

Лекция 5 Направления развития микропроцессоров
5.1. Стратегия развития процессоров Intel
Стратегия развития Intel заключается во внедрении новых микроархитектур процессоров, основанных на новых поколениях полупроводниковой производственной технологии. Темпы выпуска инновационных микроархитектур и полупроводниковых технологий основаны на принципе, который корпорация Intel называет моделью «TICK-TOCK» («ТИК-ТАК»). Каждый «TICK» обозначает (табл. 5.1) новый этап развития полупроводниковых технологий (техпроцесс – 65 нм, 45 нм, 32 нм), а каждый «ТОСК» - создание новой микроархитектуры (Intel Core, Nechalem, Sandy Bridge). Переход на новый техпроцесс сопровождается выпуском соответствующих семейств процессоров (Penryn, Westmere).
Табл. 5.1
|
Intel Core NEW Microarchitecture |
Penryn NEW Process |
Nehalem NEW Microarchitecture |
Westmere NEW Process |
Sandy Bridge NEW Microarchitecture |
Ivy Bridge NEW Process |
|
65 nm |
45 nm |
45 nm |
32 nm |
32 nm |
22 nm |
|
2006 г. |
2007 г. |
2008 г. |
2009 г. |
2010 г. |
2011 г. |
|
TOCK |
TICK |
TOCK |
TICK |
TOCK |
TICK |
Этот цикл, как правило, повторяется каждые 2 года. Новаторская микроархитектура «обкатывается» на текущем производственном процессе, затем переносится на новую производственную технологию. Данная модель развития позволяет осуществлять внедрение единообразной процессорной микроархитектуры во всех сегментах рынка. Стратегия развития архитектуры и полупроводниковой технологии, реализуемая корпорацией Intel, не только позволяет выпускать новые решения в соответствии с запланированными темпами, но и способствует внедрению инновационных решений в отрасли на уровне платформ, расширяя использование преимуществ высокой производительности и энергоэкономичности.
После семейства процессоров Ivy Bridge появится совершенно новая (как утверждают в Intel) процессорная микроархитектура Haswell.
5.2. Особенности микроархитектуры Sandy Bridge
Ключевыми особенностями процессоров архитектуры Sandy Bridge являются:
Усовершенствованное по сравнению с Nehalem вычислительное ядро.
Монолитная конструкция – процессор состоит из одного полупроводникового кристалла, изготовленного по 32 нм технологии техпроцесса.
Новый набор инструкций Intel Advanced Vector Extensions (AVX) для ускорения обработки вещественных чисел.
Оптимизированная технология Intel Turbo Boost.
Заметно увеличившаяся энергоэффективность.
Производительность интегрированного в процессор графического ядра значительно увеличена.
Новая кольцевая шина Ring Interconnect.
Наличие нового функционального узла процессора – системного агента.
Усовершенствованный интегрированный контроллер памяти.
Усовершенствования вычислительного ядра
Наиболее важные изменения в вычислительном ядре процессора с архитектурой Sandy Bridge (рис. 5.1):
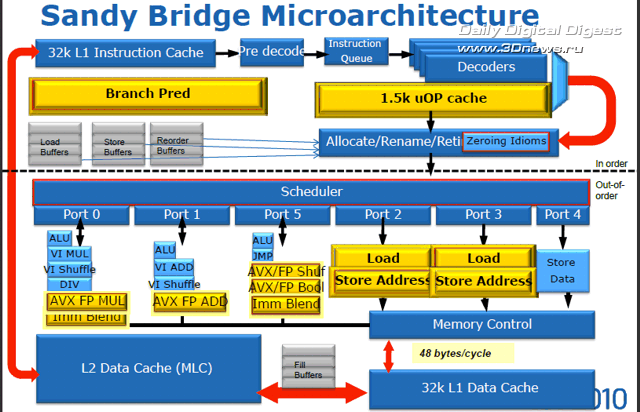
Рис. 5.1. Структура ядра
Возврат к выделению кэш-памяти для примерно 1,5 тысяч декодированных микроопераций L0 (использовался в Pentium 4), являющейся обособленной частью L1, что позволяет одновременно обеспечить более равномерную загрузку конвейеров и снизить энергопотребление вследствие увеличения пауз в работе достаточно сложных схем декодеров операций;
Повышение эффективности блока предсказания ветвлений вследствие увеличения емкости буферов адресов результатов ветвления, истории команд, истории ветвлений, что увеличило эффективность конвейеров;
Увеличение емкости буфера переупорядоченных команд (ROB - ReOrder Buffer) и повышение эффективности этой части процессора благодаря внедрению физического регистрового файла (PRF – Physical Register File, тоже характерной особенности Pentium 4) для хранения данных, а также расширение других буферов;
Удвоение емкости регистров для работы с потоковыми вещественными данными, что в ряде случаев может обеспечить в два раза большую скорость выполнения операций, их использующих;
Увеличение эффективности исполнения инструкций шифрования для алгоритмов AES, RSA и SHA;
Оптимизация работы кэш-памяти первого L1 и второго L2 уровней.
Оптимизация для более эффективной виртуализации и исполнения серверных приложений.
Одним из наиболее важных нововведений микроархитектуры Sandy Bridge является кеш декодированных микроопераций, или кеш инструкций L0. По сути своей кеш декодированных микроопераций напоминает трассировочный кеш микроархитектуры NetBurst (Pentium 4), однако принцип работы у них совершенно разный, сходство заканчивается на том, что оба они работают с микрооперациями.
Благодаря структурной организации формата 32х8 с возможностью хранения шести микроопераций в линии, кеш декодированных микроопераций вмещает чуть более полутора тысяч микроопераций. Без особых затей он кеширует на выходе декодеров все предварительно декодированные микрооперации. Как только поступает на обработку новая инструкция, блок упреждающей выборки первым делом производит сверку с кешем L0, и в случае обнаружения совпадений, загрузка конвейера по четыре микрооперации за такт в обход декодеров осуществляется уже из кеша L0. Незадействованные и простаивающие цепи декодеров, кстати, весьма сложные, и потому достаточно «прожорливые», в этот момент попросту… отключаются от питания. В противном случае, когда кеш декодированных операций оказывается невостребованным, продолжается обычная работа по выборке и декодированию команд, а кеш декодированных операций переводится в режим экономии энергии.
Кеш L0 в какой-то мере можно считать частью кеша L1, в который он, кстати, интегрирован, но отдельной и очень быстрой его частью. По словам представителей Intel, при работе с большинством приложений, вероятность удачного «попадания» в кеш декодированных микроопераций очень велика и может достигать 80%.
Ничуть не меньше изменился блок предсказания ветвлений (branch prediction). В частности, буфер предсказания результата ветвления (branch target buffer, BTB) чипа Sandy Bridge вмещает в два раза больше адресов результатов ветвления и вдвое большую историю комбинаций команд, нежели аналогичный буфер Nehalem. Кроме того, увеличены размеры области хранения истории ветвлений, в том числе предсказанных и выполненных. Так, удалось снизить количество неудачных предсказаний ветвлений, что положительно отозвалось как на увеличении производительности за счёт уменьшения времени вынужденного простоя для сброса конвейера с десятками обработанных впустую инструкций, так и на потреблении энергии, затрачиваемой зря на обработку неудачных ветвлений.
Процессы распределения, переименования, планировки и вывода данных в процессе конвейерного выполнения макроопераций в микроархитектуре Sandy Bridge подверглись самой значительной переработке.
Реализация алгоритма исполнения инструкций с изменением последовательности в предыдущих поколениях процессоров Intel Core, вплоть до Westmere, базировалась на использовании буфера переупорядочивания - ROB (reorder buffer), который в конечном итоге также служит для восстановления последовательности инструкций. По структуре этот буфер представляет собой матрицу с записями всех исполняемых в данный момент инструкций, а также гигантский массив виртуальных данных со значениями регистров и информацией о перемещениях между регистрами.
Теперь, в микроархитектуре Sandy Bridge, результаты отслеживания и переименования микроопераций фиксируются с помощью физического регистрового файла, PRF (physical register file), присущего архитектуре NetBurst (Pentium 4) и также характерного для многих Out-of-Order архитектур вроде AMD Bulldozer/Bobcat, IBM POWER, но отсутствующего в ядрах Nehalem. Фактически, на буфер переупорядочивания в ядре Sandy Bridge возложена только функция «трассировки» инструкций, обрабатываемых в данный момент времени, в то время как функции хранения данных возложены на независимый физический регистровый файл. Иными словами, факт исполнения операции в Out-of-Order структуре Sandy Bridge приводит только к тому, что регистр указывает на иное значение в PRF, а не к переносу 32-, 64-, 128- или 256-битных данных, как в случае, когда используется только буфер переупорядочивания.
Распределение процессов между двумя структурами вместо одной может показаться архитектурным ретроградством, ведущим к усложнению конструкции и дополнительному увеличению количества транзисторов, то есть, к росту энергопотребления чипа. Тем не менее в конечном итоге такое разделение функций значительно разгружает буфер переупорядочивания, постоянно перегруженный в чипах Nehalem и от того постоянно «горячий».
Кроме появления в архитектуре Sandy Bridge физического регистрового файла, изменились и характеристики традиционных модулей кластера Out-of-Order процессов. Так, буфер переупорядочивания способен обрабатывать до 168 микроопераций одновременно. Целочисленный физический регистровый файл Sandy Bridge хранит 160 отдельных 64-битных записей; физический регистровый файл для векторно-вещественных данных с плавающей запятой хранит 144 256-битных записей, то есть регистры YMM с новыми векторными x86-64 командами AVX целиком.
В микроархитектуре Sandy Bridge вводятся новые векторные инструкции AVX.
Сами по себе инструкции AVX – это дальнейшее развитие SSE, расширяющие разрядность типовых векторных SIMD операций на 256-битные операнды. Размер векторных регистров SIMD увеличивается с 128 (XMM) до 256 бит (регистры YMM0 – YMM15). Кроме того, новый набор позволяет проводить операции в недеструктивной форме, то есть без потери исходных данных в регистрах. Благодаря этим свойствам набор инструкций AVX наравне с микроархитектурными улучшениями также можно отнести к нововведениям, направленным на повышение производительности и на экономию энергии, так как их внедрение позволит упростить многие алгоритмы и совершать большее количество работы с использованием меньшего числа команд. Инструкции AVX хорошо подходят для интенсивных вычислений с плавающей точкой в мультимедиа, научных и финансовых задачах.
Для эффективного исполнения 256-битных инструкций исполнительные устройства процессора были подвергнуты специальному редизайну. Суть изменений сводится к тому, что для работы с 256-битными данными 128-битные исполнительные устройства объединяются попарно. А учитывая то, что каждый из трёх исполнительных портов Sandy Bridge (как и Nehalem) имеет устройства для работы одновременно с тремя видами данных – 64-битными, 128-битными целыми или 128-битными вещественными – попарное объединение SIMD устройств в рамках одного порта выглядит вполне естественным и разумным решением. И, что немаловажно, такое перераспределение ресурсов не наносит ущерба общей пропускной способности исполнительного блока процессора.
Как и раньше, в чипах Nehalem, загрузка микроопераций всех типов: SIMD, целочисленных и с плавающей запятой, происходит по одинаковому сценарию, единым унифицированным планировщиком, динамически распределённым между всеми потоками. Разница в том, что в архитектуре Sandy Bridge планировщик более ёмкий и загружается сразу 54 переименованными и готовыми к исполнению микрокомандами.
Благодаря существенной доработке, нацеленной на удвоение производительности при работе с 256-битными векторными инструкциями AVX и возможности исполнения большинства из них как единой микрооперации, исполнительные блоки микроархитектуры Sandy Bridge стали вдвое мощнее, чем у чипов Nehalem. Теперь они способны обрабатывать восемь операций двойной точности с плавающей запятой (FP) или 16 FP-операций одинарной точности за такт. Таким образом, ядро Sandy Bridge способно исполнять за каждый такт 256-битное FP-умножение, 256-битное FP-сложение и 256-битное смещение.
Несмотря на увеличение разрядности исполнительных блоков ядра до 256 бит, увеличения ширины шины данных до 256 бит не произошло. Для исполнения 256-битных микроопераций в ядре Sandy Bridge объединяются возможности имеющихся в наличии 128-битных трактов для работы с данными SIMD INT и SIMD FP.
Также стоит упомянуть, что в ядре Sandy Bridge повышена производительность при обработке инструкций стандарта шифрования AES и RSA, а также производительность при вычислении хешей SHA-1.
Необходимость работы с вдвое увеличенными (до 256 бит) операндами SSE FP не могла не сказаться на нагрузке подсистемы памяти ядра Sandy Bridge, которая должна обслуживать не менее двух запросов за такт, гарантированно обеспечивая возможность 16-байт записи и 16-байт чтения.
Вот почему в структуре 8-банкового кеша данных L1 ядра Sandy Bridge был добавлен второй 16-битный порт чтения, благодаря которому суммарная пропускная способность кеша выросла до 48 байт за такт: два 16-байт запроса чтения и 16-байт запись. Размеры буферов записи и чтения, разделённых между исполнительными блоками ядра Sandy Bridge, были также увеличены: буфер записи - до 64 ячеек, буфер чтения - до 36 ячеек.
8-банковый ассоциативный кеш L2 микроархитектуры Sandy Bridge, распределённый по 256 Кбайт на каждое ядро, достаточно схож с тем, что применялось в предыдущих поколениях процессоров Intel. Здесь изменения минимальны.