

Первая публикация в книги «Числа» Ветхого завета.
|
Родоначальник |
Число военнообязанных |
|
От Рувима |
46500 |
|
От Симюна |
59300 |
|
……. |
……….. |
|
От Ассира |
41500 |
|
От Неффалима |
53400 |
|
итого |
603550 |
__________________________________________________________________________________
Этапы:
1) Описательная статистика
2) Параметрическая статистика
3) Непараметрическая статистика
4) Нечисловая статистика
Земская статистика — статистические работы земств по обследованию главным образом состояния сельского хозяйства и процессов его социально-экономического развития.
Земская статистика делилась на основную и текущую. Основная хозяйственная статистика имела задачей выяснить общее положение хозяйства, в связи с имеющимися средствами производства. В большинстве случаев она основывалась на специальных местных (экспедиционных) исследованиях. Главным предметом этих исследований служило крестьянское хозяйство, которое с 1880 года изучалось преимущественно путем местной сплошной подворной переписи. В сравнительно небольшом числе уездов экспедиционным способом было исследовано частновладельческое хозяйство и, наконец, в единичных уездах, при помощи земской статистики, было выполнено сплошное исследование территории.
Текущая земская статистика фиксировала положение сельского хозяйства за каждый отчётный год, и, так же как и статистика департамента земледелия, основывалась в большинстве случаев на сведениях, доставленных добровольными корреспондентами, но кое-где и к ней был применен экспедиционный способ (например в курском земстве в 1883 году, в таврическом в 1888 году, в нижегородском в 1891 году).
Впервые термин «статистика» мы находим в художественной литературе – в «Гамлете» Шекспира (1602 г., акт 5, сцена 2). Смысл этого слова у Шекспира – знать, придворные. По-видимому, оно происходит от латинского слова status, что в оригинале означает «состояние» или «политическое состояние».
В 1954 г. академик АН УССР Б.В. Гнеденко дал следующее определение: «Статистика состоит из трех разделов:
1) сбор статистических сведений, т.е. сведений, характеризующих отдельные единицы каких-либо массовых совокупностей;
2) статистическое исследование полученных данных, заключающееся в выяснении тех закономерностей, которые могут быть установлены на основе данных массового наблюдения;
3) разработка приемов статистического наблюдения и анализа статистических данных. Последний раздел, собственно, и составляет содержание математической статистики».
Структура современной статистической науки.
Общая теория статистики является методологической основой, ядром всех отраслевых статистик, она разрабатывает общие принципы и методы статистического исследования общественных явлений и является наиболее общей категорией статистики.
Задача экономической статистики – разработка и анализ синтетических показателей, отражающих состояние национальной экономики, взаимосвязи отраслей, особенности размещения производительных сил, наличие материальных, трудовых и финансовых ресурсов. Социальная статистика формирует систему показателей для характеристики образа жизни населения и различных аспектов социальных отношений.
В целом статистика занимается сбором информации различного характера, ее упорядочиванием, сопоставлением, анализом и интерпретацией (объяснением) и обладает следующими отличительными особенностями. Во-первых, статистика изучает количественную сторону общественных явлений: величину, размер, объем и имеет числовое значение. Во-вторых, статистика исследует качественную сторону явлений: специфику, внутреннюю особенность, отличающую одно явление от других. Качественная и количественная стороны явления всегда существуют вместе, образуя единство.
Все общественные явления и события протекают во времени и в пространстве, и в отношении любого из них всегда можно установить, когда оно возникло и где оно развивается. Таким образом, статистика изучает явления в конкретных условиях места и времени.
Изучаемые статистикой явления и процессы общественной жизни находятся в постоянном изменении, развитии. На основе сбора, обработки и анализа массовых данных об изменении изучаемых явлений и процессов выявляется статистическая закономерность. В статистических закономерностях проявляются действия общественных законов, которые определяют существование и развитие социально-экономических отношений в обществе.
Предметом статистики является изучение общественных явлений, динамики и направления их развития. При помощи статистических показателей данная наука определяет количественную сторону общественного явления, наблюдает закономерности перехода количества в качество на примере данного общественного явления и на основании этих наблюдений производит анализ данных, полученных в определенных условиях места и времени. Статистика исследует социально-экономические явления и процессы, которые носят массовый характер, изучает множество определяющих их факторов.
Большинство общественных наук пользуются статистикой для выведения и подтверждения своих теоретических законов. Выводами, основанными на статистических исследованиях, пользуются экономика, история, социология, политология и многие другие гуманитарные науки. Статистика необходима не только общественным наукам для подтверждения их теоретической основы, но велика и практическая ее роль: ни одно крупное предприятие или серьезное производство, разрабатывая стратегию экономического и социального развития объекта, не может обойтись без анализа данных статистического учета. Для этого на предприятиях создаются специальные аналитические отделы и службы, которые привлекают специалистов, прошедших профессиональную подготовку по данной дисциплине.
Как любая наука, статистика имеет определенную методологию изучения своего предмета. Как уже отмечалось выше, ее в основном интересует развитие явления и его связь с другими явлениями общественной жизни, поэтому метод статистики выбирается в зависимости от изучаемого явления и конкретного предмета изучения. В статистике разработаны и применяются специфические способы и приемы исследования общественных явлений, которые в совокупности и образуют метод статистики. К ним относятся наблюдение, сводка и группировка данных, исчисление обобщающих показателей на основе специальных методов (метод средних индексов и т. д.). В соответствии с вышесказанным различают три этапа работы со статистическими данными:
• сбор;
• группировка и сводка;
• обработка и анализ.
Под сбором данных понимают массовое научно-организованное наблюдение, посредством которого получают первичную информацию об отдельных фактах (единицах) исследуемого явления. Такой статистический учет большого числа или всех входящих в состав изучаемого явления единиц является информационной базой для статистических обобщений, для формулирования выводов об изучаемом явлении или процессе. Подгруппировкой и сводкой данных понимают распределение множества фактов (единиц) на однородные группы и подгруппы, подсчет итогов по каждой группе и подгруппе и оформление полученных итогов в виде статистической таблицы.
Статистический анализ является заключительной стадией статистического исследования. Он включает в себя обработку статистических данных, полученных при сводке, интерпретацию полученных результатов с целью получения объективных выводов о состоянии изучаемого явления и закономерностях его развития. В процессе статистического анализа изучаются структура, динамика и взаимосвязь общественных явлений и процессов.
К основным этапам статистического анализа относят:
• установление фактов и их оценку;
• выявление характерных особенностей и причин явления;
• сопоставление явления с нормативными, плановыми и прочими явлениями, принятыми за базу сравнения;
• формулирование выводов, прогнозов, предположений и гипотез;
• статистическую проверку выдвинутых гипотез.
Математическая статистика Прикладная статистикаСМ в эк (эконометрия)
СМ в тех (технометрия)
СМ в биом (биометрия)
СМ в госупр и др
Этапы развития прикладной статистики
|
Этапы |
Характерные черты |
Периоды |
|
1 Описательная статистика |
Таблицы, графики, тексты, расчетные приемы (МНК) |
До 1900 |
|
2 Параметрическая статистика |
Модели параметрических семейств (нормальное Гамма распределение) |
1900 - 1933 |
|
3 Непараметрическая статистика |
Произвольное распределение, непараметрические методы оценки гипотез |
1933 - 1973 |
|
4 Нечисловая статистика |
Анализ и обработка нечисловых данных ( интервалы, множества) |
С 1979 |
Цель описательной (дескриптивной) статистики — обработка эмпирических данных, их систематизация, наглядное представление в форме графиков и таблиц, а также их количественное описание посредством основных статистических показателей.
В отличие от индуктивной статистики дескриптивная статистика не делает выводов о генеральной совокупности на основании результатов исследования частных случаев. Индуктивная же статистика напротив предполагает, что свойства и закономерности, выявленные при исследовании объектов выборки, также присущи генеральной совокупности.
5.Параметрическая статистика
|
Этапы |
Характерные черты |
Периоды |
|
1 Описательная статистика |
Таблицы, графики, тексты, расчетные приемы (МНК) |
До 1900 |
|
2 Параметрическая статистика |
Модели параметрических семейств (нормальное Гамма распределение) |
1900 - 1933 |
|
3 Непараметрическая статистика |
Произвольное распределение, непараметрические методы оценки гипотез |
1933 - 1973 |
|
4 Нечисловая статистика |
Анализ и обработка нечисловых данных ( интервалы, множества) |
С 1979 |
(parametricstatistics) -инференциальная статистика, учитывающая, что население, из которого была сделана выборка, обладает специфическими формами, то есть включающая гипотезы о параметрах населения. Таковыми являются, как правило, следующие предположения: выбранные популяции имеют нормальное распределение, равные средние дисперсии (см. Меры дисперсии), а данные принадлежат к интервальному уровню (см. Критерии и уровни измерения) . Примеры этого - коэффициент корреляции производного значения Пирсона, многократная регрессия и дисперсионный анализ. Такие процедуры используют всю доступную информацию, а тесты более объемные, чем непараметрические. В социологии часто возникает проблема данных, которые не распределяются нормально в населении, решаемая путем преобразования шкалы, проверки надежности метода или перехода к непараметрическому эквиваленту. Ср. Непараметрическая статистика.
6.Непараметрическая статистика
|
Этапы |
Характерные черты |
Периоды |
|
1 Описательная статистика |
Таблицы, графики, тексты, расчетные приемы (МНК) |
До 1900 |
|
2 Параметрическая статистика |
Модели параметрических семейств (нормальное Гамма распределение) |
1900 - 1933 |
|
3 Непараметрическая статистика |
Произвольное распределение, непараметрические методы оценки гипотез |
1933 - 1973 |
|
4 Нечисловая статистика |
Анализ и обработка нечисловых данных ( интервалы, множества) |
С 1979 |
Непараметрические методы позволяют обрабатывать данные "низкого качества" из выборок малого объёма с переменными, про распределение которых мало что или вообще ничего неизвестно.
Непараметрические методы не основываются на оценке параметров (таких как среднее или стандартное отклонение) при описании выборочного распределения интересующей величины. Поэтому эти методы иногда также называются свободными от параметров или свободно распределенными.
7.Нечисловая статистика
|
Этапы |
Характерные черты |
Периоды |
|
1 Описательная статистика |
Таблицы, графики, тексты, расчетные приемы (МНК) |
До 1900 |
|
2 Параметрическая статистика |
Модели параметрических семейств (нормальное Гамма распределение) |
1900 - 1933 |
|
3 Непараметрическая статистика |
Произвольное распределение, непараметрические методы оценки гипотез |
1933 - 1973 |
|
4 Нечисловая статистика |
Анализ и обработка нечисловых данных ( интервалы, множества) |
С 1979 |
Статистика нечисловых данных - это направление в прикладной математической статистике, в котором в качестве исходных статистических данных (результатов наблюдений) рассматриваются объекты нечисловой природы. Так принято называть объекты, которые нецелесообразно описывать числами, в частности элементы различных нелинейных пространств. Примерами являются бинарные отношения (ранжировки, разбиения, толерантности и др.), результаты парных и множественных сравнений, множества, нечеткие множества, измерение в шкалах, отличных от абсолютных. Этот перечень примеров не претендует на законченность. Он складывался постепенно, по мере того, как развивались теоретические исследования в области нечисловой статистики (статистики нечисловых данных) и расширялся опыт применений этого направления прикладной математической статистики.
Объекты нечисловой природы широко используются в теоретических и прикладных исследованиях по экономике, менеджменту и другим проблемам управления, в частности управления качеством продукции, в технических науках, социологии, психологии, медицине и т.д., а также практически во всех отраслях народного хозяйства.
8.
Прикладная статистика – это наука о том, как обрабатывать данные. Методы прикладной статистики активно применяются в технических исследованиях, экономике, теории и практике управления (менеджмента), социологии, медицине, геологии, истории и т.д. Основные проблемы прикладной статистики – описание данных, оценивание, проверка гипотез – разобраны во второй части.
Статистическая совокупность – совокупность однородных по какому-либо признаку предметов, ограниченных пространством и временем. Статистическая совокупность — это множество единиц (объектов, явлений), объединенных единой закономерностью и варьирующих в пределах общего качества. Специфическим свойством статистической совокупности является массовость единиц, поскольку явление характеризуется массовым процессом и всем многообразием определяющих его причин и форм. Под единицами совокупности понимаются ее неделимые первичные элементы, выражающие ее качественную однородность, т. е. являющиеся носителями признаков. Под качественной однородностью единиц совокупности понимается сходство единиц (объектов, явлений) по каким-либо существенным признакам, но различающихся по каким-либо другим признакам.
Генеральной совокупностью называют совокупность всех мысленно возможных объектов данного вида, над которыми проводятся наблюдения с целью получения конкретных значений случайной величины, или совокупность результатов всех мыслимых наблюдений, проводимых в неизменных условиях над одной из случайных величин, связанных с данным видом объектов.
Замечание: Часто генеральная совокупность содержит конечное число объектов. Однако если это число достаточно велико, то иногда в целях упрощения вычислений допускают, что генеральная совокупность состоит из бесчисленного множества объектов. Такое допущение оправдывается тем, что увеличение объема генеральной совокупности (достаточно большого объема) практически не сказывается на результатах обработки данных выборки.
Выборочной совокупностью называют часть отобранных объектов из генеральной совокупности.
Объемом совокупности (выборочной или генеральной) называют число объектов этой совокупности. Например, если из 1000 деталей отобрано для обследования 100 деталей, то объем генеральной совокупности N = 1000, а объем выборки п =100.
Число объектов генеральной совокупности N значительно превосходит объем выборки n .
9.
ЕСС обладают определенными свойствами которые называются признаками.
Статистика изучает явления через их признаки, чем более однородна
совокупность тем больше общих признаков имеют ее единицы и тем меньше
варьируют значения этих признаков.
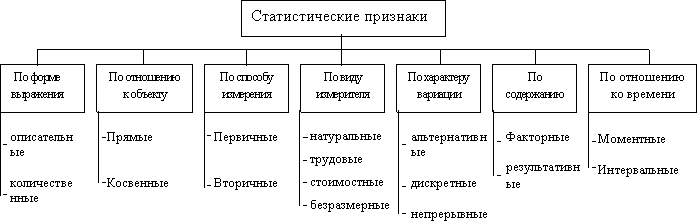
Описательный признак – признак, который может быть выражен только словесно.
Количественный признак – признак, который может быть выражен численно.
Прямой признак – свойство непосредственно присуще характерному объекту.
Косвенный признак – свойства не самого характеризуемого объекта, а объекта связанного с ним либо входящих в него.
первичный признак – абсолютная величина, может быть измерен.
вторичный признак – результат сопоставления первичных признаков, он измеряется непосредственно.
натуральный признак –измеряется в штуках, кг, тоннах, литрах и т.д.
трудовой признак– измеряется в человеко-днях, человеко-часах.
Стоимостной признак - измеряется в рублях, $, €, ₤.
безразмерный признак – измерение в долях, %
альтернативный признак – признак, который принимает только одно значение из нескольких возможных.
дискретный признак – принимает только целое значение, без промежуточного.
непрерывный признак – признак, принимающий любые значения в определенном диапазоне.
факторный признак – признак, под действием которого изменяется другой признак.
результативный признак – признак, который изменяется под признаком другого
моментный признак – признак, измеренный на определенный момент времени.
Интервальный признак – признак за определенный интервал времени.
Один и тот же признак может быть классифицирован одновременно по разным
классификациям.
10.Деление статистики по виду данных Области прикладной статистики
|
№ п/п |
Вид статистических данных |
Область прикладной статистики |
|
1 |
Числа |
Статистика (случайных) величин |
|
2 |
Конечномерные векторы |
Многомерный статистический анализ |
|
3 |
Функции |
Статистика случайных процессов и временных рядов |
|
4 |
Объекты нечисловой природы |
Статистика нечисловых данных (статистика объектов нечисловой природы) |
В многомерном статистическом анализе выборка состоит из элементов многомерного пространства. Отсюда и название этого раздела прикладной статистики. Из многих задач многомерного статистического анализа рассмотрим основные – корреляцию, восстановление зависимости, классификацию, уменьшение размерности, индексы.
Методы статистики случайных процессов и временных рядов применяют для постановки и решения, в частности, следующих задач:
• предсказание будущего развития случайного процесса или временного ряда; • управление случайным процессом (временным рядом) с целью достижения поставленных целей, например, заданных значений контролируемых параметров; • построение вероятностной модели реального процесса, обычно длящегося во времени, и изучение свойств этой модели.
Напомним, что объектами нечисловой природы называют элементы пространств, не являющихся линейными. Примерами являются вектора из 0 и 1, измерения в качественных шкалах, бинарные отношения (ранжировки, разбиения, толерантности), множества, последовательности символов (тексты). Объекты нечисловой природы нельзя складывать и умножать на числа, не теряя при этом содержательного смысла. Этим они отличаются от издавна используемых в прикладной статистике (в качестве элементов выборок) чисел, векторов и функций.
11.Основные задачи прикладной статистики
Выделяют три основные области статистических методов обработки результатов наблюдений – описание данных, оценивание (характеристик и параметров распределений, регрессионных зависимостей и др.) и проверка статистических гипотез. Рассмотрим основные понятия, применяемые в этих областях.
Описание данных – предварительный этап статистической обработки. Используемые при описании данных величины применяются при дальнейших этапах статистического анализа – оценивании и проверке гипотез, а также при решении иных задач, возникающих при применении вероятностно-статистических методов принятия решений, например, при статистическом контроле качества продукции и статистическом регулировании технологических процессов.
СТАТИСТИЧЕСКОЕ
ОЦЕНИВАНИЕ -
один из основных разделов математической
статистики, посвящённый оцениванию
параметров теоретических моделей по
косвенным измерениям или распределений случайной
величины х по
наблюдению её реализаций. Если
предполагается, что распределение
является элементом параметрического
семейства![]() ,
то возникает задача параметрического
оценивания. Когда вид распределения
неизвестен, говорят о задаче
непараметрического оценивания. При
параметрическом оценивании различают
два подхода: точечное оценивание
и интервальное
оценивание.
,
то возникает задача параметрического
оценивания. Когда вид распределения
неизвестен, говорят о задаче
непараметрического оценивания. При
параметрическом оценивании различают
два подхода: точечное оценивание
и интервальное
оценивание.
Статистической гипотезой называется любое предположение о виде неизвестного закона распределения или опараметрах известных распределений. Предположим, что на основании имеющихся данных есть основания выдвинуть предположения о законе распределения или о параметре закона распределения случайной величины (или генеральной совокупности, на множестве объектов которой определена эта случайная величина). Задача проверки статистической гипотезы заключается в подтверждении или опровержении этого предположения на основании выборочных (экспериментальных) данных.
Прикладная статистика — это наука о том, как обрабатывать данные произвольной природы.
Математи́ческаястати́стика — наука, разрабатывающая математические методы систематизации и использования статистических данных для научных и практических выводов.
12.Выборка
Статистические совокупности – это не только реально существующие множества, но и очень большие множества (примеры: 47 млн. жителей Украины).
Из этого следует, что если при изучении статистических совокупностей пользоваться сплошным наблюдением, то нужны огромные затраты времени.
Затраты большие, материальные. Поэтому прибегают к несплошному наблюдению или выборке.
Часть при обследовании (наблюдении) в единице совокупности приходится уничтожать единицы. Нужно прибегать к выборке.
Очень часто единицы недоступны по каким-то причинам для непос-нной регистрации, поэтому прибегают к выборочному анкетированию (выборка). В свете всего вышеизложенного практически любое наблюдение – выборочное.
Таким образом выборочное наблюдение (выборка) имеет массу преимуществ:
- экономит время, материальные расходы;
- сохраняет продукцию, позволяет изучать слишком большие и удаленные совокупности.
Выборка – это часть генеральной совокупности, которую мы будет непосредственно исследовать, то есть это те люди, к которым мы обратимся с вопросами интервью или с анкетами; те материалы, которые мы будет изучать методом контент-анализа и т. п.
Иногда выборка равна генеральной совокупности (например, в случае, когда мы опрашиваем всех студентов первого курса факультета журналистики МГУ). Но обычно она меньше, иногда в несколько десятков и сотен раз. При этом практика социологических исследований доказала, что в общенациональных исследованиях достаточно выбрать для опросов 1,5–2 тысячи человек. Если выборка хорошо, правильно, репрезентативно сформирована, то она может дать объективную информацию о мнении всех россиян.
Итак, главное – это правильно сформировать выборку. Объем выборки зависит от целей исследования, специфики и степени однородности объекта исследования, дробности групп, которые предстоит изучить, и планируемой степени ее репрезентативности.
Объём выборки — число случаев, включённых в выборочную совокупность. Из статистических соображений рекомендуется, чтобы число случаев составляло не менее 30—35.
13.Вероятностные основы статистики. Пр-во элементарных событий. Алгебра событий.
Соответствие терминов теории вероятностей и теории множеств
|
Теория вероятностей |
Теория множеств |
|
Пространство элементарных событий |
Множество |
|
Элементарное событие |
Элемент этого множества |
|
Событие |
Подмножество |
|
Достоверное событие |
Подмножество, совпадающее с множеством |
|
Невозможное событие |
Пустое
подмножество
|
|
Сумма А+В событий А и В |
Объединение
|
|
Произведение АВ событий А и В |
Пересечение
|
|
Событие, противоположное А |
Дополнение А |
|
События А и В несовместны |
|
|
События А и В совместны |
|
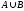
Пусть
конечное множество
![]() является пространством элементарных
событий, соответствующим некоторому
опыту. Пусть каждому
является пространством элементарных
событий, соответствующим некоторому
опыту. Пусть каждому![]() поставлено в соответствие неотрицательное
число
поставлено в соответствие неотрицательное
число![]() ,
называемое вероятностью элементарного
события
,
называемое вероятностью элементарного
события![]() ,
причем сумма вероятностей всех
элементарных событий равна 1, т.е.
,
причем сумма вероятностей всех
элементарных событий равна 1, т.е.
![]() . (1)
. (1)
Тогда
пара
![]() ,
состоящая из конечного множества
,
состоящая из конечного множества![]() и неотрицательной функцииР,
определенной на
и неотрицательной функцииР,
определенной на
![]() и удовлетворяющей условию (1), называетсявероятностным
пространством.
Вероятность события А
равна сумме вероятностей элементарных
событий, входящих в А, т.е. определяется
равенством
и удовлетворяющей условию (1), называетсявероятностным
пространством.
Вероятность события А
равна сумме вероятностей элементарных
событий, входящих в А, т.е. определяется
равенством
![]() .
.
Алгебра событий (в теории вероятностей) — алгебра подмножеств пространства элементарных событий Ω, элементами которого служат элементарные события.
Как и положено алгебре множеств алгебра событий содержит невозможное событие (пустое множество) и замкнута относительно теоретико-множественных операций, производимых в конечном числе. Достаточно потребовать, чтобы алгебра событий была замкнута относительно двух операций, например, пересечения и дополнения, из чего сразу последует её замкнутость относительно любых других теоретико-множественных операций. Алгебра событий, замкнутая относительно счётного числа теоретико-множественных операций, называется сигма-алгеброй событий.
Под случайным событием, связанным с некоторым опытом, понимается всякое событие, которое при осуществлении этого опыта либо происходит, либо не происходит.
Событие называется достоверным, если оно обязательно произойдет в результате опыта или экспериментов. Обозначается U. Если событие заведомо не может произойти в результате опыта, то оно называется невозможным. Обозначается V или ø. Случайные события обозначаются А, В, С…
События называются совместными, если появление одного из них не исключает появление других, в противном случае – несовместными.
Событие Ā (не «А») называется противоположным к событию А, если оно состоит в том, что событие А не произошло. События называются независимыми, если появление одного из них не зависит от того, произошло или нет другое событие. В противном случае зависимо.
Операции над событиями:
1. Суммой (объединением) событий А и В называется событие С, А+В=С (АUВ=С) которое происходит, когда наступает либо событие А, либо событие В, либо оба одновременно.
2. Произведением (пересечением) событий А и В называется событие С, которое наступает, когда происходят оба события А и В. А*В=С (АΩВ=С).
3. Разностью событий А и В (А/В=С) называется событие С, наступающее, когда происходит событие А, но не происходит В.
События А и В называются независимыми, если Р(АВ) = Р(А)Р(В). Несколько событий А, В, С,… называются независимыми, если P(f(A)f(B)f(C)…) = P(f(A))P(f(B))P(f(C))… для любого набора f(A), f(B), f(C),…, где f(Z) = Z либо f(Z) = . Если события А, В, С,… независимы, то Р(АВС…) = Р(А)Р(В)Р(С)…
Это определение соответствует интуитивному представлению о независимости: осуществление или неосуществление одного события не должно влиять на осуществление или неосуществление другого. Иногда соотношение
Р(АВ) = Р(А) Р(В|A) = P(B)P(A|B), справедливое при P(A)P(B) > 0, называют также теоремой умножения вероятностей.
14.Сл. величины как функции на пространствах элементарных событий. Распределения случайных величин. Функции распределения. Квантили, квартили, децили. Плотности. Независимые сл.величины.
Случайная величина – это величина, значение которой зависит от случая, т.е. от элементарного события . Таким образом, случайная величина – это функция, определенная на пространстве элементарных событий . Примеры случайных величин: количество гербов, выпавших при независимом бросании двух монет; число, выпавшее на верхней грани игрального кубика; число дефектных единиц продукции среди проверенных.
Определение случайной величины Х как функции от элементарного события лямбда(попка), т.е. функции х делить на омега следовательно н , отображающей пространство элементарных событий омега в некоторое множество Н, казалось бы, содержит в себе противоречие. О чем идет речь – о величине или о функции? Дело в том, что наблюдается всегда лишь т.н. «реализация случайной величины», т.е. ее значение, соответствующее именно тому элементарному исходу опыта (элементарному событию), которое осуществилось в конкретной реальной ситуации. Т.е. наблюдается именно «величина». А функция от элементарного события – это теоретическое понятие, основа вероятностной модели реального явления или процесса.
Распределения случайных величин и функции распределения. Распределение числовой случайной величины – это функция, которая однозначно определяет вероятность того, что случайная величина принимает заданное значение или принадлежит к некоторому заданному интервалу.
Первое – если случайная величина принимает конечное число значений. Тогда распределение задается функцией Р(Х = х), ставящей каждому возможному значению х случайной величины Х вероятность того, что Х = х.
Второе – если случайная величина принимает бесконечно много значений. Это возможно лишь тогда, когда вероятностное пространство, на котором определена случайная величина, состоит из бесконечного числа элементарных событий. Тогда распределение задается набором вероятностей P(a <X <b) для всех пар чисел a, b таких, что a<b. Распределение может быть задано с помощью т.н. функции распределения F(x) = P(X<x), определяющей для всех действительных х вероятность того, что случайная величина Х принимает значения, меньшие х. Ясно, что
P(a <X <b) = F(b) – F(a).
Это соотношение показывает, что как распределение может быть рассчитано по функции распределения, так и, наоборот, функция распределения – по распределению.
Непрерывные функции распределения, используемые в вероятностно-статистических методах принятия решений, имеют производные. Первая производная f(x) функции распределения F(x) называется плотностью вероятности,
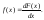
По плотности вероятности можно определить функцию распределения:
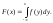
Для любой функции распределения
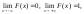
а потому
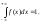
При описании дифференциации доходов, при нахождении доверительных границ для параметров распределений случайных величин и во многих иных случаях используется такое понятие, как «квантиль порядка р», где 0 < p < 1 (обозначается хр). Квантиль порядка р – значение случайной величины, для которого функция распределения принимает значение р или имеет место «скачок» со значения меньше р до значения больше р (рис.2). Может случиться, что это условие выполняется для всех значений х, принадлежащих этому интервалу (т.е. функция распределения постоянна на этом интервале и равна р). Тогда каждое такое значение называется «квантилью порядка р». Для непрерывных функций распределения, как правило, существует единственная квантиль хр порядка р (рис.2), причем
F(xp) = p. (2)
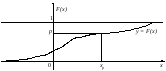
Рис.2. Определение квантили хр порядка р
Кванти́ль в математической статистике — значение, которое заданная случайная величина не превышает с фиксированной вероятностью.
Кроме медианы существуют еще квартили (делят ряд на 4 равные части), квинтили (на 5 частей), децили (на 10 частей) и процентили (на 100 частей), которые все вместе называются квантилями.
Квартиль - значение, ниже которого лежит часть распределения вероятностей случайной величины, кратная одной четвёртой (четверть, половина или три четверти).
Дециль характеризует распределение величин совокупности, при котором девять значений дециля делят её на десять равных частей. Любая из этих десяти частей составляет 1/10 всей совокупности. Так, первый дециль отделяет 10 % наименьших величин, лежащих ниже дециля от 90 % наибольших величин, лежащих выше дециля.
Так же, как в случае моды и медианы, у интервального вариационного ряда распределения каждый дециль (и квартиль) принадлежит определённому интервалу и имеет вполне определённое значение.
15.Закон больших чисел и его роль к статистике.
Содержание закона больших чисел сводится к следующему: в массе индивидуальных явлений общая закономерность проявляется тем полнее и точнее, чем больше их охвачено наблюдением.
Иными словами, закон больших чисел выражает общий принцип, в силу которого в большом числе явлений при некоторых общих условиях почти устраняется влияние случайных факторов.
Закон больших чисел получил свое математическое доказательство в теории вероятностей, а также подтверждение в многочисленных экспериментальных проверках. Так, французский естествоиспытатель А.Бюффон поставил следующий опыт: подбросил монету 4040 раз, при этом орел выпал 2048 раз, а решка 1992 раза. Отсюда, частность выпадения орла составила 2048/4040 = 0,507 и отклонилась от вероятности его выпадания в каждом отдельном случае, равной 1/2, лишь на 0,007 (0,507 - 0,500).
Это говорит о том, что в рассматриваемом опыте почти полностью проявилось влияние основных, постоянных причин, а случайные причины отклонили результаты только на весьма незначительную величину. Т.е. в результате взаимопогашения случайных отклонений средние, исчисленные для величин одного и того же вида, становятся типичными, отражающими действие постоянных и существенных факторов в данных условиях времени и места.
В силу закона больших чисел случайные отклонения и ошибки в измерении величин взаимопогашаются в массе явлений. Опять-таки в силу этого же свойства следует изучать основные закономерности в большой совокупности объектов, а не на отдельных объектах, на величину которых, кроме основной закономерности, действуют двоякого рода погрешности: индивидуальные особенности данного события (объекта) и неточности, связанные с измерением его величины.
При определенных условиях величину отдельного элемента в совокупности можно рассматривать как случайную величину, имея в виду, что она является не только автоматическим результатом какой-то общей закономерности, но в то же время и сама определена действием множества факторов, не зависящих от этой общей закономерности.
Поэтому в основе статистического исследования всегда лежит массовое наблюдение фактов. Но подчеркнем, что закон больших чисел не является регулятором процессов, изучаемых статистикой. Ошибочно считать его основным законом статистики. Он характеризует лишь одну из форм проявления закономерностей в массовых количественных отношениях, которую в науке называют статистической закономерностью.
16.Биномиальное распределение. Теорема Муавра-Лапласа. Норм.распределение.
Биномиальное распределение, распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях. Если при каждом испытании вероятность появления события равна р, причём 0 £ p £ 1, то число m появлений этого события при n независимых испытаниях есть случайная величина, принимающая значения m = 1, 2,.., n с вероятностями
![]()
где q =
1 — p, a ![]() — биномиальные
коэффициенты (отсюда название Б. р.).
Приведённая формула иногда называется
формулой Бернулли. Математическое
ожидание и дисперсия величины
m, имеющей Б. р., равны М (m)
= np и D (m)
= npq,
соответственно. При больших n, в
силу Лапласа
теоремы,
Б. р. близко к нормальному
распределению,
чем и пользуются на практике. При
небольших n приходится
пользоваться таблицами Б. р.
— биномиальные
коэффициенты (отсюда название Б. р.).
Приведённая формула иногда называется
формулой Бернулли. Математическое
ожидание и дисперсия величины
m, имеющей Б. р., равны М (m)
= np и D (m)
= npq,
соответственно. При больших n, в
силу Лапласа
теоремы,
Б. р. близко к нормальному
распределению,
чем и пользуются на практике. При
небольших n приходится
пользоваться таблицами Б. р.
Теорема Муавра — Лапласа — одна из предельных теорем теории вероятностей, установлена Лапласом в 1812 году. Если при каждом из n независимых испытаний вероятность появления некоторого случайного события Е равна р (0<р<1) и m — число испытаний, в которых Е фактически наступает, то вероятность неравенства близка (при больших n) к значению интеграла Лапласа. Нормальное распределение, также называемое распределением Гаусса — распределение вероятностей, которое в одномерном случае задается функцией плотности вероятности, совпадающей сфункцией Гаусса:
![]()
где параметр μ — математическое ожидание, медиана и мода распределения, а параметр σ —стандартное отклонение (σ² — дисперсия) распределения.
Таким образом, одномерное нормальное распределение является двухпараметрическим семейством распределений. Многомерный случай описан в многомерном нормальном распределении.
17.Центральная предельная теорема теории вероятностей и ее роль в статистике.
Простейший вариант Центральной предельной теоремы (ЦПТ) теории вероятностей таков.
Центральная
предельная теорема (для
одинаково распределенных слагаемых).
Пусть X1, X2,…, Xn,
…– независимые одинаково распределенные
случайные величины с математическими
ожиданиями M(Xi)
= m и
дисперсиями D(Xi) = ![]() , i =
1, 2,…, n,…
Тогда для любого действительного
числа х существует
предел
, i =
1, 2,…, n,…
Тогда для любого действительного
числа х существует
предел
![]()
где Ф(х) – функция стандартного нормального распределения.
Эту теорему иногда называют теоремой Линдеберга - Леви [3, с.122].
В ряде прикладных задач не выполнено условие одинаковой распределенности. В таких случаях центральная предельная теорема обычно остается справедливой, однако на последовательность случайных величин приходится накладывать те или иные условия. Суть этих условий состоит в том, что ни одно слагаемое не должно быть доминирующим, вклад каждого слагаемого в среднее арифметическое должен быть пренебрежимо мал по сравнению с итоговой суммой. Наиболее часто используется теорема Ляпунова.
Центральная
предельная теорема (для
разно распределенных слагаемых) – теорема
Ляпунова.
Пусть X1,X2,…, Xn,
…– независимые случайные величины
с математическими ожиданиями M(Xi)
= mi и
дисперсиями D(Xi) = ![]() , i =
1, 2,…, n,…
Пусть при некотором δ>0 у всех
рассматриваемых случайных величин
существуют центральные моменты порядка
2+δ и безгранично убывает «дробь Ляпунова»:
, i =
1, 2,…, n,…
Пусть при некотором δ>0 у всех
рассматриваемых случайных величин
существуют центральные моменты порядка
2+δ и безгранично убывает «дробь Ляпунова»:
![]()
где
![]()
Тогда для любого действительного числа х существует предел
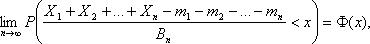 (1)
(1)
где Ф(х) – функция стандартного нормального распределения.
В случае одинаково распределенных случайных слагаемых
![]()
и теорема Ляпунова переходит в теорему Линдеберга-Леви.
19.Основные понятия теории статистического оценивания: состоятельные и несмещенные оценки.
Состоя́тельная оце́нка в математической статистике — это точечная оценка, сходящаяся по вероятности к оцениваемому параметру.
Определения:
Пусть
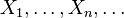 — выборка из распределения,
зависящего от параметра
— выборка из распределения,
зависящего от параметра 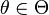 .
Тогда оценка
.
Тогда оценка 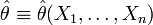 называется
состоятельной, если
называется
состоятельной, если
![]() по
вероятности при
по
вероятности при ![]() .
.
В противном случае оценка называется несостоятельной.
Оценка
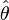 называется си́льно
состоя́тельной,
если
называется си́льно
состоя́тельной,
если
![]() почти
наверное при
почти
наверное при ![]() .
.
На практике «увидеть» сходимость «почти наверное» не представляется возможным, поскольку выборки конечны. Таким образом, для прикладной статистики достаточно требовать состоятельности оценки. Более того, оценки, которые были бы состоятельными, но не сильно состоятельными, «в жизни» встречаются очень редко. Закон больших чисел для одинаково распределённых и независимых величин с конечным первым моментом выполнен и в усиленном варианте, всякие крайние порядковые статистики тоже сходятся в силу монотонности не только по вероятности, но и почти наверное.
Пример:
Выборочное
среднее ![]() является
сильно состоятельной оценкой математического
ожидания
является
сильно состоятельной оценкой математического
ожидания ![]() .
.
Несмещённая оце́нка в математической статистике — это точечная оценка, математическое ожидание которой равно оцениваемому параметру.
Определение:
Пусть ![]() — выборка из распределения,
зависящего от параметра
— выборка из распределения,
зависящего от параметра ![]() .
Тогда оценка
.
Тогда оценка ![]() называется
несмещённой, если
называется
несмещённой, если
![]() .
.
В
противном случае оценка называется
смещённой, и случайная
величина ![]() называется
её смеще́нием.
называется
её смеще́нием.
21. Основные идеи теории проверки статистических гипотез. Уровень значимости и мощность критерия.
Проверка гипотезы осуществляется на основевыявления согласованности эмпирических данных с гипотетическими (теоретическими). Если расхождение между сравниваемыми величинами не выходит за пределы случайных ошибок,гипотезу принимают. При этом не делается никаких заключений о правильности самойгипотезы, речь идет лишь о согласованности сравниваемых данных. Основой проверкистатистических гипотез являются данные случайных выборок.
Статистической гипотезой называется предположение о свойстве генеральной совокупности,которое можно проверить, опираясь на данные выборки. Обозначается гипотеза буквой Н от латинского слова hypothesis.
Различают простые и сложные гипотезы. Гипотеза называется простой, если она однозначнохарактеризует параметр распределения случайной величины. Например, Н : ц = а.'Сложнаягипотеза состоит из конечного или бесконечного числа простых гипотез, при этом указываетсянекоторая область вероятных значений параметра. Например, Н : ? > b. Эта гипотеза состоит измножества простых гипотез Н :? = с, где с — любое число, большее b.
Статистическим критерием называют определенное правило, устанавливающее условия, прикоторых проверяемую нулевую гипотезу следует либо отклонить, либо не отклонить. Критерийпроверки статистической гипотезы определяет, противоречит ли выдвинутая гипотезафактическим данным или нет.
Проверка статистических гипотез складывается из следующих этапов:
• формулируется в виде статистической гипотезы задача исследования;
• выбирается статистическая характеристика гипотезы;
• выбираются испытуемая и альтернативная гипотезы на основе анализа возможных ошибочныхрешений и их последствий;
• определяются область допустимых значений, критическая область, а также критическоезначение статистического критерия (t, F, ?2 ) по соответствующей таблице;
• вычисляется фактическое значение статистического критерия;
• проверяется испытуемая гипотеза на основе сравнения фактического и критического значенийкритерия, и в зависимости от результатов проверки гипотеза либо отклоняется, либо не отклоняется.
Однозначно определенный способ проверки статистических гипотез называется статистическим критерием. Статистический критерий строится с помощью статистики U(x1, x2, …, xn) – функции от результатов наблюдений x1, x2, …, xn. В пространстве значений статистики U выделяют критическую область Ψ, т.е. область со следующим свойством: если значения применяемой статистики принадлежат данной области, то отклоняют (иногда говорят -отвергают) нулевую гипотезу, в противном случае – не отвергают (т.е. принимают).
Статистику U, используемую при построении определенного статистического критерия, называют статистикой этого критерия. Применяют критерий Колмогорова, основанный на статистике
![]() .
.
При этом Dn называют статистикой критерия Колмогорова.
В вероятностно-статистических методах принятия решений, статистические критерии, как правило, основаны на статистиках U, принимающих числовые значения, и критические области имеют вид
Ψ = {U(x1, x2, …, xn) > C}, (9)
где С – некоторые числа.
Итак, мощность критерия – это вероятность того, что нулевая гипотеза будет отвергнута, когда альтернативная гипотеза верна.
Понятия уровня значимости и мощности критерия объединяются в понятии функции мощности критерия – функции, определяющей вероятность того, что нулевая гипотеза будет отвергнута. Функция мощности зависит от критической области Ψ и действительного распределения результатов наблюдений. В параметрической задаче проверки гипотез распределение результатов наблюдений задается параметром θ. В этом случае функция мощности обозначается М(Ψ,θ) и зависит от критической области Ψ и действительного значения исследуемого параметра θ. Если
Н0: θ = θ0,
Н1: θ = θ1, то
М(Ψ,θ0) = α,
М(Ψ,θ1) = 1 – β,
где α – вероятность ошибки первого рода, β - вероятность ошибки второго рода. В статистическом приемочном контроле α – риск изготовителя, β – риск потребителя. При статистическом регулировании технологического процесса α – риск излишней наладки, β – риск незамеченной разладки.
Основной характеристикой статистического критерия является функция мощности. Для многих задач проверки статистических гипотез разработан не один статистический критерий, а целый ряд. Чтобы выбрать из них определенный критерий для использования в конкретной практической ситуации, проводят сравнение критериев по различным показателям качества, прежде всего с помощью их функций мощности.
22. Таблицы как способ описания данных. Таблица «объект – признак». Подлежащее и сказуемое статистической таблицы. Комбинационные таблицы.
Особое место в статистике занимает табличный метод, который имеет универсальное значение. С помощью статистических таблиц осуществляется представление данных результатов статистического наблюдения, сводки и группировки. Поэтому обычно статистическая таблица определяется как форма компактного наглядного представления статистических данных.
Внешне статистическая таблица представляет собой систему построенных особым образом горизонтальных строк и вертикальных столбцов, имеющих общий заголовок, заглавия граф и строк, на пересечении которых и записываются статистические данные.
Каждая цифра в статистических таблицах — это конкретный показатель, характеризующий размеры или уровни, динамику, структуру или взаимосвязи явлений в конкретных условиях места и времени, то есть определенная количественно-качественная характеристика изучаемого явления.
Основными элементами статистической таблицы являются подлежащее и сказуемое таблицы.
Подлежащее таблицы — это объект статистического изучения, то есть отдельные единицы совокупности, их группы или вся совокупность в целом.
Сказуемое таблицы — это статистические показатели, характеризующие изучаемый объект.
Подлежащее и показатели сказуемого таблицы должны быть определены очень точно. Как правило, подлежащее располагается в левой части таблицы и составляет содержание строк, а сказуемое — в правой части таблицы и составляет содержание граф.
Обычно при расположении показателей сказуемого в таблице придерживаются следующего правила: сначала приводят абсолютные показатели, характеризующие объем изучаемой совокупности, затем — расчетные относительные показатели, отражающие структуру, динамику и взаимосвязи между показателями.
Практикой статистики разработаны следующие правила составления таблиц:
Таблица должна быть выразительной и компактной. Поэтому вместо одной громоздкой таблицы по множеству признаков лучше сделать несколько небольших по объему, но наглядных, отвечающих задаче исследования таблиц.
Название таблицы, заглавия граф и строк следует формулировать точно и лаконично.
В таблице обязательно должны быть указаны: изучаемый объект, территория, и время к которым относятся приводимые в таблице данные, единицы измерения.
Если какие-то данные отсутствуют, то в таблице либо ставят многоточие, либо пишут "нет сведений", если какое-то явление не имело места, то ставят тире
Значения одних и тех же показателей приводятся в таблице с одинаковой степенью точности.
Таблица должна иметь итоги по группам, подгруппам и в целом. Если суммирование данных невозможно, то в этой графе ставят знак умножения "*".
В больших таблицах после каждых пяти строк делят промежуток, чтобы было удобнее читать и анализировать таблицу.
Вид статистической таблицы определяется характером разработки показателей ее подлежащего.
Различают три вида статистических таблиц:
простые
групповые
комбинационные
Простые таблицы содержат перечень отдельных единиц, входящих в состав совокупности анализируемого экономического явления. В групповых таблицах цифровая информация в разрезе отдельных составных частей исследуемой совокупности данных объединяется в определенные группы в соответствии с каким-либо признаком. Комбинированные таблицы содержат отдельные группы и подгруппы, на которые подразделяются экономические показатели, характеризующие изучаемое экономическое явление. При этом такое подразделение осуществляется не по одному, а по нескольким признакам. в групповых таблицах осуществляется простая группировка показателей, а в комбинированных — комбинированная группировка. Простые таблицы вообще не содержат никакой группировки показателей. Последний вид таблиц содержит лишь не сгруппированный набор сведений об анализируемом экономическом явлении.
Комбинационные таблицы
Комбинационные таблицы имеют в подлежащем группировку единиц совокупности по двум или более признакам.
|
Внешняя торговля РФ в 2007 г. (в фактически действовавших ценах) |
|
|
|
|
млрд.долл США |
в % к итогу |
|
Экспорт товаров |
355,2 |
100 |
|
со странами дальнего зарубежья |
301,5 |
84,9 |
|
со странами СНГ |
53,7 |
15,1 |
|
Импорт товаров |
223,1 |
100 |
|
со странами дальнего зарубежья |
191,2 |
85,7 |
|
со странами СНГ |
31,9 |
14,3 |
По характеру разработки показателей сказуемого различают:
таблицы с простой разработкой показателей сказуемого, в которых имеет место параллельное расположение показателей сказуемого.
таблицы со сложной разработкой показателей сказуемого, в которых имеет место комбинирование показателей сказуемого: внутри групп, образованных по одному признаку, выделяют подгруппы по другому признаку.
В зависимости от этапа статистического исследования таблицы делятся на:
разработочные (вспомогательные), цель которых обобщить информацию по отдельным единицам совокупности для получения итоговых показателей.
сводные, задача которых показать итоги по группам и всей совокупности в целом.
аналитические таблицы, задача которых — расчет обобщающих характеристик и подготовка информационной базы для анализа и структуры и структурных сдвигов, динамики изучаемых явлений и взаимосвязей между показателями.
23. Таблицы выборочных распределений. Расчет таблиц. Совпадение итога по столбцам и итога по строкам (при рассмотрении совместного распределений двух признаков).
См. любой пример из ДЗ по прикладной статистике. Задача номер 1 и 4.
24. Столбиковые и круговые диаграммы как способ наглядного графического представления данных.
Графический метод есть метод условных изображений статистических данных при помощи геометрических фигур, линий, точек и разнообразных символических образов.
Диаграмма - это чертеж, на котором численные данные представлены с помощью геометрических объектов (точек, линий, фигур различной формы и различных цветов) и вспомогательных элементов (осей координат, условных обозначений, заголовков и т.п.). В зависимости от типа используемых геометрических объектов, диаграммы делятся на точечные, линейные, плоскостные и пространственные (объемные). Плоскостные и пространственные диаграммы могут составляться из объектов различной формы и бывают, например, столбиковыми, круговыми, фигурными и т.д.
Столбиковая диаграмма используется для наглядного сравнения данных либо для представления изменения данных за определенный промежуток времени.
Принцип построения такой диаграммы состоит в изображении статистических показателей в виде поставленных по вертикали прямоугольников - столбиков. Каждый столбик изображает величину отдельного уровня исследуемого статистического ряда. Таким образом, сравнение статистических показателей возможно потому, что все сравниваемые показатели выражены в одной единице измерения.
Правила построения столбиковых диаграмм допускают одновременное расположение на одной горизонтальной оси изображений нескольких показателей (рис.1.11). В этом случае столбики располагаются группами, для каждой из которых может быть принята разная размерность варьирующих признаков.
Достаточно распространенным способом графического изображения структуры статистических совокупностей является секторная диаграмма, так как идея целого очень наглядно выражается кругом, который представляет всю совокупность. Относительная величина каждого значения изображается в виде сектора круга, площадь которого соответствует вкладу этого значения в сумму значений. Этот вид графиков удобно использовать, когда нужно показать долю каждой величины в общем объеме.
Для этого строятся круги, пропорциональные объему изучаемого признака, а затем секторами выделяются его отдельные части.
Рассмотренный способ графического изображения структуры совокупности имеют как достоинства, так и недостатки.
Так, секторная диаграмма сохраняет наглядность и выразительность лишь при небольшом числе частей совокупности, в противном случае ее применение малоэффективно. Кроме того, наглядность секторной диаграммы снижается при незначительных изменениях структуры изображаемых совокупностей: она выше, если существеннее различия сравниваемых структур. Преимуществом столбиковых диаграмм по сравнению с секторными является их большая емкость, возможность отразить более широкий объем полезной информации.
25. Вариационный ряд.
Если ряд распределения
построен по количественному признаку,
то такой ряд называют ![]() вариационным.
Построить вариационный ряд - значит
упорядочить количественное распределение
единиц совокупности по значениям
признака, а затем подсчитать числа
единиц совокупности с этими значениями
(построить групповую таблицу).
вариационным.
Построить вариационный ряд - значит
упорядочить количественное распределение
единиц совокупности по значениям
признака, а затем подсчитать числа
единиц совокупности с этими значениями
(построить групповую таблицу).
Выделяют три формы вариационного ряда: ранжированный ряд, дискретный ряд и интервальный ряд.
![]() Ранжированный
ряд - это
распределение отдельных единиц
совокупности в порядке возрастания или
убывания исследуемого признака.
Ранжирование позволяет легко разделить
количественные данные по группам, сразу
обнаружить наименьшее и наибольшее
значения признака, выделить значения,
которые чаще всего повторяются.
Ранжированный
ряд - это
распределение отдельных единиц
совокупности в порядке возрастания или
убывания исследуемого признака.
Ранжирование позволяет легко разделить
количественные данные по группам, сразу
обнаружить наименьшее и наибольшее
значения признака, выделить значения,
которые чаще всего повторяются.
Другие формы вариационного ряда - групповые таблицы, составленные по характеру вариации значений изучаемого признака. По характеру вариации различают дискретные (прерывные) и непрерывные признаки.
![]() Дискретный
ряд - это такой
вариационный ряд, в основу построения
которого положены признаки с прерывным
изменением (дискретные признаки). К
последним можно отнести тарифный разряд,
количество детей в семье, число работников
на предприятии и т.д. Эти признаки могут
принимать только конечное число
определенных значений.
Дискретный
ряд - это такой
вариационный ряд, в основу построения
которого положены признаки с прерывным
изменением (дискретные признаки). К
последним можно отнести тарифный разряд,
количество детей в семье, число работников
на предприятии и т.д. Эти признаки могут
принимать только конечное число
определенных значений.
Дискретный вариационный ряд представляет таблицу, которая состоит из двух граф. В первой графе указывается конкретное значение признака, а во второй - число единиц совокупности с определенным значением признака.
Если признак имеет
непрерывное изменение (размер дохода,
стаж работы, стоимость основных фондов
предприятия и т.д., которые в определенных
границах могут принимать любые значения),
то для этого признака нужно
строить ![]() интервальный
вариационный ряд.
интервальный
вариационный ряд.
Групповая таблица здесь также имеет две графы. В первой указывается значение признака в интервале «от - до» (варианты), во второй - число единиц, входящих в интервал (частота).
Частота (частота повторения) - число повторений отдельного варианта значений признака, обозначается fi , а сумма частот, равная объему исследуемой совокупности, обозначается
![]()
где k - число вариантов значений признака
Очень часто таблица дополняется графой, в которой подсчитываются накопленные частоты S, которые показывают, какое количество единиц совокупности имеет значение признака не большее, чем данное значение.
Частоты ряда f могут заменяться частостями w, выраженными в относительных числах (долях или процентах). Они представляют собой отношения частот каждого интервала к их общей сумме, т.е.:
![]()
![]() (7.1)
(7.1)
При построении вариационного ряда с интервальными значениями прежде всего необходимо установить величину интервала i, которая определяется как отношение размаха вариации R к числу групп m:
![]() (7.2)
(7.2)
где R = xmax -
xmin ;
m = 1 + 3,322 lgn (формула ![]() Стерджесса);
n - общее число единиц совокупности.
Стерджесса);
n - общее число единиц совокупности.
26. Выборочное среднее арифметическое и математическое ожидание. Состоятельность и несмещенность выборочного среднего арифметического как оценки математического ожидания.

Математическим ожиданием случайной величины Х называется число
![]() (4)
(4)
т.е. математическое ожидание случайной величины — это взвешенная сумма значений случайной величины с весами, равными вероятностям соответствующих элементарных событий.
Пусть случайная величина Х принимает значения х1, х2,…, хm. Тогда справедливо равенство
![]() (5)
(5)
т.е. математическое ожидание случайной величины — это взвешенная сумма значений случайной величины с весами, равными вероятностям того, что случайная величина принимает определенные значения.
27. Выборочная и теоретическая дисперсии. Несмещенная оценка теоретической дисперсии. Две формулы для расчета выборочной дисперсии.
Математическое ожидание показывает, вокруг какой точки группируются значения случайной величины. Необходимо также уметь измерить изменчивость случайной величины относительно математического ожидания. Выше показано, что M[(X–a)2] достигает минимума по а при а = М(Х). Поэтому за показатель изменчивости случайной величины естественно взять именно M[(X–М(Х))2].
.
Дисперсией случайной величины Х
называется число
![]()

28. Выборочное среднее квадратическое отклонение и его аналог - теоретическое среднее квадратическое (среднее квадратичное, стандартное) отклонение.29. Выборочный и теоретический коэффициенты вариации.
Среднее квадратическое отклонение – это неотрицательное значение квадратного корня из дисперсии:
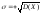 .
.
Коэффициент вариации – это отношение среднего квадратического отклонения к математическому ожиданию:
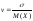 .
.
Коэффициент вариации применяется при M(X)>0. Он измеряет разброс в относительных единицах, в то время как среднее квадратическое отклонение – в абсолютных.

30. Минимум, максимум и размах как выборочные характеристики.

31. Мода выборки и амплитуда моды.

32. Выборочная медиана и теоретическая медиана.
Большое значение в статистике имеет квантиль порядка р = 1/2. Он называется медианой (случайной величины Х или ее функции распределения F(x)) и обозначается Me(X). В геометрии есть понятие «медиана» – прямая, проходящая через вершину треугольника и делящая противоположную его сторону пополам. В математической статистике медиана делит пополам не сторону треугольника, а распределение случайной величины: равенство F(x0,5) = 0,5 означает, что вероятность попасть левее x0,5 и вероятность попасть правее x0,5 (или непосредственно в x0,5) равны между собой и равны 1/2, т.е.
P(X < x0,5) = P(X > x0,5) = 1/2.
Медиана указывает «центр» распределения.

33. Выборочные и теоретические верхний квартиль, нижний квартиль и межквартильное расстояние.
Квантиль порядка р =1/4 и порядка р = 3/4 показывают соответственно четверть и три четверти распределения.

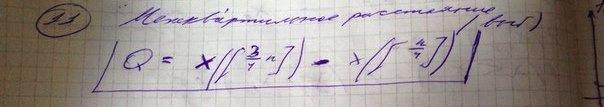
34. Расчет средних характеристик (средней арифметической, медианы, моды) заработной платы для условного предприятия.
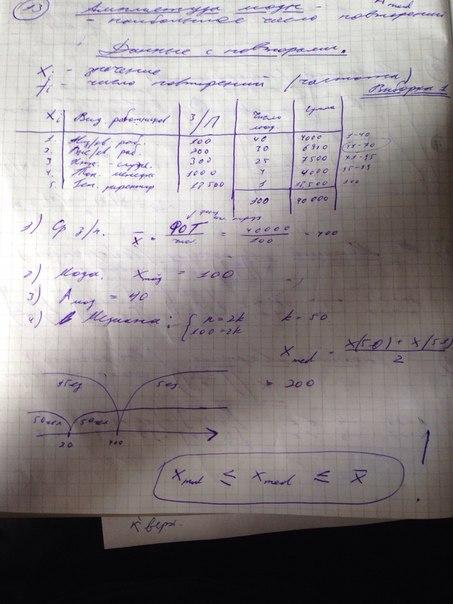
35. Данные с повторами (сгруппированные данные) и соответствующие варианты формул для расчета выборочных характеристик.
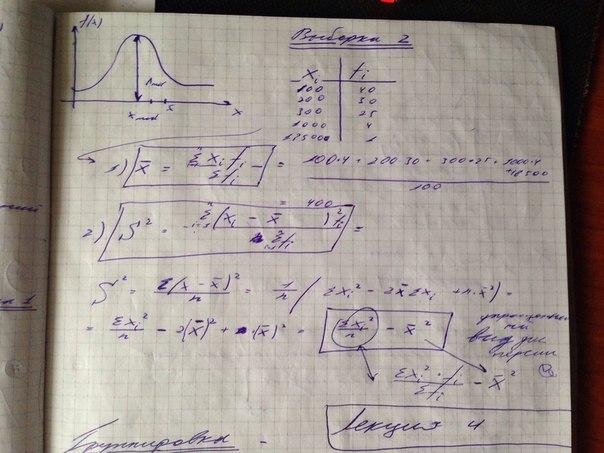
Все остальные характеристики расчитываются одинаково.
36. Эмпирическая функция распределения. График эмпирической функции распределения. Свойства эмпирической функции распределения. Теорема Гливенко.
Понятие функции распределения было дано в разделе теории вероятности для случайной величины. Для выборки вводится понятие эмпирической функции распределения. Эмпирическая функция распределения (функция распределения выборки) это функция F*(x), которая определяет для каждого значения xiотносительную частоту события X<x. Эмпирическая функция распределения имеет вид:
|
|
|
(6.1) |
где: nx – число вариант меньших х, n – объём выборки.
Определение 1.
Эмпирической функцией
распределения, построенной по
выборке ![]() объема
объема![]() ,
называется случайная функция
,
называется случайная функция![]() ,
при каждом
,
при каждом![]() равная
равная

Эмпирическая функция распределения F*(x) по вероятности стремится к теоретической функции распределения F(x) при больших количествах испытаний и обладает всеми свойствами F(x):
Значения эмпирической функции принадлежат отрезку F*(x) Î [0;1].
F*(x) – неубывающая функция.
Если х1 – наименьшая варианта, то F*(x)=0 при x ≤ x1.
Если хk – наибольшая варианта, то F*(x)=1 при x > xk.
Можно построить эмпирическую функцию распределения по вариационному ряду:

Верен более общий результат, показывающий, что сходимость эмпирической функции распределения к теоретической имеет «равномерный» характер.
Теорема Гливенко — Кантелли.
Пусть ![]() —
выборка объема
—
выборка объема![]() из
неизвестного распределения
из
неизвестного распределения![]() с
функцией распределения
с
функцией распределения![]() .
Пусть
.
Пусть![]() —
эмпирическая функция распределения,
построенная по этой выборке. Тогда
—
эмпирическая функция распределения,
построенная по этой выборке. Тогда
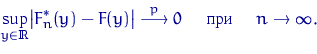
Замечание 3.
Более того, в условиях теорем 1и Гливенко — Кантелли имеет место сходимость не только по вероятности, но ипочти, наверное.
37. Статистика Колмогорова и ее распределение.
статистический критерий, применяемый для проверки простой непараметрической гипотезы Н 0, согласно к-рой независимые одинаково распределенные случайные величины Х 1,..., Х п имеют заданную непрерывную функцию распределения F(x), причем альтернативная гипотеза Н 1 предполагается двусторонней:
![]()
где ![]() -
математическое ожидание функции
эмпирического
распределения Fn(x). Критическое множество К.
к. выражается неравенством
-
математическое ожидание функции
эмпирического
распределения Fn(x). Критическое множество К.
к. выражается неравенством
![]()
и
основано на теореме, доказанной А. Н.
Колмогоровым в 1933: в случае справедливости
гипотезы Н 0 распределение
статистики Dn не
зависит от функции F(x), причем
если ![]() то
то
![]()
где
![]()
В
1948 Н. В. Смирнов [4] табулировал функцию
распределения Колмогорова К(l). Согласно
К. к. с уровнем значимости a, 0< a <0,5,
гипотезу Н 0 следует
отвергнуть, если ![]() где
ln(a)
- критическое значение К. к., соответствующее
заданному уровню значимости а и являющееся
корнем уравнения
где
ln(a)
- критическое значение К. к., соответствующее
заданному уровню значимости а и являющееся
корнем уравнения ![]()
Для
определения ln(a)
рекомендуется пользоваться аппроксимацией
допредельного закона статистики
Колмогорова Dn ее
предельным распределением; см. [3], где
показано, что если ![]() и
и ![]() то
то
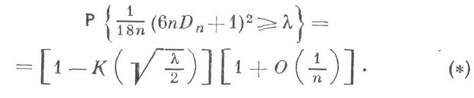
Применение аппроксимации дает следующее приближение критического значения
![]()
где
z - корень уравнения ![]()
На практике для вычисления значения статистики Dn пользуются тем обстоятельством, что
![]()
где
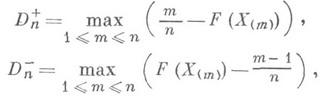
![]() - вариационный
ряд, построенный
по выборке X1,
... ,Х п. К.
к. имеет следующее геометрич. истолкование
(см. рис.).
- вариационный
ряд, построенный
по выборке X1,
... ,Х п. К.
к. имеет следующее геометрич. истолкование
(см. рис.).
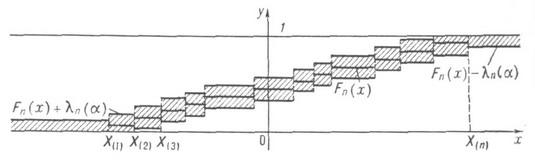
Изобразим
на плоскости хОу графики
функций Fn(x),![]() Заштрихованная область является
доверительной зоной уровня 1-a. для
функции распределения F(x), так
как если гипотеза Н 0 верна,
то согласно теореме Колмогорова
Заштрихованная область является
доверительной зоной уровня 1-a. для
функции распределения F(x), так
как если гипотеза Н 0 верна,
то согласно теореме Колмогорова
![]()
Если график функции F(x)не выходит из заштрихованной области, то по К. к. с уровнем значимости, а гипотезу H0 следует принять, в противном случае гипотеза H0 отвергается.
К. к. дал мощный толчок развитию математич. статистики, в результате чего были получены совершенно новые методы статистич. исследований, к-рые легли в основу непараметрич. статистики.
38. Критерий Колмогорова – критерий согласия с заданным фиксированным распределением.
Теорема Колмогорова.
Пусть ![]() —
выборка объема
—
выборка объема![]() из
неизвестного распределения
из
неизвестного распределения![]() с непрерывной функцией
распределения
с непрерывной функцией
распределения![]() ,
а
,
а![]() -- эмпирическая
функция распределения. Тогда
-- эмпирическая
функция распределения. Тогда
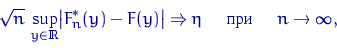
где случайная
величина ![]() имеет
распределение Колмогорова с непрерывной
функцией распределения
имеет
распределение Колмогорова с непрерывной
функцией распределения

Следующие свойства
эмпирической функции распределения —
это хорошо знакомые нам свойства среднего
арифметического ![]() независимых
слагаемых, имеющих, к тому же,
распределение Бернулли.
независимых
слагаемых, имеющих, к тому же,
распределение Бернулли.
В
первых двух пунктах утверждается, что
случайная величина ![]() имеет
математическое ожидание
имеет
математическое ожидание![]() и
дисперсию
и
дисперсию![]() ,
которая убывает как
,
которая убывает как![]() .
Третий пункт показывает, что
.
Третий пункт показывает, что![]() сходится
к
сходится
к![]() со
скоростью
со
скоростью![]() .
.
Свойство 1.
Для
любого ![]()
1)
![]() ,
т.е.
,
т.е. ![]() —
«несмещенная» оценка для
—
«несмещенная» оценка для![]() ;
;
2)
![]() ;
;
3)
если ![]() ,
то
,
то![]() ,
т.е.
,
т.е.![]() —
«асимптотически нормальная» оценка
для
—
«асимптотически нормальная» оценка
для![]() ;
;
4)
случайная
величина ![]() имеет
биномиальное распределение
имеет
биномиальное распределение![]() .
.
Доказательство
свойства 1.
Заметим снова, что![]() имеет
распределение Бернулли
имеет
распределение Бернулли![]() ,
поэтому
,
поэтому
![]()
1)
Случайные
величины ![]() ,
,![]() ,
,![]() одинаково
распределены, поэтомугде
используется одинаковая распределенность?
одинаково
распределены, поэтомугде
используется одинаковая распределенность?
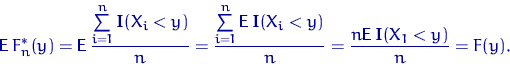
2)
Случайные
величины ![]() ,
,![]() ,
,![]() независимы
и одинаково распределены, поэтомугде
используется независимость?
независимы
и одинаково распределены, поэтомугде
используется независимость?
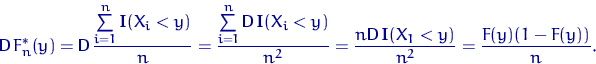
3)
Воспользуемся ЦПТ Ляпунова:а что это такое?

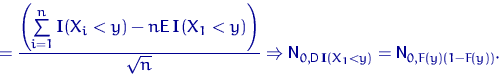
4)
Поскольку ![]() (число
успехов в одном испытании) имеет
распределение Бернулли
(число
успехов в одном испытании) имеет
распределение Бернулли![]() ,почему? то
,почему? то ![]() имеет
биномиальное распределение
имеет
биномиальное распределение![]() .почему? а
что такое устойчивость по суммированию?
.почему? а
что такое устойчивость по суммированию?
Замечание 4. Все определения, как то: «оценка», «несмещенность», «состоятельность», «асимптотическая нормальность» будут даны в главе 2. Но смысл этих терминов должен быть вполне понятен уже сейчас.
43)Непараметрические ядерные оценки плотности.
Методы оценивания плотности вероятности в пространствах общего вида предложены и первоначально изучены в работе [18]. В частности, в задачах диагностики объектов нечисловой природы предлагаем использовать непараметрические ядерные оценки плотности типа Парзена-Розенблатта (этот вид оценок и его название впервые были введены в статье [18] ). Они имеют вид:
![]()
где
К:
![]() – так называемая ядерная функция,x1,
x2,
…, xn
– так называемая ядерная функция,x1,
x2,
…, xn
![]() X –
выборка, по которой оценивается плотность,
d(xi,
x) – показатель
различия (метрика, расстояние, мера
близости) между элементом выборки xi
и точкой
x,
в которой оценивается плотность,
последовательность hn
показателей
размытости такова, что
hn
X –
выборка, по которой оценивается плотность,
d(xi,
x) – показатель
различия (метрика, расстояние, мера
близости) между элементом выборки xi
и точкой
x,
в которой оценивается плотность,
последовательность hn
показателей
размытости такова, что
hn![]() 0 и nhn
0 и nhn![]() при
при
![]() ,
а
,
а![]() – нормирующий множитель, обеспечивающий
выполнение условия нормировки (интеграл
по всему пространству от непараметрической
оценки плотностиfn(x)
по мере
– нормирующий множитель, обеспечивающий
выполнение условия нормировки (интеграл
по всему пространству от непараметрической
оценки плотностиfn(x)
по мере
![]() должен равняться 1). Ранее американские
исследователи Парзен и Розенблатт
использовали подобные статистики в
случае
должен равняться 1). Ранее американские
исследователи Парзен и Розенблатт
использовали подобные статистики в
случае![]() сd(xi
, x)
= |xi
— x|
.
сd(xi
, x)
= |xi
— x|
.
Введенные описанным образом ядерные оценки плотности – частный случай так называемых линейных оценок, также впервые предложенных в работе [18]. В теоретическом плане они выделяются тем, что удается получать результаты такого же типа, что в классическом одномерном случае, но, разумеется, с помощью совсем иного математического аппарата.
44)Прикладная статистика как наука о том, как обрабатывать данные – результаты наблюдений, измерений, испытаний, анализов, опытов. Статистические технологии. Десять основных этапов прикладного статистического исследования.
Статистика – это отрасль практической деятельности по сбору, накоплению, обработке и анализ цифровых данных, характеризующих население, экономику, культуру, образование и другие явления общественной жизни и предназначенную для задач государственного регулирования и управления.
Статистика – это собственно данные (цифровой материал), который обрабатывается определенными методами.
Статистические технологии. Статистический анализ конкретных данных, как правило, включает в себя целый ряд процедур и алгоритмов, выполняемых последовательно, параллельно или по более сложной схеме. В частности, с точки зрения организатора прикладного статистического исследования можно выделить следующие этапы:
- планирование статистического исследования (включая разработку анкет, бланков наблюдения и учета и других форм сбора данных; их апробацию; подготовку сценариев интервью и анализа данных и т.п.);
- организация сбора необходимых статистических данных по оптимальной или рациональной программе (планирование выборки, создание организационной структуры и подбор команды статистиков, подготовка кадров, которые будут заниматься сбором данных, а также контролеров данных и т.п.);
- непосредственный сбор данных и их фиксация на тех или иных носителях (с контролем качества сбора и отбраковкой ошибочных данных по соображениям предметной области);
- первичное описание данных (расчет различных выборочных характеристик, функций распределения, непараметрических оценок плотности, построение гистограмм, корреляционных полей, различных таблиц и диаграмм и т.д.),
- оценивание тех или иных числовых или нечисловых характеристик и параметров распределений (например, непараметрическое интервальное оценивание коэффициента вариации или восстановление зависимости между откликом и факторами, т.е. оценивание функции),
- проверка статистических гипотез (иногда их цепочек - после проверки предыдущей гипотезы принимается решение о проверке той или иной последующей гипотезы; например, после проверки адекватности линейной регрессионной модели и отклонения этой гипотезы может проверяться адекватность квадратичной модели),
- более углубленное изучение, т.е. одновременное применение различных алгоритмов многомерного статистического анализа, алгоритмов диагностики и построения классификации, статистики нечисловых и интервальных данных, анализа временных рядов и др.;
- проверка устойчивости полученных оценок и выводов относительно допустимых отклонений исходных данных и предпосылок используемых вероятностно-статистических моделей, в частности, изучение свойств оценок методом размножения выборок и другими численными методами;
- применение полученных статистических результатов в прикладных целях, т.е. для формулировки выводов в терминах содержательной области (например, для диагностики конкретных материалов, построения прогнозов, выбора инвестиционного проекта из предложенных вариантов, нахождения оптимальных режима осуществления технологического процесса, подведения итогов испытаний образцов технических устройств и др.),
- составление итоговых отчетов, в частности, предназначенных для тех, кто не является специалистами в статистических методах анализа данных, в том числе для руководства - "лиц, принимающих решения".
45)Необходимость выборочных исследований. Построение выборочной функции ожидаемого спроса и расчет оптимальной розничной цены при заданной оптовой цене(издержках).
Термин «выборочные исследования» применяют, когда невозможно изучить все единицы представляющей интерес совокупности. Приходится знакомиться с частью совокупности – с выборкой, а затем с помощью статистических методов и моделей переносить выводы с выборки на всю совокупность. Выборочные исследования – способ получения статистических данных и важная часть прикладной статистики.
В одном из экспериментов выборка состояла из 20 опрошенных. Они назвали следующие максимально допустимые для них цены (в рублях по состоянию на сентябрь 1998 г.):