

Уханов - лекции
.pdfТипы структур данных
Любой набор знаков, рассматриваемый безотносительно к его содержательному смыслу, называют данными. Данные обычно изображают некоторую информацию, которую можно получить, если известен смысл, приписываемый данным. Однако в программировании, особенно в системном, часто приходится иметь дело именно с данными. Например, разрабатывая систему хранения и поиска некоторых текстов, программист может не знать их содержания. Его задача - обеспечить экономное использование памяти и быстрый поиск требуемых текстов по заданным признакам. Для решения этой задачи достаточно знать лишь количественные характеристики текстов, рассматриваемых как данные. Вообще вычислительные машины выполняют только обработку данных, которая заинтересованным лицам, приписывающим этим данным некоторый смысл, представляется обработкой информации.
Совокупности данных, организованные некоторым образом, называют структурами данных. Структура определяется отношениями между ее элементами. В рамках данного курса будем изучать структуры данных: стек, очередь, массивы, списки, деревья и таблицы.
Стек
Стек (магазин) – это одномерный, динамически изменяемый линейный набор данных. Новый элемент всегда добавляют к одному и тому же концу набора и как правило доступен только самый последний элемент. Удаление элементов производится с того же конца, с которого происходит добавление. Этот принцип называется LIFO (Last In First Out) – “последний пришел, первый ушел”. Стек называют также магазином по аналогии с магазином огнестрельного оружия, в котором патрон, вставленный последним, выходит первым. Конец стека, с которого добавляются и удаляются элементы, называют вершиной стека. На рисунке стек можно изобразить следующим образом.
top
Простым примером использования стека может служить ситуация, когда мы просматриваем множество данных и составляем список особых данных, которые должны обрабатываться позднее. Когда первоначальное множество обработано, возвращаемся к этому списку и выполняем последующую обработку, удаляя элементы из списка, пока список не станет пустым.
Простейший способ работы со стеком – представление его в виде массива.
#define MAXSTACK 20 |
//объявляем максимальную величину стека |
... stack [MAXSTACK]; |
//объявляем сам стек в виде массива нужного типа |
int V; |
//указатель на вершину стека |
Когда V = -1 – это признак пустоты стека. Рассмотрим операции над стеком: Поместить в стек.
V++;
if (V >= MAXSTACK) переполнение(); stack [V] = новые данные;
Взять из стека.
if (V < 0) пусто(); данные = stack [V--];
переполнение() и пусто() – некоторые функции, обрабатывающие соответствующие ситуации.
Организация рекурсий
Если функция А(а1, а2, ..., аn) обращается сама к себе с аргументами A(b1, b2, ..., bn), то такая операция называется рекурсией. При этом аргументы а1, а2, ..., аn опускаются в стек.
Рекурсией называют способ описания функций или процессов через самих себя. Повидимому, наиболее известным примером рекурсивно описанной функции является факториальная функция от положительного целого аргумента. Другим примером рекурсивной функции может служить рекуррентное соотношение между функциями Бесселя различных порядков. Еще одна возможная форма рекурсии встречается тогда, когда процесс описывается через подпроцессы, один из которых идентичен основному. Например, двойной интеграл. Один из методов вычисления двойного интеграла состоит в двукратном простом интегрировании.
Это типичный пример рекурсивного использования процедуры. Следует отличать такую рекурсию от другого типа рекурсии, при котором функция присутствует в правой части своего описания. В случае двойного интеграла вычисление внешнего интеграла требует вычисления другого интеграла, а внутренний интеграл вычисляется непосредственно. Принято говорить в таких случаях, что рекурсия имеет глубину равную единице; это означает: процесс обращается к себе как к подпроцессу только один раз. При вычислении функции factorial (3) в соответствии с рекурсивным описанием нужно вычислить factorial (2), factorial (1) и factorial (0); в этом случае глубина рекурсии равна трем.
Для факториала глубина рекурсии видна сразу. Однако это исключение, а обычно глубина рекурсии не является очевидной даже при простейших описаниях.
Например, рассмотрим алгоритм Эвклида для вычисления наибольшего общего делителя (НОД) двух положительных целых чисел. Этот алгоритм может быть описан следующим образом. Даны два положительных числа m и n. Требуется найти их наибольший общий делитель, т.е. наибольшее положительное целое число, которое нацело делит как m, так и n.
Шаг 1. Разделим m на n. Пусть остаток от деления равен r. Шаг 2. Если r = 0, то НОД найден; n – искомое число. Шаг 3. Присвоим m значение n, а n – r и вернемся к шагу 1.
В общем случае можно утверждать, что рекурсивное использование процедуры требует очевидной конечной глубины рекурсии, а вычисление рекурсивно описанной функции приводит к неопределенной глубине рекурсии, зависящей от значений аргументов. Оба типа рекурсии могут присутствовать одновременно.
Существует еще одна ситуация, в которой применять рекурсивные методы выгодно; она возникает при обработке данных, имеющих рекурсивную структуру. Такой структурой является, например, дерево.
Рассмотрим теперь способ организации рекурсии на базе стека. Такая система включает стек и две подпрограммы, которые будем называть ОБРАЩЕНИЕ и ВОЗВРАТ. Подпрограмма ОБРАЩЕНИЕ имеет три параметра:
а) адрес подпрограммы, в которую нужно войти; б) адрес первой ячейки подлежащего запоминанию участка рабочего поля; в) число ячеек, подлежащих запоминанию.
Работа подпрограммы ОБРАЩЕНИЕ состоит в том, чтобы запомнить в стеке адрес возврата и указанные ячейки памяти, а затем обычным образом передать управление на ту подпрограмму, к которой требуется обратиться.
Подпрограмма ВОЗВРАТ имеет два аргумента:
а) адрес первой из подлежащих восстановлению ячеек рабочего поля;

б) число ячеек, подлежащих восстановлению.
Подпрограмма ВОЗВРАТ восстанавливает по содержимому стека состояние указанных ячеек, а затем передает управление по адресу возврата, который хранится в стеке.
Различие между рекурсивным языком и нерекурсивным языком состоит в том, что на языке, не поддерживающим механизм рекурсии программист, желающий ею воспользоваться, должен сам организовать стек и включить в текст программы фрагменты, соответствующие подпрограмма ОБРАЩЕНИЕ и ВОЗВРАТ, тогда как на рекурсивном языке это обеспечивается системой, так сказать, “за кулисами”. Во многих рекурсивных системах за это приходится платить тем, что автоматический аппарат, предусмотренный для обеспечения рекурсии, вступает в действие даже тогда, когда программа не является рекурсивной; это приводит к напрасным затратам машинного времени.
Рассмотрим использование стека для организации рекурсий на примере. Пример:
Требуется обойти шахматную доску шагом коня, побывав в каждой клетке только один раз. Сначала напишем функцию хода конем из заданной клетки.
Всевозможные хода из заданной клетки следующие.
7 0
6 1
*
5 2
4 3
#define N 8
int hod (int x1, int y1, int nomhod, int *x2, int *y2) { //x1, y1 – координаты текущей клетки
//nomhod – номер хода
//x2, y2 – новые координаты
//функция возвращает 1, если ход допустим; 0, если выход за пределы доски switch (nomhod) {
case 0:
*x2 = x1 + 1;
*y2 = y1 + 2; break;
case 1:
...
default: сообщение о недопустимости хода;
}
return (*x2 < N && *x2 >= 0 && *y2 < N && *y2 >= 0);
}
В стеке будем держать координаты клетки и номер хода, с помощью которого покинули клетку. Тогда для задания элемента стека удобно воспользоваться структурой.
typedef struct { |
|
int x,y; |
//координаты клетки, начальная координата (0, 0) |
int hod; |
//номер хода |
} MOVE;
Обход заключается в следующем. Будем делать случайный ход (от 1 до 8). Если ход допустим, то поместим в стек координаты и номер хода, которым мы покидаем клетку. Если ни один ход из 8 не является допустимым, следовательно нужно изменить предыдущий ход. Тогда достаем из стека координаты и номер предыдущего хода и делаем другой ход. Если это невозможно, то меняем еще один предыдущий ход и т.д.
Функция horse будет получать результат обхода в стеке stack. Функция вернет 1, если обход доски завершен успешно, и 0, если обход невозможен.
int horse (MOVE *stack) { |
|
|
int V = -1; |
//указатель на вершину стека, сначала он пуст |
|
int x1, y1; |
//координаты текущей клетки, сначала они нулевые |
|
int x2, y2; |
//новые координаты |
|
int nomhod, nom; |
//номер хода |
|
int doska [N][N]; |
//массив игровой доски, если doska [i][j] = 1, то клетка занята ходом |
|
int good; |
//флаг, сообщающий, найден допустимый ход (1) или нет (0) |
|
x1 = y1 = 0; |
|
|
nomhod = 0; |
//ход, с которого начинается перебор |
|
memset (doska, 0, N*N*sizeof(int)); |
//заполнение массива нулями |
|
for (;;) { |
|
|
good = 0;
for (nom = nomhod; nom < N; nom ++) {
if (hod(x1, y1, nom, &x2, &y2) && !doska[x2][y2]) {
good = 1; |
//допустимый ход найден, его номер nom |
break; |
|
} |
|
} |
|
if (good) { |
|
V ++; |
|
stack [V].x = x1; |
|
stack [V].y = y1; |
|
stack [V].hod = nom; |
|
if (V = = N*N - 1) return 1; //обход доски завершен |
|
nomhod = 0; |
//снова устанавливаем ход, с которого начинается перебор |
doska [x1][y1] = 1; |
//помечаем клетку как посещаемую |
} else { |
|
if (V < 0) return 0; |
//тупиковая ситуация, обход доски невозможен |
x1 = stack [V].x; |
|
y1 = stack [V].y; |
|
nomhod = stack [V].hod + 1; |
|
V --; |
|
doska [x1][y1] = 0; |
//клетка больше не посещается |
} |
|
} |
|
Стек для распределения памяти
Посмотрим как используется стек при вызове функций. При вызове функции аргументы
функции опускаются в стек. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
Например, имеем программу следующей структуры. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
void main (void) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
int x; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
char p; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
..... |
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f1 (x); |
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
..... |
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
} |
|
f2 (x,p); |
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
void f1 (int z) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
float r; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
int l; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
..... |
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f2 (z,l); |
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
} |
..... |
|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
void f2 (int c, char d) { |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
double q; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
} |
..... |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Рассмотрим состояние стека в процессе выполнения программы. |
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
байты памяти |
|
|
|
|
|
|
|
|
|
|
|
|||||
|
0 |
|
1 |
|
2 |
3 |
|
4 |
5 |
6 |
|
7 |
8 |
9 |
|
10 |
11 |
|
12 |
13 |
14 |
|
15 |
16 |
17 |
|
18 |
19 |
20 |
21 |
1 |
|
x |
|
p |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
x |
|
p |
|
z |
|
|
r |
|
|
l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
5 |
|
x |
|
p |
|
z |
|
|
r |
|
|
l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
6 |
|
x |
|
p |
|
z |
|
|
r |
|
|
l |
|
c |
d |
|
|
|
|
|
q |
|
|
|
||||||
7 |
|
x |
|
p |
|
z |
|
|
r |
|
|
l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
3 |
|
x |
|
p |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
x |
|
p |
|
c |
d |
|
|
|
|
|
q |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Реентерабельность – повторный вход модуля (reenter). Пример:
Преобразование выражения в обратную польскую запись.
Имеем выражение (a + b) * ((c - d) + p/q).
Обратная польская запись этого выражения ab+cd-pq/+*. Сначала записываем операнды, а затем знак операции.
Текст любой программы можно преобразовать в обратную польскую запись.
Исходные данные – символьная строка, содержащая преобразуемое выражение. Строка содержит операнды (только буквы) и знаки операций ( + - / *). Результат работы – символьная строка, содержащая обратную польскую запись.
Алгоритм преобразования выражения в польскую запись следующий. Входную строку просматриваем слева направо. если встретился операнд, то сразу помещаем его в выходную строку. Открывающую скобку помещаем в стек. Знак операции тоже будет помещен в стек, но перед этим его приоритет сравниваем с приоритетом операции на вершине стека и все операции, имеющие приоритет выше или равный приоритету входной операции выталкиваем из стека в
выходную строку. Теперь помещаем в стек знак операции. Закрывающая скобка в стек не помещается, но выталкивает из него все в выходную строку. Ближайшей открывающая скобка выталкивается из стека, но в выходную строку не записывается. Когда входная строка закончится, остаток стека переносится в строку результата.
Алгоритм вычисления обратной польской записи стековый. Просматриваем запись слева направо. Операнды помещаются в стек. Если встречается знак операции, то она выполняется над операндами на вершине стека. Результат операции помещается в стек на вершину вместо выбранных операндов.
Очередь
Это дисциплина обслуживания одномерной последовательности. Все дополнения происходят с одного конца, уменьшения с другого по принципу “первым пришел – первым ушел”
FIFO (First In First Out).
 L
L 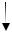 F
F
Если очередь – это одномерный массив V [ ], то L и F указатели на начало и конец очереди. От F к L индекс массива V растет.
Рассмотрим операции с очередью. Помещение элемента в очередь. l ++;
if (l >= MAXQUEE) авария (); V [l] = новые данные;
Взять элемент из очереди. if (f > l) пусто ();
новые данные = V [f];
f++;
Врезультате такого подхода очередь “ползет” по памяти, поскольку L и F постоянно увеличиваются. Это означает чрезвычайно расточительное использование памяти. Чтобы этого избежать представим массив V в виде кольца.
F
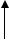 L
L
Тогда операции с очередью будут выглядеть следующим образом. Помещение элемента в очередь.
static int pusto = 1, f, l;
void PutInQuee (... newdata) { l = (l +1)%MAXQUEE;
if (f = = l) переполнение (); V [l] = newdata;
pusto = 0;
}
Взять элемент из очереди. int GetFromQuee (... newdata) {
if (pusto) return 0; newdata = V [f]; pusto = (l = = f);
f = (f + 1)%MAXQUEE; return 1;
}
Массивы
Массив – наиболее известная структура данных, представленная во всех распространенных алгоритмических языках. Массив – однородная совокупность элементов, с каждым из которых связан упорядоченный набор целых чисел, называемых индексами. Число индексов у элемента массива называют размерностью массива. Важным частным случаем является прямоугольный массив, в котором каждый индекс изменяется от нижней до верхней границы, при этом границы изменения индекса не зависят от значения других индексов.
Массив представляет собой статическую структуру данных, т.е. его элементы не порождаются и не исчезают в процессе существования массива.
Автоматические или статические массивы объявляются как прямоугольные.
Например, int a [i][j][k] – трехмерный массив. Наглядно его можно представить в виде параллелепипеда. Если элементы массива расположить в памяти так, чтобы первым изменялся последний индекс, то адрес любого элемента вычисляется по следующей схеме.
Адрес (Aijk) = i * объем слоя + j * размер строки + k +адрес начала массива. В общем случае описание массива имеет вид: A [i1:j1, i2:j2, ..., in:jn].
В этом случае адрес элемента будет вычисляться как:
|
Адрес (Ak1, k2, ..., kn) = ∑n |
(kl − il )Dl |
+ адрес начала массива = адрес начала массива – ∑n |
il Dl + |
|
l=1 |
|
l=1 |
|
+ ∑n |
kl Dl = базовый адрес массива + ∑n |
kl Dl , |
|
|
l=1 |
|
l=1 |
|
|
|
где Dl – объем l-сечения. |
|
|
|
Чем выше размерность массива, тем медленнее вычисляется адрес массива. Массив в памяти ЭВМ хранится следующим образом.
IA = {B, n, i1, j1, i2, j2, ..., in, jn},
где B – базовый адрес массива, n – размерность, i, j – нижние и верхние границы.
Метод Айлиффа (векторизация массива). Этот метод позволяет работать с непрямоугольными массивами.
Рассмотрим этот метод на примере трехмерного массива.
Указатель на начало массива указывает на массив указателей слоев. Каждый из указателей указывает на указатели строк, которые в свою очередь указывают на элементы, расположенные в памяти последовательно.

|
|
|
|
А |
|
|
|
50: |
|
100 |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
200 |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
указатели слоев |
|
|
|
|
|
|
|
|
|
||||
|
|
|
100: |
|
|
|
|
|
|
|
|
200: |
|
|
|
|
|
|
|
|
||
|
|
|
|
300 |
|
|
|
|
|
|
|
305 |
|
|
|
|
|
|
||||
|
|
|
|
|
|
304 |
|
|
указатели строк |
|
|
311 |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
102 |
|
|
|
|
|
|
|
|
000 |
001 |
002 |
|
003 |
010 |
|
011 |
|
100 |
|
101 |
|
103 |
104 |
110 |
111 |
112 |
113 |
||||
300 |
301 |
302 |
|
303 |
304 |
|
305 |
|
306 |
|
307 |
308 |
|
309 |
310 |
311 |
312 |
312 |
314 |
|||
Обращение к элементу непрямоугольного массива может быть осуществлено следующим образом.
*(*(*(A + i) +j) +k) = Aijk
Это эквивалентно A [i][j][k], если массив А прямоугольный. Пример:
Работа с нижней треугольной матрицей. float **a;
a = (float**) calloc (n, sizeof(float *));
for (i = 0; i < n; i ++) a[i] = (float*) calloc (i + 1, sizeof(float));
Тогда a [i][j] как и прямоугольный массив.
int heapcheck () – проверяет коррекцию кучи. Возвращает значения больше нуля, если куча корректна (1 – куча пуста, 2 – куча корректна) и меньше нуля в случае ошибки (-1 – куча повреждена).
Все указатели, память под которые выделяется из кучи, должны быть инициированы постоянным нулем.
float **a = NULL;
Освобождение памяти: for (i = 0; i < n; i ++) {
if (a[i] != NULL) free (a[i]); else ошибка!!!();
}
if (a != NULL) free(a);
Списки
Рассмотрим строку. КОРА
Эта строка в памяти компьютера представляется следующим образом: К 

 О
О 
 Р
Р 
 А
А 
Т.е. неявным образом хранятся указатели на следующие буквы за счет последовательного расположения элементов строки в памяти. Получили список.
Если теперь в строку захотим вставить строку ИЦ в исходную, чтобы получить строку КОРИЦА , то последняя буква сдвигается и на освободившееся место вставляется нужная строка следующим образом:
К

 О
О 
 Р
Р 
 А
А 
И
 Ц
Ц 
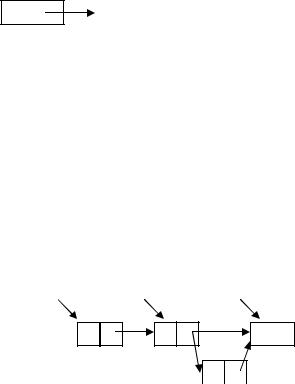
Список – это множество из N узлов, которые связаны между собой некоторым образом с помощью связей. В списке каждый элемент имеет два поля: поле, где хранится необходимая информация и поле, где хранится указатель на следующий элемент (или NULL, если элемент последний в списке).
Список представляет собой динамическую структуру данных. Его элементы порождаются и уничтожаются в процессе существования списка. Списки удобно использовать, когда неизвестно, сколько элементов будет находиться во множестве.
В списочной структуре структурные связи хранятся явным образом. Списочные структуры – связанные, не списочные – последовательные.
Линейные односвязные списки
Элемент односвязного списка состоит из поля данных и поля, где хранится указатель на следующий элемент списка.
info
Каждый элемент линейного односвязного списка представляется структурой: typedef struct A {
... info; |
//поле данных |
struct A *link; |
//поле связи, указатель на следующий элемент |
} UZEL; |
|
Нужно отметить, что память под узлы списка всегда выделяется динамически при помощи функции calloc из кучи.
Линейный односвязный список всегда представлен указателем на первый элемент списка, назовем его BEGIN. Заканчивается список пустой связью.
Нужно отметить, что если известен указатель на некоторый узел списка, то указатель на узел последователь вычислим, а на узел предшественник нет. Это особенность односвязного списка.
Рассмотрим операции со списком.
Операция вставки элемента в линейный односвязный список. BEGIN P P′

X 

Будем производить вставку узла X следом за узлом P. Для этого напишем функцию, которая будет возвращать указатель на вставленный узел.
UZEL* Insert (UZEL *p) { |
|
UZEL *x; |
//объявляем новый узел |
x = (UZEL*) calloc (1, sizeof(UZEL)); |
//распределяем под него память из кучи |
if (x = = NULL) авария(); |
//если память не выделилась |
x Æ info = новые данные; |
//заполнение данными узла |
x Æ link = p Æ link; |
//перенаправляем связи |
p Æ link = x; |
|
return x; |
|
}
Как видно из этой функции, для того, чтобы произвести вставку узла в линейный односвязный список, нужно знать указатель на предшественника. Поэтому функция вставки в начало будет специфичной.
UZEL* Insert (UZEL **p) {

UZEL *x;
x = (UZEL*) calloc (1, sizeof(UZEL)); if (x = = NULL) авария();
x Æ info = новые данные; x Æ link = *p;
*p = x; return x;
//распределяем под него память из кучи //если память не выделилась //заполнение данными узла
//перенаправляем связи
}
Тогда вызов функции вставки элемента после элемента А будет выглядеть следующим образом:
insert (&(A Æ link));
А вызов функции для вставки элемента перед первым элементом H будет выглядеть так: insert (&H);
Для выполнения операции удаления элемента также нужно знать указатель на узел предшественник.
P X
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
void Delete (UZEL *p) { |
|
|
|
||||||
UZEL *x; |
|
|
|
||||||
x = p Æ link; |
|
|
//получаем узел, который нужно удалить |
||||||
if (x != NULL) { |
|
|
|
||||||
p Æ link = x Æ link; |
|
|
//перенаправляем связи |
||||||
free (x); |
|
|
|
||||||
}
return;
}
Так же существует особенность при удалении первого элемента списка.
Односвязный кольцевой список.
Это список, последний элемент которого указывает на первый, т.е. получается кольцо. Кольцевой список всегда представлен указателем на хвост tail.
Такой список очень легко расщепить на два списка.
|
P |
|
tail |
||
|
|
|
|
|
|
|
|
|
|
|
|
Процедура расщепления выглядит следующим образом. x = p Æ link;
p Æ link = tail Æ link; tail Æ link = x;
Эта процедура работает как кнопочный выключатель, т.е. выполняет и расщепление и сцепление.
Закольцованный список обладает тем хорошим свойством, что позволяет избежать особенностей, связанных с обработкой узла в начале списка.
Списки с головой.