

1.10 Эффективность индексированных файлов
Пусть блок главного файла максимально вмещает E записей. Тогда в худшем случае блок будет вмещать e равное (E+1)/2 записей. Эта ситуация складывается при делении блока при вставке новой записи. Аналогично если блок индекса максимально вмещает D, тогда в худшем случае он будет содержать d равное (D+1)/2 записей. Если в файле содержится n записей, то можно сделать следующие выводы об эффективности индексированных файлов.
При двоичном поиске в индексированном файле потребуется 2+Log2(n/de) обращений к диску. Где n/de – максимальное количество блоков в индексе (логарифм из эффективности двоичного поиска). Еще два обращения для чтения и записи блока основного файла. При интерполирующем поиске потребуется 3+Log2Log2(n\de) обращений к диску.
1.11 Плотное индексирование
Индексирование, рассмотренное выше, называется разреженным индексированием. Существует другой вид индексирования широко распространенный в реальных СУБД – плотное индексирование. В этом случае индексные файлы содержат пары вида (v,p), где первый элемент – значение ключа, а второй – адрес записи в основном файле с этим ключом. Такой подход не требует обязательного упорядочивания записей по индексируемому полю, а так же не обязательна уникальность ключа. Поэтому подход плотного индекса применим для ускорения поиска по любым полям, позволяя построить несколько независимых индексов.
При организации таких файлов скорость доступа будет 2+время поиска в файле индекса.
1.12 B-деревья
При увеличении числа блоков, занятых индексом в разреженных индексированных файлах, снижается эффективность работы. Структура, называемая В–деревом, позволяет избежать такого снижения путем построения индекса для индекса, и при необходимости далее, пока верхний индекс не будет помещаться в один блок. Таким образом, получается иерархическая структура индексов - рисунок 10.
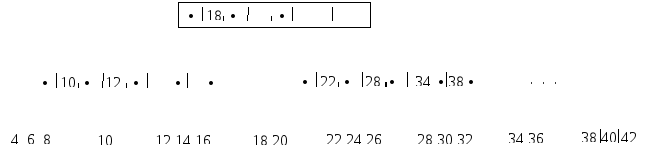
Рисунок 10 – В-дерево степени 5
В В-дереве узел может иметь много сыновей (на практике до тысячи). Количество сыновей (максимальное) определяет степень В-дерева.
Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х.
При организации В–деревьев не должно быть узлов, заполненных меньше, чем наполовину. Структура В–дерева отличается от простой иерархии индексов следующим соглашением: в индексных блоках В–деревьев значения ключей в первой записи пропускаются. При поиске полагают, что все значения, меньшие второго значения в индексе, покрываются отсутствующим первым значением ключа.
1. 13 Операции на в-деревьях.
Поиск.
Пусть необходимо найти запись со значением ключа V. При этом нужно найти путь от корня дерева до конкретного листа, в котором должна находиться запись v, если она существует в файле. Поиск начинается с корня дерева и продолжается по иерархии индексов, выстраивая путь.
Пример.
Текущий узел=корень.
While текущий узел не лист
Begin
Путь=Путь + Текущий узел
Адрес = адрес из записи, покрывающей значение v.
Текущий узел=извлечь блок(адрес)
end;
Путь=Путь + Текущий узел
В результате текущий блок является блоком основного файла, поэтому искомая запись со значением v ищется в нем.
Модификация.
Если модификация затрагивает первичный ключ, то необходимо выполнить операции удаления и вставки.
Если модифицируются не ключевые атрибуты, то выполняется операция поиска, после чего вносятся изменения в поля записи, и блок перезаписывается на диск.
Вставка.
Изначально необходимо найти блок В, в котором должна располагаться новая запись. Если В содержит меньше, чем 2е-1 записей, то запись размещается в блоке так, чтобы не нарушить сортировку. Очевидно, что новая запись не будет первой записью блока, кроме случая самого левого блока. Следовательно, нет необходимости изменять значения ключей в индексных блоках по иерархии.
Если в блоке уже 2е-1 записей, то в файле выделяется новый блок В1 и все записи блока В делятся поровну между блоками В и В1 (первые е записей остаются в блоке В, остальные переносятся в В1). При начальном поиске уже был найден путь от корня до блока В1. Теперь необходимо повторить процедуру вставки для всех блоков в обратном направлении к корню для регистрации блока В1 в индексах. В результате на определенном уровне индексный блок также может разделиться, если до вставки в нем уже было 2d-1 записей. Процесс разделения блоков может затронуть и корневой блок, в этом случае увеличивается количество уровней иерархии, так как в корне дерева должен лежать только один блок.
Удаление.
При удалении необходимо найти блок В, в котором содержится запись v. Если после удаления в блоке осталось е или более записей, то после удаления найденной записи и сдвига всех остальных операция закончена.
Если удаляемая запись является первой в блоке, то необходимо изменить значения в блоках в направлении обратном найденному пути. При этом необходимо учитывать следующее. Если В первый потомок своего предка, то предок не включает значения для ключа первой записи блока В. В этом случае нужно проверить предка предка и так далее, пока не найдется блок-предок А1 для В, такой что, А1 – не первый потомок своего предка А2. Тогда новое меньшее значение ключа блока В записывают в блок А2 вместе с адресом блока А1.
Если после удаления блок В содержит е-1 запись, то необходимо найти блок В1, имеющий того же родителя, что и В и расположенный непосредственно слева или справа от В. Если блок В1 содержит более е записей, то необходимо перераспределить записи блоков В и В1 поровну с сохранением порядка. Далее необходимо внести изменения в записи общего предка. Если в блоке В1 содержится только е записей, то блоки В и В1 должны быть объединены. После этого в общем предке В и В1 при необходимости изменяется информация о блоке В1 и удаляется информация о блоке В. Если в предке В1 оказывается d записей, то необходимо повторить ту же операцию, но уже на индексных блоках. В результате выполнения таких действий с блоками пути, построенного в результате поиска, возможно уменьшение числа уровней индексов.