

Метод Шелла.
Метод Шелла похож на метод пузырька, однако он более сложно устроен. Основным недостатком метода пузырька является то, что он может сравнивать и менять местами только соседние элементы. Это приводит к тому, что для перемещения элемента массива на i элементов вверх или вниз требуется i операций обмена.
Метод Шелла рассматривает пары элементов, находящихся на различных расстояниях друг от друга. Как и в методе пузырька, в методе Шелла перебираются все пары элементов на заданном расстоянии, и те из них, в которых предыдущий элемент больше последующего, элементы меняются местами. Так продолжается до тех пор, пока не будет выполнено ни одного обмена.
Сначала расстояние между сравниваемыми элементами берется равным половине длины массива. После того, как все пары на таком расстоянии упорядочены, оно делится пополам, и начинается упорядочение пар на этом новом расстоянии. Так продолжается до тех пор, пока не будут упорядочены все пары с расстоянием между элементами, равном единице.
void shell(void *base, size_t nelem, size_t width, int (*fcmp)(const int, const int, const void*, const size_t))
{
int iOffset, iSwitch, iLimit, i;
iOffset = nelem/2;
while (iOffset)
{
iLimit = nelem - iOffset - 1;
do
{
iSwitch = 0; // Здесь хранится номер последнего
// элемента, для которого был сделан обмен
for(i = 0; i <= iLimit; i++)
{
if (fcmp(i, i+iOffset, base, width) > 0)
{
elemswap(i, i+iOffset, base, width);
iSwitch = i;
}
}
//Оптимизация: нет смысла проверять пары дальше последней
// замененной–там они уже все упорядочены. Поэтому лимит
// ставим таким образом, чтобы в последнюю пару новой
// итерации вошёл последний проверенный элемент iSwitch,
// это пара (iSwitch-iOffset, iSwitch)
iLimit = iSwitch - iOffset;
} while(iSwitch); // Повторяем пока все пары с интервалом
// iOffset не упорядочатся
iOffset /= 2;
}
}
Метод кучи (бинарной кучи).
Данный метод является наиболее сложным из всех рассматриваемых здесь методов сортировки.
Этот метод основывается на представлении массива данных в виде бинарного дерева, где 0-й элемент является корневым элементом дерева, а каждому i-му массива ставятся в соответствие 2 дочерних элемента 2*i и 2*i+1.
Например, массив {1,2,3,4,5,6} представлется в виде:
1
/ \
3
/ \ /
4 5 6
При этом выполняются следующие свойства:
все узлы имеют глубину k или k-1 - дерево сбалансированное.
при этом уровень k-1 полностью заполнен, а уровень k заполнен слева направо.
При применении определённых алгоритмов можно также добиться выполнения так называемого «свойства пирамиды»: каждый дочерний элемент меньше предыдущего.
При этом алгоритм сортировки состоит из 2 стадий:
Построение дерева, удовлетворяющего 3 вышеописанным свойствам (т.е. предварительная сортировка элементов таким образом, чтобы все дочерние элементы были меньше родительских). В примере это делается с помощью функции PercolateUp.
Собственно сортировка: Поскольку корневой элемент дерева является наибольшим среди всех остальных (см. «свойство пирамиды»), то меняем его местами с последним элементом массива, после чего восстанавливаем пирамидальность с помощью функции PercolateDown. Эту функцию надо вызвать только для вновь появившегося корневого элемента, т.к. только он может не удовлетворять свойству пирамиды.
После этого повторяем процесс для всей пирамиды, уменьшив число её элементов на 1. Таким образом, в конце массива будут скапливаться отсортированные по возрастанию элементы.
void PercolateDown(int MaxLevel, void *base, size_t width,int (*fcmp)(const int, const int, const void*, const size_t))
{
int i = 0, child;
do
{
child = 2*i;
if (child > MaxLevel)
{
break;
}
if (child+1 <= MaxLevel)
{
if (fcmp(child+1, child, base, width) > 0)
{
child++;
}
}
if (fcmp(i, child, base, width) < 0)
{
elemswap(i, child, base, width);
i = child;
}
else
{
break;
}
} while (1);
}
void PercolateUp(int MaxLevel, void *base, size_t width,int (*fcmp)(const int, const int, const void*, const size_t))
{
int i = MaxLevel, parent;
while (i != 0)
{
parent = i / 2;
if (fcmp(i, parent, base, width) > 0)
{
elemswap(parent, i, base, width);
i = parent;
}
else
{
break;
}
}
}
void heap(void *base, size_t nelem, size_t width, int (*fcmp)(const int, const int, const void*, const size_t))
{
int i;
for (i = 1; i < (int)nelem; i++)
{
PercolateUp(i, base, width, fcmp);
}
for (i = nelem - 1; i > 0; i--)
{
elemswap(0, i, base, width);
PercolateDown(i-1, base, width, fcmp);
}
}
Структуры хранения данных: стек, очередь, дек, линейный список.
В данной лекции будут рассмотрены сложные структуры хранения данных, имеющие большое распространение:
Стек
Очередь
Очередь с двумя концами – дек (deque – double-ended queue)
Список
Дерево
Двоичное дерево.
Стек
Понятие стека часто встречается в повседневной жизни. Пример такой ситуации – когда начальник складывает приходящие на рассмотрение бумаги в стопку, так что пришедшие первыми долго лежат внизу. Исторически бытует легенда, что стек был придуман в придорожном «Макдональдсе» – чистые тарелки ставились на стопку, подпружиненную снизу. Снимая сверху очередную чистую тарелку, приводили в действие механизм подталкивания стопки вверх.
Стеком называется множество некоторого переменного числа данных (возможно, нулевого), на котором выполняются следующие операции:
пополнение стека новыми данными, добавляемыми в конец стека;
проверка, определяющая, пуст ли стек;
просмотр последнего элемента, если таковой существует
уничтожение последнего прибавленного элемента в стеке.
В большинстве реализаций стеков последние 2 операции (чтение и удаление элемента) объединены.
Графически стек и операции над ним можно представить таким образом:
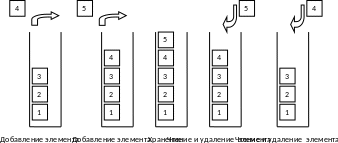
Часто стек определяется аббревиатурой LIFO – Last In First Out – последний пришел – первый вышел. Стеки широко применяются в различных программных решениях, причём настолько широко, что практически во всех микропроцессорах и микроконтроллерах есть специальные комманды, реализующие стек микропроцессора на аппаратном уровне.