

Лабораторная работа № 1
Основы статистической обработки информации с использованием EXCEL. Определение некоторых числовых характеристик экспериментальных статистических данных.
Основной целью статистического анализа является выяснение некоторых свойств изучаемой генеральной совокупности. Если генеральная совокупность конечна, то наилучшая процедура — рассмотрение каждого ее элемента. Однако в большинстве задач используются либо бесконечные генеральные совокупности, либо конечные, но трудно обозримые. В этой ситуации необходимо отобрать из генеральной совокупности подмножество из n элементов, называемое выборкой объема n, исследовать его свойства, а затем обобщить эти результаты на всю генеральную совокупность. Это обобщение называется статистическим выводом.
Генеральная совокупность (популяция) W — полный набор объектов w, с которыми связана данная проблема. Эти объекты могут быть людьми, животными, изделиями и так далее. С каждым объектом связана величина (или величины), называемая исследуемым признаком (xi).
Различные значения признака, наблюдающиеся у членов генеральной совокупности (или выборки), называются вариантами, а числа, показывающие сколько раз встречается каждый вариант — их частотами.
В данном определении предполагается дискретное изменения признака. Однако, если мы измеряем непрерывную величину, то точность измерения и количество измерений в единицу времени тоже дадут некий дискретный набор.
Мы предполагаем, что измеряемый или исследуемый признак изменяется некоторым случайным образом. Произведя серию измерений, получим набор данных, которые, скорее всего, будут случайной выборкой из генеральной совокупности. Чтобы провести первичную обработку этой выборки, необходимо построить экспериментальное распределение данных по частотам или (если данные имеют явно непрерывный характер) по интервалам частот.
Числовые характеристики статистического распределения
В качестве характеристик измеримого признака вместо исходных значений величин или таблиц их частот используют числовые характеристики, называемые также статистическими мерами.
Среднее арифметическое
 :
Определяется по формуле
:
Определяется по формуле
![]() ,
где xi — значения вариант.
,
где xi — значения вариант.
Медиана
 —
срединное значение для ряда измерений
n. Для ее вычисления необходимо все
наблюдения расположить в порядке
возрастания или убывания результатов.
Если n — нечетное число, то медиана
просто является числом, находящимся в
середине упорядоченной последовательности.
При четном n
равна
среднему арифметическому двух
расположенных в середине значений
упорядоченной последовательности.
—
срединное значение для ряда измерений
n. Для ее вычисления необходимо все
наблюдения расположить в порядке
возрастания или убывания результатов.
Если n — нечетное число, то медиана
просто является числом, находящимся в
середине упорядоченной последовательности.
При четном n
равна
среднему арифметическому двух
расположенных в середине значений
упорядоченной последовательности.
Мода — (наиболее вероятное значение) является наиболее часто встречающейся в выборке величиной.
Размах вариации R — разность между максимальным и минимальным значениями признака в ряде измерений.
R = xmax -xmin
Среднее линейное отклонение d — среднее арифметическое абсолютных величин отклонений вариантов от их средней арифметической.
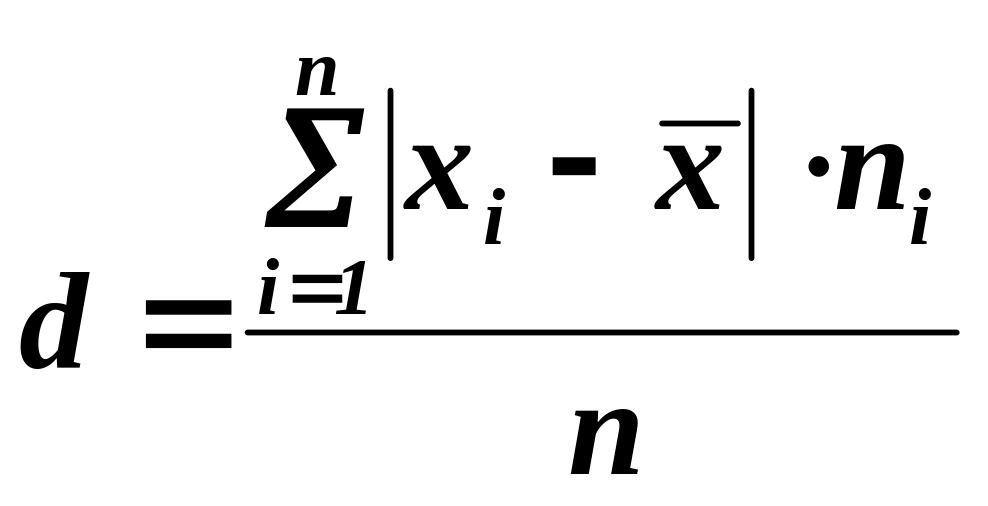 ,
ni — частота признака xi.
,
ni — частота признака xi.
Дисперсия D — среднее арифметическое квадратов отклонений вариантов от их средней:
![]()
Среднее квадратичное отклонение — квадратный корень из дисперсии.
Под формой статистического распределения понимается форма его графика — полигона или гистограммы. Различают симметричные формы и несимметричные (асимметричные).
Распределение называется симметричным, если веса любых вариантов, равноотстоящих от среднего, равны между собой.
На практике такого совпадения для всех вариантов обычно нет и симметричными считаются распределения, в которых веса вариантов, равноотстоящих от среднего, отличаются незначительно. (Пример 1 — близок к симметричному распределению).
Асимметричные распределения можно разбить на три вида:
умеренно асимметричные — распределения, у которых частоты, находящиеся по одну сторону от наибольшей, больше (или меньше) частот, находящихся по другую сторону от наибольшей на таком же “расстоянии”.
крайне асимметричные — распределения, у которых частоты или все время возрастают, или все время убывают.
U-образные — частоты сначала убывают, а затем возрастают.
В табл. № 1 представлены экспериментальные данные, полученные после медицинского обследования 100 студентов МаГУ. Необходимо оценить числовые характеристики выборки студентов, проанализировать форму распределения частот.
Таблица 1
Результаты измерения веса студентов МаГУ
61 |
57 |
61 |
85 |
48 |
41 |
73 |
66 |
91 |
70 |
50 |
45 |
64 |
46 |
55 |
82 |
69 |
75 |
82 |
72 |
68 |
43 |
81 |
71 |
47 |
50 |
54 |
75 |
81 |
68 |
80 |
67 |
64 |
76 |
61 |
57 |
62 |
57 |
66 |
53 |
79 |
56 |
63 |
88 |
65 |
74 |
67 |
54 |
65 |
80 |
86 |
40 |
59 |
64 |
65 |
71 |
72 |
78 |
70 |
61 |
39 |
63 |
89 |
59 |
61 |
75 |
67 |
51 |
65 |
55 |
62 |
60 |
75 |
73 |
91 |
72 |
54 |
46 |
52 |
55 |
78 |
67 |
94 |
60 |
44 |
49 |
88 |
74 |
44 |
60 |
52 |
61 |
66 |
74 |
56 |
52 |
71 |
73 |
75 |
60 |
Используя данные выборки студентов, рассчитать:
среднее арифметическое;
медиану;
моду;
дисперсию;
среднее квадратичное отклонение;
эксцесс;
асимметрию распределения.
Построить в Excel гистограмму распределения признаков по частотам и полигон частот. Для этого:
найти min и max значения в выборочной совокупности (с помощью статистических функций Excel);
размах варьирования: Rx = xmax - xmin;
число интервалов: k [1+3,2 lg(n)], (n – количество данных в выборке).
создать массив признаков (интервалов) и посчитать для них частоту.
Для создания массива признаков сначала рассчитывают цену деления c= Rx/k.
Затем рассчитывают первый интервал по формуле: min + c, следующий интервал определяется как предыдущий плюс цена деления, эта формула копируется до тех пор пока последний признак не станет равным или немного больше максимального значения в выборке.
3. Определить форму распределения выборки