

Раздел 3 Пример выполнения самостоятельной работы
Пример ответа на первый теоретический вопрос
Теоретический вопрос: "Основные этапы технологического процесса подготовки и решения экономических задач на ПЭВМ"
Автоматизированная обработка экономической информации (АОЭИ)
В процессах автоматизированной обработки экономической информации в качестве объекта, подвергающегося преобразованиям, выступают различного рода данные, которые характеризуют те или иные экономические явления. Такие процессы именуются технологическими процессами АОЭИ и представляют собой комплекс взаимосвязанных операций, протекающих в установленной последовательности. Или, более детально, это процесс преобразования исходной информации в выходную с использованием технических средств и ресурсов.
Рациональное проектирование технологических процессов обработки данных в ЭИС во многом определяет эффективное функционирование всей системы.
Весь технологический процесс можно подразделить на процессы сбора и ввода исходных данных в вычислительную систему, процессы размещения данных и хранения в памяти системы, процессы обработки данных с целью получения результатов и, процессы выдачи данных в виде, удобном для восприятия пользователем.
Технологический процесс можно разделить на 4 укрупненных этапа:
– начальный или первичный (сбор исходных данных, их регистрация и передача на ВУ);
– подготовительный (прием, контроль, регистрация входной информации и перенос ее на машинный носитель);
– основной (непосредственно обработка информации);
– заключительный (контроль, выпуск и передача результатной информации, ее размножение и хранение).
Технологические операции сбора, передачи, хранения, контроля и обработки данных
В зависимости от используемых технических средств и требований к технологии обработки информации изменяется и состав операций технологического процесса.
Операции сбора и регистрации данных осуществляются с помощью различных средств. Различают:
– механизированный;
– автоматизированный;
– автоматический;
Механизированный – сбор и регистрация информации осуществляется непосредственно человеком с использованием простейших приборов (весы, счетчики, мерная тара, приборы учета времени и т.д.).
Автоматизированный – использование машиночитаемых документов, регистрирующих автоматов, универсальных систем сбора и регистрации, обеспечивающих совмещение операций формирования первичных документов и получения машинных носителей.
Автоматический – используется в основном при обработке данных в режиме реального времени (информация с датчиков, учитывающих ход производства – выпуск продукции, затраты сырья, простои оборудования и т.д. – поступает непосредственно в ЭВМ).
Технические средства передачи данных включают:
– аппаратуру передачи данных (АПД), которая соединяет средства обработки и подготовки данных с телеграфными, телефонными и широкополосными каналами связи;
– устройства сопряжения ЭВМ с АПД, которые управляют обменом информации – мультиплексоры передачи данных.
Запись и передача информации по каналам связи в ЭВМ имеет следующие преимущества:
– упрощает процесс формирования и контроля информации;
– соблюдается принцип однократной регистрации информации в первичном документе и машинном носителе;
– обеспечивается высокая достоверность информации, поступающей в ЭВМ.
Дистанционная передача данных, основанная на использовании каналов связи, представляет собой передачу данных в виде электрических сигналов, которые могут быть непрерывными во времени и дискретными, т.е. носить прерывный во времени характер. Наиболее широко используются телеграфные и телефонные каналы связи. Электрические сигналы, передаваемые по телеграфному каналу связи, являются дискретными, а по телефонному – непрерывными.
В зависимости от направлений, по которым пересылается информация, различают каналы связи:
– симплексный (передача идет только в одном направлении);
– полудуплексный (в каждый момент времени производится либо передача, либо прием информации);
– дуплексный (передача и прием информации осуществляются одновременно в двух встречных направлениях).
Каналы характеризуются скоростью передачи данных, достоверностью, надежностью передачи.
Скорость передачи определяется количеством информации, передаваемой в единицу времени и измеряется в бодах (бод = бит/сек):
Телеграфные каналы (низкоскоростные – V = 50-200 бод).
Телефонные (среднескоростные – V = 200-2400 бод).
Широкополосные (высокоскоростные – V = 4800 бод и более). При выборе наилучшего способа передачи информации учитываются объемные и временные параметры доставки, требования к качеству передаваемой информации, трудовые и стоимостные затраты на передачу информации.
Говоря о технологических операциях сбора, регистрации, передачи информации с помощью различных технических средств необходимо несколько слов сказать и о сканирующих устройствах.
Ввод информации, особенно графической, с помощью клавиатуры в ЭВМ очень трудоемок. В последнее время наметились тенденции применения деловой графики – одного из основных видов информации, что требует оперативности ввода в ЭВМ и предоставления пользователям возможности формирования гибридных документов и БД, объединяющих графику с текстом. Все эти функции в ПЭВМ выполняют сканирующие устройства. Они реализуют оптический ввод информации и преобразование ее в цифровую форму с последующей обработкой.
Для ПЭВМ IBM PC разработана система PC Image/Graphix, предназначенная для сканирования различных документов и их передачи по коммуникациям. В числе документальных носителей системы, которые могут сканироваться камерой, являются: текст, штриховые чертежи, фотографии, микрофильмы. Сканирующие устройства на базе ПЭВМ применяются не только для ввода текстовой и графической информации, но и в системах контроля, обработки писем, выполнения различных учетных функций.
Для указанных задач наибольшее применение нашли способы кодирования информации штриховыми кодами. Сканирование штриховых кодов для ввода информации в ПЭВМ производится с помощью миниатюрных сканеров, напоминающих карандаш. Сканер перемещается пользователем перпендикулярно группе штрихов, внутренний источник света освещает область этого набора непосредственно около наконечника сканера. Штриховые коды нашли широкое применение и в сфере торговли, и на предприятиях (в системе табельного учета: при считывании с карточки работника фактически отработанное время, регистрирует время, дату и т.д.).
В последнее время все большее внимание уделяется устройствам тактильного ввода – сенсорному экрану ("сенсорный" – чувствительный). Устройства тактильного ввода широко применяются как информационно-
справочные системы общего пользования и системы автоматизированного обучения. Фирмой США разработан сенсорный монитор Point-1 с разрешением 1024 х 1024 точек для ПЭВМ IBM PC и др. ПЭВМ. Сенсорный экран широко применяется для фондовых бирж (сведения о последних продажных ценах на акции ...).
На практике существует множество вариантов (организационных форм) технологических процессов обработки данных. Это зависит от использования различных средств вычислительной и организационной техники на отдельных операциях технологического процесса.
Построение технологического процесса зависит от характера решаемых задач, круга пользователей, от используемых технических средств, от систем контроля данных и т.д.
Технологический процесс обработки информации с использованием ЭВМ включает в себя следующие операции:
1 Прием и комплектовка первичных документов (проверка полноты и качества их заполнения, комплектовки и т.д.).
2 Подготовка МП и контроль.
3 Ввод данных в ЭВМ.
4 Контроль, результаты которого выдаются на ПУ, терминал (различают визуальный и программный контроль, позволяющий отслеживать информацию на полноту ввода, нарушение структуры исходных данных, ошибки кодирования, при обнаружении ошибки производится исправление вводимых данных, корректировка и их повторный ввод).
5 Запись входной информации в исходные массивы.
6 Сортировка (если в этом есть необходимость).
7 Обработка данных.
8 Контроль и выдача результатной информации.
Перечисляя операции технологического процесса, хотелось бы несколько слов сказать об операции хранения информации. Еще совсем недавно информация хранилась на таких машинных носителях, как перфокарты, перфоленты, магнитные ленты, магнитные диски. С развитием ВТ изменились и носители информации. Уже дискета (гибкий магнитный диск), которая подвергалась постоянно изменениям как внешне, так и объемом записываемой информации, на сегодняшний день уже не может отвечать требованиям пользователей. Это касается не только технической надежности носителей информации, но и объема хранимой информации. Современные экономические информационные системы с мощными процессорами, оснащенными съемными винчестерами, сидиромами с лазерными дисками, обеспечивают более высокую скорость обработки информации и предоставляют пользователю работать с большими объемами данных, обеспечивая удобство в работе и надежность в сохранности информации.
Разработка информационных технологий
Проектирование рациональных технологических процессов обработки данных является довольно слож'нбй задачей. Эта сложность обусловливается тем, что сама система АОЭИ относится к классу сложных систем и при ее разработке должны учитываться многие параметры, среди которых не только чисто технические, но и параметры, учитывающие различные человеческие факторы, вопросы повышения сроков эксплуатации и использования инструментальных средств, уменьшения сроков разработки, ряд экономических соображений и т.д.
Этапы разработки технологических процессов
Технология проектирования автоматизированной обработки экономической информации при решении любой экономической задачи подразделяется на 4 этапа:
– начальный;
– подготовительный;
– основной;
– заключительный.
Состав и структура операций каждого из этапов технологического процесса могут быть различными в зависимости от используемых средств ВТ, средств оргсвязи и требований к технологии преобразования информации. По своему назначению технологические операции бывают вспомогательными, основными и контрольными. Вторые составляют основу и относятся к операциям внутримашинной технологии обработки данных. Это операции упорядочения, корректировки, накопления и собственно обработки.
Упорядочение – произвольно расположенные данные размещаются в определенной последовательности значений ключевых слов.
Корректировка – процесс внесения изменений в уже сформированные файлы данных, позволяющий поддержать их в актуальном для обработки состоянии.
Накопление – процесс периодического добавления данных в существующие файлы с целью формирования исходных данных за определенный интервал времени.
Обработка – выполнение всех арифметических и логических операций по преобразованию исходной информации в результатную.
Существуют различные формы внутримашинной технологии обработки информации. Наиболее распространенными формами являются обработка данных в пакетном и диалоговом режимах.
Иногда автоматизированное решение задач должно согласовываться по времени с ходом управляемых процессов. Соответственно организация обработки информации для этих нужд получила название технологии обработки данных в режиме реального времени. Важной характеристикой, определяющей область применения режима реального времени является скорость реакции системы управления на изменение состояний объекта управления.
В настоящее время прослеживается тенденция к максимальному приближению информационных и программных ресурсов к пользователю. ПЭВМ, работающие в сети, имеют существенное преимущество перед АРМ, работающими в режиме разделения времени. А, главное, средства интеллектуального интерфейса обеспечивают пользователя простыми и надежными способами решения своих профессиональных задач.
Возвращаясь к вопросу об этапах разработки технологических процессов, необходимо сказать, что на заключительном этапе производится контроль и выпуск результатных документов.
Известно, что все этапы разработки технологических процессов (предпроектная стадия, техническое проектирование, стадия рабочего проектирования, ввода в действие, функционирование, сопровождение, модернизация) документируются.
Документирование – оформление описания выбранных вариантов построения информационной технология с комментариями, обеспечивающими их использование в процессе эксплуатации системы.
Параметры технологических процессов
Рациональное построение и оптимизация информационных технологий возможны только на основе использования параметрической модели процесса.
Параметры – измеримые величины, характеризующие структуру процесса и его развитие. Параметры информационных технологий отражают взаимосвязанное множество характеристик процессов. Параметры элементов системы проектирования информационной технологии взаимозависимы.
Рассматривая основные характеристики технологических процессов обработки данных, используются обобщенные показатели с дальнейшей их детализацией на других уровнях анализа системы обработки данных.
К таким параметрам относятся:
– экономический эффект от автоматизации обработки данных (ОД);
– капитальные затраты на средства вычислительной и организационной техники;
– стоимость проектирования тех. процессов ОД;
– ресурсы на проектирование и эксплуатацию системы;
– срок проектирования технологии ОД;
– эксплуатационные расходы;
– параметры функциональных задач;
– параметры вычислительной и организационной техники;
– стоимость организации и эксплуатации БД или файлов данных;
– параметры структур хранения и стоимость хранения данных;
– время доступа к данным;
– время решения функциональных задач пользователей;
– эффективность методов контроля.
Анализируя выше сказанное, можно выделить три группы параметров:
– исходные – параметры задач, параметры ВТ, ресурсы, параметры структур хранения;
– промежуточные и результатные – экономический эффект от автоматизированной обработки данных, эксплуатационные расходы, срок и стоимость проектирования и т.д.
На технологию обработки данных влияют факторы, не зависящие или слабо зависящие от проектировщика – нерегулируемые, и факторы, на которые он может оказать существенное влияние – регулируемые (управляемые).
К нерегулируемым параметрам технологии можно отнести: объем входных и выходных данных, сложность алгоритма и объем вычислений, периодичность и регламентность решения задач, степень использования результатов одной задачи в других задачах, параметры жестко заданных технических средств и общесистемного программного обеспечения и т.д.
К регулируемым параметрам технологии можно отнести выбор характеристик технических средств и программного обеспечения, параметры информационного обеспечения, методы контроля и защиты данных, размещение технических средств, последовательность операций технологического процесса.
В процессе выбора регулируемых (управляемых) параметров при проектировании технологии обработки данных хорошим подспорьем является использование методов математического моделирования. Иногда для упрощения задачи приходится рассматривать отдельные фрагменты технологического процесса, осуществляя поиск рациональных решений. Таким методом надо пользоваться очень осторожно, так как частичная оптимизация может оказать отрицательное влияние на общую оптимизацию.
Практика обработки данных и ряд теоретических исследований показали целесообразность выбора некоторых значений регулируемых параметров технологии в случае принятия нерегулируемыми параметрами определенного значения. Например, при большом объеме входных данных с целью уменьшения затрат времени на их обработку рекомендуется подготовку данных осуществлять на многопультовых системах подготовки данных на магнитном носителе. При этом следует максимально использовать программные методы контроля с точной локализацией ошибок, обнаруженных в процессах ввода и обработки информации. Это позволяет обеспечить процесс нахождения и исправления ошибок.
Большой объем входных данных диктует в качестве целесообразной технологии выбирать такую технологию, которая предусматривает уменьшение количества вычислений в программах вывода, обеспечение возможности возобновления печати в случае сбоя, обрыва и замятия бумаги, обеспечение надежности устройств вывода, в том числе путем резервирования, проработки методов размножения табуляграмм и т.п.
Сложность алгоритма и большой объем вычислений определяют необходимость создания в программах контрольных точек, которые позволят возобновить обработку данных в случае каких-либо сбоев ЭВМ не с самого начала, а с ближайшей контрольной точки.
Критерии качества технологических процессов
Проектирование рациональной технологии следует рассматривать как задачу принятия решений. Каждая задача такого типа характеризуется наличием ряда целей и наличием различных путей достижения этих целей с различной эффективностью их реализации. Эффективность реализации различных вариантов технологического процесса должна быть количественно определена, т.е. выражена с помощью определенной величины: критерия эффективности.
Пользуясь этим показателем, можно определить сравнительные достоинства и недостатки различных вариантов организации технологических процессов. Кроме того, углубляясь в сравнительные оценки, необходимо говорить и об эффективности использования тех или иных готовых программных продуктов однотипных или близких по своим функциональным возможностям, будь то табличные процессоры, текстовые редакторы, базы данных или интегрированные ППП.
Помимо глобального критерия – эффективности, используются и локальные критерии, одним из которых является время решения задачи на ЭВМ. В настоящее время поставлен и решен целый ряд задач по рациональной и оптимальной технологии обработки данных. Эти задачи связаны с выбором организации информационных массивов, выбором способов обработки данных, в частности выбором методов сортировки, способов разделения задач на модули, поиска информации.
Большое внимание уделяется методам обеспечения достоверности и надежности информации и т.д.
В основе качественной оценки информационной технологии лежит многообразие методов и способов их конструирования. Важнейшим показателем является степень соответствия информационной технологии научно-техническому уровню ее развития.
Критерии оптимизации информационных технологий
Экономические задачи (плановые, учетные, управленческие и т.д.) нуждаются в информации о развитии и потребностях экономики, о состоянии объектов управления. Эта информация позволяет проанализировать деятельность объекта за прошедший период, сделать обобщающие выводы и дать прогноз будущей деятельности объекта управления.
Для экономических задач, реализуемых в диалоговом (интерактивном) режиме характерны следующие факторы:
1 Многовариантность решений (каждая задача имеет различные варианты, отличающиеся друг от друга экономическими показателями, расходуемыми ресурсами, достигаемым экономическим эффектом).
2 Наличие критерия оптимальности.
Многовариантность решений задачи диктуется существованием различных путей для достижения цели, поставленной в задаче. При этом немаловажную роль играет вмешательство человека в ход решения задачи.
Интерактивный режим решения задачи чаще всего применяется в оперативном управлении экономическим объектом. Данные здесь чаще подвержены изменениям, модернизации и требуются ответы в различных разрезах и на многочисленные вопросы. Экономическая задача, как правило, многокритериальная, поэтому для выбора критерия необходимо участие человека.
Многовариантность и многокритериальность экономических задач предполагает их реализацию как человеко-машинные процедуры.
Одним из параметров экономических задач, решаемых в интерактивном режиме, является сложность алгоритма (объем вычислений и сложность процедур обработки данных, требующих больших контрольных моментов в технологическом процессе АОЭИ).
Большое значение имеют также периодичность решения задачи и частота использования входных и результатных данных. Рост периодичности требует минимизации времени и эксплуатационных расходов на решение
задачи, повышает степень оперативности результатов расчета и количества контрольных операций. Увеличение частоты использования показателей приводит к повышению требований к их достоверности и росту автономности внесения изменений в хранимые данные. Для организации процесса автоматизированного решения задач характерно широкое применение методов логико-синтаксического и арифметического контроля исходных, промежуточных и результатных данных.
Средства проектирования технологических процессов
При проектировании технологии обработки данных в диалоговом режиме центральным моментом является организация диалога пользователя и ЭВМ, в ходе которого пользователь информируется о состоянии решения задачи и имеет возможность активно воздействовать на ход вычислительного процесса. Существует несколько подходов к организации общения пользователя с БД.
Наиболее распространенный – создание специального формализованного языка, что является недостатком, т.к. требуется специальная подготовка пользователя, изучение языка, частое обращение к инструкциям, которые периодически меняются с изменениями и совершенствованием системы. В связи с этим в настоящее время наибольшее распространение получили методы общения с БД, не требующие специальных знаний и навыков от пользователя. К ним относятся:
1 Диалог "да – нет" (не нашел широкого распространения из-за пассивной роли пользователя).
2 Программированный вопросник.
3 "Свободный диалог" (пользователь формирует запрос в произвольной форме на естественном языке. Система, оперирующая с БД, извлекает из этого запроса понятные ей элементы и строит на их основе новый запрос, который предъявляет пользователю. При утвердительном ответе со стороны пользователя, он получает требуемые данные. В противном случае система организует уточняющий диалог). Этот метод эффективен и позволяет снять психологический барьер.
Недостатки всех трех методов:
1 Неэффективное использование машинного времени и дорогостоящего канала связи (если он задействован), что снижает рентабельность всей управляющей системы;
2 Отсутствие гарантии быстрого ответа на вопрос, требующий принятия оперативного решения в критических ситуациях.
Технология внутримашинной ОЭИ задается последовательностью реализуемых процедур – схем взаимосвязи программных модулей и информационных массивов. Такая схема представляет собой декомпозицию общего процесса решения задачи на отдельные процедуры преобразования массивов, именуемыми модулями (это – ввод, контроль, перезапись информации с одного МН на другой, сортировка, уплотнение данных, редактирование, накопление, вывод на печать и т.п.). Все это требует уменьшения числа просмотров массивов и времени решения задачи, сокращения числа и объема трудоемких процедур, использования эффективных методов поиска информации.
При декомпозиции процесса решения задачи на ЭВМ на отдельные этапы необходимо так же учитывать наличие готовых программ для реализации соответствующего модуля и наличие готовых программных вопросников. При проектировании оптимальной внутримашинной технологии ОД в интерактивном режиме необходимо установить критерии оптимизации и ограничения. Критерий оптимизации технологии ОД должен быть единственным, если мы хотим применить для решения этой задачи экономические методы. Важным условием является критерий, остальные (показатели, условия) выступают как ограничения.
Одним из критериев оптимизации технологии ОЭИ в интерактивном режиме является время реализации задачи на ЭВМ, зависящее от характера
– работы с массивами. Поэтому разработка оптимальной технологии ОЭИ на ЭВМ должна обеспечить выполнение следующих требований:
– сокращение числа массивов на МН, что способствует уменьшению времени счета;
– увеличение кол-ва параллельно обрабатываемых в одном модуле массивов;
– сортировки и эффективные методы поиска в оперативной памяти;
– сокращение времени ответа пользователя на запросы ЭВМ;
– сокращение времени ввода данных пользователем с клавиатуры.
При разработке оптимальной технологии ОЭИ важными критерием является время ожидания ответа пользователем или ЭВМ. Оптимальным считается время ожидания равное 2 сек. Если оно превышает 2 сек, то это ведет к увеличению времени решения задачи, к неэффективному использованию ТС и каналов связи. Если время ожидания меньше 2 сек, то снижается работоспособность человека.
Другим критерием оптимизации технологии ОД является использование различных СУБД (тип и параметры СУБД влияют на эффективность эксплуатации системы). Следующим критерием является выбор необходимого и достаточного количества запросов для реализации задачи и получения необходимой информации.
Технология диалогового режима на практике способствует наилучшему сочетанию возможностей пользователя и ЭВМ в процессе решения экономических задач. Так, например, диалоговый режим общения с БД обеспечивает:
– возможность перебора различных комбинаций поисковых признаков в запросе;
– улучшение характеристик выходных данных за счет оперативной корректировки запроса с терминала;
– возможность расширения, сужения или изменения направления поиска сразу после получения результатов;
– многоплановость точек доступа;
– быстрый доступ к редко используемой информации;
– оперативный анализ выходной информации и т.д.
В процессе диалога пользователь реализует следующие основные функции:
– функцию ввода (оперативность исправления текста, визуальный контроль и т.д.);
– функцию просмотра (редактирование текста с включением, исключением, заменой, сдвигом, перестановкой, разъединением, слиянием данных);
– функцию обработки (смысловая ОД, новое размещение страниц, составление оглавления, организация ввода данных из других программ);
– функцию воспроизведения текста, которая управляет выводом текста и фиксирует параметры печати.
Говоря о диалоговом режиме, о взаимоотношении пользователя и ЭВМ необходимо затронуть вопрос о степени защищенности данных системы.
Проблема защиты информации является одной из важнейших при проектировании оптимальной технологии ОИ. Эта проблема охватывает как физическую защиту данных и системных программ, так и защиту от несанкционированного доступа к данным.
Проблема обеспечения санкционированности использования данных охватывает вопросы защиты данных от нежелаемой их модификации или уничтожения, а также и от несанкционированного чтения.
Можно выделить три обобщенных механизма управления доступа к данным:
1 Идентификация пользователя (защита при помощи паролей). Пароль периодически меняется, чтобы предотвратить несанкционированное его использование. Этот метод является самым простым и дешевым, но не обеспечивает надежной защиты.
2 Метод автоматического обратного вызова (отпадает необходимость в запоминании паролей. Пользователь сообщает ЭВМ свой идентификационный код, который сверяется с кодами, находящимися в памяти ЭВМ и только затем получает доступ к информации; недостаток – низкая скорость обмена).
3 Метод кодирования данных – наиболее эффективный метод защиты. Источник информации кодирует ее при помощи некоторого алгоритма и ключа кодирования. Получаемые закодированные выходные данные не доступны никому, кроме владельца ключа.
Графическое представление диалога
Режим диалога задается в виде схемы и таблиц диалога. Схема диалога разрабатывается на весь комплекс решаемых задач, вводится в систему и предопределяется организация пользователя с ЭВМ.
Схема диалога представляет собой графическую интерпретацию конструкции диалога, задающей требуемую последовательность обменов данными между пользователем и системой. Основным графическим представлением схемы диалога является диаграмма состояний. Каждая вершина графа соответствует определенному состоянию диалога, а дуга определяет изменение этого состояния. В каждом состоянии диалога система ожидает ввода сообщения от пользователя и в зависимости от введенной информации переходит в другое состояние. При выходе осуществляется соответствующая обработка данных из информационной базы и выдается определенная информация на экран или печать.
Различают линейные (при вводе и просмотре разнотипной информации), древовидные (при выборочной коррекции и управлению по меню) и сетевые (соответствуют директивному управлению и непосредственному редактированию данных) схемы диалога.
Пример ответа на второй теоретический вопрос
Теоретический вопрос: "Классификация и кодирование экономической информации"
Классификация экономической информации
Важным понятием при работе с информацией является классификация объектов.
Классификация – система распределения объектов (предметов, явлений, процессов, понятий) по классам в соответствии с определенным признаком.
Под объектом понимается любой предмет, процесс, явление материального или нематериального свойства. Система классификации позволяет сгруппировать объекты и выделить определенные классы, которые характеризуются рядом общих свойств. Классификация объектов – процедура группировки на качественном уровне, направленная на выделение однородных свойств. Применительно к информации как к объекту классификации выделенные классы называют информационными объектами.
Пример 1. Всю информацию об университете можно классифицировать по многочисленным информационным объектам, которые будут характеризоваться общими свойствами:
– информация о студентах – в виде информационного объекта "Студент";
– информация о преподавателях – в виде информационного объекта "Преподаватель";
– информация о факультетах – в виде информационного объекта "Факультет" и т.п.
Свойства информационного объекта определяются информационными параметрами, называемыми реквизитами. Реквизиты представляются либо числовыми данными, например вес, стоимость, год, либо признаками, например цвет, марка машины, фамилия.
Реквизит – логически неделимый информационный элемент, описывающий определенное свойство объекта, процесса, явления и т.п.
Пример 2. Информация о каждом студенте в отделе кадров университета систематизирована и представлена посредством одинаковых реквизитов:
– фамилия, имя, отчество;
– пол;
– год рождения;
– место рождения;
– адрес проживания;
– факультет, где проходит обучение студент, и т.д.
Все перечисленные реквизиты характеризуют свойства информационного объекта "Студент".
Кроме выявления общих свойств информационного объекта классификация нужна для разработки правил (алгоритмов) и процедур обработки информации, представленной совокупностью реквизитов.
Пример 3. Алгоритм обработки информационных объектов библиотечного фонда позволяет получить информацию обо всех книгах по определенной тематике, об авторах, абонентах и т.д.
Алгоритм обработки информационных объектов фирмы позволяет получить информацию об объемах продаж, о прибыли, заказчиках, видах производимой продукции и т.д.
Алгоритмы обработки в том и другом случае преследуют разные цели, обрабатывают разную информацию, реализуются разными способами.
При любой классификации желательно, чтобы соблюдались следующие требования:
– полнота охвата объектов рассматриваемой области;
– однозначность реквизитов;
– возможность включения новых объектов.
В любой стране разработаны и применяются государственные, отраслевые, региональные классификаторы. Например, классифицированы: отрасли промышленности, оборудование, профессии, единицы измерения, статьи затрат и т.д.
Классификатор – систематизированный свод наименований и кодов классификационных группировок.
При классификации широко используются понятия классификационный признак и значение классификационного признака, которые позволяют установить сходство или различие объектов. Возможен подход к классификации с объединением этих двух понятий в одно, названное как признак классификации. Признак классификации имеет также синоним основание деления.
Пример 4. В качестве признака классификации выбирается возраст, который состоит из трех значений: до 20 лет, от 20 до 30 лет, свыше 30 лет.
Существует три метода классификации объектов: иерархический, фасетный, дескрипторный. Эти методы различаются разной стратегией применения классификационных признаков. Рассмотрим основные идеи этих методов для создания систем классификации.
Иерархическая система классификации
Иерархическая система классификации (рис. 2.3) строится следующим образом:
– исходное множество элементов составляет 0-й уровень и делится в зависимости от выбранного классификационного признака на классы (группировки), которые образуют 1-й уровень;
– каждый класс 1-го уровня в соответствии со своим, характерным для него классификационным признаком делится на подклассы, которые образуют 2-й уровень;
– каждый класс 2-го уровня аналогично делится на группы, которые образуют 3-й уровень и т.д.

Рисунок 1 – Иерархическая система классификации
Учитывая процедуру построения структуры классификации, необходимо определить ее цель, то есть какими свойствами должны обладать объединяемые в классы объекты. Эти свойства принимают в дальнейшем за признаки классификации.
В иерархической системе классификации следует особое внимание уделить выбору классификации признаков. Каждый объект на любом уровне должен быть отнесен к одному классу, который характеризуется конкретным значением выбранного классификационного признака. Для последующей группировки в каждом новом классе необходимо задать свои классификационные признаки и их значения. Таким образом, выбор классификационных признаков будет зависеть от семантического содержания того класса, для которого необходима группировка на последующем уровне иерархии.
Количество уровней классификации, соответствующее числу признаков, выбранных в качестве основания деления, характеризует глубину классификации.
Достоинства иерархической системы классификации:
– простота построения;
– использование независимых классификационных признаков в различных ветвях иерархической структуры. Недостатки иерархической системы классификации:
жесткая структура, которая приводит к сложности внесения изменений, так как приходится перераспределять все классификационные группировки;
невозможность группировать объекты по заранее не предусмотренным сочетаниям признаков.
Пример 5. Создать иерархическую систему классификации для информационного объекта "Факультет", которая позволит классифицировать информацию обо всех студентах по следующим классификационным признакам: факультет, на котором он учится, возрастной состав студентов, пол студента, для женщин – наличие детей. Система классификации представлена на рис.2.4 и будет иметь следующие уровни:
0-й уровень. Информационный объект "Факультет";
1-й уровень. Выбирается классификационный признак – название факультета, что позволяет выделить несколько классов с разными названиями факультетов, в которых хранится информация обо всех студентах;
2-й уровень. Выбирается классификационный признак – возраст, который имеет три градации: до 20 лет, от 20 до 30 лет, свыше 30 лет. По каждому факультету выделяются три возрастных подкласса студентов;
3-й уровень. Выбирается классификационный признак – пол. Каждый подкласс 2-го уровня разбивается на две группы. Таким образом, информация о студентах каждого факультета в каждом возрастном подклассе разделяется на две группы – мужчин и женщин;
4-й уровень. Выбирается классификационный признак – наличие детей у женщин: есть, нет.
Созданная иерархическая система классификации имеет глубину классификации, равную четырем.
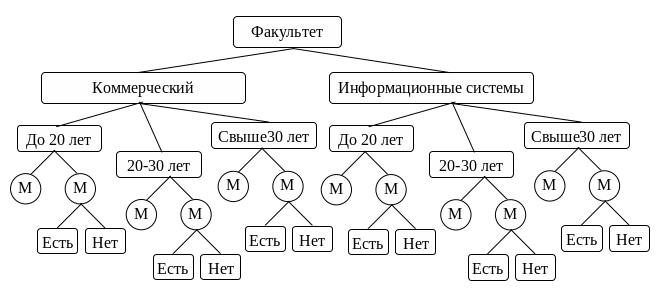
Рисунок 2 – Пример иерархической системы классификации для информационного объекта "Факультет"
Фасетная система классификации
Фасетная система классификации в отличие от иерархической позволяет выбирать признаки классификации независимо как друг от друга, так и от семантического содержания классифицируемого объекта. Признаки классификации называются фасетами(Фасет – рамка). Каждый фасет (Ф) содержит совокупность однородных значений данного классификационного признака. Причем значения в фасете могут располагаться в произвольном порядке, хотя предпочтительнее их упорядочение.
Пример 6.
– Фасет цвет содержит значения: красный, белый, зеленый, черный, желтый.
– Фасет специальность содержит названия специальностей.
– Фасет образование содержит значения: среднее, среднее специальное, высшее.
Схема построения фасетной системы классификации в виде таблицы отображена на рисунке 3. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2, ..., Фi, ..., Фn. Например, цвет, размер одежды, вес и т.д. Произведена нумерация строк таблицы. В каждой клетке таблицы хранится конкретное значение фасета. Например, фасет цвет, обозначенный Ф2, содержит значения: красный, белый, зеленый, черный, желтый.
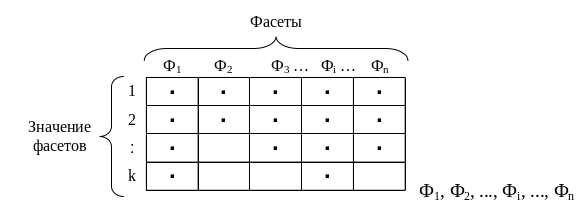
Рисунок 3 – Фасетная система классификации
Процедура классификации состоит в присвоении каждому объекту соответствующих значений из фасетов. При этом могут быть использованы не все фасеты. Для каждого объекта задается конкретная группировка фасетов структурной формулой, в которой отражается их порядок следования: Ks = (Ф1, Ф2, ..., Фi, ..., Фn), где Фi – i-й фасет; Кs – класс; n – количество фасетов.
При построении фасетной системы классификации необходимо, чтобы значения, используемые в различных фасетах, не повторялись. Фасетную систему легко можно модифицировать, внося изменения в конкретные значения любого фасета.
Достоинства фасетной системы классификации:
– возможность создания большой емкости классификации, т.е. использования большого числа признаков классификации и их значений для создания группировок;
– возможность простой модификации всей системы классификации без изменения структуры существующих группировок.
Недостатком фасетной системы классификации является сложность ее построения, так как необходимо учитывать все многообразие классификационных признаков.
Пример 7. Обратимся к содержанию примера 5, где показано построение иерархической системы классификации. Для сопоставления разработаем фасетную систему классификации.
Сгруппируем и представим в виде таблицы (рисунок 4) все классификационные признаки по фасетам:
– фасет название факультета с пятью названиями факультетов;
– фасет возраст с тремя возрастными группами;
– фасет пол с двумя градациями;
– фасет дети с двумя градациями.
Структурную формулу любого класса можно представить в виде: Кs = (Факультет, Возраст, Пол, Дети).
Присваивая конкретные значения каждому фасету, получим следующие классы: К1 = (Радиотехнический факультет, возраст до 20 лет, мужчина, есть дети); К2 = (Коммерческий факультет, возраст от 20 до 30 лет, мужчина, детей нет); К3 = (Математический факультет, возраст до 20 лет, женщина, детей нет) и т.д.
Название факультета |
Возраст |
Пол |
Дети |
Радиотехнический |
До 20 лет |
М |
Есть |
Машиностроительный |
20 – 30 лет |
Ж |
Нет |
Коммерческий |
Свыше 30 лет |
|
|
Информационные сисетмы |
|
|
|
Математический |
|
|
|
Рисунок 4 – Пример фасетной системы классификации для информационного объекта "Факультет"
Дескрипторная система классификации
Для организации поиска информации, для ведения тезаурусов (словарей) эффективно используется дескрипторная (описательная) система классификации, язык которой приближается к естественному языку описания информационных объектов. Особенно широко она используется в библиотечной системе поиска. Суть дескрипторного метода классификации заключается в следующем:
– отбирается совокупность ключевых слов или словосочетаний, описывающих определенную предметную область или совокупность однородных объектов. Причем среди ключевых слов могут находиться синонимы;
– выбранные ключевые слова и словосочетания подвергаются нормализации, т.е. из совокупности синонимов выбирается один или несколько наиболее употребляемых;
– создается словарь дескрипторов, т.е. словарь ключевых слов и словосочетаний, отобранных в результате процедуры нормализации.
Пример 8. В качестве объекта классификации рассмотрим успеваемость студентов. Ключевыми словами могут быть выбраны: оценка, экзамен, зачет, преподаватель, студент, семестр, название предмета. Здесь нет синонимов, и поэтому указанные ключевые слова можно использовать как словарь дескрипторов. В качестве предметной области выбирается учебная деятельность в высшем учебном заведении. Ключевыми словами могут быть выбраны: студент, обучаемый, учащийся, преподаватель, учитель, педагог, лектор, ассистент, доцент, профессор, коллега, факультет, подразделение университета, аудитория, комната, лекция, практическое занятие, занятие и т.д. Среди указанных ключевых слов встречаются синонимы, например: студент, обучаемый, учащийся, преподаватель, учитель, педагог, факультет, подразделение университета и т.д. После нормализации словарь дескрипторов будет состоять из следующих слов: студент, преподаватель, лектор, ассистент, доцент, профессор, факультет, аудитория, лекция, практическое занятие и т.д.
Между дескрипторами устанавливаются связи, которые позволяют расширить область поиска информации. Связи могут быть трех видов:
– синонимические, указывающие некоторую совокупность ключевых слов как синонимы;
– родовидовые, отражающие включение некоторого класса объектов в более емкие;
– ассоциативные, соединяющие дескрипторы, обладающие общими свойствами.
Пример 9. Синонимическая связь: студент- учащийся – обучаемый. Родовидовая связь: университет- факультет – кафедра. Ассоциативная связь: студент- экзамен- профессор – аудитория.
2 Кодирование экономической информации
Система кодирования экономической информации применяется для замены названия объекта на условное обозначение (код) в целях обеспечения удобной и более эффективной обработки информации.
Система кодирования – совокупность правил кодового обозначения объектов. Код строится на базе алфавита, состоящего из букв, цифр и других символов.
Код характеризуется: длиной – число позиций в коде; структурой -порядок расположения в коде символов, используемых для обозначения классификационного признака.
Процедура присвоения объекту кодового обозначения называется кодированием. Можно выделить две группы методов, используемых в системе кодирования (рисунок 5), которые образуют:
– классификационную систему кодирования, ориентированную на проведение предварительной классификации объектов либо на основе иерархической системы, либо на основе фасетной системы;
– регистрационную систему кодирования, не требующую предварительной классификации объектов. Рассмотрим представленную на рисунок 4 систему кодирования.

Рисунок 5 – Система кодирования, использующая разные методы
Классификационное кодирование
Классификационное кодирование применяется после проведения классификации объектов. Различают последовательное и параллельное кодирование.
Последовательное кодирование используется для иерархической классификационной структуры. Суть метода заключается в следующем: сначала записывается код старшей группировки 1-го уровня, затем код группировки 2-го уровня, затем код группировки 3-го уровня и т.д. В результате получается кодовая комбинация, каждый разряд которой содержит информацию о специфике выделенной группы на каждом уровне иерархической структуры. Последовательная система кодирования обладает теми же достоинствами и недостатками, что и иерархическая система классификации.
Пример 10. Проведем кодирование информации, классифицированной с помощью иерархической схемы (см. рисунок 2). Количество кодовых группировок будет определяться глубиной классификации и равно 4. Прежде чем начать кодирование, необходимо определиться с алфавитом, т.е. какие будут использоваться символы. Для большей наглядности выберем десятичную систему счисления -10 арабских цифр. Анализ схемы на рисунке 2 показывает, что длина кода определяется 4 десятичными разрядами, а кодирование группировки на каждом уровне можно делать путем последовательной нумерации слева направо. В общем виде код можно записать как ХХХХ, где X – значение десятичного разряда. Рассмотрим структуру кода, начиная со старшего разряда:
1-й (старший) разряд выделен для классификационного признака "название факультета" и имеет следующие значения: 1 – коммерческий; 2 – информационные системы; 3 – для следующего названия факультета и т.д.;
2-й разряд выделен для классификационного признака "возраст" и имеет следующие значения: 1 – до 20 лет; 2 – от 20 до 30 лет; 3 – свыше 30 лет;
3-й разряд выделен для классификационного признака "пол" и имеет следующие значения: 1 – мужчины; 2 – женщины;
4-й разряд выделен для классификационного признака "наличие детей у женщин" и имеет следующие значения; 1 – есть дети; 2 – нет детей, 0 – для мужчин, так как подобной информации не требуется.
Принятая система кодирования позволяет легко расшифровать любой код группировки, например: 1310 – студенты коммерческого факультета, свыше 30 лет мужчины; 2221 – студенты факультета информационных систем, от 20 до 30 лет, женщины имеющие детей.
Параллельное кодирование используется для фасетной системы классификации. Суть метода заключается в следующем: все фасеты кодируются независимо друг от друга; для значений каждого фасета выделяется определенное количество разрядов кода. Параллельная система кодирования обладает теми же достоинствами и недостатками, что и фасетная система классификации.
Пример 11. Проведем кодирование информации, классифицированной с помощью фасетной схемы (рисунок 4). Количество кодовых группировок определяется количеством фасетов и равно 4. Выберем десятичную систему счисления в качестве алфавита кодировки, что позволит для значений фасетов выделить один разряд и иметь длину кода, равную 4. В отличие от последовательного кодирования для иерархической системы классификации в данном методе не имеет значения порядок кодировки фасетов. В общем виде код можно записать как ХХХХ, где X – значение десятичного разряда. Рассмотрим структуру кода, начиная со старшего разряда:
1-й (старший) разряд выделен для фасета "кол" и имеет следующие значения: 1 – мужчины; 2 – женщины;
2-й разряд выделен для фасета "наличие детей у женщин" и имеет следующие значения: 1 – есть дети; 2 – нет детей; 0 – для мужчин, так как подобной информации не требуется;
3-й разряд выделен для фасета "возраст" и имеет следующие значения: 1 – до 20 лет; 2 – от 20 до 30 лет; 3 – свыше 30 лет;
4-й разряд выделен для фасета "название факультета" и имеет следующие значения 1 – радиотехнический, 2 – машиностроительный, 3 -коммерческий; 4 – информационные системы; 5 – математический и т.д. Принятая система кодирования позволяет легко расшифровать любой код группировки, например:
2135 – женщины в возрасте свыше 30 лет, имеющие детей и являющиеся студентами математического факультета;
1021 – мужчины возраста от 20 до 30 лет, являющиеся студентами радиотехнического факультета.
Регистрационное кодирование используется для однозначной идентификации объектов и не требует предварительной классификации объектов. Различают порядковую и серийно-порядковую систему. Порядковая система кодирования предполагает последовательную нумерацию объектов числами натурального ряда. Этот порядок может быть случайным или определяться после предварительного упорядочения объектов, например по алфавиту. Этот метод применяется в том случае, когда количество объектов невелико, например кодирование названий факультетов университета, кодирование студентов в учебной группе.
Серийно-порядковая система кодирования предусматривает предварительное выделение групп объектов, которые составляют серию, а затем в каждой серии производится порядковая нумерация объектов. Каждая серия также будет иметь порядковую нумерацию. По своей сути серийно-порядковая система является смешанной: классифицирующей и идентифицирующей. Применяется тогда, когда количество групп невелико.
Пример 12. Все студенты одного факультета разбиваются на учебные группы (в данной терминологии – серии), для которых используется порядковая нумерация. Внутри каждой группы производится упорядочение фамилий студентов по алфавиту и каждому студенту присваивается номер.
3 Классификация информации по разным признакам
Любая классификация всегда относительна. Один и тот же объект может быть классифицирован по разным признакам или критериям. Часто встречаются ситуации, когда в зависимости от условий внешней среды объект может быть отнесен к разным классификационным группировкам. Эти рассуждения особенно актуальны при классификации видов информации без учета ее предметной ориентации, так как она часто может быть использована в разных условиях, разными потребителями, для разных целей.
На рисунке 6 приведена одна из схем классификации циркулирующей в организации (фирме) информации. В основу классификации положено пять наиболее общих признаков: место возникновения, стадия обработки, способ отображения, стабильность, функция управления.
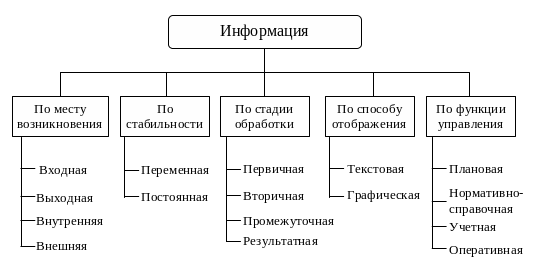
Рисунок 6 – Классификация информации, циркулирующей в организации
Место возникновения. По этому признаку информацию можно разделить на входную, выходную, внутреннюю, внешнюю. Входная информация – это информация, поступающая в фирму или ее подразделения.
Выходная информация – это информация, поступающая из фирмы в другую фирму, организацию (подразделение). Одна и та же информация может являться входной для одной фирмы, а для другой, ее вырабатывающей, выходной. По отношению к объекту управления (фирма или ее подразделение: цех, отдел, лаборатория) информация может быть определена как внутренняя, так и внешняя.
Внутренняя информация возникает внутри объекта, внешняя информация – за пределами объекта.
Пример 13.
– Содержание указа правительства об изменении уровня взимаемых налогов для фирмы является, с одной стороны, внешней информацией, с другой стороны – входной.
– Сведения фирмы в налоговую инспекцию о размере отчислений в госбюджет являются, с одной стороны, выходной информацией, с другой стороны – внешней по отношению к налоговой инспекции.
По стадии обработки информация может быть первичной, вторичной, промежуточной, результатной.
Первичная информация – это информация, которая возникает непосредственно в процессе деятельности объекта и регистрируется на начальной стадии.
Вторичная информация – это информация, которая получается в результате обработки первичной информации и может быть промежуточной и результатной.
Промежуточная информация используется в качестве исходных данных для последующих расчетов.
Результатная информация получается в процессе обработки первичной и промежуточной информации и используется для выработки управленческих решений.
Пример 14. В художественном цехе, где производится роспись чашек, в конце каждой смены регистрируется общее количество произведенной продукции и количество расписанных чашек каждым работником. Это первичная информация. В конце каждого месяца мастер подводит итоги первичной информации. Это будет, с одной стороны вторичная промежуточная информация, а с другой стороны – результатная. Итоговые данные поступают в бухгалтерию, где производится расчет заработной платы каждого работника в зависимости от его выработки. Полученные расчетные данные – результатная информация.
По способу отображения информация подразделяется на текстовую и графическую.
Текстовая информация – это совокупность алфавитных, цифровых и специальных символов, с помощью которых представляется информация на физическом носителе (бумага, изображение на экране дисплея).
Графическая информация – это различного рода графики, диаграммы, схемы, рисунки и т.д.
По стабильности информация может быть переменной (текущей) и постоянной (условно-постоянной).
Переменная информация отражает фактические количественные и качественные характеристики производственно-хозяйственной деятельности фирмы. Она может меняться для каждого случая, как по назначению, так и по количеству.
Пример 15. Количество произведенной продукции за смену, еженедельные затраты на доставку сырья, количество исправных станков и т.п. Постоянная (условно-постоянная) информация – это неизменная и многократно используемая в течение длительного периода времени информация. Постоянная информация может быть справочной, нормативной, плановой: постоянная справочная информация включает описание постоянных свойств объекта в виде устойчивых длительное время признаков.
Пример 16. Табельный номер служащего, профессия работника, номер цеха и т.п.
Постоянная нормативная информация содержит местные, отраслевые и общегосударственные нормативы. Например, размер налога на прибыль, стандарт на качество продуктов определенного вида, размер минимальной оплаты труда, тарифная сетка оплаты государственным служащим.
Постоянная плановая информация содержит многократно используемые в фирме плановые показатели. Например, план выпуска телевизоров, план подготовки специалистов определенной квалификации.
По функциям управления обычно классифицируют экономическую информацию. При этом выделяют следующие группы: плановую, нормативно-справочную, учетную и оперативную (текущую).
Плановая информация – информация о параметрах объекта управления на будущий период. На эту информацию идет ориентация всей деятельности фирмы.
Пример 17. Плановой информацией фирмы могут быть такие показатели, как план выпуска продукции, планируемая прибыль от реализации, ожидаемый спрос на продукцию и т.д.
Нормативно-справочная информация содержит различные нормативные и справочные данные. Ее обновление происходит достаточно редко.
Пример 18. Нормативно-справочной информацией на предприятии являются:
– время, предназначенное для изготовления типовой детали (нормы трудоемкости);
– среднедневная оплата рабочего по разряду;
– оклад служащего;
– адрес поставщика или покупателя и т.д.
Учетная информация – это информация, которая характеризует деятельность фирмы за определенный прошлый период времени. На основании этой информации могут быть проведены следующие действия: скорректирована плановая информация, сделан анализ хозяйственной деятельности фирмы, приняты решения по более эффективному управлению работами и пр. На практике в качестве учетной информации может выступать информация бухгалтерского учета, статистическая информация и информация оперативного учета.
Пример 19. Учетной информацией являются: количество проданной продукции за определенный период времени; среднесуточная загрузка или простой станков и т.п.
Оперативная (текущая) информация – это информация, используемая в оперативном управлении и характеризующая производственные процессы в текущий (данный) период времени. К оперативной информации предъявляются серьезные требования по скорости поступления и обработки, а также по степени ее достоверности. От того, насколько быстро и качественно проводится ее обработка, во многом зависит успех фирмы на рынке.
Пример 20. Оперативной информацией являются:
– количество изготовленных деталей за час, смену, день;
– количество проданной продукции задень или определенный час;
– объем сырья от поставщика на начало рабочего дня и т.д.
Пример выполнения первого практического задания
Практическое задание: "Классификация и кодирование экономической информации"
Товарооборот столовых за месяц составил (тыс. р.): № 1 – 156, № 2 – 192, № 3 – 147, № 4 – 178, № 5 – 219, № 6 – 185. Вычислите удельный вес товарооборота каждой столовой в общем товарообороте. Распределите расходы по инкассации в сумме 23 тыс. р. пропорционально товарообороту.
Для определения структуры и содержания СЕИ и описания заданного информационного массива удобно воспользоваться формой, представленной в таблицах 1, 2.
Таблица 1 – Описание информационного массива
№ |
Полное имя составляющей |
Имя-иденти-фикатор |
Вид составляющей |
Тип составляющей |
Класс значений |
1 |
№ столовой |
P1(I) |
Реквизит-признак |
Числовой |
{1, 2, 3, 4, 5, 6}, коли- чество элементов класса значений – 6 |
2 |
Товарооборот за месяц, тыс. р. |
Q1(I) |
Реквизит-основание |
Числовой |
{159, 192, 147, 178, 219, 185), количество элементов класса значений – 6 |
3 |
Удельный вес товарооборота, % |
Q2(I) |
Реквизит- основание |
Числовой |
Определяется по формуле – неотрицательное число, количество элементов класса значений – 6 |
4 |
Расходы по инкассации, тыс. р. |
Q3(I) |
Реквизит-основание |
Числовой |
Определяется по формуле – неотрицательное число, количество элементов класса значений – 6 |
5 |
Общий товарооборот по столо-вым за месяц, тыс. р. |
Q4 |
Реквизит-основание |
Числовой |
Определяется по формуле – неотрицательное число, количество элементов класса значений –1 |
6 |
Сумма удельных весов товарооборота по столовым, % |
Q5 |
Реквизит-основание |
Числовой |
Определяется по формуле, значение 100, количество элементов класса значений – 1 |
7 |
Общие расходы по инкассации, тыс. р. |
Q6 |
Реквизит-основание |
Числовой
|
23, количество элементов класса значений – 1 |
Таблица 2 – Описание отношении между элементами информационного массива
Составляющие |
Виды отношений |
Математическая модель (информационная модель) |
|
Логические |
Множественные отношения соответствия |
|
Логические |
Множественные отношения соответствия |
|
Логические |
Множественные отношения соответствия |
|
Арифметические |
|
|
Арифметические |
|
|
Арифметические |
|
|
Арифметические |
так как
|
Исходя из анализа структуры и содержания заданного информационного массива, его можно представить в виде таблицы 3.
Таблица 3 – Структура и содержание заданного информационного массива

Структурная модель СЕИ может быть представлена в следующем виде:
S. (1:М). (С11. (С21. (1:6). (P1, Q1, Q2, Q3), Q4, Q5, Q6).
Графическая модель СЕИ представлена на рисунке 7.

Рисунок 7 – Графическая модель СЕИ
Более подробно процесс моделирования СЕИ описан в примере выполнения второго практического задания.
Блок-схема алгоритма обработки информации представлена на рисунке 8.
Для реализации обработки информации был выбран табличный процессор Microsoft Excel. Методика обработки информации посредством табличного процессора Microsoft Excel преведена в таблице 4. Результаты обработки (в режимах отображения формул и значений) приведены в таблице 5, 6.
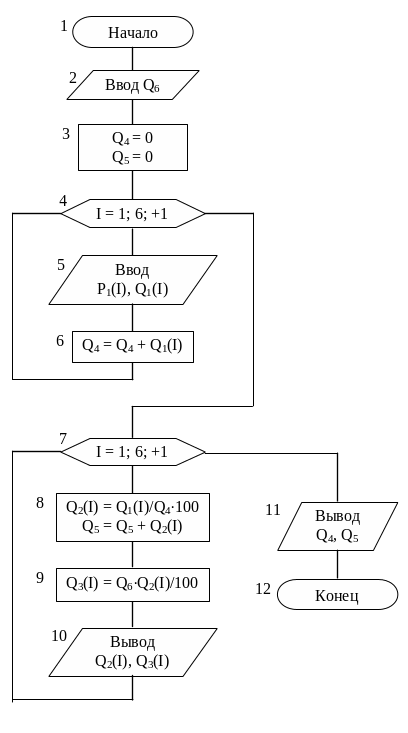
Рисунок 8 – Блок-схема алгоритма обработки информации
Таблица 4 – Методика обработки информации посредством табличного процессора Microsoft Excel
Адрес |
Действия пользователя |
Сообщения на экране |
Примечания |
Форматирование столбцов таблицы |
|||
Столбец А |
Подвести курсор мыши к границе форматируемого столбца в области заголовков столбцов. Удерживая нажатой левую кнопку "мыши", перемещать мышь, изменяя границу столбца до необходимого размера |
Изменение ширины столбца |
Аналогично изменяется ширина других столбцов таблицы. После занесения информации в ячейки таблицы можно провести более точную подгонку ширины столбцов. Для этого необходимо произвести двойной щелчок по правой границе заголовка столбца |
|
Подвести курсор "мыши" к заголовку столбца и нажать левую кнопку мыши |
Выделение ячеек столбца цветом |
Выделение ячеек производится в том случае, когда над ними необходимо произвести однотипные операции |
|
Выбрать в меню Формат команду Ячейки... В появившемся окне формата ячеек выбрать вкладку Выравнивание и установить параметр Переносить по словам |
|
Текст будет переноситься на новую строку при достижении правой границы ячейки. В окне формата ячеек можно также установить формат отображения числовых величин, выравнивания данных в ячейке, шрифт, вид границ ячейки и способы заливки |
|
|
|
Аналогично производится форматирование остальных столбцов таблицы |
Форматирование шапки таблицы |
|||
Строка 1 |
Подвести курсор "мыши" к заголовку строки и нажать левую кнопку "мыши" |
Выделение ячеек строки цветом |
Выделение строки для форматирования |
Форматирование столбцов таблицы |
|||
|
Выбрать в меню Формат команду Ячейки... В появившемся окне формата ячеек выбрать вкладку Выравнивание и установить параметр Переносить по словам, выравнивание по горизонтали и по вертикали установить по центру |
|
Выравнивание текста в шапке таблицы будет производиться по центру. Перенос слов на новую строку при достижении правой границы ячейки установлен |
Продолжение таблицы 4
Занесение исходной информации в таблицу |
|||
|
Используя
клавиши управления курсором на
клавиатуре или |
Табличный курсор перемеща ется в ячейку А1 |
Перемещение табличного курсора с помощью манипулятора "мышь" производится следующим образом: курсор "мыши" подводится к нужной ячейке и производится щелчок правой кнопкой |
Ячейка А1
|
Набрать на клавиатуре: № столовой и нажать клавишу Enter |
В ячейке А1: № столовой |
Аналогично производится занесение исходных данных в остальные ячейки таблицы |
Выполнение расчетов |
|||
Ячейка С1
|
Набрать на клавиатуре: = В3/$В$9*100 и нажать клавишу Enter |
В ячейке С1: 14,48 |
Формула обязательно должна начинаться со знака "=". Знак "$" перед именем столбца или строки означает абсолютную ссылку. Такие ссылки не корректируются при копировании формул
|
Ячейка С1 |
Нажать кнопку Копировать на панели инструментов или выбрать в меню Правка пункт Копировать |
Вокруг ячейки С1 появляется бегущая рамка |
Копирование ячейки С1. Нажатие кнопки на панели инструментов производится следующим образом: курсор "мыши" подводится к необходимой пиктограмме и нажимается левая кнопка |
Блок ячееек С2:С7 |
Подвести курсор "мыши" к ячейке С2 и удерживая нажатой левую кнопку "мыши" переместить курсор по столбцу к ячейке С7 |
Выделение блока ячеек цветом |
Выделение области вставки |
|
Нажать кнопку Вставить на панели инструментов или выбрать в меню Правка пункт Вставить |
Заполнение ячеек С2: С7 расчетными данными |
Вставка скопированной формулы в область вставки |
Продолжение таблицы 4
|
|
|
Аналогично производится расчет остальных значений. Для этого в соответствую-щие ячейки таблицы заносятся необходимые формулы (см. табл. 5) |
Ячейка С1
|
Набрать на клавиатуре: = В3/$В$9*100 и нажать клавишу Enter |
В ячейке С1: 14,48 |
Формула обязательно должна начинаться со знака "=". Знак "$" перед именем столбца или строки означает абсолютную ссылку. Такие ссылки не корректируются при копировании формул |
Создание обрамления таблицы |
|||
Блок ячеек A1:D8 |
Подвести курсор "мыши" к ячейке А1 и удерживая нажатой левую кнопку "мыши" переместить курсор по столбцу к ячейке D8 |
Выделение блока ячеек цветом |
Выделение рабочей области листа |
|
Нажать стрелку рядом с кнопкой Границы на панели инструментов и выбрать тип обрамления Все границы |
Обрамление вокруг ячеек рабочей области листа |
Задать обрамление можно используя команду Ячейки... из меню Формат. В появившемся окне формата ячеек выбрать вкладку Граница и установить тип линии и обрамления |
Сохранение и печать таблицы |
|||
|
Нажать кнопку Сохранить на панели инструментов или выбрать в меню Файл пункт Сохранить |
На экране появляется окно сохранения документа |
Окно сохранения появляется только при первом сохранении документа, так как необходимо задать имя файла, в котором будет сохранена таблица При последующих выполнениях команды Сохранить запись на диск будет производиться автоматически |
|
В окне сохранения документа задать имя файла с клавиатуры, например: Tabl1 |
В поле "имя файла" окна сохранения документа: Tabl1 |
Для сохранения таблицы необходимо нажать кнопку Ok сохранения документа |
|
Нажать кнопку Печать на панели инструментов или выбрать в меню Файл пункт Печать |
На экране появляется окно с сообщением: Идет печать документа |
Перед началом печати надо подготовить принтер к работе |
Таблица 5 – Формализованная методика расчета
|
A |
B |
C |
D |
1 |
№ столовой |
Товарооборот за месяц, тыс. р. |
Удельный вес товарооборота, % |
Расходы по инкассации, тыс. р. |
2 |
1 |
156 |
= В3/$B$9*100 |
= $D$9*C3/100 |
3 |
2 |
192 |
= В4/$B$9*100 |
= $D$9*C4/100 |
4 |
3 |
147 |
= В5/$B$9*100 |
= $D$9*C5/100 |
5 |
4 |
178 |
= В6/$B$9*100 |
= $D$9*C6/100 |
6 |
5 |
219 |
= В7/$B$9*100 |
= $D$9*C7/100 |
7 |
6 |
185 |
= В8/$B$9*100 |
= $D$9*C8/100 |
8 |
Итого |
= СУММ(В3:В8) |
= СУММ(С3:С8) |
23 |
Таблица 6 – Результаты обработки информации
|
A |
B |
C |
D |
1 |
№ столовой |
Товарооборот за месяц, тыс. р. |
Удельный вес товарооборота, % |
Расходы по инкассации, тыс. р. |
2 |
1 |
156 |
14,48 |
3,33 |
3 |
2 |
192 |
17,83 |
4,10 |
4 |
3 |
147 |
13,65 |
3,14 |
5 |
4 |
178 |
16,53 |
3,80 |
6 |
5 |
219 |
20,33 |
4,68 |
7 |
6 |
185 |
17,18 |
3,95 |
8 |
Итого |
1077 |
100,00 |
23 |
Пример выполнения второго практического задания
Практическое задание: "Разработать структуру и модель СЕИ по предложенному документу. Провести анализ структуры"
Рассмотрим информационную совокупность, описывающую информацию, содержащуюся в документе "Приказ-накладная на отпуск готовых изделий" (рисунок 9).
Документ состоит из трех частей: общей, предметной и формальной.
Таким образом, представленную этим документов СЕИ (S) можно представить как ассоциативно связанные составляющие:
СЕИ – С11 – общая часть;
СЕИ – С12 – предметная часть;
C13 – формальная часть.
Структуру S можно представить как
S. (С11, С12, С13),
где S – СЕИ;
". " – знак иерархического отношения (подчинения);
С11 , С12, С13 – составляющие СЕИ;
", " – знак отношения следования в рамках одного уровня.

Рисунок 9 – Документ "Приказ-накладная на отпуск готовых изделий"
Запись читается: "Составная единица информации состоит из составляющих С11 , С12, С13".
С11 – представление структуры общей части документа.
С11. (C21, С22, С23) – представление структуры общей части документа, где C21. (Р1, Р2, Р3, Р4), заметим, что Р1, Р2, Р3, Р4 – являются элементарными единицами информации текстового типа, то есть – реквизиты-признаки.
С22. (Р5, Р6, Р7) – данные о получателе;
С23. (С31. (P8, Р9), Р10, Р11, Р12);
С31 – данные о платежном требовании (№ и дата);
Р10 – вид упаковки (коробки);
Р11 – станция назначения (г. Тамбов – товарная);
P12 – основание для сделки (контракт).
Предметная часть документа – C12:
C12. (P13, P14, Q1, C32. (Q2, Q3), Q4),
где P13, P14 – реквизиты-признаки;
Q1, Q2, Q3, Q4 – реквизиты числового типа.
Единица информации одной формы, представляющая одно значение, называется простой, а представляющая несколько значений (различных экземпляров) – составной -массивом.
В нашем примере:
С11, С21, С22, С23, С13, С31 – простые СЕИ;
С12 – СЕИ – массив.
Определяя структуру СЕИ – массива необходимо:
1 Объявить длину массива – максимально допустимое число его позиций, предназначенных для значений-сообщений.
2 Указать номер позиции (индекса) массива, с которого начинается нумерация (индексация) позиций.
3 Указать номер последней позиции. В нашем примере 1 : 6, где 1 – номер первой позиции; 6 – номер последней позиции; " : " – запись последовательных чисел.
Индекс, с помощью которого осуществляется адресация к той или иной позиции массива, может изменяться по своему значению только в диапазоне этих двух чисел. Эту пару целых чисел обычно называют граничной парой, а сами числа – соответственно нижней и верхней границами массива (по одному его изменению; для матрицы требуется две граничные пары). В качестве нижней и верхней границ допускаются переменные. Для массива с переменной длиной используют специальные указатели (отметки) конца массива.
Например: А. (1 : N), B. (1 : К, 1 : N), С. (1 : 5), D. (1 : 5, 1 : 8, 1 : 4),
E. (M : N), F. (K+1 : K + N)
Для составной массива С12 соответственно:
C12. (1 : 6). (Р13, Р14, Q1, C32. (Q2, Q3), Q4);
С13 – формальная часть документа;
С13. (P15, P16, P17, P18) – представление структуры формальной части документа, где P15, P16, P17, P18 – реквизиты-признаки.
Представленная методика анализа документа "Приказ-накладная на отпуск готовой продукции" – есть методика разработки структуры СЕИ.
Структура информационного массива, заданного моделируемым документом "Приказ-накладная на отпуск готовой продукции" есть методика разработки структуры СЕИ.
Однако, поскольку рассмотренный документ является массовым, следует рассматривать массив таких документов.
Тогда структура СЕИ – массив S из М позиций может быть представлена следующей записью:
S. (1 : М). (С11. (С21. (Р1, Р2, Р3, Р4), С22. (Р5, Р6, Р7),
С23. (С31. (Р8, Р9), P10, P11, P12)),
С12. (1 : 6). (Р13, Р14, Q1, C32. (Q2, Q3), Q4),
C13. (P15, P16, P17, P18)).
Рассмотрим графическую интерпретацию составной структуры массива S, представленную на рисунке 10, где:
1 Идентификатор Р соответствует реквизит текстового типа, то есть реквизит-признак.
2 Идентификатор Q – соответствует реквизит числового типа.
3 Остальные вершины – это составные единицы информации, являющиеся промежуточными и составляющими по отношению к составной S.
Количество уровней иерархии – 6.
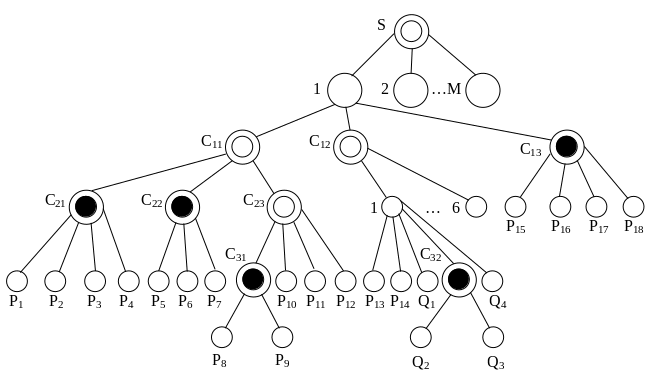
Рисунок 10 – Графическая интерпретация составной структуры массива S
Вспомогательная роль таких промежуточных составляющих единиц, являющихся СЕИ очевидна, поскольку:
1 В процессе информационного моделирования изучаемого объекта (процесса), обеспечивается возможность поэтапного анализа свойств и основных характеристик объекта (процесса), что способствует более полному определению ассоциативных связей объекта изучения, а также определения структуры.
2 Обеспечивается реализация технологии сбора и передачи данных, формирование первичных документов с целью решения задачи оптимизации информационного обеспечения профессиональной деятельности.
3 Определяется приоритетность единиц информации (составляющих) в структуре СЕИ.
4 Формируется технология обработки информации, представленной как СЕИ.
5 Исключается дублирование данных.
Число уровней с целью упрощения структуры, для нашего примера, уменьшится до трех, однако задача оптимизации информационного обеспечения в плане сбора и представления информации не упрощается, поскольку таким образом представленная табличная структура не отвечает всем требованиям решаемой задачи. Такой структуре соответствует матричная интерпретация (таблица 8) и запись структуры будет иметь вид:
S (1 : М). (Р1, Р2, Рз, Р4, Р5, Р6, Р7, Р8, Р9, Р10, P11, P12, Р13,
Р14, Q1, Q2, Q3, Q4, P15, P16, P17, P18)
Если при разработке СЕИ расставлены приоритеты составляющих, то структура такой СЕИ является нормализованной (см. таблицу 7). Если при разработке СЕИ вопрос приоритетности составляющих не учитывается, то структура такой СЕИ является ненормализованной (см. таблицу 8). На рисунке 11 представлен граф ненормализованной структуры СЕИ для рассматриваемой задачи. Таким образом, составную единицу информации можно представить как с нормализованной, так и с ненормализованной структурой.
Исключение дублирования данных при разработке структуры составных единиц экономической информации требует проведения анализа и описания информационного массива заданного документа. Здесь целесообразно воспользоваться методикой выполнения первого практического задания и использовать таблицу 1,2.

Рисунок 11 – Граф ненормализованной структуры СЕИ
Таблица 7 – Нормированная структура СЕИ
С11 |
С12 |
C13 |
||||||||||||||||||||||
С21 |
С22 |
С23 |
P13 |
P14 |
Q1 |
С32 |
Q4 |
P15 |
P16 |
P17 |
P18 |
|||||||||||||
Р1 |
Р2 |
Р3 |
Р4 |
Р5 |
Р6 |
Р7 |
С31 |
Р10 |
Р11 |
P12 |
Q2 |
Q3 |
||||||||||||
Р8 |
Р9 |
|||||||||||||||||||||||
Запись 1 |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|||
|
2 |
|
|
|
|
|
|
|
||||||||||||||||
3 |
|
|
|
|
|
|
||||||||||||||||||
4 |
|
|
|
|
|
|
||||||||||||||||||
5 |
|
|
|
|
|
|
||||||||||||||||||
6 |
|
|
|
|
|
|
||||||||||||||||||
……………………………………………………………………………………………………… |
||||||||||||||||||||||||
Запись М |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|||
|
2 |
|
|
|
|
|
|
|
||||||||||||||||
3 |
|
|
|
|
|
|
||||||||||||||||||
4 |
|
|
|
|
|
|
||||||||||||||||||
5 |
|
|
|
|
|
|
||||||||||||||||||
6 |
|
|
|
|
|
|
||||||||||||||||||
Таблица 8 – Ненормированная структура СЕИ
|
Р1 |
Р2 |
Р3 |
Р4 |
Р5 |
Р6 |
Р7 |
Р8 |
Р9 |
Р10 |
Р11 |
Р12 |
Р13 |
Р14 |
Р15 |
Р16 |
Р17 |
Р18 |
Q1 |
Q2 |
Q3 |
Q4 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
…………………………………………………………………………………………………………
|
||||||||||||||||||||||
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Пример выполнения третьего практического задания
Практическое задание: "Описать информационную модель процессов принятия решений в экономике и технологию обработки профессионально важной информации"
Главной особенностью информационной технологии принятия решения является качественно новый метод организации взаимодействия человека и компьютера. Выработка решения, что является основной целью этой технологии, происходит в результате итерационного процесса, в котором участвуют:
Система поддержки принятия решений в роли вычислительного звена и объекта управления;
Человек как управляющее звено, задающее входные данные и оценивающее полученный результат вычислений на компьютере.

Рисунок 12 – Информационная технология поддержки принятия решений как итерационный процесс.
Окончание итерационного процесса происходит по воле человека. В этом случае можно говорить о способности информационной системы совместно с пользователем создавать новую информацию для принятия решений.
Рассмотрим структуру поддержки принятия решений, а так же функции составляющих ее блоков, которые определяют основные технологические операции. (см. рисунок 13)
В состав системы принятия решений входят три основные главные компонента: база данных, база моделей и программная подсистема, которая состоит из системы управления базой данных, системы управления базой моделей и системы управления интерфейсом между пользователем и компьютером.
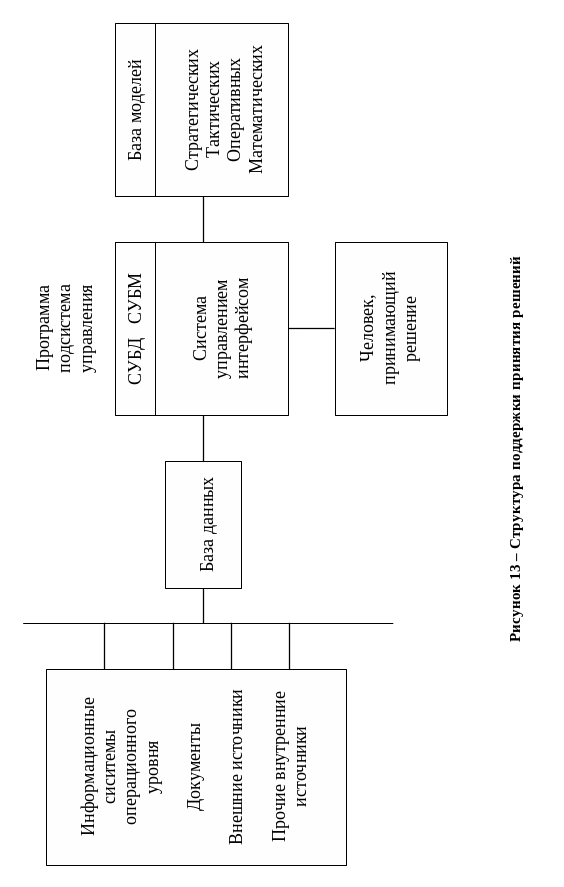
База данных.
1 Часть данных поступает от информационной системы операционного уровня. Чтобы использовать их эффективно, эти данные должны быть предварительно обработанными.
2 Помимо данных об операциях фирмы для функционирования системы поддержки принятия решений требуются и данные о движении персонала, инженерные данные и т. п., которые должны быть своевременно собраны, введены и поддержаны.
3 Важное значение для поддержки принятия решений на верхних уровнях управления имеют данные из внешних источников. В числе необходимых внешних данных следует указать данные о конкурентах, национальной и мировой экономике.
4 Документы, включающие в себя записи, письма, контракты, приказы. Если содержание этих документов будет записано в памяти и записи обработаны по нескольким ключевым характеристикам (поставщикам, потребителям, датам, видам услуг), то система получит новый мощный источник информации.
Целью создания моделей является описание или оптимизация некоторого объекта или процесса. Использование моделей обеспечивает проведение анализа в системах поддержки принятия решений. Модели, базируясь на математической интерпретации проблемы, при помощи определенных алгоритмов способствуют нахождению информации, полезной для принятия правильного решения. Существует множество типов моделей и их классификаций, например, по цели использования, области возможных приложений, способу оценки переменных и т. д.
По цели использования модели подразделяются на оптимизационные, связанные с нахождением точек минимума или максимума некоторых показателей, и описательные, описывающие поведение некоторой системы и не предназначенные для целей управления (оптимизации). По способу оценки модели классифицируются на детерминистские, использующие оценку переменных одним числом при конкретных значениях исходных данных, и стохастические, оценивающие переменные несколькими параметрами, так как исходные данные заданы вероятностными функциями.
По области возможных приложений модели разбиваются на специализированные, предназначенные для использования только одной системой, и универсальные – для использования несколькими системами.
Стратегические модели используются на высших уровнях управления для установления целей организации, объемов ресурсов, необходимых для их достижения, а также политики потребления и использования этих ресурсов. Они могут быть полезны при выборе вариантов размещения предприятий, прогнозирования политики конкурентов и т.п. Для стратегических моделей характерна широта охвата, множество переменных, представление данных в сжатой агрегированной форме. Часто эти данные могут базироваться на внешних источниках и могут иметь субъективный характер. Горизонт планирования в стратегических моделях измеряется в годах. Эти модели обычно детерминистские, описательные, специализированные для использования на одной определенной фирме.
Тактические модели применяются управляющими среднего уровня для расширения и контроля использования имеющихся ресурсов. Сферы использования: финансовое планирование, планирование требований к работникам, планирование увеличения продаж, построение схем компоновки предприятий. Эти модели применяют обычно лишь к отдельным частям фирмы (например, к системе производства и сбыта) и могут также включать в себя агрегированные показатели. Временной горизонт, охватываемый тактическими моделями – от одного месяца до двух лет. Обычно тактические модели реализуются как детерминистские, оптимизационные и универсальные.
Оперативные модели используются на низших уровнях управления для поддержки принятия оперативных решений с горизонтом, измеряемым днями и неделями. Возможные применения этих моделей включают в себя ведение дебиторских счетов и кредитных расчетов, календарное производственное планирование, управление запасами и т. д. Оперативные модели обычно используют для расчетов внутрифирменные данные. Они, как правило, детерминистские, оптимизационные и универсальные.
Математические модели состоят из совокупности модельных блоков, модулей и процедур, реализующих математические методы. Сюда могут входить процедуры линейного программирования, статистического анализа временных рядов, регрессионного анализа и т. п. – от простейших процедур до сложных ППП. Модельные блоки, модули и процедуры могут использоваться как поодиночке, так и комплексно для построения и поддержания моделей.
Система управления базой моделей должна обладать следующими возможностями: создавать новые модели или изменять существующие, поддерживать и обновлять параметры моделей, манипулировать моделями.
Эффективность и гибкость информационной технологии во многом зависят от характеристик интерфейса системы поддержки принятия решений. Интерфейс определяет: язык пользователя, язык сообщений компьютера, организующий диалог на экране дисплея, знания пользователя.



