

Уханов - лекции
.pdfЧисло физических обращений к диску равно высоте дерева. Поиск внутри узла производится методом дихотомии.
При вставке нового ключа может понадобиться расщепить l узлов. Однако, среднее число расщепляемых узлов много меньше, так как общее количество расщеплений при построении дерева ровно на единицу меньше количества узлов, которое обозначим через р. В дереве не менее
m |
|
|
|
|
N −1 |
|
|
||||||
1+ |
|
−1 (p −1) |
ключей, следовательно |
p ≤1 |
+ |
|
|
|
|
|
|
. Это означает, что среднее число |
|
|
m |
|
|
−1 |
|||||||||
2 |
|
|
|
|
2 |
|
|
||||||
|
|
|
|
|
|
|
|
1 |
|
||||
расщеплений, требующихся на одну вставку, меньше |
|
|
|
. |
|||||||||
|
m |
|
|||||||||||
|
|
|
|
|
|
|
|
2 |
|
−1 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Модификация В-деревьев
Предложенные методы можно улучшить, если изменить определение В-дерева.
В дереве В+ все ключи, связанные со ссылками на основную таблицу находятся в листьях, то есть узлы верхних (нелистовых) уровней не содержат ссылок на записи. В результате упрощается последовательное прохождение записи в В-дереве.
Если в листья добавить указатели – прошить дерево слева направо, следовательно, получим последовательный список. При удалении ключа из В+-дерева ключ удаляется только из листа. В узлах верхнего уровня он сохраняется, его роль – быть разделителем. Такая модификация упрощает вставку и удаление, но ухудшает использование памяти.
Таблицы с прямым доступом
Пусть в таблице имеется некоторое множество записей с разными значения ключа k. Для поиска записи в таблице нужно решить следующее уравнение относительно адреса: f (адрес) = ключ, т.е. получить адрес = ϕ (ключ).
Следующее требование является обязательным: ϕ (ki) ≠ ϕ (kj) при ki ≠ kj, т.е. ϕ – взаимно однозначная функция. Это требование является очень жестким.
Функцию ϕ (ключ) называют функцией расстановки. Доступ к записи по ключу осуществляется непосредственно путем вычисления значения функции ϕ (ключ). Таблица, для которой существует и известна функция расстановки ϕ (ключ), называется таблицей с прямым доступом. Подбор функции расстановки, обеспечивающей взаимно однозначное преобразование ключа записи в адрес хранения, можно решить только для небольших по объему наборов ключей и исключается возможность модификации таблицы. Всегда фиксированное количество ключей.
Рассеянные таблицы
В общем случае обеспечить взаимную однозначность преобразования ключа в адрес хранения записи практически невозможно.
Можно получить более гибкий метод, если отказаться от требования взаимной однозначности, допустив совпадение значений ϕ (ki) = ϕ (kj) для различных аргументов ki ≠ kj. Это приводит к наложению записей. Чтобы таких ситуаций было меньше, функцию расстановки подбирают из условия случайного и возможно более равномерного отображения ключей в адрес хранения. Таблицы, построенные по такому принципу называют рассеянными или таблицами со случайным перемешиванием. Метод вычисления адреса называют хешированием (от английского to hash). Функцию расстановки h (k) (хеш-функцию) стремятся сделать такой, чтобы она рассеяла ключи по памяти. Наверняка найдутся ключи ki ≠ kj, для которых h (ki) = h (kj). Это означает, что две записи претендуют на один адрес хранения. Такие ключи называют синонимами, а событие – коллизией.
Хеш-функции
В качестве хеш-функции h(k) выбирается функция, которая более равномерно рассеивает ключи по пространству таблицы. Это важно для уменьшения числа коллизий. Для рассеянных таблиц характерно заранее назначать объем памяти, которая отводится под таблицу. Предположим, что хеш-функция имеет более М различных значений 0 ≤ h(k) < M. Хорошая хешфункция должна удовлетворять двум требованиям: ее вычисление должно быть быстрым, а число коллизий – минимальным. Экспериментально была выявлена хорошая работа двух типов хешфункций. Один из них основан на делении, другой на умножении.
Метод деления использует остаток от деления на М: h(k) = k mod M. Очевидно, что некоторые значения М лучше других. Например, если М четно, то значение h(k) будет четным при четном k и нечетным при нечетном k. Если в некотором файле все ключи четны, то рассеяние будет плохим и память будет использоваться только на 50%.
Можно предложить |
следующий способ определения функции |
хеширования: |
|
h(k) = (a k + b) mod M, где a, |
b – |
некоторые константы. Это псевдослучайное преобразование |
|
ключа в адрес. |
|
|
|
Пример: |
|
|
|
а = 17; b = 23; M = 100. |
|
|
|
h(42) = 37. |
|
|
|
Мультипликативную схему |
хеширования также легко реализовать. |
Пусть число А |
|
представлено в формате с фиксированной точкой и эта точка установлена слева от машинного слова, в котором записано А. Тогда хеш-функция вычисляется следующим образом: h(k) = M ((A k) mod 1).
Пример:
А = 0,385; М = 100. h(42) = 17.
Было придумано много других методов хеширования, но ни один из них не оказался предпочтительней описанных выше простых схем деления и умножения.
Методы разрешения коллизий
Метод цепочек переполнения.
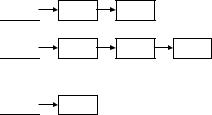
Наиболее простой способ разрешения коллизий состоит в том, чтобы поддерживать М линейных списков – по одному на каждый возможный хеш-адрес. Все записи должны иметь поля связи, кроме того, нужно иметь М голов списков Хеш-функция вычисляет номер списка, в котором следует искать запись. Поиск записи в списке производится последовательным перебором. Если имеется N записей и М списков, то средний размер списка равен N/М.
h0 

h1 

...............................................................
hM-1 

Тогда основные операции с таблицей выполняются следующим образом. Вставка: вычисляется номер списка; запись помещается в начало этого списка. Поиск: вычисляется номер списка, далее последовательный перебор. Удаление: операция поиска + удаление записи из списка.
Можно комбинировать списки с деревьями. Это поможет улучшить время поиска и вставки. Метод открытой адресации.
Метод состоит в том, чтобы, отправляясь от вычисленного хеш-адреса, просматривать записи до тех пор, пока не будет найден искомый ключ или свободная позиция. Простейшая схема
открытой адресации, известная как линейное опробирование, использует циклическую последовательность проб h(k), h(k)+1, h(k)+2, ..., М-1, 0, 1, ... h(k)-1.
Рассмотрим операции вставки, поиска и удаления.
Вставка. Вычисляется хеш-адрес. Если позиция по этому адресу свободна, то запись туда помещается. Если занята, от отправляясь от вычисленного хеш-адреса перебираем позиции таблицы одну за другой циклически в поисках свободной записи. Если свободная запись позиция найдется, следовательно, произведем вставку. Если не найдется, следовательно, таблица переполнилась. Тогда нужно выполнить рехеширование с большим значением М.
Поиск. Вычисляется хеш-адрес и начиная с него, перебираются все записи до тех пор, пока не обнаружим искомый ключ или не встретим свободную позицию. Если найдена свободная позиция, следовательно, ключа в таблице нет, ибо при вставке использовался тот же метод просмотра таблицы. Может потребоваться просмотр всей таблицы для поиска отсутствующего ключа, если таблица вся заполнена.
Удаление. Просто удалить запись, пометив ее как свободную нельзя, так как при этом нарушится работа алгоритмов поиска и вставки. Поэтому будем помечать записи как свободные, занятые и удаленные. При поиске удаленные записи трактуются как занятые. В случае вставки удаленные записи будут трактоваться как свободные. Следовательно, если встретится удаленная запись, вставка будет произведена в нее. Однако эта идея применима только при очень редких удалениях, ибо однажды занятая запись никогда не станет свободной. Поэтому после множества вставок и удалений все свободное пространство в таблице исчезнет и каждый неудачный поиск будет требовать просмотра всех М записей, т.е. сведется к последовательному. Следовательно, требуется рехеширование.
Такой метод работает хорошо, пока таблица не слишком заполнена. Для линейного опробирования характерно явление скучивания – скопления записей группами. Шанс для нового ключа попасть в кучу тем больше, чем больше размер кучи. Действительно, если адреса h(k), h(k)- 1, ..., h(k)-i уже заняты (т.е. образовалась куча), то добавление новой записи с хеш-адресом из диапазона [h(k)-i, h(k)] увеличивает кучу. Следовательно куча склонна к экспоненциальному росту. Чтобы избежать скучивания используют двойное хеширование. Тогда шаг опробирования позиции и адреса будет следующим: h(k), h(k) + h2(k), h(k) + 2h2(k), ... Значение вторичной хешфункции должно быть числом, взаимно простым с М, т.е. не должно иметь общих простых делителей.
Оценка трудоемкости операций над рассеянной таблицей
Пусть М – размер таблицы, N – количество записей. Тогда α = N/M – коэффициент использования памяти.
Конечные автоматы
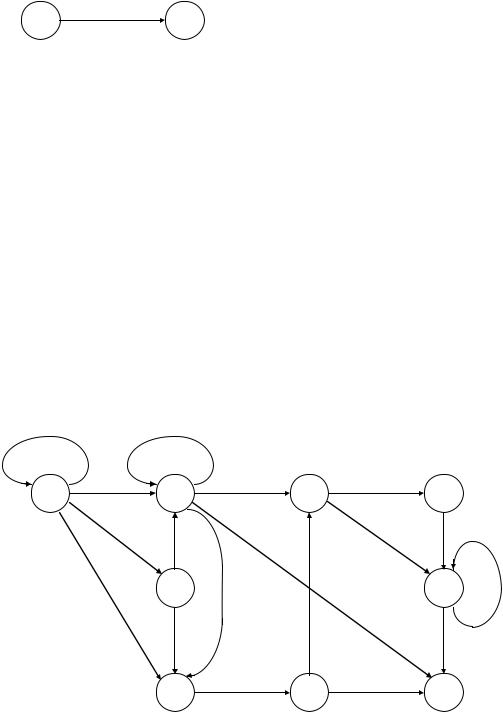
Конечный автомат – это такое абстрактное устройство, способное находиться в каждый данный момент в одном из состояний. Число состояний конечно и предопределено для каждого автомата и не меняется в процессе работы. Среди множества состояний выделяется начальное и одно или множество конечных состояний. Попав в конечное состояние автомат прекращает работу. На вход автомата поступают символы из некоторого алфавита (некоторые воздействия на автомат). Под воздействием такого символа автомат переходит из текущего состояния в другое и, может быть, выполняет при этом некоторые действия.
Существуют автоматы Мили и Мура. Действие, выполняемое автоматом, может быть ассоциировано с состоянием, а может с переходом. Например, автомат переходит из состояния 1 в состояние 2 под воздействием символа α. При переходе из одного состояния в другое выполняется функция f1. Функция f2 выполняется, когда автомат находится во втором состоянии.
α |
2 |
1 |
|
f1 |
f2 |
В общем случае, поведение автомата определяется таблицей перехода. В этой таблице |
|
описываются функции, |
ассоциированные с переходом. Таблица содержит следующие поля: |
текущее состояние; входной символ; следующее состояние, в которое переходит автомат; функция, ассоциированная с переходом.
Если есть функции, ассоциированные с состоянием автомата, то требуется две таблицы. Первая таблица будет содержать поля: текущее состояние; входной символ; следующее состояние. Вторая таблица: состояние; функция, ассоциированная с состоянием.
Пример:
Преобразование константы из символьного представления к double.
Допустимыми константами являются следующие: |
|
|
||||||
12.73 -0.03 |
-.56 +30 12.78е-13 |
-12.13Е+14 12e15 |
||||||
Определим классы символов на входе автомата: |
|
|
||||||
#define DIGIT |
0 |
|
|
|
|
|
|
|
#define DOT |
1 |
|
|
|
|
|
|
|
#define SIGN |
2 |
|
|
|
|
|
|
|
#define EE |
3 |
|
|
|
|
|
|
|
#define ETC |
4 |
|
|
|
|
|
|
|
Тогда схема конечного автомата примет вид: |
|
|
||||||
ETC |
|
|
DIGIT |
|
|
|
|
|
1 |
DIGIT |
|
2 |
EE |
5 |
SIGN |
7 |
|
|
|
|
|
|
||||
|
|
|
SIGN |
DIGIT |
|
EE |
DIGIT |
DIGIT |
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
DIGIT |
|
|
|
|
DOT |
|
|
8 |
|
|
|
|
DOT DOT |
|
|
ETC |
ETC |
|
|
|
|
|
|
|
|
||
|
|
|
|
4 |
DIGIT |
6 |
ETC |
9 |
|
|
|
|
|
|
|||
DIGIT
Состояние 1 является начальным, 9 – конечным. Опишем структуру таблицы перехода:
typedef struct {
int state; |
// текущее состояние конечного автомата |
chat symbol; |
// текущий символ на входе конечного автомата |
int next; |
// следующее состояние |
int (*f)(void); // функция, ассоциированная с переходом |
|
} TAB;
Тогда таблица перехода конечного автомата будет выглядеть следующим образом:
static TAB t [ ] = { |
|
{1, ETC, 1, dummy}, |
// конечный автомат в ожидании начала числа |
{1, DIGIT, 2, f1}, |
// на входе цифра числа из целой части |
{1, SIGN, 3, f2}, |
// на входе знак числа |
{1, DOT, 4, dummy}, |
// есть дробная часть числа |
{2, DIGIT, 2, f1}, |
// на входе цифра числа из целой части |
{2, DOT, 4, dummy}, |
// есть дробная часть числа |
{2, EE, 5, dummy}, |
// есть степень числа |
{2, ETC, 9, f3}, |
// число закончилось |
{3, DIGIT, 2, f1}, |
// на входе цифра числа из целой части |
{3, DOT, 4, dummy}, |
// есть дробная часть числа |
{4, DIGIT, 6, f4}, |
// на входе цифра числа из дробной части |
{4, EE, 5, dummy}, |
// есть степень числа |
{4, ETC, 9, f3}, |
// число закончилось |
{5, SIGN, 7, f5}, |
// на входе знак степени |
{5, DIGIT, 8, f6}, |
// на входе цифра степени числа |
{6, DIGIT, 6, f4}, |
// на входе цифра числа из дробной части |
{6, EE, 5, dummy}, |
// есть степень числа |
{6, ETC, 9, f3}, |
// число закончилось |
{7, DIGIT, 8, f6}, |
// на входе цифра степени числа |
{8, DIGIT, 8, f6}, |
// на входе цифра степени числа |
{8, ETC, 9, f3} |
// число закончилось |
}; |
|
Опишем глобальные переменные: |
|
static int sign_dig; |
// знак числа |
static int n_dig; |
// количество цифр в целой части числа |
static int d_dig; |
// количество цифр в дробной части числа |
static int sign_pow; |
// знак степени числа |
static int pow; |
// степень числа |
static double m; |
// мантисса числа |
static char symbol; |
// текущий символ на входе автомата |
Функция-пустышка. |
|
static int dummy (void) { return 0;
}
Добавляем новую цифру к целой части. static int f1 (void) {
n_dig ++;
m = 10*m + symbol - ‘0’; return 0;
}
Получим знак числа. static int f2 (void) {
if (symbol = = ‘–‘) sign_dig = -1; else sign_dig = 1;
return 0;
}
Число завершилось – преобразование к double. static int f3 (void) {
m = sign_dig*m*pow (10, sign_pow*pow - d_dig); return 0;
}
Добавляем новую цифру к дробной части static int f4 (void) {
d_dig ++;
m = 10*m + symbol - ‘0’; return 0;
}
Получим знак степени числа. static int f5 (void) {
if (symbol = = ‘–‘) sign_pow = -1; else sign_pow = 1;
return 0;
}
Добавляем новую цифру к степени числа. static int f6 (void) {
pow = 10* pow + symbol - ‘0’; return 0;
}
Литература
1.Н.Вирт. Алгоритмы + структуры данных = программы. – М.: Мир, 1980.
2.Д.Кнут. Искусство программирования для ЭВМ том 1,3. – M.: Мир, 1976.
3.М.Сибуя, Т.Ямамото. Алгоритмы обработки данных. – М.: Мир, 1986.