

Идеология организации без упорядоченного выполнения
В свое время узел формирования адреса был вынесен из операционного блока, с той целью, чтобы освободить основной сумматор от вычисления адресов операнда и перенести в блок выборки команд, в котором в совокупности с КЭШ памятью команд организован законченный цикл подготовки операндов к выполнению операций над ними в операционном блоке. Таким образом сформировать 2х ступенчатый конвейер в процессоре.
Идеология без упорядоченного выполнения основана на предварительном анализе команд по возникновению конфликтов при их выполнении, задержки их выпуска по конвейер и пропуска внеочередных команд, которые могут быть беспрепятственно выполнены. Конфликты эти относятся в первую очередь к группе конфликтов по данным. Конфликты эти классифицируются по типу RAW и WAR, WAW.
Первоначально анализ возможного возникновения этих конфликтов проводился на стадии декодирования и вычисления операндов, в дальнейшем для реализации без упорядоченного выполнения формирование адресов операндов выделили в отдельную стадию конвейера с той целью, чтобы дать возможность пропускать на конвейер внеочередные команды, не вызывающие конфликты WAW и RAW, и не блокировать конвейер на первой стадии . Таким образом, стадия декодирования была разбита на два такта:
Такт выдачи
Такт чтения операндов
Такт выдачи стал контролировать ситуацию использования регистра результата в команде, предыдущими командами в качестве регистра результата (WAW – запись после записи) с целью избежать искажения при предыдущих команд. Если такая ситуация могла иметь место, то команда не выпускала на конвейер.
На этапе чтения операндов анализировать стали возможность возникновения RAW при выпуске команды на конвейер, т.е. операнды источники проходят проверку не являются ли они регистрами результата предыдущих команд, находящихся в стадии выполнения или в данный момент не происходит ли запись из функционального устройства по адресу источника в команде.
В связи с без упорядоченным выполнением, завершающую стадию конвейера, связанную с записью результата в регистровый файл, пришлось разделить на 2 части.
Это первая предварительная - стадия завершение.
Вторая – запись результата.
На этапе запись результата блок управления конвейером отслеживает возможность возникновения конфликтов типа WAR для того, чтобы исключить искажение значений в регистрах, используемых в качестве источников предыдущими командами, находящимися на стадии выполнения.
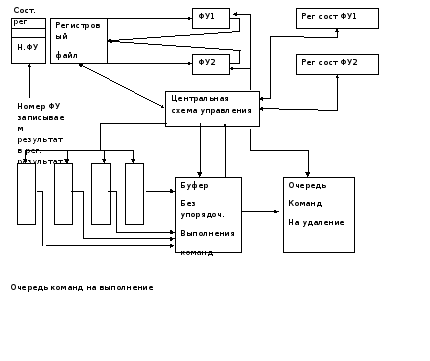
Как следует из представленной блок–схемы, централизованная схема управления осуществляет контроль за приемом команд во входную очередь, загружая их в буфер без упорядоченного выполнения. При готовности операндов и наличии свободных функциональных устройств централизованная схема управления передает команды им на выполнение и по завершении передает их в очередь команд на удаление ,соблюдая последовательность программного кода.
Алгоритм Томасуло
С одной стороны выделение чтения операндов в отдельную стадию конвейера наводит на мысль о возможности размещения узла формирования адресов операндов в глубину конвейера с целью его параллельной работы с другими функциональными блоками операционного устройства. В этом случае отпадает необходимость в начале конвейера держать буфер для команд ,ожидающих выполнения только при одном условии, если будут отсутствовать в системе конфликты RAW, которые контролирует эта стадия.
Одним из способов устранения конфликтов типа RAW-это наличие обходных цепей, когда результат сумматора передается на один из его входов в случае использования его в качестве источника в следующей команде. В этом случае в регистровом файле просто будут отсутствовать источники, которые могут быть прочитаны раньше чем попадет в них конечный результат, потому что все результаты ,которые будут использованы в следующей команде в качестве источника просто не будут записываться в регистровый файл. Следовательно, при использовании технологии без упорядоченного выполнения можно воспользоваться методом обходных цепей.
И так целесообразность перемещения узла чтения операндов в глубь конвейера будет только в том случае, если операционное устройство, имея блочную структуру, будет иметь для каждого функционального узла буфер команд, ожидающих выполнения; уже с готовыми операндами,, а блок чтения операндов имея свой буфер с адресами для операндов будет поставщиком операндов в эти функционального устройства.
Это во-первых, а во-вторых и основное промежуточные результат вычислений не будет передаваться в регистровый файл, а будет перемещаться из одного функционального устройства в другое или же в свое во входную очередь подобно архитектуре обходных цепей в сумматоре, а запись результата выполнения операции будет производиться только при завершении всех предыдущих команд при отсутствии конфликтов WAR, подобно как это делается при централизованном управлении при заключительной стадии конвейера «Запись результата».
Конфликты WAW, отслеживаемые при централизованном управлении просто будут отсутствовать, так как будет исключена ситуация циклов ранней преждевременной записи в регистровый файл в силу логики работы распределенных схем контроля за конфликтами.
Конфликты RAW при распределенной схеме управления конвейером не будут возникать же из-за того, что все циклы чтения промежуточных результатов из регистрового файла просто отсутствует, так как эти результаты будут подаваться непосредственно на исполнительное устройство из других функциональных блоков. .
Без обходных цепей в сумматоре … … С обходными цепями в сумматоре
ADD R1R2R3 ID EX WB ID EX
S
 UB
R4R1R3
ID EX WB
ID EX WB
UB
R4R1R3
ID EX WB
ID EX WB
Невозможна одновременная запись и чтение в R1
конфликт просто не возникает т.к. результат ADD поступает на вход сумматоре для вычитания.
… ….
Вышеописанная технология реализует алгоритм Томасуло, основные принципы которого мы и отметим.
Но прежде чем сформулировать эти принципы рассмотрим еще способ устранения конфликтов типа WAR на конвейере. Таким является способ переименования регистров.
1









 .R5=R1+R2
ID
EX
W
структурный конфликт:
регистр. файл занят;
.R5=R1+R2
ID
EX
W
структурный конфликт:
регистр. файл занят;
2




 .R6=R0*R5
ID
EX
W
запись 2-ой команды
.R6=R0*R5
ID
EX
W
запись 2-ой команды
3



 .R5=R3+R4
.R5=R3+R4
регистр R5 ЗАНЯТ 2ой командой запись не возможна
4
 .R7=R0*R5
.R7=R0*R5








ID
EX
EX
W
RAW
конфликт поR5
между 1и 2 командами








 ID
EX
EX
W
RAW
R5
занят 3ей
командой
ID
EX
EX
W
RAW
R5
занят 3ей
командой


 5.R5=R1+R2
5.R5=R1+R2
6

 .R6=R0*R5
IDEX
W
как видно из примера
переименование регистров
.R6=R0*R5
IDEX
W
как видно из примера
переименование регистров
7 .S1=R3+R4
ID
EX
W
увеличивает производительность
работы конвейера
.S1=R3+R4
ID
EX
W
увеличивает производительность
работы конвейера
8

 .R7=R0*S1
.R7=R0*S1


 ID
EX EX W
ID
EX EX W


 ID
EX
EX
W
ID
EX
EX
W
Метод переименования регистров (пример)
Предположим, что необходимо вычисление (¬x + ¬y)c
¬x = ix1 + jy2; ¬x + ¬y=i(x1+x2) + j(y1+y2)
¬y=ix2 + jy2; c(¬x + ¬y)=ic(x1+x2) + c(y1+y2)j
Т.е. значение координаты нового вектора: c(x1+x2), c(y1+y2) которые будут помещены в регистровый файл.
Данные вычисления будут производиться на суперскалярном процессоре имеющего 2 конвейера: конвейер с фиксированной точкой (операции сложения) и конвейер умножения (множительное устройство)
Программа для выполнения:
ADD R5=R1+R2
MUL R6=R0*R5
ADD R5=R3+R4
MUL R7=R0*R5
Общая схема:
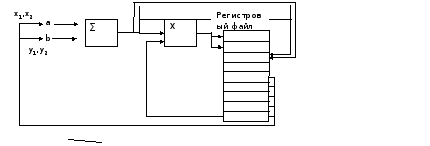
Анализ работы суперскалярного процессора с использованием переименования регистров показывает, что возможно окончание выполнения команд не в том порядке, как они расположены в программном коде т.е. на лицо внеочередное выполнение команд.
Для организации выдачи результатов в порядке определяющем программным кодом необходимо сохранять содержимое временных регистров до того времени, когда вся предыдущая команда закончит выполнение и будут удалены из конвейера. В течении времени пока временный регистр содержит данные он используется последующими командами как источник. Т.е. отсюда вывод: при суперскалярной архитектуре использование временных регистров необходим блок выходной очереди команд, который будет контролировать окончание выполнения команд в двух фазах:
Завершение
Запись результата
Удаляя с конвейера те команды, которые будут иметь статус второй фазы.
КОНВЕЙЕР очередь
завершенных команд Очередь
команд на удаление с конвейра
Р.Ф.
Входной поток
команд






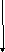







…
памяти
КОНВЕЙЕР
Одной из проблем без упорядоченного выполнения является ситуация возникающая при обработке прерываний, когда необходимо восстановить состояние процессора до начала выполнения команды, вызвавшей прерывание.
При последовательном выполнении команды этой ситуации не возникает, а так при без упорядоченном выполнении возможно окончание последующих, ранее предыдущих, а при выполнении предыдущих могут возникнуть прерывания, а исходные данные последующих может быть уже нельзя восстановить, вот тогда и возникает ситуация выход из которой можно найти
А) сохранение исходных данных команд, находящихся в буферах исполнительных устройств и всех команд в буфере очередности, контролирующего последовательность выполнения программного кода, имеющих статус “‘ завершение”.
Если возникнет прерывание, то состояние машины можно будет восстановить до точки предшествующей всем командам выполненным вне очереди
Б) сохранение всех результатов в буфере, который хранит новые значения всех команд, находящихся в состоянии “завершение”
В) выдавать команды на этап запись результата” ,если известно что все предыдущие команды выполнены без прерываний или, что ни одна из предыдущих команд не будет завершена пока не будет обработано прерывание.
Г) Хранить все адреса команд и сами команды, находящиеся на не выполнении в конвейере.
Предпосылки для внедрения технологии предсказания переходов
Безупорядоченное выполнение и механизм обработки прерываний в процессоре в этом случае, который восстанавливает состояние процессора после не одной, а возможно нескольких выполненных команд, наводит на мысль об использовании технологии предсказания переходов. Направлять поток выполненных команд на основе предсказаний, а в случае ошибки восстанавливать состояние процессора и начинать выполнение программы по адресу, сохраненному в процессоре, в случае ложного предсказания. Точно также как это осуществлялось при обработке прерывания, только вместо адреса перехода по прерыванию, используется адрес, по которому должно переходить выполнение программы в случае ложного предсказания. Но реализация идеи выполнения команд по предположению, так же как и без упорядоченное выполнение, требует внедрения дополнительных аппаратных средств в архитектуру, процессора и это в первую очередь будет буфер переупорядочивания,, который представляет дополнительные виртуальные ресурсы как и станция резервирования в алгоритме Томасуло. Буфер хранит промежуточные результаты от момента завершения операции до ее стадии “запись результата”.
Буфер является источником операндов для команд, точно так же как станция резервирования, обеспечивающая промежуточное хранение и передачу операндов в алгоритме Томасуло. После того как команда в алгоритме Томасуло записала результат в регистровый файл, он становится доступным для других команд. В случае выполнения команд с использованием механизма предсказания адреса перехода, запись в регистровый файл, производится только после получения результата условия, по которому должен быть произведен переход в программе. Только после этого все команды, следующие за командой перехода получают статус”запись результата” . Вот поэтому каждая команда имеет позицию в буфере переупорядочивания до тех пор пока она не получит статус “запись результата”., Результат помечается номером строки в буфере, а не номером станции резервирования. Вот почему станции резервирования ,получая данные из буфера, обязаны отслеживать номер строки, чтобы отправить результат операции в строку буфера из которого были получены исходные данные.
Заключение:
Блок операций в ЭВМ первых поколений, представляющий собой многофункциональное устройство все виды арифметических операций выполнял, используя операцию сложения и сдвиговые операции. С внедрением интегральных микросхем в элементную базу стали применять табличные методы, используя для этого специальные микросхемы ППЗУ, что значительно позволило сократить время выполнения операций умножения и деления в операционном блоке. С внедрением конвейерной обработки команд операционный блок стал представлять собой набор функциональных блоков, каждый из которых выполнял только ограниченный набор арифметических операций. Такая архитектура давала возможность в процессоре выполнение нескольких операций одновременно. Конвейерная обработка команд позволила значительно повысить производительность системы, но при этом перед разработчиками ЭВМ возникли новые проблемы, связанные с появлением конфликтов при обработке команд, которые стали причиной задержек в работе конвейера. Для того чтобы их устранить или уменьшить их влияние на функционирование конвейера, пришлось вводить дополнительные аппаратные средства в архитектуру процессора.
Один вид конфликтов (WAR) когда адрес регистра результата в команде используется как адрес источника в предыдущей был разрешен с помощью метода переименования регистров, суть которого заключалась в том , что при обнаружении вышеупомянутой ситуации запись результата в команде стали производить в альтернативный регистр, выполняющего функцию клона программного регистра, указанного в команде, чтобы не дожидаться выполнения предыдущей команды и не исказить ее результат. При удалении команды с конвейера данные из регистра-клона записывались в программный регистр, указанный в команде. Эта технология дала возможность увеличить производительность работы конвейера реализующего безупорядочное выполнение команд в процессоре. Без этого метода на конвейер выпускались вне очереди только те команды, которые не конфликтовали с предыдущими ни по адресам как источников в них так и по адресам записи результатов.
Другой тип конфликта(RAW) на конвейере стал возникать, когда очередная команда, поступающая на конвейер, должна дожидаться результата в предыдущей, потому что один из ее адресов источников имел то же значение что адрес регистра результата в предыдущей команде. Конфликт этот устранить нельзя, но время потерь сократить можно, подавая значение результата в операционное устройство, не записывая предварительно его в регистр результата.
Конфликт(WAW), появился в следствии безупорядочного выполнения команд на конвейере, когда результат последующей команды формируется раньше предыдущей. При использовании метода переименования регистров значение в регистре-клоне используется в промежуточных вычислениях, пока команда не удалена с конвейера. Команда может быть удалена с конвейера только в том случае, если все предыдущие выполнены и удалены с конвейера при этом предварительно производиться запись из регистра-клона в в программный регистр. Аппаратные издержки от этого конфликта заключаются в том ,что приходиться иметь буфер для команд, ожидающих выполнения всех предыдущих и дополнительные схемы контроля за состоянием фаз выполняемых на конвейере команд.
Для устранения конфликтов по управлению используются аппаратные средства блока предсказания переходов. Если при последовательном выполнении команд адрес очередного блока команд, загружаемого из памяти кэш команд или из памяти высшего уровня формируется с опережением то есть увеличением значения текущего адреса команды на величину длины блока команд, уже находящихся в буферных регистрах блока выборки команд, то при конвейерной обработке, чтобы сократить время простоя конвейера из-за конфликтов по управлению, связанных с выполнением команд переходов, адрес очередного блока команд, загружаемого из вышестоящего уровня памяти целесообразней формировать по значению адреса, указанного в команде перехода или следующего за ней на основании информации, собранной о переходах в предыдущих выполненных уже командах управления.
,
Алгоритм Томасуло
Основной идеей алгоритма Томасуло являлся отказ от централизованного управления функциональными устройствами с точки зрения связи с регистровым файлом на промежуточном этапе выполнения. Отказ от записи промежуточных результатов в регистровый файл т.е. тех, которые будут использованы в следующих командах, следовательно исключить конфликты типа RAW, и WAR, используя для этого во-первых, переименование регистров, во-вторых, станции резервирования.
Станции резервирования представляют ячейки буферной памяти типа FIFO. Для каждого функционального устройства структура каждой станции состоит из информационной части и теговой.
Информационная часть содержит операнды, поступающие на обработку из:
А) регистрового файла
Б)из функционального устройства как и промежуточный результат
В) Из оперативной памяти
Теговая часть каждой строки в буфере памяти содержит 6 полей:
Поле операции
Поля, указывающие станции резервирования, которые будут вырабатывать соответствующие операнды источники, нулевые значения этих полей указывают, что операнды уже находятся в полях значения операндов.
Поле операнда
Номер станции резервирования
Номер станции резервирования
Значение 1го операнда
Значение второго операнда
Занято
Откуда должны подавать первый операнд
Откуда должен поступать второй операнд
2 поля операндов источника
Поле занято, указывает, что данная станция резервирования и соответствующее ей устройство заняты.
Регистровый файл и буфер записи имеют поле в котором указано функциональное устройство, которое будет вырабатывать значения для записи в регистр или память. Буфер записи имеют поле для записи значения операнда в память.
Аппаратура, реализующая алгоритм Томасуло, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо, как было отмечено выше, ввести фазу фиксации результата и фазу записи результата. Добавление к последовательности выполнения команды фазы фиксации требует сохранение всех команд закончивших выполнение и их результатов до момента пока не сформируется признак, по которому должен быть произведен переход. Вот почему без упорядоченное выполнение команд и механизм предсказания требуют одних и тех же аппаратных средств- дополнительного набора аппаратных буферов, которые хранят результаты команд, закончивших выполнение но еще не записавших результат в память или в регистровый файл.
Каждая теговая строка в буфере содержит 4 поля
Поле типа команды
Поле места назначения, по которому будет отправлен результат выполнения команды
Поле значения
Поле состояния команды(микрооперации)
Поле типа команды определяет является ли команда перехода, командой записи в память, или регистровый файл.
Поскольку каждая команда имеет позицию в буфере, до тех пор, пока она не будет зафиксирована и результат не будет отправлен в регистровый файл, результат выполнения команды хранится в строке с той же позицией. Все это время позиция строки, то есть ее адрес ,будет являться ссылкой для всех команд , использующих ее результат в свих операциях.
При выполнении по предположению запись в регистровый файл не производится до тех пор пока команда не не получит статус “запись результата”
Большое преимущество схемы Томасуло заключается в распределении логики обнаружения конфликтов и устранение приостановок ,связанных с конфликтами WAW и WAR. Это преимущество возникает из-за наличия станций резервирования, которые хранят промежуточные результаты вычислений и общей магистральной шины результата ,которая дает возможность одновременной загрузки результата в несколько станций в случае необходимости , таким образом давая возможность поступления нескольких команд, ожидающих этот результат, на выполнение из входной очереди в функциональные устройства в одном такте конвейера при условии ,что каждая станция резервирования имеет свою магистраль , связанную с входной очередью. Одновременное начало выполнения команд, ожидающих данные с магистрали результата, в функциональных устройствах возможно и при наличии одной магистрали загрузки команд из входной очереди ,если эти команды уже находятся в станциях резервирования функциональных устройств.
Впервые данная схема была предложена Томасуло при проектировании устройства с плавающей точкой. В дальнейшем его идея бала использована во многих архитектурах процессоров и стала базовой при проектировании в них блоков операций. Достаточно для этого привести пример архитектуры процессоров линейки Pentium на основе базовой модели P6. Именно в этой модели были использованы функциональные устройства с использованием станций резервирования, технологии безупорядочного выполнения микроинструкций, переименования регистров и предсказания переходов.
ЛекцияN8
Архитектура современных процессоров.
Анализ архитектуры современных суперскалярных процессоров показывает, что независимо от их аппаратной реализации базируются на общих архитектурных решениях.
1.Современный суперскалярный процессор имеет модифицированную гарвардскую архитектуру с конвейерной организацией выполнения команд.
2. Для устранения конфликтов, возникающих при выполнении команд на конвейере , используются общепринятые меры по их устранению:
- для устранения конфликтов по управлению, связанными с выполнением команд условных переходов в архитектуру процессора введен блок предсказания переходов. Который совместно с другими источниками в процессоре, формирующими адреса инструкций для выборки из кэш инструкций участвует в формировании окончательного значения адреса на приоритетной основе запросов, поступающих в устройство формирования следующего адреса для выборки очередного блока инструкций из кэш от всех источников, формирующих адреса инструкций.
- для устранения конфликтов в процессоре с без упорядочным выполнением используется технология переименования регистров на время выполнения команд в процессоре. Каждому программному регистру, являющимся регистром для записи результата в команде, в регистровом файле назначается группа альтернативных регистров, невидимых системе, в которые записываются промежуточные результаты и эти регистры являются источниками данных для команд, следующими за командами ,в которых была проведена операция переименования.
- все современные суперскалярные процессоры имеют распределенную схему управления, которая впервые была предложена и применена для выполнения операций с плавающей точкой в соответствии с алгоритмом Тумасулло. Данная архитектура дает возможность промежуточные результаты ,mполученные в одном операционном блоке направлять в случае необходимости в другой операционный блок без записи в регистровый файл или хранить в промежуточном буфере не завершенных команд и производить их запись только при условии выполнения предыдущих команд. Для этого пришлось поток команд на конвейере разбивать на группы и каждую команду сопровождать тегом, указывающим на принадлежность к группе.
-Операционные устройства в процессоре представлены набором независимых функциональных устройств, выполняющих определенный для них перечень операций. Эти устройства на входах имеют буферные памяти для приема команд из потока декодированных инструкций в соответствии с кодами операций для выполнения которых они предназначены, образуя таким образом входные очереди для выполнения.
В качестве примеров рассмотрим архитектуры процессоров линейки PentiumфирмыINTEL, процессоровPower, процессоровZ990,Z10Zархитектуры фирмыIBM. Выбор обусловлен тем, что в них прослеживаются все этапы исторического развития архитектуры процессоров.
Появлению линейки процессоров предшествовала линейка процессоров х86,которая объединила процессоры первых четырех поколений и начала старт с процессора 8086, задавшего основу направлений архитектур последующих процессоров, архитектура которого используется в простейших микроконтроллеров в настоящее время. Линейка процессоров х86 разрабатывалась с учетом использования их в системах с шинной организацией, и первый процессор 8086 был 16- разрядный и имел 20ти-разрядную адресную шину. Выбор шинной организации связи процессора с другими компонентами системы был обусловлен назначением процессора в микро эвм и персональных компьютерах. Внедрение технологии сегментной адресации при обращении к оперативной памяти стало основой в дальнейшем для внедрения режима виртуальной памяти и механизма защиты, необходимого для поддержки многопрограммного режима в последующих модификациях не только этой линейки, но и линейки Pentium. Последней модификацией линейки х86,стал процессор 486,который по своим функциональным возможностям сопоставим с майнфреймами средней производительности. По своей архитектуре этот процессор был близок к модифицируемой гарвардской архитектуре, имел встроенную кэш память команд и данных, конвейер для обработки команд и отдельно встроенное устройство для обработки команд арифметических операций с плавающей точкой. Был разработан с учетом использования в многопроцессорных системах. Для реализации конвейерной обработки пришлось внедрить сложную систему декодирования инструкций, так как система команд, используемая в линейке процессоров, имелаCISCархитектуру, которая и потребовала введение дополнительных аппаратных средств для ее обработки.
Эстафету линейки процессоров х86 приняла линейка Pentium. Первым процессором в этой линейке стал процессорPentium,который был первым суперскалярным процессором, в составе было два конвейера, один из которых был универсальным, выполняющим любую инструкцию из системы команд ,а другой с ограниченными возможностями. Процессор имел блок предсказания переходов и операционный блок для выполнения инструкций классаSIMD. ПроцессорыPentium2,3 были спроектированы на базовой архитектуре процессораPentiumPro, в котором была реализована технология безупорядочного выполнения команд. Наличие операционных устройств с конвейерной организацией и буферных памятей для приема команд на исполнение, аппаратная реализация системы распределения команд в функциональные устройства в соответствии с кодами операций, наличие буферной памяти для хранения команд, ожидающих выполнения и диспетчеризации , а также буферной памяти для хранения команд выполненных ,но не имеющих признак завершения- все эти аппаратные средства обеспечивали технологию безупоряочного выполнения команд в процессоре. В этих процессорах была внедрена технология предсказания переходов и выполнение по- предложению ,то есть выполнение инструкций по направлению, выбранным блоком предсказания переходов не дожидаясь результата, полученного по окончанию выполнения команды перехода.
Особое внимание заслуживает архитектура Pentium4, в котором для выполнения команд используется кэш трасс, формируемая предварительно после загрузки инструкций в кэшL2 и с окончательной коррекцией во время выполнения в процессоре. Большинство процессоров этой линейки поддерживают мультипроцессорный режим работы.
Начало разработки линейки процессоров PowerфирмыIBMбыло положено в 1990 году. Процессоры этой серии относятся к классуRISCпроцессоров, предназначенных для конвейерной обработки команд. В предлагаемых к рассмотрению архитектурах процессоровPower4,5,6 реализованы все технологии конвейерной обработки команд, а в процессорахPower5 и 6 имеется аппаратная поддержка многопоточного режима и организации логических партиций на уровне операционной системы. Мы уже отмечали ,что во всех суперскалярных процессорах проводится на этапе декодирования инструкций формирование групп команд с целью контроля за выполнением команд на конвейере. Так вот архитектураPower6 интересна тем, что эта процедура вынесена за пределы конвейера и выполняется после загрузки команд в кэшL2 подобно тому, как вPentium4 формируется предварительно кэш трасс. Линейка процессоровPower(Power4,5,6) поддерживает организацию мультипроцессорного режима, используя для этого непосредственные связи между процессорами, технологию характерную для процессоров фирмыIBM, при организации узловSMP, а для объединения узлов в большие многопроцессорные системы используются как магистрали, так и технология непосредственных связей. ПроцессораZ990 иZ10 являются представителямиZархитектуры, которая стала дальнейшим развитием архитектуры майнфреймовIBM360 И 370. Процессора этого класса относятся кCISCпроцессорам, получившим в наследство систему команд от майнфреймовIBM360 и 370. Так процессораZ990 иZ10 по этой причине, чтобы не усложнять структуру конвейера не используют безупорядочное выполнение команд. В процессореZ10 используется конвейер с большим количеством ступеней, что дало возможность повысить частоту работы процессора до 4,4 ггц по сравнению с частотой процессораZ9,имеющего рабочую частоту 1,9ггц. Еще одной особенностью этой линейки процессоров является наличие совершенной системы контроля ,восстановления и диагностики на микроархитектурном уровне. ПроцессораZархитектуры используют технологию непосредственных связей с другими объектами системы, а для контроля за состоянием системы и сбора информации о состоянии процессора и выполнения процедур диагностики разработана система управления, реализуемая в сервисном процессоре, который имеет доступ ко всем основным узлам не только в процессоре ,но и ко всем другим объектам в компьютере, используя для этого внутреннюю сеть.
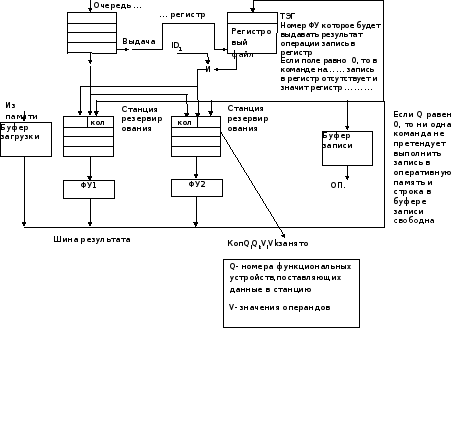
Архитектура процессора Pentium Pro
(PentiumPro) ставший в свое время базовой для процессоровPentium2 и 3. Микроархитектура этого процессора содержит аппаратные средства, обеспечивающие конвейерную обработку команд и всех ситуаций, возникающих при этом, ранее нами рассмотренных аппаратными средствами.
Как видно из блок схемы процессор содержит 3 отдельных независимых функциональных блока, обеспечивающих 3х фазную обработку команд.
А) выборка
Б) выполнение
В) завершение
Эта классическая структура применялась и ранее в предыдущих поколениях различных микроархитектур, с той лишь разницей, что для CISCмоделей эти функциональные блоки были связаны воедино во время выполнения отдельной команды. Наличие кэш команд и данных 1 ого уровня является признаком модифицированной Гарвардской архитектуры, обеспечивающей совмещение выполнения выборки очередной командыcвыполнением предыдущей. Эта технология была использована и ранее, к примеру, в наших отечественных моделях (ЕС 1045 и др.).
Микроархитектура блока декодирования имеет классические элементы, присущие любой системе, будь то жесткая логика или микропрограммное управление и предназначены для дешифрации команд и задания алгоритма обработки команд в процессоре. Но с другой стороны каждый блок имеет свои особенности, связанные со структурой и форматами команд, поступающих на обработку. Так в рассматриваемой архитектуре . команды имеют сложную структуру, которые разрабатывались без учета конвейерной обработки еще в предыдущих моделях (CISC).
Поэтому для сохранения преемственности программного обеспечения пришлось разрабатывать сложные декодеры, преобразующие СISCкоманды в набор микроопераций, представляющих по сутиRISCкоманды. Для решения этой задачи пришлось разрабатывать достаточно сложные декодеры и организовывать многостадийный конвейер в рамках блока. Как мы уже говорили ранее, что формат команд, используемых в микропроцессорах класса х86 и в последующих разработках на базовой моделиP6,
кроме поля кода операции имеет поле байта-модификатора в которых содержится вся информация о структуре команды, ее длине и способах адресации операндов, которая и служит исходной информацией для разработки аппаратных средств декодеров..
По сути, о чем мы сейчас говорили это классическая функция блока декодирования по преобразованию команды в набор микроопераций. Тогда же в чем же особенность?
А особенность заключается в том, что в CISCархитектурах микрооперации, выполняющиеся последовательно одна за другой функционально связаны, как и команды в программном коде, адрес текущей определяет адрес последующей. В данном же решении микрооперации выходящие из декодера сохраняются в промежуточном буфере, становясь доступными группе исполняющих устройств, для которых они предназначены независимо от принадлежности команд в программном коде.
Возникает вопрос? А как же строгая последовательность программного кода. А для этого декодер на этапе декодирования связывает в цепочку микрооперации, принадлежащие одной команде, для того чтобы в процессе выполнение команды считать выполненной, когда все микрооперации в цепочке устанавливают флаг статуса «выполненных». А так как в случае беспорядочного выполнения возможно и внеочередное выполнение команды, команда удаляется из процессора только в том случае, если предыдущие команды выполнены.
Именно чтобы обеспечить эту функцию аппаратными средствами используется буфер микроопераций, в котором микрооперации записываются и удаляются в строгой последовательности согласно программному коду.
Как видно из блок схемы буфер микроопераций (пул микроопераций) является связывающим звеном между тремя основными блоками в процессоре. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперации ожидающие выполнения, а также те, Которые уже выполнены, но не получили статус удаления из буфера «фиксация». Устройство диспетчера может выбирать для выполнения, как уже упомянуто выше, любую микрооперацию при готовности операндов и наличии свободного функционального устройства для их обработки Максимально 2 физических регистра со статусом завершения (удаления) могут быть прочитаны в каждом цикле. А теперь кратко о стадиях конвейера блока выборки декодирования. Наличие 3х стадий IF0,IF1,IF2 на этапе выборки объясняется следующими причинами.
выборка из кэш (32 байта кода программ.)
определение начала команд, их длина в области 32 байта (дешифрация кода команды и байта модификатора)
этап выравнивания. Т.к. декодеры работают с жестко распределенными полями в формате команды.
Команда, поступающая из декодирования должна быть выровнена на начало границы ввиду того, что в границах 32х байта считанных их кэш может начинаться не обязательно с 0 – ого байта.
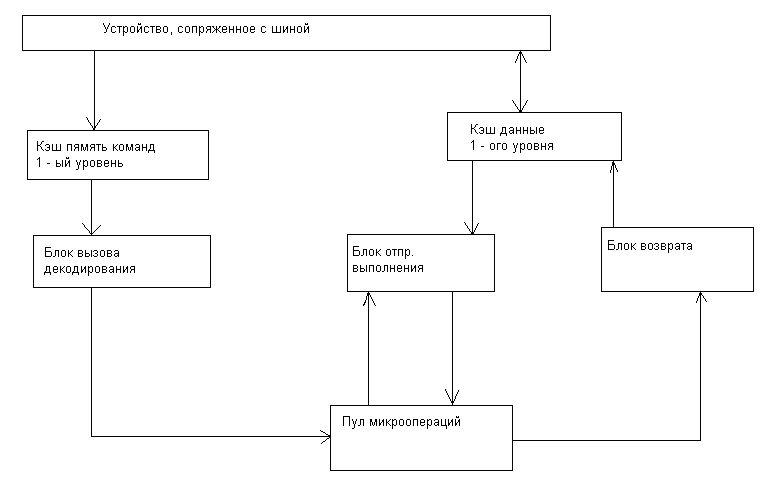
Этап декодирования включает 2 стадии: ID0,ID1.
Первая собственно предназначена для формирования форматов микроопераций.
Вторая для выстраивания очереди микроопераций.
Блок формирования очереди работает следующим образом:
Получив микрооперацию от декодера, он контролирует прием бита «завершения» из декодера в каждой следующей микрооперации и при получении его устанавливать признак конца цепочки, таким образом, связывая все микрооперации относящиеся к одной команде.
На этой же стадии конвейера получая от декодера признак команды, в случае обнаружения команды перехода формируется адрес следующей команды
с учетом, что переход назад более вероятен, чем вперед, на случай если блок предсказания не имеет другой информации о направлении перехода.
Блок декодирования имеет в своем составе 3 декодера, 2 предназначены для декодирования «простых» команд и один «сложный», декодирующий как простые, так и сложные команды. При работе декодеров имеется своя специфика. Если «сложный» декодер захватывает сложную команду, за которой следует «простые» две команды, то работают все декодера. Если же идет простых 3 команды, то 3 декодера работают одновременно и выдают в одном такте 3 микрооперации.
4 – 1 – 1 (6 микроопераций)
1 – 4 – 1 (2 микрооперации)
1 – 1 – 1 (3 микрооперации)
Этап RAT.
На этой стадии конвейера поддерживается переименование регистров (логических) программных в физические для исключения конфликтов WARиWAW. Реальные программные регистры могут быть заменены в микрооперации любым из 40 внутренних, находящиеся в буфере.
Кроме того, на этой стадии к коду микрооперации добавляется поле статуса и поле «флагов», после чего микрооперации поступают в пул микрооперации, поле микрооперации дополняется разрядами для хранения значений самих операндов.
С
сост

Устройство выборки (декодирования)
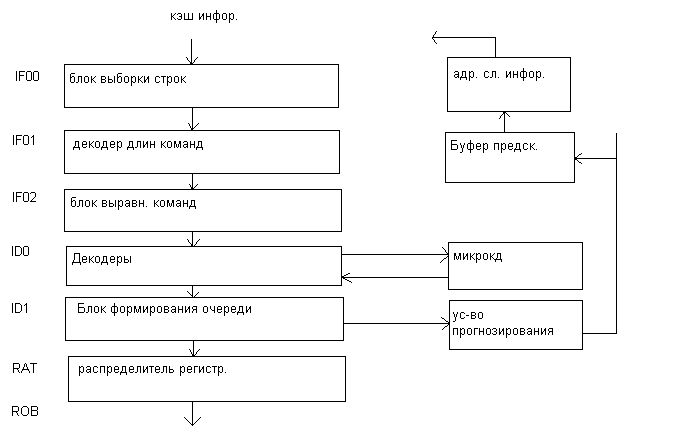

Пул инструкций.
Пул инструкций принимает поток микроопераций, определяемый программным кодом. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперацию ожидающую выполнения, а также те, которые уже выполнены, но не получили статус «фиксации». Устройство диспетчеризации может выбирать для выполнения любую микрооперацию при готовности операндов. Максимально 2 физических регистра со статусом завершения могут быть прочитаны в каждом цикле.
Устройство диспетчеризации / выполнения.
Устройство диспетчеризации / выполнения является устройством безпорядоченного выполнения, которое диспетчеризирует и выполняет согласно зависимости данных и доступности ресурсов. Выбор и диспетчеризация микроопераций из пула инструкций управляется станцией резервирования. Она постоянно сканирует пул инструкций с целью поиска микроопераций готовых для выполнения. Т.е. все источники – операнды доступны и диспетчеризация их к доступным устройствам.
Результат выполнения микрооперации возвращается в пул и хранится совместно и микрооперациями до тех пор, пока не обработаются устройством восстановления.
Процесс выполнения и диспетчеризации является классическим процессом безупорядоченного выполнения, где микрооперации обрабатываются в соответствии с готовностью данных и наличия ресурсов без учета порядка следования в программе.
Когда 2 или более микрооперации одного типа претендуют в одно и тоже время на один ресурс, они выполняются в порядке FIFOпоступления в пул.
Исполнение микрооперации осуществляется двумя целочисленными устройствами, двумя устройствами с плавающей точкой и одним устройством обращения к памяти, позволяя диспетчеризовать до 5 микроопераций за такт. Устройство формирования адресов для команд перехода промахи перехода и сигнализирует BTBпроизвести перезагрузку конвейера. Устройство связи с памятью управляет микрооперациями «Загрузка» и «Запись». Для чтения из памяти достаточно одного адреса, поэтому эта операция декодирует в одну микроперацию. Запись декодируется в 2 микрооперации (адрес/данные).
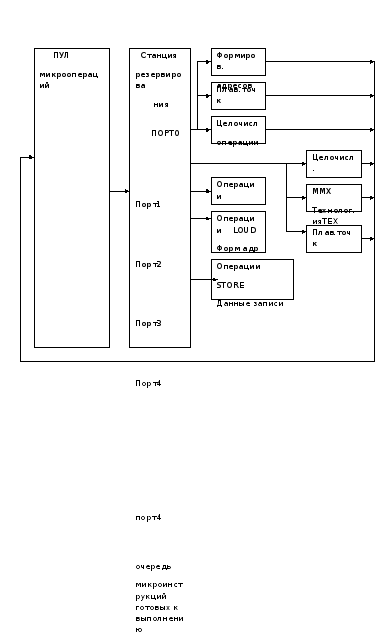
Блок обработки с изменением последовательности.
Основная задача этого блока осуществлять контроль за состоянием микрооперацией находящейся в пуле инструкций и по мере их готовности к выполнению в других устройствах помещать их для выполнения. Попав в пул, микрооперация становится доступной
Для выполнения в функциональных устройствах, о чем свидетельствует бит «готовности» в поле типов микрооперации. Длина очереди 20 элементов.
Диспетчер распределяет микрооперации по портам, которые связаны с функциональным устройством. При этом каждый порт имеет свои собственные очереди, в виде FIFO.
Некоторые функциональные устройства разделяют один порт, который является мультиплексным. Может случиться так, что в такте будет несколько микроопераций, претендующих на обработку. В этом случае вступает механизм приоритета, учитывающий «важность микрооперации» и ее момент поступления в ROB(пул инструкций). Так, например микрооперация перехода считается важнее, нежели микрооперация обработки целых чисел.
Микрооперация, попав в порт после обработки в функциональном блоке «возвращается» в пул инструкций, получая статус «выполнена». Функциональный блок должен «знать» адрес регистра в ПУЛе, значение которого должно сопровождаться инструкцией.
Т.е. являться тегом ее в процессе всей обработки. Исходя из стадий конвейера, который реализует работу блока, а их 3. Можно предположить, что:
1) ROBявляется полностью ассоциативной памятью.
2) для выдачи микроопераций в станцию резервирования в ROBучаствуют только регистры с меткой «очередь» (стадия резервации).
3) Поиск осуществляется по коду операции или нескольких их возможных значений.
4) Каждый порт для организации связи с ячейкой ROBимеет магистраль, на которую выходит регистрыROBа. Только в этом случае поиск может быть осуществлен за один такт и эти же регистры могут выдать информацию в порт в следующем такте. Для возвращения результата вROBфункциональные блоки ы также должны иметь собственные магистрали для записи результатов вROB.
Основное назначение блока восстановления.
Основное назначение блока восстановления - отправлять результаты спекулятивного выполненных микроопераций в машинные регистры, адресуемые в программном коде или в ячейки оперативной памяти. Т.е. следить за выполнением микрооперации в пулtинструкций и записывать результаты их выполнения строго согласно программному коду.
Для этого подобно станции резервирования блок восстановления постоянно контролирует состояние микрооперации в пуле инструкций, просматривая, чтобы они были выполнены и не имели бы зависимости от других микроопераций в пуле, прежде чем фиксировать их окончательные результаты в процессоре, учитывая при этом наличие прерывания исключений и условие перехода.
Устройство восстановления способно восстанавливать до 3х микроопераций в такт, после того , как результаты микрооперации зафиксировали в машинных регистрах , они удаляются из пула. Подобно блоку отправки / выполнения конвейер блока восстановления имеет 3 стадии.
Анализ выполнения операции
Запись результатов в машинные регистры
Удаление выполненных микроопераций.
Устройство сопряжения с шиной предназначено для связи процессора с кэш памятью 1 ого и 2 ого уровня и системной памятью. Связь с кэш 1-ого уровня осуществляется для кэш данных и кэш команд, осуществляя реализацию модифицированной гарвардской архитектуры. Связь с памятью 2 ого уровня осуществляется по отдельной шине 64 бит. Системная шина представляет собой группы сигналов независимых. функционально друг от друга, тем самым, обеспечивая конвейерную организацию. Для обеспечения конвейерной организации устройство шинного интерфейса содержит буфер запросов к памяти, состоящей из очередей по записи и чтению. Данный буфер обеспечивает, например выполнение запросов чтения, давая возможность «обгонять» операциям чтения, операции записи, тем самым осуществлять спекулятивное чтение данных, то есть доставляя их заранее в процессор.Следует отметить запись осуществляются только строго в программной последовательности.
С учетом безупорядоченного выполнения и чтения как следствие данного режима устройство сопряжения с шиной или «записи/чтения» должно обеспечивать следующие условия:
1) Запись никогда не выполняется спекулятивно
2) Запись выполняется только в программном порядке
3) Операции записи диспетчеризуются только когда адрес и данные доступны и нет более старшей записи, ожидающей диспетчеризации
4) Запись может быть блокирована, чтобы дать возможность ее обходить операциям чтения.
5) Возможность «спекулятивного» выполнения чтения когда более младшая операция чтения обгоняет старшиеперации чтения .
Для реализации чтения необходимо:

Для записи

В связи с этим каждому входу очереди запросов на запись соответствует
Очередь SRQ– содержит адрес записи
Очередь SDQ– содержит данные записи
Для очереди на чтение соответствующей очереди LRQ
Вход SDQсодержит результат, который должен быть записан после того, как все предыдущие микрооперации в пуле будут в фазе завершения, как только будет разрешение их удаления данные должны быть записаны в память.
Архитектура процессора Pentium4
Если кратко характеризовать архитектуру Pentium4 можно отметить следующее.
Процессор Pentium4 также как и Р6 состоит из 3х основных функциональных блоков:
устройство предварительной обработки инструкций в порядке их следования в программном коде. Результатом работы этого блока является последовательность микроопераций, поставляемые в исполнительном блоке.
блок выполнения микроопераций реализующий алгоритм безупорядоченного выполнения.
блок завершения.
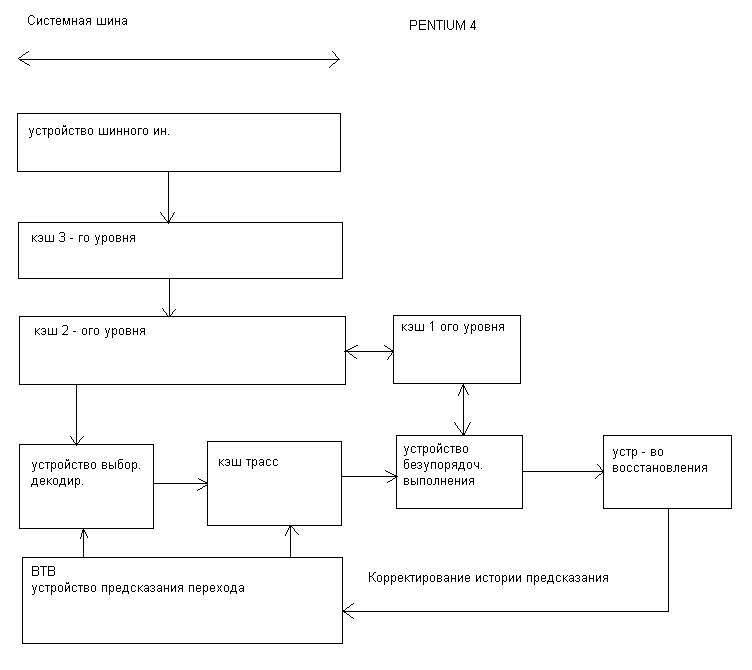
Основное отличие от Р6, это наличие кэш трасс, представляющие память декодированных инструкций т.е. микрооперации, которые читаются из кэш трасс в буферах исполнительного устройства.
Как и в Р6 микрооперации формируются по коду выполнения программы, с той или иной лишь разницей, что эту работу блок предварительной выборки производит заранее и накапливает их в памяти. При этом работает блок предсказания перехода, который выбирает направление выполнения программы и как бы «сшивая» единую последовательность микроопераций, устраивая не только безусловные переходы, но и условные на основании данных в блоке предсказания.
Если при декодировании встречается «сложная» инструкция то как и в Р6 используется постоянная память ROM, в которой уже находиться последовательность микроопераций данной инструкции. При этом эти микрооперации не вставляются в кэш трасс и ставятся на место инструкции «заплатка» - указатель /адрес на место нахождения последовательности микроопераций вROM.
В случае «промаха» в кэш трасс инструкции выбираются из более высокого уровня памяти. Декодируются таким образом поколения кэш трасс. Такая операция формирования сегмента кэш трасс занимает от 10,15 ти тактов до 30 ти т.е., «скрытый участок» конвейера достаточно сложная операция т.к. она проводится заранее и имеет большую «емкость» кэш трасс. Эти издержки вполне допустимы.
Сравним количество стадий конвейераустройства выборки/декодирования (без учета формирования очередной линейки кэш трасс) 8 по отношению к 7 стадиям в Р6. Кэш трасс представляет как бы память микропрограмм, формируемая динамически в процессе работы в процессоре и дает возможность многократно выполнять не только повторяющие инструкции но и целый сегмент программного кода.
Так на что же расходуются эти 8 стадий?
Первые 4 такта – извлечение последовательности из кэш трасс и предсказание перехода. Первый раз уже блок формирования адреса перехода выполняет свою функцию при формировании трассы но т.к. от этого момента до выполнения в процессоре проходит достаточно времени и блок предсказания переходов может иметь обновленные данные о ходе выполнения программы , то для «корреляции» в текущем моменте блок активизируется вторично. 1 такт уходит на буферизацию микроинструкции после чтения из кэш трасс и еще 1 такт чтобы выбрать «тройку» микроинструкций из очереди подготовить для нее ресурсы процессора. 2 такта уходит на замену логических регистров в микроинструкциях временными физическими из таблицы замены регистров.
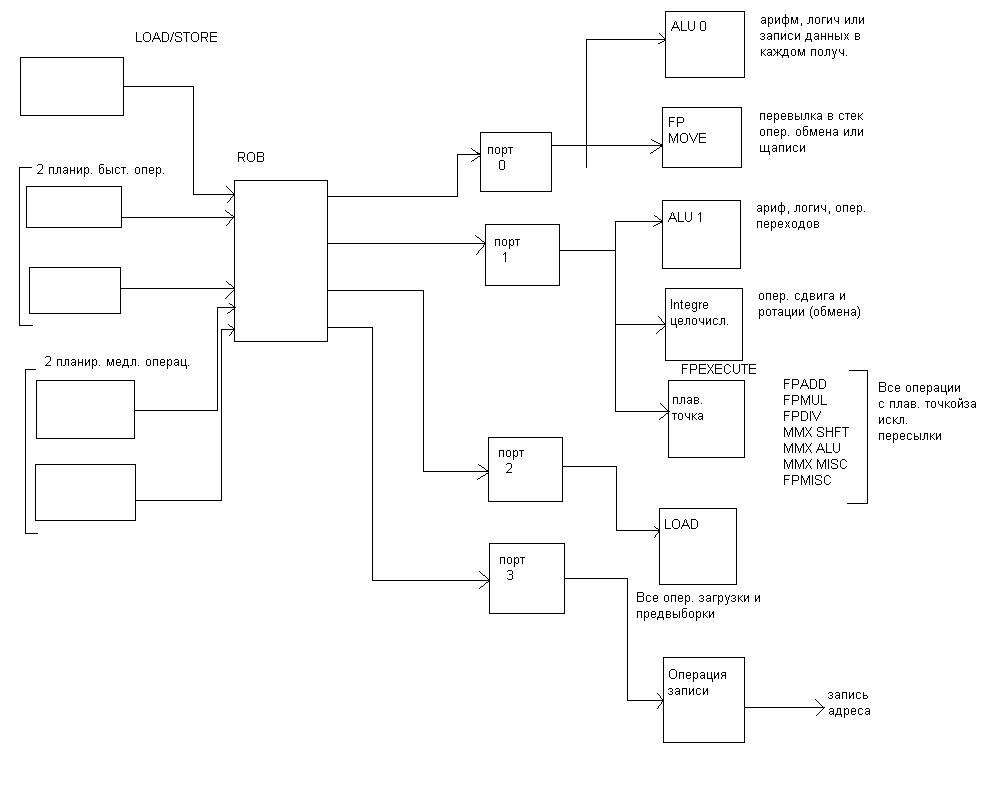
Функциональные исполнительные устройства в Pentium4
После того как инструкция поступила в пул инструкций, процессор начинает распределять их по соответствующим исполнительным устройствам.
Принцип такой же как и в Р6, но имеет свои особенности.
Во первых, если в Р6 выполнение всех микроинструкций на стадии резервирования управляется одним планировщиком, то в Pent4 таких планировщиков 5, которые «разбирают» микроинструкцию в пуле. Все микрооперации обращения к памяти формируются в отдельную очередь, которую контролирует отдельный планировщик (16 микроопераций).
Все другие формируются в другую очередь, которая управляется 2 мя «быстрыми» и 2 мя «медленными» планировщиками. Всеми простыми арифметически-логическими операциями управляют быстрые планировщики, которые распределяют по 2 микроинструкци за такт.
Вторая особенность - микроинструкции отправляются выполняться на исполнительное устройство к тому моменту времени, когда должны поступить операнды из кэш. Если в Р6 схема обработки выглядит так:

В Pentium4 работают 2 независимых планировщика со своими микрооперациями, согласовывая (синхронизируя) между собой свои действия.
Например. планировщик распределяя микроинструкцию LOADобращаясь за операндом в память, обязан сообщить всем остальным о постановке ее в очередь.. Планировщик, управляющий операцией сложения, в которой участвует этот операнд из памяти обязан поставить в очередь и отправить микрооперацию в исполнительное устройство с задержкой с таким расчетом, чтобы к появлению данных из кэш на шине микроинструкция была в исполнительном устройстве. Это теоретически. На самом деле чтобы избежать критической ситуации, когда данных не будет в кэш, конвейер исполнительного устройства имеет аппаратные средства повторить микроинструкцию, используя дублирующую копию микроинструкции, которая продвигалась параллельно по дублирующему псевдоконвейеру, не подвергаясь обработке в функциональном устройстве. Это делается‘ с той целью чтобы в случае промаха возвратить микроинструкцию на основной конвейер для повтора.
Архитектура кэш трасс
Кэш состоит из блоков размером в 6 "ячеек"
для размещения микроинструкций. Обычно
МОП занимает одну ячейку Т-кэша. Однако
в случаях, когда МОП соответствует
x86-инструкции, содержащей литеральную
константу либо непосредственный адрес
(смещение), и длина значимой части этой
константы превышает 16 разрядов, требуется
дополнительное место для размещения
недостающей информации. В ряде случаев
место может быть выделено в соседних
ячейках при условии, что поле литеральной
константы в этих ячейках не занято. При
отсутствии такой возможности выделяется
дополнительная ячейка. В этом случае
обе ячейки, составляющие МОП, должны
размещаться в одном блоке кэша. Кроме
того, если x86-инструкция состоит из
нескольких МОПов (до 4-х), то все эти МОПы
должны также размещаться в одном блоке.
Существуют и некоторые другие ограничения
на размещение МОПов.
![]() Темп
последовательного чтения из Т-кэша
составляет 1 блок за 2 такта, или 3 МОПа
за такт - что находится в соответствии
с темпом декодирования и отставки
микроинструкций, а также их обработки
на некоторых
Темп
последовательного чтения из Т-кэша
составляет 1 блок за 2 такта, или 3 МОПа
за такт - что находится в соответствии
с темпом декодирования и отставки
микроинструкций, а также их обработки
на некоторых![]() промежуточных
стадиях.
Объём Т-кэша составляет 12K
ячеек, или 2048 блоков, организованных в
256 наборов по 8 блоков. Для преобразования
программного адреса первой x86-инструкции
в каждой трассе (как правило, это
инструкция, на которую производится
переход) в положение первого блока
трассы (заголовка трассы) в кэше
используется комбинированный алгоритм,
сочетающий прямую адресацию по нескольким
разрядам программного адреса инструкции
с ассоциативным поиском. Разряды этого
адреса b10-3 указывают номер набора, а
нахождение требуемого блока в наборе
осуществляется сравнением остальных
разрядов адреса (ключа) с соответствующими
разрядами адреса (тэгами), хранящимися
для каждого блока в наборе. Для ускорения
поиска сначала происходит сравнение
нескольких разрядов ключа с соответствующими
разрядами тэга - мини-тэгом. Мини-тэг
включает в себя 6 разрядов - b13-11 и b2-0. При
нахождении блока с требуемым мини-тэгом
происходит выборка инструкций с
одновременной проверкой оставшейся
части тэга.
промежуточных
стадиях.
Объём Т-кэша составляет 12K
ячеек, или 2048 блоков, организованных в
256 наборов по 8 блоков. Для преобразования
программного адреса первой x86-инструкции
в каждой трассе (как правило, это
инструкция, на которую производится
переход) в положение первого блока
трассы (заголовка трассы) в кэше
используется комбинированный алгоритм,
сочетающий прямую адресацию по нескольким
разрядам программного адреса инструкции
с ассоциативным поиском. Разряды этого
адреса b10-3 указывают номер набора, а
нахождение требуемого блока в наборе
осуществляется сравнением остальных
разрядов адреса (ключа) с соответствующими
разрядами адреса (тэгами), хранящимися
для каждого блока в наборе. Для ускорения
поиска сначала происходит сравнение
нескольких разрядов ключа с соответствующими
разрядами тэга - мини-тэгом. Мини-тэг
включает в себя 6 разрядов - b13-11 и b2-0. При
нахождении блока с требуемым мини-тэгом
происходит выборка инструкций с
одновременной проверкой оставшейся
части тэга.![]() На
Рис. 4 приведён пример отображения
последовательных блоков инструкций на
наборы классического I-кэша, а на Рис. 5
показана организация хранения трасс в
Т-кэше. Также показана структура
программного адреса первой инструкции
в трассе при доступе к первому блоку
трассы в Т-кэше. Буквами S обозначены
разряды номера набора, буквами M - разряды
мини-тэга, и буквами T - разряды оставшейся
части тэга.
На
Рис. 4 приведён пример отображения
последовательных блоков инструкций на
наборы классического I-кэша, а на Рис. 5
показана организация хранения трасс в
Т-кэше. Также показана структура
программного адреса первой инструкции
в трассе при доступе к первому блоку
трассы в Т-кэше. Буквами S обозначены
разряды номера набора, буквами M - разряды
мини-тэга, и буквами T - разряды оставшейся
части тэга.![]()
![]()

![]() Рис.
Пример отображения последовательных
блоков инструкций на наборы
Рис.
Пример отображения последовательных
блоков инструкций на наборы
![]() классического
I-кэша (все блоки имеют одинаковые старшие
разряды адреса
классического
I-кэша (все блоки имеют одинаковые старшие
разряды адреса![]() и,
как следствие, соответствующие им наборы
кэша имеют одинаковые тэги)
и,
как следствие, соответствующие им наборы
кэша имеют одинаковые тэги)
![]()
![]()
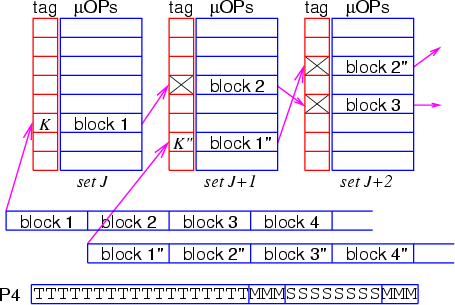
![]() Рис.
Организация хранения трасс в Т-кэше
Рис.
Организация хранения трасс в Т-кэше
Краткая характеристика Power4.
Начало направления RISCархитектурыIBMбыло положено сRISCSystem6000 в 1990
Являющейся приемственником серии eServerpSeries.
Начальная модель процессора функционировала в области частот от 20Мгц до 30Мгц. В 1993 году pow2 был разработан, работающ. В области частот от 55Мгц до 71,5Мгц и выполняет до 6 инструкций за цикл (такт).
Параллельно был анонсирован в этом же году pow601, явившийся как результат совместной разработкиIBM,APLbMotorola,Texas.
Все вышеуказанные микропрограммы были 32х разр. Архитектуры. Начиная с RS64 анонсированного в 1997 году иpow3. В 1998 начинается эпоха 64х разрядных архитектур.
Микропроцессоры класса RS64,RS64=2,3,4 през. Запись для коммерческих приложений.
RS64 вначале работали на частоте 125Мгц. Более поздние разработкиRS64 - 4 функционирующий на частоте 750Мгц.
Power- 3 был презентован (оптимизирован) для технологических приложений, работающих изначально на частоте 200Мгц. В дальнейшем модифицирован до 450Мгц.
Power- 4 был разработан для использования как в коммерческих так и в технологических приложениях.Power– 4 был сконструирован в манереPowerPCархитектуры .Изначально заложили для работы на частоте 1,1Ггц и 1,3Ггц.
Стадии конвейера Power4.
IF, IC, BP – циклы предназначенные для выборки инструкций и анализа предсказания перехода.
БЛОК ВЫБОРКИ КОМАНД POWER4.
Прежде чем рассматривать архитектуру блока выборки команд POWER4 необходимо отметь следующее:
POWER4 является суперскалярным процессором с конвейерной организацией обработки команд. Как мы увидим далее, при рассмотрении технологии конвейерной обработки команд в процессоре возникают конфликты по управлению, связанные с выполнением команд переходов.
Для уменьшения времени простоя конвейера используется технология предсказания переходов то есть вероятностный метод продвижения команд по конвейеру .Не вдаваясь в подробности функционирования механизма логики предсказания переходов, который мы рассмотрим позже, отметим только то , что загрузка очередной порции команд в кэш инструкций из вышестоящего уровня иерархии памяти происходит по адресу, сформированному этой логикой (блоком предсказания переходов)
Так как адреса обращения за командами являются логическими при использовании виртуальной памяти и требуется их преобразование в физические, то для сокращения числа обращений к блоку преобразования адресов, используются буфера быстрой переадресации (TLB) , в которых хранятся значения адресов логических страниц и соответствующих им физические адреса , вычисленные ранее при первом обращении в память по выше упомянутым логическим адресам этих страниц.
Но в отличии от кэш данных механизм обнаружения команд в кэш инструкций и использование буферов быстрой переадресации намного сложнее и это в первую очередь связано с использованием вероятностного метода выбора инструкций из кэш.
Если при загрузке строки данных в кэш промах в дальнейшем при обращении к данным этой строки может возникнуть при изменении их самим процессором или другим агентом системы (многопроцессорные системы) , то при загрузке строки команд в кэш инструкций нет ни какой гарантии, что все команды в этой строке будут выполнены полностью, прежде чем будет загружена другая порция команд в кэш инструкций (из за команд переходов).
Уменьшить вероятность промаха можно уменьшением размера строки ,загружаемой в кэш инструкций, но при этом возрастает размер буфера переадресации.
Большой же размер строки приводит к увеличению числа команд переходов и усложняет логику предсказаний и снижает вероятность правильности предсказания ,поэтому был выбран компромиссный вариант –выбирать строку большого размера ,а анализ предсказания переходов осуществлять по секторам строки ,на которые она делиться. При чем РАЗМЕР СЕКТОРА выбрать равным буферу , в который читаются команды из кэш инструкций для выполнения в процессоре. Но для этого пришлось вводить не один буфер TLBа два, потому что первый хранит физические адреса строк находящихся в кэш в соответствии с логическими адресами обращения за командами .а второй буфер осуществляет контроль за продвижением команд внутри строки каждый раз при загрузке очередного сектора из кэш инструкций в буферные регистры путем сравнения физических адресов из обоих буферов
Инструкция выбирается из КЭШ инструкций по значению адреса IFAR- Instr.fetch address reg.
Обычно IFAR загружается согласно логике предсказания перехода.
В случае ошибочного предсказания ,необходимо будет произвести корректировку значения IFAR, чтобы продолжить выполнение потока инструкций в нужном направлении. Кроме этого изменение потока инструкций может быть вызвано прерыванием от внешних событий, в любом случае, как только в IFAR будет загружен адрес команды, то до восьми инструкций поступает на конвейер в каждом цикле.
Каждая строка в КЭШ инструкция составляет 128 байт, которая разделена на 4 эквивалентных сектора по 32 байта, которые определяют ширину данных записи/ считывания в цикле работы кэш памяти команд.
В архитектуре Powerвзят буфер Т LB( translate looksid buffer) и SLB – (Segment looksid buffer) для преобразования эффективного адреса в реальный. Power4 содержит 4 буфера трансляции (по два на каждый процессор в двух ядерной архитектуре то есть на каждый процессор приходится кэш команд и кэш данных).
Когда конвейер инструкций готов получать инструкцию, содержимое IFAR посылается в полностью ассоциативный буфер IDIR(Instr. Directory), который адресуется частью эффективного адреса, другая часть которого используется как тег . Кроме этого теговая строка содержит 42 бита реального адреса, содержащие два полных физических адреса строк, переписанных из кэшL2 в кэш инструкций и находящихся в ней на данный момент. Так как размер кэшL2 составляет 1,5 МГБ, то для фиксации адресов двух строк из кэшL2 в кэш инструкций нужны эти 42 разряда. В блоке выборки команд имеется еще таблица переадресации IERAT , которая имеет такую же архитектуру как и выше упомянутый буфер с той лишь разницей , что в теговой строке содержится физический адрес-результат преобразования логического адреса. Содержимое этих двух буферных таблиц и является исходной информацией для определения наличия команд в кэш инструкций.
И так содержимое регистра адреса выборки инструкций ,обновляется принимая значение адреса первой инструкции в следующем секторе, после того как он будет передан в кэш инструкций , выше упомянутые таблицы и в блок предсказания где сформируется адрес команды, по которому возможно пой дет выполнение программы, если по данному адресу логика обнаружения команд перехода зафиксирует таковую или по другим адресам в считанном секторе в случае его нахождения в кэш инструкций . Если в считанном секторе не будет обнаружен факт перехода и все команды в секторе будут выполняться последовательно, то в буфер инструкций будет загружен следующий сектор. А сейчас вернемся к началу цикла выборки инструкций из кэш и рассмотрим подробнее механизм обнаружения их в памяти .
И так по значению в IFARсчитывается значение реального адреса из “IDIR” эффективный и реальный адреса из таблицы IERAT.
IERAT (содержит эффективный и соответствующий ему реальные адреса) проверяется с тем чтобы проверить достоверность входа и чтобы реальный адрес сравнить со значением IDIR .Сравнение необходимо ввиду того, что с момента загрузки строки из кэшL2 в кэш инструкций к моменту выбора очередного сектора из нее в буферные регистры блока выборки, строка может перейти в состояниеINVALIDили на ее место будет к этому моменту загружена другая строка из системной памяти. Если в таблице IERAT установлен флаг INVALID, то
EA должен быть транслирован из TLB и SLB. Выбранная инструкция «пузырится». Если IERAT VALID, RAIPIR=RAIERустанавливая Icahehit i=1, разрешает продвижение конвейера и работу блока предсказаний и IFAR вновь устанавливается в соответствии с индикатором ВТВ. Активизируются декодеры, начинается формирование групп, логика разрешает выбранным инструкциям продвигаться по конвейеру.
ЕСЛИ обнаружен промах, возможны несколько сценариев:
1) буфер предвыборки проверяется есть ли в нем затребованная инструкция, и если да, логика продвигает эти инструкции к конвейеру: как если бы они были выбраны из КЭШа и записывает также критический сектор в КЭШ.
2) Если инструкции нет в буфере, формируются два последовательных запроса к КЭШ уровня L2. L2 обрабатываются, в результате чего будет произведена запись в кэш инструкций и в буфер предвыборки .
В случае присутствия затребованной инструкции в буфере предвыборки, организуется запрос в кэш L2 за очередной строкой.
В дополнение к механизму выборки инструкции по затребованным запросам БВК осуществляет выборку инструкций, которые в скором времени будет затребована для выполнения.

Блок-схема блока выборки команд Power4
D0, D1, D2, D3 Xfer, GD – циклы, в течении которых инструкция декодируется и формируется в группы.
MP – цикл, в течении которого выявляются все зависимости, ресурсы, и группа диспетчеризуется в соответствующую очередь.
ISS– данный цикл предназначен для постановки в очередь для выполнения в функциональном устройстве, чтения соответствующего адреса регистра для выбора данных из регистрового файла и формирования адреса для записи результата .
EX – цикл выполнения.
WB – цикл записи в регистр результатов. В этом цикле инструкция заканчивает выполнение, но не завершенной она не моет завершиться по крайней мере еще 2 цикла.
Xfer, CP – циклы предназначенные для завершения всех старших Групп или инструкций в той же группе.
Следует отметить, что инструкции, выбранные из кэш инструкций ждут D1 цикл, если они выбираются раньше, чем попадут в группу. Подобные инструкции могут ждатьMPцикла, если ресурсы недоступны илиISSцикла или СР цикла для завершения.
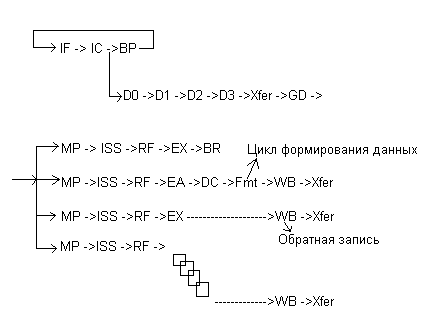
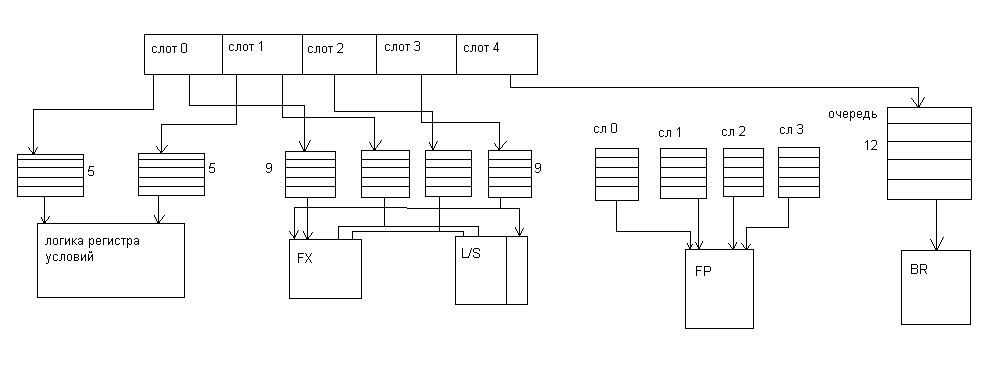
Особенностью архитектуры Power4 является объединение инструкций в группы по 5 инструкций в каждой, которые поступают после формирования на этап диспетчеризации для дальнейшего исполнения в соответствующих исполнительных устройствах. Это делается с целью упрощения механизма отслеживания за выполнением инструкций при безупорядочном выполнении в исполнительных устройствах. Если вINTELотслеживается каждая инструкция и удаляется с конвейера при завершении всех предыдущих, то вPower4 удаляется группа целиком, т.е. 5 инструкций при условии, что все инструкции в группе завершены, и все предыдущие группы удаляются с конвейера.
Power4 имеет так называемую Глобальную таблицу завершения групп. Для увеличения числа инструкций находящихся на исполнении в устройствахPower4 имеет Глобальную таблицу завершения инструкций на 20 входов. Т.е. одновременно отслеживаются 20 групп. Т.е. 20*5=100 инструкций, а при 2х ядерном до 200. Для каждой группы находящейся на этапе выполнения в таблице отводится строка, в которую заложен адрес
1 ой инструкции в группе. Таким образом, частью механизма завершения инструкций в программном порядке.
Индивидуальные группы следуют через систему то есть состояние процессора отслеживается на границе группы ,а не на границе инструкции внутри группы .Любая исключительная ситуация вызывает сохранение старшей группы, предшествующей возникновению причины прерывания.
Группа содержит до пяти внутренних инструкций. На стадии формирования группы инструкции в группе размещаются последовательно. Старшая инструкция в слот 0,следующая за ней в слот 1 и т.д. Слот 4 зарезервирован для инструкций перехода. Только одна группа инструкций распределяется за цикл и все инструкции в группе распределяются одновременно.
Индивидуальные инструкции из очередей в функциональных устройствах поступают на выполнение беcпорядочно. Результат фиксируется ,когда группа завершает выполнение условием которого является ситуация ,когда все старшие группы завершены и завершены все инструкции в группе.
Для осуществления корректного выполнения некоторым инструкциям запрещены спекулятивные операции то есть обгонять впереди идущие в программном коде. Примером таких инструкций являются инструкции чтения и записи в защищенные области памяти или такие как запись в регистры ,фиксирующие состояние процессора.
Для организации безупоряочного выполнения большинство логических (архитектурных) регистров подвергаются преобразованию, но не все . Инструкции, в которых запрещено переименование, размещаются в конце группы
Внутренние инструкции в группе в большинстве своем являются системными командами ,однако, иногда системные команды разбиваются на несколько внутренних при формировании группы. Если системная команда разбивается на две внутренние, то обе они должны быть в одной группе. Если обе инструкции не могут быть размещены в одной группе, то группа заканчивается и новая группа формируется .Инструкция следуемая за разбиваемой может быть размещена в группе при наличии в ней места.
Следует отметить, что при формировании групп учитываются возможности инструкций из слотов в исполнительном устройстве. Так например, в слоте 4 могут располагаться инструкции перехода, если к моменту формирования группы таковой не окажется, то их место 4 ый слота формир. Инструкц. Н.О.П.
Так устройство, обрабатывающее содержимое регистра условий может принимать инструкции только из слота 0 или 1.
В Power4 до 8 инструкций выбираются в каждом цикле из кэш инструкций в буфер инструкций. Логика предсказания переходов сканирует выбранные инструкции, просматривая до 2х переходов в каждом цикле. В зависимости от типа найденного перехода, различные механизмы предсказания помогают предсказывать направление и адрес перехода. Безусловные переходы не предсказываются.Power4 использует для предсказания переходов 3 таблицы историй переходов. Первая таблица, называемая локальным предсказанием подобна традиционной таблице В.T.Т. Это 16.384 входов табл (2 в 14 ой степени) индексируемая адресом инструкций перехода с 1 бит предсказания.
Вторая таблица, называемая глобальным предсказанием. Предсказывает направление перехода в соответствии со значением перехода на действительную траекторию при выполнении каждой команды перехода. Траектория прохождения фиксируется в 11 бит регистре по одному биту на каждую группу инструкций , из одиннадцати предыдущих выбранных из кэш. Этот вектор называется вектором глобальной истории. Каждый бит в глобальной истории отражает была ли выбрана следующая группа из последовательного сектора кэш. Вектор глобальной истории собирает информацию о выполнении этих секторов.
В.Т.В. содержит 3 таблицы:
1) таблица локальных переходов.
2) глобальная таблица
3) Селекторная таблица, осуществляющая фиксацию предсказаний в каждой таблице и действительный результат по каждому предсказанию.
Локальная таблица Глобальная таблица Селекторная таблица
Power5
1)Организация многопоточного режима.
Для этого на стадии до – после выборки инструкций из кэш они распределяются по 2м потокам отдельные буфера по 24 инструкции каждая. Таким образом, комплектуются группы инструкций из одного потока.
2)Регистровый фаил разделяется между двумя потоками. Т.е. все регистры файла доступны каждому из потоков.
3) Для реализации многопоточности размер и структура очередей были модифицированы.
Таблица GCTдля каждого входа (группы) сигнала содержит дополнительный бит, фиксирующий принадлежность группы к потоку.
Помимо этого каждый логический регистр при замене на физический стал содержать бит
(индекс) принадлежности к потоку. А количество физических регистров было увеличено.
4) Модернизация подверглась очередь для инструкцииL/S. Дело в том, что области памяти для потоков разнесены в адресном пространстве. Поэтому очереди эти разделились поровну между потоками. А для того, чтобы исключить «пузыри» для этих инструкций организовали виртуальные очереди, в которых фиксируется инструкция при диспетчеризации, но без указания адресов памяти. Как только в реальной очереди освобождается место, инструкция переходит из виртуальной очереди в реальную, и для нее формируется адрес обращения к памяти.
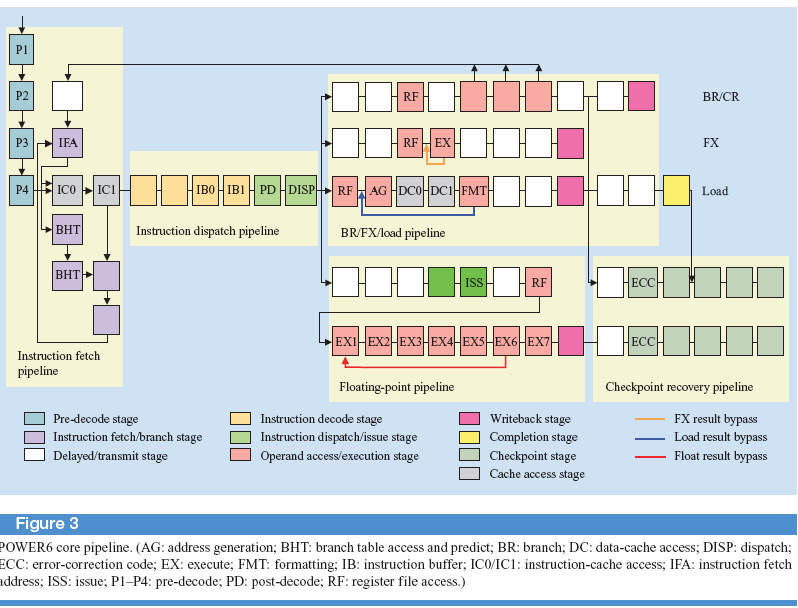
Архитектурные особенности POWER6
Главной особенностью архитектуры Power6 от предыдущих Р4 и Р5 является вынос за пределы конвейера стадий формирования групп, поступающих на диспетчеризацию. Формирование групп вPower6 осуществляется при переходе инструкций из кэшL2 в
кэш инструкции. Таким образом, в кэш L1 поступают формированные группы. Кроме этого, если в Р4 и Р5 сохраняются зависимости внутри группы, то в Р6 инструкции в группе друг от друга независимы кроме инструкции с плавающей точкой.
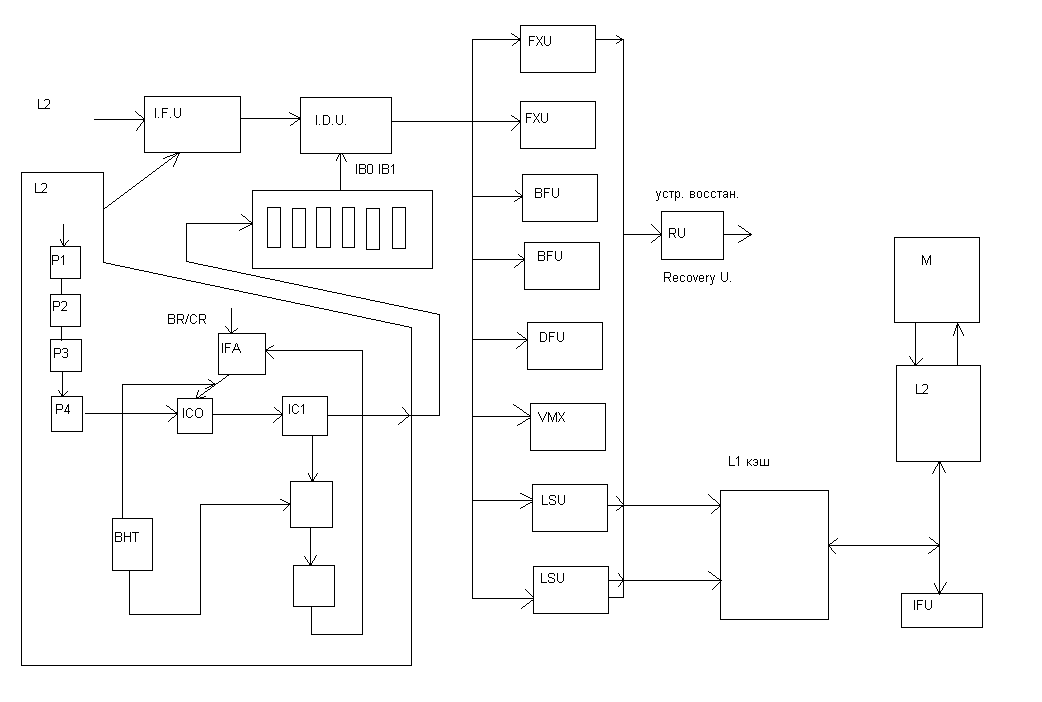
Архитектура микропроцессора Z990
Прежде чем рассматривать архитектуру микропроцессора Z990, необходимо отметить, что данная архитектура явилась результатом эволюции развития серверов предшествующих поколений, родоначальником которых была серия манфреймовIBM360. Особенностью этой серии былаCISCархитектура ,которая определяла структуру и форматы команд, реализуемых в процессорах этой серии . Кроме того эти процессора достаточно развитую аппаратную систему диагностики и восстановления работоспособности процессоров ,поддерживаемую на программном уровне специальными системными командами. Хотя эти процессора не были суперскалярными и выполняли только одну инструкцию за цикл, но имели достаточно высокие показатели и характеристики при выполнении сложныхCISCкоманд за счет наличия дополнительных аппаратных средств(акселераторы, блоки логических операций) и мощную систему памяти ,включающую буферные памяти команд и аппаратные средства поддержки преобразования логических адресов в физические.
Внедрение принципов RISCархитектуры при проектировании процессора сопровождалось разработкой и появлением новых языков программированияC,C++,Java, которые использовались для написания программных приложений для пользователей. Для того чтобы сохранить возможность выполнения уже ранее разработанных приложений и новых разработчики архитектуры процессора решили совместить как технологию суперскалярности, так и возможность выполнения сложных командCISCархитектуры.
При разработке архитектуры микропроцессора были учтены и использованы достижения и наработки в предшествующих моделях процессоров. Это в первую очередь использование милликодов и аппаратные средства восстановления работоспособности системы при возникновении сбоев.
Кроме того в микропроцессореZ990 подобно его предшественникам используется дублирование функционирования основных узлов процессора и содержится несколько механизмов для трансляции его состояния в резервный процессор в случае фатальной ошибки.
В микропроцессоре рассматриваемой архитектуры не используется технология безупорядочного выполнения команд, что является отличительной особенностью от других RISCпроцессоров. За счет этого была сокращена аппаратная часть микропроцессора поддержки этого режима и ее место заняли схемы дублирования основных узлов и восстановления при возникновении ошибок.
Одним из оригинальных решений при проектировании было решение сохранить использование милликода, который использовался еще в предшествующих моделях.
Для того, чтобы понять, что из себя представляет милликод и как он используется в процессоре, напомним, что существуют два основных метода реализации команд в процессоре. Это микропрограммное управление и жесткая логика.
Большинство команд в микропроцессореZ990 реализуется аппаратными средствами, т. е. использует жесткую логику и только сложные команды используют милликод.
Если рассматривать архитектуру микропроцессоров ,например, линейку микропроцессоров PENTIUMфирмыINTEL,то можно отметить, что при реализации сложных команд ,когда дешифратор не справляется с декодированием инструкции в микроинструкции там используется, так называемый, микрокод ,хранящийся в постоянной памяти микропроцессора , который можно интерпретировать как элемент микропрограммного управления.
С точки зрения методологии подхода к реализации сложных команд нет разницы ,,но отличие заключается в том, что INTELиспользовала микроинструкции ,имеющие свою специфичную структуру и формат, аIBMстандартные команды с вертикальным кодированием, таким образом милликод также как основной набор команд выполняется на тех же аппаратных средствах, это во первых. А во-вторых, функциональные возможности милликода намного шире ,чем системные команды, то есть при входе в режим выполнения милликода его рутинам доступны аппаратные средства, которые не доступны даже системным командам.
Размещается милликод ,точнее его рутины в системной памяти в определенной области ,в которую запрещен доступ системным командам и загружается в эту область во время инициализации системы по включению питания то есть эта область по сути выполняет функцию памяти микропрограмм.
И так, отказавшись от технологии микропрограммного управления, IBMсохранила ее метод управления вычислительным процессом за счет
1 Использования особого режима во время выполнения милликода.
2 Расширения функциональных возможностей, что позволило реализовать не только интерпретацию сложных команд, но и выполнять сервисные функции в процессоре, связанные с диагностическими операциями и реализацией механизмов прерывания.
Применение милликода в процессоре позволило разработчикам серверов перенести часть функций при реализации виртуального режима в них с системного уровня на аппаратный и именно этот факт стал при реализации технологии логических партиций LPARв серверах фирмыIBM, то есть многооперационных систем на одной аппаратной платформе.
И так рассмотрим работу конвейера в процессоре более подробно.
Выборка инструкций и блок предсказания переходов.(циклы выборки из кэш)
Доступ к кэш памяти инструкций по времени занимает 3 цикла конвейера в течении которых формируется запрос в кэш инструкций со стороны устройства выборки инструкций и передача выбранных инструкций в буферные регистры. Обычно эти циклы скрыты и не влияют на производительность процессора так как выборка инструкций из кэш производится с опережением, и была еще использована в свое время в отечественных ЭВМ серии ЕС начиная с ряда2.
В тех случаях когда текст инструкции необходимо декодировать немедленно, то она ,минуя буфер, передается на декодер(случай перевыборки, связанный с командой перехода,.когда целевая инструкция отсутствует в буфере команд)
Устройство выборки имеет 16 буферных регистров, каждый с разрядностью в 4 слова.
Логика предсказания переходов содержит буфер целевых адресов, строки которых содержат, бит предсказания, целевой адрес и адрес самой команды перехода. В случае отсутствия информации в буфере для данной команды перехода принимается решение- нет перехода на целевой адрес.
Помимо этого буфер переходов целевого адреса содержит “историю” переходов, указывая, что на данный момент наиболее вероятен “сильный”,”слабый”или отсутствие перехода в зависимости от величины счетчика переходов.
Декодирование и формирование групп .(циклы D1,AA1)
Декодеры инструкций могут декодировать любой тип инструкций. Большинство инструкций декодируется в одном цикле. Однако, наиболее сложные требуют более одного цикла для декодирования, к таким, например, относятся двухадресные инструкции, указывающие на расположение операндов в памяти.
Большинство других инструкций декодируются вместе, объединяясь в группу с одним исключением: инструкция перехода должна быть старшей в группе .До трех инструкций может входить в группу.
Совместно с командой перехода, которая является старшей в группе, могут находиться простые, выполняемые за один такт, к которым относятся логические и арифметические операции.
Идея размещения команды перехода старшей в группе связана с тем, что на первый взгляд является парадоксальной, так как эти команды предназначены для анализа признаков результатов от предыдущих команд. Однако выбранная схема при отсутствии безупорядочного выполнения, то есть в порядке следования программному коду дает возможность получать результат перехода в одном цикле с проверяемой командой, так как она выполняется в предыдущей группе программного кода.
Во время формирования групп могут иметь место факторы ,которые ограничивают их эффективное выполнение в процессоре и препятствуют включению инструкций в группу. Так ,например ,одним из условий является , что генерация адреса обращения к памяти должна быть завершена до того или в том же цикле ,в котором группа с инструкцией ,использующей этот адрес, поступает в операционное устройство для исполнения. Кроме того ,если инструкция имеет зависимость при формировании адреса от инструкции уже распределенной в группу,(старшая инструкция производит операцию над базовым или индексным регистрами, являющихся составной частью адреса операнда) то она не включается в группу.
Такие зависимости как RAWв группе между инструкциями запрещены ,с одним исключением .Если такая зависимость существует между инструкциями типаLOUD,выполняющей загрузку данных в регистр из памяти или из другого регистра регистрового файла, а другая использует загружаемый регистр как источник операнда в арифметической или логической операции, то такая комбинация разрешена в группе. Путем простого изменения маршрута на вход исполнительного конвейера продвижение операнда может быть реализовано с минимальными потерями.
Цикл AA1 предназначен не только для формирования групп, но и для формирования адреса операнда при обращении к памяти. Цикл этот по времени совпадает с началом работы конвейера кэш памяти, первым циклом которого является циклC0. Совмещение по времени этих двух циклов не случайно и вот почему.
Цикл AA1 предназначен для вычисления значения адреса операнда , указанного в команде ,который является логическим в режиме виртуальной памяти, поэтому после вычисления логического адреса в этом цикле происходит обращение к таблице , хранящей историю преобразования логических адресов в физические, то есть перечень логических адресов и физических им соответствующих. Если будет найден в таблице физический адрес операнда ,то его значение может быть использовано уже в следующем цикле конвейера кэш ,это во-первых. А во-вторых, в случае команды перехода на месте адреса операнда в формате команды указывается адрес перехода. А это означает, что к моменту вычисления логического адреса перехода можно организовать обращение не только к таблице истории ,но и в блок предсказания, в котором еще в циклах выборки это адрес перехода был считан из таблиц предсказания. Следовательно по результату сравнения логических адресов в команде перехода и в таблице предсказания, в случае совпадения их можно будет использовать результат ,полученный из таблицы истории (физический адрес команды перехода) в следующем цикле работы конвейера кэш.
Следующий цикл С1. В этом цикле по значению логического адреса, сформированного в предыдущем цикле С0 (если в таблице истории ААНТ-absoluteaddresshistorytableне найден физический адрес) активизируется частично или полностью работа блока преобразования адресов, происходит обращение к индексной памяти кэш ,если в буфере быстрой переадресации хранятся уже данные преобразования (физический адрес страницы) и буфереTLB(логический адрес страницы) и в случае наличия данных в кэш ,данные считываются из памяти и передаются в исполнительные блоки процессораdв следующем цикле С2
Кэш память организована как память с чередованием адресов, то есть данные с четными адресами расположены в одном физическом блоке, а данные с нечетными в другом и следовательно кэш имеет два независимых друг от друга конвейера . В режиме выборки одновременно две строки выбираются из памяти и передаются в процессор.
Цикл С1 по времени совпадает с циклом Е-1, в котором инструкции принимаются в исполнительные устройства.
За циклом С1 следует цикл С2. В этом цикле, данные считанные из кэш и данные считанные из регистрового файла принимаются в исполнительные устройства, который по времени совпадает с циклом Е0 их конвейеров. В цикле С2 при записи в память данные из очереди в буфере записи поступают в кэш для записи в память. В цикле С2 формируется запрос в блок преобразования адресов в случае промаха в буфере TLBили в буфере быстрой переадресации то есть циклом С2 заканчивается работа конвейера кэш в случае ,если нет необходимости активизировать работу блока преобразования адресов.
В цикле Е1,следующим за циклом Е0, выполняются операции над данными в исполнительных устройствах и в этом же цикле фиксируется промах, в случае неверного предсказания в команде перехода.
Если в конвейере с плавающей точкой выполняется операция, то в этом случае вводятся дополнительные циклы Е2-Е5.За циклом Е1(E5) следует цикл удаления команд с конвейеров, в котором из исполнительны устройств выдается результат(ы) на две 64х разрядные шины результата для записи в регистровые файлы, находящиеся в блоке исполнительных устройств или в блоке подготовки инструкций к выполнению или в буфер записи кэш. Помимо этого результат передается в устройство восстановления для контроля и сравнения с результатом ,полученном в процессоре – дублере.
Свою работу конвейер блока восстановления начинает в цикле ,следующим за циклом удаления в случае его активизации при обнаружении ошибки в процессоре или несовпадения результатов операций в процессорах.
Следует отметить один немаловажный факт при возникновении ошибки в любом из работающих процессоров. Если возникла ошибка в процессоре и он активирует работу блока восстановления, то другой процессор даже если в нем нее возникла ошибка ,то он тоже активирует работу своего блока с той же точки ,что и процессор ,в котором ошибка появилась.
Конвейеры операционных устройств
После формирования групп инструкции поступают в исполнительные устройства.
B-конвейер предназначен для определения в действительности будет переход в программе или нет.
Х конвейер выполняет простые инструкции и инструкции милликода .
Y- конвейер выполняет простые инструкции.
Z- конвейер содержит специальные аппаратные средства для выполнения сложных инструкций, включая операции умножения с фиксированной точкой и десятичную арифметику.
В других случаях при необходимости формируется виртуальный конвейер для обработки 16 байтного потока данных(пересылка символов и операции память-память).
FPUконвейер выполняет операции с плавающей точкой.
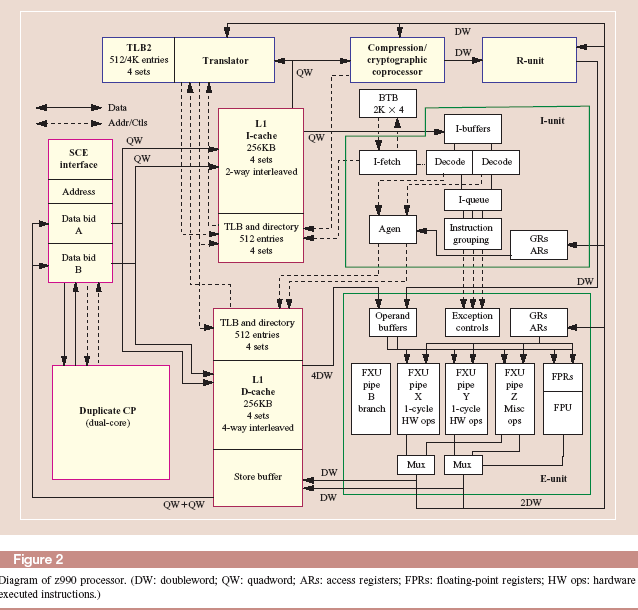

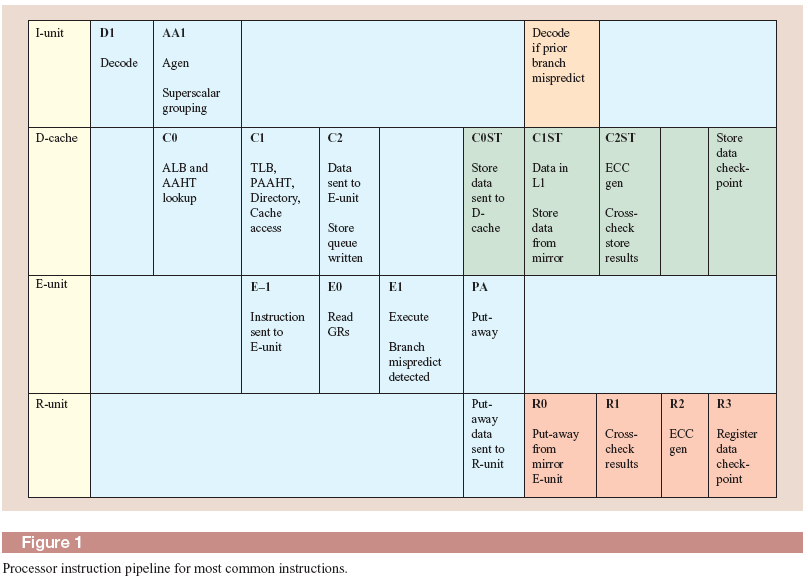
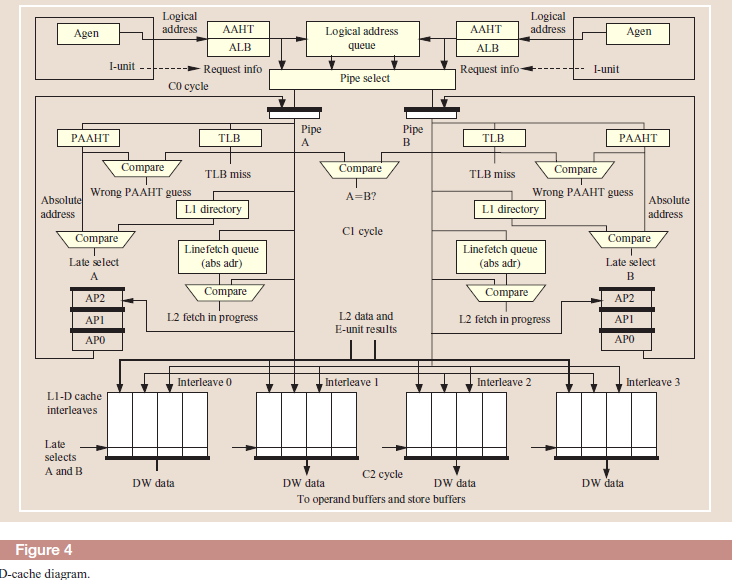
Организация кэш данных в процессореZ990.
Базовая ширина выборки/записи данных в кэш составляет 8 байт(двойное слово).Кэш данных организована как 4х канальная наборно –ассоциативная кэш с распределением( чередованием) двойных слов по четырем банкам и размером строки 256 байт( количеством байт, отслеживаемых по наличиию и достоверности в кэш)
Два независимых конвейера обеспечивают доступ к двум строкам кэш( четной и нечетной) одновременно, и только в случае двух одновременно поступающих запросов к одной строке, один из них будет задержан , но не отвергнут и также как другой проходит все стадии конвейера одновременно с ним, но с идентификатором задержанного.
Диспетчеризация запросов по двум конвейерам осуществляется по значению 55 разряда логического адреса операнда, предварительно прошедшего проверку на наличие физического адреса ,ему соответствующего в таблице истории абсолютных адресов (AAHT). Если таковой отсутствует, то логический адрес поступает в очередь для обращения в память, в противном случае физический адрес поступает в память. Логический адрес проходит все стадии конвейера, которые мы разбирали, рассматривая стадии конвейеров в процессоре выше.
Характеристики и микроархитектура процессора Z10.
Процессор Z10 имеет площадь кристалла 454мм*,на которой размещено 994 млн. транзисторов и рабочую частоту 4,4ггц.Наибольшее достижение процессораZ10- это гигантский скачок в частоте работы процессора по сравнению с предыдущимZ990, частота которого составляет 1,72ггц.
Начальная частота северов с CMOSтехнологией, начиная сS/390 составляла от 27 до29 временных задержек сигнала ( время такта работы конвейера) , за единицу измерения которой принимается задержка сигнала проходящего через 4 последовательно соединенных инвертора. Время такта работы конвейера по сравнению с предыдущими модификациями снизилось на 15 единиц.
Конвейер процессора Z10.
Главный конвейер в процессоре Z10 , подобно тому как реализован конвейер в процессореZ9, состоит из конвейеров: выборки инструкций, декодирования и выдачи, доступа к кэш данных, выполнения операций,rконтроля результатов и восстановления.
Конвейер выборки инструкций и предсказания переходов.
Устройство выборки инструкций в своем составе имеет 4х канальную наборно- ассоциативную кэш размером 64 кбт. и 2хканальную ассоциативную 128 входную кэш для хранения логических адресов инструкций и физических им соответствующих, вычисленных ранее в предыдущих обращениях. Кроме них устройство выборки имеет 4кбт. Память для хранения логических адресов переходов, сформированных ранее блоком предсказания и соответствующие им значения физических адресов.
Цикл I0 используется для обращения в эту 4хкбт. Кэш за получением адреса инструкции ,используемого для обращения в кэш инструкций за очередным блоком инструкций для загрузки в буферные регистры блока выборки при условии, наличия значения физического адреса в памяти при обращении к ней по адресу ,сформированным в блоке предсказания.
Циклы I1 иI2 используются для доступа в кэш инструкций. В циклахI3 иI4 данные из кэш инструкций загружаются в группу буферных регистров ,как указано выше, каждая из которых содержит 4 4х словных регистра.
Десяти килобайтная входная наборно –ассоциативная является ядром блока предсказания переходов. Каждая строка в кэш содержит адрес команды перехода, адрес перехода, тип, строку предсказаний, имеющей 8 состояний, сформированную по результатам переходов в предшествующих 8 командах переходов. Имея организацию 5 канальной наборно- ассоциативной кэш, блок предсказания переходов может хранить информацию для 5 инструкций переходов в каждом из наборов.
Конвейер декодирования и подготовки инструкций для выполнения.
Так по сравнению с процессором Z990 конвейер процессораZ10 имеет больше стадий, чем и обоснована большая частота работы процессораZ10.
Такты D1иD2.
При загрузке инструкций в буферные регистры блока выборки команд не производится ни каких действий по предварительному декодирования их, поэтому два такта конвейера требуются для полного декодирования инструкций, определения зависимостей от конфликтов и постановка команд в очередь. Эта и другая информация, как управление доступом к памяти и управление переходами помещается вместе с командами в очередь инструкций и очередь адресов операндов.
Такт D3.
Такт D3 предназначен для передачи из очереди двух инструкций в схему формирования групп ,которая по времени занимает три такта конвейера:G1,G2,G3. На стадияхG1 иG2 определяется, будет ли сформированная группа выпущена в исполнительные устройства для выполнения. Для этого используют информацию, передаваемую вместе с командами, подготовленную для анализа в тактах декодированияD1 иD2. Если холостых тактов не предвидится, то группа выпускается на конвейер. Если задержки имеются, то группа переводится в очередь задержанных с последующим направлением на конвейер на стадиюG1для повтора при устранении конфликта.

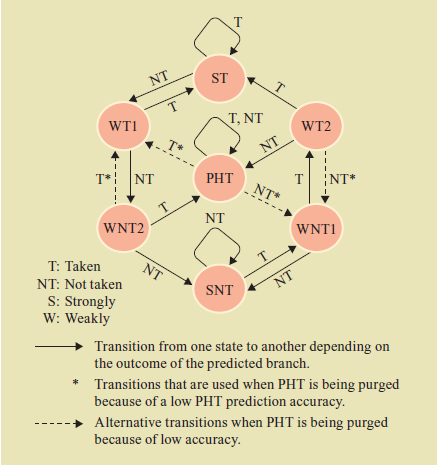
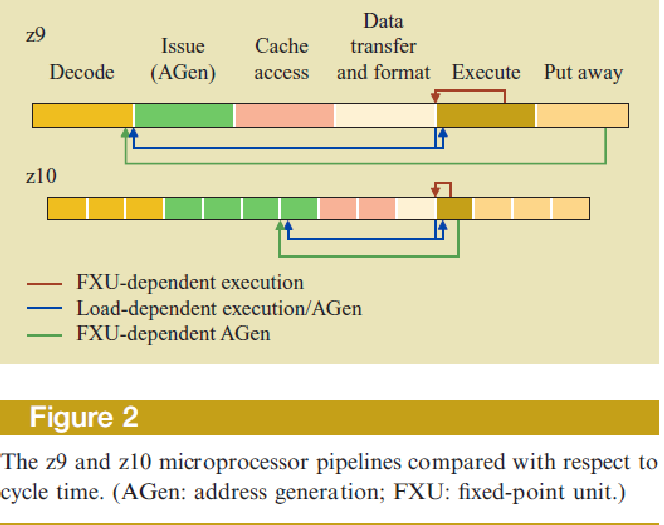
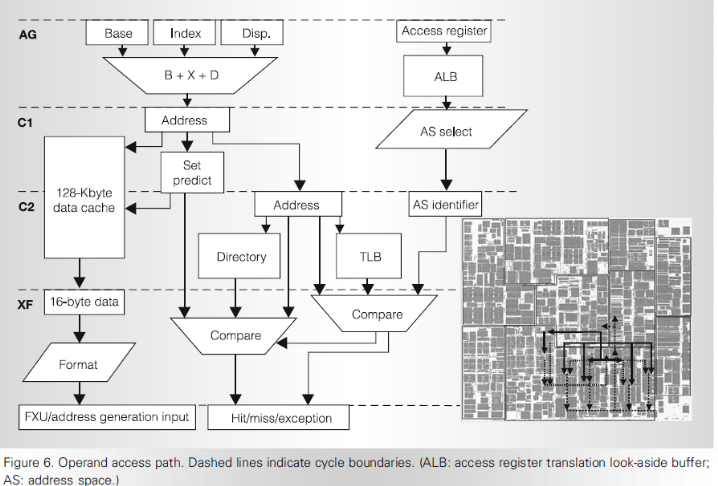
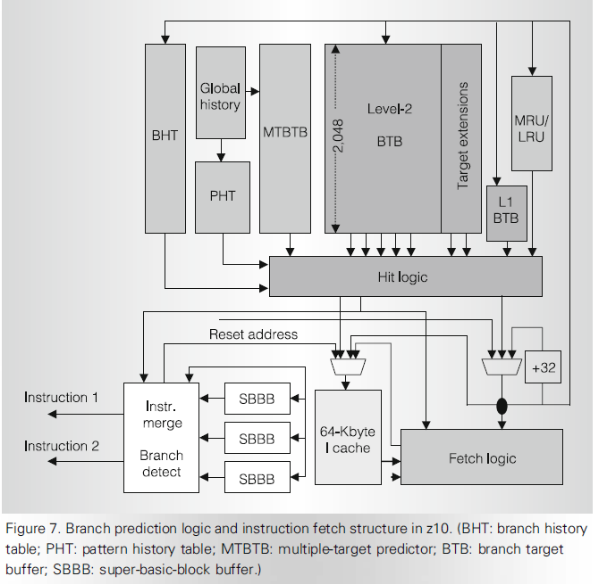
Лекция 9
Тема лекции: Мультипрограммный режим работы ЭВМ.
1. Общие принципы организации мультипрограммного режима.
2.Программно аппаратные средства поддержки мультипрограммного режима.
3.Понятие задачи, структура задачи, структурные данные для управления задачи.
4.Механизм, обеспечивающий переключение выполнения задач в мультипрограммной среде вычислительной системы.
В основу мультипрограммного режима работы ЭВМ положен принцип одновременного выполнения программ в машине.
Определение “одновременный” является чисто условное, так как данный режим был внедрен в архитектуру процессора фон неймановской модели, классифицируемой как SISD- одна инструкция, одни данные. То есть процессор в каждый момент времени в данной архитектуре выполняет одну команду и говорить об одновременном выполнении не только программ ,но команд не имеет смысла. Да, впоследствии, с внедрением конвейерной обработки команд в процессоре стало возможным их одновременное выполнение, причем количество одновременно выполняемых команд стало определяться глубиной конвейера и их количества в процессоре. Но это была технология параллельной обработки команд, принадлежащих одной программе, поэтому понятие “одновременный” в мультипрограммном режиме подразумевает только одновременное нахождение программ в системной памяти процессора, готовых в любое время продолжить выполнение при представлении им процессорного времени.
Идеи мультипрограммного режима работы ЭВМ были выдвинуты в результате анализа занятности ресурсов системы в процессе выполнения программ. Выяснилось, что процессор вынужден простаивать, то есть останавливать выполнение программы из за неготовности ее к работе, в частности отсутствия данных в памяти и ожидания окончания операций ввода вывода, когда эти данные поступят в память.
Для того, чтобы увеличить пропускную способность выполнения задач и была разработана концепция организации мультипрограммной обработки в системе, суть которой сводилась к тому, что при возникновении простоя при выполнении программы представлять ресурсы системы другой.
А для того ,чтобы реализовать это необходимо было ввести в архитектуру комплекс аппаратно программных средств и это в первую очередь управляющей программы, выполняющей функции диспетчера и контроллера за выполнением программ в процессоре.
Аппаратные средства поддержки многопрограммного режима в ЭВМ
1. Наличие виртуальной памяти для хранения программного кода и данных, представляемой каждому пользователю потребовало специальных аппаратных средств по преобразованию логических адресов виртуальной памяти в физические и разбиение физической памяти на страницы- области непрерывного адресного пространства . Смысл такого разбиения физической памяти заключается в том ,что и виртуальная память разбивается на такие же по размеру страницы в результате чего операционная система, размещая программы и данные пользователей во внешней памяти системы(диски, ленты), во время выполнения их в процессоре, используя механизм преобразования логических адресов в физические, осуществляет перемещение содержимого виртуальных страниц из внешней памяти в системную. Таким образом, используя концепцию организации виртуальной памяти в системе,
пользователям была предоставлена возможность размещения своих программ и данных вне зависимости от размеров реальной физической памяти в системе.
2. Система прерываний и средства переключения задач.
Механизм прерываний существовал и в однопрограммном режиме.
Особенностью системы прерывания в мультипрограммном режиме является то , что реакцию на большую часть причин прерываний и их обработку осуществляет не программа пользователя , а управляющая программа- супервизор, при этом если прерывание возникло при возникновении ошибки в программе или другой причине не связанной с нарушением работы системы , блокируется только выполнение этой программы с формированием сообщения пользователю о причине останова. Если пользователь в своей программе желает сформировать запрос на прерывание, то в зависимости от среды вычислительной системы ему представляется возможность использования в программе специальных команд- команд программных прерываний( архитектура intel) или команды обращения к супервизору “вызов супервизора” (в архитектуреibm). Так, например, при обработке программных прерываний пользователю может быть предоставлена возможность блокировки тех или иных причин прерываний путем их маскирования как это делалось в архитектуре отечественных ЭВМ серии ЕС и в настоящее время вzархитектуре.
Что касается механизма переключения задач, то в основу заложен принцип прерывания выполнения программы с той лишь разницей ,что при переключении задач процессор сохраняет при переключении больший объем информации состоянии программы и процессора.
3 Механизм защиты памяти.
Механизм защиты памяти в мультипрограммном режиме необходим, для того чтобы исключить вмешательство как случайное, так и преднамеренное одной программы в другую.
Существуют различные аппаратные решения реализации механизмов защиты, наиболее применяемые из них – это
Защита с использованием метода верхней и нижней границы области разрешенной памяти, наличие памяти ключей защиты, применение уровней привилегий.
4.Привилегированные команды, которые могут выполняться только на определенных уровнях или при двух уровневой организации в состоянии системы “супервизор”.
5. Средства отсчета времени, которые предназначены для управления выполнением задач в процессоре. Эти средства позволяют контролировать и выделять кванты времени на выполнение задач на аппаратных ресурсах, Супервизор обрабатывает прерывания от таймера, контролирует затраченное время работы процессора по выполнению той или иной программы и по истечении временного кванта размещает на аппаратных ресурсах другую задачу.
Уровни привилегий.
Идея использования уровней привилегий для защиты областей памяти в мультипрограммном режиме была еще реализована в архитектурах ЭВМ второго поколения. Концепция эта используется в современных микропроцессорах, примером тому может быть архитектура микропроцессоров фирмы INTEL, и была реализована в аппаратных средствах механизма сегментации, который помимо использования уровней привилегий для защиты памяти имеет дополнительные возможности и средства ,которые мы и рассмотрим .
Механизм сегментации является основным программно- аппаратным средством защиты информации в системной памяти микропроцессоров фирмы INTEL.
При использовании сегментации памяти каждая программа имеет свой собственный набор сегментов, размещаемых в линейном адресном пространстве .Процессор устанавливает границы между этими сегментами, таким образом исключая возможность вмешательства одной программы в другую. Механизм сегментации позволяет классифицировать сегменты по типу и набору разрешенных операций производимых в границах сегмента, то есть расширяет набор средств защиты памяти.
Все сегменты внутри системы содержатся в линейном адресном пространстве. Для локализации байта в конкретном сегменте должен быть сформирован логический адрес, состоящий из селектора сегмента и смещения. Селектор сегмента является уникальным идентификатором, определяющим смещение в дескрипторной таблице, указывающим на местонахождения в ней дескриптора сегмента. Каждый дескриптор определяет размер сегмента ,тип сегмента, права доступа, уровень привилегий, местонахождение первого байта в сегменте (называемым базовым адресом сегмента)
Смещение сегмента складывается со значением базового адреса для определения положения байта внутри сегмента, эта сумма называется линейным адресом.
Процессор транслирует каждый логический адрес в линейный.
Трансляция логического адреса в линейный адрес производится в три этапа.
Использует смещение в селекторе сегмента для локализации дескриптора сегмента в глобальной или локальной (задачи) дескрипторной таблице и читает содержимое дескриптора в свои регистры.
Осуществляет контроль дескриптора сегмента с целью проверки прав доступа к сегменту и проверяет значение смещения с пределом, указывающим размер сегмента.
Производит сложение адреса из дескриптора со смещением ,если не обнаружено нарушение защиты, то есть формирует логический адрес.

На данной схеме изображены два независимых этапа преобразования логического адреса в физический адрес: сегментация и страничное преобразование. Как видно из схемы сегментация адресов в процессоре не связана с режимом виртуализации системной памяти и полностью возложена на этап страничного преобразования ,то есть механизм сегментации задействован всегда и в том случае, когда страничное преобразование не используется линейный адрес становится физическим автоматически.
Следует отметить, что в некоторых архитектурах сегментация памяти используется как начальный или промежуточный этап преобразования логического адреса в физический. Примером тому архитектура процессоров фирмы IBM.
3.Понятие задачи, структура задачи, структурные данные для управления задачи.
4.Механизм, обеспечивающий переключение выполнения задач в мультипрограммной среде вычислительной системы.
Для организации мультипрограммного режима работы вычислительной системы ее архитектура содержит аппаратно программные средства ,как уже упоминалось выше.
Для того чтобы рассмотреть подробно организацию выполнения задачи, переход от одной задачи к другой в качестве примера рассмотрим, как это реализуется в механизме переключения задач в процессорах INTEL.
Архитектура процессоров INTELв составе имеет блок сегментации, который в свою очередь не только организует механизм защиты доступа ко всем структурным данным, расположенным в виртуальной памяти, но и реализует доступ к ним в соответствующих сегментах. Поэтому,
переключение задач , cвязанное с доступом к памяти также использует блок сегментации , используя при этом соответствующие структуры системных данных и дескрипторы, определяющие их специфику и расположение в виртуальной памяти.
И так прежде чем рассматривать работу этого механизма, сформулируем определение задачи , ее структуру и структуры системных данных для ее управления.
Задача – это единица работы которую процессор может активизировать ,выполнять и задержать выполнение.
Эта структура может быть использована для выполнения программы, задания или процесса, сервисной утилиты операционной системы ,обработки прерывания или исключения.
При работе процессора в защищенном режиме все действия процессора трактуются как действия внутри задачи то есть в самом простом варианте функционирование системы представляется как выполнение, по крайней мере одной задачи. В случае выполнения нескольких задач включается программно аппаратный комплекс для их переключения.
Структура задачи.
Задача состоит из двух частей:
область выполнения
сегмент состояния задачи
Область выполнения включает сегмент кода, сегмент стека один или более сегменты данных.
Сегмент состояния задачи используется для ее выполнения и является местом записи ее текущего состояния при переключении в мульти программном режиме.
Состояние задачи определяется:
областью текущего выполнения, которая представлена сегментными селекторами в сегментных регистрах
состоянием регистров общего назначения
состоянием регистра флагов
состоянием управляющего регистра, в котором хранится физический адрес каталога страниц
содержимым регистра задачи
содержимым регистра локальной дескрипторной таблицы, в котором находится селектор, указывающий на строку в глобальной дескрипторной таблице . В этой строке размещается базовый адрес локальной дескрипторной таблицы , оформленной как системный сегмент.
Базовым адресом карты ввода вывода
Звеном к предыдущей задаче
Стеком указателей к уровням привилегий 0,1, 2
Структуры данных для управления задачи представлены
Сегментом состояния задачи
Дескриптором шлюза задачи
Дескриптором сегмента состояния задачи
Регистром задачи
Флагом вложенной задачи в регистре флагов
Сегмент состояния задачи
Информация состояния процессора необходимая для восстановления задачи при переключении хранится в сегменте состояния задачи, в который эта информация была записана ранее в момент прерывания.
Помимо выше указанной информации о состоянии задачи в сегмент состояния задачи записывается адрес текущей инструкции и содержимое регистра флагов.
Рассматривая в свое время многоуровневую организацию памяти в вычислительной системе , мы отметили об использовании виртуальной памяти как об одном из средств поддержки организации мультипрограммного режима в системе. Мы уже говорили ранее, что при использовании технологии виртуализации системной памяти используется механизм преобразования логических адресов в физические. Следует помнить, что в архитектуре процессоров фирмы INTELблок сегментации не является частью механизма преобразования логических адресов памяти в физические. Он является частью аппаратных средств системы для организации сегментированной виртуальной памяти, в которой она представлена системе набором сегментов - непрерывных областей памяти различного размера, доступ к которым осуществляется через дескрипторы, организованные в таблицы.
Доступ же к ним осуществляется через селекторы, которые находятся в соответствующих регистрах сегментов кода, данных и стека.
Мы еще будем разбирать , когда и каким образом селекторы загружаются в соответствующие регистры сегментов, а сейчас разберем форматы и типы дескрипторов.
Код тип дескрипторов
11.10.98
0 0 0 0 – резерв.
0 0 0 1 – 16 бит. TSS(доступен)
0 0 1 0 – LDT
0 0 1 1 – 16 бит. TSS(занят)
0 1 0 0 – 16 бит. Шлюз вызова
0 1 0 1 – шлюз задачи
0 1 1 0 – 16 бит. Шлюз прерыв.
0 1 1 1 – 16 бит. Шлюз пов.
1 0 0 0 – резерв.
1 0 0 1 – 32 бит. TSS(доступен)
1 0 1 0 – резерв.
1 0 1 1 - 32 бит. TSS(занят)
1 1 0 1 – резерв.
1 1 1 0 - 32 бит. Шлюз. прерыв.
1 1 1 1 - 32 бит. Шлюз пов.
Типы системных дескрипторов.
Когда S( тип дескриптора ) установлен в дескриптор является системным.
Процессор распознает следующие типы дескрипторов.
дескриптор LDT
дескриптор TSS
дескриптор шлюза вызова
дескриптор шлюза ловушка
дескриптор шлюза задачи
дескриптор шлюза прерывания
Эти дескрипторы разделяются на 2 категории:
Системные дескрипторы, указывающие на вход к системным сегментам ( LDTиTSS)
Дескрипторы шлюзов, которые содержат сами указатели к точкам входа в процедурах в сегментах кода и селектора их дескриптора.
Дескрипторные сегментные таблицы – область сегментных дескрипторов. Дескрипторная таблица может быть различных размеров и может содержать до 8192 (2^13) 8 байтные дескрипторов.
Различают 2 вида таблицы LDTиGDT. Каждая система должна иметь однуGDT, которая может быть использована для всех программ и задач в системе, в то время как одна или большеLDTможет быть определено. НапримерLDTможет быть назначена для каждой отдельной задачи или несколько задач могут иметь ту же самуюLDT.GDTне является сама сегментом, т.е. она является структурой данных в линейном адресном пространстве. Базовый линейный адрес и пределGDTдолжен быть выровнен по 8 байтной границе. Величина предела дляGDTвыражается в байтах также как и для сегментов.Limit+ база адрес определяет послед байт достоверный в таблице.
Величина лимита=0 соответствует 1 байт, поэтому т.к. дескриптор сегмента 8 байт, предел GDTдолжен быть на 1 меньше т.е. 8N-1.
Все программы, выполняющиеся в системе могут использовать эту таблицу для обращения к сегментам памяти. Для локализации таблицы предназначен специальный регистр GDTR, в котором находится 32-х битное поле линейного базового адреса таблицы
1ый дескриптор в GDTне используется в процессоре. Селектор сегмента для этих «нулевых» дескрипторов не генерирует исключения, когда загружен в регистр сегмента данных (DS,ES,FS,GS), но всегда генерирует исключение в защищенном режиме, когда делается попытка доступа к памяти, используя дескриптор.
LDTразмещается в системном сегменте поэтомуGDTдолжна содержать сегментный дескриптор дляLDTсегмента. Если система поддерживает несколькоLDT, каждая таблица должна иметь отдельный селектор сегмента и сегментный дескриптор вGDT. Сегментный дескриптор дляLDTможет быть размещен в любом местеGDT.
LDTдоступна через ее селектор, базовый линейный адрес, предел, права доступа.
Дескриптор LDT
|
База сегм. 15:-0 |
Lim 15:-0 |
G P тип
-
База 31:-24
0
0
0
Lim 16:-19
DPL
База 16:-23
Поле DPLв дескрипторе дляLDTне используется.
И так при переключении задач для доступа к сегментам состояния задач имеется два вида дескрипторов.
Дескриптор сегмента состояния задачи является прямым указателем на расположение сегмента состояния задачи в линейном адресном пространстве виртуальной памяти и соответственно содержит адрес начала сегмента в памяти.
Дескриптор шлюза задачи является элементом косвенной адресации при обращении к сегменту состояния задачи.
Введение дополнительного этапа адресации объясняется следующими причинами.
Во первых, дескрипторы сегментов состояния задач могут находиться только в глобальной дескрипторной таблице и обычно имеют наивысший уровень привилегий (DPL=0).
Для того, чтобы структура задачи могла использоваться на других уровнях привилегий и при обработки прерываний и исключений и программах пользователей и был введен этот дополнительный этап, то есть дескриптор шлюза задачи содержит селектор, который указывает на строку с дескриптором сегмента состояния задачи в глобальной таблице.
Во вторых дескриптор шлюза задачи имеет свой уровень привилегий и при обращении к нему действует механизм защиты
[CPL,RPL]<,=DPLшлюза задачи
Таким образом, операционная система, располагая дескрипторы шлюзов задач с одним и тем же значением селектора может организовать доступ к одной задаче с разных уровней привилегий и расположить эти дескрипторы не только в глобальной таблице , но и локальных и таблице прерываний потому что при обращении к дескриптору состояния задачи через шлюз проверка уровня DPLдескриптора сегмента состояния задачи блокируется.
Регистр задачи.
Регистр задачи предназначен для хранения 16 битного селектора сегмента состояния задачи во время ее выполнения в процессоре причем значение селектора сегмента состояния задачи является видимой частью регистра то есть доступной для чтения и изменения программным обеспечением , а невидимая его часть, которая доступна только аппаратным средствам, предназначена для кэширования самого дескриптора сегмента состояния задачи .
Дав определение задачи, как единице работы, следует помнить что понятие задачи классифицирует процесс в вычислительной системе не с точки зрения объема и сложности выполняемых вычислений ,а cточки зрения цели, поставленной при постановке задачи. Поэтому, в зависимости от сложности задачи она может быть представлена одной или несколькими программами и даже состоять из нескольких функциональных модулей, сформированных в виде самих задач.
Связь между этими блоками во время выполнения задачи осуществляется через аппаратно-программный интерфейс , активизируемый системными командами CALLиJMP
Передача управления от одного сегмента к другому осуществляется и внутри задачи через дескрипторы сегментов, поэтому для передачи управления от одной задачи к другой используются специальные дескрипторы, классифицируемые как системные данные для управления задачами.
Для того, чтобы осуществлять связь между модулями внутри задачи оформленными в свою очередь как самостоятельные задачи, вводятся аппаратные средства в виде флагов, указывающих на вложенность одной задачи в другую.
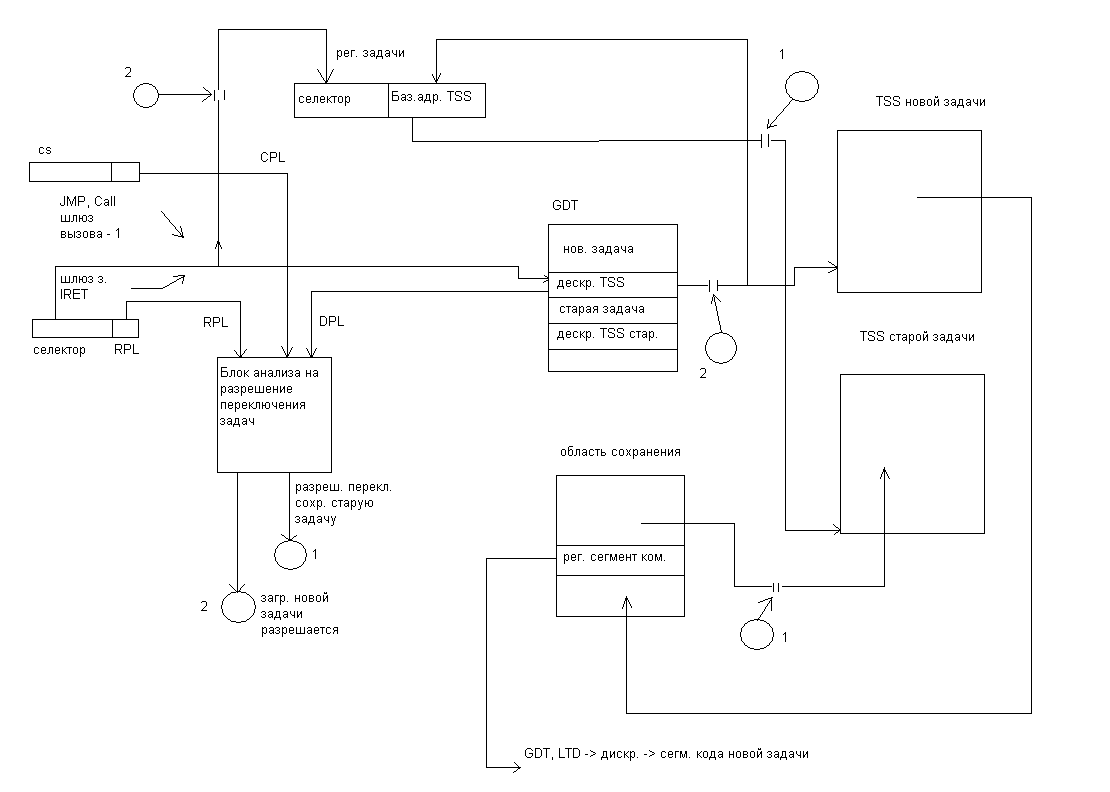



Переключение задачи.
Процессор выполняет следующие операции при переключении к новой задаче.
Получает селектор сегмента для нового задания как операнд команд УМР, или CALL, или из шлюза задачи или по командеIRET(возврата).
Проверяет, что текущей задаче разрешено переключение к новой задаче. Управление привилегиями доступа к данным контролирует исполнением JМР, иCALLинструкции (доп.п.2)CPLтекущей задачи иRPLселектора сегмента (для нового задания должны быть меньше чем величинаDPLв дескрипторе)
Исключения, прерывания (за исключением прерываний генерируемых командой INTn) и командаIRETвыполняют переключения независимо отDPL, указанных в шлюзе или дескриптореTSS.
Проверяется, что дескриптор TSSнового задания отменен как присутствующий и значения пределаnoneLimit=>67.
Контролируется, что новое задание доступно (Call, УМР, прерывание или исключение)
Проверяется, что текущее TSS, новыеTSSи все дескрипторы сегментов используемые при переключении находятся в системной памяти.
Если переключение было инициировано УМР или IRET, процессор устанавливает битBUSY(занято) в О. в текущем дескриптореTSSзадачи. Если инициировано командойCALL, исключением или прерыванием «В» флаг (занято) остается установленным.
Если переключение было инициировано IRET, процессор чиститNTфлаг во времени регистре Флагов, если инициированоCALLилиJМР, исключением или прерываниемNTфлаг не изменяется.
Сохраняется состояние текущей задачи в текущем сегменте TSS. Процессор находит базовый адрес текущего сегментаTSSв регистре задачи и затем копирует состояние следующих регистров в текущий сегментTSS: регистры общего назначения, селекторы сегментов из сегментных регистров, регистр флагов, регистрIP.
Если переключение было инициировано CALLинструкцией, исключением или прерыванием процессор устанавливаетNTфлаг в регистре флагов сохраняемом вTSSнового задания если инициированоIRET, процессор восстанавливаетNTфлаг из регистра Флагов сохраняемом в стеке. Если инициированоJМР,NTфлаг остается без изменения.
Если переключение задания было инициировано CALL,JМР, исключением или прерыванием процессор устанавливает В (занято) в новом дескриптореTSS, если инициироватьIRETВ (занято) остается установленным.
Устанавливает TSSфлаг в управляющем регистреGROс целью дать возможность устройству с плавающей точкой не прерывать работу при переключении задачи, а в случае необходимости т.е. операцииFPOв новой задаче доступ кFPOбудет осуществлен только через исключениеNH(TS=1 запрещ.FPO), которое вызовет образование этого исключения, в котором используя системную командуCLTS, установит битTSвGROв «О» сохранит состояниеFPO, и даст возможность выполнить операцииFPOв новой задаче.
Загружает регистр задачи селектором сегмента и дескриптор для нового TSS/
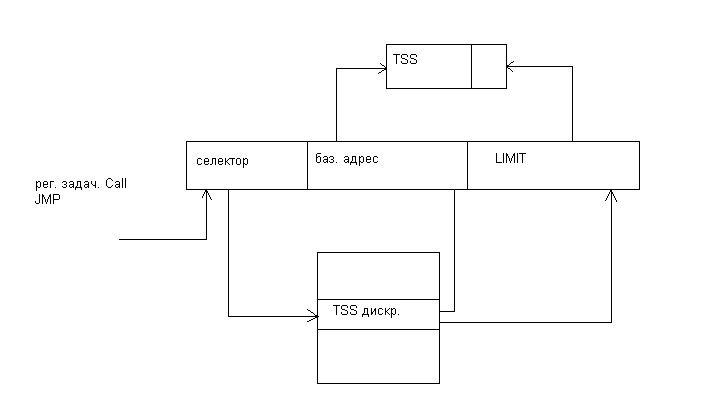
Загружает новое состояние из TSSв процессор. Любая ошибка, соответствующая загрузке квалифицируется в контексте новой задачи.
Начинается выполнение нового задания.
 .
.
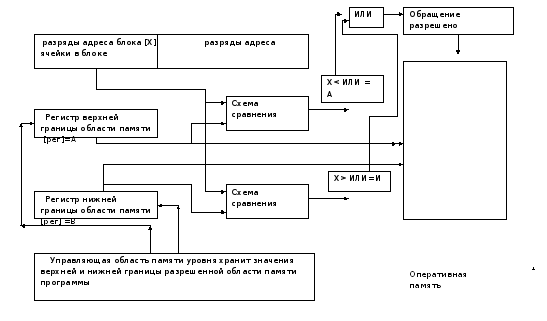
Лекция N10.
Тема лекции: Организация ввода вывода. Общие положения.
1.Введение.
2.Требования и задачи, решаемые при проектировании системы ввода вывода.
3 Состав, характеристики системной шины и способы организации межблочных связей в ЭВМ.
4. Функционирование системной шины и эволюционное развитие ее архитектуры
Система ввода вывода, являясь неотъемлемой частью любой вычислительной системы, также как процессор и память прошла эволюционный путь развития.
Структура системы ввода вывода, представляющая программно-аппаратный комплекс, определяется и проектируется с учетом выполняемых задач то есть назначения вычислительной системы .
В состав аппаратной части системы ввода вывода в зависимости от концепции, положенной в ее организацию входят: периферийные устройства (ПФУ), интерфейсы, часть оборудования процессора или каналы ввода вывода. Каналы ввода вывода по сути являются специализированными процессорами назначение которых- это управление операциями ввода вывода в системе, включая не только передачу данных но и анализ состояния устройств до начала и после операций ввода вывода и передача информации о состоянии устройств через механизм прерывания программному обеспечению системы.
По мере смены поколений ЭВМ изменялась элементная база, состав и назначение ПФУ, виды носителей информации и методы доступа к ним.
На смену бумажным носителям в виде перфокарт и перфолент пришли носители в виде магнитных лент и дисков, последние дали возможность прямого доступа к данным, замены последовательного метода, применяемого при использовании магнитных лент.
Cпоявлением многопрограммного режима и внедрением операционных систем для управления вычислительным процессом появился класс активных внешних устройств, предназначенных для работы оператора ЭВМ.
С внедрением режима диалога, пришедшего на смену пакетной обработке информации, появились внешние устройства, дающие возможность программисту (пользователю) непосредственно иметь связь с системой а не через оператора, как это делалось при пакетной обработке, предоставляя ему инструкции по выполнению задания и исходные данные на носителях.
Таким образом, было расширено операционное поле класса активных внешних устройств.
Для вычислительных систем, работающих в реальном режиме времени, используемых для управления технологическими процессами были разработаны устройства с преобразованием аналоговых сигналов в цифровые и наоборот. А для создания распределенных вычислительных систем были разработаны устройства ,осуществляющие прием и передачу информации в ЭВМ из каналов связи. В дальнейшем на их базе были созданы телепроцессоры ,которые кроме преобразования и согласования интерфейсов ЭВМ с каналами связи стали выполнять и программную обработку данных.
Несколько слов следует сказать о классе внешних запоминающих устройств ,которые в качестве носителей используют магнитные ленты и диски. От начала использования этого вида внешних устройств до настоящего времени произошли большие изменения как в объеме хранимой информации ,так и в скоростях обмена ей между внешними устройствами с процессором и памятью
Если ,например, плотность записи на магнитную ленту была в начале только десятки символов на 1мм при использовании технологии NRZи достигла значения 256 символов на 1мм при фазовом кодировании и за счет аппаратных преобразований дополнительно при методе группового кодирования до ……. То современные методы записи и соответствующая технология изготовления носителей позволяет размещать на 1мм единиц(бит) информации что позволяет на катдридже с размером
и длиной носителя в метров размещать 500Гбт.
А емкость одного жесткого диска входящего в состав дисковой подсистемы DS8300 равна146Гбт общее количество в подсистеме может достигать до и соответственно емкость всей системы может составлять до
Естественно, с увеличением объемов хранимой информации на внешних носителях и увеличения частоты работы процессора и памяти потребовалось увеличения пропускной способности системы ввода вывода ,которую не могли обеспечить интерфейсы, базирующиеся на передаче электрических сигналов по параллельным линиям связи . Так на смену параллельным каналам, связывающим периферийные устройства с остальными частями вычислительной системы , пришли последовательные с использованием оптических линий связи.
Многообразие функциональных устройств различных по принципу действия и назначению потребовало внедрения специальных промежуточных аппаратных средств, которые должны были функционировать по единым правилам и протоколам, определяющим как физические параметры сигналов, поступающих во внешние устройства и выходящих из них и алгоритмы, определяющие логические связи внешних устройств с вычислительной системой. Эти промежуточные аппаратные средства называются контроллеры внешних устройств, которые конструктивно выполняются или в отдельных стойках или могут быть реализованы в виде функциональных блоков, входящих в состав ПФУ.
По своим функциональным возможностям ПФУ можно разделить на “ быстрые”и “медленные”cточки зрения скорости приема и передачи данных в вычислительной системе. Поэтому при организации системы ввода вывода учитывается этот фактор. Внешние устройства объединяют в группы с соизмеримыми скоростями приема/передачи данных, разрабатывая для каждой группы свой протокол, представляющий комплекс аппаратных и микропрограммных средств.
Одной из основных концепций организации вычислительной системы - выбор управления основными информационными потоками. Это двунаправленные потоки: процессор-память, внешнее устройство-память и процессор -внешнее устройство.
В зависимости от выбранной стратегии первоначально исторически сложились две структуры организации ввода вывода.
1.Процессор ввода вывода.
2.Общая шина.
Эти два альтернативных направления организации ввода вывода использовались первоначально в вычислительных системах различного назначения.
Процессор ввода вывода или по другому каналы ввода вывода стали использовать в системах с большим количеством разнотипных внешних устройств. В системах в основном коллективного пользования с большими объемами обрабатываемых данных и работающих в многопрограммном режиме.
Системы с “общей шиной”были характерны для малых и микромашин с малым набором устройств.
Суть различия заключалась в следующем.
Все функции по управлению потоками в системах с “общей шиной” осуществляются процессором.
В системах с канальной организацией функции управления потоками распределены между процессором и каналами.
Концепция каналов ввода вывода состоит в том ,что процессор участвует только в инициализации операции ввода вывода, передавая основные функции по управлению и передачи информации в потоке внешнее устройство <->память специализированному процессору ввода вывода, освобождая себя на момент обмена внешнего устройства с памятью для других работ.
Канал осуществляет прием/передачу данных в память, контролирует ход выполнения операции ввода вывода согласно канальной программе, расположенной в оперативной памяти, на местонахождение которой указывает ему процессор. Контролируя ход выполнения операций ввода вывода, по ее окончанию канал формирует признак результата в виде байт состояний канала и устройства ,организуя запрос на прерывание ввода вывода в процессор ,который в свою очередь должен это прерывание обработать.
Что касается объединения разных устройств по скорости обмена данных в группы, то канальной системе это реализуется путем организации каналов разного типа, работающих соответственно по своим алгоритмам или выбором режима канала.
Структура системной шины, как было отмечено выше, первоначально была характерна для систем с малым набором ПФУ. В таких системах всеми операциями ввода вывода управлял процессор, используя для этого циклы шины обращения к внешним устройствам и останавливая выполнение программы на время обмена с внешним устройством. Обмен производился побайтно, то есть для передачи приема каждого байта из процессора во внешнее устройство или приема из него инициировалась соответствующая команда обмена.
В дальнейшем для ускорения процесса обмена стали применять так называемые строчные команды , реализующие обмен массива данных и технологию прямого доступа к памяти , используя в последнем случае специальный контроллер прямого доступа к памяти на шине, который в общем то выполнял функции каналов ввода вывода только в приеме передачи данных. Контроль же за окончанием и ходом выполнения операций ввода вывода оставался за процессором.
Характеризуя современное состояние системы ввода вывода в вычислительных системах можно отметить следующее.
Системы, родоначальники которых имели организацию ввода вывода ‘общая шина’, в настоящее время, используя технологию прямого доступа к памяти, имеют возможность организации множественных потоков информации без непосредственного участия процессора, оставляя ему функцию инициализации.
Что же касается контроля за выполнением операции ввода вывода он возложен на контроллеры шины, которые контролируют текущее состояние операции и формируют запросы на прерывание в процессор в случае сбойных ситуаций и по ходу выполнения операции, принимая от внешних устройств соответствующие сигналы..
По сути ‘общая шина’ трансформировалась в канальную архитектуру только с распределенными аппаратными ресурсами на шине и не используя технологию канальных программ для обмена.
Что касается организации канальной системы, то она подверглась также модернизации и эта модернизация коснулась в первую очередь способа адресации внешних устройств, используя при этом принцип логической адресации благодаря вводу сетевых технологий для связи процессорного ядра с внешними устройствами.
В канальную систему стали внедрять технологию прямого доступа к системной памяти, таким образом, освободив канал от выбора канальной программы и дав возможность использовать очереди запросов за данными, сформированными процессором ввода вывода под управлением супервизора операционной системы.
Информацию о расположении очередей запросов канал берет из подканала, содержимое которого формируется для каждого конкретного устройства в памяти процессора.
Канальная система не отказалась полностью от применения канальных программ и продолжает их использовать для анализа состояния внешнего устройства и передачи в него управляющей информации а передачу и прием данных осуществляет как сказано выше через технологию прямого доступа к памяти
Сохранив структуру подканалов канальная система стала использовать их , для хранения адресов ячеек памяти, в которых хранятся адреса данных для обмена с внешними устройствами как это было ранее с той лишь разницей, что раньше чем загрузить адрес данных в подканал необходимо было выбрать командное слово канала каждый раз при цепочке команд, а при прямом доступе к памяти этого не надо делать
2.Требования и задачи , решаемые при проектировании ввода вывода.
При проектировании системы ввода вывода необходимо решить следующие задачи:
- должна быть обеспечена реализация системы с переменным составом оборудования
- для высокопроизводительного использования оборудования целесообразно организовать параллельную работу процессора и устройств ввода/вывода
-необходимо упростить для пользователя и стандартизировать программирование операций ввода вывода ; обеспечить независимость программирования от особенностей того или иного оборудования
-необходимо обеспечить автоматическое распознавание и реакцию процессора на многообразие ситуаций возникающих в устройстве
Способы и пути решения задач.
Для упрощения и стандартизации программирования операций ввода вывода необходимо использовать унифицированный формат данных, передаваемых в устройство, а преобразование унифицируемого формата в индивидуальные для каждого внешнего устройства осуществлять в самом устройстве, что дает возможность шинной организации интерфейса, связывающего внешнее устройство с процессором
Модульность, которая обеспечивает присоединение новых устройств .без существенных изменений, кроме кабельных соединений и некоторых изменений в конфигурации системы решает вопрос о возможности масштабировании системы.
Использование прямого доступа к памяти со стороны внешнего устройства и каналов ввода вывода решает вопрос о параллельной работе процессора и системы ввода вывода.
Автоматический контроль хода выполнения операций ввода вывода решается как аппаратными так программными средствами с и использованием системных команд и механизма прерываний.
3.Основные характеристики системы ввода вывода
Основными характеристиками системы ввода вывода являются:
-время выполнения операции
-пропускная способность
Время выполнения операции ввода вывода может быть разделено на четыре составляющие:
-время доступа
-время устройства или контроллера
-время передачи данных
-время завершения операции
Время доступа- время необходимое каналу контроллеру и устройству стать доступным иначе это время необходимое каналу или системе для посылки команды в устройство
Время контроллера и устройства- время необходимое контроллеру и устройству для подготовки операции передачи данных Например, для дискового контроллера ,не имеющего кэш, это время будет определяться временем установки головки записи / считывания перед тем как начать чтение или запись данных.
Последние две составляющие комментарий не требуют.
Факторы влияющие на составляющие времени выполнения операции ввода вывода:
-синхронный или асинхронный режим работы системы ввода вывода
-скорость передачи данных
-расстояние
-характеристики подключаемого устройства
-характеристики канальных программ для организации операций ввода вывода
Синхронный тип операций требует чтобы канал , контроллер и устройство были активными в одно и тоже время
Например, в дисковой подсистем все действия связанные с окончанием операции и получением следующих данных должны быть завершены, перед тем как головка дисковода достигнет следующей записи. Если этого не произойдет, синхронизатор позиционера сгенерирует промах или переполнение. Выполнение следующей операции будет задержано.
Асинхронный тип операций.
В этом режиме канал, контроллер и устройство могут быть не активными в одно и то же время для выполнения операции ввода вывода ,этот режим дает возможность разнесение каналов и контроллеров на более дальние расстояния, уменьшать время ответа, разрешать каналу выполнение других операций в течение времени ожидания для устройства.
Характеристики устройств- к в ним относят дополнительные аппаратные средства в виде буферов для хранения данных и КЭШей, которые позволяют увеличить скорость передачи данных.
Характеристики канальных программ влияют на время выполнения операций ввода вывода. Так, например, канальные программы, в которых используется косвенная адресация , команды перехода в канале или цепочки команд увеличивают время ответа в подканале.
Цепочки команд увеличивают время ответа за счет увеличения времени передачи данных из за блокировки в канале между
состояниями “ канал кончил”и “устройство кончило “
3. Системная шина включает в себя:
- кодовую шину данных (кшд), содержащую провода и схемы сопряжения для параллельной передачи всех разрядов числового кола (команды, операции).
- кодовую шину адреса (кша) для передачи всех разрядов кода адреса ячейки основной памяти и порта в/выв В.У.
- кодовую шину инструкции содержащую провода и схемы для передачи управляющей информации между блоками ЭВМ (процессор – память, процессор – В.У.).
- шину питания.
Системная шина обеспечивает следующие направления связи:
Процессор ↔ память
Процессор ↔ в/выв
Память ↔в/выв
Вычислительная система (ЭВМ) компьютер состоит из множества отдельных подсистем (блоков, узлов, между которыми постоянная в процессе функционирования информационная связь. Так вот для осуществления этой связи существует совокупность средств сопряжения, которая называется интерфейсом или системой интерфейсов.
Различают внутри машинный интерфейс и внешний.
Внутри машинный интерфейс – система связи и сопряжения узлов и блоков компьютера между собой. Представляет из себя совокупность микросхем, линий связей, схем сопряжения, компонентов ЭВМ протоколов передачи и преобразования информации.
Существуют два варианта организации внутри машинного интерфейса.
а) многосвязный интерфейс – каждый отдельный функциональный блок соединен с другим локальными линиями связи. Такой тип связи был характерен для ЭВМ на начальном этапе и в последующем использовался в майнфреймах (больших машинах) для организации межблочных связей. Присутствует также в и в П.К. для высокоскоростной связи между процессором и КЭШ. Применялся в свое время в машинах 1ых, 2ых, 3их поколений для связи с внешним устройством.
Радиальный интерфейс (М32, CDCSYBER).
Односвязный интерфейс – все блоки связаны друг с другом через общую шину. Такая связь характерна была для микро и мини ЭВМ. В дальнейшем была использована в архитектуре П.К. имеющих малые количества агентов (включая В.У.), которые поддерживают общий протокол передачи информации.
В части функционирования, шины делятся на две подгруппы связанные с передачей данных:
Шины с коммутацией пакетов (мультипл. режим).
Шины с коммутацией цепей (монопольный селектор. режим).
Режим с коммутацией пакетов характеризуется разделением транзакций на две части (фазы). Во времени: фазы запроса и фазы передачи информации. Шины с коммутацией цепей характерны тем, что транзакция не разделяется на фазы и остаётся в распоряжение приемника и передатчика на весь временной цикл обмена.
Данная схема представляет реализацию последовательного опроса, где приоритетом пользуется устройство, расположенное ближе к арбитру.
Чтобы обойти такую систему в некоторых шинах устраивают несколько уровней приоритетов. На каждом уровне есть линия запроса шины, и линия представления шины. Если одновременно запрашиваются несколько уровней приоритета, арбитр представляет шину самому высокому уровню. Среди устройств одинакового приоритета используется система последовательного опроса.
На этой схеме приоритет 2,4>1,3

Арбитраж.
Как следует из вышесказанного, когда на шине присутствует несколько устройств, обладающих способностью выступать в качестве задающих, и появляется несколько запросов от них на владение шиной, необходим механизм арбитража, т.е. необходима схема, узел, блок, устройство, которое выполняло бы эту функцию.
Существует 2 метода решения этой проблемы- централизованный и децентрализованный
Централизованный арбитраж.
Функцию арбитража берет на себя отдельное выделенное устройство( блок внедренный в процессор или контроллер на шине). Все абоненты шины выставляют запросы, а арбитр согласно алгоритму представляет право на владение шиной. Примером централизованного арбитража можно привести шину PCI, прерыв. наISAобработка запросов на прерыв и обмен данных в интерфейсе в/выв ЭВМ.

Децентрализованный арбитраж.
В этом случае, если устройству нужна шина он запускает свою линию запроса. Все устройства контролируют все линии запроса, поэтому в конце каждого цикла шины, каждое устройство может определить, обладает ли оно в данный момент высшим приоритетом и следовательно разрешено ли ему пользоваться шиной в следующем цикле.
При другом типе арбитража используется только 3 линии независимо от устройств
Чтобы получить доступ к шине, устройство проверяет, свободна ли шина и наличие 1 на вх. IN, еслиIN= 0, устройство не может стать задающим, в этом случае устанавл. свой выход. сигналOUT:=0. ЕслиIN=1, то в этом случаеOUT:=0 и устанавливается сигнал «Занято». Данная схема подобна системе последовательного опроса, где сигнал представления шины арбитром заменен нач.1 (+5в) приоритетней будет устройство польз. крайнее левое устройство.

2. Как было указано ранее шинная организация межблочных связей в архитектуре ЭВМ проявилась как альтернативный вариант многосвязному интерфейсу и была применена в системах относительно простых с малым количеством агентов в мини и микро ЭВМ . Эта технология была использована в архитектуре ПК. Следует помнить, что системная шина или “общая шина” это не просто набор проводников по которым передаются данные, адрес, управляющие информацией. Это целый комплекс аппаратных средств, предназначенных для управления движением этих потоков и надежной их передачи от задающего устройства к приемнику и наоборот. В состав этих аппаратных средств входят усилители, приемники, буферные регистры (защелки) и коммутаторы, управляющие информационными потоками во время цикла шины. Компьютер (ЭВМ) или В.С. представляет комплекс подсистем различного характера (устройств) поэтому системная шина “разбита” на группы локальных шин, отделяющих группы однородных устройств. Системная шина представляла набор локальных шин. Локальная шина процессора, системная шина для подключения ВУ и локальная шина памяти.
Для управления транзакцией на шине в комплексе аппаратных средств имеется контролер шины, т.е. процессор не формирует управляющие сигналы шины, он только выдает код транзакции (тип цикла), а контролер шины реализует его на шине. Такова была архитектура шины ISAв первых компьютерах и шинах «МУЛЬТИБАС».

Функционирование системной шины
Функционирование системной шины определяется ее протоколом, устанавливающим правила, по которым которые должны выполнять все агенты шины. Правила эти устанавливают нормы и требования, представляемые как физическому, так и микроархитектурному уровню. Требования к физическому уровню определяют физическую среду и параметры передаваемых сигналов: амплитуда, длительность, частота, временная задержка.
Микроархитектурный уровень определяет структуру шины, это аппаратные средства реализующие логику взаимодействий агентов при обмене информацией (протокол).
функционирование во времени шины представляет из себя циклы, которые определяют вид и характер взаимодействия и агентов, участвующих в этот промежуток времени. Чем шире функциональные возможности шины, тем больше набор всевозможных циклов, называемых транзакциями. Как мы увидим, в дальнейшем эволюционное развитие структуры шины привело к ее конвейерной организации и внедрения многопотокового режима . Примером является шина pentium 2 с ее конвейерной организацией, заключающейся в том, что все управляющие сигналы разделены на независимые группы, которые позволили разделить циклы шины на отдельные фазы, что и позволило совмещать во времени выполнение последовательность циклов.
Данная структура системной шины (ISA) позволила организовать обмен
Процессор - память
Процессор – ВУ
Память – ВУ
Для осуществления последней связи в группе устройств на системной плате присутствует контролер ДМА 8237. Основная его задача - управлять обменом между памятью и ВУ, «подменяя» контролер шины для циклов процессор – ВУ, чтобы выдавать управляющие сигналы в память и ВУ во время обмена, при этом активизация этого контролера ДМА и передача шины под его управлении возможна только с разрешения процессора.
Для организации связи процессор – ВУ, помимо использования команд в/выв (программируемый в/выв), на шине функционирует механизм прерываний, реализованный в контроллере прерываний, находящемся в группе устройств на системной шине.
Именно этот контролер после его инициализации со стороны процессора берет на себя функции обработки запросов на прерывания от ВУ к процессору, формируя «вектора прерываний», представляющих из себя адреса памяти в которых находятся адреса обработчиков прерываний.
Эволюция системной шины была связана не только с технологическими аспектами, которые позволили объединить отдельные микросхемы в СБИС с целью повышения производительности системы за счет увеличения частот (связи СБИС), а в основном за счёт изменения концепции протокола системной шины, а именно организация параллельных процессов передачи и обработки информации в системе. Главная концепция - прямой доступ к памяти, заложенная ещё в ISAнашла своё дальнейшее развитие в протоколе шиныPCI, первоначально спроектированной как шина для периферийных устройств, которая в дальнейшем заняла ведущее место на системной шине за счёт технологии ДМА, и так называемойPnP, с использованием циклов конфигурации (настройка системы во время инициализации) в современных архитектурах. а также и за счет организации многопоточного режима на шине




 время доступа время
устройства время передачи
время завершения
время доступа время
устройства время передачи
время завершения
 и
контроллера данных операции
и
контроллера данных операции




время время
о



 жидания
обнаружения
жидания
обнаружения







 критическое время
критическое время
задержка доступа
д
Устройство
3класса
Устройство 1класса
Время формирования последовательности
выборки устройства
Время распространения сигналов по
интерфейсу
Устройство
2класса



Ожидание обслуживания каналом и
формирование байта состояния с указателем
‘сбой интерфейса
Устройствоожидает передачу данных
Запрос на прерывание
Повтор канальной прграммы
Отключение от интерфейса, формирование
аварийного случая при обращении со
стороны канала
Канальная система характеризуется
большим количеством устройств и
параллельной работой каналов с программой
процессора
Структуры системы ввода/вывода
Общая шина характерна для систем с
малым количеством устройств, характерна
приостановкой работы процессора во
время выполнения операции в/вывода





Радиальная
сеть
Последовательное соединение
Инициализация связи с устройством
Команда ввода/вывода
Механизм прерывания
мультиплексный
Блок-мультиплексный
Фрейм-мультиплексный
Организация и виды обмена
Прямой доступ к памяти с формированием
очередей запросов
Цепочки команд и данных
Формирование кадров
Организация и виды обмена
Циклы шины
Устройство-процессор
Устройство-память
побайтно
Массив слов
Топология
Связи с устройством
Режим работы
Канальная программа













Лекция N11
Тема лекции: Канальная система ввода вывода.
Структурные элементы канальной системы ввода вывода.
Организация операций ввода вывода в каналах.
.Структура канальной системы компьютеровZархитектуры.
4. Использование принципов логической адресации в каналах, сетевых топологий в интерфейсе ввода вывода, технологии очередей и прямого доступа к памяти- основные направления модернизации канальной системы.
1. Канал- совокупность технических средств вычислительной системы, предназначенных для управления обменом информацией между внешними устройствами и оперативной памятью системы. Системная шина имеет тоже часть своего оборудования, предназначенного для выполнения операций ввода вывода, но в отличии от шины канал-это централизованная аппаратная часть системы, независимо от процессора, выполняющая выше указанные функции с одним исключением: инициализации ввода вывода остается за процессором. И это ясно почему так как управление вычислительной системы идет через процессор а точнее через выполнение команд.
Аппаратная часть канала в основном реализуется в виде автономного оборудования. В таких системах для связи с оперативной памятью требуются при выполнении операций ввода вывода только циклы связи с оперативной памятью для приема передачи данных и управляющей информации. В свое время ,в системах со средней производительностью для уменьшения стоимости системы на время связи канала с памятью использовали часть оборудования процессора и его информационных трактов.. Примером подобной архитектуры была архитектура отечественной ЭВМ среднего класса ЕС1045. В той машине была общая память микропрограмм, и канал на время микропрограммного обслуживания через механизм микропрограммного прерывания получал доступ к этой памяти. При этом устанавливался специальный бит
управления дешифрации полей микрокоманд, указывающий на работу микропрограммы канала.
В современных системах каналы ввода вывода являются не зависимыми от процессора структурами , получающими управление от управляющей программы при инициализации операций ввода вывода через специальный процессор ,который выполняя ,команду ввода вывода проверяет состояние подканала и в, случае его готовности к выполнению операции ставит запрос на ввод вывод в очередь таким образом передавая управление каналу.
Для того чтобы разобраться в работе этого механизма рассмотрим базовые положения и понятия в классической структуре канальной системы , которыми являются канальная программа, ее структура ,подканал его содержимое и назначение.
Средства канала, необходимые для выполнения одной операции ввода вывода, называются подканалом. Таким средством является область оперативной памяти системы , выделенная для хранения исходной и промежуточной информации, необходимой для выполнения операции ввода вывода. Доступ к этой памяти возможен только для команд ввода вывода со стороны процессора и со стороны канала в процессе выполнения операции. Каждая операция ввода вывода предназначена для выполнения с конкретным одним устройством в системе поэтому напрашивается вывод : для обеспечения этих операций наилучшим вариантом был бы- для каждого устройства ввода вывода иметь в памяти свою область. Но этого не делается, а точнее делается частично.
То есть в каналах ввода вывода для некоторых устройств выделяют индивидуальные области в памяти, а для других одну общую область при этом учитывается специфика самих устройств и режимы их работы.
В связи с выше сказанным ввели понятия разделенных и неразделенных подканалов.
Подканал считается неразделенным, если он используется одним устройством ввода вывода.
Подканал считается разделенным, если для выполнения операции в любом устройстве из группы используется один и тот же подканал. Рассматривая классическую архитектуру системы ввода вывода, можно отметить следующее: в свое время дисковая подсистема имела разделенный подканал , так как в специфику своей работы могла организовать обмен данными только одному дисководу из группы с памятью. А, например, устройства байт – мультиплексного канала имели неразделенные подканалы так каких контроллеры позволяли независимый обмен каждого устройства друг от друга .
Структура подканала зависит от
архитектуры системы и со временем
подверглась модернизации , как и сама канальная система, для того
чтобы проанализировать эти изменения
рассмотрим классическую его структуру.
как и сама канальная система, для того
чтобы проанализировать эти изменения
рассмотрим классическую его структуру.

Как видно из содержимого подканала в нем хранится вся необходимая информация для обмена с устройством . Нулевая ячейка не требует комментарий. В первой ячейке в нулевом байте записываются флажки CCW(командное слово канала) О командном слове канала мы поговорим позже ,разбирая канальную программу . Во второй ячейке в нулевом байте хранится ключ защиты , который является элементом механизма защиты системной памяти , который мы рассмотрим позже.
В третьей ячейке содержится указатель косвенной адресации в канале. О механизме косвенной адресации, как одном из способов обмена данными из несмежных областей памяти с устройством , vмы поговорим позже.
Канальная программа.
Если подканал хранит только информацию об контрольных точках операции ввода вывода процессора с устройством на всех этапах операции , то канальная программа детализирует эту операцию ,указывая внешнему устройству ,какие непосредственно команды он должен выполнить, Если на общей шине направление передачи информации между процессором и устройством осуществляется через команду ввода и команду вывода, то в системах с канальной организацией процессор только инициирует операцию, а конкретные действия в этой операции программируются , как сказано выше, в канальной программе. Канальная программа состоит из команд, которые называются командные слова канала. Каждое командное слово канала содержит код операции, адрес данных в памяти куда или откуда они будут приниматься или передаваться в устройство, флажки или иначе биты, управляющие выполнением операции и счетчик данных, фиксирующий количество байт в операции обмена.
Для того ,чтобы канал знал о расположении канальной программы в памяти процессор размещает начальный адрес канальной программы и ключ защиты в ячейке памяти с фиксированным адресом перед началом операции ввода вывода. Эта ячейка носит название CAWили АСК- адресное слово канала. По окончании операции ввода вывода канал размещает результат операции также в ячейке с фиксированным адресом в памяти , записывая в нее байты состояния устройства и канала, остаточный счет, ключ защиты памяти и адрес последнего командного слова канала плюс восемь.


 Программные средства канала
Программные средства канала

Флажок цепочки данных. Этот управляющий бит позволяет по команде ,указанной в КСК организовать передачу блока информации в несмежные области памяти или выдавать из них. Когда данные, указанные текущим КСК , будут переданы в память или выданы из нее ,передача данных не прекращается , канал выбирает следующее КСК из памяти по текущему адресу канальной программы, игнорируя в нем поле кода команды и использует поле адреса данных и поле счетчика байтов таким образом осуществляя выше указанный обмен.
Флажок цепочки команд.
Для того чтобы канальная программа состояла из нескольких КСК и используется этот флаг, указывающий на продолжение канальной программы. Цепочка команд позволяет по одной команде ввода вывода программе осуществлять передачу нескольких блоков данных как и при цепочке данных ,но в данном случае каждое новое выбранное КСК выполняет свою операцию, поэтому, прежде чем выбрать очередное КСК из памяти , канал ждет момента когда внешнее устройство полностью закончит операцию обмена, включая все механические перемещения своих частей то есть будет готово для выполнения новой операции ввода вывода. Этот момент фиксируется каналом при получении от устройства байта состояния с указателем УК(устройство кончило).
Еще одной особенностью при выполнении цепочки команд каналом является то , что канал после выполнения каждого промежуточного КСК не формирует запроса на прерывание в процессор, сообщая об окончании операции ввода вывода после выполнения канальной программы .
Что же касается устройства при выполнении цепочки команд возникает вопрос . Информирует ли канал устройство о том, что канал работает с цепочкой команд или это только функция канала? Да, сообщает путем посылки соответствующей последовательности интерфейсных сигналов, указывая устройству на то, что по окончании текущей операции устройство обязано выставить запрос на начальную выборку- gпоследовательность интерфейсных сигналов для связи с каналом. Вопрос о том остается ли устройство логически подключенным к каналу( поддержание управляющих интерфейсных сигналов в активном состоянии) до начала следующей операции зависит от режима работы канала. О чем мы поговорим позже.
Флаг подавления неправильной длины.
Этот флаг используется для блокировки сбойной ситуации в канале ,когда счетчик байт ужу обнулен ,а устройство продолжает выставлять запрос за данными. Этот флаг рекомендуется устанавливать во всех операциях записи то есть когда данные поступают из канала в устройство потому что из за специфики интерфейса канал не сопровождает последний байт обмена специальным сигналом и поэтому устройство при записи всегда выставляет один лишний запрос, на который канал отвечает признаком конца обмена. При чтении такой ситуации понятно не возникает, так как передача последнего байта контролируется устройством, конечно же, если счетчик байт точно соответствует числу считываемых данных. Этот бит может быть использован как контроль размера блоков передаваемых данных.
Флаг блокировки записи в память
Используется в операциях чтения.
Флаг программно управляемого прерывания.
При единичном состоянии вызывает запрос на прерывание в канале. Может быть использован как инструмент наблюдения выполнения канальной программы со стороны процессора.
Флаг косвенной адресации данных
Данный флаг является дополнением к средству динамического преобразования адресов при обращении в память. Это средство позволяет каналу управлять обменом данных с несмежными страницами реальной памяти. Если этот флаг установлен, то поле адреса данных указывает на адрес ячейки оперативной памяти в которой находится первое слово списка слов косвенной адресации .Каждое слово содержит абсолютный адрес начала области данных оперативной памяти в пределах страницы. Число слов в списке зависит от величины счета в КСК и адреса данных в первом слове списка .Когда адрес данных оказывается на границе страницы канал выбирает следующее слово из списка и продолжает передачу данных.
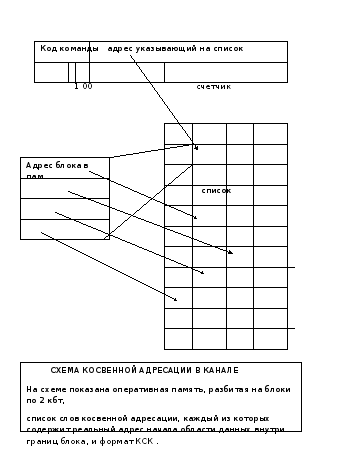
Адресация устройств в канальной системе.
Для того ,чтобы процессор смог обратиться к внешнему устройству с командой ввода вывода , внешнее устройство должно иметь свой идентификатор. Таким идентификатором является физический адрес устройства, который кодируется двоичным кодом и фиксируется в устройстве на все время работы системы аппаратными средствами. Обычно используется регистр, разряды которого устанавливаются в нулевые и единичные состояния в соответствии с кодом адреса принудительно с помощью перемычек, через которые подаются нулевые или единичные уровни на его установочные входы. Для изменения адреса устройства производят перекодировку регистра адреса устройства. Так как канальная система состоит из множества каналов, то результирующий адрес обращения в команде ввода вывода состоит из адреса канала и адреса устройства в канале. Классический формат состоит из двух байт, который указываются эти адреса.

Режимы работы каналов.
Если канальная программа определяет направление потоков данных между памятью и устройством и размещением данных в памяти, то взаимодействие канала и устройства во временных границах операции обмена определяется режимом работы канала иначе протоколом, который обязаны поддерживать все устройства подключенные к каналу. Протокол реализуется на микро архитектурном уровне аппаратными средствами в канальной систем и воздействует на устройство через интерфейс- набор физических проводов, соединяющих канал с устройством
И так с точки зрения временного взаимодействия канала с устройством операция ввода вывода может быть выполнена в одном из двух режимах:
- монопольном
-мультиплексном
В монопольном режиме все средства интерфейса ввода вывода и канала монополизируются устройством и оно остается логически связанным с каналом на все время операции ввода вывода.
Никакое другое устройство не может подключиться к каналу, пока не завершиться передача данных в ВУ. Физически блокировка других устройств осуществляется логическим сигналом, выдаваемым устройством в канал, и пока этот сигнал остается активным устройство монополизирует вышеуказанные средства.
В мультиплексном режиме канал может обслужить несколько одновременно работающих устройств путем представления коротких промежутков во времени для передачи данных. При этом на канале функционирует схема приоритета подобная арбитражу на шине при последовательном присоединении устройств к каналу, или внутри канальной системы при радиальном соединении канала с устройствами.
В соответствии с режимом работы каналов различают типы каналов в классической архитектуре:
- байт-мультиплексный
- блоковый(селекторный)
- блок-мультиплексный
Байт-мультиплексный канал поддерживает связь с устройством на время передачи одного байта данных. Кроме мультиплексного режима может поддерживать и монопольный. Этот режим устанавливается устройством, но может быть изменен каналом.
Блоковый канал работает только в монопольном режиме.
Блок мультиплексный канал разрешает мультиплексирование между блоками данных, если указана цепочка команд. В этом случае канал, не дожидаясь от устройства байта состояния “устройство кончило” может начать операцию обмена с другим устройством.
Возможность мультиплексирования блоков данных зависит от состояния управляющего мультиплексированием в управляющем регистре процессора, от конструкции самого устройства и вида подканала является ли он разделенным или неразделенным. Если каналу не разрешено работать в блок- мультиплексном режиме,
то он функционирует как блоковый.
2.Ввод вывод данных в канальной системе начинается с выполнения команды “Начать ввод вывод” Выполнение этой команды в процессоре задерживается, пока не будут удовлетворены все предыдущие запросы от процессора к основной памяти по отношении к каналам и к другим процессорам в многопроцессорных системах. Только после этого начинается выполнение команды.
Необходимо отметить что команды ввода вывода являются привилегированными командами и могут только выполнятся на системном уровне кроме того операционная система точнее супервизор( управляющая программа реализующая ввод вывод) готовит канальную программу и записывает начальный ее адрес расположения в памяти в фиксированную ячейку для дальнейшей передачи ее содержимого каналу.
Начав выполнятся команда ввода вывода читает эту ячейку(АСК)и передает в канал .Адрес канала и устройства находится в памяти по адресу указанному в формате команды. После чего процессор передает управление вводом вывода каналу, включив таймер, и ожидает ответа от канала.
Передача управления в различных архитектурах реализуется своими способами. Так ,на пример, в отечественной ЭВМ ЕС1046, общую управляющую память для процессора и канала, как мы уже говорили об этом, управление каналу передавалось микропрограммными средствами путем установки со стороны процессора запроса на микропрограммное прерывание.
В течении определенного времени канал обязан организовать выборку адресуемого устройства, предварительно проверив его состояние в подканале. Адрес устройства канал читает из регистра связи с процессором в который команда ввода вывода записывает этот адрес в начале выполнения.
Канал же произведя начальную выборку, если устройство не занято уже другой операцией, ранее начавшейся, о чем он узнает из содержимого подканала, формирует по результату выборки байт состояния этого устройства и передает процессору. Механизм передачи может быть различным. В выше упомянутом примере передача результата проверки готовности работы устройства и канала
Осуществляется через механизм микропрограммного прерывания.
Процессор получив ответ от канала завершает выполнение команды ввода вывода . формируя соответствующий признак результата.
По содержимому АСК канал начинает выполнение канальной программы и организует передачу данных в соответствии с канальной программой и режимом его работы. По окончании выполнения канальной программы канал отключается от устройства, посылая последовательность управляющих сигналов по интерфейсу в соответствии с протоколом.
Устройство, получив приказ отключения от канала формирует байт конечного своего состояния и организует запрос на передачу его в канал.
Канал, получив запрос на связь устройства с ним, по своему усмотрению может принять этот байт или дать указание устройству “ запомнить состояние” в зависимости от состояния в канале.
Канал, если в этом будет необходимость, сам обратится к устройству и примет этот байт конечного состояния.
В любом случае окончанием операции ввода вывода в
канале будет формирование слова состояния канала и запроса на прерывание ввода вывода в процессор.
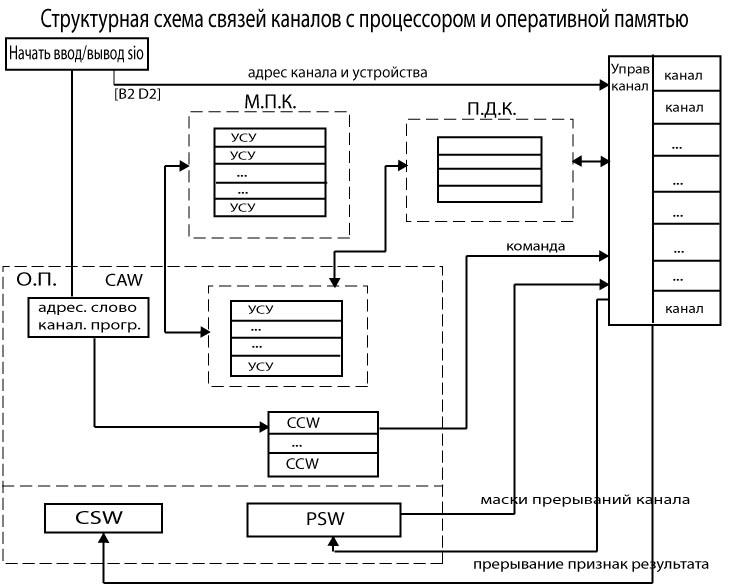
Структура канальной системы серверов Zархитектуры
Является дальнейшим развитием структуры классической канальной системы, основные принципы которой мы уже рассмотрели. Расширение ее функциональных возможностей было осуществлено в результате модернизации, как аппаратных, так и программных средств.
В классической архитектуре каналы получали всю управляющую информацию из блока управления каналами,
Который был связующим звеном между процессором и каналами и координировал работу всех каналов аппаратно или используя микропограммное управление.
В Zархитектуре эти функции были возложены на специализированные процессоры, входящие конструктивно в процессорный комплекс компьютера и на адаптеры шины памяти и на аппаратную логику интерфейса, связывающего каналы с памятью и выше упомянутыми процессорами.
То есть изменилась и архитектура блока связи процессора с каналами. Если в классической системе количество каналов
было немногочисленно, то для большого количества каналов с большой пропускной способностью (ESCON17мгб/сек,FICON1гбт/сек) существующая топология стала неприемлемой, и был разработан высокоскоростной самосинхронизирующий интерфейсSTI, поддерживающий сетевую топологию с передачей кадров между каналами и адаптерами памяти, выполняющими часть функций общего канала в классической системе. Поэтому процессорные узлы каналов стали выполнять не только функции , реализующие выполнение канальных программ, но и формирование кадров для связи согласно протоколаSTIс процессом ввода вывода и системной памятью и кадров для связи с устройствами ввода вывода по протоколу типа канала.
Интерфейс STIимеет трехуровневую организацию:
физический
логический
пользовательский
Физический уровень обеспечивает побайтный прием и передачу кадров от каналов к оперативной памяти и обратно.
Логический уровень отвечает за формирование кадров, состоящих из заголовка и информационного блока.
Заголовок содержит адреса источника и получателя.
Информационный блок определяется типом кадров.
Одни кадры предназначены для передачи данных из каналов в память и обратно другие для передачи управления и снятия состояния как самих канальных адаптеров так аппаратной логики интерфейса.
Уровень пользовательского интерфейса определяет тип кадров в соответствии с канальной программой, формируя кадры запросов к системной памяти за данными при записи во внешние устройства или для передачи данных в память при чтении из них. Каждый запрос в память со стороны каналов подтверждается адаптерами, ответными кадрами то есть на интерфейсе реализуется протокол с квитированием, как и в классической архитектуре.
Контроль продвижения данных по интерфейсу и формирования запросов на повтор операций при сбоях возложен на аппаратную логику свитчей.
Как видно из блок-схемы канальной системы связь каналов с памятью осуществляется через адаптеры шины памяти, в состав каждого из которых входит двух портовый буфер, обеспечивающий дуплексный режим обмена данными между каналами и памятью.
Адаптер памяти содержит дополнительный буфер для хранения команд ввода вывода, которые в соответствии с указанным адресатом в команде осуществляют запись и чтение не только из адаптеров каналов ,но и из аппаратной логики интерфейса, что дает возможность процессору ввода вывода управлять работой каналов и отслеживать их текущее состояние .
Каждый адаптер имеет несколько идентичных портов, работающих в дуплексном режиме ,управляющая логика которых дает возможность не только управлять потоками данных каналов с памятью ,.но и содержит аппаратное обеспечение межкомпьютерного интерфейса, предназначенного для организации кластерных структур.
Порты также имеют аппаратную логику для формирования сетевых кадров и схему конвертирования восьмиразрядного кода байта в десятиразрядный код для обеспечения надежности передачи данных и схему обратного преобразования на приеме. Соответственно аналогичные схемы имеют порты свитчей, подключаемых к адаптерам.
Изменилась и программная поддержка функционирования канальной системы. Был расширен набор системных команд, производящих операции с подканалами то есть областями памяти ,в которых хранятся текущая информация о состояниях устройств ввода вывода и были изъяты команды, которые непосредственно управляли устройствами точнее формировали свои признаки результата только после того как получали из каналов информацию об окончании операций с устройством. Например, команда начать ввод вывод SIOзаканчивала свое выполнение только после того, как получит результат опроса устройства каналом. Эта команда была заменена командой старт подканалаSSCH, которая устанавливает признак результата после анализа состояния подканала, не дожидаясь пока канал, непосредственно опросит устройство. Если состояние устройства не позволяет начать операцию ввода вывода, то канал через механизм прерывания сообщает об этом процессору.
Модернизация коснулась как использования среды и способа передачи информации, так и самой архитектуры каналов и канальной программы, хотя основополагающие принципы остались неизменными.
Во первых отказ от параллельной передачи данных и использование в качестве среды оптоволоконную связь позволило увеличить пропускную способность каналов от 4.5 мгбт/сек. До 17.5 мгб/сек.(ESCON).
Во – вторых отказ от шинной организации, которая обеспечивала в лучшем случае блок-мультиплексный режим связи канала с внешними устройствами , и переход на сетевую топологию с соответствующим оформлением передаваемой информации в форме кадров, с вводом сетевых узлов и присвоением им сетевых адресов в процессе инициализации, позволило использовать не только множественный доступ к устройству, но и принцип логической адресации на уровне связи канал – контролер ВУ, а не использовать физический адрес устройства для адресации подканала, как это было в классической архитектуре. А использование логических адресов дало возможность организовывать множество канальных систем подобно тому, как существует множество виртуальных пространств памяти при наличии механизма динамической адресации в системе.
Кроме того, введение логической адресации и самих каналов в каждой канальной системе в совокупности с использованием образов внешних устройств, а не их физических адресов позволило формировать одновременное функционирование множества полноценных операционных систем в рамках одной аппаратной платформы.
В отличии от систем виртуальных машин в которых под управлением одной операционной системы существует множество других операционных систем для организации виртуальных машин и вызываемых в оперативную память как подпрограммы при передаче управления конкретной виртуальной машине, в данном случае в оперативной памяти системы постоянно присутствует несколько ядер операционных систем, которые являются базовыми и каждой из которых формируется канальная система со структурой логической организации устройств и каналов. Каждая такая структура называется логической партицией LPAR.
В рамках же каждой партиции существует свое множество виртуальных машин, что в конечном счете увеличивает не только мощность, но и производительность системы, учитывая еще тот фактор, что в системе существует не один процессор, а многопроцессорная система, на аппаратную платформу которой накладывается множество операционных систем.
Что же касается физических адресов каналов и устройств необходимо отметить следующее:
Подобно тому как при использовании виртуальной памяти существует механизм преобразования логических адресов памяти в физические, так и в канальной системе с вводом принципов логической организации в каналах пришлось формировать таблицы соответствия логических адресов каналов в каждой из канальных систем физическим, т. е. физический адрес канала стал использоваться как указатель на объект, расположенный в системе ,через который осуществляется связь системы с устройством. При этом для каждой канальной системы должно выполняться правило:
Для каждого логического канала существует только один физический ,через который система может связаться с устройством. Но так как физические каналы являются сетевыми узлами , то доступ к устройству может осуществляться через множество этих физических каналов, для этого канальная система при формировании информационного подканала указывает значения логических адресов каналов, в виде альтернативных путей доступа к устройству. Таким образом, понятие разделённого и не разделённого подканала в современных канальных системах перешло на уровень канала, так как один и тот же физический канал может быть указан в таблицах в соответствие логических каналов физическим каждой канальной системы.
Физический адрес устройства, который определяет местонахождение в системе ввода-вывода, и дополнительно в классической архитектуре и расположение подканала устройства в оперативной памяти стало использовать на уровне контроллер ВУ-ВУ.
Контроллёр Ву с вводом много портового Ву перестал быть единственным посредником доступа к Ву, а разделил канал доступа к Ву с другими контроллерами ему подобными. Поэтому для указания адреса доступа к устройству ввели понятия логического контроллера Ву или по-другому его имиджа, представляющего идентификатор группы контроллеров через которые возможен доступ к устройству.
Физический же адрес устройства не обязательно представляет конкретный дисковод а может указывать на конкретный домен в физическом пространстве, например, на имя логического тома в дисковой системе с технологией организации RAIDмассива, а контроллер получив информацию о расположению массива по своему алгоритму определяет конкретный дисковод.
Ознакомившись с функционированием основных компонентов канальной системы серверов Zархитектуры можно отметить следующее:
1) Для обеспечения функционирования всей системы, учитывая сетевую топологию соединения канала с устройством и механизм логической адресации в каналах, канал каждый раз, получая указание начать операцию ввода вывода или опрос состояния устройства, получает дополнительную информацию , содержащую номер логической партиции и логический номер канала в партиции и включает их в состав кадра, формируемого для отправки во внешнее устройство, для того чтобы получить их обратно в ответе от устройства и сформировать запрос на прерывание в процессор ввода вывода с указанием типа прерывания, его приоритета и адресата ,кому ответ из устройства предназначен . Приоритет прерывания для каждого подканала устанавливается процессором ввода вывода при формировании содержимого подканала или может быть установлен системной командой из процессора в любое время.
2) При формировании кадра, отправляемого во внешнее устройство канал обязан указать номер своего порта в сети и номер порта назначения для того чтобы ответ, отправленный со стороны внешнего устройства был получен в сети каналом- инициатором связи с устройством
3) свитч или маршрутизатор является диспетчером имеет полную информацию об подключенных к нему узлах сети, через которые можно получить доступ к устройству и которую он получает каждый раз при активации канальной системы .Информация эта формируется при начальной конфигурации системы и сохраняется в конфигурационных файлах сервисного процессора сервера и контроллерах внешних устройств.
Операция ввода/вывода начинается с выполнения команды Старт подканала SSCH. Супервизором партиции (LPAR) во время выполнения партиции по запросу от прикладной программы пользователя.
Команда Старт подканала имеет 2 операнда:
А) по адресу [В2D2] находятся в памятиORB(аналог 48 ячейки в классической схеме). [ORB]= ключ, адрес адрес канальной программы.
B) Второй операнд находится в общем регистре процессора.GRO=SBNUM– адрес подканала.SBNUM– идентификатор подканала, установив который осуществляется операция ввода/вывода. В отличии от классической системы является только указателем на устройства как в классической схеме.
2) Так как каждая партиция имеет свою область подканалов в HSA( системная область памяти), то при обращении в подканал формируется адрес, индексируемый номером партиции. ИнструкцияSSCHанализирует состояние подканала и если он не занят, то выполнение команды завершается с нулевым значением признака результата и устанавливается запрос на ввод/вывод дляSAP– процессора ввода/вывода, на этом выполнениеSSCHзаканчивается.
Блок ORBсодержит начальный адрес канальной программы , который передается в подканал.
3) SAPанализируя очередь запросов, обращается 4) к подканалу и на основании адресов логических каналов, указанных в структуре подканала, по своим таблицам определяет физический канал, через который будет осуществляться доступ к устройству.
Выбрав оптимальный вариант SAP, 5) устанавливает запрос на начало операции ввода вывода для выбранного физического канала с указанеием номера партиции и логического канала
6) Канал, зная идентификатор устройства, с которым он должен установить связь на основании информации о всех портах в сети с подключенным к ним устройствам, выбирает требуемый порт и формирует кадр для передачи в сеть. Информацию о портах и подключенным к ним устройствам канал получает во время инициализации сети во время включения (нижний уровень протокола(FC–SB2))
7) Контролер ВУ получив кадр формирует ответный кадр согл. протокола.
8) Канал, получив кадр ответа от устройства корректирует состояние подканала и формирует запрос на прерывание в SAP.
9) SAP, получив запрос на прерывание информации, передаваемой каналомSUBNOM,MГF,CHPK, устанавливает запрос в очередь запросов для обработки программы прерываний вLPAR.
10) Если операция ввода/вывода связана с передачей данных, канал самостоятельно начинает обмен с устройством, выбирая канальную программу согласно
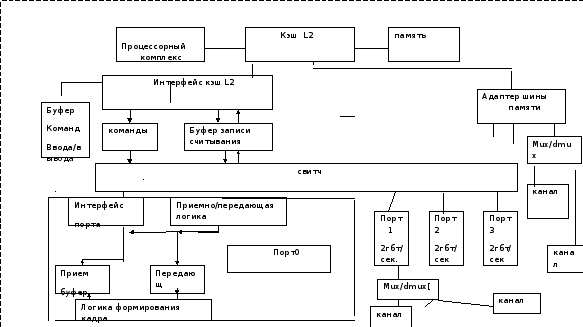

Лекция N12
Тема лекции: Многопроцессорные системы.
1.Общие принципы организации многопроцессорных систем. Классификация, определения мультипроцессора и мультикомпьютера.
2. Мультипроцессоры класса SMPcобщей шиной.
Согласно классификации по Флину мультипроцессоры и мультикомпьютеры относятся к классу MIMD- МНОГО ИНСТРУКЦИЙ МНОГО ДАННЫХ.
Мультипроцессор-это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров. В такой системе существует одна копия операционной системы, с одним набором таблиц.
Смена процессов в мультипроцессорной системе происходит также как и в однопроцессорной, то есть с записью состояния процесса в системных таблицах и сегментах и активизацией другого процесса готового к выполнению и загрузкой его данных в регистры процессора. Отличие заключается только в расширении аппаратных ресурсах, позволяющих одновременное выполнение нескольких процессов на разных процессорах. Именно наличие одного отображения операционной системы и отличает мультипроцессор от мультикомпьютера.
Мультикомпьютер- это система представляющая совокупность компьютеров со своими операционными системами ,со своими памятями и со своим наборами внешних устройств, в которой компьютеры соединены между собой в зависимости от архитектуры системы различными способами или по- другому сетевыми соединениями различных топологий.
Если основная связь между процессорами при обмене информацией в мультипроцессорной системе осуществляется через общую память, то в мультикомпьютерах основными средствами передачи информации являются сообщения , передаваемые по физическим каналам, связывающими компьютеры меж собой.
В дальнейшем рассматривая организацию транспьютера и рекурсивных вычислительных систем, мы убедимся в том, что изначальная архитектура транспьютера основу, которой составляли: вычислительный модуль, интерфейсный модуль для подсоединения внешних устройств, коммуникационный модуль для связи с другими транспьютерами и протокол связи между ними, основу которого составляли сообщения с использованием программных операторов SENDиRECEIVE, вызывающих передачу сообщения из одного транспьютера и прием его в другой - стала основой организации мультикомпьютеров. Именно увеличение мощности вычислительного узла и объема оперативной памяти и как следствие размещение соответствующих программных средств в нем стали основой архитектуры мультикомпьютеров с интерфейсом, основанном на передаче сообщений.
И так прежде чем рассматривать более детально различные архитектуры систем класса MIMD, отметим признаки по которым они классифицируютcя.
Для мультипроцессоров – это в первую очередь, так называемая , симметрия, определение которой дадим позже, и во- вторых топология подключения к памяти.
Для мультикомпьютеров -это классификация как по топологии связи между собой, по степени однородности и интерфейсов их образующих, так и по инфраструктуре программной среды.
|
MIMD
ПРОЦЕССОРЫ С МАССОВЫМ
ПАРАЛЛЕЛИЗМОМ
(MPP)
БЕЗ ИПОЛЬЗОВАНИЯ
КЭШЕЙ (NC-NUMA)
MIMD
МУЛЬТИПРОЦЕССОРЫ
МУЛЬТИКОМПЬЮТЕРЫ
Однородные с
равноправным ДОСТУПОМ К ПАМЯТИ (UMA) С НАЛИЧИЕМ ТОЛЬКО
КЭШЕЙ
(COMA)
ПРОЦЕССОРЫ С МАССОВЫМ
ПАРАЛЛЕЛИЗМОМ
(MPP)
КЛАСТЕРЫ РАБОЧИХ
СТАНЦИЙ
(COW)
С ШИННОЙ ОРГАНИЗАЦИЕЙ
(SMP)
С КОООРДИН. КОММУТАТОР.
БЕЗ ИПОЛЬЗОВАНИЯ
КЭШЕЙ (NC-NUMA)
топология РЕШЕТКИ
ТОПОЛОГИЯ ГИПЕРКУБА
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
неоднородные С НЕРАВНОПРАВНЫМ ДОСТУПОМ
К ПАМЯТИ (NUMA)
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
Использование
КЭШЕЙ (CC-NUMA) |
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|

















Мультипроцессоры класса SMP.
Модель мультипроцессорной данной системы представляет собой архитектуру с разделяемой памятью и распределенными прерываниями ввода вывода. Такая модель является полностью симметричной. То есть все процессоры функционально равнозначны, и каждый процессор может связаться с каждым. В данной модели нет иерархии, нет отношения мастер исполнитель, нет конфигурации, ограничивающей соединения. Модель является симметричной в двух важных направлениях.
Симметрия памяти.
Память является симметричной, когда все процессоры разделяют одно и то же адресное пространством и получают доступ к одним и тем же адресам. Симметрия памяти обладает одной важной особенностью-возможностью выполнения работ процессорами под управлением одной и той же операционной системы , как уже говорилось раньше.
Симметрия ввода вывода имеет место когда все процессора разделяют доступ к одной и той же системе ввода вывода, включая порты ввода вывода и контроллеры прерываний , и любой процессор может получить прерывание из любого источника. Некоторые мультипроцессорные системы, имеющие симметричный доступ к памяти являются не симметричными к
обработке прерываний ввода вывода, асимметрия в таких системах определяется на программном уровне , а не аппаратными средствами.
Архитектура симметричной мультипроцессорной системы
с общей шиной.
|
ПРОЦЕССОР
ПРОЦЕССОР1
ПРОЦЕССОР2
ПРОЦЕССОРN
РАЗДЕЛЯЕМАЯ
ПАМЯТЬ
КОНТРОЛЛЕР
ШИНЫ
ШИНА АРБИТРАЖА
СИСТЕМНАЯ ШИНА
|
|
ШИНА МЕЖПРОЦЕССОРНЫХ СВЯЗЕЙ
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
КОНТРОЛЛЕР
прерываний
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
МОДУЛЬ ИНТЕРФЕЙСОВ ВНЕШНИХ УСТРОЙСТВ
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|











Механизмы управления функционированием мультипроцессорной системы с общей шиной.
При работе данной системы возникает множество ситуаций,
cвязанных с обращением процессоров к разделяемой памяти. Для того, чтобы система функционировала нормально должны быть механизмы, представляющие программно- аппаратные средства, задачей которых является управление когерентностью системной памяти при одновременном доступе нескольких процессоров к одной и той же ячейке памяти.
Другой задачей является обеспечение обработки прерываний и организации межпроцессорных сообщений с целью реализации симметрии ввода вывода. Такими механизмами являются.
механизм блокировки шины
инструкции сериализации
расширенный контроллер прерываний
а при наличии кэшей в каждом процессоре ,протокол когерентности системной памяти и кэшей.
реализуется все это путем использования модели согласованности порядка записей между процессорами в системную память, механизм блокировки шины позволяет блокировать цикл очередного арбитража, давая возможность активному агенту завершить его транзакции на шине. Механизм блокировки активизируется программным способом с использованием специального префикса в формате команд. Механизм блокировки шины также активизируется, если процессор выполняет операции со структурами системных данных, к которым относятся:
-операция переключения задач
-изменение содержимого дескриптора сегмента
-обновление каталогов и таблиц страниц
циклы подтверждения прерывания во время получения значения вектора прерывания с шины данных(данная операция характерна для SMPна базе процессоров компанииINTEL).
Блокировка при переключении задач исключает возможность доступа других процессоров к ресурсам вызываемой задачи.
Что же касается моделей согласованности записей в память агентами системы ,то существует несколько моделей, выбор которой определяется архитектурой системы. Наиболее известные мы обсудим позже.
|
|
основные
компоненты
архитектуры многопроцессорных
симметричных систем
системные процессора
системная память
система ввода вывода
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
расширенные
контроллеры прерываний
расширенных
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|



|
|
|
|
|
|
|
|
|
|
|
|
| |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
программно-аппаратные
механизмы
поддержки функционирования
симметричных мультипроцессорных
систем
механизм блокировки
шины
согласованность по
последовательности
процессорная
согласованность
расширенные
контроллеры прерываний
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
механизм описания и и распределения
ресурсов памяти
|
|
поддержка когерентности системной
памяти и кэшей
|
|
|
механизм согласованности записей
|
|
система прерываний и межпроцессорных
сообщений
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
механизм
префиксации
наличие
регистров для описания
памяти
|
|
протокол когерентности
|
наличие команд
сериализации и
префикса
блокировки в формате
команды
|
|
блокировка шины при операциях с
системными данными
|
строгая
согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
интерфейс межпроцессорных
сообщений
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
слабая согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
свободная
согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| ||
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |















строгая согласованность- самая простая модель. В такой модели при любом обращении к ячейке памяти за данными из нее считывается самая последняя запись. На практике это реализуется путем простого алгоритма: первый пришел- первым обслужен. Кэширование и дублирование в основной памяти блоков данных запрещено. Такая последовательность применяется для областей памяти ,предназначенных для ввода вывода ,характеризуемые как не кэшируемые.
Согласованность по последовательности- этот алгоритм реализует последовательность записей и операций чтения при одновременном их поступлении от процессоров согласно правилам, установленными аппаратными средствами системы, при этом все процессоры наблюдают один и тот же порядок.
Процессорная согласованность- данная последовательность записей осуществляется согласно следующим двум правилам:
1Все процессоры воспринимают запись любого процессора в том порядке , они начинаются.
2.Все процессоры видят записи в котором они происходят.
Два этих правила устанавливают порядок при котором контроллер шины не гарантирует непрерывность цепочки записей от процессора, то есть контроллер может с согласия процессора задержать запись в своих буферных регистрах и пропустить запись вперед от другого процессора при представлении последнему шины согласно арбитража. Контроллер шины только гарантирует процессору, что его записи попадут в память согласно программной последовательности. Данная модель используется при реализации протокола когерентности MESIи при обращении к областям памяти, в которых можно реализовать политику обратной записиWB.
Для наглядности рассмотрим пример.
Пусть процессор1 осуществляет последовательность записей:
1А,1В,1С
Соответственно процессор2
2А,2В,2C
тогда контроллер шины имеет право произвести записи в память согласно следующей последовательности:
1A, 2A, 1B, 2B, 1C, 2C
из которой видно, что записи от процессоров произведены в программном порядке, хотя нарушена непрерывность их цепочек.
Слабая согласованность, при ней операции записей и чтения могут производиться в любом порядке, при этом аппаратные средства не гарантируют и не поддерживают какого- либо порядка поэтому, чтобы устранить хаос в обращениях к памяти и соблюсти алгоритм программы,
в программы вводят специальные команды синхронизации, при выполнении которых процессор заканчивает все ранее начатые операции обращения в память, таким образом, производится контроль за содержимым данных в системе.
Тема лекции: Организация межпроцессорных связей в симметричных мультипроцессорных системах .
1.Расширенный механизм прерываний как основной канал для передачи управляющей информации между процессорами в мультипроцессорной системе. Расширенный контроллер прерываний. Блок- схема.
2. Виды и форматы сообщений в мультипроцессорных системах. Протокол инициализации мультипроцессорной системы. (на примере SMPна базе процессоровINTEL).
Каждая модель мультипроцессорной спецификации в зависимости от архитектуры системы решает вопрос о межпроцессорных связях по-своему. В симметричных мультипроцессорных системах основным каналом обмена информацией является общая разделяемая память, которая дает возможность использовать системные команды LOADиSTOREпри обмене данными между процессорами.
Но помимо этого канала для передачи управляющей информации как во время инициализации системы так и во время работы, для обработки ситуаций ,вызывающих прерывания в системе используют расширенный механизм обработки прерываний, который кроме обработки прерываний, характерных для однопроцессорного режима осуществляет обработку так называемых внешних или межпроцессорных запросов на прерывания. В состав расширенного механизма прерывания входит отдельный физический интерфейс, через который связаны все процессора в мультипроцессорной системе.
Физическая организация такого интерфейса может быть различной и быть реализована как в виде шины, так и в виде многоточечных соединений: от каждого процессора ко всем остальным.
Топология соединения определяет и протокол межпроцессорного обмена. Так шинная организация обязательно должна предполагать наличие цикла арбитража, прежде чем будет передача сообщения от одного процессора к другому. В случае же многоточечного соединения в каждый момент времени каждый процессор имеет информацию о каждом и поэтому арбитраж осуществляется аппаратными средствами внутри каждого процессора в результате чего обрабатывается запрос на прерывание от самого приоритетного агента в данном такте, после обработки которого изменяется приоритет каждого процессора в системе .Обычно используется кольцевая схема приоритета, когда процессор имеющий высший приоритет “падает на дно”, а все остальные увеличивают значения своих арбитражных номеров на единицу.
Примером такой организации может служить спроектированная в свое время мультипроцессорная система AS400. Имея общую шину связи процессоров с разделяемой памятью, то есть архитектуруSMPс общей шиной, но в отличии отSMPINTEL, осуществляла связь между процессорами по принципу межмодульных связей, причем степень глубины связей была достаточно высокой с точки зрения информационной емкости в межпроцессорных сообщениях. Связь осуществлялась по параллельному интерфейсу ,формат межпроцессорного сообщения: поле данных, тип команды, поле идентификаторов процессоров, указатель на прерывание. Каждый раз, обращаясь в память, процессор обязан был по протоколу передавать всем другим процессорам код команды, с которой он обращается в общую память. Таким образом ,буферизируя эти команды, каждый процессор имел очередь не только своих запросов к памяти, но и всех агентов системы.
Для того, чтобы активизировать прерывание в другом процессоре инициатор –процессор в сообщении устанавливал указатель и идентификатор процессора, который должен был выполнить прерывание. Выполнив прерывание, целевой процессор обязан был сбросить в своем регистре межпроцессорной связи свой идентификатор. Таким образом, процессор-инициатор, анализируя соответствующий бит на своей входной шине от целевого процессора, определял окончание операции в целевом процессоре.
Инициализация межпроцессорных сообщений в разных системах происходит по-разному. Так, например, в свое время в системе IBM370 и ей подобным ЭВМ отечественного производства класса ЕС передача межпроцессорных сообщений осуществлялась через специальный интерфейс прямого управления и для активизации, которых использовалась системная команда “СИГНАЛ ПРОЦЕССОРУ”. Формат этой команды был
трех адресный и имел следующий вид.
|
|
|
|
|
|
|
|
|
| |
|
|
КОД ОПЕРАЦИИ
R1 R2 B2 D2
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|





А[B2,D2]-адрес ячейки оперативной памяти, в которой находится байт управляющей информации для адресуемого процессора.
[ R1]- байт состояния адресуемого процессора после выполнения приказа
[R2]- адрес процессора, которому предназначен приказ.
При выполнении данной команды, процессор после считывания байта управляющей информации из памяти формирует запрос на прерывание на интерфейсе прямого управления, выставляет на шины адреса и данных соответствующую информацию , таким образом активизирует запрос на внешнее прерывание в адресуемом процессоре.
Обработчик прерываний в адресуемом процессоре считывает байт управляющей информации с шины данных интерфейса прямого управления, активизируя соответствующие аппаратные средства в соответствии с приказом. Если для выполнения действий в адресуемом процессоре требуется дополнительная информация ,то для этого используются ячейки оперативной памяти, специально выделенные для этой цели.
Для организации межпроцессорных связей в модели мультипроцессорной спецификации на базе процессоров фирмы INTELиспользуется расширенный контроллер прерываний (APIC), имеющий распределенную архитектуру то есть часть его оборудования размещается по-блочно в каждом из процессоров системы, являясь частью аппаратных средств каждого процессора. Каждый такой блок называется локальныйAPIC, состав и работу которого рассмотрим позже.
Отдельная часть расширенного контроллера прерываний размещается на системной плате в “южном мосте”, в котором размещены аппаратные средства для обеспечения ввода вывода. Часть эта носит название IOAPICи предназначена для приема запросов на прерывания от всех источников на системной плате, включая, безусловно , и запросы от внешних устройств в системе. Общая структурная схема представлена ниже.
|
процессор1
локальный APIC
j
процессор2
локальный APIC
процессор3
локальный
APIC
источники
локальных
прерываний
процессорв
Шина APIC IO APIC
южный мост
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
прерывания от устройств
ввода
вывода
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|











Как видно из структурной схемы ,локальные APICпринимают запросы на прерывания от локальных источников для каждого процессора, которые могут находиться в системе. Помимо этого все внутренние источники прерываний в процессоре также направляют свои запросы в локальный блокAPIC
Так как симметричная мультипроцессорная система имеет одну копию операционной системы, а задачи, которые она распределяет между процессорами в каждый момент времени, имеют различные приоритеты в системе ,так же как и запросы на прерывания, то для обеспечения нормального функционирования системы локальные APICдолжны обеспечивать выполнение задач и обработку запросов на прерывания с учетом приоритетности тех и других. Исходя из выше сказанного , функциональная схема каждого локальногоAPICдолжна содержать аппаратные средства для реализации выше указанных требований.
Прежде чем приступить к разбору состава блок-схемы, дадим классификацию прерываний в мультипроцессорной системе.
|
|
|
|
|
|
|
|
|
|
|
Архитектура APIC
Архитектура APICразрабатывалась с учетом требований протокола шиныPCI, которая в архитектурахINTELявляется ведущей шиной, организующей связь процессоров с другими компонентами системы.
Для адресации контроллера локального APICиIOAPICсогласно требованиям протокола шиныPCIбыл принят вариант отображения адресов регистров выше упомянутых устройств с отображением на память. Для этого в адресном пространстве системной памяти выделена область для адресации регистров , входящих в состав выше упомянутых устройств.
Процессор, обращаясь к локальному контроллеру APICилиIOAPIC, формирует адрес обращения к системной памяти. В случае, если адрес принадлежит области локальногоAPIC, цикл обращения к памяти не формируется. В случае, если обращение кIOAPIC, контроль возложен на системный чипсет, в которомIOAPICявляется одной из его функций в конфигурационном пространстве шиныPCI.
В архитектуре шины ISAконтроллер прерываний 8259 выполняет не только фиксацию прерываний ,но и берет на себя функцию арбитража среди аппаратных прерываний, формируя в конечном итоге вектор прерывания и передает его в процессор. В архитектуреIOAPICнет схемы арбитража. Арбитраж осуществляется в локальном контроллереAPIC, которомуIOAPICадресует сообщение.
Основной задачей IOAPICявляется:
фиксация прерываний в таблице, количество строк в которой равно количеству входных контактов, на которые поступают запросы на прерывания.
Формирование и передача сообщения на шину для межпроцессорных сообщений.
|
|
|
|
|
|
|
|
|
|
|
| |
|
блок таймеров
вектор таймера
вектора локальных прерываний
вектор системных событий
вектор
ошибок
регистр адреса
процессора APICID
регистр логического
адреса
регистр режима логической
адресации
,блок приемной логики
декодер
вектора
|
|
шина адреса/данных
|
|
|
|
|
INTA EXINT[ INTR
|
|
|
| |
|
|
|
|
|
регистр приоритета задачи
|
|
|
|
|
|
| |
|
|
|
|
|
блок приоритета
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
регистр обслуживания прерываний
регистр
запросов прерываний
регистр фиксации
формы сигналов прерываний( по уровню
или по фронту)
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
регистр команды
прерывания
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
регистр окончания прерывания
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
регистр
арбитража
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
регистр приоритета
процессора
|
|
|
|
блок интерфейса шины APIC
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|


































Описание блок-схемы локального APIC.
В состав APICвходит группа регистров фиксирующих приоритет выполняемой задачи приоритета процессора и арбитражного номера процессора. Каждый из них выполняет свою функцию.
Регистр приоритета задачи используется для контроля запросов прерываний от внутренних и внешних источников и только в случае запроса с приоритетом большим, чем приоритет выполняемой задачи, схема приоритетов формирует запрос на прерывание в процессоре.
Другие прерывания фиксируются и будут обслужены, как только значение в регистре приоритета задачи будет достаточным для их обработки. Это дает возможность блокировать операционной системе определенные классы прерываний при выполнении приложений с высоким приоритетом. Данный механизм не распространяется для режимов, не использующих векторную информацию в своих сообщениях, это режимы передачи сообщений о прерываниях немаскируемых NMI,SMI-системного управления, во время инициализации системы-INITи прерываниях эмулирующих прерывания контроллера 8259,когда векторная информация поступает в процессор через системную шину в цикле подтверждения. Данный режим передается процессору путем установки кода в формате кадра ,передаваемого в сообщении.(режимEXTINT).
Регистр приоритета процессора отслеживает текущее состояние приоритета обрабатываемого прерывания, значение которого устанавливается из регистра приоритета задачи или из регистра обслуживания прерывания, поступившего для обработки в процессор, в зависимости от значений в старших тетрадах , которые указывают на классы прерываний.( вектор прерывания имеет размер байта, в котором старшие четыре разряда определяют класс прерывания, а четыре младших разряда определяют номер прерывания в классе : наивысший приоритет имеет нулевой класс ) .
Регистр приоритета арбитража содержит значение наименьшего класса приоритета прерывания в процессоре.
Для этого сравниваются значения в регистрах приоритета задачи, обслуживания и запросов, и зависимости от их значений производится его установка.
Если значение регистра приоритета задачи меньше чем в регистре запросов, то регистр приоритета арбитража принимает максимальное значение класса прерывания трех вышеупомянутых регистров.
Если больше, то производится анализ на сравнение со значением регистра обслуживания.
Если значение регистра приоритета задачи также меньше чем значение в регистре обслуживания, то устанавливается также максимальное значение из трех регистров.
Если регистр приоритета задачи имеет наибольшее значение из трех регистров, то его значение передается в регистр арбитража.
Регистр окончания обработки прерывания.
Установка этого регистра в блоке локального APICвызывает формирование специального сообщения об окончании обработки прерывания в процессоре. ‘Это сообщение формируется, если для данного прерывания в регистре, фиксирующем форму сигнала прерывания, установлен признак “уровень”.
Дело в том, что при данной форме сигнала фиксации запроса на прерывание возможно совместное использование линии запроса несколькими источниками по схеме монтажное “ИЛИ”. В случае такого варианта процессор обязан сообщить контроллеру прерывания на шине об окончании обработки, чтобы контроллер прерывания проверил состояние входной линии запроса и в случае низкого уровня вновь сформировал запрос на прерывания, таким образом , исключив потерю запросов на прерывания от устройств ввода вывода.
Регистры адресации процессора в мультипроцессорной системе.
Как видно из блок- схемы для адресации используются два регистра: регистр логического адреса и регистр физического адреса, кроме того, есть еще регистр режима логической адресации.
В режиме физической адресации адрес процессора формируется во время подачи питания по значениям на четырех входных контактах шины арбитража. Эти первоначальные значения и формируют значение адреса процессора в системе. Схему арбитража мы рассматривали ранее, сейчас же отметим, что по окончанию включения адреса процессоров в четырех процессорной системе имеют значения : 0111,1011,1101,1110. Эти же значения заносятся в арбитражные регистры и соответственно изменяются в процессе работы системы. Таким образом данная архитектура позволяет организовать только систему из четырех агентов. Для увеличения числа агентов на шине используется режим логической адресации.
Режим логической адресации.
В режиме логической адресации используются два варианта или две модели.
FLATмодель
Кластерная модель.
модель определяется значением разрядов 28-31 в регистре режима, если [28-31] =1111, то используется Fмодель, при этом разряды регистра логического адреса с 24 по 31 расширяют количество агентов до восьми.
Кластерная модель использует разряды регистра логического адреса следующим образом:
разряды[28-31] – номер кластера
разряды[24-27]- номер процессора в кластере
таким образом, при принятой схеме логической адресации можно адресовать до 60 агентов в системе так значение адреса кластера равное Fиспользуется для обращения ко всем агентам на шине одновременно.
Но дело в том, что данное количество процессоров на шине разместить на шине при данной архитектуре не возможно, так как арбитражный идентификатор в данной системе имеет всего четыре разряда, поэтому, даже отказавшись от принятой арбитражной схемы , можно только зафиксировать максимум 15 агентов при условии значение 1111 использовать как широковещательный адрес. Поэтому при количестве агентов больше 15 используется иерархическая система , состоящая из нескольких шин связь между которыми осуществляется через специальные аппаратные средства- менеджеры. Такая технология используется в системе неоднородных мультипроцессорных системах, но это уже другая архитектура, которую мы рассмотрим позже.
Регистр команд прерываний.
Данный регистр используется для организации сообщений в системе, поэтому прежде чем разбирать использование информации в этом регистре, целесообразно классифицировать виды сообщений и форматы кадров, передаваемых в них.
Виды сообщений
сообщениеEOI- окончание обработки прерывания
короткое сообщение- для передачи запросов на прерывание
сообщение для выявления агента с наименьшим приоритетом
сообщения типа ’удаленное чтение’ - для передачи информации между агентами
с точки зрения выбора адресата для сообщения все сообщения делятся на две группы;
статическое распределение, когда адресат указывается в сообщении
динамическое, когда адресат выявляется в процессе передачи сообщения в системе- определение адреса процессора с наименьшим приоритетом
Формат сообщения в общем виде имеет следующую структуру
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
типсообщения
арбитражный номер
агента вид адресации режим
вектор LMадресат контрсумма 000-FIX
001-LOST
PR
010-SMI
100=NMI
101-INIT
110-START
111-резерв
11-EOI
01-SHOT
L-УРОВЕНЬ ИЛИ
ФРОНТ
М=1-EOI ВСЕМ АГЕНТАМ
M=0-АДРЕСАТУ
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
1-физ
0-лог
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
















Режимы передачи:
000- FIX
передача сообщения ко всем агентам системы информации, подготовленной в регистре команды прерывания
001- LOST
наименьший приоритет, передается также как и FIXко всем агентам, за исключением того, приемником сообщения становится процессор с наименьшим приоритетом выполняемой задачи
010-SMI
Прерывания, связанные с режимом системного управления
100-NMI
Немаскируемые, прерывания. возникающие при возникновении аппаратных ошибок в системе
101-INIT
Прерывания ко всем агентам для установки их арбитражных идентификаторов в соответствии со значениями, записанными в их регистрах APICID
110-START
Используются как специальные сообщения между процессорами для указания передачи управления загрузочному блоку для начала активизации процессора приложения, используется в процедуре инициализации многопроцессорной системы

Протокол инициализации мультипроцессорной системы.
Функционирование любой вычислительной системы начинается с ее инициализации. Эта процедура начинается с включения питания. В первоначальный момент времени любая система использует аппаратные средства, которые формируя сигнал аппаратного сброса, устанавливается в исходное состояние, и в частности загружают адрес инструкции начальным значением, указывающим на расположение загрузочного блока в постоянной памяти.
Системы, которые не используют постоянную память для загрузки, аппаратно формируют команду ввода вывода с обращением к устройству загрузки.
Но прежде чем произойдет обращение к устройству загрузки, система должна быть уверена в исправности своих аппаратных средств, поэтому во многих системах при инициализации осуществляется прогон тестов автоматически и только после их успешного прохождения формируется вектор, указывающий на первую команду, с которой начинается программа загрузки. Так в архитектуре процессоров фирмы INTELтакие тесты являются частьюBIOS.
В системах со сложной архитектурой, например манфреймах фирмы IBM, операции инициализации и проверку работоспособности аппаратных средств осуществляет сервисный процессор.
В качестве примера рассмотрим протокол инициализации мультипроцессорной системы на базе процессоров фирмы INTELс архитектурой базовой моделиP6.
Для успешной инициализации мультипроцессорной системы протокол накладывает определенные требования и ограничения на систему во время процедуры инициализации:
- все механизмы прерываний в системе должны быть отключены,
- протокол может быть инициирован только после аппаратного сброса,
-по окончании процедуры инициализации, согласно алгоритму, должен быть установлен флаг в блоке локального контроллера APICдля процессора в системе, с которого будет произведена загрузка управляющей программы,
- протокол инициализации основан на том факте, что только одно сообщение может присутствовать на шине в данный момент времени и каждый из агентов может выставить его на шину только один раз во время процедуры в соответствии с приоритетом.
Действия по инициализации начинаются по сигналу аппаратного сброса, сформированного при включении питания в системе путем активизации диагностических тестов в каждом из процессоров.
Во время прохождения тестов в процессорах арбитраж на шине блокируется до окончания прохождения тестов. Блокировка эта осуществляется путем активизацией сигналов низкого уровня в каждом из процессоров, соединенных между собой в ‘монтажное ИЛИ” на шине арбитража . Поэтому пока будет присутствовать низкий уровень на шине, арбитраж будет заблокирован, и только по окончании тестов в каждом из процессоров он станет высоким.
Далее начинается активизация действий по определению процессора BSPв системе.
Эти действия основаны на следующих положениях:
- процессору, которому будет установлен флаг загрузочного по включению питания, устанавливается низший приоритет путем внешнего монтажа контактов процессоров, подсоединенных к арбитражной шине и подачей сигнала низкого уровня на один из этих контактов в каждом процессоре являющихся двунаправленными.
- для выявления BSPна шине каждый из агентов формирует сообщение типа “всем агентам включая себя” и согласно протоколу формирует в процессе инициализации только один раз
-формируется финальное сообщение, которое автоматически формирует BSPпроцессор, сообщая всем остальным об окончании процедуры.
-формат сообщения содержит вектор прерывания младшие разряды которого формируются по значениям APICIDкаждого из процессоров полученных ими с шины арбитража во время аппаратного сброса при включении питания.
Получив сообщение от агента в соответствии с приоритетом на шине, процессора сравнивают значения младших разрядов вектора из сообщения со своими идентификаторами APICID. Если эти значения равны, то процессор определяется какBSP. Если нет, то процессор будет процессором приложений.
На первый взгляд протокол не обеспечивает определения BSPи содержит противоречивое положение так как каждый процессор посылая свое сообщение будет себя идентифицировать какBSP. Но дело в том , что протокол обязывает каждый процессор принять одно сообщение от себя и три от других процессоров, поэтому в привилегированном положении окажется процессор с наименьшим приоритетом в начальный момент активизации межпроцессорных сообщений . Когда этот процессор получит доступ к шине все другие будут иметь статусы приложений и он установит свой статусBSPи сформирует на шину сообщение окончания процедуры с соответствующим значением вектора прерывания.
Получив на шине финальное сообщение, локальные контроллеры прерываний APICформируют запросы на прерывания, обрабатываемые вBIOS, но так как все процессора, кроме процессора со статусомBSP, имеющие статусы процессоров приложений, будут остановлены до моментов, когда каждый из них получит стартовое сообщение с вектором прерывания от процессораBSP.
Процессор BSP, выставляя на шину стартовое сообщение адресату, в программе включает таймер по истечении которого обращается в оперативную память по определенному адресу с командой чтения, и если адресат присутствует на шине то последний, обрабатывая стартовое сообщение, обязан записать свой идентификатор. Таким образом процессорBSPопределяет наличие агентов на шине.
|
|
|
|
источники прерываний
в
мультипроцессорной системе
|
|
|
|
|
|
| ||||||||||
|
локальные
прерывания
шинные сообщения
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
прерывания от внутренних источников
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
от IOAPIC
|
|
|
|
| ||||||||||
|
контроллер
прерываний
8259
|
|
не маскируемые
|
|
|
|
|
|
схемы контроля
|
| ||||||||||
|
|
|
|
|
|
межпроцессорные
|
|
|
|
| ||||||||||
|
|
|
маскируемые
|
|
|
|
|
|
таймер
|
| ||||||||||
|
|
|
|
|
|
|
|
|
программные
|
|
| |||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||
|
|
|
|
|
|
|
|
|
|
| ||||||||||














Лекция N12
Тема лекции: Многопроцессорные системы.
1.Общие принципы организации многопроцессорных систем. Классификация, определения мультипроцессора и мультикомпьютера.
2. Мультипроцессоры класса SMPcобщей шиной.
Тема лекции: Организация межпроцессорных связей в симметричных мультипроцессорных системах .
1.Расширенный механизм прерываний как основной канал для передачи управляющей информации между процессорами в мультипроцессорной системе. Расширенный контроллер прерываний. Блок- схема.
2. Виды и форматы сообщений в мультипроцессорных системах. Протокол инициализации мультипроцессорной системы. (на примере SMPна базе процессоровINTEL).
3.Расширенный механизм прерываний как основной канал для передачи управляющей информации между процессорами в мультипроцессорной системе. Расширенный контроллер прерываний. Блок- схема.
4. Виды и форматы сообщений в мультипроцессорных системах. Протокол инициализации мультипроцессорной системы. (на примере SMPна базе процессоровINTEL).
Согласно классификации по Флину мультипроцессоры и мультикомпьютеры относятся к классу MIMD- МНОГО ИНСТРУКЦИЙ МНОГО ДАННЫХ.
Мультипроцессор-это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров. В такой системе существует одна копия операционной системы, с одним набором таблиц.
Смена процессов в мультипроцессорной системе происходит также как и в однопроцессорной, то есть с записью состояния процесса в системных таблицах и сегментах и активизацией другого процесса готового к выполнению и загрузкой его данных в регистры процессора. Отличие заключается только в расширении аппаратных ресурсах, позволяющих одновременное выполнение нескольких процессов на разных процессорах. Именно наличие одного отображения операционной системы и отличает мультипроцессор от мультикомпьютера.
Мультикомпьютер- это система представляющая совокупность компьютеров со своими операционными системами ,со своими памятями и со своим наборами внешних устройств, в которой компьютеры соединены между собой в зависимости от архитектуры системы различными способами или по- другому сетевыми соединениями различных топологий.
Если основная связь между процессорами при обмене информацией в мультипроцессорной системе осуществляется через общую память, то в мультикомпьютерах основными средствами передачи информации являются сообщения , передаваемые по физическим каналам, связывающими компьютеры меж собой.
В дальнейшем рассматривая организацию транспьютера и рекурсивных вычислительных систем, мы убедимся в том, что изначальная архитектура транспьютера основу, которой составляли: вычислительный модуль, интерфейсный модуль для подсоединения внешних устройств, коммуникационный модуль для связи с другими транспьютерами и протокол связи между ними, основу которого составляли сообщения с использованием программных операторов SENDиRECEIVE, вызывающих передачу сообщения из одного транспьютера и прием его в другой - стала основой организации мультикомпьютеров. Именно увеличение мощности вычислительного узла и объема оперативной памяти и как следствие размещение соответствующих программных средств в нем стали основой архитектуры мультикомпьютеров с интерфейсом, основанном на передаче сообщений.
И так прежде чем рассматривать более детально различные архитектуры систем класса MIMD, отметим признаки по которым они классифицируютcя.
Для мультипроцессоров – это в первую очередь, так называемая , симметрия, определение которой дадим позже, и во- вторых топология подключения к памяти.
Для мультикомпьютеров -это классификация как по топологии связи между собой, по степени однородности и интерфейсов их образующих, так и по инфраструктуре программной среды.
|
MIMD
ПРОЦЕССОРЫ С МАССОВЫМ
ПАРАЛЛЕЛИЗМОМ
(MPP)
БЕЗ ИПОЛЬЗОВАНИЯ
КЭШЕЙ (NC-NUMA)
MIMD
МУЛЬТИПРОЦЕССОРЫ
МУЛЬТИКОМПЬЮТЕРЫ
Однородные с
равноправным ДОСТУПОМ К ПАМЯТИ (UMA) С НАЛИЧИЕМ ТОЛЬКО
КЭШЕЙ
(COMA)
ПРОЦЕССОРЫ С МАССОВЫМ
ПАРАЛЛЕЛИЗМОМ
(MPP)
КЛАСТЕРЫ РАБОЧИХ
СТАНЦИЙ
(COW)
С ШИННОЙ ОРГАНИЗАЦИЕЙ
(SMP)
С КОООРДИН. КОММУТАТОР.
БЕЗ ИПОЛЬЗОВАНИЯ
КЭШЕЙ (NC-NUMA)
топология РЕШЕТКИ
ТОПОЛОГИЯ ГИПЕРКУБА
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
неоднородные С НЕРАВНОПРАВНЫМ ДОСТУПОМ
К ПАМЯТИ (NUMA)
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
Использование
КЭШЕЙ (CC-NUMA) |
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|


















Мультипроцессоры класса SMP.
Модель мультипроцессорной данной системы представляет собой архитектуру с разделяемой памятью и распределенными прерываниями ввода вывода. Такая модель является полностью симметричной. То есть все процессоры функционально равнозначны, и каждый процессор может связаться с каждым. В данной модели нет иерархии, нет отношения мастер исполнитель, нет конфигурации, ограничивающей соединения. Модель является симметричной в двух важных направлениях.
Симметрия памяти.
Память является симметричной, когда все процессоры разделяют одно и то же адресное пространством и получают доступ к одним и тем же адресам. Симметрия памяти обладает одной важной особенностью-возможностью выполнения работ процессорами под управлением одной и той же операционной системы , как уже говорилось раньше.
Симметрия ввода вывода имеет место когда все процессора разделяют доступ к одной и той же системе ввода вывода, включая порты ввода вывода и контроллеры прерываний , и любой процессор может получить прерывание из любого источника. Некоторые мультипроцессорные системы, имеющие симметричный доступ к памяти являются не симметричными к обработке прерываний ввода вывода, асимметрия в таких системах определяется на программном уровне , а не аппаратными средствами.
Архитектура симметричной мультипроцессорной системы
с общей шиной.
|
ПРОЦЕССОР
ПРОЦЕССОР1
ПРОЦЕССОР2
ПРОЦЕССОРN
РАЗДЕЛЯЕМАЯ
ПАМЯТЬ
КОНТРОЛЛЕР
ШИНЫ
МОДУЛЬ ИНТЕРФЕЙСОВ
ВНЕШНИХ УСТРОЙСТВ
ШИНА АРБИТРАЖА
ШИНА МЕЖПРОЦЕССОРНЫХ
СВЯЗЕЙ
СИСТЕМНАЯ ШИНА
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
КОНТРОЛЛЕР
прерываний
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|










Механизмы управления функционированием мультипроцессорной системы с общей шиной.
При работе данной системы возникает множество ситуаций,
cвязанных с обращением процессоров к разделяемой памяти. Для того, чтобы система функционировала нормально должны быть механизмы, представляющие программно- аппаратные средства, задачей которых является управление когерентностью системной памяти при одновременном доступе нескольких процессоров к одной и той же ячейке памяти.
Другой задачей является обеспечение обработки прерываний и организации межпроцессорных сообщений с целью реализации симметрии ввода вывода. Такими механизмами являются.
механизм блокировки шины
инструкции сериализации
расширенный контроллер прерываний
а при наличии кэшей в каждом процессоре ,протокол когерентности системной памяти и кэшей.
реализуется все это путем использования модели согласованности порядка записей между процессорами в системную память, механизм блокировки шины позволяет блокировать цикл очередного арбитража, давая возможность активному агенту завершить его транзакции на шине. Механизм блокировки активизируется программным способом с использованием специального префикса в формате команд. Механизм блокировки шины также активизируется, если процессор выполняет операции со структурами системных данных, к которым относятся:
-операция переключения задач
-изменение содержимого дескриптора сегмента
-обновление каталогов и таблиц страниц
циклы подтверждения прерывания во время получения значения вектора прерывания с шины данных(данная операция характерна для SMPна базе процессоров компанииINTEL).
Блокировка при переключении задач исключает возможность доступа других процессоров к ресурсам вызываемой задачи.
Что же касается моделей согласованности записей в память агентами системы ,то существует несколько моделей, выбор которой определяется архитектурой системы. Наиболее
известные мы обсудим позже.
|
|
основные
компоненты
архитектуры многопроцессорных
симметричных систем
системные процессора
системная память
расширенные
контроллеры
прерываний расширенных
система ввода вывода
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|




механизм
префиксации
|
|
|
|
|
|
|
|
|
|
|
| |
|
программно-аппаратные
механизмы
поддержки функционирования
симметричных мультипроцессорных
систем
механизм блокировки
шины
согласованность по
последовательности
процессорная
согласованность
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
механизм описания и и распределения
ресурсов памяти
|
|
поддержка когерентности системной
памяти и кэшей
|
|
|
механизм согласованности записей
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
система прерываний и межпроцессорных
сообщений
|
|
|
| |
|
наличие
регистров для описания
памяти
|
|
протокол когерентности
|
наличие команд
сериализации и
префикса
блокировки в формате
команды
|
|
блокировка шины при операциях с
системными данными
|
строгая
согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
расширенные контроллеры прерываний
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
интерфейс межпроцессорных
сообщений
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
слабая согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
свободная
согласованность
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
















Строгая согласованность- самая простая модель. В такой модели при любом обращении к ячейке памяти за данными из нее считывается самая последняя запись. На практике это реализуется путем простого алгоритма: первый пришел- первым обслужен. Кэширование и дублирование в основной памяти блоков данных запрещено. Такая последовательность применяется для областей памяти ,предназначенных для ввода вывода ,характеризуемые как не кэшируемые.
Согласованность по последовательности- этот алгоритм реализует последовательность записей и операций чтения при одновременном их поступлении от процессоров согласно правилам, установленными аппаратными средствами системы, при этом все процессоры наблюдают один и тот же порядок.
Процессорная согласованность- данная последовательность записей осуществляется согласно следующим двум правилам:
1Все процессоры воспринимают запись любого процессора в том порядке , они начинаются.
2.Все процессоры видят записи в котором они происходят.
Два этих правила устанавливают порядок при котором контроллер шины не гарантирует непрерывность цепочки записей от процессора, то есть контроллер может с согласия процессора задержать запись в своих буферных регистрах и пропустить запись вперед от другого процессора при представлении последнему шины согласно арбитража. Контроллер шины только гарантирует процессору, что его записи попадут в память согласно программной последовательности. Данная модель используется при реализации протокола когерентности MESIи при обращении к областям памяти, в которых можно реализовать политику обратной записиWB.
Для наглядности рассмотрим пример.
Пусть процессор1 осуществляет последовательность записей:
1А,1В,1С
Соответственно процессор2
2А,2В,2C
тогда контроллер шины имеет право произвести записи в память согласно следующей последовательности:
1A, 2A, 1B, 2B, 1C, 2C
из которой видно, что записи от процессоров произведены в программном порядке, хотя нарушена непрерывность их цепочек.
Слабая согласованность, при ней операции записей и чтения могут производиться в любом порядке, при этом аппаратные средства не гарантируют и не поддерживают какого- либо порядка поэтому, чтобы устранить хаос в обращениях к памяти и соблюсти алгоритм программы,
в программы вводят специальные команды синхронизации, при выполнении которых процессор заканчивает все ранее начатые операции обращения в память, таким образом, производится контроль за содержимым данных в системе.
Каждая модель мультипроцессорной спецификации в зависимости от архитектуры системы решает вопрос о межпроцессорных связях по-своему. В симметричных мультипроцессорных системах основным каналом обмена информацией является общая разделяемая память, которая дает возможность использовать системные команды LOADиSTOREпри обмене данными между процессорами.
Но помимо этого канала для передачи управляющей информации как во время инициализации системы так и во время работы, для обработки ситуаций ,вызывающих прерывания в системе используют расширенный механизм обработки прерываний, который кроме обработки прерываний, характерных для однопроцессорного режима осуществляет обработку так называемых внешних или межпроцессорных запросов на прерывания. В состав расширенного механизма прерывания входит отдельный физический интерфейс, через который связаны все процессора в мультипроцессорной системе.
Физическая организация такого интерфейса может быть различной и быть реализована как в виде шины, так и в виде многоточечных соединений: от каждого процессора ко всем остальным.
Топология соединения определяет и протокол межпроцессорного обмена. Так шинная организация обязательно должна предполагать наличие цикла арбитража, прежде чем будет передача сообщения от одного процессора к другому. В случае же многоточечного соединения в каждый момент времени каждый процессор имеет информацию о каждом и поэтому арбитраж осуществляется аппаратными средствами внутри каждого процессора в результате чего обрабатывается запрос на прерывание от самого приоритетного агента в данном такте, после обработки которого изменяется приоритет каждого процессора в системе .Обычно используется кольцевая схема приоритета, когда процессор имеющий высший приоритет “падает на дно”, а все остальные увеличивают значения своих арбитражных номеров на единицу.
Примером такой организации может служить спроектированная в свое время мультипроцессорная система AS400. Имея общую шину связи процессоров с разделяемой памятью, то есть архитектуруSMPс общей шиной, но в отличии отSMPINTEL, осуществляла связь между процессорами по принципу межмодульных связей, причем степень глубины связей была достаточно высокой с точки зрения информационной емкости в межпроцессорных сообщениях. Связь осуществлялась по параллельному интерфейсу ,формат межпроцессорного сообщения поле данных, тип команды, поле идентификаторов процессоров, указатель на прерывание. Каждый раз, обращаясь в память, процессор обязан был по протоколу передавать всем другим процессорам код команды. с которой он обращается в общую память. Таким образом ,буферизируя эти команды, каждый процессор имел очередь не только своих запросов к памяти, но и всех агентов системы.
Для того, чтобы активизировать прерывание в другом процессоре инициатор –процессор в сообщении устанавливал указатель и идентификатор процессора, который должен был выполнить прерывание. Выполнив прерывание, целевой процессор обязан был сбросить в своем регистре межпроцессорной связи свой идентификатор. Таким образом, процессор-инициатор, анализируя соответствующий бит на своей входной шине от целевого процессора, определял окончание операции в целевом процессоре.
Инициализация межпроцессорных сообщений в разных системах происходит по-разному. Так, например, в свое время в системе IBM370 и ей подобным ЭВМ отечественного производства класса ЕС передача межпроцессорных сообщений осуществлялась через специальный интерфейс прямого управления и для активизации, которых использовалась системная команда “СИГНАЛ ПРОЦЕССОРУ”. Формат этой команды был
трех адресный и имел следующий вид.
|
|
|
|
|
|
|
|
|
| |
|
|
КОД ОПЕРАЦИИ
R1 R2 B2 D2
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|





А[B2,D2]-адрес ячейки оперативной памяти, в которой находится байт управляющей информации для адресуемого процессора.
[ R1]- байт состояния адресуемого процессора после выполнения приказа
[R2]- адрес процессора, которому предназначен приказ.
При выполнении данной команды, процессор после считывания байта управляющей информации из памяти формирует запрос на прерывание на интерфейсе прямого управления, выставляет на шины адреса и данных соответствующую информацию , таким образом активизирует запрос на внешнее прерывание в адресуемом процессоре.
Обработчик прерываний в адресуемом процессоре считывает байт управляющей информации с шины данных интерфейса прямого управления, активизируя соответствующие аппаратные средства в соответствии с приказом. Если для выполнения действий в адресуемом процессоре требуется дополнительная информация ,то для этого используются ячейки оперативной памяти, специально выделенные для этой цели.
Для организации межпроцессорных связей в модели мультипроцессорной спецификации на базе процессоров фирмы INTELиспользуется расширенный контроллер прерываний (APIC), имеющий распределенную архитектуру то есть часть его оборудования размещается по-блочно в каждом из процессоров системы, являясь частью аппаратных средств каждого процессора. Каждый такой блок называется локальныйAPIC, состав и работу которого рассмотрим позже.
Отдельная часть расширенного контроллера прерываний размещается на системной плате в “южном мосте”, в котором размещены аппаратные средства для обеспечения ввода вывода. Часть эта носит название IOAPICи предназначена для приема запросов на прерывания от всех источников на системной плате, включая, безусловно , и запросы от внешних устройств в системе. Общая структурная схема представлена ниже.
|
процессор1
локальный APIC
j
процессор2
локальный APIC
процессор3
локальный
APIC
источники
локальных
прерываний
процессорв
Шина APIC IO APIC
южный мост
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
прерывания от устройств
ввода
вывода
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|











Как видно из структурной схемы ,локальные APICпринимают запросы на прерывания от локальных источников для каждого процессора, которые могут находиться в системе. Помимо этого все внутренние источники прерываний в процессоре также направляют свои запросы в локальный блокAPIC
Так как симметричная мультипроцессорная система имеет одну копию операционной системы, а задачи, которые она распределяет между процессорами в каждый момент времени, имеют различные приоритеты в системе ,так же как и запросы на прерывания, то для обеспечения нормального функционирования системы локальные APICдолжны обеспечивать выполнение задач и обработку запросов на прерывания с учетом приоритетности тех и других. Исходя из выше сказанного , функциональная схема каждого локальногоAPICдолжна содержать аппаратные средства для реализации выше указанных требований.
Прежде чем приступить к разбору состава блок-схемы, дадим классификацию прерываний в мультипроцессорной системе.
|
|
|
|
|
|
|
|
|
|
| |
|
источники прерываний
в
мультипроцессорной системе
локальные
прерывания
шинные сообщения
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
прерывания от внутренних источников
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
контроллер
прерываний
8259
|
|
не маскируемые
|
|
|
от IOAPIC
|
|
схемы контроля
|
|
| |
|
|
|
|
|
межпроцессорные
|
|
|
таймер
|
|
| |
|
|
|
маскируемые
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
программные
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|













Архитектура APIC
Архитектура APICразрабатывалась с учетом требований протокола шиныPCI, которая в архитектурахINTELявляется ведущей шиной, организующей связь процессоров с другими компонентами системы.
Для адресации контроллера локального APICиIOAPICсогласно требованиям протокола шиныPCIбыл принят вариант отображения адресов регистров выше упомянутых устройств с отображением на память. Для этого в адресном пространстве системной памяти выделена область для адресации регистров , входящих в состав выше упомянутых устройств.
Процессор, обращаясь к локальному контроллеру APICилиIOAPIC, формирует адрес обращения к системной памяти. В случае, если адрес принадлежит области локальногоAPIC, цикл обращения к памяти не формируется. В случае, если обращение кIOAPIC, контроль возложен на системный чипсет, в которомIOAPICявляется одной из его функций в конфигурационном пространстве шиныPCI.
В архитектуре шины ISAконтроллер прерываний 8259 выполняет не только фиксацию прерываний ,но и берет на себя функцию арбитража среди аппаратных прерываний, формируя в конечном итоге вектор прерывания и передает его в процессор. В архитектуреIOAPICнет схемы арбитража. Арбитраж осуществляется в локальном контроллереAPIC, которомуIOAPICадресует сообщение.
Основной задачей IOAPICявляется:
фиксация прерываний в таблице, количество строк в которой равно количеству входных контактов, на которые поступают запросы на прерывания.
Формирование и передача сообщения на шину для межпроцессорных сообщений.
|
|
|
|
|
|
|
|
|
|
|
| |
|
блок таймеров
вектор таймера
вектора локальных прерываний
вектор системных событий
вектор
ошибок
регистр команды
прерывания
регистр адреса
процессора APICID
регистр логического
адреса
регистр режима логической
адресации
,блок приемной логики
декодер
вектора
регистр обслуживания
прерываний
регистр запросов
прерываний
регистр фиксации формы
сигналов прерываний( по уровню или
по фронту)
блок
приоритета
регистр окончания
прерывания
INTA EXINT[ INTR
регистр
арбитража
|
|
шина адреса/данных
|
|
регистр приоритета задачи
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
блок интерфейса шины APIC
|
|
|
|
|
| |
|
регистр приоритета
процессора
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|































Описание блок-схемы локального APIC.
В состав APICвходит группа регистров фиксирующих приоритет выполняемой задачи приоритета процессора и арбитражного номера процессора. Каждый из них выполняет свою функцию.
Регистр приоритета задачи используется для контроля запросов прерываний от внутренних и внешних источников и только в случае запроса с приоритетом большим, чем приоритет выполняемой задачи, схема приоритетов формирует запрос на прерывание в процессоре.
Другие прерывания фиксируются и будут обслужены, как только значение в регистре приоритета задачи будет достаточным для их обработки. Это дает возможность блокировать операционной системе определенные классы прерываний при выполнении приложений с высоким приоритетом. Данный механизм не распространяется для режимов, не использующих векторную информацию в своих сообщениях, это режимы передачи сообщений о прерываниях немаскируемых NMI,SMI-системного управления, во время инициализации системы-INITи прерываниях эмулирующих прерывания контроллера 8259,когда векторная информация поступает в процессор через системную шину в цикле подтверждения. Данный режим передается процессору путем установки кода в формате кадра ,передаваемого в сообщении.(режимEXTINT).
Регистр приоритета процессора отслеживает текущее состояние приоритета обрабатываемого прерывания, значение которого устанавливается из регистра приоритета задачи или из регистра обслуживания прерывания, поступившего для обработки в процессор, в зависимости от значений в старших тетрадах , которые указывают на классы прерываний.( вектор прерывания имеет размер байта, в котором старшие четыре разряда определяют класс прерывания, а четыре младших разряда определяют номер прерывания в классе : наивысший приоритет имеет нулевой класс ) .
Регистр приоритета арбитража содержит значение наименьшего класса приоритета прерывания в процессоре.
Для этого сравниваются значения в регистрах приоритета задачи, обслуживания и запросов, и зависимости от их значений производится его установка.
Если значение регистра приоритета задачи меньше чем в регистре запросов, то регистр приоритета арбитража принимает максимальное значение класса прерывания трех вышеупомянутых регистров.
Если больше, то производится анализ на сравнение со значением регистра обслуживания.
Если значение регистра приоритета задачи также меньше чем значение в регистре обслуживания, то устанавливается также максимальное значение из трех регистров.
Если регистр приоритета задачи имеет наибольшее значение из трех регистров, то его значение передается в регистр арбитража.
Регистр окончания обработки прерывания.
Установка этого регистра в блоке локального APICвызывает формирование специального сообщения об окончании обработки прерывания в процессоре. ‘Это сообщение формируется, если для данного прерывания в регистре, фиксирующем форму сигнала прерывания, установлен признак “уровень”.
Дело в том, что при данной форме сигнала фиксации запроса на прерывание возможно совместное использование линии запроса несколькими источниками по схеме монтажное “ИЛИ”. В случае такого варианта процессор обязан сообщить контроллеру прерывания на шине об окончании обработки, чтобы контроллер прерывания проверил состояние входной линии запроса и в случае низкого уровня вновь сформировал запрос на прерывания, таким образом , исключив потерю запросов на прерывания от устройств ввода вывода.
Регистры адресации процессора в мультипроцессорной системе.
Как видно из блок- схемы для адресации используются два регистра: регистр логического адреса и регистр физического адреса, кроме того, есть еще регистр режима логической адресации.
В режиме физической адресации адрес процессора формируется во время подачи питания по значениям на четырех входных контактах шины арбитража. Эти первоначальные значения и формируют значение адреса процессора в системе. Схему арбитража мы рассматривали ранее, сейчас же отметим, что по окончанию включения адреса процессоров в четырех процессорной системе имеют значения : 0111,1011,1101,1110. Эти же значения заносятся в арбитражные регистры и соответственно изменяются в процессе работы системы. Таким образом данная архитектура позволяет организовать только систему из четырех агентов. Для увеличения числа агентов на шине используется режим логической адресации.
Режим логической адресации.
В режиме логической адресации используются два варианта или две модели.
FLATмодель
Кластерная модель.
модель определяется значением разрядов 28-31 в регистре режима, если [28-31] =1111, то используется Fмодель, при этом разряды регистра логического адреса с 24 по 31 расширяют количество агентов до восьми.
Кластерная модель использует разряды регистра логического адреса следующим образом:
разряды[28-31] – номер кластера
разряды[24-27]- номер процессора в кластере
таким образом, при принятой схеме логической адресации можно адресовать до 60 агентов в системе так значение адреса кластера равное Fиспользуется для обращения ко всем агентам на шине одновременно.
Но дело в том, что данное количество процессоров на шине разместить на шине при данной архитектуре не возможно, так как арбитражный идентификатор в данной системе имеет всего четыре разряда, поэтому, даже отказавшись от принятой арбитражной схемы , можно только зафиксировать максимум 15 агентов при условии значение 1111 использовать как широковещательный адрес. Поэтому при количестве агентов больше 15 используется иерархическая система , состоящая из нескольких шин связь между которыми осуществляется через специальные аппаратные средства- менеджеры. Такая технология используется в системе неоднородных мультипроцессорных системах, но это уже другая архитектура, которую мы рассмотрим позже.
Регистр команд прерываний.
Данный регистр используется для организации сообщений в системе, поэтому прежде чем разбирать использование информации в этом регистре, целесообразно классифицировать виды сообщений и форматы кадров, передаваемых в них.
Виды сообщений
сообщениеEOI- окончание обработки прерывания
короткое сообщение- для передачи запросов на прерывание
сообщение для выявления агента с наименьшим приоритетом
сообщения типа ’удаленное чтение’ - для передачи информации между агентами
с точки зрения выбора адресата для сообщения все сообщения делятся на две группы;
статическое распределение, когда адресат указывается в сообщении
динамическое, когда адресат выявляется в процессе передачи сообщения в системе- определение адреса процессора с наименьшим приоритетом
Формат сообщения в общем виде имеет следующую структуру
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
11-EOI
01-SHOT
L-УРОВЕНЬ ИЛИ
ФРОНТ
М=1-EOI ВСЕМ АГЕНТАМ
M=0-АДРЕСАТУ
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
1-физ
0-лог
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
000-FIX
001-LOST
PR
010-SMI
100=NMI
101-INIT
110-START
111-резерв
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
















Режимы передачи:
000- FIX
передача сообщения ко всем агентам системы информации, подготовленной в регистре команды прерывания
001- LOST
наименьший приоритет, передается также как и FIXко всем агентам, за исключением того, приемником сообщения становится процессор с наименьшим приоритетом выполняемой задачи
010-SMI
Прерывания, связанные с режимом системного управления
100-NMI
Немаскируемые, прерывания. возникающие при возникновении аппаратных ошибок в системе
101-INIT
Прерывания ко всем агентам для установки их арбитражных идентификаторов в соответствии со значениями, записанными в их регистрах APICID
110-START
Используются как специальные сообщения между процессорами для указания передачи управления загрузочному блоку для начала активизации процессора приложения, используется в процедуре инициализации многопроцессорной системы
Протокол инициализации мультипроцессорной системы.
Функционирование любой вычислительной системы начинается с ее инициализации. Эта процедура начинается с включения питания. В первоначальный момент времени любая система использует аппаратные средства, которые формируя сигнал аппаратного сброса, устанавливается в исходное состояние, и в частности загружают адрес инструкции начальным значением, указывающим на расположение загрузочного блока в постоянной памяти.
Системы, которые не используют постоянную память для загрузки, аппаратно формируют команду ввода вывода с обращением к устройству загрузки.
Но прежде чем произойдет обращение к устройству загрузки, система должна быть уверена в исправности своих аппаратных средств, поэтому во многих системах при инициализации осуществляется прогон тестов автоматически и только после их успешного прохождения формируется вектор, указывающий на первую команду, с которой начинается программа загрузки. Так в архитектуре процессоров фирмы INTELтакие тесты являются частьюBIOS.
В системах со сложной архитектурой, например манфреймах фирмы IBM, операции инициализации и проверку работоспособности аппаратных средств осуществляет сервисный процессор.
В качестве примера рассмотрим протокол инициализации мультипроцессорной системы на базе процессоров фирмы INTELс архитектурой базовой моделиP6.
Для успешной инициализации мультипроцессорной системы протокол накладывает определенные требования и ограничения на систему во время процедуры инициализации:
- все механизмы прерываний в системе должны быть отключены,
- протокол может быть инициирован только после аппаратного сброса,
-по окончании процедуры инициализации, согласно алгоритму, должен быть установлен флаг в блоке локального контроллера APICдля процессора в системе, с которого будет произведена загрузка управляющей программы,
- протокол инициализации основан на том факте, что только одно сообщение может присутствовать на шине в данный момент времени и каждый из агентов может выставить его соответствии с приоритетом.
Действия по инициализации начинаются по сигналу аппаратного сброса, сформированного при включении питания в системе путем активизации диагностических тестов в каждом из процессоров.
Во время прохождения тестов в процессорах арбитраж на шине блокируется до окончания прохождения тестов. Блокировка эта осуществляется путем активизацией сигналов низкого уровня в каждом из процессоров, соединенных между собой в ‘монтажное ИЛИ” на шине арбитража . Поэтому пока будет присутствовать низкий уровень на шине, арбитраж будет заблокирован, и только по окончании тестов в каждом из процессоров он станет высоким.
Далее начинается активизация действий по определению процессора BSPв системе.
Эти действия основаны на следующих положениях:
- процессору, которому будет установлен флаг загрузочного по включению питания, устанавливается низший приоритет путем внешнего монтажа контактов процессоров, подсоединенных к арбитражной шине и подачей сигнала низкого уровня на один из этих контактов в каждом процессоре являющихся двунаправленными.
- для выявления BSPна шине каждый из агентов формирует сообщение типа “всем агентам включая себя” и согласно протоколу формирует в процессе инициализации только один раз
-формируется финальное сообщение, которое автоматически формирует BSPпроцессор, сообщая всем остальным об окончании процедуры.
-формат сообщения содержит вектор прерывания младшие разряды которого формируются по значениям APICIDкаждого из процессоров полученных ими с шины арбитража во время аппаратного сброса при включении питания.
Получив сообщение от агента в соответствии с приоритетом на шине, процессора сравнивают значения младших разрядов вектора из сообщения со своими идентификаторами APICID. Если эти значения равны, то процессор определяется какBSP. Если нет, то процессор будет процессором приложений.
На первый взгляд протокол не обеспечивает определения BSPи содержит противоречивое положение так как каждый процессор посылая свое сообщение будет себя идентифицировать какBSP. Но дело в том , что протокол обязывает каждый процессор принять одно сообщение от себя и три от других процессоров, поэтому в привилегированном положении окажется процессор с наименьшим приоритетом в начальный момент активизации межпроцессорных сообщений . Когда этот процессор получит доступ к шине все другие будут иметь статусы приложений и он установит свой статусBSPи сформирует на шину сообщение окончания процедуры с соответствующим значением вектора прерывания.
Получив на шине финальное сообщение, локальные контроллеры прерываний APICформируют запросы на прерывания, обрабатываемые вBIOS, но так как все процессора, кроме процессора со статусомBSP, имеющие статусы процессоров приложений, будут остановлены до моментов, когда каждый из них получит стартовое сообщение с вектором прерывания от процессораBSP.
Процессор BSP, выставляя на шину стартовое сообщение адресату, в программе включает таймер по истечении которого обращается в оперативную память по определенному адресу с командой чтения, и если адресат присутствует на шине то последний, обрабатывая стартовое сообщение, обязан записать свой идентификатор. Таким образом процессорBSPопределяет наличие агентов на шине.
Лекция N13
1.Проблемы когерентностей кэш в симметричных мультипроцессорных системах. Протоколы MSI,MESI,MOESI.
2. Организация больших многопроцессорных систем на базе процессоров, объеденных в SMP. Архитектура системCC-NUMA,NC-NUMA,NUMA-Q.
3.Организация SMPс межмодульными связями.
4.Блок-схема SMPс межмодульными связями. Организация многопроцессорной системыCC-NUMAс кольцевой топологией на базе подобныхSMPнапримере ‘1многокнижной’ архитектуры сервераZ990
Протокол MSI
Данный протокол поддерживает когерентность КЭШей в мультипроцессорных системах используя три состояния строк в КЭШ:
M-модифицированный
S- разделяемое
I-недействительная
M- Состояние строки в результате записи данных из процессора, свидетельствует о содержание в строке кэш измененных данных и несоответствие данных в строке памяти. Данное состояние приведет всех копий данной строки в кэш всех агентов с состояниеI.
S- Данное состояние устанавливается когда строка кэш содержит действительное значение данных эквивалентной информации в строке системной памяти. Перевод в данные состояние осуществляется при записи из оперативной памяти или из копии строки в любом кэш при состояние М
Устанавливается если в каком либо кэш копия строки переходит из состояния Sв состояние М, или изIи М при условии в последнем случае, если в системе нет уже копии строки в состоянии М, то есть протокол допускает в системе наличие только одной копии с измененными данными. Поэтому при попытке произвести запись процессором в строку с состоянияI(недействит.), при наличии копии строки с состояния М в другой кэш, происходит блокировка операций, а шина представляет процессору кэш со строкой в состоянии М, для того, чтобы данный процессор призвал запись в системную память и кэш того процессора каждый пытался создать еще копии с измененными данными. Только после этого, когда в системе будет отсутствовать строка с состоянием М, может быть произведена следующая модификация строки любым из процессоров в системе.
Из анализа работы протокола следует, что данный протокол имеет существенный недосаток, а именно, при любой попытке вторичной модификации в системе, независимо от того, существует одна копия или несколько в системе, контроллер шины вынужден вводить дополнительный цикл записи в оперативную память агенту с 0 строкой в состояние М для ее перевода в S. И только после этого давать возможность другому агенту производить следующую модификацию, так как протокол имея состояний строк с индексомS, не определяет сколько копий строк оперативной памяти находится в КЭШ агентов.
Если предположить, что в системе находится только одна копия строки, то процессору можно было бы разрешить ее модификацию многократно, пока исходная строка из оперативной памяти не потребуется другим агентам. Такая идея была реализована в протоколе MESI, в котором вводится еще одна строка состояние строки.
Е - единственная. Именно это состояние строки КЭШа позволяет производить многократную модификацию, но как только будет сформирован запрос другим агентом за этой строкой из памяти, процессор, имея копию этой строки с М состоянием, обязан сформировать запрос в память и записать эту строку в кэш память и перевести ее из состояния М в S. Агент выставит запрос и ждет пока процессор, владеющий строкой с состоянием М, запишет в память, а потом читает ее из памяти, устанавливая состояние своей строки разделяемое(S).
Протокол MOSI.
Протокол MOSIвводит новое состояние стокиOWNED-(принадлежащий), означающий, что копия данной строки может находиться в других КЭШах , отличаются от копии в системной памяти, то есть переходит в это состояние из состояния М. пока строка находится в состояние О, все её копии в других кэш имеют состояниеS, то есть одновременно в системе может находится несколько копий, отличных от оригинал а в системной памяти.
Протокол предусматривает только наличие только одной строки в системе с состоянием “owned”. При попытке модифицировать строку с таким состоянием, все копии строки в других кэш приводятся в состояниеI(инвалид), после чего строка переводится в состояниеM-“модифицированное”. Строка в состояние “owned” может переходить в состояниеS, при записи ее оперативной памяти, так как в этом случае будет соответствие между строками в состояниеSв кэш и строки в памяти. ЗначенияM,S,Iтакие же ак и в протоколахMSI,MESI.
Протокол MOESI.
Протокол MOESIэто комбинация протоколовMOSI+MESI=MOESI. Данный протокол позволяет во первых модифицировать копию в кэш, пока строка находится в состояние “Е” без записи ее в оперативную память. При переводе строки в состояние “О”, имеется несколько модифицированных копий в других КЭШах, до момента попытки второй ее модификации, с переводом ее в состояние М после установки ее копий в других кэш в состояниеSпри записи строки в системную память. Возможен вариант оставить строку в состояние “О” при условии удовлетворить запрет на обновление и сохранение им состоянияS.
Мультипроцессоры класса NC-NUMAи СС-NUMA.
Прежде чем рассматривать подробно каждый вид данной категории мультипроцессоров, отметим ключевые характеристики, которыми обладают и которые отличают их от других мультипроцессоров
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOADиSTORE.
3. Доступ к удаленной памяти происходит медленнее чем доступ к локальной памяти.
Подкласс процессоров NC-NUMAхарактеризуется отсутствием кэш памятей в узлах мультипроцессора, и общая блок-схема имеет следующий вид
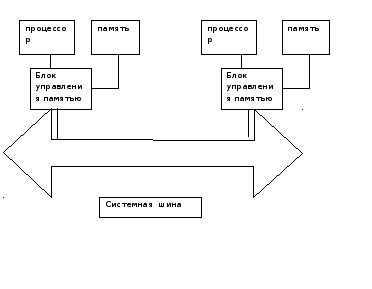
Одной из первых машин NC-NUMAбылаCarnegie-Mellon
Структурная схема, которой была подобная, указанной выше. Машина состояла из набора процессоров LS-11, каждый с собственной памятью, обращение к которой производилось по локальной шине. Когда запрос приходил в блок управления памятью, производилась проверка, находится ли запрашиваемое слово в локальной памяти. Если да, то запрос выдавался на локальную шину. В противном случае запрос направлялся на системную шину в узел, в памяти которого находилось запрашиваемое слово.