

4.3.3. Алгоритм непрерывной корректировки профиля лпр
При использовании алгоритма непрерывной корректировки профиля ЛПР предполагается, что существует некоторое хранилище предыдущих запросов пользователя. В текущий момент времени iпользователь вводит новый запрос, который после соответствующей обработки помещаетсяв хранилище запросов. Обновленное (или дополненное) в момент времени iтекущим запросом хранилище запросов будем обозначатьQi.
Запрос перед передачей алгоритму обрабатывается с целью выделения ключевых терминов. Далее производится пересчет взвешенных частот терминов в хранилище запросов Qiс учетом нового запроса. Когда пользователь вводит очередной запрос, ключевым словам (терминам) данногозапроса назначаются наибольшие веса. При поступлении запроса в хранилищезапросов происходит проверка на наличие в этом хранилище терминов, присущих текущему запросу. Если термин встречается впервые, то при его занесении в хранилище вес остается без изменений, если же такой термин уже существует (это означает, что пользователь уже когда-то использовал запрос, включающий данный термин), то производится пересчет весового коэффициента данного термина. В результате происходит нормирование весовых коэффициентов. Категории интересовCiдля включения в текущий профиль извлекаются из хранилища посредством использования методологииPLSA.
Представим пошаговый алгоритм непрерывной корректировки профиля пользователя.
Инициализировать хранилище запросов Qi= {w1i,w2i, …,wki}, гдеwki– термины хранилища запросов,k= 1, …,M.
Выделить набор ключевых терминов текущего запроса.
Скорректировать весовые коэффициенты терминов и произвести их нормировку с учетом нового запроса.
Рассчитать уровень изменчивости i.
Рассчитать условные вероятности классов, используя процедуру TEMследующим образом:
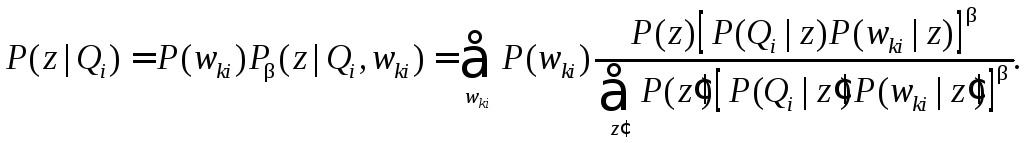
Рассчитать вероятность категории Ciдля заданного класса латентного семантического пространства:
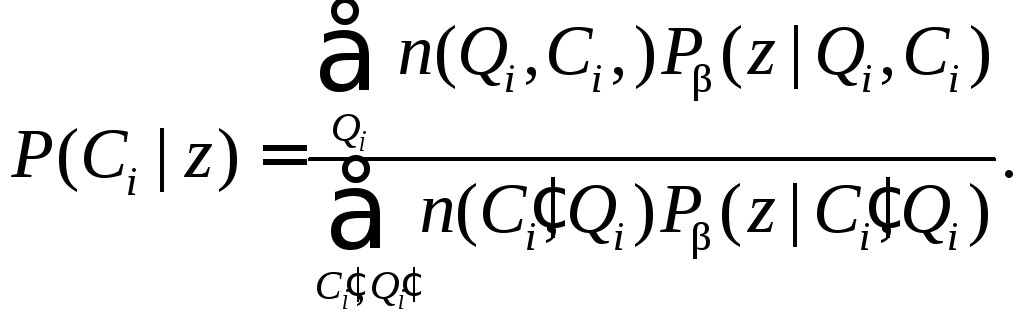
Рассчитать вероятность включения категории Ciдля текущего состояния хранилища запросовQi.
Занести категорию в профиль пользователя. Для этого включить соответствующую тройку (Ci,Wi,i) в профиль.
Если уровень изменчивости i>0(где0– заданная величина), то увеличить текущий вес категорииCiна величину
Wi :Wi= Wi+Wi.
Отсортировать последовательность троек (Ci,Wi,i) в профиле по порядку убывания весаWi.
Сохранить получившийся профиль как текущий.
Эффективность работы алгоритма непрерывной корректировки профиля пользователя была оценена на сравнительно небольших тестовых наборах данных, но и это позволило отразить реальную ситуацию в корпоративных информационно-управляющих системах.
4.4. Мультилингвистическая поисковая система
Для подготовки и принятия решения в корпоративных
Информационно-управляющих системах
Рассмотрим систему поиска мультилингвистической информации для поддержки принятия решений в корпоративных информационно-управляющих системах при помощи методики определения расстояния между отдельными точками метрического пространства производственных ситуаций (рис. 4.4). При этом для нахождения расстояния между двумя произвольными производственными ситуациями S1(t), S2(t) {S(t)} необходимо предварительно определить функции, устанавливающие степень сходства, существующего между соответствующими характеристиками S1(t), S2(t).
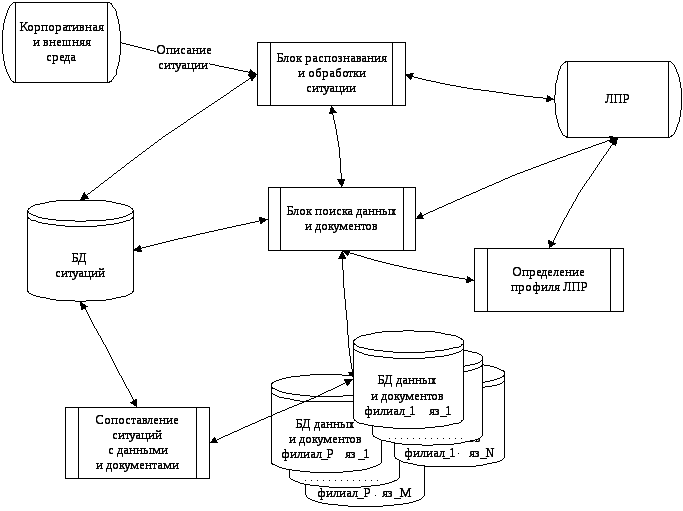
Рис. 4.4. Структурная схема реализации мультилингвистической технологии
п оиска
данных для подготовки и принятия решения
в ИУС [54]
оиска
данных для подготовки и принятия решения
в ИУС [54]
Все характеристики разбиты на четыре группы. В первой группе содержится текстовая информация, во второй группе хранится информация в числовой форме, в третьей группе – ориентированные графы, используемые ЛПР в процессе подготовки и принятия решения [16]. При этом граф G1 характеризует взаимосвязи, существующие между параметрами объекта управления, системы управления и среды, влияющими на процесс принятия решения в ситуации S, а граф G2 учитывает взаимосвязи между административными мероприятиями, которые рекомендуется осуществить в сло-жившейся ситуации. В характеристиках четвертой группы хранятся названия производственных ситуаций.
Информационные элементы мультилингвистической поисковой системы содержатся в базе данных реляционного типа в виде совокупности отношений различной структуры. Поиск этих элементов осуществляется по запросу СУБД, сформированному на языке SQL и выдаваемому при обработке каждой производственной ситуации.
После
проведения процедур формирования
функций сходства для каждой из указанных
групп характеристик выбирается метрика,
определяющая расстояние между отдельными
производственными ситуациями. Функции
![]() j
= 1, ..., 4 используются
в составе метрики ps,
задающей расстояние
между характеристиками S1(t),
S2(t)
в пространстве
производственных ситуаций. Следует
обратить внимание на то, что при t
= const
метрика ps(S1(t),
S2(t))
должна быть действительной
числовой функцией, для которой выполняются
известные аксиомы метрики. В качестве
функции, заведомо обладающей данными
свойствами, выбрано евклидово расстояние,
определяемое по формуле
j
= 1, ..., 4 используются
в составе метрики ps,
задающей расстояние
между характеристиками S1(t),
S2(t)
в пространстве
производственных ситуаций. Следует
обратить внимание на то, что при t
= const
метрика ps(S1(t),
S2(t))
должна быть действительной
числовой функцией, для которой выполняются
известные аксиомы метрики. В качестве
функции, заведомо обладающей данными
свойствами, выбрано евклидово расстояние,
определяемое по формуле
![]()
На основе предложенной методики определения расстояния между различными производственными ситуациями, возникающими в процессе функционирования объекта управления, реализованы новые алгоритмы оперативного поиска мультилингвистических данных и документов, которые будут представлены далее.