

Int scanf(const char * форматная_строка, …);
форматная_строкаопределяет способ чтения значений в переменные, на которые указывает список аргументов. Форматная строка состоит из трёх типов символов:
Спецификаторы формата
Специальные символы
Стандартные символы
Функция scanf( )возвращает число введённых полей. Она возвращаетEOF, если обнаруживается преждевременный конец файла.
Спецификаторы формата перечислены в следующей таблице:
|
Код %c %d %i %e %f %lf %g %o %s %x %p %n
%u %[] |
Значение Читает одиночные символы Читает десятичное число Читает десятичное число Читает число с плавающей запятой Читает число с плавающей запятой Читает число с плавающей запятой двойной точности Читает число с плавающей запятой Читает восьмеричное число Читает строку Читает шестнадцатеричное число Читает указатель Получает целочисленное значение, равное числу прочитанных символов Читает беззнаковое целое Сканирует множество символов |
В scanf( ) следует передавать адреса. Это означает, что все аргументы должны быть указателями на переменные. Например, для чтения целого в переменнуюcountнадо использовать следующий вызовscanf():
scanf(“%d”, &count);
Во избежание ошибок при вводе из-за несовпадения форматов, можно пользоваться значением возвращаемым функцией scanf().
Например:
#include <stdio.h>
#include <clocale>
int main()
{
setlocale(LC_CTYPE,"Russian");
int x, flag = 0;
printf("Введите число ");
do{
flag = scanf("%d", &x);
if(flag != 1) {
puts("Вы попытались ввести не число,");
puts("попробуйте ещё раз");
fflush(stdin);
}
}while(flag != 1);
printf("Введённое Вами число %d\n", x);
return0;
}
Файловая система ANSI C
Заголовочный файл stdio.hпредоставляет прототипы для функций ввода-вывода и определяет три типа:size_t,fpos_tиFILE. Типыsize_tиfpos_t– зависят от адресного пространства (обычно unsigned long).stdio.hтакже определяет несколько макросов. Наиболее значимые NULL, EOF, FOPEN_MAX, SEEK_SET, SEEK_CUR, SEEK_END.
|
Имя |
Функция |
|
fopen() fclose() putc() fputc() getc() fgetc() fseek() fprintf() fscanf() feof() ferror() rewind() remove() fflush() |
Открывает файл Закрывает файл Записывает символ в файл Аналогично putc() Читает символ из файла Аналогично getc() Переходит к указанному байту в файле Делает то же в файл, что и printf() на консоль Делает то же с файлом, что и scanf()cконсолью Возвращает истину при достижении конца файла Возвращает истину при обнаружении ошибки Сбрасывает индикатор позиции файла на начало файла Стирает файл Очищает буфер файла |
Запись символа
Система ввода-вывода ANSIС определяет две эквивалентные функции, выводящие символ – putc() иfputc(). Поддержка двух идентичных функций необходима для совместимости со старыми версиями С.
Функция putc() используется для записи символов в поток, ранее открытый функцией fopen(). Прототип для putc() следующий:
int putc(int ch, FILE *fp);
где fp– это указатель на файл, возвращённыйfopen( ), аch– выводимый символ.
Если putc( ) выполнена успешно, она возвращает выведенный символ. В противном случае возвращаетEOF.
Чтение символа
Имеется две эквивалентные функции для ввода символа – getc() и fgetc(). Функцияgetc( ) используется для чтения символа из потока, открытого на чтение с помощьюfopen( ). Прототипgetc( ) следующий:
intgetc(FILE*fp);
где fp– это указатель на файл типа FILE *, возвращенный fopen(). Функцияgetc( ) возвращаетEOFпри достижении конца файла. Для чтения текстового файла до конца следует использовать следующий код:
ch = getc(fp);
while( ch != EOF) { ch = getc(fp); }
fclose( )
Функция fclose( ) используется для закрытия потока, ранее открытого с помощьюfopen( ). Она сохраняет в файл данные, находящиеся в дисковом буфере, и выполняет операцию системного уровня по закрытию файла.
Функция fclose( ) имеет прототип:
intfclose(FILE*fp);
где fp– это указатель на файл возвращённыйfopen( ). Если возвращён 0, то операция закрытия была выполнена успешно, а еслиEOF, то, значит, была ошибка.
Использование feof( )
Когда файл открыт для двоичного ввода, может быть прочитано значение равное EOF. В результатеgetc( ) будет отображать состояние конца файла, хотя конец файла не достигнут. Для разрешения этой проблемы в С имеется функцияfeof( ).
Её прототип:
intfeof(FILE*fp);
где fp – идентифицирует файл. Функцияfeof() возвращает не 0, если достигнут конец файла, в противном случае она возвращает 0. Следующий код читает двоичный файл, пока не встретится конец файла:
while(!feof(fp)) ch = getc(fp);
Следующая программа копирует файл любого типа. Файлы открываются в двоичном режиме, и feof() используется для проверки наличия конца файла:
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
FILE *in, *out;
char ch, p[1025], p1[1025];
puts("Input filename");
fgets(p,1025,stdin);
if(p[strlen(p)-1] == '\n') p[strlen(p)-1]='\0';
printf("Length of filename now = %lu\n", strlen(p));
puts("Output filename");
fgets(p1,1025,stdin);
if(p1[strlen(p1)-1] =='\n') p1[strlen(p1)-1]='\0';
printf("Length of filename now = %lu\n", strlen(p1));
if((in=fopen(p, "rb")) == NULL) {
printf("Cannot open source file.");
return 1;
}
if((out=fopen(p1, "wb")) == NULL) {
printf("Cannot open destination file.");
return 1;
}
while(!feof(in)) {
ch = getc(in);
if(!feof(in)) putc(ch, out);
}
fclose(in);
fclose(out);
return 0;
}
Работа со строками: fgets() и fputs()
Файловая система ввода-вывода С содержит две функции, которые могут читать или писать строки в поток – fgets() и fputs(). Они имеют следующие прототипы:
int fputs(const char *str, FILE *fp);
char *fgets(char *str, int длина, FILE *fp);
Функция fputs() подобнаputs(), за исключением того, что она пишет строку в указанный поток. Функция fgets() читает строку из указанного потока, пока не встретится символ новой строки или не будет прочитано (длина-1) символов. Если прочитан символ новой строки, то он станет частью строки. В обоих случаях результирующая строка завершается нулевым символом. Функция возвращаетstrв случае успеха и нулевой указатель - в случае ошибки.
Можно использовать fgets() для чтения строки с клавиатуры. Чтобы сделать это, надо использовать stdin как указатель на файл. Например:
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
char s[80];
printf("Enter a string: ");
fgets(s, 80, stdin);
if(s[strlen(s)-1] == '\n') s[strlen(s)-1]='\0';
puts(s);
return 0;
}
fread( ) и fwrite( )
Файловая система предоставляет две функции, позволяющие читать и писать блоки данных - fread( ) иfwrite( ). Их прототипы:
size_t fread(void *буфер, size_t число_байт, size_t объём, FILE *fp);
size_t fwrite(const void *буфер, size_t число_байт, size_t объём, FILE *fp);
В случае fread()буфер– это указатель на область памяти, которая получает данные из файла. В случаеfwrite()буфер– это указатель на информацию, записываемую в файл. Длина каждого элемента в байтах определяется вчисло_байт. Аргументобъёмопределяет, сколько элементов (каждый длинойчисло_байт) будет прочитано или записано.fp – это указатель на ранее открытый поток.
Функция fread( ) возвращает число прочитанных элементов. Данное значение может быть меньше, чемобъём, если раньше был достигнут конец файла или произошла ошибка. Функцияfwrite( ) возвращает число записанных элементов. Данное значение равнообъём, если не возникла ошибка.
Пример
#include <stdio.h>
struct bal{
char name[80];
float cash;
};
int main(void)
{
register int i;
FILE *fp;
bal balance[100];
// открытие на запись
if((fp=fopen("balance","wb"))==NULL) {
printf("Cannot open file.\n");
return 1;
}
for(i=0;i<100;i++) {
balance[i].name[0]='a'+(i%26);
balance[i].name[1]='a'+(i/26);
balance[i].name[2]='\0';
balance[i].cash=(float)i;
}
// сохранение массива balance
fwrite(balance,sizeof balance,1,fp);
fclose(fp);
//обнуление массива
for(i=0;i<100;i++) {balance[i].cash=0.0;}
if((fp=fopen("balance","rb"))==NULL) {
printf("Cannot open file.\n");
return 1;
}
//чтение массива
fread(balance, sizeof balance,1,fp);
//вывод содержимого массива
for(i=0;i<100;i++) {
printf("%s = ", balance[i].name);
printf("%9f\n",balance[i].cash);
}
printf("\n");
fclose(fp);
return 0;
}
Указатели
Указатели предоставляют способ, позволяющий функциям модифицировать передаваемые аргументы.
Указатели используются для динамического выделения памяти.
Использование указателей может повысить эффективность работы некоторых программ.
Указатели, как правило, используются для поддержки некоторых структур данных типа связанных списков и двоичных деревьев.
Указатели – это адреса.
Указатель содержит адрес памяти. Как правило, данный адрес содержит местоположение какой-либо переменной в памяти. Если одна переменная содержит адрес другой, то говорят, что первая переменная указывает на вторую.
Переменные-указатели
Если переменная должна содержать указатель, она объявляется следующим образом:
тип *имя;
где тип– это любой допустимый тип (базовый тип указателя), аимя– это имя переменной-указателя. Все арифметические действия с указателями выполняются применительно к базовому типу. Поэтому базовый тип указателя играет важную роль.
Операторы для работы с указателями
Имеется два специальных оператора для работы с указателями - * и &.
Оператор & - это унарный оператор, возвращающий адрес операнда. Например:
p=# помещает адрес переменной num в p.
Оператор * - это унарный оператор, возвращающий значение переменной, находящейся по указанному адресу. Например, если р содержит адрес памяти переменной num, то
q=*p; поместит значение num в q.
Пример:
#include <stdio.h>
int main(){
int num, q;
int *p;
num = 100;
p=#
q=*p;
printf("%d\n", q);
return0;
}
Арифметические действия с указателями
К указателям могут применяться только две арифметические операции: сложение и вычитание. Помимо прибавления или вычитания к указателю целых чисел, можно вычитать из одного указателя другой. Нельзя умножать или делить указатели, нельзя складывать указатели, нельзя добавлять или вычитать типы float и double.
Односвязные списки
Организация данных, способ их расположения в памяти, зависит от алгоритма, который будет использоваться.
Односвязный список – это способ соединения объектов, таким образом, когда каждый объект указывает на следующий объект в этом списке. Порядок расположения объектов зависит от приложения, и обычно это просто порядок, в котором программа встречает данные. Списки особенно полезны тогда, когда порядок элементов в них не играет роли.
Списки особенно полезны в тех случаях, когда данные в памяти необходимо запоминать сразу же, а мы заранее не знаем, сколько данных можем получить, или когда требуется переставлять данные произвольным образом.
Хотя структура данных не может содержать экземпляр самой себя, она может содержать указатель на экземпляр самого себя. Если используется этот указатель, чтобы указывать на следующий элемент в списке, можно быстро и просто создавать списки, а также добавлять новые элементы в любое место списка, в том числе и в начало. Потребуется «сигнальное» значение для обозначения конца списка, и значение NULLподходит для этой цели превосходно.
Адрес следующего
Значение
Адрес следующего
Значение
NULL
Значение
Структуры и функции для односвязных списков
Для создания односвязного списка, содержащего числа типа int, прежде всего, требуется подходящая структура данных.
Листинг 1
struct LIST
{
int Object;
struct LIST *Next;
};
Добавление элементов
Новый элемент можно поместить в начале, в конце или где-нибудь в середине списка. Начнем с функции, добавляющей элемент где-то в середину списка; две другие функции являются фактически частными случаями данной функции.
Листинг 2
int LAdd(LIST **Item, int Object)
{
LIST *NewItem;
if(Item == NULL) {
printf("Error argument function LAdd\n");
exit(1);
}
try{NewItem = new LIST;}
catch(...){
puts("Allocation error!\n");
return 0;
}
NewItem->Object = Object;
if(NULL == *Item) /* Обработать пустой список */
{
NewItem->Next = NULL;
*Item = NewItem;
}
else /* Вставить сразу после текущего элемента */
{
NewItem->Next = (*Item)->Next;
(*Item)->Next = NewItem;
}
return 1;
}
Данная функция вставляет элемент в список после того элемента, адрес которого ей передаётся. Хотелось бы также иметь возможность вставлять новый элемент перед тем элементом, адрес которого передаётся в функцию. Эту задачу выполняет следующая функция.
Листинг 3
int LFront(LIST **Item, int Object)
{
int Result = 1;
LIST *p = NULL;
if(Item == NULL) {
printf("Error argument function LFront\n");
exit(1);
}
Result = LAdd(&p, Object);
if(1 == Result) {
p->Next = *Item;
*Item = p;
}
returnResult;
}
Однако для односвязных списков это сопряжено с некоторыми трудностями. Можно сделать это только в начале списка, так как невозможно добраться до предыдущего элемента, чтобы изменить его указатель Next.
Добавлять элементы в начало списка выгодно, так как это выполняется быстро. Однако иногда может потребоваться поместить новые элементы в конец списка.
Листинг 4
int LAppend(LIST **Item, int Object)
{
int Result = 1;
LIST *EndSeeker;
if(Item == NULL) {
printf("Error argument function LAppend\n");
exit(1);
}
if (NULL == *Item)
{
Result = LAdd(Item, Object);
}
else
{
EndSeeker = *Item;
while(EndSeeker->Next != NULL)
{
EndSeeker = EndSeeker->Next;
}
Result = LAdd(&EndSeeker, Object);
}
returnResult;
}
Удаление элемента
Элемент удаляется из списка достаточно просто в том случае, если требуется только освободить память. Однако это не всё, что нужно сделать. Проблема заключается в целостности списка. Можно легко удалить элемент, стоящий после того, который нам указан. Но поскольку у нас нет указателя на предыдущий элемент, можно удалить тот, что указан, и вернуть указатель на следующий элемент.
Листинг 5
LIST *LDeleteThis(LIST *Item)
{
LIST *NextNode = NULL;
if(Item != NULL)
{
NextNode = Item->Next;
delete Item;
}
returnNextNode;
}
Следующая функция удаляет элемент, следующий за указанным.
Листинг 6
void LDeleteNext(LIST *Item)
{
if(Item != NULL && Item->Next != NULL)
{
Item->Next = LDeleteThis(Item->Next);
}
}
Очередь
В основных чертах очереди похожи на стеки, но подчиняются другому набору правил – первым пришёл, первым ушёл. При таком режиме можно добавлять элементы только в конец очереди и удалять элементы только из начала очереди. Эта очередь функционирует точно так же, как и обычная очередь в магазине или на почте.
Очереди часто используются при моделировании. Очереди могут быть также полезными в системном программировании. Например, многозадачные операционные системы хранят события и сообщения в очереди или, чаще, во множестве очередей – по одной для каждого текущего процесса.
Программировать очередь с помощью односвязного списка не так удобно, как стек, но это можно осуществить. Хитрость заключается в том, что используются два указателя: один на начало очереди, а другой – на её конец.
Обход односвязного списка
Алгоритм обхода односвязного списка посещает каждый пункт списка. При этом над каждым пунктом выполняется какая-либо операция, например, вывод содержания на экран или изменение данных.
p = List;
while(p != NULL)
{
printf("%d ", p->Object);
p = p->Next;
}
Можно выполнить этот обход и при помощи цикла for:
for(p = List; p != NULL; p = p->Next) printf("%d ", p->Object);
Бинарное дерево поиска
Поле, по которому производится поиск, называется поисковым ключом, или просто ключом.
Для каждого узла Nбинарное дерево поиска удовлетворяет следующим трём условиям:
Значение поискового ключа узла Nбольше всех значений поисковых ключей, содержащихся в левом поддеревеTL.
Значение поискового ключа узла Nменьше всех значений поисковых ключей, содержащихся в правом поддеревеTR.
Деревья TLиTRявляются бинарными деревьями поиска.
Алгоритм симметричного обхода бинарного дерева поиска посещает узлы в порядке, определённом их поисковыми ключами.
Три варианта:
Узел Nявляется листом
Узел Nимеет только один дочерний узел
Узел Nимеет два дочерних узла
В третьем случае необходимо найти симметричного преемника поискового ключа узла N. Тогда задачу можно свести к первым двум вариантам.
Графы
Множество V вершин и набор R неупорядоченных и упорядоченных пар вершин называется графом; обозначается (V,R).
Неупорядоченная пара вершин называется ребром, упорядоченная дугой. Граф, содержащий только ребра, называется неориентированным, граф, содержащий только дуги, ориентированным. Пара вершин может соединяться двумя или более ребрами (дугами одного направления), такие ребра (дуги) называются кратными. Дуга (или ребро) может начинаться и кончаться в одной вершине, такая дуга (ребро) называется петлей.
Последовательность ребер (u0,u1), (u1,u2),…,(ui-1,ui),…,(ur-1,ur) называется маршрутом, соединяющим вершины u0и ur. Маршрут называется цепью, если все его ребра различны, и простой цепью, если все его вершины различны. Длина маршрута (цепи, простой цепи) равна количеству ребер в порядке их прохождения.
Длина кратчайшей простой цепи, соединяющей вершины uiи ujв графе, называется расстоянием d(ui,uj) между uiи uj. В связном неориентированном граферасстояние удовлетворяет аксиомам метрики.
Маршрут вида (u0,u1), (u1,u2),…,(ui-1,ui),…,(ur-1,u0) называется циклом.
Деревья
Дерево в теории графов – это связный неориентированный граф Г, не содержащий циклов. Дерево с одной выделенной вершиной называется корневым деревом.
В корневых деревьях можно построить иерархию. Поскольку из корня можно попасть в любую вершину графа и маршрут только один, то если вершины А и В лежат на одном пути и А встречается раньше В, А называется предком В, а В потомком А. Не все вершины могут быть связаны отношениями предок-потомок.
Вершина, у которой нет потомков, называется листом.
Поддеревом корневого дерева называется любая вершина со всеми её потомками.
Бинарные деревья
Бинарное дерево – это корневое дерево с множеством вершин V, таких что
множество Vпусто, или множествоVраспадается на три непересекающихся подмножества:
- отдельная вершина r, корень;
- два, возможно пустых поддерева, являющихся бинарными деревьями.
Высота дерева – это количество вершин, расположенных на самом длинном пути от корня к листу.
Обход бинарного дерева
Алгоритм обхода бинарного дерева посещает каждую вершину. При этом над каждой вершиной выполняется какая-либо операция, например, вывод содержания на экран или изменение данных. Для определённости будем считать, что при посещении вершины на экран просто выводятся записанные в неё данные.
Рекурсивный алгоритм выглядит следующим образом.
traverse(BinaryTree binTree)
{
if(деревоbinTreeне пусто)
{
traverse(левое поддерево корня дереваbinTree)
traverse(правое поддерево корня дереваbinTree)
}
}
Здесь не указаны инструкции, выполняющие вывод на экран данных, находящихся в корне. При обходе любого бинарного дерева алгоритм имеет три возможности посещения корня r. Он может посетить корень r перед обходом обоих поддеревьев, после обхода левого поддерева, но перед обходом правого, или после обхода обоих поддеревьев. Такой порядок называется прямым, симметричным и обратным, соответственно.
Балансировка бинарного дерева поиска
Алгоритмы вставки элемента в бинарное
дерево поиска, поиска элемента по ключу,
удаления элемента из бинарного дерева
поиска требуют количества операций
линейно зависящее от высоты дерева
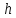 .
.
При вставке элементов в бинарное дерево поиска дерево может иметь как вид а) так и вид б).






а) б)
Очевидно, что в случае а) высота дерева равна числу узлов. Поэтому возникает задача приведения бинарного дерева поиска к виду с высотой как можно меньше.
Введём понятие уровня узла А.
Если узел А является корнем дерева Т, он принадлежит первому уровню.
В противном случае уровень узла на единицу больше чем уровень его предка.
Бинарное дерево Т, имеющее высоту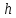 ,
является совершенным, если выполняются
следующие условия:
,
является совершенным, если выполняются
следующие условия:
все узлы, начиная с уровня
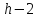 и выше, имеют по два дочерних узла;
и выше, имеют по два дочерних узла;если узел, находящийся на уровне
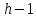 ,
имеет дочерние узлы, то все узлы,
находящиеся на этом же уровне слева от
него, имеют по два дочерних узла;
,
имеет дочерние узлы, то все узлы,
находящиеся на этом же уровне слева от
него, имеют по два дочерних узла;если узел, находящийся на уровне
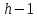 ,
имеет один дочерний узел, то он является
его левым дочерним узлом.
,
имеет один дочерний узел, то он является
его левым дочерним узлом.
При симметричном обходе бинарного дерева поиска узлы посещаются в порядке возрастания ключа.
Если есть достаточное количество памяти, то можно воспользоваться следующим методом приведения бинарного дерева поиска к дереву с минимальной высотой.
Записать все элементы из бинарного дерева поиска в массив при симметричном обходе, при этом массив будет упорядочен по возрастанию ключа.
Удалить исходное дерево.
Создать пустое бинарное дерево поиска.
Вставлять элементы из массива длины
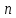 при помощи следующей рекурсивной функции
(псевдокод).
при помощи следующей рекурсивной функции
(псевдокод).
Insert_from_array(BinaryTree *binTree, Type_elem *a, int n)
{
if(n == 0) return;
else{
Insert(binTree, a[n/2]);
Insert_from_array(binTree, a, (n/2));
Insert_from_array(binTree, &a[n/2+1],(n-(n/2)-1));
}
}
Здесь Insert(BinaryTree *binTree, Type_elem a) – функция вставляющая элемент в бинарное дерево поиска.
|
0 |
1 |
2 |
… |
|
… |
|
|
|
|
|
… |
|
… |
|
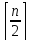
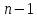
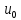
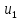
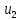
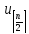

Для действительного числа
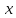 обозначим
обозначим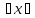 – верхнюю грань, т.е. минимальное число
не меньшее
– верхнюю грань, т.е. минимальное число
не меньшее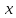 .
Для дерева T обозначим
.
Для дерева T обозначим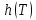 его высоту. Докажем, что построенное
таким образом бинарное дерево, с числом
вершин
его высоту. Докажем, что построенное
таким образом бинарное дерево, с числом
вершин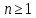 ,
имеет высоту равную
,
имеет высоту равную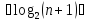 .
.
Доказательство по индукции.
При
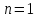 ,
,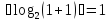 утверждение верно.
утверждение верно.Предположим, что оно верно при всех
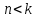 .
.Докажем для
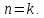 Высота полученного дерева равна
Высота полученного дерева равна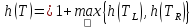 .
Поскольку левое поддерево содержит не
меньше вершин, чем правое, то
.
Поскольку левое поддерево содержит не
меньше вершин, чем правое, то
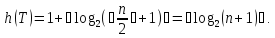
Утверждение доказано.
В случае, когда нет возможности приводить дерево к дереву с минимальной высотой, приводят дерево к виду с высотой близкой к минимальной.
Бинарное дерево поиска называется сбалансированным по высоте, или просто сбалансированным, если высота правого поддерева любого его узла отличается от высоты левого поддерева не больше чем на 1.
Сбалансированное бинарное дерево поиска
с
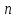 узлами имеет высоту между
узлами имеет высоту между и
и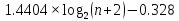 (см.D.Knuth,TheArtofComputerProgramming,v.3).
(см.D.Knuth,TheArtofComputerProgramming,v.3).
Методы балансировки бинарных деревьев, требующие существенно меньших затрат памяти, чем изложенный, не рассматриваются в данном курсе.