

26.Рассмотрите методы оптимального кодироваия (сжатия информации). Опишите алгоритм метода Шенона-Фано.
27.Рассмотрите
методы оптимального кодирования (сжатия
информации). Опишите алгоритм метода
Хаффмана. Оптимальным
статистическим (экономным) кодированием наз-ся
кодирование, при к-ом обеспечивается
распределение времени на передачу
отдельных символов
алфавита в
зависимости от априорных вероятностей их
появления:
 ;
(1), где Cп - пропускная
способность канала;
pi -
априорная вероятность i–й
кодовой комбинации; ti -длительность
i-й кодовой комбинации.
Оптимальными
неравномерными кодами (ОНК) – наз-ся
коды, в к-ых символы алфавита
кодируются кодовыми словами мин средней
длины. Принципы
построения оптимальных кодов: 1.
Каждая кодовая комбинация должна
содержать мах кол-во
инф-ции,
что обеспечивает мах скорость передачи
данных. 2. Символам первичного
алфавита, имеющим наибольшую вероятность
появления в сообщении, присваиваются
более короткие кодовые слова, при этом,
средняя длина кодовых комбинаций имеет
мин-возможную длину. При
таком кодировании избыточность кода,
к-ая вызвана неравной вероятностью символов
алфавита, сводится к минимуму (практически
к нулю). Оптимальные коды явл-ся
неравномерными блочными кодами, при их
построении необх обеспечить однозначность
декодирования. Префиксным (неприводимым)
– наз-ся код, в к-ом ни одна кодовая
комбинация не явл-ся началом другой.
Для обеспечения этого св-ва кодовые
комбинации должны записываться от корня
кодового дерева. Возможность
однозначного декодирования неравномерного
кода обеспечивается выполнением
требования разделимости (префиксности)
кодовых комбинаций. При
неравномерном кодировании производится сжатие
данных. Сжатие
данных используется
как при хранении данных в памяти, так и
при их передаче. Оптимальное кодирование
можно использовать только в каналах
без помех или в случае низкой
требовательности к достоверности
передаваемой информации. Сущ-ет много
методов оптимального, статистического
кодирования. Наиболее часто используют
оптимальное кодирование по методу
Шеннона - Фано и Хаффмена. Кодирование по
методу Хаффмена осуществляется следующим
об-разом:
1. Все подлежащие кодированию
символы записываются в порядке убывания
их априорных вероятностей. Если нек-ые
символы имеют одинаковые вероятности,
то их распо-лагают рядом в произвольном
порядке. 2. Выбирают символы с мин
вероятностями по 2 и одному приписывают
0, а другому 1. 3.
Выбранные символы объединяют в
промежуточные символы с суммарной
вероятностью. 4. Снова находят пару
символов с наимен вероятностями и
поступают аналогично. В таблице 2 приведен
пример кодирования по методу Хаффмена
для источника сообщений с заданными
вероятностями символов алфавита: x1 =
0,4; x2 =
x5 =
0,2; x3 =
0,1; x4 =
x6 =
0,05.
Таблица 2
;
(1), где Cп - пропускная
способность канала;
pi -
априорная вероятность i–й
кодовой комбинации; ti -длительность
i-й кодовой комбинации.
Оптимальными
неравномерными кодами (ОНК) – наз-ся
коды, в к-ых символы алфавита
кодируются кодовыми словами мин средней
длины. Принципы
построения оптимальных кодов: 1.
Каждая кодовая комбинация должна
содержать мах кол-во
инф-ции,
что обеспечивает мах скорость передачи
данных. 2. Символам первичного
алфавита, имеющим наибольшую вероятность
появления в сообщении, присваиваются
более короткие кодовые слова, при этом,
средняя длина кодовых комбинаций имеет
мин-возможную длину. При
таком кодировании избыточность кода,
к-ая вызвана неравной вероятностью символов
алфавита, сводится к минимуму (практически
к нулю). Оптимальные коды явл-ся
неравномерными блочными кодами, при их
построении необх обеспечить однозначность
декодирования. Префиксным (неприводимым)
– наз-ся код, в к-ом ни одна кодовая
комбинация не явл-ся началом другой.
Для обеспечения этого св-ва кодовые
комбинации должны записываться от корня
кодового дерева. Возможность
однозначного декодирования неравномерного
кода обеспечивается выполнением
требования разделимости (префиксности)
кодовых комбинаций. При
неравномерном кодировании производится сжатие
данных. Сжатие
данных используется
как при хранении данных в памяти, так и
при их передаче. Оптимальное кодирование
можно использовать только в каналах
без помех или в случае низкой
требовательности к достоверности
передаваемой информации. Сущ-ет много
методов оптимального, статистического
кодирования. Наиболее часто используют
оптимальное кодирование по методу
Шеннона - Фано и Хаффмена. Кодирование по
методу Хаффмена осуществляется следующим
об-разом:
1. Все подлежащие кодированию
символы записываются в порядке убывания
их априорных вероятностей. Если нек-ые
символы имеют одинаковые вероятности,
то их распо-лагают рядом в произвольном
порядке. 2. Выбирают символы с мин
вероятностями по 2 и одному приписывают
0, а другому 1. 3.
Выбранные символы объединяют в
промежуточные символы с суммарной
вероятностью. 4. Снова находят пару
символов с наимен вероятностями и
поступают аналогично. В таблице 2 приведен
пример кодирования по методу Хаффмена
для источника сообщений с заданными
вероятностями символов алфавита: x1 =
0,4; x2 =
x5 =
0,2; x3 =
0,1; x4 =
x6 =
0,05.
Таблица 2
|
Символ |
pi |
Граф кода Хаффмена |
Код |
|
x1 x2 x5 x 3 x 4 x 6 |
0,4 0,2 0,2 0,1 0,05 0,05 |
1 (1,0) 1 0 (0,6) 1 0 (0,4) 1 0 (0,2) 1 0 (0,1) 0 |
1 01 001 0001 00001 00000 |
 Энтропия источника
равна
Энтропия источника
равна
 Средняя
длина кодовой комбинации данного
кода
Средняя
длина кодовой комбинации данного
кода Длина
кодовой комбинации примитивного кода
определяется соотношением
Длина
кодовой комбинации примитивного кода
определяется соотношением (7)
Округляя
до ближайшего целого в большую сторону,
получим l = 3.
Эффективность
ОНК максимальна, если
(7)
Округляя
до ближайшего целого в большую сторону,
получим l = 3.
Эффективность
ОНК максимальна, если ![]() .
Коэф-т
отн-ной эффективности равен
.
Коэф-т
отн-ной эффективности равен
 . Коэф-т
статистического сжатия равен
. Коэф-т
статистического сжатия равен
 .
Неравно-мерный код можно передавать
блоками заданной длины, а на приемной
стороне декодировать всю последовательность.
.
Неравно-мерный код можно передавать
блоками заданной длины, а на приемной
стороне декодировать всю последовательность.
28.Опишите алгоритм арифметического кодирования. Ариф кодирование (Arithmetic coding) — алгоритм сжатия информации без потерь, к-ый при кодировании ставит в соответствие тексту вещественное число из отрезка [0;1). Данный метод (как и алгоритм Хаффмана) является энтропийным т.е. длина кода конкретного символа зависит от частоты встречаемости этого символа в тексте. Ариф кодирование показывает более высокие результаты сжатия, чем алгоритм Хаффмана, для данных с неравномерными распределениями вероятностей кодируемых символов. Кроме того, при ариф кодировании каждый символ кодируется нецелым числом бит, что эффективнее кода Хаффмана (теоретически символу a с вероятностью появления p(a) допустимо ставить в соответствие код длины –log2p(a), следовательно при кодировании Хаффманом это достигается только с вероятностями, равными обратным степеням двойки). Кодирование. Алгоритму передаются текст для кодирования и список частот встречаемости символов.
Рассм отрезок [0;1) на координатной прямой.
Поставим каждому символу текста в соответствие отрезок, длина которого равна частоте его появления.
Считаем символ из входного потока и рассмотрим отрезок, соответствующий этому символу. Этот отрезок разделим на части, пропорциональные частотам встречаемости символов.
Повторим пункт (3) до конца входного потока.
Выберем любое число из получившегося отрезка. Это и будет результат арифметического кодирования.
При арифметическом кодировании длина кодового слова не превышает энтропии исходного текста.
Размер
сообщения 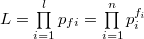 (
(![]() -
длина текста;
-
длина текста;![]() -
размер алфавита;
-
размер алфавита;![]() -
частота встречаемости символа;
-
частота встречаемости символа;![]() -
вероятность вхождения символа)
-
вероятность вхождения символа)
Число
бит в закодированном тексте: 