

Нечітка логіка – основні положення, лінгвістична модель.
 Логико-лингвистическая
модель [ logical-linguistic model ] - модель знаний,
в которой представление знаний основано
на учете объектов предметной области,
отношений между ними и использовании
лингвистических средств. Примерами
логико-лингвистических моделей
являются семантические сети и нечеткая
логика.
Нечітка
логіка – математичний апарат, функції
приналежності.
Логико-лингвистическая
модель [ logical-linguistic model ] - модель знаний,
в которой представление знаний основано
на учете объектов предметной области,
отношений между ними и использовании
лингвистических средств. Примерами
логико-лингвистических моделей
являются семантические сети и нечеткая
логика.
Нечітка
логіка – математичний апарат, функції
приналежності.




![]()
Нечітка
логіка - нечіткий логічний вивід
Нечітка
логіка - нечіткий логічний вивід


Реалізація
нечіткого алгоритму прийняття рішень
за допомогою Matlab
Реалізація
нечіткого алгоритму прийняття рішень
за допомогою Matlab
Для выполнения сложных расчетов, подобных работе с алгоритмами нечеткой логики, необходимо использовать дополнительные инструментальные пакеты. Их можно запустить с помощью Launch Pad либо из окна команд. Инструментальный пакет для работы с алгоритмами нечеткой логики запускается с помощью команды fuzzy. Основными элементами окна Fuzzy Toolbox (рис. 7) являются: 1) меню; 2) настройка входных и выходных функций принадлежности; 3) настройка методов сложения множеств на разных этапах. Основные этапы реализации нечеткого алгоритма в пакете Matlab. 3.1. Осуществить выбор функций принадлежности, используя метод экспертных оценок (варианты задания приведены в Приложении). 3.2. Построить базу правил, используя выбранные функции принадлежности. 3.3. Промоделировать механизм нечеткого логического вывода с помощью пакета прикладных программ Matlab. Синтез нечітких моделей за допомогою субтрактивно кластеризації системи нейронечіткого виведення anfis середовища Matlab.
Смотри лабу про ANFIS ( 7_2 файл) Генетичні алгоритми – сфери застосування, основні поняття і компоненти.
Как известно, оптимизационные задачи заключаются в нахождении минимума (максимума) заданной функции. Такую функцию называют целевой. Как правило, целевая функция — сложная функция, зависящая от некоторых входных параметров. В оптимизационной задаче требуется найти значения входных параметров, при которых целевая функция достигает минимального (максимального) значения. Нахождение локального экстремума вместо глобального называется преждевременной сходимостью. Помимо проблемы преждевременной сходимости существует другая проблема — время процесса вычислений. Зачастую более точные оптимизационные методы работают очень долго. Генетические алгоритмы — это адаптивные методы поиска, которые в последнее время используются для решения задач оптимизации. В них используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде и основные понятия линейной алгебры.
Вектор — упорядоченный набор чисел, называемых компонентами вектора Булев вектор — вектор, компоненты которого принимают значения из двух элементного (булева) множества
Хеммингово расстояние — используется для булевых векторов и равно числу различающихся в обоих векторах компонент. Хеммингово пространство — пространство булевых векторов, с введенным на нем расстоянием (метрикой) Хемминга. Хромосома — вектор (или строка) из каких-либо чисел. Индивидуум (генетический код, особь) — набор хромосом (вариант решения задачи). Обычно особь состоит из одной хромосомы Кроссинговер (кроссовер) — операция, при которой две хромосомы обмениваются своими частями Мутация — случайное изменение одной или нескольких позиций в хромосоме. Инверсия — изменение порядка следования битов в хромосоме или в ее фрагменте. Приспособленность — значение целевой функции (пригодности). Основные принципы работы ГА заключены в следующей схеме: 1. Генерируем начальную популяцию из n хромосом. 2. Вычисляем для каждой хромосомы ее пригодность. 3. Выбираем пару хромосом-родителей с помощью одного из способов отбора. 4. Проводим кроссинговер двух родителей с вероятностью pc, производя двух потомков. 5. Проводим мутацию потомков с вероятностью pm 6. Повторяем шаги 3–5, пока не будет сгенерировано новое поколение популяции, содержащее n хромосом. 7. Повторяем шаги 2–6, пока не будет достигнут критерий окончания процесса.
Опис (схема) роботи генетичного алгоритму
Основные принципы работы ГА заключены в следующей схеме: 1. Генерируем начальную популяцию из n хромосом. 2. Вычисляем для каждой хромосомы ее пригодность. 3. Выбираем пару хромосом-родителей с помощью одного из способов отбора. 4. Проводим кроссинговер двух родителей с вероятностью pc, производя двух потомков. 5. Проводим мутацию потомков с вероятностью pm 6. Повторяем шаги 3–5, пока не будет сгенерировано новое поколение популяции, содержащее n хромосом. 7. Повторяем шаги 2–6, пока не будет достигнут критерий окончания процесса. Генетичні алгоритми - основні генетичні оператори
1) операторы выбора родителей Панмиксия —В соответствии с ним каждому члену популяции сопоставляется случайное целое число на отрезке [1; n], где n — количество особей в популяции. Будем рассматривать эти числа как номера особей, которые примут участие в скрещивании. При таком выборе какие-то из членов популяции не будут участвовать в процессе размножения, так как образуют пару сами с собой.
Инбридинг´ представляет собой такой метод, когда первый родитель выбирается случайным образом, а вторым родителем является член популяции ближайший к первому (с минимальным Хемминговым расстоянием). Аутбридинг´ представляет собой такой метод, когда первый родитель выбирается случайным образом, а вторым родителем является член популяции дальнейший к первому (с максимальным Хемминговым расстоянием). Селекция состоит в том, что родителями могут стать только те особи, значение приспособленности которых не меньше пороговой величины, например, среднего значения приспособленности по популяции. Два основных метода а) При турнирном отборе (tournament selection) из популяции, содержащей N особей, выбираются случайным образом t особей (t – размер турнира), и лучшая из них особь записывается в промежуточный массив. Эта операция повторяется N раз. Особи в полученном промежуточном массиве затем используются для скрещивания (также случайным образом).
б) При рулеточном отборе крутим рулетку, сектора которой отвечают особям родителям, а их размер пропорционален пригодности особи. + простота метода – не подходит для больших популяций.
2) Рекомбинация – применяется в основном для действительных чисел. а) Дискретная рекомбинация – для каждого гена потомка генерируем случайное число соответствующее тому или иному родителю, создаем новую особь с этими генами. Применима для любого типа генов: веществ. символьных, бинарных.
Б) промежуточная применяется лишь для вещественных генов. Для каждого отдельного гена-потомка генерируется число α в промежутке [-d; 1+d]. d>=0, реком. значение d=0.25. Формула Г= Род.1 + α* (Род.2 – Род.1) Род.1 и Род.2 – значения соотв. гена у родителей 1 и 2.
в) линейная рекомбинация – аналогично промежуточной, но значение α для каждого потомка генерируется 1 раз.
Кросинговер
– бинарная рекомбинация.
а) одноточечный
– используется только 1 точка случайного
разрыва хромосомы. Хромосомы обмениваются
хвостами.
б) двуточечный – две
случайные точки разрыва, таким образом
можно заменить любые гены в хромосомах.
Строки преобразуются в циклы.
 в)
многоточечный – позволяет
задать произвольное число точек разрыва
в порядке возрастания. Голова у потомка
не меняется. Весь обмен происходит по
точкам разрыва.
г) однородный –
создает для каждого потомка маску,
к-рая являет собой набор 0 и 1 длинной в
хромосому. В зависимости от значения
маски в каждом локусе потомок наследует
ген от того или иного родителя. Таким
образом изменятся может любой ген.
д)
триадный – в качестве
маски используется особь, случайно
выбранная из популяции, не включающей
родителей. У маски мутирует 10% генов.
Гены родителя 1 сравниваются с маской,
при совпадении – его гены
попадают потомку1, иначе потомку2.
е)
перетасовочный
– родители производят случайный
обмен генами. Создаются не только
потомки, но и изменяются родители. После
обмена точечный кроссинговер.
ё) с
уменьшением замены –
точка разрыва только там, где отличны
гены, то есть уменьш. Кол-во лишних
операций. Сильная зависимость от
генофонда популяции, важно правильно
выбрать мутации.
в)
многоточечный – позволяет
задать произвольное число точек разрыва
в порядке возрастания. Голова у потомка
не меняется. Весь обмен происходит по
точкам разрыва.
г) однородный –
создает для каждого потомка маску,
к-рая являет собой набор 0 и 1 длинной в
хромосому. В зависимости от значения
маски в каждом локусе потомок наследует
ген от того или иного родителя. Таким
образом изменятся может любой ген.
д)
триадный – в качестве
маски используется особь, случайно
выбранная из популяции, не включающей
родителей. У маски мутирует 10% генов.
Гены родителя 1 сравниваются с маской,
при совпадении – его гены
попадают потомку1, иначе потомку2.
е)
перетасовочный
– родители производят случайный
обмен генами. Создаются не только
потомки, но и изменяются родители. После
обмена точечный кроссинговер.
ё) с
уменьшением замены –
точка разрыва только там, где отличны
гены, то есть уменьш. Кол-во лишних
операций. Сильная зависимость от
генофонда популяции, важно правильно
выбрать мутации.
3) Мутации нужны для вытаскивания решения
из локального экстремума, являют собой
случайное изменение генов у потомка.
Вероятность данного события может быть
случайной величиной или функцией.
а) для вещественных особей.
Шаг мутации – число на
которое изменится
ген при мутации. Меняется в течении
всего процесса, лучше малый шаг работает.
Формула: Нов.Перем =
Стар.перем
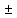 αδ
αδ
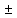 – выбираем
равновероятно
α =
0.5 * Поиск.пространство (область
значений переменной)
δ
=
– выбираем
равновероятно
α =
0.5 * Поиск.пространство (область
значений переменной)
δ
=
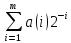
a(i) = 1, с
вероятностью
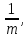 иначе 0
m – параметр.
Вероятность малого шага мутации
выше чем у большого.
б) двоичная
мутация – работаем
с бинарными строками (двоичный код или
код Грея). Суть – случайная
инверсия гена. Эффект зависит от способа
кодирования.
Плотность мутации –
параметр, задающий максимально
возможное изменение генов. Помимо
вероятности мутации потомка вообще, мы
задаем мутации каждого отдельного гена,
оптимального от 1% до 10%.
иначе 0
m – параметр.
Вероятность малого шага мутации
выше чем у большого.
б) двоичная
мутация – работаем
с бинарными строками (двоичный код или
код Грея). Суть – случайная
инверсия гена. Эффект зависит от способа
кодирования.
Плотность мутации –
параметр, задающий максимально
возможное изменение генов. Помимо
вероятности мутации потомка вообще, мы
задаем мутации каждого отдельного гена,
оптимального от 1% до 10%.
В) Другие виды мутации Присоединение – добавление нового гена к концу последовательности. Вставка — добавление нового гена в случайно выбранное место. Удаление — удаление случайно выбранного гена из последовательности. Эти операторы работают только с особями без фиксированной длинны. Для особи с фиксированной длинной только обмен в чистом виде.
4) Отбор:
А) Усечение. Особи в популяции (и родители и потомки) сортируются по значению функции пригодности (фп) . Дальнейший отбор производится лишь среди особей, значение фп которых, превышает заданный нами порог, лежащий в пределах от 0 до 1. При задании порога >1 отбор идет среди всех особей. Среди усеченной таким образом популяции N раз производится случайный выбор особи в новую популяцию.
Б) Элитарный. Включаем и родителей и потомков. Из них выбираем N самых лучших в следующее поколение. Оставшееся число генерируем так же как и исходную популяцию. Плюс метода — сохранение хороших решений до тех пор, пока не будут найдены лучшие.
В) Вытеснение. Выбор зависит не только от значений функции пригодности, но и от разнообразия генотипа родителей и потомков. Плюсы: не теряются лучшие найденные решения и поддерживается генетическое разнообразие. Работает для многоэкстремальных решений задач. Схема функціонування класичного генетичного алгоритму
1) Популяция n хромосом с фиксированной длинной генов.
2) Пропорциональный отбор формирует промежуточный массив
3) Панмиксией отбираем 2 родителей.
4) Одноточечный кроссинговер.
5) Бинарная одноточечная мутация
6) Отбор только среди потомков.
Окончание после n шагов, или при нахождении решения.
Стандартні функції універсального пакета MATLAB, призначені для вирішення завдань оптимізації за допомогою генетичних алгоритмів
Существуют 4 основные функции для работы с алгоритмом: ga — функция для нахождения минимума целевой функции; gaoptimget — возвращает параметры используемого генетического алгоритма; gaoptimset — устанавливает параметры генетического алгоритма; gatool — открывает окно Genetic Algorithm Tool. (смотри рисунок)
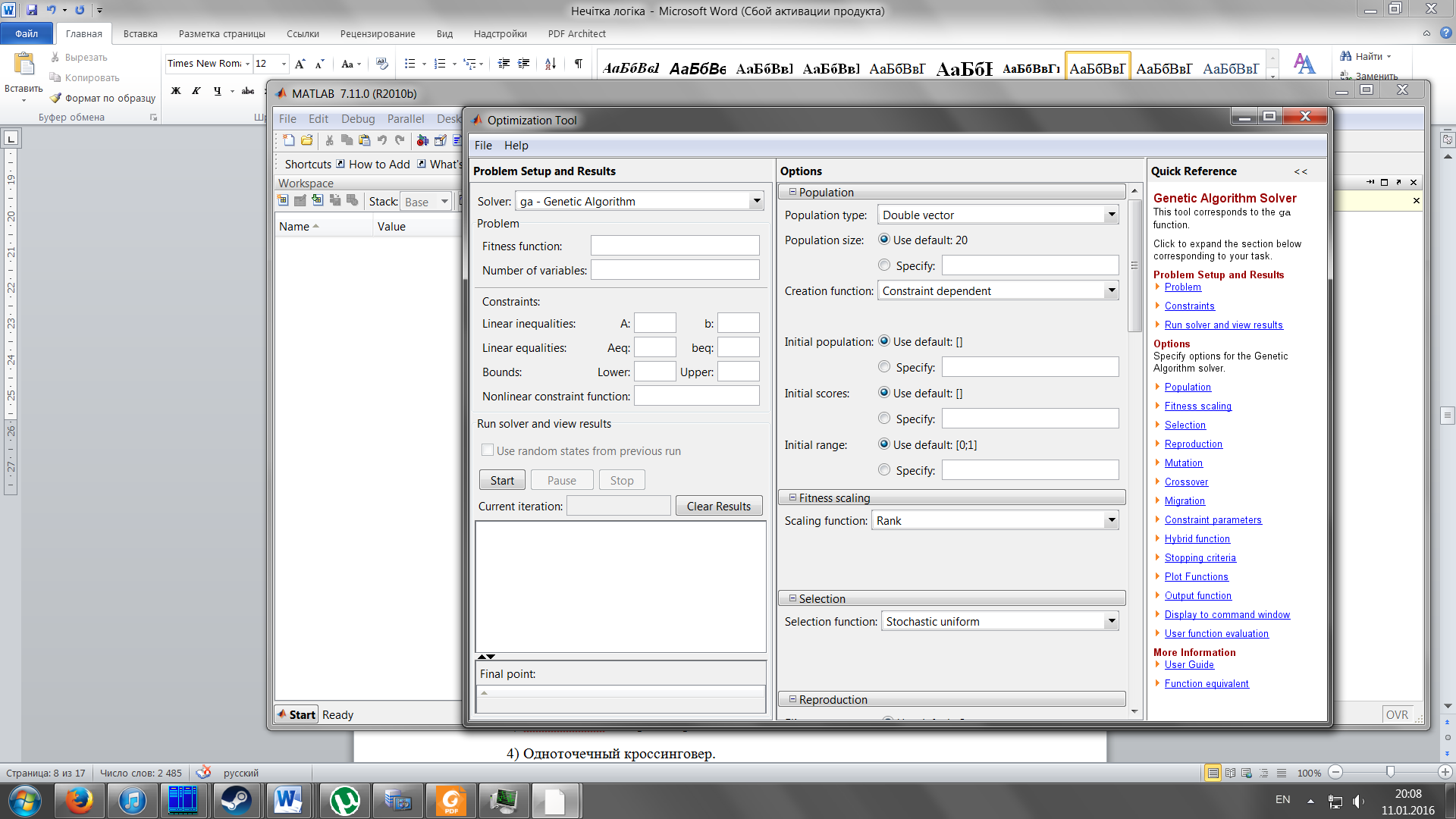
Функция ga вызывается в командной строке согласно нижеприведенному синтаксису: [x fval] = ga(@fitnessfun, nvars, options) здесь fitnessfun — имя M-file, содержащего поставленную целевую функцию; nvars — число независимых переменных в целевой функции; options — структура, содержащая параметры используемого ГА. Если параметры не изменять, то их значения возьмутся по умолчанию; Результаты вычислений сохранятся в переменных: fval — окончательное значение целевой функции; x — точка, в которой достигнуто оптимальное значение.
Для настройки генетического алгоритма используется функция gaoptimset. Она позволяет построить ГА комбинируя, операторы по желанию пользователя. Синтаксис данной функции выглядит следующим образом. Синтаксис options = gaoptimset gaoptimset options = gaoptimset(’param1’,value1,’param2’,value2,...)
options = gaoptimset (здесь аргументы не вводятся) с помощью данной конструкции задается структура ГА, отличная от структуры ГА поумолчанию. gaoptimset не требует ввода или вывода аргументов. В результате сформирует список параметров и их действительных значений. options = gaoptimset(’param1’,value1,’param2’,value2,...) генерирует структуру с множеством параметров их значений. Для нескольких неспециальных параметров можно использовать значения по умолчанию.
Методи розв'язання задач оптимізації за допомогою GA в пакеті Matlab

Типи
генетичних алгоритмів (канонічний,
генітор, метод переривчастого рівноваги,
гібридний
алгоритм та ін.
Типи
генетичних алгоритмів (канонічний,
генітор, метод переривчастого рівноваги,
гібридний
алгоритм та ін.
а) Канонический 1) Популяция n хромосом с фиксированной длинной генов.
2) Пропорциональный отбор формирует промежуточный массив
3) Панмиксией отбираем 2 родителей.
4) Одноточечный кроссинговер.
5) Бинарная одноточечная мутация
6) Отбор только среди потомков.
Окончание после n шагов, или при нахождении решения.
Б) Генитор (специфический отбор). 1) Инициализация популяции.
2) Случайный отбор 2 особей.
3) Первый потомок заменяет наименее приспособленную особь в популяции.
4) Повторяем шаг 2
5) Потомок 2 заменяет наименее приспособленного родителя.
6) Итог: на каждом шаге обновляется 1 особь. Продолжаем пока пригодности хромосом не станут одинаковыми.
Окончание после n шагов, или при нахождении решения.
В) Метод прерывистого равновесия.
1) Инициализация популяции.
2) Панмиксия.
3) Кроссинговер.
4) Смешиваем максимально пригодных родителей и потомков
5) Новое поколение будет иметь пригодность выше средней
6) Итог: управление размером популяции, в зависимости от наличия лучших особей.
Г) Гибридный.
Сочетание ГА с другими классическими методами подходящими под данную задачу. Популяция формируется из особей, находящихся в локальных оптимумах.
-
Отбор родителей
-
Кроссинговер
-
Мутация
Вероятность найти глобальный максимум велика. После оптимизации такая особь будет решением задачи.
Д) СНС – нет мутаций. Популяции небольшого размера (15-20, до 50). Отбор между родителями и потомками. Панмиксия + инбридинг для однородного кроссинговера. Потомку достается ровно по половине генов от каждого родителя. Дублирование строк (особей) запрещено. В новой популяции лучшие особи.
Е) ГА с нефиксированным размером. Внедрение параметра возраста позволяет исключить оператор отбора (максимальный возраст). Возраст зависит от приспособляемости и индивидуален. Потомки выделяются в дополнительную популяцию, пропорциональную родительской * вероятность воспроизведения. Родители отбираются из основной популяции. Кроссинговер, мутации. Возраст = const в процессе эволюции особи. Умерших удаляем из основной популяции, и добавляем потомков из дополнительной популяции. Формула: Popsize (t+1) = Popsize (t) + AuxPop (t) – D (t) D(t) – умершие AuxPop (t) – дополнительная популяция Popsize (t) – основная популяция
Паралельне виконання ГА - паралельний ГА, міграція, глобальна модель, модель дифузії.
А) Параллельный ГА. Популяция из N хромосом фиксированной длинны. Пропорциональный отбор скидывается в промежуточный массив. Панмиксией отбираем родителей. Однородный кроссинговер. Бинарная одноточечная мутация. Далее используем турнирный отбор, берем n= размер турнира (особей). Проводим 2 турнира, победителей скрещиваем, потомков — в новое поколение. Итог: за 1 цикл работы меняется целое поколение.
Б) Миграция. Множество подпопуляций. Эти подпопуляции развиваются независимо друг от друга в течение одинакового количества поколений T (время изоляции). По истечении Т происходят миграции (переход особи в другую подпопуляцию). При пропорциональном отборе берем наиболее пригодных особей. Топологию миграции задаем самостоятельно, сколь-угодно сложную (кольцо, полный граф и т.д.). В итоге возникает генетическое многообразие.
В) Глобальная модель рабочий хозяин. Рабочий осуществляет: отбор родителей, кросинговер, мутации, вычисляет пригодность. Хозяин занимается лишь отбором особей в новое поколение. Рабочие работают параллельно, отдают хозяину данные.
Г) Островная модель. Суть: популяция разбивается на одинаковые по размеру подпопуляции, каждая из них обрабатывается отдельно какой-либо разновидностью непараллельного ГА. Если миграций нет, то они независимы. Генетический дрейф приводит разные популяции к разным доминирующим особям (удельные князья). В маленькой популяции появляются ложные доминирующие особи и происходит преждевременное схождение. Во время миграции подпопуляции обмениваются доминирующим генетическим материалом. При частой миграции идет перемешивание. Расстояние изоляции – максимальное расстояние, на которое могут мигрировать особи одной популяции. Острова совместно используют доминирующий генетический материал.
Етапи Data Mining процесу 8 этапов
Процесс Data Mining является своего рода исследованием. Как любое исследование, этот процесс состоит из определенных этапов, включающих элементы сравнения, типизации, классификации, обобщения, абстрагирования, повторения. Этапы: – анализ предметной области; Процесс исследования заключается в наблюдении свойств объектов с целью выявления и оценки важных, с точки зрения субъекта-исследователя, закономерных отношений между показателями данных свойств. – постановка задачи; – формулировка задачи; – формализация задачи. Постановка задачи включает также описание статического и динамического поведения исследуемых объектов. – подготовка данных; 1. Определение и анализ требований к данным 2. Сбор данных 3. Предварительная обработка данных – построение моделей; Для построения моделей используются различные методы и алгоритмы Data Mining. Некоторые задачи могут быть решены при помощи моделей, построенных на основе различных методов. Идеальной модели, которая бы позволила решать разнообразные задачи, не существует. Поэтому многие разработчики включают в инструменты Data Mining возможность построения различных моделей, многие также обеспечивают возможность расширяемости моделей. – проверка и оценка моделей; Проверка модели подразумевает проверку ее достоверности или адекватности. Эта проверка заключается в определении степени соответствия модели реальности. Адекватность модели проверяется путем тестирования. Проверка модели также подразумевает определение той степени, в которой она действительно помогает менеджеру при принятии решений. Оценка модели подразумевает проверку ее правильности. Оценка построенной модели осуществляется путем ее тестирования – выбор модели; Если в результате моделирования нами было построено несколько различных моделей, то на основании их оценки мы можем осуществить выбор лучшей из них. Основные характеристики модели, которые определяют ее выбор, - это точность модели и эффективность работы алгоритма – применение модели; После тестирования, оценки и выбора модели следует этап применения модели. На этом этапе выбранная модель используется применительно к новым данным с целью решения задач, поставленных в начале процесса Data Mining. Для классификационных и прогнозирующих моделей на этом этапе прогнозируется целевой (выходной) атрибут (target attribute).
– коррекция и обновление модели; Существует много причин, требующих обучить модель заново, т.е. обновить ее, чтобы отразить определенные изменения. Основными причинами являются следующие: • изменились входящие данные или их поведение; • появились дополнительные данные для обучения; • изменились требования к форме и количеству выходных данных; • изменились цели бизнеса, которые повлияли на критерии принятия решений; • изменилось внешнее окружение или среда (макроэкономика, политическая ситуация, научно-технический прогресс, появление новых конкурентов и товаров) Організаційні та людські чинники в Data Mining Организационная культура подразумевает активное открытое сотрудничество по обмену информацией между отделами компании и ее сотрудниками. Чтобы сотрудники могли работать на максимально высоком уровне, организация должна обеспечить свободный поток нужной информации к тому сотруднику, которому она требуется, в четкие сроки и в правильной форме; только тогда возможно будет выработать своевременное оптимальное решение. Довольно сложно и установить время, которое необходимо для определения качества оценки модели. Этот отрезок времени обусловливается спецификой задачи и определяется индивидуально. Человеческие факторы: Человеческий фактор при внедрении Data Mining - это наличие и квалификационное соответствие специалистов, готовых работать с Data Mining. Проблема недоверия пользователей: Основными причинами этого является недоверие к моделям либо их непонимание. Для того чтобы избежать подобных явлений, лица, принимающие решения, должны принимать участие в постановке той задачи, для которой строится модель. В дальнейшем следует научить руководителя работать с моделью (т.е. ее программной реализацией), в частности, объяснить ему функции модели, возможности, ограничения и т.д. Построенная модель может обладать рядом погрешностей. Вот некоторые из них: недостоверные исходные допущения при построении модели; ограниченные возможности при сборе необходимых данных; неуверенность и страхи пользователя системы, и, в силу этого, слабое их применение; неоправданно высокая стоимость. Процес Data Mining з погляду людського чинника, ролі в Data Mining
Процесс Data Mining, с точки зрения человеческого фактора, является постоянным взаимодействием трех основных специалистов (специалист предметной области, администратор баз данных, специалист по добыче данных).
Взаимодействие специалиста по добыче данных и специалиста по предметной области осуществляется в двух точках соприкосновения (не забываем при этом, что Data Mining - итеративный процесс).
Первая точка - анализ предметной области, где определяются задачи и требования к будущей системе. Специалист по добыче данных должен вникнуть в предметную область, изучить ее базовые термины, другими словами, он должен провести анализ предметной области. На основании знаний методов и инструментов Data Mining специалист по добыче данных предлагает вариант решения проблемы.
Второй точкой соприкосновения указанных выше специалистов является интерпретация результатов, полученных в результате Data Mining.
Взаимодействие специалиста по добыче данных и администратора баз данных осуществляется на этапах анализа требований к данным и сбора данных. Непосредственно подготовка данных для Data Mining может осуществляться специалистом по добыче данных самостоятельно либо во взаимодействии с администратором баз данных.
Взаимодействие трех специалистов осуществляется на завершающих этапах Data Mining при проверке работоспособности системы, например, при сравнении прогнозных результатов с реальными. При необходимости процесс Data Mining возвращается на один из предыдущих этапов.
Роли: Специалисты компании, вовлеченные в процесс Data Mining, исполняют одну из ролей: специалист предметной области, администратор баз данных, специалист по добыче данных. Роли Data Mining, в зависимости от конечной цели работ, распределяются следующим образом:
-
исследователи (написание исследовательских докладов и статей);
-
практикующие аналитики (решение реальных и практических задач анализа данных);
-
разработчики программного обеспечения (написание Data Mining- программного обеспечения);
-
студенты (в настоящее время обучающиеся в учебных заведениях);
-
бизнес-аналитики (главным образом, оценивающие результаты использования data mining);
-
менеджеры (управляют одним или большим количеством проектов);
-
другие.
Стандарти Data Mining
CRISP-DM методологія При помощи методологии CRISP-DM Data Mining превращается в бизнес-процесс, в ходе которого технология Data Mining фокусируется на решении конкретных проблем бизнеса. Методология CRISP-DM, которая разработана экспертами в индустрии Data Mining, представляет собой пошаговое руководство, где определены задачи и цели для каждого этапа процесса Data Mining. SEMMA методологія Эта методология не навязывает каких-либо жестких правил. В результате использования методологии SEMMA разработчик может располагать научными методами построения концепции проекта, его реализации, а также оценки результатов проектирования. Стандарт PMML По словам сторонников PMML, этот стандарт "делает Data Mining более демократичным", позволяет все большому количеству пользователей пользоваться продуктами Data Mining. Это достигается за счет возможности использования ранее созданных моделей данных. PMML позволяет использовать модели данных сколь угодно часто и существенно помогает в практической работе с ними. По результатам последних опросов KDnuggets (2004 г.), 42% опрошенных лиц использует методологию CRISP-DM, 10% - методологию SEMMA, 6% - собственную методологию организации, 28% - свою собственную методологию, другими методологиями пользуется 6% опрошенных. Не пользуются никакой методологией 7% опрошенных. CRISP-DM методологія
CRoss Industry Standard Process for Data Mining (сокращенно CRISP – DM) – кросс-индустриальный стандарт глубинного анализа данных. Состоит из 6 этапов жизненный цикл: 1) Понимание бизнеса (постановка задачи) Этот начальный этап посвящен цели проекта и требованиям с точки зрения бизнеса, а затем преобразованию этих знаний в задачу применения интеллектуального анализа данных, а также разработке предварительного плана, направленного на достижение целей.
2) Понимание данных (детализация задачи и подзадач) Понимание данных начинается с первоначального сбора данных и переходу ознакомлению с данными, выявлению проблем качества данных. Цель понять структуру данных, обнаружить интересные подмножества для формирования гипотез для анализа скрытых закономерностей.
3) Подготовка данных На данном этапе формируются таблицы с набором записей и атрибутов, а также необходимые преобразования и очистка данных для моделирования.
4) Моделирование Как правило, существует несколько методов для одного и того же типа задач. В этой фазе идет выборов методов моделирования и их применение. Кроме того, на этом же этапе идет подгонка параметров модели под оптимальные результаты. Иногда необходим возврат на предыдущий этап.
5) Оценка Прежде чем приступить к окончательному развертыванию модели, важно более тщательно оценить модель, и оценить все шаги построения модели, решает ли она основную бизнес задачу.
6)
Развертывание
Полученные
знания должны быть представлены таким
образом, что бизнес-заказчик их мог
интерпретировать и использовать в своей
работе. Во многих случаях это будет
решать бизнес-заказчик, а не DM-аналитик.
В любом случае аналитик должен сопровождать
этот процесс.
SEMMA
методологія
Ее
аббревиатура образована от слов Sample
("Отбор данных", т.е. создание
выборки), Explore ("Исследование отношений
в данных"), Modify ("Модификация
данных"), Model ("Моделирование
взаимозависимостей"), Assess ("Оценка
полученных моделей и результатов").

Стандарт PMML
Не так давно рабочей группой Data Mining Group был предложен стандарт PMML (Predictive Model Markup Language), который позволяет осуществлять обмен моделями, созданными в приложениях различных поставщиков программного обеспечения Data Mining. Основа этого стандарта - язык XML. Примером другого стандарта, также основанного на языке XML, является стандарт обмена статистическими данными и метаданными. Стандарт PMML используется для описания моделей Data Mining и статистических моделей. Основная цель стандарта PMML - обеспечение возможности обмена моделями данных между программным обеспечением разных разработчиков. При помощи стандарта PMML -совместимые приложения могут легко обмениваться моделями данных с другими PMML -инструментами. Таким образом, модель, созданная в одном программном продукте, может использоваться для прогнозного моделирования в другом. По словам сторонников PMML, этот стандарт "делает Data Mining более демократичным", позволяет все большому количеству пользователей пользоваться продуктами Data Mining. Это достигается за счет возможности использования ранее созданных моделей данных. PMML позволяет использовать модели данных сколь угодно часто и существенно помогает в практической работе с ними.
Стандарт PMML включает:
-
описание анализируемых данных (структура и типы данных);
-
описание схемы анализа (используемые поля данных);
-
описание трансформаций данных (например, преобразования типов данных);
-
описание статистик, прогнозируемых полей и самих прогнозных моделей.
Стандарт PMML обеспечивает поддержку наиболее распространенных прогнозных моделей, созданных при помощи алгоритмов и методов анализа данных, в частности - нейронных сетей, деревьев решений, алгоритмов ассоциативных правил, кластерного анализа, логических правил и др. Інструменти Data Mining – критерії порівняння, класифікація
Для выбора продукта следует тщательно изучить задачи, поставленные перед Вами, и обозначить те результаты, которые необходимо получить. Оценка программных средств Data Mining с точки зрения конечного пользователя определяется путем оценки набора его характеристик. Их можно поделить на две группы: бизнес-характеристики(Наличие демонстрационной версии, Защита и пароль, Наглядность и разнообразие получаемой отчетности) и технические характеристики (Удобство экспорта/импорта данных, Скорость вычислений и скорость представления результатов, Платформы). Это деление является достаточно условным, и некоторые характеристики могут попадать одновременно в обе категории (Интуитивный интерфейс). Рынок инструментов Data Mining определяется широтой этой технологии и вследствие этого - огромным многообразием программного обеспечения. Приведем классификацию инструментов Data Mining согласно KDnuggets: инструменты общего и специфического назначения; бесплатные и коммерческие инструменты.
Наиболее популярная группа инструментов содержит следующие категории (6):
-
наборы инструментов (К этой категории относятся универсальные инструменты, которые включают методы классификации, кластеризации и предварительной подготовки данных);
-
классификация данных (Существует множество инструментов для решения задач классификации. Инструменты этой группы строят модели, которые делят исходный набор данных на 2 или более дискретных класса. Инструменты классификации, в соответствии с используемыми методами, делятся на следующие категории: правила, деревья решений, нейронные сети, Байесовские сети, метод опорных векторов и другие.);
-
кластеризация и сегментация (Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной. Сегментация – кластеризация рынка или потребителей.);
-
инструменты статистического анализа (реализуют: процедура анализа распределений переменных (например, чтобы выявить переменные с несимметричным или негауссовым распределением, в том числе и бимодальные), просмотр корреляционных матриц (см. предыдущий пример), или анализ многовходовых таблиц частот);
-
анализ текстов (Text Mining), извлечение отклонений (Information Retrieval (IR)) (метод может быть использован для лучшего понимания текстовой компоненты данных за счет автоматического выделения наиболее распространенных ключевых понятий);
-
инструменты визуализации (В результате визуализации создается графический образ анализируемых данных. Для решения задачи визуализации используются графические методы , показывающие наличие закономерностей в даннях).
Які сучасні проблеми вирішуються в «штучному інтелекті»? В современном мире рост производительности программиста практически достигается только в тех случаях, когда часть интеллектуальной нагрузки берут на себя компьютеры. Одним из способов достигнуть максимального прогресса в этой области является "искусственный интеллект", когда компьютер не только берет на себя однотипные, многократно повторяющиеся операции, но и сам может обучаться. Кроме того, создание полноценного "искусственного интеллекта" открывает перед человечеством новые горизонты развития. ИИ должен уметь решать «интеллектуальные задачи», то есть те, для которых нет алгоритмов решения. Штучний інтелект – це штучно створена людиною система, здатна обробляти інформацію, яка до неї надходить, пов'язувати її із знаннями, якими вона вже володіє, і відповідно формувати своє власне уявлення про об’єкти пізнання. Робота над штучним інтелектом ведеться в трьох основних напрямках. Перше - це розкрити таємниці людського мислення, дослідити структуру мозку і механізми його роботи. Вчені працюють над вивченням психофізіологічних даних людини, відпрацьовують гіпотези, пов'язані з роботою механізмів різних видів інтелектуальної діяльності, розглядають впровадження їх в інтелектуальні інформаційні системи.
У другому напрямі ведуться роботи по власне моделюванню, тобто створенню такої системи за допомогою комп'ютерної техніки і т.д. Його представники зайняті розробкою програмного забезпечення, алгоритмічних схем для обчислювальної техніки такого роду і класу, яка б виступала як інтелектуальна система і вирішувала проблеми на людському, усвідомленому і творчому рівні.
Вчені, що представляють так званий третій напрямок, працюють в, здавалося б, зовсім фантастичною області - створення конкретних людино-роботів, в яких функції інформаційної системи, тобто штучного розуму, поєднувалися б з можливостями природного людського інтелекту.
Інтелектуальні інформаційні системи – три базові функції Отже, інтелектуальними автоматизованими інформаційними системами (ІАІC) називаються інформаційно-програмні вироби, які тією чи іншою мірою виконують три основні функції інтелектуальності: подання та обробку знань, міркування, спілкування. Користувацькі ІАІС на відміну від інструментальних мають професійні бази знань користувача, і це їх найсуттєвіша різниця. (помогает врачу определить болезнь) Інструментальні ІАІС призначені для формалізації професійних знань користувачів, а тому основний зміст їх баз знань становлять інформаційні технології формалізації знань, які через інтерфейс стають доступними для користувачів. (опрашивает врача, чтобы обучиться тому как определять болезни) 1 сприймає вхідну інформацію 2 обробляє введені дані, згідно правилам/алгоритмам 3 виводить зформовану відповідь. 1. Подавати та обробляти знання — нагромаджувати відомості про реальний світ, класифікувати та оцінювати їх у прагматичному плані (щодо корисності) та щодо несуперечливості, ініціювати процеси здобування нових знань, зіставляти щойно здобуті знання з тими, що вже зберігаються.
2. Провадити міркування — поповнювати знання, що надходять, за допомогою логічних умовиводів, відображати закономірності реального світу або нагромаджених раніше знань, здобувати узагальнені знання на підставі частинних знань і логічно планувати свою діяльність.
3. Забезпечувати спілкування — передавати інформацію людині у зручній для неї формі і діставати інформацію по каналах зв'язку, аналогічних тим, які використовує людина, сприймаючи навколишній світ, вміти формувати «для себе» або за запитом людини пояснення власної діяльності, вміти взаємодіяти з іншими інформаційно-програмними виробами.
Дайте декілька визначень поняття «Інтелектуальної системи» 1) Інтелектуальні системи (ІС) – це новий клас автоматизованих систем оброблення інформації на основі ПК, які моделюють розумові процеси, притаманні людині при прийнятті рішень у різних галузях соціально-економічної сфери суспільства. 2) Інтелектуальними називають системи, основним ядром яких є база знань або модель предметної області, що описана мовою високого рівня наближеною до природної. 3) Експертні системи - комп’ютерні програми, здатні накопичувати і моделювати процес експертизи. Експертна система акумулює професійні знання керівників і фахівців, використовуючи їх для формування бази знань, яка містить набір взаємопов’язаних правил, також надавати готове рішення або пораду. 4) СППР - такі інтерактивні інформаційні системи, які допомагають особам, що приймають рішення, використовувати дані і моделі, щоб вирішувати неструктуровані і слабоструктуровані проблеми. На рівні стратегічного управління СППР використовуються для довгострокового, середньострокового, короткострокового і фінансового планування. При операційному управлінні СППР застосовуються в галузях маркетінгу (прогнозування та аналіз збуту, дослідження ринку і цін), науково-дослідних та конструкторських робіт, в управлінні кадрами. Знання — основний термін теорії ШІ, основні властивості знань Знання – це закономірності предметної області (принципи, закони, зв’язки), що набуті під час практичної діяльності та професійного досвіду, і в подальшому дозволяють фахівцям вирішувати задачі в цій області. Зна́ние — в теории искусственного интеллекта и экспертных систем — совокупность информации и правил вывода (у индивидуума, общества или системы ИИ) о мире, свойствах объектов, закономерностях процессов и явлений, а также правилах использования их для принятия решений. Главное отличие знаний от данных состоит в их структурности и активности, появление в базе новых фактов или установление новых связей может стать источником изменений в принятии решений. Поняття знань розглядається як сукупність даних, що мають розвинену і складну структуру. Знання – це спеціальна форма подання інформації, що дозволяє мозку зберігати, відтворювати і розуміти її. Далеко не вся інформація виступає у ролі знання. Знання – це особлива інформація, зафіксована і виражена в мові. Типи відносин, що визначають зв’язок знань з позамовним світом, один з одним і з системою людських дій
підпорядковуються особливим закономірностям – семантиці, синтаксису і прагматиці Основні властивості знань:
– Внутрішня інтерпретованість. Разом з елементом даних в ЕОМ зберігається система
імен. Це дозволяє «знати», що зберігається в пам’яті системи і вміти відповідати на за-
пити про зміст пам’яті.
– Рекурсивна структурованість. Інформаційні одиниці можуть бути розбиті на
менш дрібні і об’єднуватися в більш великі (за аналогією з матрьошкою). Для цього
використовуються родо-видові відносини і приналежність елементів до певного класу.
(Число структуроутворюючих відносин – більш 200 типів).
– Взаємозв’язок інформаційних одиниць. Між одиницями встановлюються різно-
манітні відносини семантичного і прагматичного характеру зв’язків (явищ і фактів).
Коли між одиницями виникають такі відносини, фрагменти цієї структури становлять
нові інформаційні одиниці.
– Наявність семантичного простору. Воно характеризує близькість-віддаленість
інформаційних одиниць один від одного. Знання можуть являти собою безсистемне
нагромадження одиниць, вони повинні бути взаємопов’язані і взаємозалежні в се-
мантичному просторі Внутрішня інтерпретація. Кожна інформаційна одиниця повинна мати унікальне ім’я, за яким її знаходить інтелектуальна система, а також відповідає на запитання, де це ім.’я згадується.
Структурованість. Знання повинні мати гнучку структуру: одні інформаційні одиниці можуть міститися у складі інших (клас-ціле, елемент-клас).
Зв’язність. Між різними інформаційними одиницями можуть встановлюватися різні типи зв’язків (причинно-наслідкові, просторові).
Семантична метрика. Для інформаційних одиниць можна задавати відношення, що характеризують ситуаційну близькість.
Активність. Виконання програм в інтелектуальній системі повинно ініціюватися поточним станом бази знань.
Добре і погано структуровані предметні області
-
Предметна область. Містить знання про конкретну галузь, в якій працює інтелектуальна система.
-
Добре структуровані з чіткою аксіомізацією, широким застосуванням математичного апарату, усталеною термінологією.
-
Слабко структуровані з розмитими визначеннями, багатою емпірикою, прихованими взаємозв’язками.
Прикладами таких слабко структурованих областей є планування наукових досліджень,
проблеми конкурсного відбору проектів, створення політики відбору статей у журнали
та ін. На противагу до добре структурованих предметних областей, до яких можна від-
нести типові задачі дослідження операцій: вибір та оцінювання елементів технічних
рішень, складання плану постачання підприємств, розрахунок радіоактивного заражен-
ня місцевості та ін. у слабко структурованих областях ми не можемо побудувати адек-
ватну модель будь-яким способом, окрім як звернувшись до експерта та з’ясувавши йо-
го переваги стосовно варіантів розвитку подій, стосовно рівня впливів тих чи інших
факторів тощо. у слабко структурованих областях цільова функція зазвичай не може бути пред-
ставлена аналітично, існує тільки її алгоритмічне представлення (наприклад, такою фу-
нкцією може бути ступінь досягнення головної цілі проблеми); вхідними даними для побудови моделі є суб’єктивні експертні оцінки, які не є досить строгими і точними,
Представлення
завдання в просторі станів

Стратегії пошуку в просторі станів

Представлення
простору станів у вигляді графа
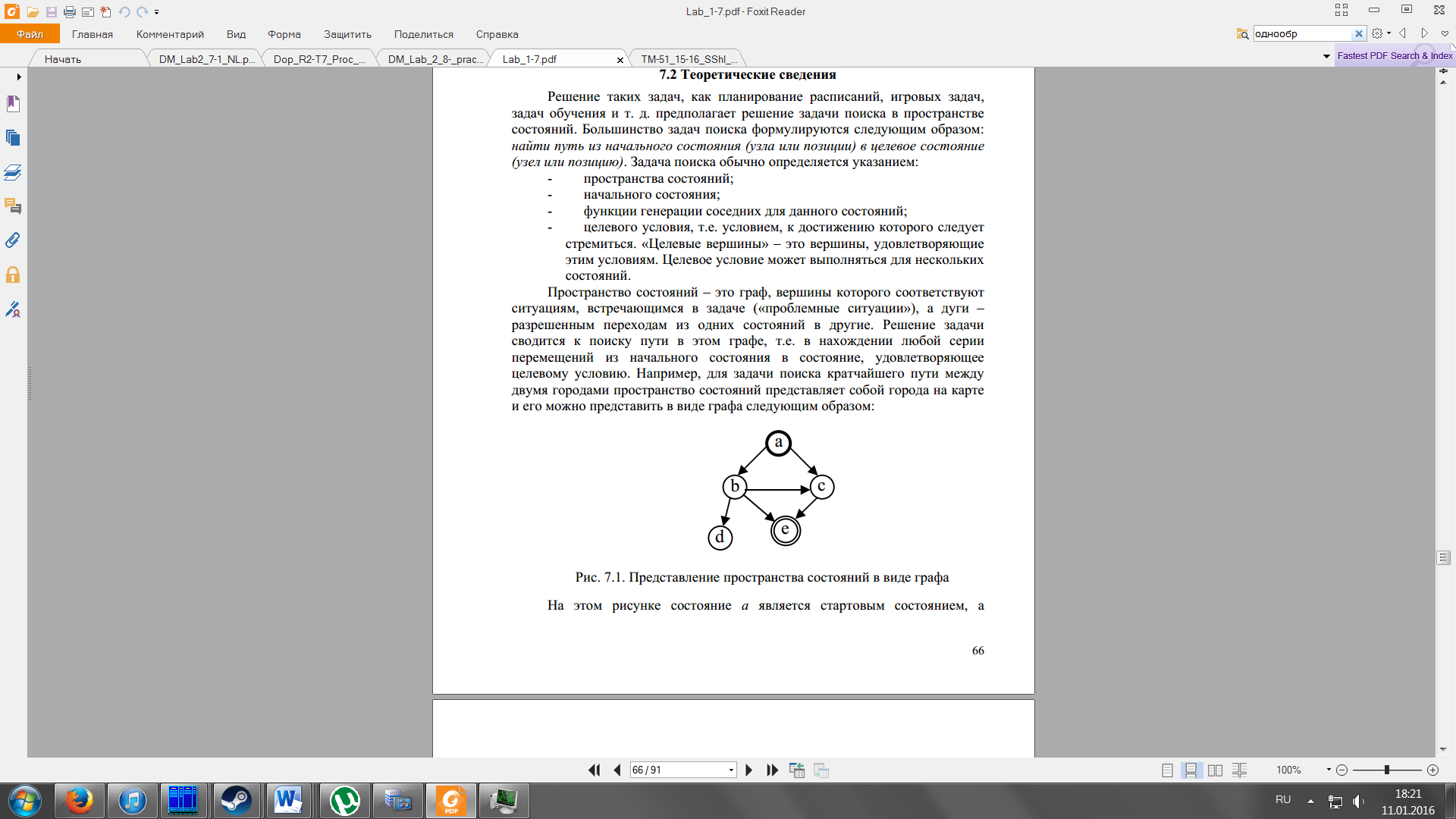
Пошук в глибину
Поиск в глубину – порядок рассмотрения альтернатив в пространстве состояний.



Пошук в ширину


Пошук з перевагою: евристичний пошук

Процесс поиска с предпочтением состоит из некоторого числа конкурирующих между собой подпроцессов, каждый из которых занимается своей альтернативой, т.е. просматривает свое поддерево. У поддеревьев есть свои поддеревья, их просматривают подпроцессы подпроцессов и т.д. В каждый данный момент среди всех конкурирующих процессов активен только один – тот, который занимается наиболее перспективной к настоящему моменту альтернативой, т.е. альтернативой с наименьшим значением f.
Остальные процессы спокойно ждут того момента, когда f-оценки изменятся и в результате какая-нибудь другая альтернатива станет наиболее перспективной. Тогда производится переключение активности на эту альтернативу.
Механизм
активации-дезактивации
процессов функционирует
следующим образом: процесс,
работающий
над текущей альтернативой
высшего приоритета, получает
некоторый
«бюджет» и остается активным
до тех пор, пока его бюджет не
исчерпался.
Находясь в активном состоянии, процесс
продолжает
углублять свое
поддерево. Встретив целевую вершину,
он выдает соответствующее
решение.
Величина бюджета, предоставляемого
процессу на данный конкретный
запуск, определяется эвристической
оценкой конкурирующей
альтернативы,
ближайшей к данной.
Класичні
способи представлення знань в
інтелектуальних системах
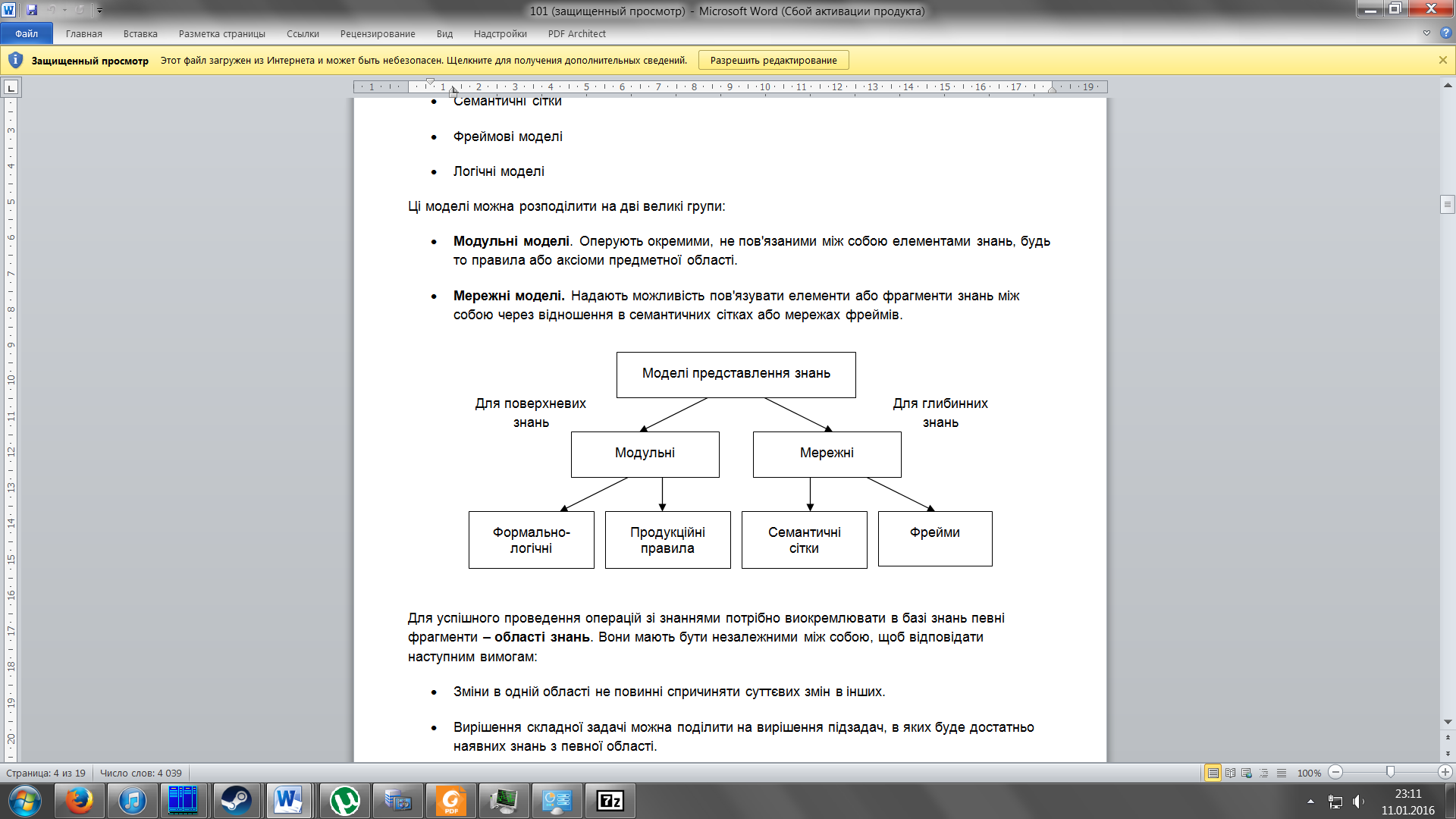
Продукційна модель Продукційна модель або модель, що заснована на правилах, дозволяє представити знання у вигляді речень типу
«Якщо (умова), то (дія)». Під умовою розуміється деяке речення-зразок, за яким здійснюється пошук у базі знань, а під дією - дії, що виконуються при успішному результаті пошуку (вони можуть бути проміжними, які виступають далі як умови, і термінальними або цільовими, що завершують роботу системи).
Семантична модель Термін семантичний означає змістовний, «семантика» - це наука, що встановлює відношення між символами і об'єктами, які вони позначають, тобто, це наука, що визначає зміст знаків.
В основі моделі лежить семантична мережа, яка в загальному випадку представляє інформаційну модель предметної області і має вигляд графа, вершини якого відповідають об'єктам предметної області, а дуги - відношення між ними.
Фреймова модель (обєктно-орієнтована)
Фреймом називається мінімально можливий опис певної сутності, такий, що подальше скорочення цього опису приводить до втрати цієї сутності.
Фреймом називається також і формалізована модель для відображення образу.
Логічні моделі
Логічна модель представлення знань — модель у представленні знань.
Основна ідея підходу при побудові логічних моделей представлення знань — вся інформація, необхідна для вирішення прикладних завдань, розглядається як сукупність фактів і тверджень, які представляються як формули в деякій логіці. Знання відображаються сукупністю таких формул, а отримання нових знань зводиться до реалізації процедур логічного висновку. У основі логічних моделей представлення знань лежить поняття формальної теорії, кортеж S = < B,F,A,R >, де:
B — зліченна множина базових символів (алфавіт);
F — множина, елементи якої називають формулами;
A — виділена підмножина апріорі справедливих формул (аксіом);
R — зліченна множина відношень між формулами, яку називають правилами висновку.
Продукційна модель: Якщо двигун не заводиться і стартер двигуна не працює, То несправна система електроживлення.
Фреймова модель: Автомобіль таксі{<автомобіль таксі>; <номерний знак> <ВО5014ТЕ>; <стан> <справний>; <гараж>; <автоколона>}. Ім*я слота {<ім*я слота>; <fi> <vi>; <fn> <vn>; <q1>; <qn>}, де fi – імена характеристик, vi – значення атрибутів, q – посилання на інші слоти
Модель семантичної мережі: студент – отримує стипендію, це людина, здає екзамен у професора, вчиться в університеті; професор – це людина, працює в університеті; університет – це ВНЗ.
Логічна модуль представлення знань: Якщо тварина має пір*я І відкладає яйця, ТО ця тварина є птахом.
Відмінність знань від даних, класифікація знань
Зна́ние — в теории искусственного интеллекта и экспертных систем — совокупность информации и правил вывода (у индивидуума, общества или системы ИИ) о мире, свойствах объектов, закономерностях процессов и явлений, а также правилах использования их для принятия решений. Главное отличие знаний от данных состоит в их структурности и активности, появление в базе новых фактов или установление новых связей может стать источником изменений в принятии решений. Класифікація:
Поверхневі знання (нульовий рівень). Це знання про очевидні взаємозв’язки між окремими подіями і фактами в предметній області.
Глибинні знання (метазнання). Це абстракції, аналоги, схеми, які відбивають структуру та природу процесів у предметній області. Вони пояснюють явища і можуть використовуватися для передбачення поведінки системи.
За рівнем деталізації:
В цьому разі до уваги береться ступінь деталізації знань. Кількість рівнів детальності залежить від специфіки задачі, обсягу наявних знань і обраної моделі представлення знань.
За способом представлення в алгоритмах:
Процедурні знання. Були історично першими. Процедурні знання розчиняються в алгоритмі, де чітко вказано план дій від А до Я. Процедурні знання керують даними, а для їх зміни – потрібно змінювати програму.
Декларативні знання. З розвитком ШІ пріоритет даних змінюється і більша частина знань зосереджується в структурах даних (таблиці, списки), де будуються взаємозв’язки між об’єктами. Розробнику лишається тільки вірно сформулювати завдання. Роль декларативних знань збільшується.
Семантична мережа - визначення, структура Термін семантичний означає змістовний, «семантика» - це наука, що встановлює відношення між символами і об'єктами, які вони позначають, тобто, це наука, що визначає зміст знаків.
В основі моделі лежить семантична мережа, яка в загальному випадку представляє інформаційну модель предметної області і має вигляд графа, вершини якого відповідають об'єктам предметної області, а дуги - відношення між ними.
Семантична модель представлення знань. Ця модель дозволяє оперувати по-
няттями, вираженими на природній мові. Прикладом реалізації такої моделі служать
експертні системи. Для побудови моделі використовують апарат семантичних мереж,
представлених у вигляді графа:
G = {Y1, Y2, ... Yn; β1, β2, ... βm},
де Y – вузли (вершини) графа. Вони відображають деякі сутності – об’єкти, події,
процеси, явища і т.д.; β – дуги графа, які позначають відносини між сутностями, задані на
множині вершин. Вершини відображають сутності різного ступеня спільності. Їх впо-
рядкування відбувається за видами відносин.
Предметна галузь відображається як сукупність сутностей і відносини між ними.
Якщо адекватно сформульовані фундаментальні поняття відносин та об’єктів предметної
галузі (тобто є всеосяжні концептуальні знання), то семантична модель працює дуже
успішно [7], [8].

Класифікація семантичних мереж
Класифікація семантичних сіток
За типом відношень
-
Однорідні. З одним типом відношень
-
Неоднорідні. З різними типами відношень
За кількістю відношень
-
Бінарні. Відношення лише між 2-ма об’єктами
-
N-арні. Відношення пов’язують більшу кількість об’єктів
Типи відношень
-
Зв’язки типу «ціле - частина» (клас – підклас, множина - елемент)
-
Функціональні зв’язки («випливає», «діє», «виробляє»)
-
Кількісні зв’язки («більше», «менше»)
-
Просторові зв’язки («далеко від», «близько до», «за», «під», «над»)
-
Часові зв’язки («раніше», «пізніше», «протягом»)
-
Атрибутивні зв’язки («має властивість», «має значення»)
-
Логічні зв’язки («І», «АБО», «НІ»)
-
Лінгвістичні зв’язки
Переваги та недоліки семантичних мереж
Термін семантичний означає змістовний, «семантика» - це наука, що встановлює відношення між символами і об'єктами, які вони позначають, тобто, це наука, що визначає зміст знаків.
В основі моделі лежить семантична мережа, яка в загальному випадку представляє інформаційну модель предметної області і має вигляд графа, вершини якого відповідають об'єктам предметної області, а дуги - відношення між ними. Переваги: - універсальність, можна описати наскільки завгодно складні факти, області;
- графічна наглядність системи;
- структура мережі описується за допомогою природньої мови;
- відповідність сучасним уявленням про функціонування памяті людини (асоціативна мережа) .
Недоліком семантичної моделі можна вважати складність організації процедури пошуку та виведення. Її недоліки виявляються, коли ми починаємо будувати складніші мережі або намагаємося врахувати особливості природної мови
Недостатки семантических сетей:
- Складне формування та модифікація моделі мережі
- потрібен спец.аппарат формального виводу;
- складно описати систему реального складності, за умови наявності великої кількості зв’язків..
Схеми для опису складних структур знань в штучному інтелекті, відмінність семантичних мереж і схем
В искусственном интеллекте для описания более сложных структур знаний, чем семантические сети, используется термин «схема». Схемы, в отличие от семантических сетей, имеют структуру, внутреннюю по отношению к узлам, в них реализованы. То есть, в них осуществляется расширение информативности о каждом узел. Все знания про определенный узел в семантической сети сведены к надписи на нем - его имени. Термин «схема» заимствован из психологии, где он определяет реакции живого существа, которые разрабатываются в соответствии с стимулом. Это означает, что живые существа, изучая причинные отношения между стимулом и результатом, стремиться повторно получить приятные стимулы и избежать неприятных. Например, при осуществлении такого действия, как езда на велосипеде, складывается определенная сенсорно-двигательная схема. Она обеспечивает координацию информации, полученной от органов, воспринимающих ощущения, с необходимыми мускульными движениями. В результате, человек не задумывается над знаниями относительно выполнения этих действий. К наиболее важных типов схем можно отнести концептуальные схемы, с помощью которых в мозге человека складываются концепции относительно объектов и явлений. То есть, все люди в своем сознании имеют определенные стереотипы, состоящий из концепций. Концептуальная схема представляет собой абстракцию, в которой конкретные объекты классифицируются согласно их общими свойствами. Во многих практических реализациях искусственного интеллекта используется разновидность схем, называемые фрейм.
Семантична мережа, в загальному випадку представляє інформаційну модель предметної області і має вигляд графа, вершини якого відповідають об'єктам предметної області, а дуги - відношення між ними. Семантическая сеть аналогична информационно-технологической структуре данных, в которой ключ поиска одновременно является, по сути, элементом данных, определяющий узел. Такой принцип организации данных применяется в базах данных иерархического и сетевого типа. В отличие от них, схема аналогична структуре данных, в которой узлы содержат записи. Такая организация, в свою очередь, является характерной для реляционных баз данных Метод представлення знань, заснований на системі фреймів
Фреймова модель представлення знань. Ця модель базується на сприйнятті лю-
диною навколишнього світу, на психології людини. Коли людина потрапляє в якусь
ситуацію, вона ідентифікує її деякій типовій структурі, наявній в її пам’яті. Ця структу-
ра і є фреймом – декларативним поданням типової ситуації, доповненою процедурною
інформацією про можливості та шляхи її використання.
Фрейм представляється мережею. Верхні рівні мережі відображають суті, істинні
для типової ситуації (конструкція фрейму). Нижні рівні закінчуються порожніми
структурами – слотами. Заповнення, визначення слотів відбувається при виклику фрейму в конкретній ситуації з предметної галузі. Фрейм включає набір слотів:
Ф = [(C1, d1), (C2, d2 ),...( Cn, dn)],
де Ф – ім’я фрейму; С – імена слотів; d – значення слотів.
Заповнення слотів відбувається в міру одержання знань про предметну галузь Фрейми дозволяють маніпулювати як декларативними, так і процедурними знаннями. До недоліків фреймових систем відносять їх відносно високу складність. Структура фрейма, основні властивості фреймів, типи фреймів
Фрейм має певну внутрішню структуру, що складається з множини елементів (слотів), яким також привласнюються імена. За слотами слідують шпації (пробіли), в які поміщають дані, що представляють поточні значення слотів. Кожен слот у свою чергу представляється визначеною структурою даних. В значення слота підставляється конкретна інформація, що відноситься до об'єкта, який описується цим фреймом.
Найважливішою властивістю теорії фреймів є запозичення з теорії семантичних мереж — так зване спадковість властивостей. Спадковість відбувається по АКО-зв'язках (A Kind of = це). Слот АКО вказує на фрейм більш високого рівня ієрархії, звідки неявно успадковуються, тобто переносяться, значення аналогічних слотів.
 Параметрами
фрейму є його імя, покажчик спадкування,
покажчик типу, значення слоту, приєднана
процедура.
Ім'я фрейму.
Воно служить для ідентифікації фрейму
в системі і має бути унікальним.
Покажчики
успадкування. Вони
показують, яку інформацію про атрибути
слотів з фрейма верхнього рівня
успадковують слоти з аналогічними
іменами в даному фреймі.
Параметрами
фрейму є його імя, покажчик спадкування,
покажчик типу, значення слоту, приєднана
процедура.
Ім'я фрейму.
Воно служить для ідентифікації фрейму
в системі і має бути унікальним.
Покажчики
успадкування. Вони
показують, яку інформацію про атрибути
слотів з фрейма верхнього рівня
успадковують слоти з аналогічними
іменами в даному фреймі.
-
U (Unique) - значення слота не успадковується;
-
S (Same) - значення слота успадковується;
-
R (Range) - значення слоту повинні знаходитися в межах інтервалу значень, зазначених в однойменному слоті батьківського фрейму;
-
О (Override) - при відсутності значення в поточному слоті воно успадковується з фрейма верхнього рівня, однак у випадку визначення значення поточного слота воно може бути унікальним.
Покажчик типу даних. Він показує тип значення слота. Найбільш вживані типи: frame – покажчик(указатель) на фрейм; real - дійсне число; integer - ціле число; boolean - логічний тип; text - фрагмент тексту; list - список; table - таблиця; expression - вираження; lisp - пов'язана процедура тощо.
Значення слоту. Воно повинно відповідати зазначеному типу даних і умові успадкування.
Демони. Демоном називається процедура, яка автоматично запускається при виконанні деякої умови. Демони автоматично запускаються при зверненні до відповідного слоту. Демон з умовою IF-NEEDED запускається, якщо в момент звернення до слоту його значення не було встановлено. Демон типу IF-ADDED запускається при спробі зміни значення слота. Демон IF-REMOVED запускається при спробі видалення значення слота. Типи фреймів:
-
Фрейми-структури використовують для позначення об’єктів та понять (університет, школа, аудиторія)
-
Фрейми-ролі (викладач, студент, декан)
-
Фрейми-сценарії (лекція, іспит, захист диплому)
-
Фрейми-ситуації (революція, раптова перевірка присутності студентів)
Приєднані процедури, використовувані у фреймовій моделі
Демони. Демоном називається процедура, яка автоматично запускається при виконанні деякої умови. Демони автоматично запускаються при зверненні до відповідного слоту. Типи демонів пов'язані з умовою запуску процедури. Демон з умовою IF-NEEDED запускається, якщо в момент звернення до слоту його значення не було встановлено. Демон типу IF-ADDED запускається при спробі зміни значення слота. Демон IF-REMOVED запускається при спробі видалення значення слота. Можливі також інші типи демонів. Демон є різновидом пов'язаної процедури.
Приєднана процедура. Як значення слота може використовуватися процедура, що називається службовою в мові ЛІСП або методом у мовах об'єктно-орієнтованого програмування. Приєднана процедура запускається за повідомленням, яке передається з іншого фрейму. Демони і приєднані процедури є процедурними знаннями, об'єднаними разом з декларативними в єдину систему. Ці процедурні знання є засобами управління виводу у фреймових системах, причому з їх допомогою можна реалізувати будь-який механізм виведення. Подання таких знань і заповнення ними інтелектуальних систем - дуже нелегка справа, яка вимагає додаткових витрат праці і часу розробників. Тому, проектування фреймових систем виконується, як правило, фахівцями, які мають високий рівень кваліфікації в галузі штучного інтелекту.
Переваги і недоліки фреймів
-
Основною перевагою фреймів як моделі представлення знань є те, що вона відображає концептуальну основу організації пам’яті людини, а також її гнучкість і наочність. Найбільш яскраво переваги фреймових систем представлення знань проявляються в тому випадку, якщо родовидові зв'язки змінюються нечасто і предметна область налічує дещо винятків.
-
Ще одна перевага фреймів полягає в тому, що значення любого слоту може бути обчислено за допомогою відповідних процедур або знайдено евристичними методами. Тобто, фрейми дозволяють маніпулювати як декларативними, так і процедурними знаннями.
-
У фреймових системах дані про родовидові зв'язки зберігаються явно, як і знання інших типів. Значення слотів представляються в системі в єдиному екземплярі, оскільки містяться тільки в одному фреймі, що описує найбільш поняття з усіх тих, які містить слот з даним ім'ям. Така властивість систем фреймів забезпечує економне розміщення бази знань у пам'яті комп’ютера.
-
До недоліків фреймових систем відносять їх відносно високу складність, що проявляється у зниженні швидкості роботи механізму виведення і збільшення трудомісткості внесення змін до родової ієрархії. Тому, при розробці фреймових систем приділяють наочним способам відображення і ефективним засобам редагування фреймових структур. Відсутність спеціального механізму керування виводом, в зв’язку з чим, розробники повинні реалізовувати даний механізм з використанням приєднаних процедур. Продукції як система представлення знань
Продукційна модель. Продукційна модель містить сукупність правил (продукції)
у вигляді:
1. ЯКЩО умова ТО дія
2. ЯКЩО причина ТО наслідок
3. ЯКЩО ситуація ТО рішення.
Суть моделі полягає в тому, що якщо виконуються певні правила умови, то потрібно зробити деяку дію. Продукційні моделі можуть бути реалізовані процедурно і декларативно. У процедурних системах неодмінно повинні бути: база даних, набір про-
дукційних правил та інтерпретатор (він визначає послідовність активізації продукцій). База даних є змінною частиною моделі, а правила та інтерпретатор постійні. Можна додавати і змінювати лише факти (знання).
Продукційні моделі застосовуються в тих предметних галузях, де немає чіткої
логіки і завдання вирішуються на основі незалежних правил (евристик). Правила продукції несуть інформацію про послідовність цілеспрямованих дій. Вони добре відображають прагматичну складову знань і використовуються для невеликих завдань [10]. Продукційна модель
Продукційна модель. Продукційна модель містить сукупність правил (продукції)
у вигляді:
1. ЯКЩО умова ТО дія
2. ЯКЩО причина ТО наслідок
3. ЯКЩО ситуація ТО рішення.
Суть моделі полягає в тому, що якщо виконуються певні правила умови, то потрібно зробити деяку дію. Продукційні моделі можуть бути реалізовані процедурно і
декларативно. У процедурних системах неодмінно повинні бути: база даних, набір продукційних правил та інтерпретатор (він визначає послідовність активізації продукцій). База даних є змінною частиною моделі, а правила та інтерпретатор постійні. Можна додавати і змінювати лише факти (знання).
Продукційні моделі застосовуються в тих предметних галузях, де немає чіткої
логіки і завдання вирішуються на основі незалежних правил (евристик). Правила продукції несуть інформацію про послідовність цілеспрямованих дій. Вони добре відображають прагматичну складову знань і використовуються для невеликих завдань [10].
Представлення знань за допомогою продукций. Структура продукції. Машина виводу. Основний цикл інтерпретатора


Продукційні правила - прямий і зворотний ланцюжок міркувань

Продукції - представлення ланцюжка виводу у вигляді І/АБО-графа


Експертні системи, засновані на правилах
Експертна система являє собою інтелектуальну систему, що моделює пам*ять і мислення людини-експерта під час вирішення інтелектуальних задач, що знаходяться у його компетенції.
Процес функціонування експертних систем здійснюється так: користувач, який бажає розв’язати свою задачу й одержати відповідну інформацію через користувацький інтерфейс, надсилає запит до системи, тобто ставить задачу. Вирішувач ЕС, використовуючи Бази Знань, розв’язує цю задачу в діалоговому режимі з користувачем і видає йому рішення, пояснюючи хід своїх міркувань за допомогою блоку пояснень. Поверхневі системи — подають знання про область експертизи у вигляді правил (умова -> дія). Умова кожного правила визначає зразок деякої ситуації, при дотриманні якої правило може бути виконано. Пошук рішення полягає у виконанні тих правил, зразки яких зіставляються з поточними даними. При цьому передбачається, що в процесі пошуку рішення послідовність формованих у такий спосіб ситуацій не обірветься до одержання рішення, тобто не виникне невідомої ситуації, що не зіставиться з жодним правилом;
Призначення. Їх використовують у різних областях людської діяльності, основні з них є: Бізнес ( прогнозування розвитку ринку економіки, вибір стратегії виходу з фірми із ризикової ситуації, вибір інвестора та страхової компанії, формування портфеля інвестицій, оцінка фінансових ризиків та оподаткування), Виробництво (планування роботи підприємств і організацій, виробництво комп*ютерів та інтегральних схем, технічна діагностика несправностей та відмовлень в устаткування), Галузі промисловості (планування промислових замовлень, контроль стану атомних реакторів, моніторинг роботи електростанцій та керування мережами розподілу електроенергії, контроль за режимами установок на хімічному заводі, керування повітряним рухом і транспортними перевезеннями, планування режимів роботи робототехнічних систем, прогнозування воєнних дій), Медицина (діагностика захіорювань і встановлення зв*язків між порушеннями функціонування організму та їх можливих причин), Наукові дослідження (одержання погоджених і коректних висновків на підставі багатоваріантного аналізу результатів спостережень), Освіта (навчання та контроль знань, навчання мови “Lips” та “Pascal”.
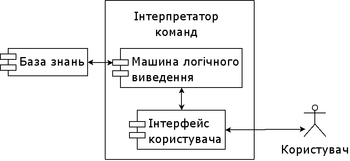
Структура експертної системи продукційного типу Типові експертні системи можуть мати таку структуру:
База даних (не обов'язкова) – містить вхідну, проміжну й вихідну інформацію щодо розв’язуваної задачі.
База знань сховище знань про властивості й закономірності предметної області.
Машина виведення (розв'язувач) – інтелектуальний комп*ютер, який моделює мислення людини-експерта.
Підсистема пояснень – видає інформацію про шлях розв*зання поставленої задачі (запиту), якщо це цікавить користувача.
Інтерфейс користувача (блок спілкування) – реалізує діалог користувача з ЕС під час введення інформації, розв*язування задачі й одержання результатів.
База знань складається з правил аналізу інформації від користувача з конкретної проблеми. ЕС аналізує ситуацію і, залежно від спрямованості ЕС, дає рекомендації з розв'язання проблеми.
ЕС створюється за допомогою двох груп людей:
- інженерів, які розробляють ядро ЕС і, знаючи організацію бази знань, заповнюють її за допомогою:
- експертів (експерта) за фахом.
До складу типової експертної системи входять підсистеми: автоматизації проектування й програмування, документування, налагодження й супроводження системи, керування процесом створення комп*ютерної системи штучного інтелекту тощо.
Переваги і недоліки продукційної моделі