

Содержание работы.
Описательная статистика позволяет с помощью специальных методов осуществить удобное представление данных для последующего анализа в виде частотных распределений, графических изображений и различных числовых характеристик.
I. Первым этапом статистической обработки данных является их шкалирование и наглядное представление. Для этого используются табличный (групповой) и графический методы.
Табличный метод анализа заключается в группировании данных в виде таблиц по определенным признакам.
Графический метод сводится к построению гистограмм ( двухмерных, трехмерных), диаграмм рассеяния и др. графиков.
Применение названных методов рассмотрим на примере. В таблице П 1 представлены данные о несчастных случаях на производстве. Проанализируем первых 50 строк таблицы (Таблица 1)
.
Таблица 1
|
N |
Цех |
Пол |
Возраст |
Квалификация |
Стаж |
t от обучения |
t от нач.смены |
Кол-во дней нетр. |
|
1 |
1 |
1 |
21 |
1 |
1 |
125 |
3,5 |
27 |
|
2 |
1 |
1 |
31 |
3 |
10 |
74 |
5,5 |
3 |
|
3 |
2 |
1 |
28 |
1 |
6 |
82 |
7 |
4 |
|
4 |
2 |
1 |
42 |
3 |
15 |
63 |
6,5 |
11 |
|
5 |
3 |
2 |
38 |
2 |
16 |
98 |
3,5 |
4 |
|
6 |
4 |
2 |
38 |
2 |
15 |
102 |
4 |
5 |
|
7 |
2 |
1 |
25 |
1 |
4 |
142 |
3 |
16 |
|
8 |
1 |
1 |
27 |
2 |
5 |
160 |
5 |
21 |
|
9 |
1 |
2 |
31 |
2 |
8 |
157 |
3 |
12 |
|
10 |
2 |
1 |
27 |
2 |
5 |
110 |
5,5 |
11 |
|
11 |
4 |
1 |
34 |
2 |
8 |
120 |
6 |
3 |
|
12 |
3 |
1 |
28 |
2 |
5 |
147 |
5 |
11 |
|
13 |
1 |
2 |
29 |
3 |
8 |
124 |
5 |
8 |
|
14 |
1 |
1 |
34 |
3 |
11 |
66 |
5 |
6 |
|
15 |
3 |
1 |
28 |
2 |
8 |
88 |
5,5 |
6 |
|
16 |
3 |
1 |
21 |
1 |
1 |
125 |
3,5 |
26 |
|
17 |
2 |
1 |
37 |
5 |
16 |
176 |
4 |
12 |
|
18 |
1 |
2 |
39 |
4 |
14 |
145 |
7 |
6 |
|
19 |
1 |
1 |
44 |
3 |
12 |
163 |
3,5 |
6 |
|
20 |
2 |
2 |
29 |
2 |
8 |
160 |
3 |
13 |
|
21 |
4 |
2 |
26 |
2 |
5 |
94 |
5 |
11 |
|
22 |
4 |
1 |
23 |
1 |
2 |
97 |
6 |
10 |
|
23 |
3 |
1 |
33 |
3 |
10 |
68 |
5 |
7 |
|
24 |
2 |
1 |
48 |
5 |
24 |
163 |
1,5 |
3 |
|
25 |
2 |
1 |
33 |
1 |
4 |
173 |
1,5 |
18 |
|
26 |
1 |
1 |
26 |
2 |
5 |
130 |
5 |
17 |
|
27 |
1 |
1 |
42 |
3 |
16 |
61 |
6,5 |
10 |
|
28 |
1 |
1 |
23 |
1 |
2 |
127 |
2,5 |
13 |
|
29 |
1 |
2 |
24 |
1 |
1 |
84 |
3,5 |
11 |
|
30 |
2 |
1 |
32 |
2 |
4 |
45 |
3,5 |
2 |
|
31 |
3 |
1 |
29 |
2 |
7 |
123 |
3,5 |
12 |
|
32 |
3 |
2 |
32 |
3 |
13 |
115 |
4,5 |
9 |
|
33 |
4 |
1 |
43 |
4 |
23 |
112 |
3 |
1 |
|
34 |
3 |
1 |
34 |
1 |
3 |
42 |
3,5 |
2 |
|
35 |
2 |
2 |
29 |
2 |
6 |
100 |
5 |
13 |
|
36 |
2 |
1 |
43 |
3 |
15 |
167 |
3,5 |
6 |
|
37 |
2 |
1 |
41 |
4 |
21 |
158 |
3,5 |
3 |
|
38 |
1 |
2 |
27 |
2 |
5 |
98 |
5 |
13 |
|
39 |
1 |
1 |
21 |
1 |
1 |
52 |
3 |
2 |
|
40 |
1 |
1 |
52 |
5 |
26 |
170 |
7 |
2 |
|
41 |
1 |
1 |
29 |
3 |
7 |
100 |
5 |
7 |
|
42 |
4 |
2 |
42 |
3 |
15 |
140 |
5 |
3 |
|
43 |
4 |
1 |
29 |
2 |
7 |
78 |
5,5 |
5 |
|
44 |
3 |
2 |
44 |
3 |
17 |
136 |
2 |
3 |
|
45 |
3 |
2 |
30 |
3 |
8 |
125 |
5 |
8 |
|
46 |
3 |
1 |
24 |
1 |
3 |
142 |
3 |
13 |
|
47 |
2 |
2 |
42 |
3 |
15 |
138 |
2 |
3 |
|
48 |
2 |
1 |
31 |
4 |
12 |
97 |
5 |
7 |
|
49 |
1 |
1 |
37 |
4 |
12 |
130 |
7 |
9 |
|
50 |
1 |
1 |
32 |
1 |
2 |
140 |
7,5 |
18 |
Используя групповой метод, проведем классификацию данных и составим таблицы.
1. Номинальная шкала:
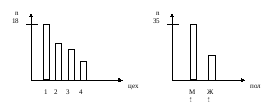
а) распределение несчастных случаев по цехам
Таблица 2
|
Номер цеха |
1 |
2 |
3 |
4 |
|
Кол-во несч. случаев |
18 |
14 |
11 |
7 |
б) распределение несчастных случаев по полу пострадавших
Таблица 3
|
Пол |
Мужчины (1) |
Женщины (2) |
|
Кол-во несч. случаев |
35 |
15 |
в) соответствующая а) и б) комбинационная таблица
Таблица 4
|
Номер цеха |
1
|
2
|
3
|
4
|
|
Пол | ||||
|
Мужчины |
13 |
11 |
7 |
4 |
|
Женщины |
5 |
3 |
4 |
3 |
На основании проведенной классификации можно сделать следующие выводы (по моде распределений):
а) чаще всего несчастные случаи происходят в первом цехе;
б) к несчастным случаям в большей степени предрасположены мужчины.
2. Порядковая шкала:
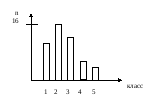
г) распределение несчастных случаев по разряду (классу) пострадавших
Таблица 5
|
Квалификация |
1 |
2 |
3 |
4 |
5 |
|
Кол-во несч. случаев |
12 |
16 |
14 |
5 |
3 |
Вывод: Травмированию подвержены в большей степени рабочие 2 разряда.
Приведенные таблицы можно представить графически
3. Для непрерывной переменной Х (шкала отношений) – «число дней нетрудоспособности»- построим эмпирическую функцию распределения.
Выделим минимальный хmin = х(1) и максимальный хmax = х(n) элементы выборки;
xmin= 1, xmax= 27.
Разобьем область задания случайной величины Х на L интервалов группирования. Для определения числа L интервалов искусственного группирования пользуются эмпирическими формулами
L
=
![]() ,L
≤5 lg
n,
L
= 1 + 3.32lg
n
. (формула
Старджеса). (1)
,L
≤5 lg
n,
L
= 1 + 3.32lg
n
. (формула
Старджеса). (1)
L = 7,07, L ≤ 8,49, L = 6,64.
Возьмем L = 7. Определение ширины интервалов гистограммы (при равноточном группировании)
![]() (2)
(2)
h = (27-1)/ 7= 3,7. Округляя до целого, получаем h = 4.
Для того чтобы x(1) и х(n) попали внутрь соответственно 1-го и L-го интервалов группирования, границы х(1) и х(n) корректируют следующим образом:
x'min = x(1) - h/2,
x'max = x(n) + h/2.
В нашем случае мы выбираем x'min = x(1) . Следовательно, границы интервалов и интервалы будут иметь вид
1, 5, 9, 13, 17, 21, 25, 29; [1,5[, [5,9[, [9,13[, [13,17[, [17,21[, [21,25[, [25-29].
Далее приступаем к заполнению таблицы 6 .
Таблица 6
|
Частичные интервалы |
Рабочее поле для подсчета частот |
Абс. частоты nj |
Плотность частоты, wj=nj/h |
Середины интервалов |
Относ. частоты, W*j=wj/n |
Накоплен-ные частоты F*(x)=Wj h |
|
1 – 5 5 - 9 9 - 13 13 - 17 17 - 21 21 - 25 25 - 29
|
\\\\\\\\\\\\\\ \\\\\\\\\\\\ \\\\\\\\\\\\ \\\\\\ \\\ \ \\ |
14 12 12 6 3 1 2 |
3,5 3 3 1,5 0,75 0,25 0,5
|
3 7 11 15 19 23 27 |
0,07 0,06 0,06 0,03 0,015 0,005 0.01
|
0,28 0,52 0,76 0,88 0,94 0,96 1.00 |
Данные табл. 6 используем для графического изображения выборочного статистического ряда в виде гистограммы плотности частоты wj и относительных частот W*j (рис. 1), либо в виде гистограммы накопленных частот (эмпирической функции распределения) (рис. 2). Это графическое изображение позволяет представить в наглядной форме закономерности, присущие генеральной совокупности.
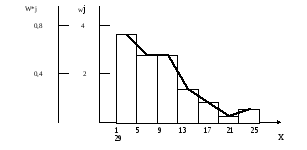
Рис. 1. Гистограммы плотности частоты wj и относительных частот W*j
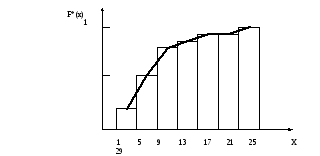
Рис. 2. Гистограмма накопленных частот F*(x)
I I. Вторым этапом обработки статистических данных является получение различных числовых характеристик:
эмпирического среднего, вокруг которого группируются наблюдения;
среднего квадратического отклонению - меры рассеяния наблюдений вокруг эмпирического среднего;
показателя асимметрии As, характеризующего скошенность гистограммы;
показателя эксцесса Es, характеризующего островершинность гистограммы.
Эти характеристики вычисляются с помощью начальных mk и центральных μk эмпирических моментов k-го порядка изучаемой случайной величины X по следующим формулам:
![]() ,
(3)
,
(3)
где k – порядок момента, k = 1, 2, 3, .... Для группированных данных
![]() ,
(4)
,
(4)
где L – количество интервалов группирования, nj - количество элементов выборки, попавших в j интервал, xj – значение случайной величины, равное середине интервала группирования.
Эмпирические центральные моменты порядка k, полученные по негруппированной выборке из генеральной совокупности, равны:
![]() ,
(5)
,
(5)
где k – порядок момента, k = 1, 2, 3, .... Для группированных данных
![]() .
(6)
.
(6)
Начальный момент первого порядка (k = 1)
![]()
называется выборочным средним, выборочным математическим ожиданием, или средним арифметическим значением выборки.
Центральный
момент второго порядка μ2
называется дисперсией
и обозначается
D.
Величина
![]() называетсясреднеквадратическим
отклонением.
Для того, чтобы получить несмещенную
оценку дисперсии, необходимо воспользоваться
выражениями
называетсясреднеквадратическим
отклонением.
Для того, чтобы получить несмещенную
оценку дисперсии, необходимо воспользоваться
выражениями
![]() ,
(7)
,
(7)
![]() ,
(8) соответственно
для негруппированной и группированной
выборок. Среднеквадратическое
отклонение
,
(8) соответственно
для негруппированной и группированной
выборок. Среднеквадратическое
отклонение
![]() .
В практических вычислениях для дисперсии
S2
часто
удобна формула
.
В практических вычислениях для дисперсии
S2
часто
удобна формула
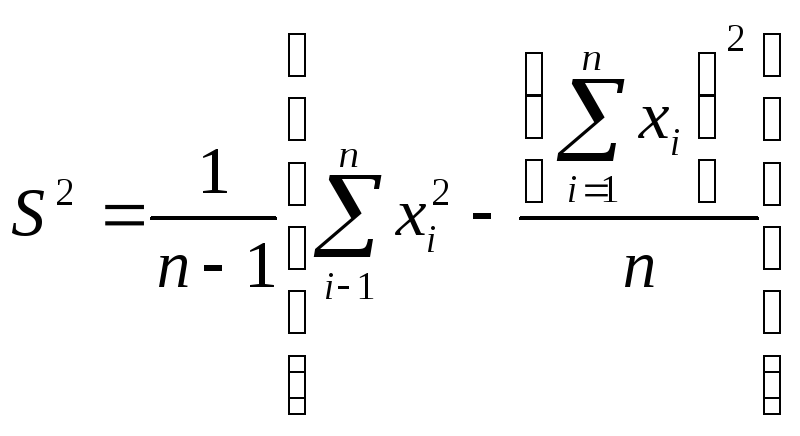
![]() .
(9)
.
(9)
В качестве характеристики формы распределения, отражающей асимметрию распределения, служит коэффициент асимметрии
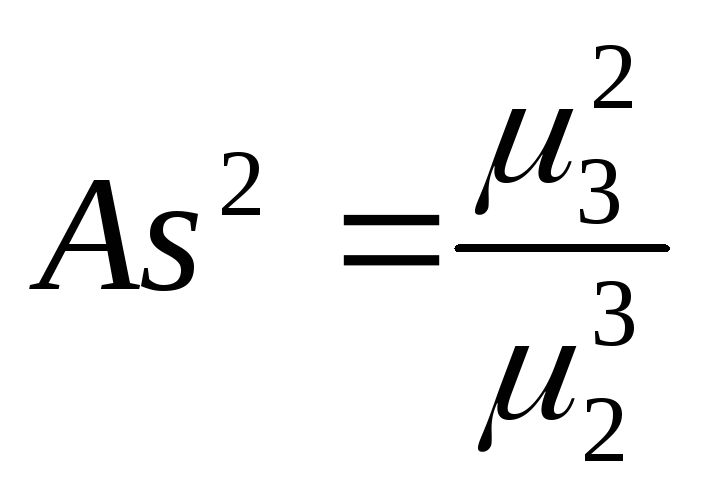 .
(10)
.
(10)
Неприведенный коэффициент эксцесса Es также является характеристикой формы распределения, а именно его островершинности, и определяется выражением
![]() .
(11)
.
(11)
Величина = Es - 3 называется приведенным коэффициентом эксцесса.
В табл. 7 представлены результаты расчета названных выше числовых характеристик для рассматриваемого примера.
Числовые параметры, полученные на основе моментов, являются интегральными характеристиками распределения. Вторая группа параметров характеризует отдельные значения функции распределения. К ним относятся квантили. Квантиль хр (порядка р) случайной величины Х с функцией распределения F(x) называется решение уравнения
F(хp) = p.
Квантили можно получить на основании вариационного ряда, закона распределения дискретной или плотности вероятности непрерывной случайных величин. В нашем примере оценим квантили с использованием гистограммы абсолютных частот.
Таблица 7
|
Числовые характеристики |
Негруппированные данные |
Группированные данные |
|
|
9,04 |
9,64 |
|
S2 |
37,02 |
39,58 |
|
|
6,08 |
6,29 |
|
As |
1,01 |
0,99 |
|
Es |
3,85 |
3,58 |
|
|
0,85 |
0,58 |
Медиану Ме (квантиль уровня р = 0.5 – х0,5) можно получить по следующему алгоритму:
1. Находим медианный интервал. Для определения этого интервала сумму частот делят пополам и на основе последовательного суммирования частот первого, второго и т.д. интервалов находят интервал, где расположена медиана. Для нашей гистограммы
(табл. 6) это второй интервал [5,9[.
2. Приближенное значение Ме в медианном интервале рассчитывается по формуле
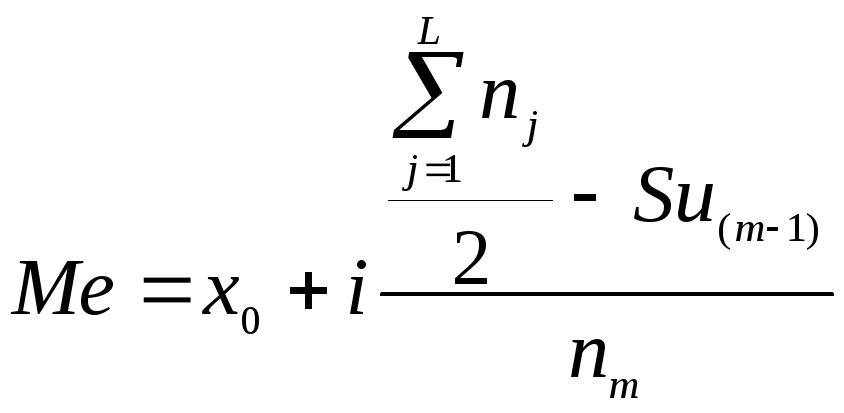 ,
(12)
,
(12)
где х0 – нижняя граница медианного интервала;
i - порядковый номер медианного интервала;
Su(m-1) - сумма накопленных частот в интервалах предшествующих медианному;
nm - частота медианного интервала.
![]() .
(13)
.
(13)
Другие квантили, например 1-я и 3-я квартиль, могут быть получены по приведенному алгоритму с использованием формул
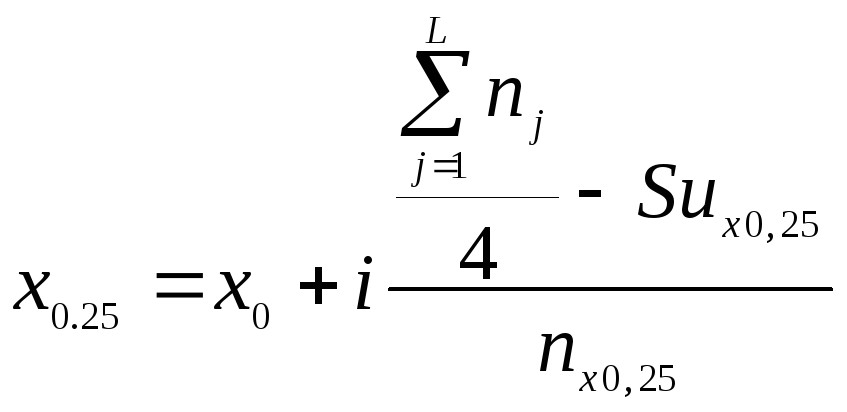 ,
(14)
,
(14)
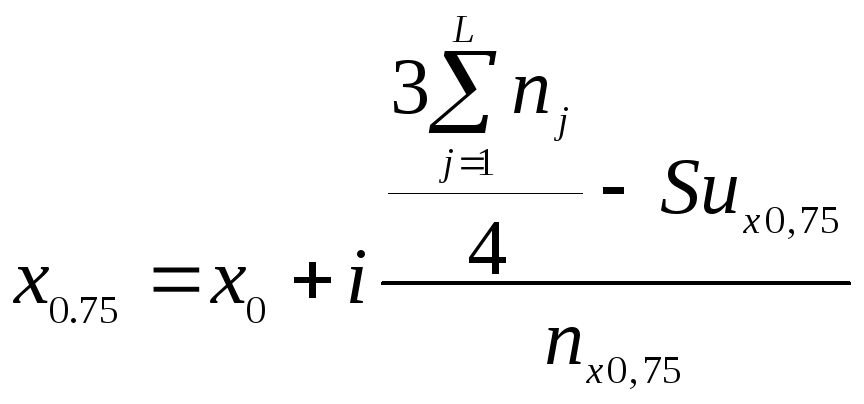 ,
(15)
,
(15)
где х0 – нижняя граница медианного интервала;
i - порядковый номер квартильного интервала;
Suх0.25, Suх0.75, - суммы накопленных частот в интервалах предшествующих квартильным;
nх0,25 , nх0,75 - частоты квартильных интервалов.
В нашем примере
![]()
![]()
Выводы:
а) в результате несчастных случаев на производстве работники нетрудоспособны в среднем 9 дней;
б) распределение числа дней нетрудоспособности имеет правостороннюю асимметрию;
в) половина всех травмированных нетрудоспособны более недели, а 25% более 12 дней.