

Федеральное государственное образовательное бюджетное учреждение
высшего профессионального образования
«Сибирский государственный университет телекоммуникации и
информатики»
(ФГОБУ ВПО «СибГУТИ»)
Факультет информатики и вычислительной техники
Кафедра вычислительных систем
КУРСОВОЙ ПРОЕКТ
по курсу «Параллельные вычислительные технологии»
тема проекта
< Решение двумерного уравнения Пуассона методом
блочных итераций>
Выполнили студенты гр. ИВ-14
Шулбаева Е.И.
Мартынов Г.В.
Принял
_____________________ / А.Д. Рычков /
Оценка ____________________
«_____» ___________________ 2013г.
Новосибирск 2013
СОДЕРЖАНИЕ ЗАДАНИЯ НА РАЗРАБОТКУ ПРОЕКТА
Решение двумерного уравнения Пуассона методом блочных итераций
Необходимо найти численное решение задачи Дирихле для уравнения Пуассона
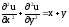 (1)
(1)
в
прямоугольной области
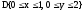 с граничными условиями
с граничными условиями
 (2)
(2)
Для решения поставленной задачи нами была написана параллельная программа на языке программирования высокого уровня С расширением MPI, а также аналогичная программа на OpenMP.
уравнение пуассон параллельная программа
1. Задание Решение двумерного уравнения Пуассона итерационным методом Зейделя
Найти численное решение задачи Дирихле для уравнения Пуассона
 (1)
(1)
в
прямоугольной области
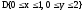 с граничными условиями
с граничными условиями
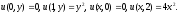 (2)
(2)
1.
Разработайте блок-схему реализации
распараллеливания данного алгоритма
и напишите параллельную программу на
MPI для численного решения уравнения (1)
с условиями (2) с помощью данной итерационной
схемы. Используйте распараллеливание
прогонки (встречная прогонка). Для
хранения сеточной функции используйте
два двумерных массива, целиком
размещающихся в памяти процессоров. В
одном из них размещайте
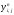 (
(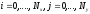 ),
во втором
),
во втором
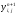 и после его обработки пересылайте все
содержимое массива в предыдущий массив
и после его обработки пересылайте все
содержимое массива в предыдущий массив
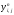 .
Тем самым вы экономите память и имеете
возможность считать до любого значения
n.
.
Тем самым вы экономите память и имеете
возможность считать до любого значения
n.
2. На сетке 50х50 проведите расчеты на разном числе процессоров и постройте зависимость ускорения вычислений и затраты на межпроцессорные обмены в зависимости от числа процессоров. Найдите оптимальное соотношение между числом процессоров и ускорением счета. Эффективность параллельного алгоритма и его отладку следует проводить с использованием средств профилирования, разработанных на кафедре ВС СибГУТИ.
3. Напишите аналогичную программу на OpenMP, проведите расчета на сетке 50х50 и определите коэффициент ускорения вычислений в зависимости от числа потоков.
4.
Постройте график изменения погрешности
 от числа итераций.
от числа итераций.
2. Теоретический материал
Блочный итерационный метод Зейделя
На равномерной прямоугольной сетке уравнение (1) аппроксимируется следующей разностной схемой
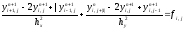 (4)
(4)
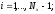
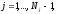
где
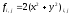 ,
n - номер итерации.
,
n - номер итерации.
Значения сеточной функции на границах области известно из граничных условий. Схему (4) можно записать в виде, удобном для реализации ее с помощью метода скалярной прогонки:
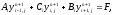 где
где
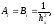

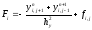
Значения прогоночных коэффициентов находятся по рекуррентным формулам, которые можно записать в виде:
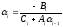 ,
,
 ,
,
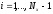 .
.
Из
граничных условий на левой границе
определяются значения прогоночных
коэффициентов
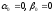 .
.
После
этого, учитывая, что
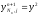 ,
обратной прогонкой находятся все
значения сеточной функции на n+1 - ом
итерационном шаге:
,
обратной прогонкой находятся все
значения сеточной функции на n+1 - ом
итерационном шаге:

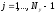
Счет
следует проводить прогонкой по оси ОХ
(индекс i), начиная с индекса j = 1. В этом
случае значение переменной
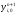 известно из граничного условия. Окончанием
итерационного процесса является
выполнение условия
известно из граничного условия. Окончанием
итерационного процесса является
выполнение условия
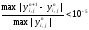
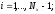
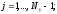
В качестве начальных значений для внутренних точек области можно взять, например, результаты линейной интерполяции между границами и этими точками.
3. Реализация поставленной задачи
3.1 Блок-схема алгоритма

3.2 Параллельная программа
#include <stdio. h>
#include <stdlib. h>
#include <math. h>
#include <mpi. h>
#define N1 50
#define N2 50
#define eps 0.00001
double Y [N1 + 1] [N2 + 1], Ysh [N1 + 1] [N2 + 1];
double hx = 1. f / N1, hy = 2. f / N2;
/*Функия точного решения*/
double Fresh (double x, double y) {
return pow (x,
2) * pow (y,
2);
}
double RoFresh (double x, double y) {
return 2 * (pow (x,
2) + pow (y,
2));
}
/*Подпрограмма инициализации матрицы*/
void Inic () {
int i, j;
for (i = 0; i < N1 + 1; i++)
for (j = 0; j < N2 + 1; j++) {
if ( (i! = 0) && (j! = 0) && (i! = N1) && (j! = N2))
Y [i] [j] = 0;
else
Y [i] [j] = Fresh ( (i * hx), (j * hy));
}
}
int main (int argc, char **argv) {
int size, rank, flag = 1;
int i, j, f, it = 0;
double A = pow (hx,
2),B = A, D = pow (hy,
2), C = - 2. f / A - 2. f / D, F1, Fi, pogr = 0;
double t_c = 0.0, time = 0.0, s_t = 0.0;
double max, m;
double alfa [N-1], beta [N-1];
// double Y [N1 + 1] [N2 + 1], Ysh [N1 + 1] [N2 + 1];
// double hx = 1. f / N1, hy = 2. f / N2;
MPI_Status stat;
MPI_Init (&argc, &argv);
MPI_Comm_size (MPI_COMM_WORLD, &size);
MPI_Comm_rank (MPI_COMM_WORLD, &rank);
time - = MPI_Wtime ();
t_c - = MPI_Wtime ();
if (rank == 0) {
printf ("%d \n", size);
Inic ();
}
MPI_Barrier (MPI_COMM_WORLD);
MPI_Bcast (Y, (N1 + 1) * (N2 + 1), MPI_DOUBLE, 0, MPI_COMM_WORLD);
if (rank == 0) {
do {
for (i = 0; i <= N1; i++)
for (j = 0; j <= N2; j++)
Ysh [i] [j] = Y [i] [j];
for (i = 1; i <= (N1 - 1) / size; i++) {
for (j = 1; j < N2; j++) {
Fi = ( - (Y [i+1] [j] + Y [i] [j+1])) / D + RoFresh;
}
}
for (i = 0; i <= (N - 1); i++) {
alfa += ( - D [i]) / (C [i] + Ai*alfa [i-1]);
beta += (F [i] - A [i] *beta [i-1]) / (C [i] + Ai*alfa [i-1]);
}
for (j = (N+1); j <= 1; j--)
Ysh += alfa [i] *Y [i+1] [j] + beta [i];
if (size == 1) {
do {
for (i = 1; i < N1; i++) {
for (j = 1; j < N2; j++) {
Fi = ( - (Y [i+1] [j] + Y [i] [j+1])) / D + RoFresh;
}
}
max = m = - 999;
for (i = 0; i <= N1; i++) {
for (j = 0; j <= N2; j++) {
pogr = fabs (Ysh [i] [j] - Y [i] [j]);
if (pogr > max) max = pogr;
pogr = fabs (Ysh [i] [j]);
if (pogr > m) m = pogr;
}
}
if (max / m < eps) {
t_c += MPI_Wtime ();
printf ("Bce 4etKo!!!! it = %d, time = %f\n", it,t_c);
flag = 0;
}
// Перезапись данных
for (i = 1; i < N1; i++)
for (j = 1; j < N2; j++)
Y [i] [j] = Ysh [i] [j];
it++;
} while (flag);
exit (1);
} else {
s_t - = MPI_Wtime ();
// Посылка следующему процессору верхнюю строку из основной матрицы в нижнюю границу
MPI_Send (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, 1, 1, MPI_COMM_WORLD);
MPI_Recv (&Y, (N1 + 1) * (N2 + 1), MPI_DOUBLE, 1, 1, MPI_COMM_WORLD, &stat);
s_t += MPI_Wtime ();
}
} while (1);
}
if ( (rank > 0) && (rank < size - 1)) {
do {
MPI_Recv (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank - 1, 1, MPI_COMM_WORLD, &stat);
for (i = (N1 - 1) / size * rank + 1; i < (N1 - 1) / size * (rank + 1) + 1; i++) {
for (j = 1; j < N2; j++) {
Fi = ( - (Y [i+1] [j] + Y [i] [j+1])) / D + RoFresh;
}
}
s_t - = MPI_Wtime ();
MPI_Send (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank - 1, 1, MPI_COMM_WORLD);
MPI_Send (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank + 1, 1, MPI_COMM_WORLD);
MPI_Recv (&Y, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank + 1, 1, MPI_COMM_WORLD, &stat);
s_t += MPI_Wtime ();
} while (1);
}
if ( (rank == size - 1) && (rank! = 0)) {
do {
s_t - = MPI_Wtime ();
MPI_Recv (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank - 1, 1, MPI_COMM_WORLD, &stat);
s_t += MPI_Wtime ();
// for (i = (N1-1) / size * (size - 1) + 1; i < N1; i++) {
for (i = (N1-1) / size * rank + 1; i < N1; i++) {
for (j = 1; j < N2; j++) {
Fi = ( - (Y [i+1] [j] + Y [i] [j+1])) / D + RoFresh;
}
}
max = m = - 999;
for (i = 0; i <= N1; i++) {
for (j = 0; j <= N2; j++) {
pogr = fabs (Ysh [i] [j] - Y [i] [j]);
if (pogr > max) max = pogr;
pogr = fabs (Ysh [i] [j]);
if (pogr > m) m = pogr;
}
}
if (max / m < eps) {
time += MPI_Wtime ();
printf ("Bce 4etKo!!!! it = %d, time = %f, s_t = %f, time_s4eta = %f \n", it, time, s_t, time-s_t);
exit (1);
}
s_t - = MPI_Wtime ();
MPI_Send (&Ysh, (N1 + 1) * (N2 + 1), MPI_DOUBLE, rank - 1, 1, MPI_COMM_WORLD);
s_t += MPI_Wtime ();
// Перезапись данных
for (i = 0; i <= N1; i++)
for (j = 0; j <= N2; j++)
Y [i] [j] = Ysh [i] [j];
it++;
} while (1);
}
MPI_Finalize ();
return 0;
}
OpenMP
#include <iostream>
#include <vector>
#include <cmath>
#include <stdio.h>
#include <cstdlib>
//#include <mpi.h>
#include <cstring>
float f(float x, float y){
return 2*(pow(x,2)+pow(y,2));
}
int main(int argc, char **argv){
float x=1,y=2;
int N=6;
float hx=x/((float)N-1),hy=y/((float)N-1);
//float U[][5]={{0,0,0,0,0},{0,0.015,0.06,0.14,0.25},{0,0.06,0.25,0.56,1},{0,0.14,0.56,1.26,2.25},{0,0.25,1,2.25,4}},V[N][N];
float U[N][N],V[N][N];
float A,B,C,F[N];
A=B=1/pow(hx,2);
C=-(2/pow(hx,2))-(2/pow(hy,2));
float alpha[N],betta[N];
//краевые уÑловиÑ
for(int j=0;j<N;j++){
U[0][j]=0;
U[N-1][j]=pow((y/(N-1)*j),2);
}
for(int i=0;i<N;i++){
U[i][0]=0;
U[i][N-1]=4*pow((x/(N-1)*i),2);
}
//интерполируем начальные уÑловиÑ
for(int i=1;i<N-1;i++){
for(int j=1;j<N-1;j++){
U[i][j]=U[i][N-1]/(N-1)*j;//(pow((x/(N-1)*i),2)*pow((y/(N-1)*j),2));
}
}
/*int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Status status;*/
std::cout.setf(std::ios::fixed);
std::cout.precision(4);
for(int i=0;i<N;i++){
for(int j=0;j<N;j++){
std::cout<<U[i][j]<<"\t";
}
std::cout<<std::endl;
}
std::cout<<std::endl;
memset(V,0,N*N);
alpha[0]=0;
betta[0]=0;
for(int i=1;i<N;i++){
alpha[i]=-(B/(C+A*alpha[i-1]));
}
float max=0,temp;
int i,j;
clock_t time;
time = clock();
int k=0;
do{
max=0;
for(i=0;i<N;i++){
for(j=0;j<N;j++){
V[i][j]=U[i][j];
}
}
#pragma omp parallel for private(i,j,F)
for(i=N-2;i>0;i--){
for(j=N-2;j>0;j--){
F[j]=-(V[i][j+1]+V[i][j-1])/pow(hy,2)+f((x/(N-1)*i),(y/(N-1)*j));
betta[i]=(F[j]-A*betta[i-1])/(C+A*alpha[i-1]);
U[i][j]=alpha[i]*U[i+1][j]+betta[i];
}
}
for(i=0;i<N;i++){
for(j=0;j<N;j++){
temp=fabs(V[i][j]-U[i][j]);
if(temp>max)
max=temp;
}
}
/*std::cout<<U[3][3]-(pow((x/(N-1)*3),2)*pow((y/(N-1)*3),2))<<" "<<k<<std::endl;
k++;*/
}while(max>0.00001);
for(int i=0;i<N;i++){
for(int j=0;j<N;j++){
std::cout<<U[i][j]<<"\t";
}
std::cout<<std::endl;
}
time = clock() - time;
printf("time=%f", (double)time/CLOCKS_PER_SEC);
}
3.3 Анализ работы программы на разном числе процессоров
Полученные результаты вычислений сведены в таблицу 1.
Таблица 1
|
N |
Time |
Time_calc |
Time_send |
|
2 |
3,986459 |
0,094489 |
3,89197 |
|
4 |
4,5573 |
0,070866 |
4,557351 |
|
6 |
5,98042 |
0,063107 |
6,043527 |
|
8 |
8,343723 |
0,061649 |
8,405372 |
На основе результатов вычислений был построен следующий график, изображенный на рисунке 1.
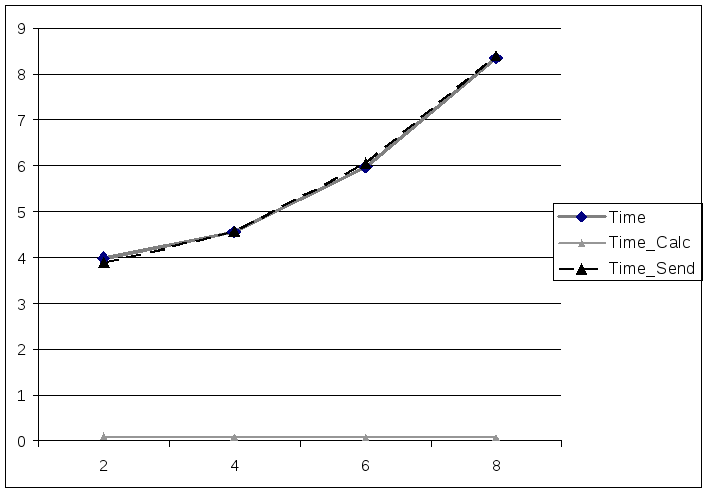
Рисунок 1 - Зависимость вычисления и передачи от числа процессоров