

Теория кодирования
.pdfОГЛАВЛЕНИЕ
Введение……………………………………………………………4
1.Основные понятия………………………………………………5
2.Критерий однозначности декодирования…...………………...6
3.Оптимальный код…………….………………………………..14
4.Самокорректирующийся код………………………………….21
5.Задачи и упражнения……….………………………………….27 Заключение………………………………………………………..35 Персоналии………………………………………………………..36 Список литературы…………………………………………….....38
3
«Язык дан для того, чтобы скрывать свои мысли»
Народная мудрость
Введение
Вопросы кодирования издавна играли заметную роль в математике:
1)десятичная позиционная система исчисления – это универсальный способ кодирования чисел, в том числе натуральных;
2)римские цифры – другой способ кодирования небольших натуральных чисел;
3)декартовы координаты – способ кодирования геометрических объектов числами.
Ранее средства кодирования играли вспомогательную роль и не рассматривались как отдельный предмет математического изучения. Как раздел математики, имеющий кодирование объектом исследования, теория кодирования возникла в 40-х годах XX века после работ К. Шеннона.
В современном понимании кодирование изучает способы представления информации любого рода.
Основные требования, предъявляемые к кодированию:
1)существование декодирования, или однозначность кодирования;
2)помехоустойчивость, или исправление ошибок;
3)заданная сложность (или простота) кодирования и
декодирования.
Рассмотрению этих задач посвящено данное пособие.
4

1. Основные понятия
Пусть имеются два алфавита: A {a1, a2 ,...am} – кодируемый и B {b1,b2 ,...bk } – кодирующий.
Символами алфавитов могут быть буквы, цифры или иные знаки, например, точки и тире. Не умаляя общности, символы алфавитов будем называть буквами.
|
Словом в алфавите |
A называется |
любая |
последовательность |
|||||||||||
букв этого алфавита: ai |
ai |
ai |
...ai . Словом в алфавите B называется |
||||||||||||
|
|
|
|
1 |
2 |
3 |
s |
|
|
|
|
|
|
|
|
любая |
|
последовательность |
букв |
этого |
алфавита bi |
bi |
bi ...bi |
. |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
p |
Множество слов алфавитов A и B обозначим ɱ ( A) и ɱ (B) . |
|
|
|||||||||||||
|
Кодированием называется отображение |
множества ɱ( A) на |
|||||||||||||
множество |
ɱ(B) . Кодом |
слова |
ai |
ai |
ai |
...ai |
называется |
слово |
|||||||
|
|
|
|
|
|
|
|
1 |
2 |
3 |
s |
|
|
|
|
ai |
ai |
ai |
...ai |
, принадлежащее ɱ(B) . |
|
|
|
|
|
|
|
|
|||
1 |
2 |
3 |
s |
|
|
|
|
|
|
|
|
|
|
|
|
Мы будем рассматривать алфавитное (буквенное) кодирование. При алфавитном кодировании задается код каждой буквы алфавита A, который называется кодовым словом:
ai |
Bi , i |
1, 2, |
...m, |
Bi |
ɱ(B) , Bi |
Bj , если i j . |
||
Тогда |
кодом |
слова |
ai |
ai ...ai |
ɱ( A) будет последовательность |
|||
|
|
|
1 |
2 |
s |
|
|
|
кодовых слов |
ai |
ai ... |
ai |
Bi |
Bi ...Bi . |
|||
|
|
1 |
2 |
|
s |
1 |
2 |
s |
Набор кодовых слов K |
|
B1, B2 ,...Bm |
называется кодом. |
|||||
Код называется взаимно однозначным или однозначно декодируемым, если коды любых двух различных слов будут различны, иными словами, код будет взаимно-однозначным, если
ai |
...ai |
bj |
...bj |
можно однозначным образом разбить на кодовые |
||||
1 |
s |
1 |
n |
|
|
|
|
|
слова, то есть представить bj |
...bj |
в виде Bi |
, Bi ...Bi . |
|||||
|
|
|
|
1 |
n |
1 |
2 |
s |
|
Пример 1. Алфавит B |
0,1 , алфавит A |
a1, a2 , a3 , |
|||||
a1 |
0, |
a2 |
01, a3 |
10, то есть K |
0,01,10 . |
|||
|
Пусть a2a3a1 |
– слово в алфавите A, |
a2a3a1 |
01100 . По этому |
||||
коду исходное слово восстанавливается однозначно: первым кодовым словом может быть только 01 (0 не может быть кодовым словом, так
5

как нет кодового слова 1, или 11, или 110), тогда вторым кодовым словом может быть только 10 и, наконец, 0 – код буквы a1 .
Рассмотрим в алфавите |
B слово 010, его можно разбить на |
кодовые слова двумя способами как B1B3 или B2 B1 , то есть коды двух |
|
разных слов a1a3 и a2a1 |
совпали. Кодирование, заданное таким |
набором кодовых слов, хотя сами кодовые слова разные, не является однозначным.
2. Критерий однозначности декодирования
Определение. |
Префиксом |
слова |
c1 c2 ...ck |
называется |
любая |
|||||
последовательность |
c1 c2 ...cp , |
где |
p |
k . |
Префикс |
называется |
||||
собственным, если p |
k . |
|
|
|
|
|
|
|
|
|
Определение. |
Суффиксом |
слова |
c1 c2 ...ck |
называется |
любая |
|||||
последовательность |
cq cq |
1 ...ck , где |
q |
1, |
суффикс |
называется |
||||
собственным, если q |
1. |
|
|
|
|
|
|
|
|
|
Рассмотрим |
M |
{ } |
– множество |
собственных |
префиксов и |
|||||
собственных суффиксов кодовых слов, которые сами не являются кодовыми словами. Если M , тогда существуют кодовые слова Bi
и Bj |
и непустые слова Br и Bs , принадлежащие ɱ B , |
такие что |
||
Bi |
Br и Bj |
Bs . |
|
|
Кодированию |
сопоставим ориентированный граф G |
V , E , |
||
где V |
M |
, |
–пустое слово (слово без букв), M { 1, |
2 ,... p } – |
множество собственных префиксов и собственных суффиксов
кодовых |
слов. |
|
Пара |
|
i |
j |
E |
тогда и |
только |
тогда, |
когда |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
существуют |
кодовые |
слова |
|
Bi |
, Bi |
,...Bi |
s |
0 |
, такие |
что |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
s |
|
|
|
|
i Bi Bi |
...Bi |
j |
– |
|
кодовое |
слово. |
При |
этом |
на |
s |
накладываются |
|||||||
1 |
2 |
s |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
следующие ограничения: |
|
|
|
|
|
|
|
|
|
|
||||||||
1) |
если |
i |
|
|
и |
j |
|
, тогда s |
0 ; |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
2) |
если |
i |
|
|
или |
j |
, тогда |
s |
1; |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
3) |
если |
i |
|
j |
|
, тогда s |
|
2. |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
6
Теорема (критерий однозначности декодирования).
Кодирование будет взаимно однозначным тогда и только тогда, когда в графе G нет ориентированных циклов, проходящих
через вершину .
Доказательство.
1.Пусть в графе G нет ориентированных циклов через вершину
,покажем, что кодирование взаимно однозначное.
Предположим противное: существуют слова, которые неоднозначно декодируются, то есть неоднозначно разбиваются на кодовые слова. Среди всех неоднозначно декодируемых слов
выберем самое короткое слово B ɱ B и рассмотрим два разных разбиения его на кодовые слова.
|
|
|
|
|
|
|
|
|
Рис. 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
На рис.1 сверху показано одно разбиение слова |
B на кодовые |
||||||||||||||||||
|
|
|
|
||||||||||||||||
слова, снизу другое. |
Точки сечений не совпадают, так как B самое |
||||||||||||||||||
короткое слово, |
1, |
2 , 3, 4 , 5 – собственные префиксы и суффиксы |
|||||||||||||||||
кодовых слов. Тогда в графе G существует орцикл через вершину . |
|||||||||||||||||||
Действительно, |
из |
|
идет дуга в |
1 , так как существует кодовое |
|||||||||||||||
слово Bj1 |
Bi1 |
1 , из 1 |
в |
2 |
идет дуга, так как существует кодовое |
||||||||||||||
слово Bi |
|
1Bj |
2 , из |
2 идет дуга в |
3 , так как существует кодовое |
||||||||||||||
|
2 |
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
слово |
Bj |
2 Bi 3 , |
из |
3 |
в |
|
4 идет |
дуга, |
так |
как |
кодовое |
слово |
|||||||
|
|
3 |
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bi |
3 |
4 |
(в этом |
случае |
s |
0 ), |
из |
4 |
в |
5 идет дуга: |
слово |
||||||||
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bj |
4 |
5 , |
наконец, |
из |
5 |
в |
|
идет дуга, так как существует слово |
|||||||||||
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bi |
5 Bj Bj . |
Найдя орцикл |
|
1 |
2 |
3 |
4 |
5 |
|
|
, мы |
||||||||
5 |
|
5 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
пришли к противоречию, следовательно, предположение о неоднозначности декодирования неверно.
7

|
2. Пусть кодирование взаимно однозначное, покажем, что в G |
|||||||||||||||||
нет |
орциклов |
через |
вершину |
|
. |
Доказательство |
проведем |
от |
||||||||||
противного. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
а) Рассмотрим самый короткий |
|
цикл |
через |
вершину |
|
–это |
|||||||||||
петля (рис. 2). |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
Но если из |
в |
|
|
идет дуга, то существуют |
|||||||||||
|
|
|
кодовые слова Bq , Bi |
Bi |
... Bi |
s |
2 |
такие, |
что |
|||||||||
|
|
|
|
|
|
|
|
|
1 |
2 |
|
3 |
|
|
|
|
|
|
|
|
|
Bq |
Bi Bi ... Bi |
|
, тогда |
aq |
|
ai |
ai |
... ai – |
|||||||
|
|
|
|
|
1 |
2 |
5 |
|
|
|
|
|
|
|
1 |
2 |
|
5 |
|
Рис. 2 |
декодирование неоднозначное. |
|
|
|
|
|
|||||||||||
|
б) Пусть орцикл проходит через две вершины (рис.3). |
|
|
|
||||||||||||||
|
|
|
Рассмотрим |
сообщение |
вдоль |
этого |
цикла: |
|||||||||||
|
|
|
|
Bi |
... Bi |
Bj |
... Bj |
которое |
допускает |
два |
||||||||
|
|
|
|
1 |
s |
1 |
|
q |
|
|
|
|
|
|
|
|
|
|
|
|
|
разных разбиения на кодовые слова |
|
|
|
|
|||||||||||
|
|
|
Bi ... Bi |
Bj |
...Bj |
|
Bi ...Bi |
|
Bj |
...Bj |
, |
где |
|
|||||
|
Рис.3 |
|
|
1 |
s |
1 |
q |
|
1 |
s |
1 |
q |
|
|
|
|||
|
|
|
Bj ...Bj и |
Bi ... Bi |
– разные кодовые слова |
|
||||||||||||
|
|
|
|
|
||||||||||||||
|
|
|
|
1 |
q |
1 |
|
s |
|
|
|
|
|
|
|
|
|
|
|
|
|
в) Рассмотрим произвольный орцикл через |
|||||||||||||||
|
|
|
вершину , тем не менее самый короткий, без |
|||||||||||||||
|
|
|
повторяющихся вершин (рис.4). Различные |
|||||||||||||||
|
|
|
разбиения на кодовые слова связаны с тем, куда |
|||||||||||||||
|
|
|
мы |
будем |
относить |
вершины |
i . |
Одна |
||||||||||
|
Рис.4 |
|
расшифровка будет такая: |
|
|
|
|
|
|
|
|
|||||||
|
|
Bi |
... Bi |
1Bj ...Bj |
2 ... 3... Bj |
...Bj |
2 ... |
3... |
|
|
|
|||||||
|
|
|
|
|
|
|||||||||||||
|
|
|
1 |
s |
|
1 |
q |
|
|
|
1 |
|
q |
|
|
|
|
|
|
Другая расшифровка: |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Bi ... Bi 1 |
Bj ...Bj |
2 Bk ...Bk 3... Bj ...Bj |
2 ... |
3... |
и |
вновь |
имеем |
|||||||||||
1 |
s |
1 |
q |
1 |
l |
|
1 |
|
q |
|
|
|
|
|
|
|
|
|
неоднозначное декодирование. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
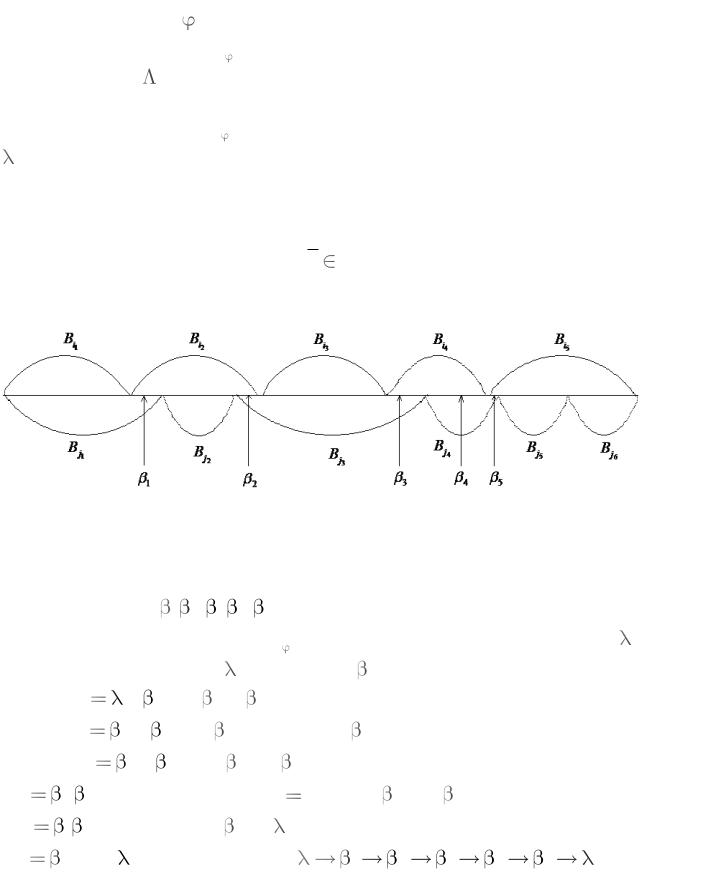
|
Пример 2. Рассмотрим код K |
|
0, 01, 10 |
из примера 1, он был |
||||||||||||||
неоднозначным, следовательно, должен существовать цикл через
вершину . Множество V |
, 1 , |
из |
идет |
дуга в 1, так как |
существуют кодовые слова 0 и 01 такие, что 01 |
B1 1, из 1 идет |
|||
дуга в , так как существует слово 10 |
1 B1 . |
|
||
Пример 3. Выяснить, является ли взаимно однозначным код
K 01, 12, 021, 0102, 10112 .
8

Здесь множество M 1, 02 , так как только они являются
одновременно и префиксом и суффиксом кодовых слов. Для того, чтобы дуга выходила из вершины , нужно чтобы существовало кодовое слово, которое начинается с другого кодового слова, а чтобы входила в вершину , нужно существование кодового слова,
оканчивающегося на другое кодовое слово. |
|
|
||
|
В нашем случае существует цикл (рис. 5) и |
|||
|
именно сообщение вдоль этого цикла допускает |
|||
|
различное |
разбиение |
на кодовые слова: |
|
|
01 021 01 |
12 0102 |
10112 . |
Рассмотрим |
Рис. 5 |
простые типы взаимно однозначных кодов. |
|||
1.Равномерный код, это код, в котором длины всех кодовых слов равны. Тогда сообщение единственным образом разбивается на куски одинаковой длины.
2.Префиксный код. Код называется префиксным, если ни одно кодовое слово не является началом другого кодового слова. В этом
случае нет дуги, выходящей из вершины , следовательно, нет цикла через вершину . Разбиение на кодовые слова начинается с начала сообщения: отрезаем первое кодовое, затем следующее и так далее.
Префиксный код употребляется чаще других, во-первых, не надо выяснять его однозначность, во-вторых, его легко строить. Префиксный код можно строить с помощью корневого дерева, которое применительно к коду называют кодовым, где кодовым словам соответствуют только висячие (концевые) вершины.
Пусть алфавит B {0, 1}, тогда из каждой вершины корневого дерева могут выходить только две дуги, левая дуга соответствует 0, правая 1. К каждой висячей вершине корневого дерева ведет от корня единственный путь, ему и соответствует кодовое слово. Поэтому чтобы построить префиксный код для алфавита A {a1 a2 ... am}, надо построить корневое дерево, в котором будет m висячих вершин.
9

Пример 4. Пусть алфавит B {0, 1}, A {a1,a2 ,... a10}. Построим, например, корневое дерево, показанное на рис.6
Рис.6 |
Рис.7 |
|
Этому дереву соответствует следующий набор кодовых слов:
B1 |
01, B2 11, B3 000, B4 |
100, B5 |
0011, B6 1011, |
B7 |
00100, B8 00101, B9 |
10100, B10 |
10101. |
Можно построить код с заданным набором длин кодовых слов. Пример 5. Построить двоичный префиксный код (то есть
алфавит B {0, 1}) с набором длин кодовых 1, 3, 3, 3, 3. Такому коду соответствует дерево, приведенное на рис.7, а сам код задается кодовыми словами B1 0, B2 100, B3 101, B4 110, B5 111.
3. Суффиксный код. Код называется суффиксным, если ни одно кодовое слово не является концом другого кодового слова. Декодирование начинается с конца сообщения: отрезается последнее кодовое слово, затем предпоследнее и так далее.
Теорема (неравенство Макмиллана). |
|
|
|
|
|||||||||||||||
Пусть заданы кодируемый алфавит A |
|
a1,...am |
и кодирующий |
||||||||||||||||
алфавит B |
b1,...bk |
. Взаимно однозначное кодирование |
задано |
||||||||||||||||
набором кодовых слов K |
|
B1, B2 ,...Bm с длинами |
l1,l2 ,...lm |
. Тогда |
|||||||||||||||
|
|
|
|
|
|
|
m |
1 |
|
|
|
|
|
|
|
|
|
||
выполняется |
неравенство |
|
|
|
1, |
где k |
– количество |
букв в |
|||||||||||
|
|
|
|
|
|||||||||||||||
|
i 1 kli |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
алфавите B , |
m – мощность алфавита A. |
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
m |
1 |
|
|
|
|
|
|
|
Доказательство. Обозначим |
|
|
x |
и рассмотрим xn , где n |
|||||||||||||||
|
|
|
|||||||||||||||||
i 1 |
kli |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
– произвольное натуральное число. |
|
|
|
|
|
|
|
|
|||||||||||
xn |
1 |
|
1 |
|
... |
|
|
1 n |
|
|
|
|
1 |
|
|
(1) |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
kl1 |
kl2 |
|
klm |
|
(i1i2 ...in ) kli1 |
li2 ... lin |
|
|||||||||||
|
|
|
|
|
|
|
|||||||||||||
10

сумма берется по всевозможным упорядоченным наборам |
|
i1i2 ...in , |
||||||||||||||||||||||||||||||||||||||||||||||||||
каждое 1 |
i |
j |
m , |
слагаемых будет mn . Для пояснения такой формы |
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
записи приведем пример. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
Пример 6. Рассмотрим x2 , где x |
|
|
1 |
1 |
|
1 |
|
|
. |
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
kl1 |
|
|
kl2 |
|
|
|
kl3 |
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
1 |
|
1 |
|
|
|
|
|
1 |
2 |
|
1 |
|
|
1 |
|
|
|
|
|
|
1 |
|
|
|
|
|
2 |
|
|
|
|
2 |
|
|
|
2 |
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
kl1 |
|
kl2 |
|
kl3 |
|
|
k |
l1 2 |
|
k |
l2 |
2 |
|
k |
l3 |
2 |
|
|
kl1 kl2 |
|
|
kl1 k l3 |
|
k l2 k l3 |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
1 |
|
|
|
|
|
1 |
1 |
|
|
1 |
|
|
|
1 |
|
|
|
1 |
|
|
|
1 |
|
1 |
|
|
|
1 |
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
kl1 l1 |
|
|
kl2 |
|
l2 |
|
kl3 l3 |
|
|
kl1 l2 |
|
|
|
kl2 |
l |
|
kl1 l3 |
|
kl3 l1 |
|
|
|
|
kl2 |
l3 |
|
kl3 l2 |
||||||||||||||||||||||
|
|
|
|
|
Обозначим max l1,l2 ,...lm |
|
|
|
lmax и, приведя подобные в равенстве |
|||||||||||||||||||||||||||||||||||||||||||
(1), получим |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xn |
nlmax |
|
1 |
q |
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(2) |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k r |
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
где |
r |
li |
|
|
li |
... |
|
li , |
qr |
|
– |
|
|
число |
наборов |
i1i2 ...in |
|
на |
которых |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
2 |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
li |
|
|
|
li ... |
|
|
li |
|
r . Если для какого-то r |
|
не будет ни одного набора |
|||||||||||||||||||||||||||||||||||||||||
1 |
|
|
|
2 |
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i1...in , на котором li ... |
li |
|
|
r , соответствующее qr |
0 . |
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
Оценим |
qr . Набору i1i2 ...in |
соответствует единственное слово |
|||||||||||||||||||||||||||||||||||||||||||||
ai |
ai |
...ai |
|
|
|
ɱ |
A . Так как упорядоченные наборы i1i2 ...in |
различны, то |
||||||||||||||||||||||||||||||||||||||||||||
1 |
2 |
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
слова ai |
ai |
...ai |
разные, кодирование |
|
взаимно однозначные, их коды |
|||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
1 |
2 |
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Bi |
|
Bi ...Bi |
– слова в множестве ɱ |
|
B |
также различны. Длина слова |
||||||||||||||||||||||||||||||||||||||||||||||
1 |
|
|
2 |
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Bi |
|
Bi ...Bi равна li |
li |
... |
|
li |
|
|
|
r . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
1 |
|
|
2 |
|
|
n |
|
|
|
1 |
|
2 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
Таким образом, qr |
– число слов длины r в алфавите B , которые |
||||||||||||||||||||||||||||||||||||||||||||||
являются кодами слов длины n в алфавите A. Всех слов длины r в
алфавите B k r , поэтому q |
|
k r , |
|
|
|
|
|
|
||||
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
xn |
nlmax |
1 |
q |
nlmax |
1 |
k r |
nl |
||
|
|
|
|
|
|
|
||||||
|
|
|
|
|
k r |
r |
|
k r |
max |
|||
|
|
|
|
r 1 |
|
r 1 |
|
|||||
Тогда x n nl |
|
. Неравенство выполняется для любого n , можно |
||||||||||
|
|
max |
|
|
|
|
|
|
|
|
|
|
перейти к пределу при n |
|
. |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
lim x |
lim n nl |
, |
||||||
|
|
|
|
n |
|
|
n |
|
|
max |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
11

x от n не зависит, поэтому |
lim x |
x , |
lim n nl |
1, следовательно, |
|||||
|
|
|
|
n |
|
|
n |
max |
|
|
|
|
|
|
|
|
|
||
|
m |
1 |
|
|
|
|
|
|
|
x 1. Отсюда |
|
1. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
i 1 kli |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
||
Теорема о существовании префиксного кода |
|||||||||
Пусть для алфавитов A |
|
a1, |
, am |
|
и B b1, |
,bk существует |
|||
взаимно-однозначный код |
, |
заданный набором кодовых слов |
|||||||
B1, B2 , , Bm |
с длинами l1,l2 , |
,lm |
, тогда для тех же алфавитов A |
||||||
и B существует префиксный код с теми же длинами кодовых слов.
Доказательство.
Для взаимного однозначного кода выполняется неравенство Макмиллана
|
|
|
m |
1 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
1. |
|
|
(3) |
||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
i |
1 |
|
kli |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|||||
Пусть имеется cr кодовых слов длины r |
и lmax max l1,l2 , |
,lm , |
|||||||||||
тогда неравенство (3) можно переписать в виде (4) |
|
||||||||||||
|
|
|
lmax |
c |
|
|
|
|
|
||||
|
|
|
|
|
|
|
r |
|
|
1. |
|
|
(4) |
|
|
|
r |
1 |
|
k r |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|||||
Для любого l |
lmax также будет справедливо |
|
|||||||||||
|
|
|
l |
|
|
cr |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. |
|
|
(5) |
|||
|
|
|
r |
1 |
|
k r |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|||||
Умножим обе части неравенства на k l |
, |
|
|
|
|||||||||
|
|
|
l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
c kl |
r |
kl , |
|
(6) |
|||||
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
r |
1 |
|
|
|
|
|
|
|
|
|
Перепишем это неравенство в виде: |
|
|
|
|
|
||||||||
|
|
c kl 1 |
c kl z ... |
|
|
c |
k |
c |
kl , |
(7) |
|||
|
|
1 |
2 |
|
|
|
l |
1 |
|
l |
|
|
|
Откуда получим оценку для cl |
– числа слов длины l в исходном |
||||||||||||
коде: c |
kl |
c kl 1 |
c kl 2 ... |
c |
|
k . |
|
|
|
||||
l |
|
1 |
2 |
l |
1 |
|
|
|
|
|
|
||
Докажем, что можно построить префиксный код, в котором |
|||||||||||||
кодовых слов длины l также будет cl |
|
l |
1, 2,... lmax . |
|
|||||||||
Доказательство проведем по индукции по l . |
|
||||||||||||
12