

7. Организация системы прерывания в pdp 11
Система прерывания моделей семейства PDP11 предусматривает:
исключения – возникают при аппаратных сбоях, при выполнении команды прерывания, при установленном флаге пошагового прерывания (четвертый бит "trap"в регистре состоянияPS), при страничном промахе механизма виртуальной памяти.
аппаратные прерывания (прерывания от внешних устройств).
Отличие системы прерывания моделей семейства PDP-11 от системы прерывания МП-IA, заключается в процедуре передачи сигнала прерывания и содержимого вектора прерывания.
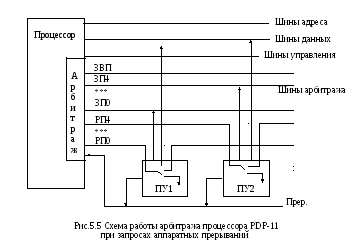
Процедура передачи сигнала прерывания в семействе PDP-11 производится по проводам системного интерфейса. В интерфейсе предусмотрено 5 проводов от периферийных устройств к арбитражу.
Это провода для передачи запроса на права доступа к шинам интерфейса (рис.5.5) для:
запросов на внепроцессорный (прямой) доступ к памяти (ЗВП – запрос с высшим 8-м уровнем приоритета, один провод),
запросов на прерывание: 4 провода с уровнями приоритета от 7 до 5 (ЗПВ7, ЗПВ6, ЗПВ5, ЗПВ4).
Процессор может иметь переменный уровень приоритета от 7 до 4. Уровень приоритета процессора задается трехбитовым полем приоритета регистра состояния (PS).
Всем внешним устройствам, использующим прямой доступ к памяти или систему прерывания, присваивается высший (8) уровень приоритета на запрос прямого доступа к памяти и один из уровней (от 7 до 4) – по запросам на передачу сигнала прерывания.
На запросы внешних устройств, если приоритет запроса выше уровня приоритета процессора, арбитраж выставляет ответный сигнал разрешения на захват шин интерфейса для прямого доступа к памяти или для передачи вектора прерывания в процессор по одному из четырех проводов разрешения (РП4, РП5, РП6, РП7) захвата (следующего) цикла процессора. Но это приоритетное выделение только уровня запроса, а не конкретного устройства на этом уровне. Для выделения единственного запроса на приоритетном уровне провода разрешения на каждом уровне соединены последовательно в контроллерах периферийных устройств. При этом в контроллере всех периферийных устройств передача сигнала на последующее устройство блокируется. Таким образом, сигнал разрешения захвата цикла процессора доходит только до контроллера одного периферийного устройства. По получении разрешения контроллер выставляет сигнал "Прер" на общий провод подтверждения разрешения. При отсутствии сигнала подтверждения процессор определяет запрос как ложный.
Таким образом, в семействах PDP-11 реализована ортогональная (многоуровневая) схема выделения приоритетов. Маскирование запросов прерывания производится не индивидуально, а по уровням. При этом уровень приоритета задается в регистре состояния (PS), запрос на прямой доступ не маскируется, т.к. запрос на внепроцессорные передачи ( 8 уровень) всегда выше приоритета процессора (от 7 до 4 уровня).
Устройство, получившее разрешение на прерывание, по окончании текущего цикла занимает цикл интерфейса и передает процессору по шине данных адрес вектора прерывания в таблице прерываний, расположенной с начальных адресов памяти. Вектор прерывания состоит из двух слов – адреса программы обработки прерывания (PC – Program counter) и регистра состояния программы (PS – Program status). В процедуре прерывания процессор сохраняет в аппаратном стеке содержимое счетчика команд (PC) и регистра состояния программы (PS). После сохранения контекста программы процессор производит загрузку регистров PC и PS соответствующими компонентами вектора прерывания.
Процедура прерывания семейства моделей PDP-11, в отличие от семейства МП IA-16, заключается в том, что вектор прерывания, кроме адреса программы обработки прерывания, содержит и начальное состояние программы обработки прерывания, и программа обработки прерывания начинает работу в своем контексте, а не в контексте прерываемой программы.
Вопросы и/или темы для самопроверки:
1. Отличия системы прерывания моделей семейства PDP-11 от системы прерывания МП-IA.
2. Процедура передачи сигнала прерывания в семействе PDP-11.
3. Работа арбитража.
4. Механизм маскирования сигналов прерывания.
6. Принцип выделения сигнала приоритетного уровня.
7. Принцип выделения приоритетного сигнала внутри уровня.
8. Особенность передачи вектора прерывания в процессор.
9. Отличия содержимого вектора прерывания в моделях семейства PDP –11.
8-неделя. Лекция 8. Система прерывания в МП INTEL
Система прерывания в МП IA-16
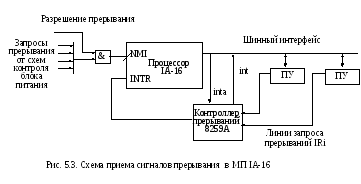
Архитектура МП IA-16 предусматривает (рис. 5.3) два входа приема сигналов прерывания:
вход приема немаскируемых сигналов прерывания (NMI),
вход приема маскируемых сигналов прерывания (INTR).
Кроме этого, схемы процессора могут формировать сигналы исключительных ситуаций (исключений), требующих прерывания текущих программ. Эти сигналы могут быть вызваны определенными событиями и/или специальными командами вызова процедур обработки исключительных ситуаций.
В МП IA прерывания по сигналам на входах NMI и INTR определены как аппаратные прерывания, но по своей сущности сигналы по входу NMI являются исключениями, а по входу INTR – классическими прерываниями.
Кроме этого, в МП IA имеются ряд команд и признак TF в регистре флагов, вызывающие процедуру прерывания. Это программируемые прерывания, которые по своей сущности являются исключениями.
Прерывания по команде INTO вызывает прерывание по флагу переполнения. Команда INT3 используется при отладке программ. Она вызывает процедуру прерывания, которая может распечатать содержимое определенных ячеек памяти или РОН. Это однобайтовая команда, которую можно вписать вместо кода операции любой команды (возможно, с добавкой команд NOP (нет операции)) без нарушения структуры последующих команд.
Прерывания по сигналам прерывания по входу NMI
Это сигналы от схем контроля блока питания, обнаружения ошибок системы памяти, требующих немедленного реагирования. Все программы обработки прерываний этих причин объединены в одну программу с номером (типом) 2 и имеют второй приоритет по обслуживанию. Прерывания по этому входу в процессоре не маскируются и выявляются по переднему фронту сигнала. Это гарантирует однократное реагирование системы прерывания на один запрос.
Прерывания по сигналам прерывания по входу INTR
Запросы на маскируемые сигналы прерываний поступают от отдельных периферийных устройств по индивидуальным проводам запроса. В контроллере прерываний они фиксируются на регистре прерываний, связанном со схемой приоритетного выбора сигнала прерывания. При этом в контроллере прерываний (8259А) формируется выходной сигнал прерывания, поступающий на вход приема маскируемых сигналов прерывания (INTR) и тип (n), где n – номер программы обработки прерывания.
 Прерывания
по сигналам прерывания по входу INTR
Прерывания
по сигналам прерывания по входу INTR
Запросы на маскируемые сигналы прерываний поступают от отдельных периферийных устройств по индивидуальным проводам запроса. В контроллере прерываний они фиксируются на регистре прерываний, связанном со схемой приоритетного выбора сигнала прерывания. При этом в контроллере прерываний (8259А) формируется выходной сигнал прерывания, поступающий на вход приема маскируемых сигналов прерывания (INTR) и тип (n), где n – номер программы обработки прерывания.
По завершении очередной команды производится проверка исключений, в частности, сигнала на входе NMI процессора. Сигнал определяется по переднему фронту. При отсутствии сигнала на входе NMI процессор проверяет значение бита разрешения прерывания в регистре флагов. При IF=0 процессор производит выборку очередной команды текущей программы.
При единичном значении IF процессор реализует процедуру прерывания. Для этого процессор выставляет на шины системного интерфейса в двух смежных тактах сигналы подтверждения прерывания (inta).
В ответ на сигнал inta во втором такте подтверждения прерывания контроллер прерывания выставляет на шины данных тип (n) программы обработки прерывания.
Тип (n) программы обработки прерывания используется в качестве номера строки таблицы прерываний. Таблица прерываний содержит векторы прерываний: IP (адрес входа в программу) и CS (базовый адрес сегмента программы).
В МП Intel, как и во многих ЭВМ, количество программ обработки прерываний ограничено числом 256. В соответствии с этим таблица прерываний содержит не более 256 векторов прерываний по 4 байта. Для МП IA-16 таблица прерываний всегда занимает первый килобайт линейной (оперативной) памяти.
Для сохранения настройки и перехода на программу обработки прерывания процессор производит следующие действия:
последовательно сохраняет в стеке содержимое CS, IP и регистра флагов (F),
в регистре флагов сбрасываются флаги разрешения прерываний IF и пошаговой ловушки TF (запрещение прерывания и пошагового режима),
делает обращение к таблице прерываний и производит последовательное заполнение регистров процессора IP и CS данными из таблицы прерывания по адресу 4n, где n – тип прерывания.
Сохранение содержимого РОН производится программой обработки прерывания.
После сохранения РОН программа обработки прерывания может сбросить флаг разрешения прерывания IF. Сброс флага IF открывает возможность прерывания программы обработки прерывания запросами прерывания с более высоким приоритетом, например, сигналом прерывания по входу NMI.
Программа обработки прерывания заканчивается командами восстановления данных в РОНах и командой IRET. По команде IRET производится восстановление регистров F, IP и CS значениями, сохраненными в стеке.
|
Таблица 7. Основные параметры различных видов прерываний
| |||
|
Вид прерывания |
Тип |
Приор. |
Примечание. |
|
По ошибке деления |
0 |
1 |
|
|
По команде INT n |
5 – 31 |
1 |
|
|
По команде INTO |
4 |
1 |
Команда прерывания при переполнении |
|
По команде INT 3 |
3 |
1 |
Однобайтовая команда контрольной точки |
|
По входу NMI |
2 |
2 |
|
|
По входу INTR |
32 – 255 |
3 |
|
|
По флагу TF |
1 |
4 |
Пошаговый режим |
Особенности системы прерывания в МП IA-32
Основными причинами модификации системы прерывания в МП IA-32 можно считать следующие архитектурные изменения:
более активное использование взаимодействия аппаратно-программных средств, например, в системе виртуальной памяти,
переход к использованию симметричных многопроцессорных систем, начиная с МП Pentium Over Drive (Pentium второго поколения).
использование механизма защиты программ от взаимных помех.
Более активное использование взаимодействия аппаратно-программных средств
В МП IA-32 используется механизм виртуальной памяти, который, в случаях страничных промахов, применяет механизм прерывания для подкачки новой страницы и рестарта прерванной команды. В этих случаях требуется сохранение адреса не следующей команды, а команды, вызвавшей исключение.
По этой причине в системе прерывания различают три случая исключений. Они различаются адресами возврата из исключения, а текущая команда может быть:
отложена,
выполнена,
принудительно (аварийно) прекращена.
В первом случае исключение обнаруживается до начала выполнения текущей команды. Это отказ (fault) – исключение, которое обнаруживается и обслуживается до выполнения текущей команды. В этом случае в процедуре прерывания восстанавливаются первоначальные значения всех регистров, которые были до начала выполнения команды, сохраняется адрес текущей (но невыполненной) команды. Это и есть рестарт команды. Примером такой ловушки является страничный промах при трансляции страниц.
В современных МП, в частности МП IA-32, функционирование счетчика команд (IP) несколько изменено. Для увеличения быстродействия процессора используется опережающая выборка программного кода в буферный регистр кодовой строки.
В МП 80386 емкость буферного регистра кодовой строки составляет 16 байт. Первый байт этой строки всегда содержит код операции команды или префикс, т.е. начало текущей команды. Команда может содержать переменное число байт. Байты команды по очереди сдвигаются к старшим разрядам и поступают на регистр команд, пока не будет выбран последний байт команды. Если при этом освобождаются четыре младших байта буферного регистра кодовой строки, то производится обращение к кодовому сегменту команд для заполнения кодовой строки. Таким образом, счетчик команд не обращается за каждой командой в кодовый сегмент памяти, а производит заполнение кодовой строки по четыре байта.
При прерываниях или исключениях буфер кодовой строки очищается и заполняется кодовой строкой программы обработки исключения. При рестарте вычисляется адрес команды рестарта, производится его запоминание в стеке и после этого производится заполнение регистра кодовой строки командами программы обработки исключения.
Во втором случае исключение обнаруживается после начала выполнения текущей команды. Это ловушка (trap) – исключение, которое обнаруживается и обслуживается после выполнения текущей команды. В процедуре прерывания сохраняется продвинутый адрес основной программы. К классу ловушек относятся все программные прерывания.
В третьем случае – это исключение, при котором невозможно точно установить адрес инструкции, вызвавшей исключение. Это аварийное завершение (abort). Оно используется для сообщения о серьезной ошибке, не допускающей рестарта.
Переход к использованию симметричных многопроцессорных систем
Контроллер прерываний (8259А) не предназначен для работы в симметричных многопроцессорных системах. По этой причине начиная с МП Pentium Over Drive (Pentium второго поколения) в системе прерываний используется новый усовершенствованный контроллер прерываний APIC (Advanced Programmable Interrupt Controller Enable). Для локальных запросов прерываний APIC использует индивидуальные линии LINT0 и LINT1 по одной на процессор. Общие (разделяемые) сигналы прерываний поступают к процессорам по интерфейсу APIC. При этом контроллеры предварительно программируются для определения функций каждого из процессоров по обработке аппаратных прерываний.
Использование механизма защиты программ от взаимных помех
Механизм защиты программ от взаимных помех предусматривает разделение программ по четырем уровням защиты, причем самый нижний уровень защиты предназначен для пользовательских программ. Их защита от взаимных помех обеспечивается операционной системой разделением их адресных пространств и использованием локальных таблиц дескрипторов. Пользовательским программам доступны только сегменты, зафиксированные в их локальных таблицах.
Программы обработки прерываний размещаются на более высоком уровне привилегий. Механизм защиты позволяет использование этих программ только командами перехода с возвратом и только с использованием шлюзов (см. 2.3. Программная модель 32-разрядного микропроцессора).
Кроме этого, механизм защиты позволяет при передачах управления использовать более защищенную процедуру переключения задач.
По этой причине таблица прерываний на каждое прерывание (включая исключения) может содержать:
дескриптор шлюза прерывания, или
дескриптор шлюза исключения, или
дескриптор шлюза задачи.
Максимальное число дескрипторов в таблице – 256.
Структуры шлюзов таблицы прерываний представлены на рис.5.4.
|
63 |
48 |
47 |
16 |
15 |
|
0 | |
|
Селектор |
Offset (Смещение в сегменте) |
Атрибуты | |||||
|
а. Структура дескриптора шлюза прерывания |
| ||||||
|
Селектор |
Offset (Смещение в сегменте) |
Атрибуты | |||||
|
б. Структура дескриптора шлюза исключения |
| ||||||
|
Селектор |
поле не используется |
Атрибуты | |||||
|
с. Структура дескриптора шлюза исключения. |
| ||||||
|
Рис.5.4. Структура дескрипторов таблицы прерывания |
| ||||||
При использовании шлюза прерывания или исключения задается процедура передачи управления с сохранением в стеке адреса возврата и содержимого регистра флагов. По селектору дескриптора шлюза производится обращение к GDT(Глобальной таблице дескрипторов) для определения дескриптора кодового сегмента программы прерывания или исключения, включая проверки по уровням привилегий.
При этом селектор дескриптора шлюза прерывания или исключения записывается в сегментный регистр CS процессора, дескриптор сегмента – в регистр дескриптора процессора, ассоциативно связанный с сегментным регистромCS, и уровень привилегий дескриптора – в поле текущего уровня селектораCS.
Отличие процедуры прерывания от процедуры исключения заключается только в том, что в процедуре прерывания после сохранения в стеке содержимого регистра флага процессор сбрасывает бит разрешения прерывания, а в процедуре исключения – не сбрасывает.
При использовании шлюза TSSпереход на программу обработки прерывания и возврат производится с применением процедуры переключения программ.
Вопросы и/или темы для самопроверки:
1. Понятие исключения – отказ(fault).Приведите пример.
2. Понятие исключения – ловушка (trap). Приведите пример.
3. Понятие исключения – аварийное завершение (abort). Приведите пример.
4. Особенности работы контроллера прерывания в симметричных многопроцессорных системах.
5. Содержимое строк таблицы прерывания в защищенном режиме.
6. Отличия в процедуре прерывания при использовании дескрипторов ловушки и прерывания.
9-неделя. Лекция 9
Теоретические основы операций ввода/вывода
Организация ввода/вывода – это передача данных между оперативной памятью (ОП) и периферийными устройствами (ПУ).
Управление вводом/выводом относится к нижнему физическому уровню управления средствами вычислительных систем. На базе операций этого уровня реализуются процедуры верхнего уровня управления, например, процедуры команд операционных систем и программных оболочек: сохранить файл, загрузить файл, копировать файл и т.д.
Для каждого типа ПУ используется устройство управления (контроллер, адаптер), алгоритмы работы которого учитывают индивидуальные особенности данного типа ПУ.
Организация управления вводом/выводом связана с решением ряда задач. Решения части из этих задач зависят от физики работы конкретных ПУ и реализуются на уровне обмена физическими сигналами (в определенные моменты времени формируются импульсы тока или напряжения определенной амплитуды и длительности). На этом уровне решаются следующие проблемы:
запись информации во внутреннюю память ПУ и чтение из нее,
управление адресацией внутренней памяти ПУ,
передача информации между ПУ и контроллером и, частично, контроль процесса ввода/вывода.
Решения другой части задач не зависят от физики работы отдельных ПУ и реализуются на уровне обмена логическими сигналами. На этом уровне решаются проблемы:
задания кода операции и адреса блока данных в ПУ,
передачи данных между ПУ и ОП,
синхронизации передачи данных,
контроля процесса ввода/вывода,
активизации и окончания работы ПУ.
Для организации ввода/вывода в контроллерах устройств ввода/вывода предусмотрены специальные регистры (основными являются регистр данных RDи регистр управленияRU), а в системе команд – команды ввода/вывода.
Управление вводом/выводом на этом уровне может быть реализовано двумя способами:
с использованием средств процессора. Такой ввод-вывод называется программным,
с использованием специальных устройств управления (процессоров ввода/вывода, устройств прямого доступа к памяти ПДП). Такой ввод-вывод называется аппаратным (внепроцессорным, с занятием цикла, с прямым доступом к памяти).
Программный ввод/вывод
При программном вводе/выводе контроллерами управляет ПР при помощи программы (драйвера) ввода/вывода. Программы этого типа учитывают конструкцию контроллера и используемого в вычислительной системе ПР и обычно входят в базовую систему программ управления вводом/выводом на физическом уровне (в РС – BIOS). Программы BIOS выполняют роль интерфейса между программами операционных систем и используемой аппаратурой вычислительной системы и обеспечивают переносимость операционных систем между ЭВМ с одинаковыми процессорами.
Синхронизация передачи данных при вводе/выводе
Специфика периферийных устройств заключается в том, что их схемы работают несинхронно с тактом работы процессора и, как правило, являются намного менее быстродействующими по сравнению с ПР и ОП.
RD контроллера по отношению к ПР является быстродействующим регистром, который способен производить прием/передачу данных наравне с внутренними регистрами ПР. С другой стороны, RD осуществляет прием/передачу данных от связанного с ним ПУ с той скоростью и в том порядке, которые обусловлены характеристиками данного ПУ.
Поэтому, моменты появления данных на RD контроллера ПУ при вводе, или готовность ПУ принять новые данные при выводе – непредсказуемы. Определение моментов готовности ПУ принять или передать новые данные и передача данных при условии наступления ожидаемых моментов составляют суть условных программных способов ввода/вывода.
В настоящее время известны два условных способа программного ввода/вывода:
с проверкой готовности,
с использованием системы прерывания.
В обоих способах синхронизация передачи данных осуществляется при помощи бита RDY ("флага готовности") в специальном программно доступном регистре управления (RU) контроллера ПУ.
Работа RD с использованием бита RDY в процессе ввода или вывода характеризуется чередованием двух фаз:
1. передача данных между RD и ПУ (доступ ПР к RD при этом запрещен);
2. передача данных между RD и ПР (доступ ПУ к RD при этом запрещен).
Закончив свои операции по загрузке RD при вводе или чтению содержимого RD при выводе, ПУ устанавливает бит RDY в состояние 1 - "поднимает флаг готовности". Поднятие флага означает окончание фазы ПУ в работе RD и начало фазы ПР : поднятый флаг разрешает доступ к RD со стороны ПР и запрещает доступ со стороны ПУ.
ПР по окончании своего этапа обмена информацией с RD сбрасывает флаг в нулевое состояние. Сброс флага символизирует окончание фазы ПР и начало фазы ПУ.
Использование системы прерывания при организации ввода/вывода освобождает процессор от непрерывного опроса состояния флага готовности, дает возможность использования процессора в фоновой работе. В этом варианте готовность данных используется для формирования сигнала прерывания фоновой работы и передачи управления программе ввода/вывода с последующим возвратом к фоновой работе.
Рассмотренная процедура передачи данных через буфер (регистр РД) и синхронизации с помощью обоюдно управляемого и тестируемого флага составляет техническую основу всякой передачи данных между устройствами.
Ввод/вывод с использованием системы прерывания
Основное преимущество организации ввода/вывода с использованием системы прерывания заключается в возможности организации фоновой работы, т.е. более эффективное использование функциональных возможностей процессора.
Отличие этого метода организации ввода/вывода заключается в том, что:
установка бита готовности не проверяется программой процессора, а приводит к формированию сигнала прерывания,
проверка нарушения тайм-аута производится не программно, а с использованием аппаратных средств процессора или внешних устройств.
В этом варианте программа ввода/вывода делится на части.
Начальная часть программы (передача параметров процедуре ввода/вывода) и заключительная часть исполняются в виде проблемной программы, а программа управления передачей оформляется в виде программы обработки внешнего прерывания.
При использовании программы обработки прерывания возникает ряд проблем. Это передача параметров и сохранение содержимого РОН.
При прерываниях основной контекст программы сохраняется аппаратно, а РОНы – в программе обработки прерывания. Перед выходом из прерывания программа обработки восстанавливает содержимое РОНов. Но фоновая (проблемная) программа может испортить содержимое РОНов, в которых программа управления вводом/выводом хранит текущий адрес оперативной памяти и размер блока вводимых (выводимых) данных. Чтобы этого не случилось, можно или сохранять эти параметры в зарезервированных ячейках оперативной памяти, или, для МП IA-32, в процедуре прерывания использовать механизм переключения задач
Ввод/вывод с использованием устройств прямого доступа к памяти
Изначально прямой доступ к памяти был предназначен для исполнительных устройств обработки данных, т.е. для процессора. Но для более эффективного использования вычислительных средств процессора стали создавать дополнительные, специализированные устройства, ориентированные на выполнение процедур управления операциями ввода/вывода.
В вычислительных системах корпорации CDC используются периферийные процессоры, которые, кроме управления вводом/выводом, могут выполнять ряд вычислительных операций и использоваться для обработки прерываний от внешних устройств. В моделях семейства IBM периферийные процессоры (каналы) более простые. При выполнении операций ввода/вывода они даже для простейших вычислений через систему прерываний используют вычислительные возможности центрального процессора.
В моделях PCIAиспользуют не процессоры, а простейшие устройства ПДП для управления вводом/выводом. Обычно это стандартные устройства управления вводом/выводом на одну операцию. Обычно они рассчитаны на работу с широким кругом периферийных устройств.
Функции процессора в передаче данных с использованием ПДП сводятся к инсталляции устройства и анализу корректности завершения передачи данных.
В этой фазе процессор производит загрузку регистра адреса начальным адресом области ввода ОП, загрузку регистра счетчика передаваемых слов и включает ПДП в работу установкой бита "Пуск" регистра управления RU в единичное состояние.
На этом этап инсталляции ПДП заканчивается, и процессор переключается на выполнение фоновых программ. Одновременно с работой процессора производится операция ввода данных устройством ПДП с занятием циклов процессора.
После активизации устройства ввода/вывода с контроллером ПДП, через определенное время устройство записывает в регистр данных RD передаваемые данные (слово) и устанавливает бит готовности RU в единичное состояние.
Бит готовности запускает процедуру внепроцессорной передачи (передачу с занятием цикла процессора):
ПУ в очередном цикле процессора по шинам арбитража выставляет запрос шин интерфейса для передачи данных в следующем цикле,
Процессор уступает шины передачи данных на следующий цикл устройству ПДП, выигравшему арбитражный запрос на занятие цикла процессора.
В следующем цикле шин устройство ПДП вместо процессора занимает шины интерфейса, задавая код операции (для ввода – записать), данные из регистра RD,, адрес ячейки ОП из регистраRA и сигнал начала цикла передачи.
Контроллер оперативной памяти принимает команду ПДП, выполняет запись переданных данных по заданному адресу ОП и выставляет сигнал окончания операции.
По этому сигналу схемы контроллера ПДП производят:
продвижение адреса данных в регистре адреса ,
коррекцию счетчика передаваемых данных
сброс бита готовности в регистре управления (RU),
При значении счетчика> 0, ПДП формирует новые данные и повторяет цикл внепроцессорной передачи.
При значении счетчика= 0 или обнаружении нештатной ситуации, устройство ПДП формирует и передает в процессор сигнал прерывания.
Таким образом, ввод/вывод данных с использованием внепроцессорных передач начинается с программы процессора по настройке устройства ПДП, а заканчивается программой процессора по анализу корректности окончания операции ввода/вывода.
Вопросы и/или темы для самопроверки:
Определение операции ввода/вывода.
Определение программного ввода/вывода.
Ввод/вывод с проверкой готовности.
Ввод/вывод с использованием системы прерывания.
Основные особенности организации ввода/вывода с использованием системы прерывания.
Процедура прямого доступа к памяти.
4. Процедура занятия цикла процессора.
5. Действия контроллера ПДП по завершению цикла ПДП.
6. Окончание процедуры ввода-вывода.
10 -неделя. Лекция 10
Организация виртуальной памяти
Предпосылки появления виртуальной памяти
Виртуальная память появилась для решения проблем многопрограммных пакетных режимов работы и режимов коллективного доступа высокопроизводительных ЭВМ.
Основными требованиями этих режимов являлись: независимость подготовки программ и исключение взаимных помех.
Требование исключения взаимных помех
Требование исключения взаимных помех заключается в том, что возможные конфликты программ должны разрешаться также на уровне операционных систем.
Для этого в пределах программ операционной системы предусмотрен ряд корректно написанных сервисных программ по управлению этими ресурсами. Для их использования предусмотрены стандартные вызовы, например, через команды прерывания.
Основные задачи виртуальной памяти
Основными задачами виртуальной памяти являются реализации:
динамической переадресации программ,
организация памяти единого уровня.
Переадресации программ
В соответствии с основной концепцией виртуальной памяти пользователи могут писать программы с использованием любых адресов математической памяти. Переадресация программ заключается в изменении всех адресов обращения к памяти за командами и данными в соответствии с адресами памяти, выделенными операционной системой.
Имеется два способа переадресации программ: программный и аппаратный. Аппаратный способ переадресации используется в механизме виртуальной памяти. Альтернативой ему является программный способ.
Программный способ переадресации программ
Схема программного способа переадресации программ

При статической переадресации исходная программа, возможно разделенная на части, написанная с использованием различных языков программирования, перед выполнением проходит две процедуры преобразования:
Перевод программы с используемого языка программирования на язык машинных команд (процедура компиляции программы). В результате этой процедуры формируются объектные модули. Объектные модули – это программы в машинных кодах, но не настроенные на "свободные участки адресов физической памяти".
Дальше используются две программы операционной системы: супервизор памяти (программа выделения свободных участков оперативной памяти) и редактор связей (программа, связывающая отдельные участки программы в единую последовательность команд – исполняемый модуль).
Все эти процедуры преобразования программ необходимы и при однопрограммных режимах работы, когда нет проблемы распределения памяти.
Разница заключается в том, что в многопрограммных режимах при каждом запуске (прогоне) программы нужно повторять преобразование объектного модуля в исполняемый модуль.
Построение памяти единого уровня
В современных ЭВМ используется многоуровневая физическая память: оперативная, энергонезависимая память на основе магнитных дисков и архивная память на основе записи на магнитных лентах. В однопрограммных режимах пользователи имеют возможность напрямую контролировать и управлять передачей данных по уровням памяти. В многопрограммных режимах работы программисту подконтрольна только математическая память (набор адресов, которые можно использовать в программах). Если этого достаточно для управления работой процессора, включая подкачку данных из памяти прямого доступа (свопинг), то говорят о реализации виртуальной памяти.
Таким образом, в понятие виртуальной памяти входят два механизма: динамическая переадресация и построение памяти единого уровня.
Кроме программного способа переадресации программ возможны и аппаратные способы. В этих способах исполняемый модуль формируется только один раз под адреса, назначенные программистом (в расчете на то, что вся оперативная память свободна). Настройка программ с учетом выполнения программы в многопрограммном режиме производится чисто аппаратно схемами процессора. Это динамическая переадресация программ.
Простейшая схема динамической переадресации программ представлена на рис. В этой схеме программа, написанная для определенного участка адресов математической памяти, может быть помещена в произвольное место адресного пространства оперативной памяти без изменения адресов в командах.
Для корректного выполнения программы в аппаратуру процессора вводятся дополнительный регистр (регистр смещения) и сумматор.
П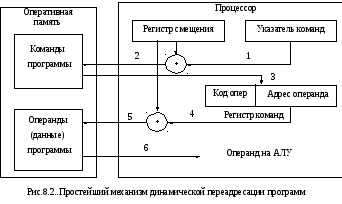 ри
загрузке исполняемого модуля программы
супервизор памяти выделяет для нее
определенный участок оперативной
памяти. Адреса этого участка могут
отличаться от адресов, используемых в
программе. Для их согласования в регистр
смещения заносится число, компенсирующее
разницу адресов в выделенном участке
физической памяти и математической
памяти:
ри
загрузке исполняемого модуля программы
супервизор памяти выделяет для нее
определенный участок оперативной
памяти. Адреса этого участка могут
отличаться от адресов, используемых в
программе. Для их согласования в регистр
смещения заносится число, компенсирующее
разницу адресов в выделенном участке
физической памяти и математической
памяти:
Адрес физической :=адрес математической памяти + смещение.
Величина смещения может иметь любой знак (отрицательный или положительный).
Для запуска программы на регистр указателя команд (счетчик команд) заносится адрес входа в программу, указанный программистом, т.е. адрес математической памяти.
Работа программы начинается с выборки команды по содержимому регистра указателя команд. Но, так как указатель содержит адрес математической памяти, а не физической, производится аппаратная коррекция этого адреса. Она заключается в сложении содержимого регистра указателя команд и регистра смещения.
После выборки и дешифрации команды, если это команда обращения к оперативной памяти, в команде содержится также адрес не оперативной памяти, а математической. Поэтому любой адрес обращения к оперативной памяти перехватывается и проходит процедуру преобразования адресов.
Этот механизм преобразования адресов имеет ряд недостатков. Он предполагает механизм распределения оперативной памяти массивами произвольной размерности, что приводит к дефрагментации памяти. Кроме этого, он не решает проблему построения памяти единого уровня.
В МП IA используется процедура трансляции сегментов, которая частично решает проблемы виртуальной памяти: разделение адресных пространств задач и автоматическое преобразование математического адреса в линейный адрес оперативной памяти. Но это не считается механизмом виртуальной памяти, В защищенном режиме, кроме трансляции страниц, возможно включение механизма классической виртуальной памяти – "процедуры трансляции страниц".
Страничная организации виртуальной памяти
В основе механизма классической виртуальной памяти лежит страничная организация математической оперативной памяти и, частично, памяти прямого доступа (памяти на магнитных дисках).
Страничная организация оперативной и математической памяти заключается в разбиении адресных пространств памяти на страницы, расположенные в целочисленных границах, т.е. размером, кратным степени числа два (основания системы счисления). Это обычная многомерная декартова система координат.
В МП IA-32 размер страницы выбран равным 212 = 4096 байт (4 Кб).
При этом старшие 20 разрядов адреса определяют номер страницы, а младшие 12 разрядов – номер байта в странице. Адресация информации на магнитных дисках имеет свои особенности. Минимальным блоком информации является сектор (на круговой дорожке) в 512 байт. Секторы объединяются в кластеры. Размер кластера зависит от системы разметки. Чаще всего используются кластеры размером в 4 Кб, т.е. равные странице оперативной памяти. В магнитных дисках используется файловая структура поиска. Для поиска информации на дисках имеется специальная FAT-таблица (File Allocation Table – таблица размещения файлов), в которой записаны имена файлов и список адресов расположения последовательностей кластеров на дорожках диска. Диски читаются не отдельными кластерами в произвольном порядке, а последовательно от начального кластера в файле до последнего. Но для организации виртуальной памяти требуется чтение страниц в произвольном порядке.
По этой причине часть дорожек магнитных дисков размечается на страницы с возможностью их чтения в произвольном порядке. То есть для части памяти на магнитных дисках формируют страничную структуру. Это область памяти, которую в технических описаниях обозначают как область ввода, обмена или область виртуальной памяти. По умолчанию операционная система назначает размер этой области равным трехкратной емкости оперативной памяти. Программно можно изменять размеры этой области.
Известны две схемы построения страничной виртуальной памяти:
на основе таблицы математических страниц,
на основе таблицы физических страниц.
Виртуальная память на основе таблицы математических страниц
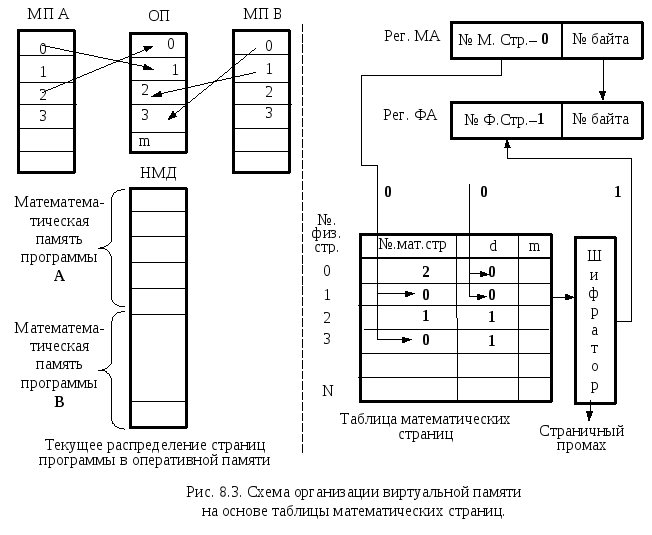
Схема построения виртуальной памяти на основе таблицы математических страниц представлена на рисунке. Это один из первых вариантов виртуальной памяти. Она была использована в ЭВМ "Атлас" (Англия).
ОП – страничная оперативная память, разбитая на страницы от 0 до m.
МП А – программа А, разбитая на страницы.
МП В – программа В, разбитая на страницы,
НМД – дисковая память, поддерживающая страничную структуру данных.
Изначально, программы А и В хранятся на магнитных дисках. При активизации этих программ, часть страниц по мере выполнения программы, переписывается в оперативную память.
Процедура переадресации программ производится следующим образом.
При обращении к памяти номер математической страницы из регистра математического адреса (Рег.МА) поступает в таблицу математических страниц. Таблица математических страниц строится на основе ассоциативной памяти. Входной адрес (из Рег.МА) параллельно сравнивается с содержимым всех строчек. Для представленного на рис. 8.3 примера совпадение фиксируется для первой и третий строчки, т.е. для всех совпадающих значений входного и записанных номеров.
Одновременно со сравнением номеров производится сравнение бита доступности (d). Выбирается строка с d=0.
Порядковый номер выбранной строки определяет номер страницы в оперативной (физической) памяти. Формирование этого номера реализуется шифратором.
Адрес обращения формируется на регистре физического контрактацией номера страницы с номером байта в странице.
При отсутствии совпадений в таблице фиксируется страничный промах, т.е. отсутствие страницы в оперативной памяти.
Страничный промах является стартовым сигналом свопинга с использованием прерывания (прерывания по страничному промаху).
Процедура свопинга
В таблице математических страниц всегда оставляется свободная строчка. В случае страничного промаха, в программе прерывания предусмотрена процедура переписи этой страницы из памяти на магнитных дисках (области ввода) в свободную область оперативной памяти. Эта процедура, в лучшем случае, по времени равняется одному обороту диска. В это время процессор определяет страницу-кандидата на удаление из оперативной памяти (устаревшую страницу). При этом используются различные алгоритмы определения устаревшей страницы.
После подкачки требуемой страницы процессор переключается на обработку команд прерванной программы, но в начале проверяется, была ли модификация данных удаляемой страницы. Если модификация была, то процессор активизирует устройство прямого доступа к памяти (ПДП) для сохранения данных этой страницы в памяти подкачки.
Таким образом, во время свопинга процессор не простаивает, а вычисляет адрес страницы-кандидата на удаление из оперативной памяти.
Рассмотренная система виртуальной памяти является полной. Она выполняет функции переадресации (реализует независимость подготовки программ) и свопинга (организации памяти единого уровня).
Недостатками этой системы виртуальной памяти являются использование не адресной, а более сложной ассоциативной памяти и выходного дешифратора.
Преимуществом этой системы виртуальной памяти является малый размер таблицы.
Количество строк таблицы физических страниц определяется емкостью не математической, а физической памяти. Но она почти во всех системах, за небольшим исключением (в моделях семейства PDP-11 емкость оперативной памяти в 4 раза больше емкости математической) использует неполный набор адресов по отношению к математической памяти, особенно, после того как стали использовать в качестве элементов памяти энергозависимые электронные схемы.
Упрощенная схема виртуальной памяти на основе таблицы физических страниц
Таблица физических страниц строится для каждой программы. В ней для каждой математической таблицы указаны номера физических страниц оперативной или внешней памяти на магнитных дисках.
Таблицы физических страниц составляются для каждой задачи. В каждой строке таблицы физических страниц содержится номер страницы физической памяти (оперативной памяти или на магнитных дисках). Страницы, расположенные в оперативной памяти, отмечаются признаком доступности d= 0, а расположенные на магнитных дисках –d= 1.
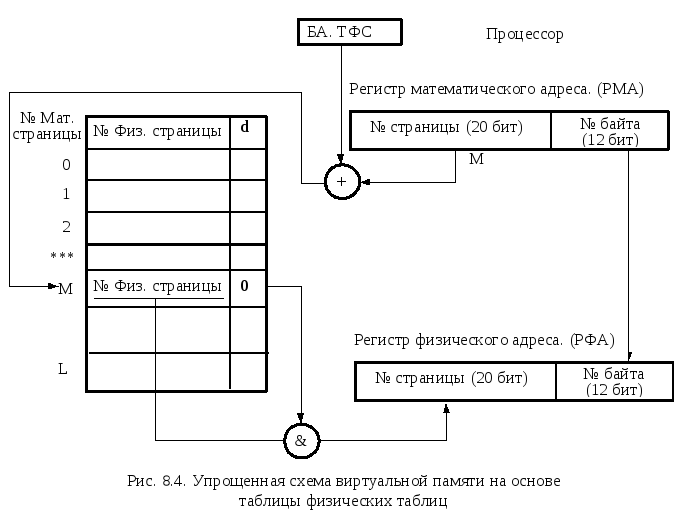
Для привязки таблиц к задачам используется регистр базового адреса таблицы физических страниц (БА ТФС), индивидуальный для каждой задачи.
Процедура трансляции страниц имеет следующие этапы:
1. Вычисление адреса обращения к строке таблицы сложением номера страницы математического адреса с базовым адресом таблицы физических таблиц (БА ТФС).
2. Чтение по вычисленному адресу из таблицы физических страниц значения адреса физической памяти и бита доступности (d=0).
3. В случае доступности данных (d=0) – обращение по физическому адресу с учетом номера байта внутри страницы данных для записи или чтения в зависимости от кода операции.
4. В случае страничного промаха (d=1) – свопинг данных, коррекция таблицы и повтор обращения к данным.
Рассмотренная схема проста, использует адресную память, но имеет серьезные недостатки. Эти недостатки связаны с местом хранения таблиц.
В 32-разрядных ЭВМ максимальная емкость памяти может достигать величины 232 = 4 Гбайта, а количество математических страниц 220 = 1М. С учетом 20-разрядного адреса строки физического адреса и дополнительных управляющих разрядов строка должна содержать 4 байта, общая емкость памяти для хранения таблицы только одной программы составляет 224 = 4 Мбайта. Для первых ЭВМ, использовавших виртуальную память, это было значительной величиной, чтобы хранить таблицы десятков программ в процессоре или в оперативной памяти.
Для построения виртуальной памяти стали использовать довольно сложную систему виртуальной памяти с хранением таблиц физических страниц на магнитных дисках.
Каждая из задач может использовать весь объем адресного пространства сегмента (4Гбайт). Максимальное количество физических страниц (по 4 Кбайт) в полном сегменте составляет 1Мбайт. Каждая строчка таблицы физических страниц должна содержать 4 байта (20 бит номера физической страницы, бит доступности и дополнительная информация для меток разрешения модификации страницы и вычисления устаревших страниц). Таким образом, размер таблицы физических страниц только одного сегмента программы может составлять 4 Мбайт. Это было слишком много для размещения таблиц в процессоре или в оперативной памяти первых ЭВМ. По этой причине таблицы физических страниц хранятся в памяти на магнитных дисках, и их применение связано с разбиением таблиц на более мелкие участки (разделы) и с использованием операций ввода/вывода.
Таблицы физических страниц делятся на разделы (до 1024 разделаов по 1024 страницы в разделе).
В оперативной памяти размещаются только части таблиц. В минимальном варианте – каталог и по одному разделу таблицы физических страниц. Каталог – это таблица размещения разделов в памяти на магнитных дисках и их копий для выбранных в оперативную память страниц.
Таблица каждого раздела содержит 1024 строчек по четыре байта, т.е. занимает 4096 Кбайт (одну страницу виртуальной памяти). В строчках таблицы разделов фиксируются физические номера страниц раздела, признак доступности (размещение в оперативной памяти или памяти на магнитных дисках) и дополнительная информация. Признак доступности, равный нулю, означает расположение копии страницы в оперативной памяти и на магнитных дисках, единице – только в памяти на магнитных дисках (в области ввода).
Каталог разделов содержит 1024 строчки (по числу разделов математической памяти). В каждой строке каталога содержится базовый адрес таблицы физических страниц, признак доступности и дополнительная информация (модификации активности и т.д.). Признак доступности, равный нулю, означает расположение раздела таблицы физических страниц в оперативной памяти, единице – в памяти на магнитных дисках (в области ввода).
Одновременно в оперативной памяти должны находиться каталоги и таблицы физических разделов для всех задач. При переключении задач должны активизироваться каталоги и таблицы физических страниц новых задач. Для этого процессор содержит регистр базового адреса таблицы физических страниц БА ТФС. При каждом переключении задач в него записывается базовый адрес каталога новой задачи.
Вопросы и/или темы для самопроверки:
Проблемы переадресации программ.
Проблема свопинга.
Память единого уровня.
Страничная организация памяти.
Использование регистра базового адреса таблицы физических таблиц.
Страничный промах.
Основные биты строк TLB.
Алгоритм листания.
11 неделя. Лекция 11 (2-е Тестирование и лекция)
Органитзация виртуальной памяти.
Работа схемы.
Схема преобразования адресов содержит два регистра адресов: регистр математического адреса (РМА) и регистр физического адреса (РФА).
Регистр математического адреса содержит три поля: номер раздела, номер страницы и номер байта.
Регистр физического адреса содержит два поля: номер страницы и номер байта.
Для преобразования математического адреса в физический адрес номер раздела (М) из регистра РМА складывается с базовым адресом каталога из регистра БА ТФС (в МП IA-32 – это CR0) и производится обращение к оперативной памяти по сформированному адресу.
Обращение производится к строке М каталога, в которой записан адрес таблицы физических страниц раздела М и признак доступности. При нулевом значении признака доступности адрес таблицы физических страниц складывается с номером страницы математических страниц (N) и производится второе обращение к оперативной памяти по сформированному адресу.
Обращение производится к странице N раздела М таблицы математических страниц, в которой записан двадцатиразрядный физический адрес страницы и признак доступности. При нулевом значении признака доступности выбранный номер физической страницы фиксируется в регистре физического адреса, где к нему добавляются двенадцать разрядов номера байта, и производится третье обращение к оперативной памяти для выборки команды или данных.
В случае обнаружения отрицательного (единичного) признака доступности, производится прерывание по страничному промаху. Программа прерывания реализует процедуру листания (замену таблицы раздела или физических страниц с сохранением в памяти на магнитных дисках модифицированных страниц).
Рассмотренный алгоритм работы виртуальной памяти предусматривает три обращения к оперативной памяти: за адресом раздела, за адресом страницы и за операндом. Это недопустимо много.
Для увеличения быстродействия в механизм виртуальной памяти вводят буфер быстрой переадресации (TLB). Это набор регистров со схемами ассоциативного доступа.
Каждый регистр имеет три поля:
номера математической страницы (20 бит),
номера физической страницы (20 бит),
дополнительной информации.
Буфер быстрой переадресации обновляется при каждом обращении к каталогу и таблицам раздела физических адресов. Номер раздела M, номер математической страницы N и номер физической страницы сохраняются в свободном регистре буфера быстрой переадресации.
При каждом обращении к оперативной памяти проверяют наличие номеров математических страниц в буфере быстрой переадресации. При их наличии, номера физических страниц выбираются непосредственно из TLB.
В буфере быстрой переадресации реализован ассоциативный поиск информации по совпадению входной информации с содержимым полей номеров страниц математической памяти MN. На рис. 8.5 строка с совпадением информации отмечена затемнением.
Буфер быстрой переадресации расположен непосредственно в процессоре, и потери времени на процедуру переадресации соизмеримы с тактом работы процессора.
Одна страница (4 Кбайт) содержит 1024 двойных слова. С учетом локальности обращений (по времени и расположению) к командам программ и данным существует большая вероятность повторных обращений к этой же странице даже более 1024 раз. Но на первое обращение к данным и командам в новых страницах требуется до трех обращений к памяти, на остальные (1024) – по одному.
При переключении задач содержимое TLBдолжно сбрасываться, так как номера математических страниц в разных задачах могут совпадать.
В оперативной памяти для каждой задачи должны быть сформированы две таблицы: таблица каталога и таблица физических страниц одного раздела. Обмен страниц (подкачка данных и программ из внешней памяти в оперативную память и сохранение модифицированной информации) производится постранично.
Это относится и к страницам программных кодов, данных и управляющей информации (каталоги программ, таблицы физических страниц, строки TLBи т.д.). Сохранение в оперативной памяти "устаревших страниц" производится только для модифицированных страниц. СтрокиTLB, кроме полей номеров математической и физической страниц, содержат дополнительное поле. Информация этого поля используется в процедурах смены страниц (листания).
Основными битами этого поля являются:
d– бит присутствия страницы в оперативной памяти;
r – бит (обращения) к странице, используется при выборе кандидата на удаление из оперативной памяти;
m– бит модификации (записи) страницы, определяет необходимость сохранения содержимого страницы при удалении из оперативной памяти;
W– признак прав доступа по записи, определяет разрешение операции модификации данных в странице.
Алгоритмы листания
Это алгоритм определения страницы-кандидата на удаление из оперативной памяти при страничном промахе и загрузке новой страницы. В идеальном случае для минимизации процедур листания при страничных промахах из оперативной памяти должна удаляться страница, вероятность обращения к которой не больше, чем к любой другой странице.
В настоящее время наработано множество реализуемых алгоритмов листания. Наиболее известными из них являются алгоритмы:
случайного замещения,
удаления страницы, дольше других находившейся в ОП,
удаления страницы, меньше других находившейся в ОП,
удаления страницы из последней позиции в списке страниц, причем, при каждом обращении к странице ее место в списке перемещается на одну позицию к началу списка (алгоритм "карабкающейся страницы"),
Наиболее известными являются варианты алгоритма "рабочий комплект".
В этом алгоритме задается определенный интервал времени, например, 1024 машинных такта. При каждом обращении к странице (по записи или чтению) страница помечается. Помеченные страницы образуют рабочий комплект. Состав рабочего комплекта может изменяться в последующих интервалах. Страницы, вышедшие из рабочего комплекта, образуют две очереди кандидатов на удаление: модифицированных (было обращение по записи) и не модифицированных в течение их нахождения в ОП. Кандидатами на удаление из ОП являются страницы из этих очередей с приоритетом у модифицированных страниц.
Организация виртуальной памяти в микро ЭВМ на основе МП i8х86
В МП этих архитектур можно выделить по режимам работы четыре программные модели:
реальный режим шестнадцатиразрядного микропроцессора МП i8086,
защищенный режим работы,
реальный режим тридцатидвухразрядного микропроцессора,
виртуальный режим 86.
Реальный режим шестнадцатиразрядногомикропроцессора МП i8086
Это основной режим 8-и 16-разрядных первых персональных ЭВМ, программно совместимых с IBM PC (режим МП IA-16).
Защищенный режим работы
Это основной 32-разрядный режим работы для 32-разрядных микропроцессоров МП IA (Intel архитектуры). В этом режиме доступны все команды и все архитектурные возможности. Используется механизм виртуальной памяти, все встроенные средства защиты, процедура переключения задач (режим МП IA-32). Дополнительными режимами для них являются реальный и виртуальный 86 (режим V86).
Реальный режим 32-разрядного микропроцессора
Это 16-разрядный режим адресации и обработки данных с прямым обращением к памяти. Режим эмулирует программную среду (модель) МП 8086 с некоторыми дополнительными возможностями, включая новые РОНы, часть новых команд и расширений как адресов, так и данных. Но в любом случае, 32-разрядное смещение в сегменте не должно превышать значения 65 535 (64 Кбайт).
При запуске или перезагрузке МП устанавливается именно реальный режим. Он используется для подготовки программной среды для работы в защищенном режиме.
Виртуальный режим 86
Это разновидность формы эмуляции модели 8086. Здесь нет прямой адресации памяти. В этом режиме применяются механизмы защиты и виртуальной памяти. Виртуальный режим 86 устанавливается из защищенного (для запуска программ, написанных для реального режима) с возможностью возврата в защищенный режим.
Одна из особенностей МП Intel – это использование сегментированной памяти. 16-разрядная адресация позволяла адресовать только 216 = 65 536 байт (64 Кбайт). Модель структурированной математической памяти, состоящая из 16 сегментов по 65 536 байт (64 Кбайт), позволил увеличить адресное пространство математической памяти в реальном режиме до 220 = 1 048 576 (1 Мбайт).
Дескрипторы сегментов. В реальных режимах МП IA-16 и МП IA-32, сегментные регистры содержат непосредственно базовый адрес сегмента.
В защищенном режиме МП IA-32 задание сегментов производится с использованием специальных программных объектов – дескрипторов сегментов.
Дескриптор сегмента является 64-битовым поисковым образом сегментов. Дескриптор сегмента определяет тип сегмента, расположение в памяти (базовый адрес и размер), права доступа и использования.
Основными полями дескрипторов являются:
базовый адрес сегмента (32 бита),
размер сегмента (20 бит),
поле атрибутов (12 бита).
Поле атрибутов содержит:
бит дробности G(Granularity– 4 разряда),
тип сегмента,
настройки прав доступа и использования (8 разрядов).
На рис биты полей дескрипторов для наглядности сгруппированы в отдельные массивы смежных адресов.
-
63
32
31
12
11
8
7
0
Базовый адрес сегмента (B)
Предел (L)
Атрибуты
AR
G
G
P
DPL
S
Type(4бита)
Рис.3.8. Структура дескриптора сегмента
Дескрипторы шлюзов программ
Шлюзы (Gate) – это точки входа в программы (программный сегмент). В МП IA-32 вызов процедур операционной системы (передача управления с повышением уровня привилегий) производится только с использованием шлюзов и только по командам передачи управления с возможностью возврата (запрещено использование команды Jmp).
Дескриптор шлюза программных сегментов содержит три поля:
селектора сегмента,
смещения в сегменте (offset),
атрибутов.
|
63 |
48 |
47 |
16 |
15 |
|
0 | |||||||||
|
Селектор |
Offset (Смещение в сегменте) |
Атрибуты | |||||||||||||
|
|
|
|
|
| |||||||||||
|
Индекс(13 бит) |
G/L |
RPL (2 бита) |
|
Счетчик двойных слов |
P |
DPL |
0 |
Тип (4бита) |
| ||||||
|
Структура дескриптора шлюза программных сегментов. |
| ||||||||||||||
Селектор сегмента
Все дескрипторы, кроме дескрипторов прерываний (дескрипторы сегментов, задач, шлюзов сегментов или задач), хранятся в оперативной памяти в специальных таблицах GDT (глобальная таблица дескрипторов) и LDT (локальная таблица дескрипторов).
В глобальной таблице дескрипторов хранятся все сегменты операционной системы.
Локальные таблицы дескрипторов формируются на каждую задачу (программу, находящуюся в стадии исполнения, возможно, с разделением по времени). Но в каждый момент времени активны только две таблицы: GDT и одна из LDT. Обращение к таблицам производится по селектору сегмента.
Селектор сегмента определяет дескриптор используемого кодового сегмента, т.е. целевой сегмент. Селектор сегмента содержит следующие поля:
индекс (13 бит) – используется как адрес в таблице целевого дескриптора (указателя "целевой" строки таблицы дескрипторов),
бит типа "целевой" таблицы дескрипторов; при нулевом значении G/L – выбирается GDT, иначе LDT,
поле уровня привилегии запроса (в рассматриваемой конструкции не используется).
Смещение в сегменте (offset)
Смещение в сегменте в программных сегментах определяет точку входа в сегмент. (По селектору дескриптора шлюза определяется целевой кодовый сегмент, а по смещению в сегменте – адрес первой команды).
Атрибуты сегмента
Атрибуты сегмента определяют тип сегмента, права использования, доступность программной процедуры по уровням привилегий, а также задают размер параметров, передаваемых в процедуру через стек.
Вопросы и/или темы для самопроверки:
Максимальный размер сегмента в МП IA-32.
Максимальное количество сегментов в МП IA-32.
Чем определяется максимальное количество сегментов в МП IA-32.
Максимальный размер математической памяти сегментов в МП IA-32.
Максимальный адрес обращения к оперативной памяти без использования трансляции страниц.
Назначение дескрипторов
Таблица GDT
Таблица LDT
12 неделя
Организация кэш-памяти
Назначение и общая схема подключения кэш-памяти
Кэш-память – это промежуточная память между оперативной памятью и процессором.12 неделя
Основной целью использования кэш-памяти в ЭВМ является согласование полосы пропускания оперативной памяти и процессора. Полоса пропускания определяется количеством передаваемых бит за единицу времени (количество передаваемых бит на частоту передачи).
В современных ЭВМ быстродействие процессоров (количество выполняемых команд за единицу времени) в десятки раз превышает потока данных обмена с оперативной памятью.
Оперативная память большой емкости принципиально не может работать на тактовой частоте процессора. Основная проблема – большие задержки при выборке информации.
Информационный поток данных определяется количеством подаваемых или обработанных данных за единицу времени.
Для простоты рассмотрим работу процессора с одноадресной системой команд. В этом варианте выполнение одной команды связано с одним обращением к оперативной памяти по чтению или записи операнда.
Пусть процессор за такт (t) выполняет одну команду с формированием одного результата в формате двойного слова (4 байта), а обращение к оперативной памяти по чтению или записи составляет 4 такта процессора.
Очевидно, что в этом случае полосы пропускания процессора и оперативной памяти не совпадают, что приводит к простою процессора по 3 такта из четырех. Для согласования информационных потоков увеличивают ширину обращения к памяти. Например, можно при обращении к памяти производить чтение не одного двойного слова (4 байта), а строку из четырех двойных слов (16 байт). Простейший вариант этого решения представлен на рис. 9.3.
Эффективность этого решения основывается на статистической локальности обращений к памяти по месту и времени. Это означает, что существует большая вероятность того, что обращения к памяти в локальный промежуток времени с большой вероятностью будут производиться в локальный участок адресов памяти.
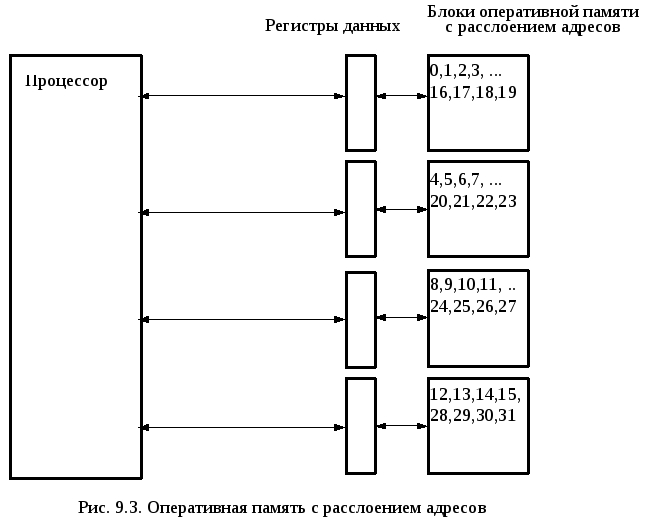
Здесь важно, что память разбивается на несколько блоков с обязательным расслоением адресов. Расслоение адресов (интерливинг) означает, что последовательность адресов двойных слов располагается в независимых блоках памяти.
Но это еще не кэш-память, а просто выборка данных с упреждением.
Проблема решается введением множества регистров, по одному для множества чтений из памяти, т.е. использованием дополнительной памяти, но уже на основе статических регистров, расположенных как можно ближе к процессору или в самом процессоре.
Важность расположения кэш-памяти в процессоре определяется тем, что в этом случае она может использовать тактовую частоту процессора, а не материнской платы.
Дополнительной проблемой для кэш-памяти остается задержка первого чтения строки данных из оперативной памяти. Но и эта проблема в современных ЭВМ решается разделением команд на команды действия и команды обращения к памяти.
Команды действия – это команды типа регистр/регистр, без обращения к оперативной памяти.
Команды обращения к памяти – это команды только обращения к оперативной памяти по чтению или записи (загрузки данных в РОН или сохранения данных в ячейке памяти).
Проблема задержек при первом обращении к памяти может решаться вынесением команд загрузки данных вперед на несколько команд до их исполнения.
Системы адресации кэш-памяти
При обращении к оперативной памяти процессор указывает в качестве критерия поиска адрес данных в оперативной памяти. Контроллеру кэш-памяти при перехвате обращения к оперативной памяти этот адрес становится доступным. При первом обращении к конкретному слову данных, контроллер кэш-памяти его не обнаружит. Это кэш-промах. В этом случае запрос процессора обслужит оперативная память, но выбрано будет не одно заданное двойное слово, а вся строчка, например, четыре двойных слова, причем, в целочисленных границах строки. Вся строка будет записана в кэш-памяти, а затребованное двойное слово будет отправлено в процессор.
Здесь встает проблема адресации ячеек строк данных в кэш-памяти. Адресация строк данных в кэш-памяти должна допускать нахождение данных по адресам двойных слов (тегов) в оперативной памяти.
В настоящее время широко известны три схемы адресации, удовлетворяющие этому требованию. Это системы адресации на основе:
аппаратной ассоциативной выборки,
адресации с прямым отображением адресов,
множественно-ассоциативной выборки.
Организация кэш-памяти на основе ассоциативной выборки
В ядро кэш-памяти входят:
ассоциативная память тегов со схемами параллельного сравнения входного слова (адреса данных в оперативной памяти) с тегами,
схемы обнаружения кэш-промаха,
регистры хранения строк данных,
регистр команд обращения процессора к оперативной памяти,
дешифратор адреса двойного слова в строке кэш-памяти,
входные/выходные усилители и вентильные схемы.
При включении процессора строки адресных тегов и данных не заполнены. При первом же обращении процессора к памяти, например по чтению, контроллер кэш-памяти проверяет присутствие запрашиваемых данных в кэш-памяти. Для этого адрес строки оперативной памяти (старшие 24 бита адреса данных в оперативной памяти) сравнивается со всеми адресами строк, записанными в памяти в качестве тегов поиска. Если совпадений нет, то:
фиксируется кэш-промах,
производится обращение к оперативной памяти,
читается и записывается в схемы хранения строк данных вся строчка (8 байт), по любому свободному адресу, а адрес строки – в соответствующую ячейку поисковой части ассоциативной памяти,
запрашиваемые данные (слово или двойное слово) пересылаются в процессор,
дополнительная информация (например, биты присутствия, модификации операцией записи и т.д.).
Повторное обращение к данным из этой же строчки производится уже без обращения к оперативной памяти.
Первоначальное заполнение памяти при промахах может производиться в любом порядке. При полном заполнении кэш-памяти, новые строчки данных, как и при использовании виртуальной памяти, записываются с использованием алгоритмов листания. Для реализации алгоритмов листания каждая строка данных имеет поле дополнительной информации, в котором отмечаются обращения и типы обращения (по чтению или по записи).
Ассоциативная память широко использовалась до появления интегральной технологии.В современных ЭВМ кэш-память размещают на одной микросхеме с процессором, в этом случае количество выводов микросхемы определяется не кэш-памятью, а интерфейсом процессора. Но и в этом случае использование чисто ассоциативной памяти ограничено.
Организация кэш-памяти с прямым отображением адресов
Основная идея кэш-памяти с прямым отображением – это нахождение функциональной зависимости адресов кэш-памяти от адресов оперативной памяти:
Адрес кэш-памяти = f (адрес оперативной памяти).
Используя свойство локальности обращений программ к памяти по времени, используют функцию прямого отображения.
Функция прямого отображения заключается в выделении младших разрядов аргумента. Количество выделяемых разрядов определяется емкостью кэш-памяти, вернее, количеством строк в кэш-памяти.
Для сохранения каждой строки оперативной памяти определена единственная строка кэш-памяти. Это строка, адрес которой совпадает с адресом, составленным из старших цифр адреса этой строки в оперативной памяти.
Но по этим же адресам могут быть записаны данные из множества строк оперативной памяти, адреса которых различаются младшими разрядами. При максимально возможной емкости оперативной памяти (равной математической) количество совпадающих строк может быть равным 217.
Для идентификации строк в старшие разряды строк кэш-памяти записываются "идентифицирующие" теги, равные (по численному значению) старшим разрядам адреса оперативной памяти.
При обращении к кэш-памяти старшие разряды адреса строк оперативной памяти сравниваются с тегами на внешних схемах сравнения. При несовпадении этих строк фиксируется кэш-промах, при совпадении – фиксируется попадание. При кэш-попадании данные (двойное слово) выбираются из кэш-памяти по адресу двойных слов в строке с использованием дешифратора.
Таким образом, здесь используется тройная адресация: адресация строки кэш-памяти по младшим разрядам адреса оперативной памяти, ассоциативный поиск по сравнению старших разрядов адреса оперативной памяти с тегами и для выбора двойного слова из строки кэш-памяти.
Организация кэш-памяти на основе множественно-ассоциативной памяти
Это модификация поиска с прямым отображением адресов. В этой схеме отображение адресов оперативной памяти в адреса кэш-памяти производится не для одной строки (кэш-памяти), а для множества строк, имеющих совпадения в младших разрядах их адресов в оперативной памяти.
Правомерна и другая интерпретация этой схемы как множеств отдельных блоков памяти с ассоциативным поиском информации, но с адресной выборкой "целевого" блока.
В этой схеме для строк оперативной памяти с совпадающими значениями младших разрядов оперативной памяти определена для сохранения не единственная строка кэш-памяти, а множество строк, кратное степени двух: два, четыре или восемь, наиболее часто – четыре.
Режимы работы кэш-памяти
Все преимущества в использовании кэш-памяти относятся, в основном, к операциям чтении информации. При выполнении операций записи процессор передает в контроллер памяти команду записи и записываемые данные.
При записи с использованием кэш-памяти возможны различные варианты выполнения операции записи в зависимости от ситуации (кэш-промах или кэш-попадание).
При кэш-попадании возможны следующие процедуры записи:
сквозная запись,
обратная запись.
Процедура сквозной записи. Запись данных производится в оперативную память и, одновременно, в строку кэш-памяти. При этом строки (в кэш-памяти и оперативной памяти) помечаются битом "модифицированные". Эти признаки учитываются при удалении страниц из строки кэш-памяти (в оперативную память) или страницы из оперативной памяти (в накопитель на магнитных дисках). Сквозная запись гарантирует нахождение в оперативной памяти "более свежей" копии данных, но без использования буферизации данных приводит к задержкам процессора.
Процедура обратной записи
При обратной записи запись данных производится только в строки кэш-памяти. Обновление данных в оперативной памяти по адресам записи откладывается до замещения модифицированной строки. Замещение строки производится, если страница признается "устаревшей" алгоритмом "листания".
При кэш-промахах возможны следующие процедуры записи:
сквозная,
сквозная с размещением.
Сквозная запись
При кэш-промахе, размещение новой информации связано с освобождением одной из строк (признанной устаревшей) кэш-памяти. Чтение записываемых данных в ближайший промежуток времени после их записи маловероятно. Сквозная запись производится, минуя записи в кэш-память. Записанная информация становится доступной при чтении, через кэш-пр омах при чтении и обновлении информации в кэш-памяти. Сквозная запись не затрагивает кэш-память и оптимизирует очередь обращений к ней.
Обычно в кэш-памяти со сквозной записью при промахе используется и сквозная запись при кэш-попадании.
Сквозная запись с размещением (в кэш-памяти)
Запись производится в кэш-память и в оперативную память. Этот вид записи может быть полезен в многопроцессорных многозадачных системах с общей оперативной памятью, но разделенными системами кэш-памяти.
Иерархическая структура кэш-памяти
Проблема согласования плотности потоков информации при больших отношениях быстродействии процессора и оперативной памяти решается многоуровневой системой кэш-памяти с расширениями строк при обращениях к блокам кэш-памяти на более высоких уровнях.
При этом, часть уровней кэш-памяти интегрируется в микросхему процессора, а более дальние уровни размещаются на материнской плате.
При этом кэш-память первого уровня может работать на частоте процессора, второго уровня – с потерей от четырех до девяти тактов процессора, а третьего уровня, расположенная на материнской плате, с потерей значительного большего числа тактов, зависящей от тактовой частоты материнской платы.
Средства управления кэш-памятью
Рассмотрим основные возможности управления функционированием кэш-памяти на примере МП i486.
Процессор i486 имеет встроенную в микросхему внутреннюю множественно-ассоциативную кэш-память для хранения 8Кбайт команд и данных. Предусмотрено использование и внешней кэш-памяти.
Работа внутренней и внешней кэш-памяти прозрачна для прикладного программного обеспечения, но знание их поведения может быть полезным с точки зрения оптимизации быстродействия программного обеспечения.
Кэш-память доступна во всех режимах работы: реальном режиме, защищенном режиме и виртуальном режиме 8086.
Размер кэш-строки в процессоре i486 равен четырем двойным словам (8 байт). Допускается кэширование со сквозной записью и с обратной записью. При кэшировании со сквозной записью обновляется кэш-память и внешняя память. Кэширование с обратной записью обновляет только кэш-память, внешняя память обновляется только при выполнении операции обратной записи. Операции обратной записи запускаются при необходимости отменить распределение строк кэш-памяти, например, при кэш-промахах.
Программное обеспечение управляет режимом работы кэш-памяти. Кэширование может быть разрешено или запрещено. В последнем случае кэш-память может работать как внутренняя сверхоперативная память при существовании достоверных строк кэш-памяти, или кэширование может быть запрещено полностью при установке управляющих бит в единичное состояние и очищенных (нераспределенных) ячейках хранения данных.
Организация когерентности системы кэш-памяти в многопроцессорных системах с общей оперативной памятью.
Наибольшая эффективность использования кэш-памяти достигается при использовании обратной записи.
Проблема когерентности (согласованности) первичных модулей кэш- памяти возникает в многопроцессорных системах при параллельной обработке массивов разделяемых данных, именно при использовании обратной записи. Но при записи данных одним процессором с обратной записью, данные в оперативной памяти и, возможно, в локальных модулях других процессоров становятся устаревшими, т.е. нарушается когерентность данных кэш-памяти с данными не только в оперативной памяти, но и с данными в кэш-памяти других процессорах.
Проблема когерентности памяти для мультипроцессоров и устройств ввода/вывода имеет много аспектов. Обычно в малых мультипроцессорах системах используется аппаратный механизм, позволяющий решить эту проблему при помощи протоколов наблюдения. Существуют два класса таких протоколов:
Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии.
Вопросы и/или темы для самопроверки:
Природа основных задержек при обращении к оперативной памяти.
Механизм считывания информации из ячейки динамической памяти.
Взаимодействие устройств: процессор – оперативная память – кэш-память.
Взаимодействие устройств в системе: процессор, кэш-память, оперативная память.
Поисковый адрес данных, используемый при обращении к кэш-памяти.
Кэш-память на основе ассоциативного поиска.
Алгоритм определения множества-кандидата на удаление.
Замораживание данных в кэш-памяти для обеспечения гарантийного кэш-попадания для кодов и данных, критичных к времени доступа
Неделя 13. Лекция 13
Шинные интерфейсы
Общие положения
Интерфейсом называется стандартное сопряжение объектов для обмена данными. Это очень широкое понятие. В понятие интерфейс входит множество средств обмена информацией: разговорный язык, письменность, живопись и т.д. В ЭВМ используется целый ряд интерфейсов. Это – экранный интерфейс (человек – ЭВМ), аппаратный (сопряжение между блоками), программный (сопряжение между программными блоками) и т.д.
В настоящем разделе рассматривается только стандартное аппаратное сопряжение для обмена данными с использованием шин.
Шинные интерфейсы определяются тремя стандартами:
стандарт на провода
стандарт на передаваемые сигналы,
стандарт на протоколы передачи данных.
Стандарты на провода
Стандарты на провода определяют их количество, размеры, электрические параметры, назначение (заземления, сигнальные, экранирующие и т.д.).
Стандарты на передаваемые сигналы
Стандарты на передаваемые сигналы определяют тип модуляции сигналов (импульсные, частотные), полярность, параметры частот, ограничения на фронты, амплитуды и т.д.
Стандарты на протоколы
Стандарты на протоколы определяют:
семантику комбинаций сигналов,
протоколы передачи.
Семантика определяет смысловое значение передаваемых комбинаций сигналов.
Протоколы передачи определяют допустимые последовательности комбинаций сигналов приказов, их смысловое значение и возможные комбинации ответов (допустимых комбинаций приказов и ответов).
Основное назначение интерфейсов – организация структур вычислительных систем с переменной конфигурацией. В первую очередь, это возможность замены и наращивания парка периферийных устройств. По этой причине первыми интерфейсами стали интерфейсы ввода/вывода.
Но уже модели первого семейства мини-ЭВМ (PDP-11) использовали системный интерфейс "Общая шина" (Unibas) для более удобного конфигурирования всей системы. Первые микро-ЭВМ также использовали системные интерфейсы ISA (EISA).
Шинные интерфейсы могут быть:
по способам соединений – индивидуальными и общими,
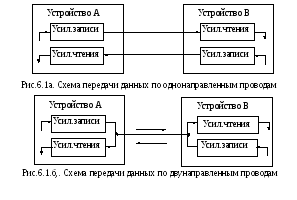
по способам передачи информации по проводам – однонаправленными и двунаправленными,
по способам синхронизации – синхронными и асинхронными.
По способам соединений наиболее популярно использование общих для всех устройств шин. Использование индивидуальных шин повышает производительность передач, но усложняет интерфейс и используется только для связи ведущего устройства с ведомыми и только в исключительных случаях.
Использование однонаправленных проводов повышает производительность интерфейса за счет совмещения передач, но по ряду других параметров уступает использованию двунаправленных. В интерфейсах однонаправленные провода используются только для передачи индивидуальных сигналов, например, сигналов прерывания от периферийных устройств.
Использование способа синхронизации зависит от заданного быстродействия, протяженности интерфейсных проводов и разброса в быстродействии устройств источника и приемника. При больших расстояниях передачи и низком быстродействии устройств обычно используют асинхронные интерфейсы, при малых расстояния – синхронные.
В любой момент времени на шинном интерфейсе возможна передача данных только между двумя устройствами. Одно из них является ведущим, другое – ведомым. Ведущее устройство определяет ведомое устройство и направление передачи.
Эти устройства могут иметь разное быстродействие. Одна из задач протоколов интерфейса – обеспечить корректную передачу данных даже при разном быстродействии устройств.
При этом могут использоваться два типа протоколов: синхронный и асинхронный. Синхронный протокол отличается от асинхронного тем, что в синхронном протоколе используется общая система синхронизации, которая отсутствует в асинхронном протоколе. В синхронном протоколе все сигналы привязываются к синхроимпульсам. По этой причине он проще в реализации, но рассчитан только на передачу данных на сравнительно короткие расстояния.
В асинхронном протоколе корректность передачи данных обеспечивается путем сопровождения каждого этапа передачи специальными сигналами (стробами и квитанциями).
Вопросы и/или темы для самопроверки:
1. Определение интерфейса.
2. Стандарты на провода.
3. Стандарты на передаваемые сигналы.
4. Стандарты на протоколы.
5. Синхронные и асинхронные интерфейсы.
Неделя 14. Лекция 14
Организация асинхронного системного интерфейса мини ЭВМ "Общая шина" (PDP - 11)
С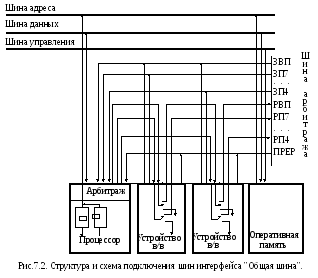 истемный
интерфейс "Общая шина" был разработан
для семейства программно совместимых
(от микро- до супермини-) ЭВМ "PDP-11"
корпорации DEC.
истемный
интерфейс "Общая шина" был разработан
для семейства программно совместимых
(от микро- до супермини-) ЭВМ "PDP-11"
корпорации DEC.
Это первая попытка создания единого стандартного интерфейса для связи всех компонентов вычислительной системы, т.е. создания системного интерфейса.
Интерфейс "Общая шина" содержит 56 проводов, максимальная длина которых 15 метров. По способу передачи информацииэто асинхронный интерфейс.
Все провода интерфейса делятся на две секции:
передачи данных,
арбитража.
Секция передачи данных предназначена для организации сеансов связи (транзакций) для передачи данных.
Секция арбитража предназначена для выбора "задатчика".
Обе секции работают параллельно. Во время сеанса передачи данных при помощи сигналов на проводах секции арбитража выбирается устройство-задатчик для следующего сеанса.
Шины секции передачи данных
Шинами секции передачи данных являются:
шина адреса – 18 проводов, которые используются для выбора исполнителя,
шина данных – 16 проводов,
шина управления.
В состав шины управления входят провода:
кода операции – 2 провода: У0, У1 (задают тип передачи: чтение, запись байта, запись слова);
контрольных разрядов – 2 провода: К0, К1 (используются для передачи контрольной информации);
занято – 1 провод, активный сигнал которого указывает, что секция занята для сеанса связи;
СИЗ (синхроимпульс задатчика) – 1 провод (используется для передачи сигнала-строба от задатчика);
СИИ (синхроимпульс исполнителя) – 1 провод (используется для передачи сигнала-строба от исполнителя).
Секция арбитража
В секцию арбитража входят провода для передачи сигналов:
запрос внепроцессорных передач (ЗВП) – 1 провод от устройств к процессору (используется для передачи запроса на шину для осуществления внепроцессорных передач);
разрешение внепроцессорных передач (РВП) – 1 провод от процессора к устройствам (используется для выбора задатчика на следующий сеанс связи для осуществления внепроцессорных передач);
запросы прерывания (ЗП-i, ) 4, 5, 6 и 7 уровней – 4 провода от устройств к процессору (используются для передач запросов на шину для передачи прерывания);
разрешение прерываний (РП-i) 4, 5, 6 и 7 уровней – 4 провода от процессора к устройствам (используются для выбора задатчика на следующий сеанс связи для передачи прерывания);
подтверждение выборки (ПВб) – 1 провод от устройств к процессору (используется для ответного сигнала получения разрешения захвата шины устройством для передачи адреса вектора прерывания или для осуществления внепроцессорных передач);
прерывания (ПРЕР) – 1 провод от устройств к процессору (используется для передачи сигнала-строба при передаче адреса вектора прерывания).
Кроме этого интерфейс содержит 4 специальных провода от процессора к устройствам для передачи сигналов: подготовки (ПОДГ), разрешения смены состояния (СМС), аварии источника питания (АИП) и аварии системы питания (АСП).
Любое устройство, кроме памяти и процессора, может быть как задатчиком, так и исполнителем. Процессор может быть только задатчиком, а память – только исполнителем. Чтобы быть задатчиком, устройство должно иметь соответствующие схемы и быть подключенным к шинам арбитража. Для работы в режиме внепроцессорных передач устройство должно быть подключено к проводам запроса (ЗПВ) и разрешения внепроцессорных передач(РПВ).
Для возможности использования системы прерывания устройство должно быть подключено к одной из пар шин запросов (ЗПi, где i – 4, 5, 6 или 7) и разрешения (РПi) прерываний. При этом запрос внепроцессорных передач имеет наивысший (восьмой) уровень приоритета на захват шины, а запрос прерывания (ЗП4) – наименьший (четвертый) уровень приоритета.
Провода сигналов разрешения внепроцессорных передач (РВП) и прерываний 7 – 4 уровней проходят последовательно от процессора через все устройства, использующие систему прерывания и/или использующие внепроцессорные передачи.
Если устройство делает запрос на внепроцессорные передачи или на прерывание, то оно разрывает соответствующую линию разрешения, переключая ее на внутренние схемы (рис. 7.1). Таким образом, сигнал разрешения прерывания или внепроцессорных передач достигает только одного, первого по линиям шин интерфейса устройства, выставившего соответствующий запрос. Расположение устройств вдоль проводов разрешения определяет их приоритет в группе устройств, использующих определенную шину разрешения.
Протоколы передачи данных
Если задатчиком является процессор или устройство, запросившее шину, то возможны два типа сеансов связи: чтение (передача данных к задатчику от исполнителя) или запись (передача данных к исполнителю от задатчика).
Если задатчиком является устройство, запросившее шину для передачи прерывания, то выполняется сеанс связи – передача процессору адреса вектора прерывания.
На рис. 7.3 представлены временные диаграммы выполнения операций чтения и записи в протоколе системного интерфейса "Общая шина".
Длительность сеанса связи в интерфейсе "Общая шина" зависит от расстояния между задатчиком и исполнителем. В среднем она составляет 1мкс. Все определяется задержками распространения сигналов.
Для демонстрации влияния времени распространения сигналов по проводам шины временные диаграммы сигналов на шине (рис 7.3) представлены в точке задатчика и в точке исполнителя. Из всех задержек в схемах в диаграмме учитываются только задержка в опознании адреса и перекосы сигналов на шинах адреса и данных. Максимально-допустимые значения этих задержек – 75 нс. Пунктирные линии между диаграммами показывают распространение фронтов сигналов между задатчиком и исполнителем.
Каждая передача данных по интерфейсу содержит два этапа: задатчика и исполнителя. Окончание одного сеанса связи может перекрываться началом следующего (на диаграмме рис.7.3. – затененная область на шине данных).
Любой сеанс связи (передачи данных) начинается по сигналам от задатчика. Задатчик выбирается схемой арбитража по запросам внепроцессорных передач от периферийных устройств, Устройство, выигравшее арбитраж, становится задатчиком на следующий сеанс (цикл) связи по интерфейсу. При отсутствии запросов от периферийных устройств задатчиком становится процессор.
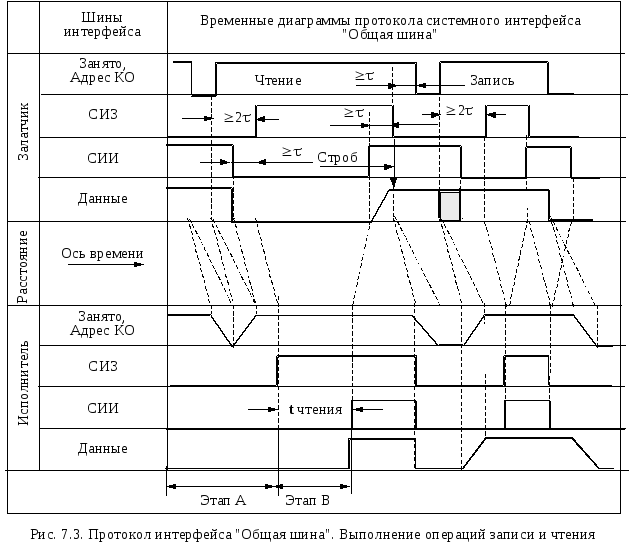
Этапы передачи данных по интерфейсу.
По сбросу сигнала «занято» (верхний ряд, задатчик) задатчик выставляет:
на шине адреса – адрес нового исполнителя,
на линии «занято» – сигнал "занято",
на шине управления – код операции "прочитать» или «записать".
Выставленные сигналы стробируются стробом задатчика СИЗ.
Строб СИЗ выставляется с задержкой. Время задержки определяется условиями:
T задержки выдачи СИЗ ≥ 2τ, где τ = 75 нс. после установки адреса.Задержка учитывает время опознания адреса исполнителем и время перекоса фаз.
Перекос фаз – это разброс времени установления передаваемых значений (адресов или данных) в точке их приема. На диаграммах (рис. 7.3) перекос фаз обозначен разной скоростью распространения фронтов сигналов (пунктирные линии с разными наклонами) и наклоном переднего фронта сигналов на период переходных процессов.
Задержка времени в опознавании адреса – это время задержки в устройстве сравнения адресов (рис. 7.4).
Л инии
адреса, кода операции и данных соединяются
со входами регистра защелки, а линии
адреса дополнительно соединены и со
входами схемы сравнения адресов. Схемы
сравнения адресов непрерывно производят
сравнение поданного адреса с адресами
устройства (адресами ячеек памяти или
регистров портов ввода/вывода). При
совпадении адресов устройство становится
исполнителем и по переднему фронту
синхроимпульса задатчика (СИЗ) производит
прием входной информации в регистр-защелку.
инии
адреса, кода операции и данных соединяются
со входами регистра защелки, а линии
адреса дополнительно соединены и со
входами схемы сравнения адресов. Схемы
сравнения адресов непрерывно производят
сравнение поданного адреса с адресами
устройства (адресами ячеек памяти или
регистров портов ввода/вывода). При
совпадении адресов устройство становится
исполнителем и по переднему фронту
синхроимпульса задатчика (СИЗ) производит
прием входной информации в регистр-защелку.
При появлении на входе схемы совпадения сигнала СИЗ, до окончания переходных процессов в схеме сравнения адресов возможен ложный выбор задатчика. Для исключения этого и производится компенсация перекосов фаз и задержки в схеме сравнения адресов. В интерфейсе "Общая шина" компенсация перекосов фаз и задержек в схемах сравнения адресов всегда возлагается на устройство, являющееся задатчиком.
Приемом информации с линий адреса, кода операции и, при операциях записи, данных, заканчивается этап А1 (рис. 7.4).
Этап B1. В операциях чтения исполнитель (память) запускает процесс чтения. Происходит задержка на время выполнения заданной операции – t чтения на рис. 2.2( исполнитель, шины "данные").
По окончании этапа чтения исполнитель выставляет прочитанные данные на шине данных и строб – СИИ. Исполнитель выставляет строб без компенсации перекосов. На этом заканчивается этап В1.
Этап А2. Задатчик, получив строб СИИ, выполняет компенсацию перекоса фаз на шине данных (75 нс.) и производит стробирование данных После задержки на компенсацию перекоса фаз задатчик завершает цикл сбросом сигнала "занято", кода операции и адреса.
Компенсация перекоса фаз здесь необходима, так как при снятии адреса на шине происходит переходной процесс, "видимый" на схемах сравнения адресов всех устройств. Для блокировки "ложного выбора задатчика" строб СИЗ должен быть снят до начала переходного процесса на шине данных.
После снятия сигнала «занято», любое другое устройство, выбранное арбитражем следующим задатчиком, может занять шины, выставив на шинах интерфейса новый адрес, код операции и данные (при операции записи). Это может случиться до освобождения шины данных предыдущим исполнителем. Но передача искаженных данных здесь исключается компенсацией перекоса фаз задатчиком при выставлении СИЗ после снятия исполнителем данных и СИИ.
Этап выполнения операции при записи может быть "невидим" задатчиком, так как исполнитель, получив данные в буфер, может сразу ответить сигналом СИИ, ускорив освобождение шины до фактического завершения операции записи.
Вопросы и/или темы для самопроверки:
Определение интерфейса.
Синхронные и асинхронные интерфейсы.
Функции арбитража.
Выбор задатчика и исполнителя.
Протоколы передачи данных.
Сигналы СИЗ и СИИ.
Схема выбора исполнителя.
Компенсация перекосов.
Неделя. 15. Лекция 15
.
Системные интерфейсы МП IA
Системные интерфейсы МП IA предназначены для передачи данных между процессором и регистрами контроллеров памяти и всех периферийных устройств в пределах материнской платы. Здесь предпочтительнее использование более простого синхронного интерфейса.
Основным достоинством асинхронных интерфейсов является возможность передачи данных параллельно по разрядам на расстояния в десятки метров. Синхронные интерфейсы значительно проще асинхронных, и для передачи данных в пределах материнской платы их использование является предпочтительным.
Но в современных ЭВМ используется множество устройств, которые могут работать с центральным процессором. Это различные вычислительные и управляющие устройства (видео-, интернет- и звуковая карты, контроллеры накопителей на магнитных дисках и лентах и т.д.). Это все быстродействующие устройства, которые используются в различных системах.
Для возможности их параллельной работы и стандартизации подключения множества периферийных устройств к вычислительным системам с процессорами разных программных моделей шинный интерфейс строится на основе набора локальных шин, например, шины PCI (Peripheral Component Interconnect bus – шина соединения периферийных устройств).
Это набор из нескольких (не менее двух) стандартных локальных шин.
Наличие многих шин допускает возможность одновременных соединений на разных шинах, что повышает производительность системы.
Одной из этих шин является локальная шина для взаимодействия процессоров с системой оперативной памяти (включая кэш-памяти нижних уровней). Это шина с высокой пропускной способностью. Пропускная способность определяется как произведение частоты передачи на разрядность параллельно передаваемых данных. Для процессоров Pentium Pro протокол интерфейса процессора гарантирует, при наличии кэш-памяти, одновременную работу до 4 процессоров.
Шина PCI предназначена для связи относительно быстродействующих периферийных устройств. Это видео-, интернет-, и звуковая карты, контроллеры накопителей на магнитных дисках и лентах и т.д.
Интерфейс на основе шины PCI допускает исn пользование третьей локальной шины для взаимодействиия медленных периферийных устройств с использованием одного из старых стандартных протоколов: ISA, EISA,MCA и т.д.
Передача данных между устройствами на разных уровнях осуществляется через конверторы протоколов северного и южного портов.
Использование множества (до трех) локальных шин позволяет:
совмещение передач данных на разных уровнях,
использование общего парка новых современных быстродействующих внешних устройств вне зависимости от протоколов интерфейсов используемых процессоров.
В следующем варианте шины PCI – X – передача данных производится с использованием механизма расщепленных транзакций. Механизм передачи с расщепленными транзакциями предполагает разбиение передачи на отдельные фазы (этапы):
передачи адреса и кода операции с получением тега (номера заказа),
проверки возможного отказа (по номеру заказа),
передачи данных (по номеру заказа).
Каждый этап начинается с запроса шины, затем выполняется подключение к шине для реализации передач текущего этапа, и заканчивается этап отключением от шины. Этот прием увеличивает общее время пересылки отдельных данных, но повышает производительность шины, так как в промежутках между фазами шина не простаивает, а обслуживает фазы транзакций других устройств. Таким образом производится обслуживание запросов устройств (до 8) с разделением по времени.
Важной особенностью шины PCI является возможность автоконфигурации (технология – plug-and-play). Каждая из периферийных карт PCI должна содержать специальный 256-байтный заголовок, доступ к которому осуществляется в течение специальных циклов автоконфигурации PCI. В заголовке предусмотрены поля, указывающие на производителя карты, тип и версию устройства, его функции, требования по занимаемому адресному пространству, прерываниям, свойства циклов работы по шине. Программа инициализации опрашивает устройства и назначает системные ресурсы в соответствии с требованиями, содержащимися в конфигурационных заголовках.
Локальный интерфейс микропроцессора i80386
Особенности локального интерфейса i80386
Локальный интерфейс МП является шиной, линии которой непосредственно соединяются с выводами корпуса процессора. Основным назначением локального интерфейса является организация передачи информации (связи) между процессором, сопроцессором, оперативной памятью, кэш-памятью и, при помощи конвертора и интерфейса расширения, другими функциональными узлами РС. Локальная шина работает в синхронном режиме.
Основными компонентами интерфейса являются:
адресная шина A,
шина данных D,
сигналы идентификации цикла,
строб адреса,
строб данных.
Можно выделить пять особенностей в конструкции и функционировании локального интерфейса МП i80386. Это:
задание адреса,
автоконфигурация шины данных,
использование 16-байтового буфера кодовой строки,
сигналы идентификации цикла,
конвейеризация циклов (конвейеризация адреса).
Конвейеризация циклов является основной (этапной) новацией, c точки зрения развития технологии передачи информации в интерфейсах МП Intel.
Задание адреса
Тридцатидвухразрядный МП i80386 может обращаться к сегментам памяти в диапазоне 4 Гбайта и портам ввода/вывода (включая компоненты сопроцессора) – в диапазоне 64 Кбайта. При этом периферийные устройства в системе могут быть отнесены либо к пространству памяти, либо к пространству вода/вывода, либо к обоим пространствам.
Интерфейс допускает передачу шестнадцати- и тридцатидвухразрядных операндов, не выровненных по границам слова или двойного слова. При этом возможна параллельная передача по шине данных от одного до четырех байт. Соответственно, для указания размера передаваемых данных и секций шины данных, по которым они передаются, требуются дополнительные линии интерфейса.
В МП i80386 эта проблема решена следующим образом. Шина данных содержит 34 линии. Из них 30 используются для задания адреса операнда (младшего байта операнда) с точностью до адреса двойного слова. Это разрядные линии адреса от А31 до А2. Адрес операнда с точностью до байта и секции шины данных, по которым передаются байты операнда, задаются четырьмя дополнительными сигналами выбора байтов: BE3#, BE2#, BE1#, BEO# (4 линии).
Количество параллельно передаваемых байтов определяется числом активных сигналов выбора байтов, а адрес данных (с точностью до байта) – комбинацией этих сигналов.
Автоконфигурация шины данных. Под автоконфигурацией шины данных здесь понимается механизм динамического изменения ширины шины данных и выравнивание операндов.
Возможность динамического изменения ширины шины данных обеспечивает непосредственное взаимодействие как с 32-разрядными, так и с 16-разрядными внешними устройствами. МП i80386 в серии МП i80Х86 был первым 32-разрядным процессором, и для него проблема совместимости со "старыми" 16-разрядными периферийными устройствами являлась актуальной.
Для решения проблемы автоконфигурации в МП используется сигнал от исполнителя (внешнего устройства) к процессору BS16# (bus size 16 bits). Активный сигнал BS16# означает, что исполнитель – 16-разрядное устройство по шине данных.
При активном уровне сигнала BS16# и необходимости передачи данных разрядностью больше 16 (или 16-разрядных данных, не выровненных по границе слова) МП автоматически вместо одного цикла выполняет два или три цикла передачи. При этом данные передаются только по линиям D0 – D15.
Сигналы идентификации цикла
Циклом (транзакцией) называется один сеанс связи устройств, в течение которого осуществляется передача данных через интерфейс. Интерфейс использует синхронную передачу. Каждый цикл имеет несколько фаз, называемых тактами. Длительность такта определяется периодом синхросигналов, доступных всем устройствам, использующим интерфейс. Локальный интерфейс МП i80386 поддерживает циклы с переменным числом тактов, минимальное число тактов в цикле – два.
В первом такте процессор (или другое устройство со статусом задатчика) задает адрес и тип цикла. Первый такт помечается стробом задатчика. Это сигнал использования адреса (ADS#). В последнем такте оперативная память (или другой исполнитель) выставляет строб данных. Это сигнал окончания цикла (READY#). По этому сигналу стробируются данные на шине данных. При операции чтения (передача данных от исполнителя к задатчику) исполнитель этим сигналом указывает такт, в котором возможна фиксация задатчиком данных с шины данных. При операции записи исполнитель указывает задатчику такт, в котором им были сняты данные с шины данных. Это своеобразная квитанция исполнителя на возможность окончания задатчиком текущего цикла и перехода на следующий цикл.
Два такта в цикле – это расчетный вариант, когда быстродействие задатчика и исполнителя согласованы.
В рабочем режиме микропроцессор может выполнять следующие типы циклов:
чтение из памяти,
запись в память,
чтение из устройства ввода/вывода (или из сопроцессора),
запись в устройство ввода/вывода (или в сопроцессор),
подтверждение прерывания,
индикация останова или выключения.
Сигналы идентификации цикла определяют:
W/R# – операцию в цикле: запись или чтение,
D/C# – тип передаваемой информации: данные или команды,
М/IO# – тип цикла: обращение к памяти или обращение к устройствам ввода/вывода,5
LOCK# – блокировку шины в последовательности циклов.
Конвейеризация адреса
Разработка новых процессоров с более высоким быстродействием всегда связана с проблемой использования старых систем памяти, рассчитанных на работу с менее быстродействующими МП. Конвейерная передача данных (конвейеризация адреса) в какой-то мере решает эту проблему. Использование конвейеризации в PC 386/AT, где МП i80386 имел рабочую частоту 16 МГц и оперативную память, построенную на динамических элементах с временем выборки 100 нс., позволило в циклах интерфейса исключить состояния ожидания и при трехтактовых циклах передавать данные на каждый второй такт.
Конвейерная работа связана не только с протоколами интерфейса, но и относительно несложной модернизацией памяти.
Согласования по быстродействию процессора и памяти можно достигнуть повышением полосы пропускания памяти (произведение ширины обращения на частоту). Для этого можно увеличить (удвоить) ширину обращения, например путем реализации двух банков памяти с чередованием адресов двойных слов (с расслоением), и организовать параллельную, конвейерную или пакетную передачу данных по шине данных.
Параллельная передача данных связана с расширением (по разрядам) шины данных. Конвейерная и пакетная передачи данных используют стандартную 32-разрядную шину данных. Если допускать возможность обращения к разным банкам данных по несмежным адресам без увеличения разрядности шины адреса, то доработка обычной памяти для реализации конвейерной передачи должна предусматривать наличие регистров-защелок на каждый блок памяти для фиксации адресов обращения к памяти. Адрес обращения для следующего цикла передается в конвейерном режиме в тактах текущего цикла.
МП i80386 может работать как с обычной памятью, так и с допускающей конвейерную передачу адреса. При этом выбор режима определяет контроллер памяти (как исполнитель). Если память ориентирована на работу в конвейерном режиме, то она во втором такте запрашивает адрес обращения для следующего цикла. Сигналом запроса является сигнал запроса адреса Na#.
Интерфейсы с расщепленными транзакциями
Особенностью локального интерфейса МП Pentium Pro и более поздних моделей является их ориентация на возможность многопроцессорной обработки данных. На его основе можно строить симметричные многопроцессорные (до четырех процессоров) системы. Процессор Pentium Pro имеет независимую двойную интерфейсную шину. Одна из этих шин предназначена для связи процессора с оперативной памятью, другая – с кэш-памятью второго уровня.
В результате этого доля обращений к оперативной памяти снизилась до 10%, что послужило основой для построения многопроцессорных систем с общей памятью.
В процессорных системах IA-архитектуры интерфейс процессора – это печатный монтаж проводов на материнской плате, а локальный интерфейс процессор-память – не более дюйма. Главными источниками задержки здесь являются не длительность передачи, а латентность памяти, т.е. задержки в адресных цепях процессора.
Адресные шины содержат множество адресных проводов. Первые процессоры IA-архитектуры состояли из 10 проводов. По этим проводам по очереди передавали значения старших и младших разрядов 20-разрядного адреса на два дешифратора (колонки и строки матрицы). Каждый дешифратор выбирает один провод из 1024 проводов. На невыбранных проводах ток отсутствует, он утекает на землю, через открытые диоды дешифратора. На выбранной шине он составляет 1/1024 от тока на входе дешифратора. Таким образом, ток заряда паразитной емкости выходной шины дешифратора составляет одну тысячную от входного. Соответственно с этим, время нарастания напряжения на выбранной шине уменьшается в тысячу раз. Это главная причина задержек ответа (время латентности) при обращении к памяти.
С ростом быстродействия процессора доля потерь времени в адресных цепях непрерывно возрастает.
При отдельных операциях записи контроллер памяти принимает команду процессора в буфер памяти и освобождает интерфейс. При выполнении операций чтения ситуация более сложная. Чтение – это, в общем случае, передача пакета (строчки кэш-памяти). Чтобы передать пакет данных, кроме задержки на латентность памяти, нужно учесть время выбора исполнителя чтения (основной памяти или локальной кэш-памяти другого процессора, в которой может быть копия затребованных данных). Передача "кэш - кэш" намного быстрее передачи "оперативная память - кэш". Кроме этого, данные в основной памяти могут быть устаревшими по сравнению с кэш-памятью других процессоров. Одним из решений этой проблемы явились протоколы с расщепленной транзакцией. (split transaction).
Шина с расщепленной транзакцией при наличии нескольких главных устройств шины (процессоров или устройств ПДП) обеспечивает значительно большую пропускную способность за счет разделения транзакции на две основных части: передача запроса, проверка отказа и получение ответа.
Здесь речь идет о команде "прочитать". При выполнении команды "записать" процессор передает в одной фазе и адрес записи, и данные. Контроллер памяти помещает данные в буфер записи и на этом транзакция интерфейса заканчивается.
При передаче команды "прочитать" каждая часть транзакции начинается арбитражем запросов на занятие определенной группы шин и оканчивается отключением от этих шин. В промежутках между указанными соединениями интерфейсная шина может использоваться для реализации следующих транзакций этого же процессора или других процессоров, или устройств ПДП. По сути – это вариант пакетной передачи с конвейеризацией передачи адреса, но с использованием времени латентности памяти.
В этом протоколе разные группы шин адреса и данных используются в разных фазах транзакции и практически независимы. Любая фаза начинается выставлением запроса арбитражу на доступ к шинам интерфейса. Одновременно может быть множество запросов на доступ к интерфейсу. Доступ получает запрос, выигравший арбитраж.
Временная диаграмма интерфейса с расщепленными транзакциями представлена на рис. 7.15.
В интерфейсе с расщепленными транзакциями используются несколько арбитражей:
запроса шин адреса и команды,
запроса шин данных,
запроса передачи сигнала ошибки (на рис.7.4 не показаны).
Для реализации транзакции процессор должен выиграть запрос к арбитражу шин адреса и команды. Для этого процессор или устройства ПДП подают на устройство арбитража запрос – идентификатор процессора и идентификатор арбитража.
В ответ арбитраж посылает сигнал разрешения занятия следующего цикла процессора и присвоенный транзакции тег.
При отрицательном ответе процессор сохраняет запрос.
Первой фазой первого этапа транзакции (рис. 7.15) является запрос к арбитражу для занятия шин адреса и получение разрешения, второй фазой первого этапа является передача запроса (код операции, адрес, размер, разрешенные секции шин данных и идентификатор источника – трехразрядный тег).
Тег присваивается запросу арбитражем. Здесь возможны случаи, когда арбитраж выигрывает одно и то же устройство ПДП. Поэтому тег присваивается не ПДП, а транзакции, по ее очереди в конвейере.
Одновременно на этом конвейере могут находиться до 8 транзакций на разных стадиях выполнения, и для идентификации транзакций достаточно использования трехбитного тега.
Первой фазой второго этапа является запрос ответчика (контролера памяти) в арбитраж на захват шин передачи данных. Второй фазой этого этапа является передача данных.
Между этими основными этапами возможны дополнительные этапы. Это этап возможной ошибки и этап управления завершением.
Вопросы и/или темы для самопроверки:
1.Протоколы с расщепленной транзакцией.
2. Первый этап протокола с расщепленной транзакцией.
3. Второй этап протокола с расщепленной транзакцией.
4. Назначение тега в протоколе с расщепленной транзакцией.
16-я неделя. Лекция 16