таким
образом, оценка уравнения регрессии
будет иметь вид:![]() .
После
подстановки окончательно получим:
.
После
подстановки окончательно получим:
![]()
Из уравнения регрессии следует, что при увеличении объема производства на единицу его измерения производительность труда в среднем увеличивается на 0,753 тыс. руб.
Для
интерпретации модели можно также
воспользоваться коэффициентом
эластичности, значение которого
 показывает,
что при увеличении объема производства
х
на
1% производительность
труда у
в
среднем увеличится на 0,918%.
показывает,
что при увеличении объема производства
х
на
1% производительность
труда у
в
среднем увеличится на 0,918%.