

Очередь
Очередь можно охарактеризовать как структуру данных, работающую по принципу «первый пришел – первый уходит». В литературе очереди часто обозначают как FIFO – First In First Out.
Графическое представление очереди выглядит следующим образом:

Очереди также имеют большое значение в информатике и применяются при решении самых разнообразных задач. Типичный пример – буферизация, например при получении данных компьютером из локальной сети. Получаемые кусочками данные складываются в специальную структуру хранения данных – очередь, откуда потом извлекаются программой-получателем в том же порядке, в котором и пришли.
Дек - очередь с двумя концами (deque – double-ended queue)
Это очередь, в которой включения и исключения можно делать на обоих концах. Это позволяет извлекать данные как в порядке поступления (FIFO), так и в обратном порядке (LIFO) Графически это можно представить следующим образом:

Линейный список
Линейный список – это представление конечного и упорядоченного множества элементов некоторого типа. Операции, которые мы можем выполнять с линейными списками, включают, например, следующие:
получить доступ к k-му элементу списка, чтобы проанализировать и/или изменить содержимое его полей;
включить новый узел в список непосредственно перед k-м узлом;
исключить k-й узел;
объединить два или более линейных списка в один список;
разбить линейный список на два или более;
сделать копию линейного списка;
определить количество узлов в списке;
найти в списке заданный узел (или узел с заданными характеристиками);
и т.п.
Если мы взглянем на только что перечисленные структуры, то увидим, что стек и очереди являются частными случаями линейного списка, у которого операции включения и исключения производятся в первом или последнем узлах:
Стек – линейный список, в котором все включения и исключения (и обычно всякий доступ) делают только в одном конце списка.
Очередь – линейный список, у которого все включения производятся на одном конце, а исключения – на другом.
Дек – линейный список, у которого включения и исключения делаются на обоих концах списка.
В реальных языках программирования нет какой-либо структуры данных для представления линейного списка так, чтобы все указанные операции над ним выполнялись в одинаковой степени эффективно. Поэтому при работе с линейными списками важным является представление используемых в программе линейных списков таким образом, чтобы была обеспечена максимальная эффективность и по времени выполнения программы, и по объему требуемой памяти.
Физическое (машинное) представление линейных списков
Обычно наиболее естественным являются два варианта машинного представления:
Элементы списка расположены последовательно, один за другим;
Элементы списка расположены в различных местах, но связаны цепочкой указателей.
В первом варианте основой списка является массив. Соседние элементы списка занимают соседние элементы этого массива.
Во втором варианте элементы списка располагаются в различных местах в памяти. Для того чтобы установить связи между ними, каждый элемент списка кроме собственно данных содержит еще указатель на последующий элемент этого списка, который в таком случае называется связанным списком, либо на предыдущий и последующие элементы (дважды связанный список).
Ниже изображены возможные варианты реализации линейного списка. В реализациях в виде связанного списка заполненными кружками условно обозначены указатели на следующий элемент, а ромбами – указатели на предыдущий элемент.
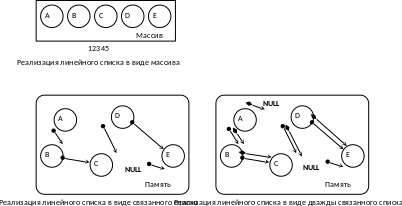
Отметим, что связанный список может быть реализован на основе непрерывного массива. В этом случае роль указателей выполняют индексы в этом массиве. Обратное неверно – последовательно хранимый список в общем случае не может быть реализован на основе связанного списка, поскольку последний не гарантирует последовательного размещения в памяти соседних элементов.
Каждый из этих вариантов обладает своими достоинствами и недостатками. Рассмотрим основные из них.
При организации связанного распределения в памяти потребуется выделить дополнительное пространство для размещения связей. В некоторых ситуациях этот фактор может оказаться доминирующим. Однако важнее то, что с помощью связанного распределения памяти выигрыш можно получить неявно за счет частичного перекрытия таблиц, совместно использующих некоторые области памяти. Часто последовательное распределение не так рационально, как связанное, поскольку для его эффективной работы необходимо очень большое количество дополнительных вакантных ячеек памяти.
Операция удаления элемента в связанном списке выполняется проще. Например, для удаления элемента 3 необходимо только изменить связь с ним в элементе 2. А при последовательном выделении памяти такое удаление в общем случае подразумевает перемещение значительной части списка в другие ячейки.
При использовании схемы связанного распределения памяти проще выполняется и вставка элемента в середину списка. Например, для вставки элемента в список потребуется изменить только две связи. А при работе с длинной таблицей с последовательным выделением памяти для вставки нужно будет выполнить гораздо больше действий, для чего потребуется чрезвычайно много времени.
Обращения к произвольным элементам списка гораздо быстрее осуществляются при последовательном выделении памяти. Для доступа к k-му элементу списка, где k—некоторая переменная, в случае последовательного распределения памяти потребуется фиксированное время, но для доступа к нужному элементу в случае связанного распределения памяти потребуется выполнить k итераций. Таким образом, полезность связанного распределения памяти основывается на том, что в большинстве приложений доступ к элементам списка выполняется в последовательном, а не произвольном порядке. Для доступа к элементам в середине или в конце списка можно создать дополнительную переменную связь или целый список переменных связи, которые указывают на нужные позиции списка.
В схеме связанного распределения памяти проще организовать объединение двух списков или разбиение списка на два других списка, которые могут увеличиваться независимо.
Схема связанного распределения памяти прекрасно подходит для организации более сложных структур, чем простые линейные списки. Например, ее можно применить для создания переменного количества списков переменного размера. Причем каждый узел одного из них может быть началом другого списка, к тому же узлы могут быть связаны между собой несколькими способами и образовывать другие списки и т. д.
Таким образом, технология связанного распределения памяти позволяет обойти ограничения, накладываемые последовательной природой компьютерной памяти. При выполнении одних операций она способствует достижению гораздо более высокой эффективности, а при выполнении других, наоборот, снижает се. Обычно совершенно ясно, какая технология лучше всего подходит в конкретной ситуации. Поэтому часто в одной и той же программе используют списки разных типов.
Дерево
Деревом называется структура, которая образована из одного или более узлов типа T, среди которых имеется один узел, называемый корнем, и, возможно пустое, множество поддеревьев этого дерева.
Среди структур данных деревья относятся к наиболее важным, так как они обобщают свойства всех перечисленных выше структур. Особое значение они имеют для задач искусственного интеллекта и задач синтаксического анализа.
Корень поддерева называется вершиной, если корень поддерева не имеет поддеревьев – то это лист. Вершины, не совпадающие с корнем и листьями, называются внутренними вершинами.

Двоичное (бинарное) дерево – это дерево, у каждой вершины которого могут быть только два поддерева: левое и правое. Двоичные деревья широко используются, при этом существует каноническое правило, позволяющее преобразовать любое дерево к двоичному, но мы не будем настолько подробно останавливаться на деревьях. Программная реализация хранения данных в виде дерева будет рассмотрена ниже