

Контрольні запитання:
Що таке автоматизована база даних?
Які ви знаєте класифікації АБД?
Яка структура у АБД?
Література
Литвиненко О.Є. До питання про інтеграцію просторово прив’язаних тематичних даних // Тези для виставки “Проблеми інформатизації центральних органів державної виконавчої влади“, Київ, 9-11.03.99.
Першиков В.И., Савинков В.М. Толковый словарь по информатике.- М.: Финансы и статистика, 1991.- 543 с.
Основи інформаційних систем: Навч. посіб. -- 2-е вид., перероб. і доп. / В. Ф. Ситник, Т. А. Писаревська, Н. В. Єрьоміна, О. С. Краєва; За ред. В. Ф. Ситника. -- К.: КНЕУ, 2001. -- 420 с.
Тема: Характеристика інфологічної та даталогічної моделі баз даних
Мета: вивчити рівні моделі даних. Будову інфологічної моделі та даталогічного проектування
План
Будова інфологічної моделі
Даталогічне проектування
Побудова инфологічної моделі
Опис предметної області, виконаний без орієнтації на використовувані надалі програмні та технічні засоби, називається инфологической моделлю.
Тому перш ніж почати проектування бази даних, необхідно як сл ід розібратися, як функціонує предметна область, для відображення якої створюється БД. Для цього використовують штучні формалізовані мовні засоби. У зв'язку з цим п ід инфологической моделлю (Илм) розуміють опис предметної області, виконаний з використанням спеціальних мовних засобів, що не залежать від використовуваних надалі програмних засобів (Рис.4) Основними конструктивними елементами инфологической моделі є сущність, зв'язки між ними та їх властивості (атрибути).
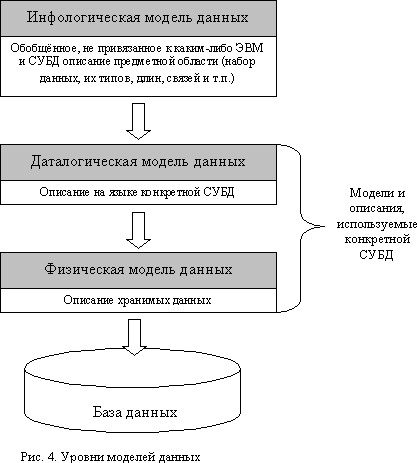
Концептуальна інфологічна модель відображає зв'язок сутностей, розмірність зв'язків і будується у вигляді діаграми з використанням спеціальних позначень. Модель наочно показує взаємозв'язок об'єктів предметної області, на основі яких будувалися сутності, з її допомогою формується цілісне уявлення про семантику предметної області.
Даталогічне проектування
На етапі даталогічного проектування створюється даталогічна модель (ДЛМ) предметної області. ДЛМ будується на базі инфологической моделі, отриманої на попередньому етапі проектування, і є моделлю логічного рівня, представляючи собою відображення логічних зв'язків між елементами даних безвідносно до їхнього вмісту і середовища зберігання. На етапі даталогічного проектування суті перетворюються на однойменні відносини з аналогічними атрибутами. Перед складанням даталогічноі схеми необхідно встановити зв'язки і нормалізувати
Контрольні питання:
Назвіть рівні моделей даних
Опишіть будову інфологічної моделі
Опишіть даталогічне проектування
Література
Електроний ресурс: http://www.ed.vseved.ru/
Основи інформаційних систем: Навч. посіб. -- 2-е вид., перероб. і доп. / В. Ф. Ситник, Т. А. Писаревська, Н. В. Єрьоміна, О. С. Краєва; За ред. В. Ф. Ситника. -- К.: КНЕУ, 2001. -- 420 с.
Тема: Методи створення оптимальної моделі баз даних
Мета: ознайомитися з поняттям оптимальної моделі баз даних та методами її побудови при використанні БД в комерційній діяльності підприємств
План
Загальні положення. Поняття бази даних та системи управління базою даних
Вимоги та методи до оптимальних моделей баз даних
Під оптимальною логічною моделлю баз даних розуміють модель, яка не має аномалій, пов’язаних з модифікацією БД, тобто проблем, що можуть виникнути у зв’язку із замінами, вставками і вилученнями даних із БД.
Для створення такої моделі баз даних незалежно від того, яка СУБД використовується — ієрархічна, сіткова чи реляційна — застосовується теорія нормалізації реляційних баз даних. Використання реляційного підходу дає змогу спроектувати оптимальну логічну модель БД, яка потім досить просто трансформується в ієрархічну чи сіткову модель.
В основу реляційних моделей покладено поняття відношення, яке подають у вигляді двовимірної таблиці.
Реляційна БД — це набір взаємопов’язаних відношень. Кожне відношення (таблиця) в ЕОМ подається як файл. Відношення можна поділити на два класи: об’єктні і зв’язкові.
Об’єктні відношення зберігають дані про інформаційні об’єкти предметної області. Наприклад: КЛІЄНТ (код клієнта, назва клієнта, адреса, телефон) є об’єктним відношенням.
В об’єктному відношенні один з атрибутів однозначно ідентифікує окремий об’єкт. Такий атрибут називається первинним ключем відношення. У наведеному відношенні роль ключа виконує атрибут «код клієнта».
Ключ може вміщувати кілька атрибутів, тобто бути складеним. В об’єктному відношенні не повинно бути рядків з однаковим ключем, тобто не допускається дублювання об’єктів. Це основне обмеження реляційної моделі для забезпечення цілісності даних.
Зв’язкове відношення зберігає первинні ключі двох або більше об’єктних відношень. Ключі зв’язкового відношення мають на меті встановлення зв’язків між об’єктними відношеннями.
Розглянемо, наприклад, ще одне об’єктне відношення БАНК (код банку, назва банку, адреса банку).
Тоді зв’язкове відношення БАНК-КЛІЄНТ (код банку, код клієнта) буде сполучним між двома об’єктними відношеннями БАНК і КЛІЄНТ. У зв’язковому відношенні можуть дублюватися ключові атрибути. Крім ключів, за якими встановлюють зв’язок у зв’язковому відношенні, можуть бути ще й інші атрибути, які функціонально залежать від цього складового ключа.
Ключі в зв’язкових відношеннях називаються вторинними або зовнішніми ключами, оскільки вони є первинними ключами об’єктів інших відношень. Реляційна модель накладає на зовнішні ключі обмеження, яке називають посилковою цілісністю. Воно необхідне для забезпечення цілісності даних.
Посилкова цілісність — це відповідність між об’єктними та зв’язковими відношеннями, яка полягає в тому, що кожному зовнішньому ключеві зв’язкового відношення має відповідати рядок якогось об’єктного відношення. Без такого обмеження може статися так, що зовнішній ключ посилається на об’єкт, про який нічого не відомо.
У реляційній БД накладається ще одне обмеження — відношення мають бути нормалізовані.
Контрольні запитання:
Що таке БД?
Що таке СУБД?
Які ви знаєте вимоги та методи до оптимальних моделей баз даних?
Література:
1. Информатика для юристов и экономистов/ Симонович С.В. и др. - СПб: Питер,
2. М.І. Жалдак, Ю.С.Рамський. Інформатика. Київ, "Вища школа", 1991.
3. Ю. Шафрин. Информатика. Информационные технологии: в 2 ч. М.: Лаборатория Базовых Знаний, 2001.
4. Куперштейн. В. Современные информационные технологии в производстве и управлении.-СПб.:БХВ, 2000.-304 с.
Тема: Теорія нормалізації відношень
Мета: вивчення теорії нормалізації відносин БД
План
Визначення «Нормалізація відносин»
Склад атрибутів відносин БД
Нормалізація відносин - це ітераційний зворотний процес декомпозиції початкового відносини на декілька більш простих відносин меншої розмірності. Під возвратностью процесу розуміють те, що операція об'єднання відносин, отриманих в результаті декомпозиції, повинна дати початкове ставлення. У результаті нормалізації склад атрибутів відносин БД повинні відповідати таким вимогам:
між атрибутами повинні виключатися небажані функціональні залежності;
групування атрибутів не повинно мати збиткового дублювання даних;
забезпечувати обробку та обнобновленіе атрибутів без ускладнень.
Апарат нормалізації був розроблений американським вченим Е.Ф. Коддом. Кожна нормальна форма обмежує тип допустимих залежностей між атрибутами. Кодд виділив три нормальних форми (скорочена назва 1НФ, 2НФ і ЗНФ). Цілковита з них - це ЗНФ. Тепер вже відомі і певні 4НФ, 5НФ. Нормалізація відносин виконується за кілька кроків (рис. 1).

1-й крок (1-я ітерація) - зведення відносин до першої нормальної форми (1НФ). Ставлення в 1 НФ повинні відповідати таким вимогам:
всі атрибути відносини повинні бути атомарними, тобто неподільними;
всі рядки таблиці повинні бути однакової структури, тобто мати одне і те ж кількість атрибутів з однаковими іменами;
імена стовпців повинні бути різними, а значення однорідними (мати однаковий формат);
порядок рядків у таблиці неістотний.
Кожне відношення БД містить як структурну, так і семантичну інформацію. Структурна інформація задається схемою відносини, а семантична висловлює функціональні зв'язки між атрибутами.
2-й крок (2-а ітерація) нормалізації виявляє ключі, атрибути та аналізує відповідні залежності з метою вилучення неповних функціональних залежностей.
Визначення 1. Атрибут Б функціонально залежить від А відносно R тоді, коли в кожен момент часу одному й тому ж значенню А відповідає не більше ніж одне значення Б. Функціональної залежності відповідає ставлення 1:1 між атрибутами.
Визначення 2. Атрибут знаходиться в повній функціональної залежності, якщо він залежить від усього ключа й не залежить від його складових.
3й крок (3-я ітерація) нормалізації - це вилучення транзитивних залежностей. Ставлення в 2 НФ повинні аналізуватися на предмет присутності транзитивних залежностей.
Транзитивна залежність - це залежність між неключових атрибутами. Транзитивні залежності вилучаються також за допомогою декомпозиції відносини на інші два або більше відносин, які не містять транзитивних відносин та об'єднання яких дасть початкове ставлення.
4-й крок (4-я ітерація) нормалізації виконує аналіз на присутність незалежних багатозначних залежностей у відношенні. Якщо вони є, то виконується декомпозиція відносини.
Багатозначна залежність - це різновид функціональної залежності. Атрибут В знаходиться в багатозначною залежно від атрибута А, тоді коду одного значення атрибута А відповідає багато значень атрибуту В. Наприклад, поміж атрибутами код структурного підрозділу: табельний номер = 1: Б, так як в одному підрозділі може працювати багато співробітників. Тобто багатозначною залежності відповідає відношення 1: Б між атрибутами.
Існують поняття тривіальної і нетривіальною багатозначною залежності.
Залежність типу X ®> У і У ®> Х є тривіальною, а залежність X ®> У і У # ®> X - нетривіальною. Присутність нетривіальних багатозначних залежностей у схемі відносини і незалежність їх правих частин зумовлюють комбінаторики правих частин відносини.
Визначення 3. Відношення R міститься в 4 НФ, коли в структурі багатозначною залежності, яка визначається на множині атрибутів, є лише тривіальні або такі нетривіальні багатозначні залежності, у яких ліва частина будь-якої з них є ключем.
Декомпозиція початкового відносини на кілька інших повинні гарантувати його звернення, тобто забезпечувати одержання початкової відносини об'єднанням відносин, знайдених в результаті декомпозиції.
Проте не завжди декомпозиція гарантує звернення. Відношення, яке містить більше трьох багатозначних залежностей, потребує спеціальних заходах щодо забезпечення обігу декомпозиції. Для цього існує 5 НФ. При декомпозиції з 4 НФ отримують такі проекції, щоб кожна з них містила не менш ніж один можливий ключ і щонайменше один неключових атрибут початкового відносини.
5 НФ усуває надмірність і разом з тим аномалії поповнення БД. Нормалізація відносин скасовує між атрибутами такі залежності: неповні функціональні, транзитивні, нетривіальні (незалежні) багатозначні. Усуваючи ці залежності, виключаємо дублювання даних і можливість виникнення аномалій при виконанні операцій поповнення, заміни та вилучення даних з БД. Крім того, нормалізована база даних вимагає значно менше пам'яті для її збереження, ніж ненормалізоване база даних.
Контрольні запитання:
Що таке «нормалізація відносин»?
Хто першим придумав апарат нормалізації відносин?
Що таке перша нормальна форма (1НФ)?
Що таке друга нормальна форма (2НФ)?
Що таке третя нормальна форма (3НФ)?
Що таке четверта нормальна форма (4НФ)?
Що таке п’ята нормальна форма (5НФ)?
Література:
Електроний ресурс: http://ru.wikipedia.org/wiki/Нормальная_форма
Електроний ресурс: http://www.citforum.idknet.com/database/dblearn/dblearn06.shtml
Розділ VI. Створення комп’ютерних технологій
Тема: Характеристика та класифікація технологічних операцій
Мета: ознайомитися з характеристикою та класифікацією технологічних операцій використовуємих на підприємствах
План
Визначення інформаційної технології
Класифікація інформаційних технологій та операцій
Операція — це комплекс дій з інформацією та її носіями, які виконуються на одному робочому місці.
Виділення окремих дій в одну технологічну операцію умовне. На виділення технологічних операцій можуть вплинути різноманітні фактори. Серед них найчастіше зустрічаються:
1. Особливості технічних пристроїв та програмних засобів, які використовуються для обробки інформації.
2. Кваліфікація персоналу, який обробляє інформацію.
3. Розподіл обов’язків між працівниками.
4. Переривання процесу обробки інформації на ЕОМ через потребу виконати додаткові та допоміжні дії.
Наприклад, перенесення даних на магнітну стрічку може виконуватися за допомогою спеціального пристрою — ЄС-9004. Особливості такого пристрою дають змогу переглядати набрані на клавіатурі дані на екрані дисплея, тому можливе виділення операцій переносу та контролю даних на магнітній стрічці.
Перенесення даних на магнітну стрічку за допомогою пристрою ЄС-9001 не дає змоги відразу переглядати інформацію, яка набирається, тому виокремлюються дві операції: перенесення даних на носій інформації і контроль такого перенесення за допомогою інших пристроїв.
Якщо спостереження за роботою операторів показують, що вони припускаються багатьох помилок при наборі даних, то в такому разі перенесення даних і відповідний контроль доручають різним операторам навіть тоді, коли технічний пристрій дозволяє одночасно виконувати набір даних і контролювати його. У такій ситуації вирізняють окремі технологічні операції перенесення даних на машинний носій і контролю такого перенесення.
Розподіл обов’язків між економістами може вплинути на виділення технологічних операцій на АРМ. АРМ бухгалтера може виконувати облік заробітної плати та облік матеріалів. У бухгалтерії такі ділянки обліку звичайно закріплені за окремими бухгалтерами, тому і на АРМ їх функції відповідають окремим технологічним операціям. Можливі операції перенесення даних на жорсткий магнітний диск документів з обліку заробітної плати і операція з перенесення на гнучкий магнітний диск документів з обліку матеріалів.
Переривання процесу обробки даних на ЕОМ особливо характерне для АРМ. Робота на АРМ будується за принципом вибору тієї чи іншої функції обробки інформації. Кожне переривання процесу обробки для вибору функції може бути основою для виокремлення технологічних операцій.
У ряді випадків переривання обробки може бути пов’язане з установленням інших машинних носіїв інформації, виконанням тих чи інших дій за допомогою пакетів програмних засобів, які не є складовою програмного забезпечення конкретного розрахунку, копіюванням інформації по каналах зв’язку і т.ін. Ці переривання дають змогу розбити процес обробки інформації на окремі операції.
Технологічні операції за призначенням поділяються на виконавські та контрольні. Виконавські операції змінюють значення атрибутів або форму подання інформації. Контрольні операції звичайно не змінюють значень атрибутів і форми подання інформації, а лише перевіряють правильність виконавських операцій. Iноді контрольні операції можуть змінювати форму подання інформації (звичайно — це друкування інформації на папері), але лише з метою контролю. Ця нова форма подання інформації ніде більше не використовується.
За ступенем механізації операції поділяються на ручні, машинно-ручні (автоматизовані) та автоматичні. Сама назва виду операції пояснює особливості її виконання. В автоматичних операціях може бути невелика кількість ручної праці. Наприклад, автоматична операція обробки інформації на ЕОМ може містити ручні дії зі встановлення машинних носіїв інформації, підготовки пристроїв до роботи тощо.
За функціонально-часовими характеристиками операції поділяються на операції збору та реєстрації інформації, передавання її на обробку, підготовки машинних носіїв, обробки, видачі результатів, розмноження результатів.
Кожна технологічна операція може бути віднесена до того чи іншого класу операцій за кожною з ознак класифікації. Наприклад, операція перенесення даних на магнітну стрічку — це виконавська операція, операція машинно-ручна, операція підготовки машинних носіїв.