

Уханов - лекции
.pdfНазовем головой некоторый специфический узел списка. Часто в поле данных головы помещают такие данные, которых не может быть в остальных узлах списка. Голова всегда присутствует в списке, даже если он пуст.
Двусвязные линейные списки
Элемент двусвязного списка состоит из поля данных и двух полей связи, левой и правой.
info 
Каждый элемент линейного двусвязного списка представляется структурой:
typedef struct R { |
|
... info; |
//поле данных |
struct R *llink; |
//поле связи, указатель на предыдущий элемент |
struct R *rlink; |
//поле связи, указатель на следующий элемент |
} UZEL; |
|
Поскольку введена еще одна связь, то проблема поиска предшественника узла решена. Вставку узла теперь можно производить как вправо от узла, так и влево.
Рассмотрим теперь операции с двусвязным списком. Операция вставки узла справа от заданного.
P 
X 
Как видно из рисунка, требуется поменять не две связи, а четыре. Функция будет возвращать указатель на вставленный узел. UZEL* RInsert (UZEL *p) {
UZEL *x;
x = (UZEL*) calloc (1, sizeof(UZEL)); x Æ llink = p;
x Æ rlink = p Æ rlink; p Æ rlink Æ llink = x; p Æ rlink = x;
return x;
}
Удаление узла из двусвязного списка. P
Известен указатель на удаляемый узел. void Delete (UZEL *p) {
p Æ rlink Æ llink = p Æ llink; p Æ llink Æ rlink = p Æ rlink; free (p);
}
Аналогично односвязным, двусвязные списки могут быть кольцевые и с головой.

Достоинством двусвязных списков по отношению к односвязным является возможность вычисления предшественника узла. Однако это становится возможным за счет введения дополнительной связи. А, следовательно, появляются недостатки:
•затрачивается память на хранение лишнего указателя;
•становится невозможным получить такую структуру:
Постараемся при работе со списками обойтись без указателей. Для этого узел списка зададим структурой
typedef struct {
... info; int rlink; int llink;
} UZEL;
Здесь rlink и llink индексы массива UZEL U [2000];
Тогда левая связь правого соседа узла x может быть найдена следующим образом: U [U [x].rlink].llink
Список может быть внешним (лежать на диске). Тогда он может быть задан структурой: typedef struct {
... info; long rlink; long llink;
} UZEL;
Здесь rlink и llink либо номер узла на диске, либо смещение этого узла.
Ортогональные списки
Ортогональные списки можно считать аналогом многомерных массивов. Пример:
|
3 |
2 |
0 |
|
Задана матрица |
0 |
7 |
3 |
. |
|
0 |
0 |
1 |
|
|
|
В виде списка ее можно представить следующим образом.
!!!!!!!! !!!!!!!! !!!!!!!
!!!!!!!! |
|
3 |
|
2 |
|
|
value = 3; |
|
|
|
|
|
|
|
row = 1; |
!!!!!!!! |
|
|
|
7 |
|
3 |
column = 2; |
|
|
|
|
|
|
|
|
!!!!!!!! |
|
|
|
|
|
1 |
|
Получается, что каждый нетривиальный элемент входит в два списка. Структура узла такого списка следующая.
typedef struct UM { double value;
int row, column;
struct UM *right, *down; } UZEL;
Списки общего вида
В списках общего вида каждый элемент списка сам может быть спискам.
Узел списка содержит поле данных, поле связи и поле plink – указатель на подсписок, исходящий из данного узла. Следовательно, такой узел в общем случае представляет собой список.
Структура узла следующая. typedef struct A {
... info;
struct A *next; struct A *plink;
} UZEL;
Пример:
A: |
a |
|
|
c |
|
|
q |
|
|
|
|
B: |
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
t |
|
|
r |
|
|
w |
|
Для списка A имеем элементы: а, с(А) (сам является списком), q(В) (сам является списком).
Для списка В: x, t, r(A), w.
В списке А удалить первый узел невозможно. Этого можно избежать, если потребовать наличие головы у списка.
Топологическая сортировка
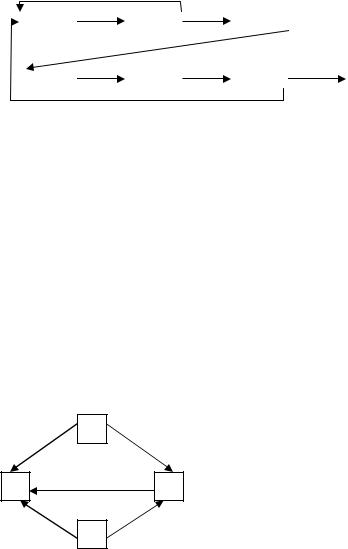
Топологическая сортировка играет огромную роль в лингвистике и, вообще, она оказывается полезной всякий раз, когда сталкиваемся с частичным упорядочением. Множество S называется частично упорядоченным, если над его элементами определено отношение x{y (x предшествует y). Частичное упорядочение встречается довольно часто. В качестве примера из математики можно привести отношение x ≤ y между вещественными числами, x y между множествами.
Частичное упорядочение на конечном множестве всегда можно проиллюстрировать на диаграмме.
Имеется набор отношений: 1{2 3{2 4{2 3{4 1{4.
|
1 |
2 |
4 |
3
Стрелками на диаграмме представлены отношения между элементами: x{y, следовательно, от x к y существует путь, идущий вдоль стрелок в соответствии с их направлением.
Свойство частичного упорядочения предполагает, что в диаграмме нет замкнутых контуров (путей, замыкающихся на себя). Если бы вместо упорядочения 3{2 в исходном множестве имелась бы пара 2{3, то частичного упорядочения уже не было бы.
Проблема топологической сортировки состоит в том, чтобы перевести частичное упорядочение в линейное, т.е. расположить элементы в линейной последовательности a1 ,a2 ,...,a n
такую, что если a j{ak , то j < k. Графически это можно представить в виде:
1 3  4
4  2
2
Т.е. все стрелки ориентированы направо. Существование такого расположения не является очевидным. Оно заведомо невозможно, если есть хотя бы один контур. Таким образом, алгоритм топологической сортировки интересен не столько с точки зрения пользы выполняемой операции, сколько из-за доказательства того, что эта операция возможна при любом способе частичного упорядочения.
Пример использования топологической сортировки. Имеем толковый словарь. Можно определить упорядоченность терминов словаря, если один термин прямо или косвенно зависит от другого. Это отношение частичное упорядочение, если нет “циклических” определений. Задача топологической сортировки заключается в следующем. Найти такой способ расположения слов в словаре, при котором ни один из терминов не использовался раньше, чем он определен.
Рассмотрим алгоритм, выполняющий сортировку за время, пропорциональное длине массива.
Данные будут представлены списком со структурой узла: typedef struct A {
int el; int count;
struct A *llink; struct A *rlink; struct B *plink;
} MAIN; typedef struct B {
MAIN *m; struct B *next;
} POD;
Т.е. элемент списка будет представлять собой следующую конструкцию.
el |
count |
|
|
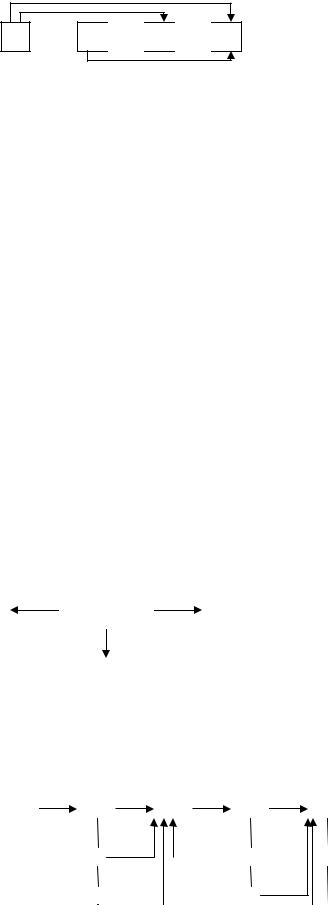
I фаза алгоритма – построение основного списка.
Будем строить список с узлами типа MAIN с головой и закольцованный. Строим список следующим образом.
!!! |
|
|
1 |
0 |
|
2 |
3 |
|
3 |
0 |
|
4 |
2 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

II фаза алгоритма – выделение списка ведущих элементов.
Проходим весь основной список и те элементы, счетчик который равен нулю переносим в список ведущих.
!!! |
|
|
2 |
3 |
|
4 |
2 |
||||
основной |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ведущих |
|
|
!!! |
1 0 |
3 0 |
III фаза алгоритма – формирование выходной последовательности.
Проходим список ведущих и элемент из списка помещаем в выходную последовательность. Далее проходим подсписок этого элемента и поле счетчика узла, на который ссылается элемент из списка уменьшаем на 1. Если после этого счетчик окажется 0, то он перемещается в хвост списка ведущих.
Обслуживание списка свободного пространства
Свободное пространство организуется как список. Здесь лежат узлы, которые списки освободили. Список свободного пространства представлен указателем avail.
При удалении элемента из списка происходит его помещение в список свободного пространства следующим образом.
avail 
 avail
avail
P
При вставке элемента в список он берется из списка свободного пространства. avail  avail
avail 
P 

Для списков общего вида такая простая реализация не подходит. Когда в таком списке происходит удаление узла, то, возможно, этот узел останется принадлежать другим спискам. Следовательно, совершенно неясно, когда следует возвратить его в свободное пространство. Для обслуживания списка свободного пространства существует два основных метода: счетчик ссылок и “сбор мусора”.

В методе счетчика ссылок используется специальное поле в каждом узле, в котором учитывается, сколько ссылок указывает на этот узел. Всяких раз, когда счетчик сбрасывается в нуль, данный узел становится свободным. Тогда этот узел можно отправить в свободное пространство. Однако есть принципиальный недостаток. Если имеется узел, который ссылается сам на себя, то поле счетчика такого узла никогда не будет равным нулем и он никогда не будет возвращен в свободное пространство.
Второй метод – “сбор мусора”. Программа берет узлы в свободном пространстве и не возвращает их до тех пор, пока не исчерпается память. Мусором называется память, которая не входит ни в одну из списочных структур, доступных программе. Когда окажется, что свободное пространство пусто, вызывается мусорщик (это специальная подпрограмма), который должен собрать брошенные узлы и соединить их в список свободного пространства.
Работа мусорщика заключается в следующем. Требуется один бит маркировки. На этапе разметки мусорщик обходит все память, отведенную под списки, и устанавливает все биты маркировки в нуль. Последующие действия выполняются систематически. Мусорщик проходит все списки, доступные программе и проставляет биты маркировки в единицу. Те узлы, которые не принадлежат спискам остаются помеченными нулем. На этапе сборки мусора вновь обходится вся память и все узлы с нулевыми битами мусорщик собирает в стек свободного пространства.
Недостатком метода сбора мусора является то, что он медленно работает, когда загрузка памяти велика. В таких случаях число свободных ячеек, полученных с помощью сбора мусора, мало и не окупает затраченных усилий. Те программы, которым не хватает памяти, впустую расходуют массу времени, многократно и бесплодно вызывая мусорщика перед тем, как окончательно исчерпать память.
Посчитаем время, затраченное мусорщиком. Введем некоторые обозначения.
N – количество узлов в памяти.
M – количество узлов, занятых в списках. N - M – мусор.
τ – время, потраченное на посещение одного узла.
Тогда время, потраченное мусорщиком, может быть описано формулой
Nτ + Mτ + Nτ
(время, затраченное на разметку памяти + время, затраченное на обход списков, доступных программе + время, затраченное на сбор мусора).
А время, требуемое на возврат одного узла
Nτ + Mτ + Nτ |
|
2 τ + |
M |
τ |
|
τ(2 +α) . |
||||
= |
N |
= |
||||||||
|
N −M |
|
M |
|||||||
|
|
1− |
|
1−α |
||||||
M |
|
|
N |
|
|
|
||||
=α – коэффициент использования памяти. |
||||||||||
N |
||||||||||
|
|
|
|
|
|
|
|
|
||
1
Можно видеть, до какой степени неэффективен сбор мусора, память становится полной, и насколько он эффективен, когда требования к памяти невелики. Алгоритм сбора мусора практически непригоден в режиме реального времени, даже если мусорщик вызывается нечасто.

Деревья
Деревом называется множество из N узлов, в котором выделен один узел, называемый корнем, а остальные узлы разбиты на попарно непересекающиеся множества, каждое из которых является деревом.
Пример:
a
|
|
I уровень |
b |
c |
d |
|
|
II уровень |
e |
f |
|
Принята следующая терминология. а – отец узлов b, c, d.
b, c, d – сыновья а. b, c, d – братья.
e, f – потомки а.
Узел, не имеющий сыновей, называется листом. Дерево называется упорядоченным, если порядок следования сыновей существенен. В упорядоченном дереве левый брат считается старшим. Число уровней в дереве определяет его высоту. Число сыновей узла – его степень.
Лес – это множество, может быть пустое, состоящее из некоторого числа непересекающихся деревьев.
Примерами древовидной структуры являются генеалогические деревья, оглавленья. Существует два способа представления дерева.
Первый способ:
typedef struct U { |
|
... info; |
//поле данных узла |
int nson; |
//степень узла |
struct U *son [MAXSON]; |
//массив указателей на сыновей |
struct U *father; |
//указатель на отца. |
} UZEL;
Указатель на отца может и отсутствовать. Второй способ:
typedef struct U { |
|
... info; |
|
struct B *first; |
//указатель на указатель на первого сына} MAIN_UZEL; |
Структура узлов вспомогательного списка: |
|
typedef struct B { |
|
MAIN_UZEL *U; |
//указатель на узел дерева |
struct B *next; |
//указатель на следующий узел списка. |
} VSP; |
|
MAIN_UZEL
 VSP
VSP
Бинарные деревья
Бинарные деревья состоят из корня и двух поддеревьев, которые являются в свою очередь являются бинарными деревьями. Эти деревья могут быть пустыми. Одно из поддеревьев называется левым, другое правым.
a
b d
e f g
Деревья
a a
b |
b |
различны, так как в первом случае пусто правое поддерево, а во втором – левое. Пример:
Арифметическое выражение можно представить с помощью бинарного дерева. (a + b) / (c - d)
/
+–
a b c d
Для представления бинарного дерева достаточно иметь две связи в каждом узле и указатель на дерево.
Узел бинарного дерева представляется следующей структурой. typedef struct R {
... info;
struct R *llink; struct R *rlink;
} NODE;
Для работы с деревом требуется некоторым способом просматривать узлы дерева, т.е. совершать обход дерева. Обойти дерево – это значит посетить каждый узел дерева некоторым систематическим образом ровно один раз. Существует несколько вариантов обхода бинарного дерева, определяемых рекурсивно.
• Прямой порядок. Сначала корень, затем левое поддерево, далее правое.
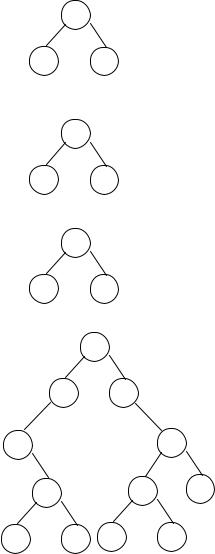
1
23
•Обратный порядок. Сначала левое поддерево, затем корень, далее правое.
2
13
•Концевой порядок. Сначала левое поддерево, затем правое, далее корень.
|
3 |
|
|
1 |
|
2 |
|
Пример: |
|
|
|
|
|
a |
|
b |
|
c |
|
d |
|
|
p |
e |
|
q |
l |
f |
g |
s |
r |
При использовании прямого обхода получим последовательность: a b d e f g c p q s r l.
Обратный обход: d f e g b a c s q r p l. Концевой обход: f g e d b s r q l p c a.
Рассмотрим функции обхода. Поскольку алгоритм обхода рекурсивный, то и здесь используется рекурсия.
Прямой.
void TreeD (NODE *root) { if (root = = NULL) return;
обработка (root); TreeD (root Æ llink); TreeD (root Æ rlink);
}
Обратный.
void TreeO (NODE *root) { if (root = = NULL) return; TreeD (root Æ llink);
обработка (root); TreeD (root Æ rlink);
}
Концевой.
void TreeK (NODE *root) {
if (root = = NULL) return; TreeD (root Æ llink); TreeD (root Æ rlink);
обработка (root);
}
Рекурсия может быть реализована с использованием механизма стека. void TreeO (NODE *root) {
NODE *a;
NODE *stack [MAXSTACK];
int v = -1; a = root; for (;;) {
while (a != NULL){ stack [ ++v] = a; a = a Æ llink;
}
if (v < 0) return; //дерево пройдено полностью a = stack [v --];
обработка (а); a = a Æ rlink;
}
}
Вставка узла в дерево не вызывает сложностей. Для этого нужно только правильно направить связи.
Удаление узла из бинарного дерева должно происходить так, чтобы порядок следования узлов в обходе дерева не был нарушен. Легко удаляется лист или узел с пустой левой или правой связью. Удаление узла с непустыми связями может проходить по такому алгоритму. Найти предшественника или последователя в обратном порядке с пустыми связями, удалить его, а затем вернуть на место узла, который на самом деле следовало удалить.
Пример:
Рассмотрим некоторую последовательность: 5 3 7 2 4 8 6 1 Будем строить дерево по принципу – если меньше, то влево. Получим такое дерево.
5
3 7
2 |
4 |
6 |
8 |
1
Тогда обратный обход даст сортированную последовательность: 1 2 3 4 5 6 7 8. Если дерево хорошо организовано, то его длина ~ log2N, N число узлов в дереве.
Прошитые деревья
Если в дереве с N узлами имеется N-1 непустая связь, то N+1 связь пуста, ибо общее число связей 2N. Таким образом, число пустых связей велико. Поля, занятые пустыми связями, можно занять другой полезной информацией, которая упрощает прохождение дерева. Вместо пустых