

7. Пирамидальная сортировка. Сортировка слиянием (однократное и циклическое)
 Пирамидальная
сортировка
— алгоритм сортировки, работающий в
худшем, в среднем и в лучшем случае (то
есть гарантированно) за Θ(n log n) операций
при сортировке n элементов. Количество
применяемой служебной памяти не зависит
от размера массива (то есть, O(1)). Сортировка
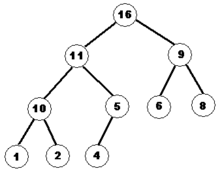
пирамидой использует сортирующее
дерево(см. рис.) — такое двоичное дерево,
для которого выполнены три условия:
Пирамидальная
сортировка
— алгоритм сортировки, работающий в
худшем, в среднем и в лучшем случае (то
есть гарантированно) за Θ(n log n) операций
при сортировке n элементов. Количество
применяемой служебной памяти не зависит
от размера массива (то есть, O(1)). Сортировка
пирамидой использует сортирующее
дерево(см. рис.) — такое двоичное дерево,
для которого выполнены три условия:
Значение в любой вершине не меньше, чем значения её потомков.
Глубина листьев (расстояние до корня) отличается не более чем на 1 слой.
 Последний
слой заполняется слева направо.
Последний
слой заполняется слева направо.
Удобная структура данных для сортирующего дерева — такой массив Array, что Array[1] — элемент в корне, а потомки элемента Array[i] — Array[2i] и Array[2i+1]. Алгоритм сортировки будет состоять из двух основных шагов:
1. Выстраиваем элементы массива в виде сортирующего дерева:
![]()
![]()
при
![]() .
Этот шаг требует
.
Этот шаг требует
![]() операций.
операций.
2.
Будем удалять элементы из корня по
одному за раз и перестраивать дерево.
То есть на первом шаге обмениваем
Array[1]
и Array[n],
преобразовываем Array[1],
Array[2],
… , Array[n-1]
в сортирующее дерево. Затем переставляем
Array[1]
и Array[n-1],
преобразовываем Array[1],
Array[2],
… , Array[n-2]
в сортирующее дерево. Процесс продолжается
до тех пор, пока в сортирующем дереве
не останется один элемент. Тогда Array[1],
Array[2],
… , Array[n]
— упорядоченная последовательность.
Этот шаг требует
![]() операций.
операций.
Сортировка слиянием— алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно) в определённом порядке. ОДНОКРАТНОЕ СЛИЯНИЕ.
Очевидно, что если из упорядоченных последовательностей брать по одному очередному элементу из каждой, затем выбирать из них минимальный и переносить его, то выходная последовательность будет упорядоченной. Отсюда возможен самый простой способ однократного слияния: массив разбивается на n частей, каждая из них сортируется независимо, а затем отсортированные части объединяются слиянием. ЦИКЛИЧЕСКОЕ СЛИЯНИЕ. Первоначально массив разделяется на n последовательностей. Затем в каждой из них выбирается по одному элементу (первому) в таком порядке, чтобы получилась упорядоченная группа из n элементов, которая запоминается в выходной последовательности (слияние). Выходная последовательность будет состоять из групп по n элементов, каждая из которых упорядочена. Далее файл опять распределяется, но уже группами по n элементов по тем же самым n входным последовательностям. В результате слияния образуются упорядоченные группы из n*n элементов. Затем процесс повторяется группами по n*n*n и т.д..
8. Стек. Основные базисные операции для работы со стеком. Организация стека на основе массива и связного списка.
Стеком называется одномерная структура данных, загрузка или увеличение элементов для которой осуществляется с помощью указателя стека в соответствии с правилом LIFO ("last-in, first-out" "последним введен, первым выведен"), т.е. включение и исключение элементов производится только с одного конца.
Начало последовательности называется дном стека, конец последовательности, в который производится добавление элементов и их исключение - вершиной стека. Переменная, которая указывает на последний элемент последовательности в вершине стека - указатель стека. Таким образом, указатель стека sp (stackpointer) содержит в любой момент времени индекс (адрес) текущего элемента, который является единственным элементом стека, доступным в данный момент времени для обработки.
Стек можно организовать при помощи массивов. При представлении стека в статической памяти для стека выделяется память. В дескрипторе (число которое уникальным образом характеризует какой-либо ресурс) должен находиться также указатель стека - адрес вершины стека. Указатель стека может указывать либо на первый свободный элемент стека, либо на последний записанный в стек элемент. (Все равно, какой из этих двух вариантов выбрать, важно впоследствии строго придерживаться его при обработке стека.) В дальнейшем мы будем всегда считать, что указатель стека адресует первый свободный элемент и стек растет в сторону увеличения адресов.
Стек можно организовать на базе любой структуры данных, где возможно хранение нескольких однотипных элементов и где можно реализовать определение стека: линейный массив, типизированный файл, однонаправленный или двунаправленный список. В нашем случае наиболее подходящим для реализации стека является однонаправленный список, причём в качестве вершины стека выберем начало этого списка.
Выделим типовые операции над стеком и его элементами:
добавление элемента в стек;
удаление элемента из стека;
проверка, пуст ли стек;
просмотр элемента в вершине стека без удаления;
очистка стека.