

BD
.pdf3.4.Базы данных.
3.4.1.Структуры данных.
Оперативная память ПК организована в виде отдельных ячеек с последовательными адресами. Однако часто бывает удобно представлять эти ячейки в виде других структур данных. Например, записи о продажах за неделю удобно представлять в табличной форме, которая является абстрактным представлением данных.
Во время конструирования абстрактных представлений необходимо различать является структура данных статической или динамической, то есть, меняется ли со временем ее форма и размер. В целом статическими структурами проще управлять, чем динамическими. Если структура статическая необходимо только обеспечит способы доступа к различным элементам данных и способы изменения значений элементов, находящихся на определенных местах. В случае динамической структуры необходимо решать проблемы добавления и удаления элементов данных и поиска пространства в памяти для увеличения размера структуры.
Указатели. Указатель – это ячейка (или блок ячеек), содержащий адрес другой ячейки памяти. Применительно к структурам данных указатели используются для записи адресов элементов данных. Таким образом, элемент данных может храниться в какой-либо ячейки памяти, а адрес этой ячейки – в указателе, при помощи которого можно позже получить эти данные. То есть значение указателя сообщит нам, где искать данные («указатель указывает на данные»).
Пример использования указателя. В памяти ПК храниться список рассказов, отсортированный в алфавитном порядке по названию. Такая организация удобна во многих приложениях, но затрудняет поиск рассказов, написанных одним автором, т.к. они разбросаны по всему списку. Для решения этой проблемы можно зарезервировать в каждом блоке ячеек памяти, представляющем один рассказ, отдельную ячейку типа указатель. Тогда в каждом из этих указателей можно хранить адрес другого блока, представляющего произведение того же автора, и все рассказы одного автора будут связаны в замкнутую цепь.
Массивы. Часто удобно представлять данные в виде таблиц, т.е. как двумерный массив. Но память машины организована не как таблица, а как цепочка ячеек с последовательными адресами. Поэтому требуемую прямоугольную структуру массива приходится моделировать. Если массив статичен (то есть его размер не изменяется по мере внесения изменений в данные), то подсчитаем объем памяти необходимый для всего массива, и зарезервируем непрерывный блок ячеек памяти полученного размера. Начиная с первой ячейки этого блока, последовательно в каждую ячейку записываем значения из первой строки массива, после первой строки таким же образом записываем последующие. Такая система записи называется построчной (может быть постолбцовая запись). При обращении к элементам массива транслятор преобразует запросы в фактические адреса памяти. Программист тем временем может представлять данные в табличной форме (абстрактная структура), даже если на самом деле они хранятся в одной строке (фактическая структура).
Списки. Это набор записей, выстроенных в определенной последовательности. Один из способов хранения списка – запись всего списка в один блок ячеек памяти с последовательными адресами (непрерывный список). Если данные динамические, то при добавлении или удалении данных приходится перемещать часть элементов списка в другие ячейки памяти.
Проблем, возникающих при работе с динамическими списками, можно избежать, разрешив хранение отдельных имен в различных областях памяти, а не одном большом непрерывном блоке. Например, можно хранить каждое имя в блоке из девяти смежных ячеек памяти. Первые восемь необходимы для записи самого имени, а последняя ячейка будет использоваться как указатель на следующее имя в списке. Следуя этому принципу, список можно раскидать по небольшим блокам, каждый из 9 ячеек, которые связаны между собой указателями. Подобная организация списков называется связным списком.
Для того чтобы определить начало связного списка, отдельно определяется еще один указатель, в котором хранится адрес первой записи. Так как этот указатель указывает на начало, или голову списка, он называется указателем головы.
Для определения конца связного списка используется пустой указатель (NIL), который является просто определенного вида набором битов и находится в последней записи, указывая, что за ним в списке более нет элементов, пример, если мы условимся никогда не хранить элементы списка по адресу 0; значение 0 никогда не будет являться разрешенным значением указателя, и этому его можно использовать как пустой указатель.
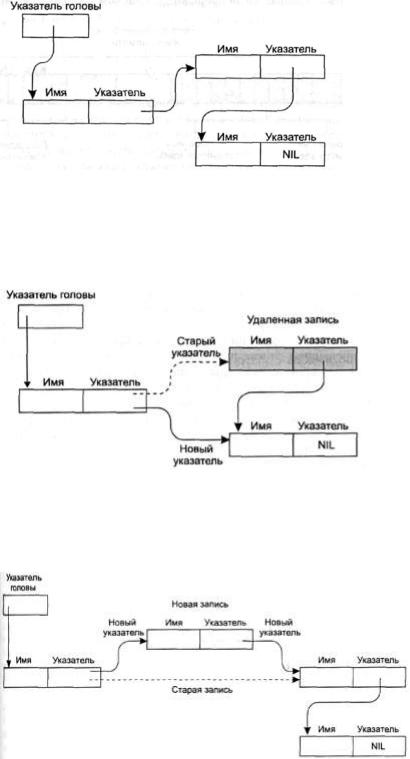
На рис. 3.11 отдельные блоки памяти, в которых хранятся элементы связного списка, представлены в виде прямоугольников. Строение каждого прямоугольника (блока памяти) обозначено надписями над ним. Указатели представлены стрелками, идущими от самого указателя к адресу, на который тот указывает. Для прохождения списка нужно последовать указателю головы — так мы найдем первую запись. Далее необходимо следовать указателям, хранящимся в записях, и по ним переходить от элемента к элементу до достижения пустого (NIL) указателя.
Рис. 3.12. Структура связного списка.
Теперь вернемся к вопросу удаления и добавления элементов в список. Использование указателей устраняет необходимость перемещения имен из одной ячейки памяти в другую, возникающую при хранении списка в одном связном блоке. Удалить имя можно, изменив один указатель. Это означает, что указатель, который ранее указывал на удаленное имя, изменяется и указывает теперь на имя, следующее за удаленным (рис. 3.13). Тогда при обработке списка удаленное имя пропускается.
Рис. 3.13. Удаление записи из связного списка.
При добавлении нового имени находим неиспользуемый блок из девяти ячеек памяти, записываем новое имя в первые восемь ячеек, а в девятую записываем адрес имени, которое должно следовать в списке за новым. Затем изменяем указатель, связанный с именем, которое должно предшествовать новому имени в списке так, чтобы он указывал на этот новый блок (рис. 3.14). После этого новую запись можно будет найти на нужном месте при прохождении списка.
Рис. 3.14. Добавление записи в связный список.
Стек. Если разрешить удаление и добавление данных только в начале или в конце структуры, то можно использовать непрерывную структуру. В стеке последний добавленный элемент всегда будет удален первым (последним прибыл – первым убыл). Тот конец стека, где добавляются или удаляются элементы, называется вершиной стека, другой конец называют основанием стека. Для
реализации стека в памяти компьютера обычно резервируют блок смежных ячеек памяти достаточного размера, чтобы вместить стек с учетом его увеличения или уменьшения.
Очередь – это список, в который записи добавляются с одной стороны, а удаляются с другой (первым прибыл – первым обслужен). Тот конец очереди, откуда удаляются записи, называется головой или началом очереди, конец очереди, куда добавляются записи, называется хвостом очереди.
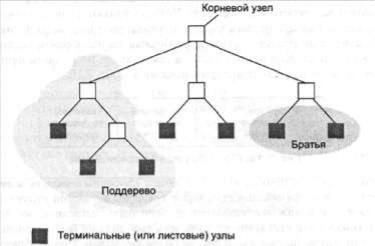
Деревья. Эта структура данных отражает принцип организации типичных компаний. В такой структуру президент находится на вершине, от которой отходят линии к вице-президентам, и т.д. Чтобы дать интуитивное определение дерева накладывает ограничение, состоящее в том, что ни один сотрудник компании не подчиняется двум разным начальникам. То есть разные ветви организации не сливаются на нижнем уровне.
Рис. 3.15. Структура дерева.
Каждый элемент дерева называется узлом (рис. 3.15). Узел, находящийся наверху, называется корневым. Если перевернуть рисунок вверх ногами, этот узел будет находиться на месте основания или корня дерева. Узлы на противоположном конце дерева называются терминальными (или листовыми). Если мы выберем любой нетерминальный узел дерева, то обнаружим, что он вместе с узлами, находящимися ниже, также образует дерево. Эти меньшие структуры называются поддеревьями. Иногда структура деревьев рассматривается так, как если бы каждый узел порождал узлы, находящиеся сразу же под ним. Так определяются предки и потомки. Потомки узла называются дочерними узлами, а его предок - родителем. Узлы, имеющие одного и того же родителя, называются братьями. Глубину дерева определяют как количество узлов в наиболее длинном пути от корня до листа. Другими словами, глубина дерева – это количество горизонтальных уровней в нем.
Бинарное дерево – дерево, где у каждого узла может быть максимум два потомка. Бинарные деревья обычно хранятся в памяти при помощи связной структуры, похожей на связные списки. Каждая запись (или узел) дерева состоит из трех компонентов: 1) данные, 2) указатель на первого потомка узла и 3) указатель на второго потомка узла.
Файловые структуры.
Хранение файла на запоминающем устройстве предписывает, что файл должен быть разделен на блоки, являющиеся физическими записями, совместимыми с используемым устройством хранения. Например, файлы, записанные на диски, должны делиться на блоки размером с сектор, т.е. 512байт. Управление файлами в терминах физических единиц осуществляется операционной системой. Если приложению необходимо найти часть файла, измеряемую в логических записях, оно обращается к операционной системе, чтобы та произвела нужное обращение. Операционная система считывает достаточное для выполнения запроса количество физических записей, размещая полученные данные в оперативной памяти, называемой буфером, а затем предоставляет этот буфер приложению. Аналогично, для записи информации приложение передает данные операционной системе. Операционная система хранит их в буфере до тех пор, пока не накопится полная физическая запись (или файл не будет закрыт), а затем передает эту запись на запоминающее устройство. [1, 4, 5]
3.4.2. Структуры баз данных.
Современные информационные системы, основанные на концепции интеграции данных, характеризуются огромными объёмами хранимых данных, сложной организацией, необходимостью удовлетворять различные требования многочисленных пользователей. Цель любой информационной системы - обработка данных об объектах реального мира.
Вшироком смысле слова база данных - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и, в конечном счёте, автоматизации, например, сеть железных дорог, железнодорожная станция, ВУЗ, и т.д.
Исторически базы данных развивались как способ интеграции систем хранения данных. В настоящее время базы данных стали мощным средством интеграции информации, хранимой и обрабатываемой внутри определенной структуры. Целью создания базы данных служит стремление упорядочить огромные объёмы информации по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков. Сделать это возможно, только если данные структурированы, т.е. существует определенное соглашение о способах представления данных.
Но в то же время при использовании баз данных возникают и проблемы: управление доступом
кданным, передача больших объемов информации без искажения, право собирать и хранить информацию.
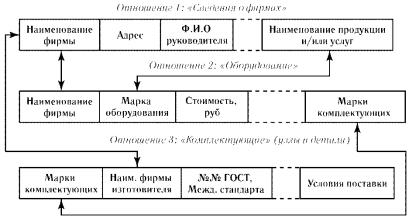
Базы данных представляют собой синтез структур данных и файловых структур. Типичная система базы данных состоит из двух уровней – прикладного уровня (уровня приложений) и системы управления базой данных (СУБД). Приложения отвечают за общение с пользователем (обычно в виде диалога) и они определяют внешние характеристики системы. Управление базой данных осуществляется системой управления базой данных (СУБД) - комплексом программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. После того как приложение определило, какое действие требуется пользователю, оно применяет СУБД как абстрактный инструмент для получения нужных результатов. Если запрос направлен на добавление или удаление данных, именно СУБД в действительности обновляет базу данных. Если запрос предназначен для получения информации, СУБД выполняет требуемый поиск. Централизованный характер управления данными в базе данных предполагает необходимость существования некоторого лица (или группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе. Такой способ управления базой данных часто используют в локальных сетях компьютеров.
Если база данных размещается на нескольких ЭВМ в сети, то она является распределенной. Такая база данных может содержать фрагментированные и/или дублированные данные.
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удалённым (сетевым) доступом. Системы централизованных баз данных с сетевым доступом могут иметь различные архитектуры.
Архитектура файл-сервер систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
Вконцепции клиент-сервер подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объёма обработки данных. Запрос на данные, выдаваемые клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлечённые данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование при работе с базой языка запросов.
Преимущества разделения базы данных на уровни:
1)возможность создания и использования абстрактных инструментов (часть действий изолирована внутри СУБД);
2)возможность управлять доступом к базе данных. Приняв, что доступ к базе данных будет производиться только через СУБД, мы определим, что именно она будет реализовывать ограничения, обусловленные различными подсхемами.
3)достижение независимости данных. Можно изменить организацию базы данных, не меняя приложения. Для внесения изменений, необходимых одному пользователю, нужно модифицировать только общую схему и подсхемы пользователей, которых эти изменения касаются.
3.4.3. Модели баз данных.
Абстрактное представление базы данных называется моделью базы данных. Модель базы данных определяет структуру данных и операции их обработки. Поиски наилучшей модели базы данных все еще ведутся. Цель этих поисков найти модели, позволяющие легко реализовать сложные информационные системы, компактно записывать запросы информации и создавать эффективные системы управления базами данных.
В настоящее время СУБД основываются на использовании иерархической, сетевой или реляционной модели, или на комбинации этих моделей.
Реляционная модель.
Вэтой модели концептуальное представление базы – набор таблиц, состоящих из строк и столбцов. СУБД в таком случае будет включать процедуры, которые позволят приложению выбирать определенные элементы определенной строки таблицы.
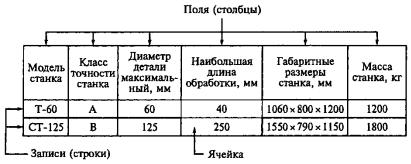
Внастоящее время эта модель является наиболее распространенной (рис. 3.16, 3.17). Данные в такой базе хранятся в прямоугольных таблицах (называемых отношениями). Строки в таблице называются записями, столбцы – атрибутами (полями). Каждая запись столбца описывает некоторую характеристику, или атрибут, сущности, представляемой соответствующей строкой. Значения атрибутов определяются из доменов. Домен – область определения значений одного или нескольких атрибутов.
Поле - элементарная единица логической организации данных, которая соответствует неделимой единице информации - реквизиту. Для описания поля используются следующие характеристики:
1)имя поля (например, Фамилия, Имя, Отчество, Дата рождения);
2)тип данных, которые будут находиться в этом поле (например, символьный, числовой, календарный);
3)длина (например, 15 байт, причём длина поля будет определяться максимально возможным количеством символов);
4)точность для числовых данных (например, два десятичных знака для отображения дробной части числа).
Запись - совокупность логически связанных полей. Экземпляр записи - отдельная реализация
записи, содержащая конкретные значения её полей.
Файл (таблица) - совокупность экземпляров записей одной структуры. Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики. В структуре записи файла указываются поля, значения которых являются:
•первичными ключами, которые идентифицируют экземпляр записи;
•вторичными ключами, которые играют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Рис. 3.16. Структура таблицы реляционной базы данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1)каждый элемент таблицы - один элемент данных;
2)все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
3)каждый столбец имеет уникальное имя;
4)одинаковые строки в таблице отсутствуют;
5)порядок следования строк и столбцов может быть произвольным.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется
простым ключом (ключевым полем, первичным ключом). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Нормализация таблиц представляет собой способы разделения одной таблицы базы данных на несколько таблиц, объединенных связями. Таблица находится в первой нормальной форме, когда ни одно из полей не содержит более одного значения и ключевое поле не пусто. Эта форма является основой реляционной модели данных. В такой таблице нет полей, которые можно было бы разделить на несколько. Таблица находится во второй нормальной форме, если она удовлетворяет требованиям первой нормальной формы и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом (каждому значению ключевого поля соответствует одно значение поля таблицы). Если таблица имеет простой первичный ключ, то она автоматически находится во второй нормальной форме. Таблица находится в третьей нормальной форме, если она удовлетворяет определению второй нормальной формы и ни одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля. Требование третьей нормальной формы сводится к тому, чтобы все не ключевые поля зависели только от первичного ключа и не зависели друг от друга. Процесс нормализации позволяет разработать базу данных, требующую наименьших ресурсов памяти.
Первичная разработка реляционной базы данных включает в себя создание таблиц, составляющих базу данных. Как показывает практика удобно разбивать большие таблицы на несколько небольших, если это можно сделать без потери информации. Над таблицами можно производить следующие операции: 1) выбрать строку, 2) выбрать столбец; 3) объединить несколько таблиц в одну. [4, 5]
В действительности данные базы хранятся на запоминающем устройстве. Чтобы освободить разработчика базы данных от подробностей фактической реализации хранения, предусмотрена СУБД, которая позволяет писать приложения в терминах модели базы данных. В обязанности СУБД входит получение команд в терминах реляционной модели и преобразование их в действия, проводимые в действительной структуре хранения. Это делается за счет предоставления набора процедур, которые приложение может использовать как абстрактные инструменты.
Простейший способ, при помощи которого СУБД может реализовать таблицу – записать ее в виде последовательного файла, в котором каждая строка является логической записью. Но такая организация данных при выполнении операции поиска потребует последовательного поиска в файле, а этот процесс занимает много времени, если таблица большая. Поэтому СУБД, вероятно, будет хранить таблицу как индексированный файл или применять методы хеширования для обеспечения быстрого доступа к данным.
Рис. 3.17. Принцип организации связей между разными отношениями (таблицами) в реляционной модели
Иерархическая модель.
Модель позволяет строить базы данных с древовидной структурой, где каждый узел содержит свой тип данных (рис. 3.18).
Для представления такой модели используется ориентированный граф. Граф – графическое представление математической модели системы связей между объектами любой природы. Объекты задаются в графе точками, которые называются вершинами, связи между объектами – линиями, соединяющими вершины, - ребрами или дугами графа. Ребро может быть ориентированным, т.е. иметь определенное направление от одной вершины к другой, либо неориентированным. Число ребер, соединяющих две вершины, может быть произвольным, поскольку оно определяется количеством и характером связей между этими вершинами.
Рис. 3.18. Иерархическая структура модели базы данных.
К основным понятиям иерархической структуры базы данных относятся: уровень, элемент (узел), связь. Узел - это совокупность данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчинённую никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчинённые) узлы (вершины) находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один путь от корневой записи. Перемещение по такой системе от одной записи к другой осуществляется с помощью ссылок. Основные достоинства иерархической модели – простота описания иерархических структур реального мира и быстрое выполнение запросов.
Сетевая модель.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом (рис. 3.19).
Рис. 3.19. Сетевая модель базы данных.
Объектно-ориентированная база данных является одной из новейших моделей, она начала разрабатываться в связи с появлением объектно-ориентированных языков программирования в 90- е г.г. ХХ века. Она состоит из объектов, связи между которыми отражают отношения между объектами. Связи между объектами в такой базе данных обычно поддерживаются СУБД, поэтому подробности их реализации не касаются программиста, разрабатывающего приложения. Когда новый объект добавляется в базу, приложению необходимо указать с какими объектами его нужно связать в базе. СУБД сама создает необходимую для регистрации этих связей систему указателей.
3.4.4.Системы управления базами данных (СУБД).
Как упомянуто выше, СУБД называют программную систему, предназначенную для создания на компьютерах общей БД, используемой для решения множества задач. Подобные системы служат для поддержания базы данных в рабочем состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным. СУБД предназначена для централизованного управления базой данных в интересах всех работающих в этой системе пользователей.
По степени универсальности различают два класса СУБД: 1) системы общего назначения; 2) специализированные системы.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
СУБД общего назначения не ориентированы на какую-либо предметную область или на информационные потребности какой-либо группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели компьютера в определённой операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной базой данных. Этим СУБД присущи развитые функциональные возможности и даже определённая функциональная избыточность.
СУБД общего назначения характеризуются:
-временем выполнения операций импортирования базы данных из других форматов;
-скоростью создания индексов и выполнения таких массовых операций, как обновление, вставка, удаление данных;
-максимальным числом параллельных обращений к данным в многопользовательском режиме; -временем генерации отчёта.
СУБД выполняет следующие функции:
1.Обеспечение целостности данных на уровне СУБД. В случае многопользовательских систем стоимость неправильных или утерянных данных может быть огромной и иметь разрушительные последствия. В таких средах главная роль СУБД сохранить целостность базы данных.
Эта характеристика подразумевает наличие средств, позволяющих удостовериться, что информация в базе данных всегда остаётся корректной и полной. Должны быть установлены правила целостности, и они должны храниться вместе с базой данных и соблюдаться на глобальном уровне. Целостность данных должна обеспечиваться независимо от того, каким образом данные заносятся в память (в интерактивном режиме, посредством импорта или с помощью специальной программы).
Одна транзакция (процесс изменения базы данных, вызванный передачей одного входного сообщения) может потребовать нескольких действий на уровне базы данных. Например, для перевода средств между банковскими счетами необходимо уменьшить баланс одного счета и увеличить баланс другого. Между этими двумя действиями в базе данных может быть противоречие, т.к. в краткий миг между списанием средств и зачислением их на другой счет наблюдается недостача средств. В случае больших баз данных с огромным количеством транзакций высока вероятность того, что в случайные моменты времени можно застать базу данный в середине выполнения транзакции. Запросы на выполнение транзакций или неполадки оборудования могут произойти в то время, когда баз данных находится в противоречивом состоянии. Цель СУБД – гарантировать, что неполадка не зафиксирует базу данных в противоречивом состоянии.
Ксредствам обеспечения целостности данных на уровне СУБД относятся:
-встроенные средства для назначения первичного ключа, в том числе средства для работы с типом полей с автоматическим приращением, когда СУБД самостоятельно присваивает новое уникальное значение;
-средства поддержания ссылочной целостности, которые обеспечивают запись информации о связях таблиц и автоматически пресекают любую операцию, приводящую к нарушению ссылочной целостности.
Некоторые СУБД имеют хорошо разработанный процессор СУБД для реализации таких возможностей, как уникальность первичных ключей, ограничение (пресечение) операций и даже каскадное обновление и удаление информации. В таких системах проверка корректности, назначаемая полю или таблице, будет проводиться всегда после изменения данных, а не только во время ввода информации с помощью экранной формы. Это свойство можно настраивать для каждого поля и для записи, в целом, что позволяет контролировать не только значения отдельных полей, но и взаимосвязи между несколькими полями данной записи.
2. Обеспечение безопасности. СУБД обычно содержат средства обеспечения безопасности данных. Такие средства обеспечивают выполнение следующих операций:
-шифрование прикладных программ;
-шифрование данных;
-защиту паролем;
-ограничение уровня доступа (к базе данных, к таблице, к словарю, для пользователя).
3.Работа в многопользовательских средах. Практически все СУБД, предназначены для работы в многопользовательских средах, но обладают для этого различными возможностями.
Обработка данных в многопользовательских средах предполагает выполнение программным продуктом следующих функций:
-блокировку базы данных, файла, записи, поля;
-идентификацию станции, установившей блокировку;
-обновление информации после модификации;
-контроль за временем и повторение обращения;
-обработку транзакций (транзакция - последовательность операций пользователя над базой данных, которая сохраняет её логическую целостность);
-работу с сетевыми системами
4.Импорт – экспорт данных. Эта характеристика отражает возможность обработки СУБД информации, которая подготовлена другими программным средствами. [1, 4, 5]
Доступ к данным посредством языка SQL Язык запросов SQL (Structured query language -
язык структурированных запросов) реализован в целом ряде популярных СУБД для различных типов компьютера либо как базовый, либо как альтернативный. Является международным языком запросов. Он предоставляет развитые возможности, как пользователям БД, так и специалистам в области обработки данных. Этот язык широко используется программистами, создающими приложения для работы с базами данных.
Любая СУБД позволяет выполнять четыре простейшие операции с данными:
-добавлять в таблицу одну или несколько записей;
-удалять из таблицы одну или несколько записей;
-обновлять значения некоторых полей в одной или нескольких записях;
-находить одну или несколько записей, удовлетворяющих заданному условию.
Для выполнения этих операций используется механизм запросов. Результатом выполнения запросов является либо отобранное по определенным критериям множество записей, либо изменения в таблицах. Запросы к базе формируются на языке SQL.
Этапы проектирования и создания базы данных.
1)построение информационно-логической модели данных предметной области;
2)определение логической структуры реляционной базы данных;
3)конструирование таблиц базы данных;
4)создание схемы данных;
5)ввод данных в таблицы (создание записей);
6)разработка необходимых форм, запросов, макросов, модулей, отчетов;
7)разработка пользовательского интерфейса.
3.4.5. Microsoft Access - СУБД реляционного типа.
СУБД Access хранит все данные в одном файле, хотя и распределяет их по разным таблицам. Базой данных Access является файл, который имеет расширение mdb. Этот файл может содержать не только таблицы, но и другие объекты приложений Access — запросы, формы, отчеты, страницы доступа к данным, макросы и модули.
На первый взгляд СУБД Access очень похожа по своему назначению и возможностям на программу электронных таблиц Microsoft Excel. Однако между ними существуют принципиальные различия:
1)При работе с электронной таблицей Excel вы можете в ячейку таблицы внести любую информацию, вследствие чего на рабочем листе можно разместить и таблицу, и текст, и рисунок.
Вразные ячейки одного столбца таблицы могут при необходимости вноситься разные данные — числа, текст, даты. Таблица в базе данных Access отличается от таблицы Excel тем, что в ней, для каждого поля записи (столбца) определен тип данных.
2)Access позволяет не только вводить данные в таблицы, но и контролировать правильность вводимых данных. Для этого необходимо установить правила проверки прямо на уровне таблицы. Тогда каким бы образом не вводились данные — прямо в таблицу, через экранную форму или на странице доступа к данным, Access не позволит сохранить в записи те данные, которые не удовлетворяют заданным правилам.
3)Таблицы баз данных могут включать в себя огромное количество записей, и при этом СУБД обеспечивает удобные способы извлечения из этого множества нужной информации.
4)Если все необходимые для работы данные, вы будете хранить в документах Word и электронных таблицах, то по мере накопления информации вы просто можете запутаться в большом количестве файлов. Access позволяет хранить все данные в одном файле и осуществлять доступ к этим данным постранично, т. е. не превышая ограничений на ресурсы памяти компьютера.
5)В Access возможно создание связей между таблицами, что позволяет совместно использовать данные из разных таблиц. При этом для пользователя они будут представляться одной таблицей. Реализовать такую возможность в системах управления электронными таблицами сложно, а иногда просто невозможно.
6)Устанавливая взаимосвязи между отдельными таблицами, Access позволяет избежать ненужного дублирования данных, экономить память компьютера, а также увеличить скорость и точность обработки информации. Для этого таблицы, содержащие повторяющиеся данные, разбивают на несколько связанных таблиц.