

ИИС ЛР 3-12
.pdfЗамена значений используется для замены по таблице подстановок, ко-
торая содержит пары, состоящие из исходного и внесенного значения. Напри-
мер, "кр" –"красный".
Группировка данных позволяет объединять записи по -полям измерениям и агрегировать данные в полях-факторах для дальнейшего анализа.
Преобразование данных к скользящему окну используется тогда, ко-
гда при прогнозировании динамического ряда наблюдается его периодичность.
Учитываются значения факторов не только в данный момент времени, но и за прошлый период.
Слияние предназначено для объединения двух наборов данных по -не скольким одинаковым полям. К исходной таблице добавляются новые поля и/или строки, значения которых беруются из присоединяемой таблицы.
Data Mining (Добыча данных)
Прогнозирование - одна из наиболее востребованных задач анализа. В Deductor включено несколько механизмов построения прогностических моде-
лей, в том числе с использованием самообучающихся алгоритмов. Прогнозиро-
вание возможно лишь после построения какой-либо модели прогноза: нейрон-
ной сети, линейной регрессии.
Нейронная сеть – это самообучающаяся система, способная анализиро-
вать вновь поступающую информацию, находить в ней закономерности, произ-
водить прогнозирование и пр. Данные системы способны имитировать деятель-
ность человеческого мозга.
Несмотря на большое разнообразие нейронных сетей, все они имеют общие черты. Нейронные сети состоят из большого количества взаимосвязан-
ных между собой однотипных элементов – нейронов.
Входы Синапсы Ячейка нейАксон Выход рона
X1 |
W1 |
|
X2 |
W2 |
Y |
… |
|
|
Xn |
Wn |
|
|
Рисунок 14 – Схема нейрона |
|
21
Состояние нейрона определяется по формуле: S = ∑XiWi
где n – число входов нейрона;
Xi - значение i–го входа нейрона;
Wi - вес i–го синапса.
Значение аксона нейрона определяется по формулеy = f(S). Наиболее часто в качестве функции f используется сигмоид.
В общем случае задача обучения нейронной сети сводится к нахожде-
нию некоторой функциональной зависимостиy = f(S). В общем случае такая задача имеет бесконечное множество решений. Для ограничения пространства поиска используется метод наименьших квадратов.
Линейная регрессия предусматривает построение линейной регресси-
онной модели. Полученную в результате модель можно использовать для про-
гнозирования целевой переменной.
Если для простоты предположить, что выходное значение одно, то мож-
но записать a0+X1*a1+X2*a2+...+Xn*an=Y. Таким образом, задача сводится к подбору коэффициентов ai., при котором ошибка рассогласования реальногоY
и рассчитанного Y' значений выходов будет минимальной.
Логистическая регрессия – это разновидность множественной регрес-
сии. С помощью логистической регрессии можно оценивать вероятность того,
что событие наступит для конкретного испытуемого(больной/здоровый, воз-
врат кредита/дефолт и т.д.). Логистическая регрессия описывается уравнением: P=a1*x1+a2*x2+...+an*xn + a0, P=1/(1+exp(-y)) - логистическая функция.
В результате работы данного компонента строится бинарная логистиче-
ская регрессионная модель. Полученную в результате модель можно использо-
вать для прогнозирования целевой бинарной переменной.
Расчет коэффициентов a0,...an производится алгоритмом Ньютона. Це-
лью обучения является получение такого набора коэффициентовai, которые обеспечивают максимальное правдоподобие (likehood).
22
Автокорреляция производит выяснение степени статистической зави-
симости между различными значениями (отсчетами) случайной последователь-
ности, которую образует поле выборки данных. В процессе автокорреляцион-
ного анализа рассчитываются коэффициенты корреляции(мера взаимной зави-
симости) для двух значений выборки, находящихся друг от друга на опреде-
ленном количестве отсчетов, называемые также лагом.
Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила, служит утверждение, что покупатель, приобретающий 'Хлеб', приобретет и 'Молоко' с вероятностью
75%. Впервые эта задача была предложена для поиска ассоциативных правил для нахождения типичных шаблонов покупок, совершаемых в супермаркетах,
поэтому иногда ее еще называют анализом рыночной корзины(market basket analysis).
Пользовательская модель позволяет создавать аналитические модели на основании формул и экспертных оценок. Такая возможность требуется в тех случаях, когда объем исходной выборки мал, либо ее качество недостаточно для того, чтобы обучить нейронную сеть. В этом случае можно воспользоваться хорошо известными простыми моделями, задающимися с помощью формул.
Примером такой модели может служить скользящее среднее или модель авто-
регрессии.
Любой набор данных можно визуализировать одним или несколькими способами: в виде OLAP кубов, таблиц, диаграмм, гистограмм, карты Кохоне-
на, дерева решений, таблицы сопряженности и т.д
Самоорганизующаяся карта Кохонена является одной из разновидно-
стей нейросетевых алгоритмов. Это двумерная карта, имеющая цветную рас-
краску. Интенсивность цвета в определенной точке зависит от данных, которые туда попали. Ячейки, в которые попали элементы с минимальными значениями или не попало вообще ни одной записи, отображаются синим цветом, а ячейки с максимальными значениями окрашиваются в красный.
23
Деревья решений (decision trees) являются одним из самых мощных средств решения задачи отнесения какого-либо объекта(строчки набора дан-
ных) к одному из заранее известных классов. Дерево решений – это классифи-
катор, полученный из обучающего множества, содержащего объекты и их ха-
рактеристики, на основе обучения. Дерево состоит из узлов и листьев, указы-
вающих на класс.
Результатом работы алгоритма является список иерархических правил образующих дерево. Каждое правило – это интуитивно-понятная конструкция вида "Если…то…" (if-then). Дерево может использоваться для классификации объектов, не вошедших в обучающее множество. Чтобы принять решение, к ка-
кому классу следует отнести некоторый объект или ситуацию, требуется отве-
тить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра А больше ?"В. Если ответ положительный,
осуществляется переход к правому узлу следующего уровня. затем снова сле-
дует вопрос, связанный с соответствующим узлом и т. д.
Таблица сопряженности является визуализатором, позволяющим каче-
ство классификации данных. Для решения задачи классификации используется таблица, в которой уже есть выходной столбец, содержащий класс объекта. По-
сле применения алгоритма добавляется еще один столбец с выходным полем,
но его значения уже вычисляются, используя построенную модель. При этом значения в столбцах могут отличаться. Чем больше таких отличий, тем хуже построенная модель классификации.
Таблицу сопряженности удобно применять для оценки качества модели,
построенный с помощью обработчика "Дерево решений".
Контрольные вопросы:
1 Что является отправной точкой для анализа данных Deductorв Stu-
dio?
2Что такое сценарий?
3Что такое узел сценария?
4Что включает в себя очистка данных?
24
5Что включает в себя трансформация данных?
6Что включает в себя добыча данных?
7Что такое парциальная обработка данных?
8Что понимают под факторным анализом?
9Что такое корреляционный анализ?
10Что понимают под выявлением дубликатов и противоречий данных?
11Что такое выравнивание по скользящему окну?
12Что включает в себя прогнозирование данных?
13Что понимают под линейной регрессией?
14Что такое нейронная сеть?
15Что понимают под деревом решений?
16Что представляет собой самоорганизующаяся карта Кохонена?
17Что такое модель ассоциативных правил?
18Что такое модель логистической регрессии?
19Что такое пользовательская модель?
20Что понимают под визуализацией данных?
Практическая часть
Тема 1 Простая аналитика
Постановка задачи: определить в хранилище данныхЗаказыБорей:Заказы объемы и структуру товаров в разрезе групп, проданных Ясеневой И. К рассмотрению не принимаются те товары, количество которых меньше 21 и более 60.
Задания
1 Осуществить фильтрацию данных.
Последовательность выполнения задания
Øактивизировать хранилище данных ЗаказыБорей:Заказы;
Øзагрузить Мастер обработки -  ;
;
Øв диалоговом окне выбрать операцию Фильтрация и нажать [Далее];
25
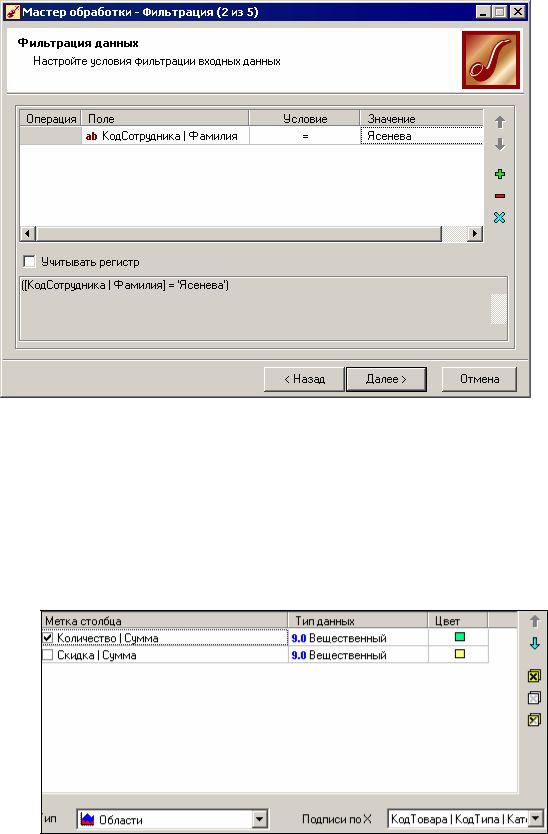
Øнастроить условия фильтрации:
Рисунок 15 – Диалоговое окно настройки фильтрации данных
Øнажать [Далее], [Пуск], [Далее];
Øвыбрать способ отображения данных– Таблица, Диаграмма; нажать
[Далее];
Øнастроить параметры диаграммы: цвет – зеленый, тип – области, под-
писи по Х – Категория;
Рисунок 16 – Фрагмент окна настройки параметров диаграммы
Øнажать [Далее], [Готово];
26
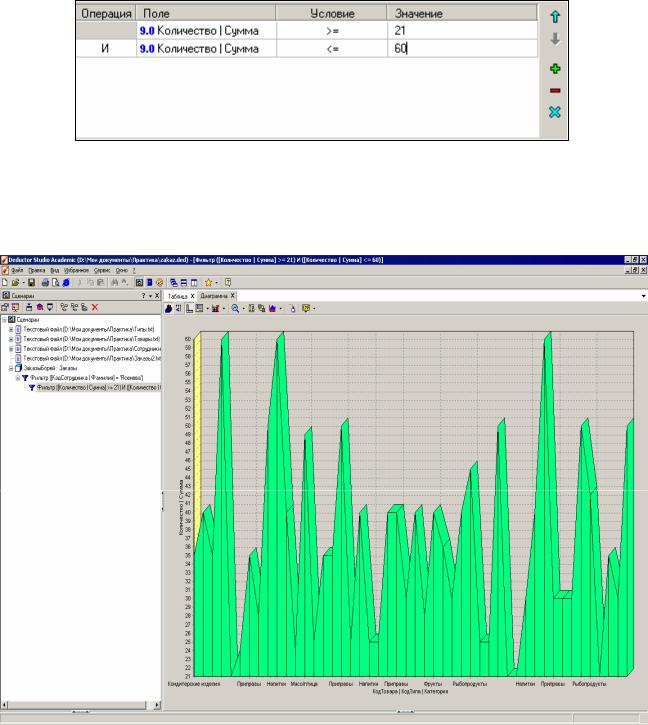
Øпровести сортировку данных по столбцуКоличество:Сумма (1ЛКМ по полю Сумма – по возрастанию, 1ЛКМ - по убыванию, 1ЛКМ - возврат в первоначальное состояние);
Øвыбрать товары в количестве от21 до 60 на основе операции Фильтр
(для настройки условия фильтрации используется кнопкаДобавить условие –
 );
);
Рисунок 17 – Фрагмент окна задания условий фильтрации данных
Øпоследовательность работы и параметры диаграммы аналогичны вы-
шеприведенным.
Рисунок 18 – Диаграмма отфильтрованных данных
27
2 Изменить тип диаграммы на линейчатую, цвет диаграммы - синий.
Последовательность выполнения задания
Øвызвать конструктор Настроить узел -  для узла Фильтр ([Количе-
для узла Фильтр ([Количе-
ство | Сумма] >= 21) И ([Количество | Сумма] <= 60);
Øнастроить требуемые параметры диаграммы.
3 Определить количество товаров по их группам.
Последовательность выполнения задания
Øзагрузить Мастер обработки -  для узлаФильтр ([Количество |
для узлаФильтр ([Количество |
Сумма] >= 21) И ([Количество | Сумма] <= 60);
Øв диалоговом окне выбрать операциюГруппировка данных и нажать
[Далее];
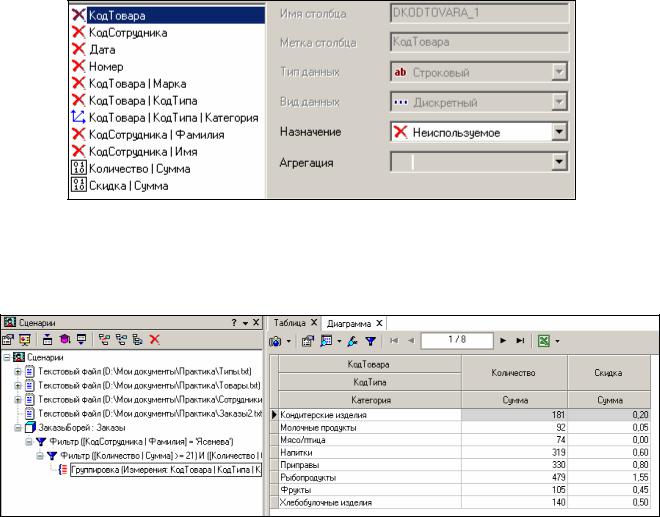
Øнастроить условия группировки данных:
Рисунок 19 – Фрагмент окна настройки условий группировки данных
Øвыбрать способ отображения – таблица, диаграмма;
Øуказать желтый цвет диаграммы и тип – столбчатая диаграмма;
Рисунок 20 – Таблица группировки данных
28
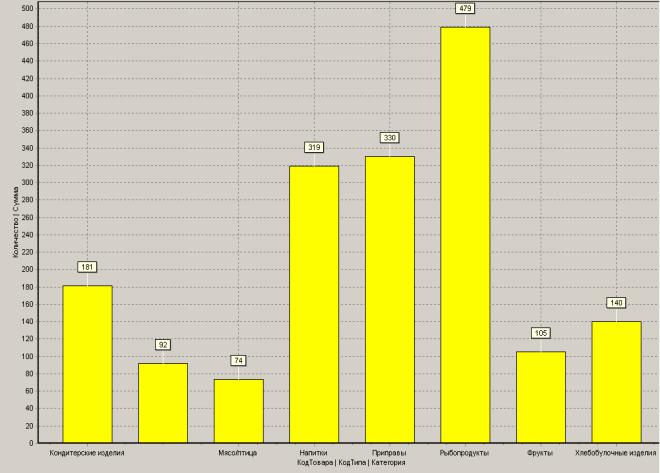
Øвывести метки данных, используя на вкладке Диаграмма пиктограмму
Тип метки - :
:
Рисунок 21 – Столбчатая диаграмма группировки данных
Øпреобразовать диаграмму в круговую и вывести легенду внизу;
Øсделать вывод о реализации товаров Ясеневой И.
Тема 2 Импорт данных
Постановка задачи: Провести графический анализ рентабельности по данным файла База данных по Московской обл за2000-2006 и динами-
ка.xls.
Задания
1 Преобразовать файл База данных по Московской обл за2000-2006 и
динамика.xls. в файлы 2004_Анализ_ФИО.txt и 2006_Анализ_ФИО.txt (Прило-
жение В).
29
Последовательность выполнения задания
Øвыбрать из файла База данных по Московской обл за2000-2006 и ди-
намика.xls следующие поля за2004 г.: Название района; Среднегодовая чис-
ленность работников; Рез. от реал. прод. растениев.: полная себестоимость; Рез.
от реал. прод. растениев.: всего выручено; Рез. от реал. прод. животнов.: полная себестоимость; Рез. от реал. продукции животноводства: выручено; Субсидии на продукцию растениеводства - всего; Субс. на прод. животн. (без субс. на пе-
реработку);
Øскопировать выделенные поля в рабочую книгуMS Excel с именем
ФИО_2004.xls, где ФИО – Ваши инициалы. Файл сохранить в папке Практика;
Øотредактировать файл ФИО_2004.xls:
-удалить строки с номерами столбцов, кодами форм отчетов, кодами показателей, единицами измерений;
-отредактировать названия поле й следующим образом: Название рай-
она; Среднегод. численность работников, чел.; Себестоимость прод. растени-
ев,т.руб.; Выручка от реал.прод. растениев, т.руб.; Себестоимость прод.
жив,т.руб.; Выручка от реал.прод. жив, т.руб.; Субсидии растениев., т.руб.;
Субсидии животнов., т.руб.
- отформатировать шапку и боковик таблицы в соответствии с требова-
ниями ГОСТ;
Øвыполнить расчет промежуточных итогов по названию районов; в ка-
честве операции выбрать Сумма по всем числовым полям;
Øполученную таблицу свернуть по второй группе итогов;
Øвыделить таблицу без итоговой строки;
Øскопировать таблицу в MS Word;
Øскопировать таблицу из MS Word в новый файл MS Excel;
Øдобавить текстовое поле Год перед полем Название района;
Øзаполнить поле Год данными:
- в начальную ячейку ввести значение2004. Назначить ячейке тексто-
вый формат;
30