

4.3. Методология plsa в области
Извлечения информации
Как мы уже отмечали выше, индивидуализация, или персонализация, интерфейса пользователя благодаря алгоритмам его идентификации позво-ляет учитывать неявные интересы АПР и использовать их в контекстетекущего запроса. Тем самым еще на стадии обработки результатов запроса отсеивается большая часть нерелевантных документов.
В настоящее время применение моделей пользователя в адаптивных гипермедиасистемах вызывает большой интерес исследователей. Однако пока еще не предложено эффективных моделей, позволяющих описывать пользователя в режиме реального времени, а тем более производить корректировку модели в соответствии с новой информацией или изменением состояния окружения АГС.
Любая адаптивная гипермедиасистема это прежде всего информационная система, т. е. система, представляющая информацию по некоторой предметной области в удобном для пользователя виде. Удобство представления обеспечивается введением в узлы АГС ссылок и, наряду с текстовой информацией, мультимедиаэлементов. В гипермедиасистемах выделяют два основных способа поиска информации: во-первых, это навигацияпо ссылкам, т. е. перемещение от одного узла системы к другому; во-вторых,это поисковые запросы, т. е. описание необходимой информации в виде строки запроса и активация механизма поиска. В этом случае в ответ на запрос может быть выдана совокупность страниц.
Далее мы будем рассматривать алгоритм непрерывной корректировки модели пользователя на основе текущих запросов в соответствии с методологией вероятностного латентно-семантического анализа (ProbabilisticLatentSemanticAnalysis, PLSA) [42].
Один из распространенных подходов к представлению документов (и запросов) при извлечении информации из Интернета основан на понятии модели векторного гиперпространства [57], которое при использовании методологии латентной семантической индексации заменяется представлением документа в латентном пространстве меньшей размерности [29].
Расширим понятие латентного семантического пространства с учетом текущих интересов пользователя, изменяющихся со временем, для чего должна быть предусмотрена возможность уменьшения или увеличения важности этих интересов. Введем понятие временного измерения в латентном семантическом пространстве и назовем результирующее пространство временны́м латентным семантическим пространством. Это пространство служит для отслеживания динамики изменения интересов (профиля) пользователя с течением времени. Координаты документа и запроса в новом латентном семантическом пространстве рассчитываются аналогично схеме, предложенной Т. Хофманом в работе [92]. Отличие заключается лишь в том, что запросы имеют временное измерение (текущий вес), начальное значение которого задается положительными величинами, убывающими с течением времени.
4.3.1. Частотная терминологическая модель запросов лпр
В настоящее время каждый пользователь Интернета имеет доступ ко всем источникам информации, представленным в нем. Однако качество поиска информации при всей ее доступности очень низкое. В существующих поисковых системах отсутствуют эффективные алгоритмы поиска релевантной информации, т. е. набора релевантных документов, отражающих сущность запроса. И в ответ на запрос такая система может выдать сколь угодно большое количество документов, либо отдаленно отражающих сферу интересов пользователя, либо вовсе не имеющих никакой связи с сутью запроса.
Разработка алгоритмов поиска релевантной информации базируется на двух научных направлениях: традиционное лингвистическое направление, пытающееся научить компьютер естественному языку, и направление, ориентированное на применение статистических методов. При поиске информации предлагается использовать подход PLSA, относящийся ко второму направлению.
В основе PLSA, как мы уже отмечали, лежит модель векторного пространства [44; 45]. При этом любой документ представляется как вектор частот появления определенных терминов в нем. В этом подходе отношения между документами и терминами выражены в виде матрицы смежности A, элементом wij которой является частота появления термина tj в документе di.
Обозначим через m количество проиндексированных терминов в коллекциидокументовd, а черезn– количество самих документов. В общем случае элементомwijматрицыAявляется некоторый вес, поставленный в соответствие паре «документ–термин» (di,tj). После того как все веса заданы, матрицаAстановится отображением коллекции документов в векторном гиперпространстве. Таким образом, каждый документ можно представить как вектор весов терминов:
A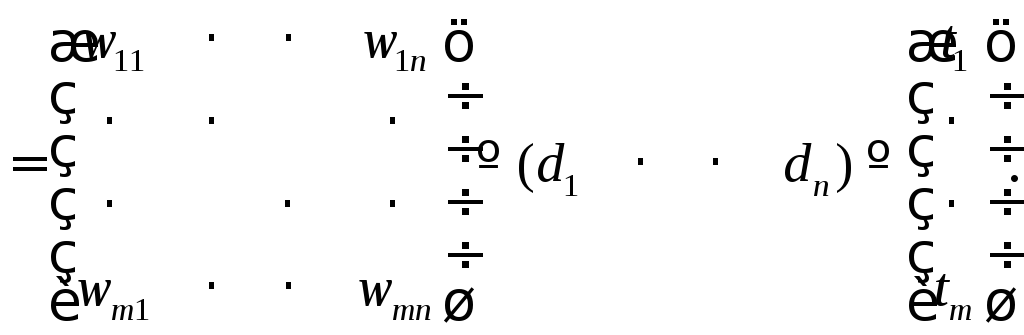 (4.1)
(4.1)
Методология PLSA основана на идее, предложенной в LSA (см. п. 3.2.3) и расширенной следующим образом. В PLSA на латентном семантическом пространстве вводится понятие латентного класса
z Z =z1, …,zk,
а также рассматриваются условные вероятности среди документов
d D =d1, …,dk
и терминов
w W =w1, …, wk.
Далее предположим, что распределение слов, принадлежащих данному классу, не зависит от документа и пары наблюдений «документ–термин» (d,w) независимы.
Распределение терминов в документе P(w | d) определяется выпуклойкомбинацией факторов P(w | z) и P(z | d) и записывается следующим образом:
![]() (4.2)
(4.2)
Совместная вероятность документа и термина рассчитывается по соотношению
![]() (4.3)
(4.3)
Используя алгоритм максимизации математического ожидания (Expectation-Maximization (EM) Algorithm), который состоит из двух этапов: Е и М, оценим вероятности P(w | z) иP(z | d),максимизируя логарифми-ческуюфункцию правдоподобия:
![]() (4.4)
(4.4)
где n(d,w) – частота термина в документе, т. е. количество появлений терминаwв документеd.
Вероятность того, что появление термина wв документеdобъясняется принадлежностью их к классуz, на этапе E оценивается как
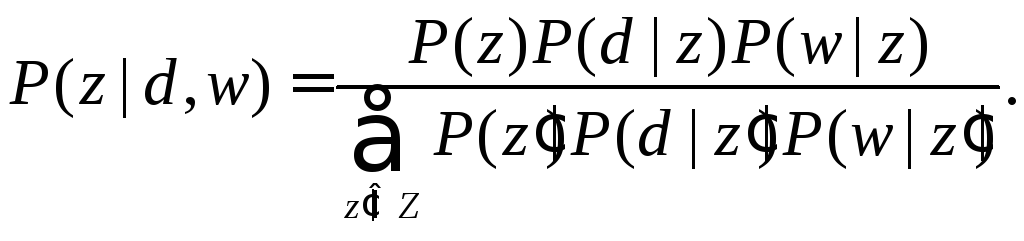 (4.5)
(4.5)
На этапе М происходит переоценка вероятностей:
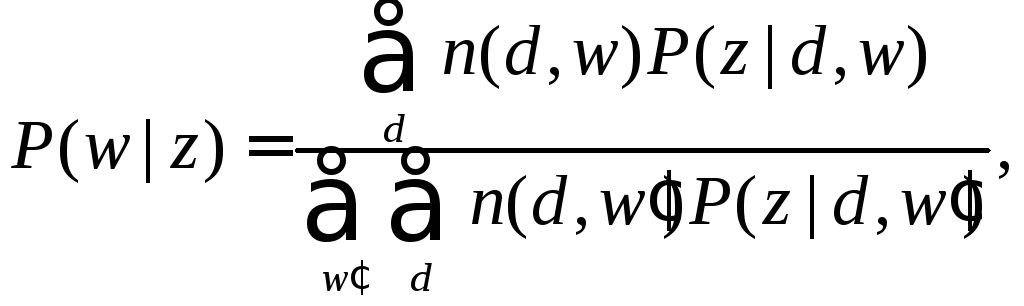
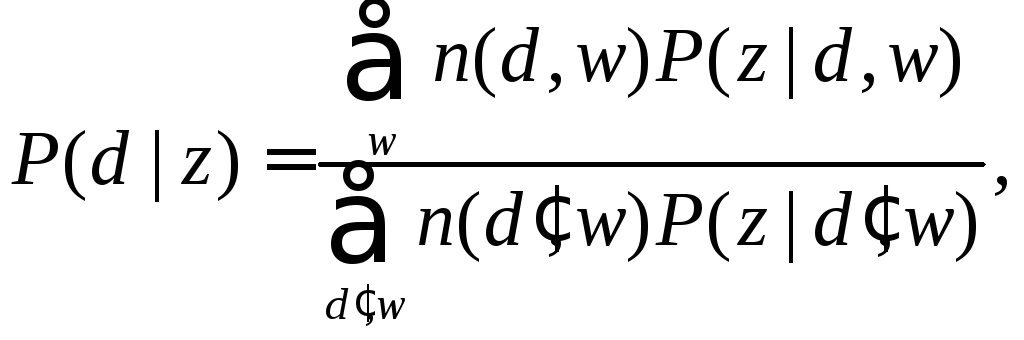 (4.6)
(4.6)
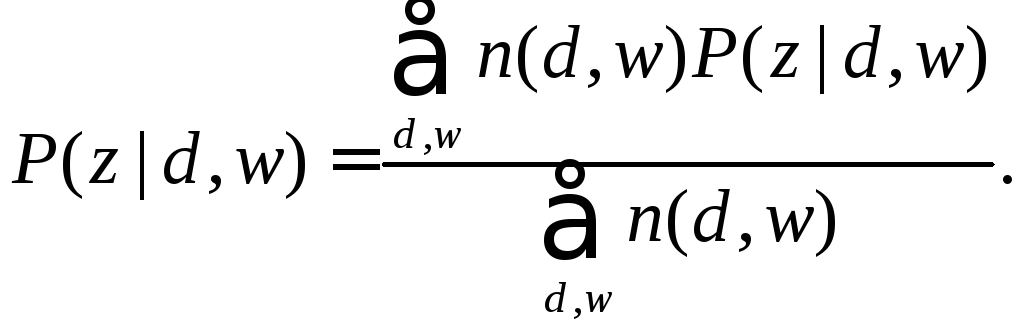
В работе [101] Т. Хофман предложил обобщенную модель для оценивания условной вероятности, которую он назвал ослабленной процедурой максимизации математического ожидания (Tempered ExpectationMaximization, TEM).
В этой модели на этапе E в оценку условной вероятности вносится регуляризационный параметр :
 (4.7)
(4.7)
Согласно (4.2) любая условная вероятность P(w | d) может быть аппро-ксимирована полиномом, представляющим собой выпуклую комбинацию условных вероятностей P(w | z). Весовые коэффициенты P(z | d) геометрически могут быть интерпретированы как координаты документа в подпространстве, определяемом как латентное семантическое пространство [91].
Именно такое пространство несет в себе основную смысловую нагрузку и формируется по близости расположения точек.