

Тема 5
.doc
Тема
5. Основные методы моделирования
статистических
связей между
признаками
-
Методы статистических группировок и дисперсионного анализа
2. Методы корреляционного анализа
3. Основные характеристики однофакторных уравнений регрессии
4. Основные характеристики многофакторных уравнений регрессии
-1-
В функциональных зависимостях изменению фактора соответствует определенное изменение результативного признака. Функциональные зависимости записываются в виде факторных моделей (аддитивных, мультипликативных, кратных).
В отличии от функциональных связей вероятностные (стохастические, статистические) предусматривают наличие такой статистической взаимозависимости, при которой одному и тому же изменению фактора могут соответствовать различные значения результативного признака (чем больше урожайность сельскохозяйственных культур, продуктивность животных, тем меньше себестоимость продукции). Размер этой величины определить только по изменению фактора невозможно, так как она зависит от множества случайных (вероятностных) факторов (причин). Поэтому статистические связи описываются усредненной моделью для некоторой совокупности объектов. (Для другой совокупности усредненная статистическая взаимосвязь может быть иной).
Для изучения статистической взаимосвязи необходимо иметь целую совокупность наблюдений, которые позволяют усреднить размеры влияния одного признака на другой. Чем больше количество наблюдений, тем с большей точностью можно оценить взаимосвязь признаков.
В экономических исследованиях используются вероятностные связи, для оценки которых применяются 2 группы показателей:
-
Дискретные переменные дают качественную характеристику объектов наблюдения. Их трудно выразить количественно, т.к. они имеют определенные значения (специализация предприятия, форма собственности).
-
Непрерывные переменные отражают количественную сторону явлений и процессов, имеют определенные единицы измерения и могут принимать различные значения.
В статистических моделях возникает необходимость определить взаимосвязь между самими переменными. Основной метод оценки взаимосвязи - метод статистических группировок. Он предусматривает расчленение совокупности наблюдений на отдельные группы. В качестве группировочного признака выступают факторы (причины) и такие группировки называются факториальными. Результативный признак отражает следствие влияния фактора. Главная задача состоит в выяснении направления и величины изменения результативного показателя с изменением фактора. Виды группировок зависят от признаков, участвующих в исследованиях.
-
Для оценки взаимосвязей между (качественными) дискретными переменными используются таблицы сопряженности. Они предусматривают построение сложных комбинационных группировок, где каждому признаку соответствует количественная характеристика, означающая частоту проявления данного признака. Она может быть в абсолютных величинах (сколько раз) и относительных (удельный вес).
Например, группировка звеньев по специализации и форме организации и оплаты труда.
|
Специализация |
Форма организации и оплаты труда |
||
|
Коллективный подряд |
Арендный подряд |
Аренда |
|
|
1.Специализированные звенья |
|
|
|
|
2.Отраслевые звенья |
|
|
|
|
3.Комплексные звенья |
|
|
|
![]() -количественная
характеристика - количество звеньев с
i специализацией при j
форме организации и оплаты труда.
-количественная
характеристика - количество звеньев с
i специализацией при j
форме организации и оплаты труда.
Для оценки связей используются различные
критерии, позволяющие оценить достоверность
разностей между отдельными наблюдениями.
Наиболее часто используется критерий
согласия
![]() (Пирсона).
Чем меньше значение критерия, тем
меньше отклонение между эмпирическими
и теоретическими частотами, т. е.
теоретическое распределение лучше
воспроизводит эмпирическое, при этом
фактическое значение критерия
(Пирсона).
Чем меньше значение критерия, тем
меньше отклонение между эмпирическими
и теоретическими частотами, т. е.
теоретическое распределение лучше
воспроизводит эмпирическое, при этом
фактическое значение критерия
![]() должно
быть меньше табличного.
должно
быть меньше табличного.
-
Для оценки связей между дискретными и непрерывными переменными (качественными и количественными) используются типологические группировки, в которых группировочным признаком является дискретная переменная.
Например, группировка звеньев по специализации и площади посевных площадей.
-
Для оценки взаимосвязей между непрерывными (количественными) признаками используются аналитические группировки.
Например, группировка почв по плодородию.
|
Балл бонитета |
Количество объектов |
Средняя урожайность ц/га |
Среднеквадратическое отклонение урожайности |
Коэффициент вариации, % |
|
До 50 |
2 |
10 |
2 |
20 |
|
50-70 |
10 |
11 |
5 |
45,4 |
|
Свыше 70 |
— |
— |
— |
— |
Для оценки качества группировок используются различные критерии.
Распределение объектов по отдельным группам должно подчинятся закону нормального распределения. Это характеризует коэффициент нормальности распределения отклонений. Чем он ближе к 1 , тем ближе распределение к нормальному. В этом случае можно пользоваться более точно корреляциоными и дисперсионными приемами анализа. Если распределение объектов по группам значительно отличается от нормального закона или имеются группы с нулевым количеством объектов, то необходимо определить другой интервал изменения группировочного признака или изменить количество групп в группировке.
Наблюдения в группировке должны быть качественно и количественно однородными.
Качественная однородность определяется выбором объектов одной природно-климатической зоны, с одинаковыми почвами и так далее.
Количественная однородность определяется коэффициентом вариации.
![]()
G-среднеквадратическое отклонение фактора
X-среднее значение фактора
Если коэффициент вариации меньше или равен 33%, то группа количественно однородна. Если коэффициент больше 33% - группа неоднородна, ее необходимо разбить на отдельные группы.
Метод статистических группировок не позволяет количественно оценить степень связи между результатом и факторами, что часто приводит к субъективным выводам. Окончательная оценка группировки проводится на основе дисперсионного анализа, позволяющего оценить достоверность группировки.
Модель дисперсионного анализа
![]()
![]() -изменение
(дисперсия) результативного признака
-изменение
(дисперсия) результативного признака
![]() -межгрупповая
дисперсия, которая характеризует
вариацию результативного признака,
обусловленную группировочным фактором
-межгрупповая
дисперсия, которая характеризует
вариацию результативного признака,
обусловленную группировочным фактором
![]() -изменение
результативного признака под действием
случайных, неучтенных факторов (остаточная
дисперсия)
-изменение
результативного признака под действием
случайных, неучтенных факторов (остаточная
дисперсия)
Дисперсионный анализ основан на способе цепных постановок.
Для двухфакторной модели
![]()
![]() -неразложенный
остаток, изменение результата под
совместным влиянием
-неразложенный
остаток, изменение результата под
совместным влиянием
![]() и
и
![]()
На основе разложения общей дисперсии на факториальную и остаточную рассчитывается критерий Фишера
![]()
F-критерий позволяет судить о достоверности и существенности связи между признаками, при этом расчетное значение сравнивается с табличным. Если Fрасч.> Fтабл., то с определенным уровнем вероятности можно утверждать о статистически достоверной связи между признаками.
Соотношение
![]() - называется корреляционным отношением.
Оно показывает долю вариации результативного
признака под влиянием фактора в общей
вариации.
- называется корреляционным отношением.
Оно показывает долю вариации результативного
признака под влиянием фактора в общей
вариации.
-2-
Для количественной оценки взаимосвязи между признаками используется коэффициент корреляции, изменяется от –1 до 1 и характеризует тесноту связи между признаками.
Коэффициент корреляции позволяет оценивать линейные связи между признаками, но линейных связей в природе практически не существует. Для нелинейных связей рассчитывается корреляционное отношение. При значительном отличии коэффициента корреляции и корреляционного отношения можно утверждать о наличии нелинейной связи между признаками.
Корреляционное отношение в отличии от коэффициента корреляции можно использовать как для линейных, так и нелинейных связей. Корреляционное отношение учитывает причинно-следственные связи между признаками.
Если
![]() , то
, то
![]()
![]()
Квадрат коэффициента корреляции называется детерминацией для линейной зависимости, которая характеризует процент изменения результата под действием фактора.
На основе расчетов коэффициентов корреляции в экономических исследованиях часто пользуются методами многомерного статистического анализа (метод главных компонент, метод главных факторов). Они позволяют построить комплексные оценки признаков, между которыми существует тесная взаимосвязь. Все признаки на основе коэффициентов корреляции распределяются на отдельные группы, которые могут быть количественно выражены.
Например,
![]()
![]() -
фактор, объединяющий несколько признаков
в одну группу
-
фактор, объединяющий несколько признаков
в одну группу
![]() -
факторные нагрузки показателей
-
факторные нагрузки показателей
![]() -показатели
-показатели
Аналогично строятся
![]() и
так далее
и
так далее
По каждому фактору строится корреляционная решетка и по коэффициентам корреляции факторов их сводят в одну группу. Вместо множества факторов используется несколько их групп, т.е. рассчитывается комплексный показатель.
-3-
Уравнения регрессии - это уравнение линии. Линии могут быть прямые и "кривые". Для оценки взаимосвязей между признаками широко используются методы регрессионного анализа, позволяющие описать зависимость между результатом и признаком в виде уравнения (модели) Y = f(x) + E.
E - случайная величина, характеризующая ошибку описания взаимосвязи между результатом "y" и признаком "x".
Источники этой ошибки:
-
Определяются составом модели, т.е. на изменения результата оказывают факторы (причины), не включенные в модель. Часто их учесть невозможно.
-
Она (ошибка) зависит от аналитического вида модели, т.е. формы зависимости. Чем хуже данная модель отображает связь между признаками, тем больше величина Е.
-
Определяется ошибкой выборки (ошибки измерений, ошибки расчетов и т.п.). Она связана с ограниченностью количества наблюдений (ошибка репрезентативности).
Моделирование статистических связей между признаками предусматривает определение такого аналитического вида управления, при котором величина ошибки стремится к нулю. Чем меньше значение ошибки Е, тем точнее модель. Из этого положения следуют критерии выбора формы зависимости.
Существует 3 способа описания статистических зависимостей: табличный, графический, в виде аналитических функций.
В экономике используется большое количество разнообразных форм зависимости.
Линейная зависимость y = a + bx, где "a" и "b" - коэффициенты регрессии. Они отражают средние зональные нормативы эффективности использования производственных ресурсов. В каждом отдельном предприятии они характеризуют субъективный уровень интенсивности (эффективности) производства. В однофакторных моделях свободный член "а" означает начальный уровень результативного признака, не зависящий от размеров факторов. Коэффициент регрессии "b" означает на сколько изменится результативный показатель при изменении фактора на 1. Необходимо учитывать экономический смысл фактора. Если знак коэффициента регрессии не соответствует экономическому смыслу, то или коэффициент не достоверен или данный фактор используется очень неэффективно. Необходимо увеличить количество наблюдений или исключить объекты, выпадающие из общего направления.
Показательные функции y = abx; y = a/bx .
Для нахождения коэффициентов регрессии "a" и "b" от нелинейных зависимостей переходят к линейным. Лучше это сделать логарифмированием обеих частей уравнений. Y = abx ; lgy = lga + хlgb. Заменим lgy = Y, ; lga = A; lgb = B тогда получим Y = A + BX. В дальнейшем получили уравнение прямой линии.
Многочлен 2-го порядка (парабола) - y = a + bx + cx2
Многочлен 3-го порядка (парабола) – y = a + bx + cx2 + dx3
Экспонента - y = aеx
Модифицированная экспонента - y = k + aеx
где k - асимптота, предельно допустимое значение результативного признака, значение, к которому стремится результативный показатель.
Логистическая кривая - y=k/(1+ax-b) . Они описывают, как правило, процессы с насыщением, накоплением результатов производства.
Кривая Гомперца - y = k a b x представляет ассиметрично S - образную кривую. Используется при описании процессов в страховании, налогообложении (Y=ka=k^a).
Кривые с асимптотами, логистическая и кривая Гомперца, приводятся посредствам логарифмирования к уравнениям линейной зависимости.
Тригонометрические функции используются при описании довольно длительного периода, который можно принять за цикл изменения результативного показателя.
Имея большое количество наблюдений по значениям фактора и соответствующим значениям результативного показателя, необходимо выбрать для описания такую форму зависимости, которая бы лучше всего отражала фактическую зависимость. Для этого по принятым формам рассчитываются коэффициенты регрессии и для каждого значения фактора рассчитывается теоретическое значение результативного показателя.
Выбор функции осуществляется по следующим показателям:
-
средний коэффициент аппроксимации
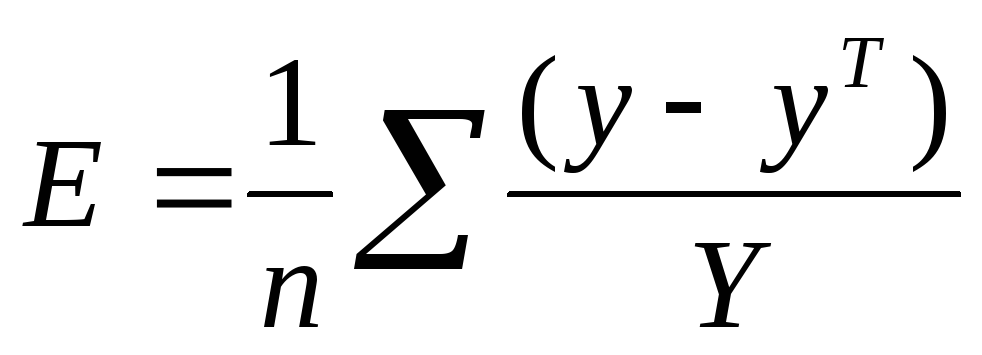 .
Он показывает на сколько отклоняются
фактические значения результативного
показателя (у) от теоретического (yT).
Чем он меньше, тем предпочтительнее
форма зависимости.
.
Он показывает на сколько отклоняются
фактические значения результативного
показателя (у) от теоретического (yT).
Чем он меньше, тем предпочтительнее
форма зависимости.
n –количество наблюдений.
-
корреляционное отношение (коэффициент корреляции) характеризует тесноту связи и позволяет определить на сколько % изменяется результат под действием факторов. Чем оно больше, тем теснее зависимость. Оно изменяется от 0 до 1.
-
среднеквадратическое отклонение остатков характеризует отклонение расчетных значений от фактических по каждому наблюдению. Чем оно меньше, тем ближе данная форма зависимости к фактической, тем обоснованнее предположение о случайности распределения остатков. Среднеквадратическое отклонение остатков определяется:
![]() ,
,
где У, УТ – соответственно фактическое и расчетное значения результативного показателя;
n – количество наблюдений.
-
нормальность распределения отклонений. Отклонения теоретических значений от фактических должны подчиняться нормальному закону распределения. Приближенное представление о нормальности остатков можно судить, вычислив величину.
![]()
Если S* близка к S (среднеквадратическому отклонению остатков), то распределение остатков можно считать нормальным.
Чем ближе этот показатель к 1, тем ближе распределение остатков к нормальному закону, тем точнее принятая форма зависимости описывает фактическую.
-
средняя и предельная ошибки прогноза не должны превышать 1/3 прогноза. Чем меньше ошибка, тем точнее принятая форма зависимости.
-
Зависимость одного уровня динамического ряда от другого называется автокорреляцией. Наличие автокорреляции может быть оценено с помощью коэффициента автокорреляции. Расчетное значение по абсолютной величине должно быть меньше табличного. Чем оно меньше, тем лучше. Коэффициентом автокорреляции Ra:
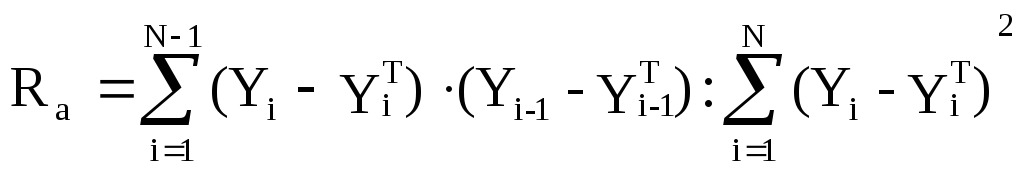 ,
,
где Yi-YiT – отклонение теоретического значения результативного признака от его фактического значения;
Yi-1-Yi-1T – отклонение теоретического от фактического значений результативного показателя следующего уровня.
Если Ra меньше табличного по абсолютной величине, то в остаточном ряду существенной автокорреляции не обнаружено.
-
Т-критерий достоверности Стьюдента. Он позволяет оценить статистическую значимость коэффициентов. Например, отношение коэффициента корреляции к его ошибке:
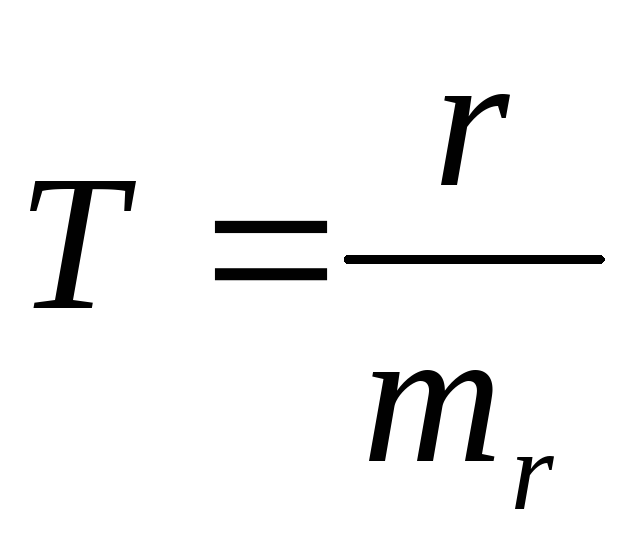 ;
;
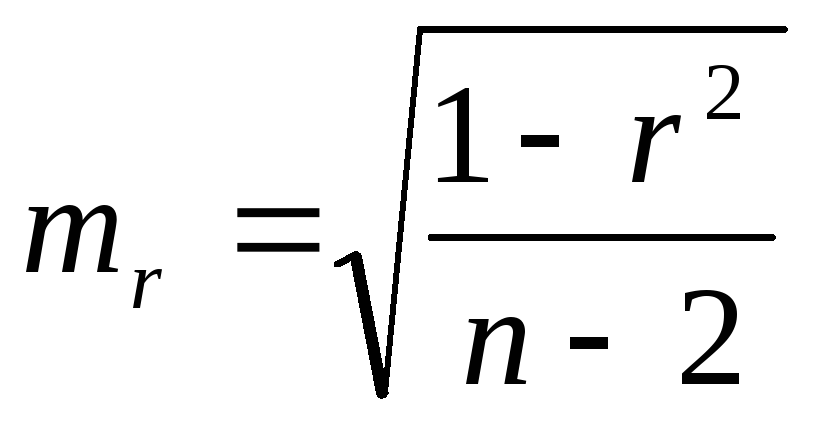 ;
где
;
где
n – количество наблюдений;
2- число степеней свободы.
Если Трасч.Ттабл., то с принятой степенью вероятности, например 0.95, можно утверждать о достоверном влиянии фактора на результат не только в данной выборке, но и в генеральной совокупности. В противном случае данной формой зависимости можно пользоваться только для описания зависимости в принятой выборке.
-
F - критерий Фишера - отношение дисперсий факториальной к остаточной. Позволяет оценить статистическую значимость уравнения регрессии.Если расчетные значения критерия больше табличного, то с принятым уровнем вероятности можно утверждать о существенном влиянии фактора (факторов) на результат не только в выборке, но и в генеральной совокупности объектов.
-
Проверку на нормальность распределения из множества методов, наиболее простым является вычисление отношения R/S, где R=Ymax-Ymin – размах вариаций зависимой переменной; S – стандартное отклонение
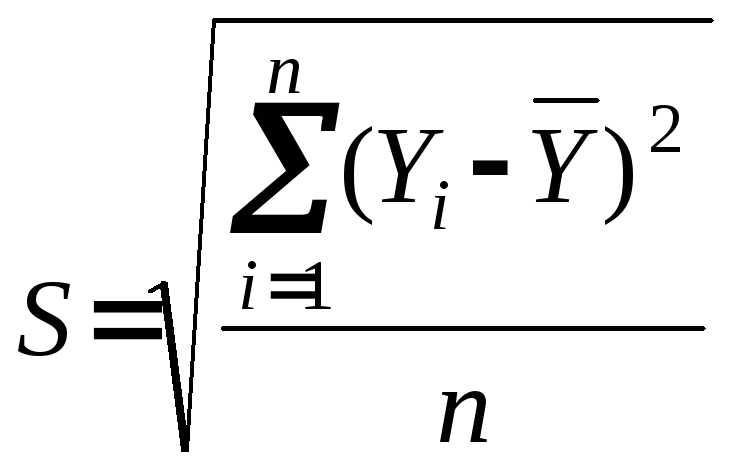 .
Отношение R/S
сравнивают с критическим по верхней и
нижним границам. Если R/S
больше нижней границы, но меньше верхней,
то нормальность распределения
выполняется.
.
Отношение R/S
сравнивают с критическим по верхней и
нижним границам. Если R/S
больше нижней границы, но меньше верхней,
то нормальность распределения
выполняется. -
Процедура выбора кривой, адекватной процессу заканчивается вычислением дисперсии отклонений фактических значений от расчетных:
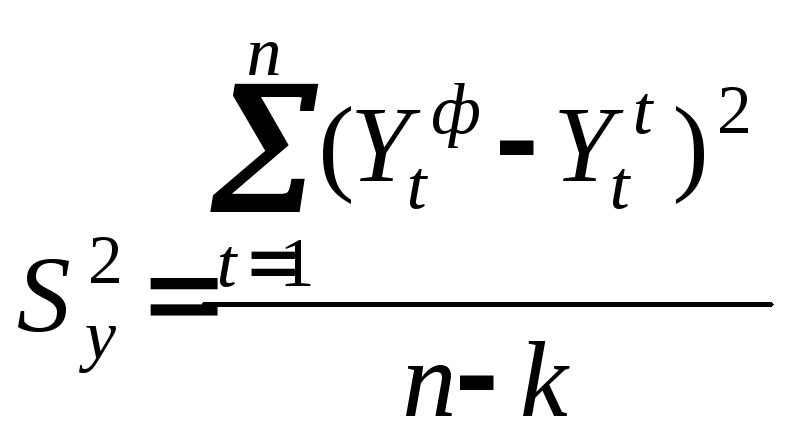 ,
где
,
где
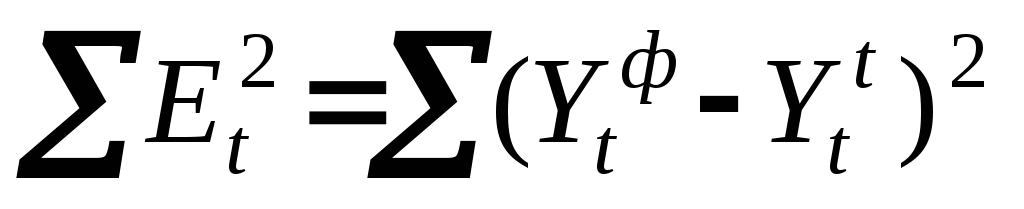 -
сумма квадратов отклонений фактических
и теоретических значений Yt;
-
сумма квадратов отклонений фактических
и теоретических значений Yt;
n- число уровней ряда;
k- количество параметров модели.
В качестве аппроксимирующей выбирается кривая, дисперсия которой имеет минимальное значение.
Используя комплекс показателей статистических характеристик, выбирают из всех возможных ту форму зависимости, которая ближе всех к фактической зависимости. Используя аналитические уравнения и коэффициенты регрессии, записывают уравнения регрессии.
-4-
В экономике сельского хозяйства результаты производства зависят от множества факторов. Поэтому использование однофакторных регрессионных моделей правомерно в тех случаях, когда результативный показатель и фактор являются сложными. Наиболее эффективно использовать многофакторные экономико-статистические модели вида:
Y = f(Xi) + E, где Xi - значение i-го фактора, Е - ошибка.
При составлении многофакторных моделей предусматривается решение двух основных вопросов:
1. Обоснование состава моделей (выбор количества и состава факторов);
2. Обоснование аналитического вида зависимости.
При обосновании состава модели все факторы можно условно подразделить на 3 группы:
-
Объективные, характеризующие нормообразующие условия производства (качество почвы, наличие средств производства, трудовых ресурсов и т.п.).
-
Субъективные, характеризующие уровень организации использования производственных ресурсов. Они зависят от квалификации, уменья, знаний специалистов, работников предприятия. Такие факторы, как правило, не включаются в модель.
-
Ошибка модели, предусматривающие влияние случайных факторов, выбранного аналитического вида функции и ошибки выборки. Данные факторы в модель не включаются, но при моделировании стремятся определить такой набор факторов, которые объясняли бы 70 – 80 % вариации результативного признака (т.е. коэффициент множественной детерминации R2 = 0,7-0,8). 30-20% изменения результата остается на влияние не включенных в модель факторов.
При обосновании состава модели главное внимание уделяется причинно-следственным связям.
В качестве факторов используются причины, в качестве результативного показателя их влияние, следствие. Причинно-следственную связь можно представить в виде цепочки моделей. Например, урожайность производительность труда себестоимость прибыль. Случайные факторы исключить из модели невозможно. Их влияние уменьшается в процессе моделирования.
Каждый фактор должен быть обоснован теоретически. Включаются только те факторы, которые оказывают существенное влияние на результативный признак. Количество факторов не должно превышать одной трети количества наблюдений. Факторы не должны быть линейно зависимы т.е. мультиколинеарны. В модель рекомендуется включать те факторы, которые можно измерить численно. Нельзя включать в одну модель совокупный фактор и образующие его частные факторы. Для выявления мультиколлинеарных (взаимозависимых) факторов, входящих в многофакторную регрессионную модель, используются парные коэффициенты корреляции. Они характеризуют тесноту связи между всеми парами факторов. Если коэффициент корреляции rx1x2 между факторами Х1 и Х2 по абсолютной величине больше каждого из коэффициентов корреляции между факторами и результатом rx1y и rx2y , то факторы Х1 и Х2 взаимозависимы (мультиколлинеарны). Они искажают общее влияние всех факторов, входящих в модель, на изменение результата. Для устранения данного явления необходимо один из факторов исключить из модели и прорешать задачу заново.
Отбор влияющих на результативный признак факторов проводится с использованием статистических методов. Наибольшее распространение получил метод пошаговых процедур отбора переменных. Метод исключения предполагает сначала включать в аппроксирующее уравнение все факторы и последовательно их исключать в зависимости от получаемых характеристик. Можно использовать метод последовательного включения переменных в модель до тех пор, пока регрессионная модель на будет отвечать заранее установленному критерию качества. Для этого используются значения частных парных коэффициентов корреляции.
После того как сформулированы результат и факторы проводят характеристику распределения переменных. С этой целью расчитывают среднее значение, среднеквадратическое отклонение и коэффициент вариации, по которым можно судить об однородности выборки. Среднеарифметическое значение переменных позволяет оценить уровень этих изменений в сравнении с показателями каждого объекта и со среднеобластным значением. Среднеквадратические отклонения позволяют оценить степень вариации показателя по хозяйствам района от средней величины. Коэффициент вариации, рассчитываемый как отношение среднеквадратического отклонения к среднему значению фактора, выраженный в процентах, позволяет судить об однородности выборки. Для нормального распределения коэффициент вариации равен примерно 33 %. Если он меньше 33 %, то хозяйства по уровню обеспеченности данным ресурсом не существенно различаются между собой, т.е. они количественно однородны. Если коэффициент вариации больше 70 - 80 %, то различия хозяйств по данному признаку существенны. Они количественно не однородны. Это, как правило, является признаком качественной неоднородности, т.е. в совокупности хозяйств имеет одно или несколько хозяйств резко отличающихся от всех других хозяйств по данному признаку. В этом случае из выборки необходимо исключить резко отличающиеся объекты или исключить данный фактор из модели.