

2. Выделение памяти под нетипизированный указатель
Оператор new выделяет область памяти размером соответствующим заданному типу. Программист имеет возможность выделить область памяти произвольного размера. Для этого используются функции семейства alloc. Для их применения необходимо подключить библиотеки #include <stdlib.h> или #include<alloc.h>
Функция malloc()
void *malloc(unsigned size); выделяет блок памяти размером size байт.
В случае успеха, malloc() возвращает указатель на выделенный блок памяти. Если недостаточно памяти для нового блока, это возвращается пустой указатель (NULL). Если размер аргумента равен 0, malloc() возвращает NULL.
str=(char*)malloc(10)
Функция calloc()
void *calloc(unsigned nitems, unsigned size); выделяет блок памяти размером nitems*size. Блок инициализируется нулями. Возвращаемые значения аналогичны функции malloc().
str=(char*)calloc(10,size of (char));
Функция realloc()
void *realloc(void *block, unsigned size);
позволяет перевыделить память .realloc,пытается изменить размер предварительно выделенного блока. Если size — ноль, блок памяти освобождается, и возвращается NULL. Аргумент block указывает на память, предварительно выделенную функциями семейства alloc. Если block==NULL, realloc работает как malloc.
realloc копирует содержимое старого блока памяти в новый и возвращает адрес нового блока памяти, который может отличаться от старого.
str=(char*)realloc(str,20);
Функция free()
void free(void *block);
Освобождает память, выделенную функциями calloc, malloc, или realloc
Линейный односвязный список
Если тип определен следующим образом
typedef struct List_Item *List;
struct List_Item { int key; List next; };
то получается следующая структура данных

Такая структура называется линейным односвязным списком.
Определим некоторые операции с линейными списками.
Ф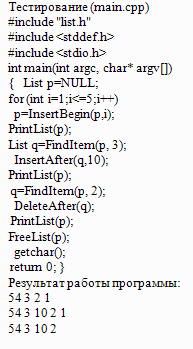 айл
list.h
айл
list.h
#ifndef __LIST_H
#define __LIST_H
typedef struct List_Item *List;
struct List_Item { int key; List next; };
void PrintList(List); //Печать списка
List InsertBegin(List, int); //Вставка элемента в начало списка
List FindItem(List, int); //Поиск элемента по ключу
void InsertAfter(List, int); //Вставка элемента после заданного
void DeleteAfter(List); //Удаление элемента после заданного
void FreeList(List); //Освобождение памяти
#endif
Реализация (list.cpp)
#include "list.h"
#include "stdio.h"
#include "stdlib.h"
void PrintList(List p)
{
while (p) { printf("%d ", p->key); p=p->next; } printf("\n");
};
List InsertBegin(List p, int x)
{
//List q=(List)malloc(sizeof(List_Item));
List q=new List_Item; q->key=x; q->next=p; return q;
};
List FindItem(List p, int x)
{ while (p && p->key!=x) p=p->next; return p;
};
void InsertAfter(List p, int x)
{
//List q=(List)malloc(sizeof(List_Item));
List q=new List_Item; q->key=x; q->next=p->next; p->next=q; };
void DeleteAfter(List p)
{
List q=p->next; p->next=q->next; delete q;
//free(q);
};
void FreeList(List p)
{ List q; while (p) { q=p; p=p->next; delete q; //free(q); } };
17. Динамические массивы. Особенности выделения и освобождения памяти для многомерных массивов.
Оператор new может выделить из хипа память для размещения массива. В этом случае после спецификатора типа в [] указывается кол-во элементов массива.
// создание единственного объекта типа int с начальным значением 1024
int *p = new int[ 1024 ];
Основное преимущество динамического массива состоит в том, что количество элементов в нем не обязано быть константой, т.е. может быть неизвестным во время компиляции, а стать известным в процессе выполнения программы.
int N; scanf(“%d”,&N);
int *p = new int[N];
Для освобождения памяти используется модификационный оператор delete: delete[]p;
[] говорят компилятору, что освобождается память из под массива, а не из под единичного элемента.
Выделять память под массив также удобно с помощью функции calloc.
int *p=(int*)(calloc(N, sizeof(int));
Для создания двумерного массива вначале нужно распределить память для массива указателей на одномерные массивы, а затем распределять память для одномерных массивов.
double **a;
int n,m,i;
scanf("%d %d",&n,&m);
a=(double **)calloc(m, sizeof(double *));
for (i=0; i<m; i++)
a[i]=(double *)calloc(n, sizeof(double)); //получается дин. двум. массив m строчек n столбцов
Аналогичным обращом можно распределить память для трехмерного массива размером m, n, l.
main ()
{ long ***a;
int n, m, l, i, j;
scanf("%d %d %d", &m, &n, &l);
/* -------- распределение памяти -------- */
a=(long ***)calloc(m, sizeof(long **) );//выделение памяти на двум. массив указ. на указ.
for (i=0; i<m; i++) //на каждый из двумерных массивов выделяется память
{ a[i]=(long **)calloc(n, sizeof(long *) );
for (j=0; j<n; j++)
a[i][j]=(long *)calloc(l, sizeof(long) );
}
. . . . . . . . . . . .
/* --------- освобождение памяти ----------*/ //в обратном порядке
for (i=0; i<m; i++)
{ for (j=0; j<n; j++)
free (a[i][j]);
free (a[i]);
}
free (a);
}
Директивы препроцессора. Макроопределения.
Директивы препроцессора - инструкции, записанные в тексте программы на СИ, и выполняемые до трансляции программы. Программа, которая обрабатывает эти директивы, называется препроцессором (в современных компилято-рах препроцессор обычно является частью самого компилятора). Директивы препроцессора позволяют изменить текст программы, например, текст из другого файла и т.п. Все директивы препроцессора начинаются со знака #. После директив препроцессора точка с запятой не ставятся.
Директива #include включает в текст программы содержимое указанного файла. Эта директива имеет две формы: #include "имя файла" и #include <имя файла>
Имя файла должно соответствовать соглашениям операционной системы и может состоять либо только из имени файла, либо из пути и имени файла.
Если имя файла заключено в угловые скобки (<>), считается, что мы подключаем стандартный заголовочный файл.
Если имя файла заключено в “”, то заголовочный файл — пользовательский.
Директива #include широко используется для включения в программу так называемых заголовочных файлов, содержа-щих прототипы библиотечных функций, и поэтому большинство программ на СИ начинаются с этой директивы.
Директива #define служит для замены часто использующихся констант, ключевых слов, операторов или выражений некоторыми идентификаторами. Идентификаторы, заменяющие текстовые или числовые константы, называют именованными константами. Идентификаторы, заменяющие фрагменты программ, называют макроопределениями, причем макроопределения могут иметь аргументы. Директива #define имеет две синтаксические формы:
#define идентификатор текст и #define идентификатор (список параметров) текст
Эта директива заменяет все последующие вхождения идентификатора на текст. Такой процесс называется макроподстановкой. Текст может представлять собой любой фрагмент программы на СИ или отсутствовать. В последнем случае все экземпляры идентификатора удаляются из программы.
Пример: #define WIDTH 80 #define LENGTH (WIDTH+10)
Эти директивы изменят в тексте программы идентификатор WIDTH на число 80, а идентификатор LENGTH на выражение (80+10) вместе с окружающими его скобками.
Скобки, содержащиеся в макроопределении, позволяют избежать недоразумений, связанных с порядком вычисления операций. Например, при отсутствии скобок выражение t=LENGTH*7 будет преобразовано в выражение t=80+10*7, а не в выражение t=(80+10)*7, как это получается при наличии скобок, и в результате получится 780, а не 630.
Во второй синтаксической форме в директиве #define имеется список формальных параметров, который может содержать один или несколько идентификаторов, разделенных запятыми. Формальные параметры в тексте макроопределения отмечают позиции, на которые должны быть подставлены фактические аргументы макровызова.
При макровызове вслед за идентификатором записывается список фактических аргументов, количество которых должно совпадать с количеством формальных параметров. Пример: #define MAX(x,y) ((x)>(y))?(x):(y)
Эта директива заменит фрагмент t=MAX(i,s[i]); на фрагмент t=((i)>(s[i])?(i):(s[i]);
Как и в предыдущем примере, круглые скобки, в которые заключены формальные параметры макроопределения, позволяют избежать ошибок связанных с неправильным порядком выполнения операций, если фактические аргументы являются выражениями.
Например, при наличии скобок фрагмент t=MAX(i&j,s[i]||j); будет заменен на фрагмент t=((i&j)>(s[i]||j)?(i&j):(s[i]||j);
а при отсутствии скобок - на фрагмент t=(i&j>s[i]||j)?i&j:s[i]||j; в котором условное выражение вычисляется в совершенно другом порядке.Директива #undef используется для отмены действия директивы #define. Синтаксис этой директивы следующий #undef идентификатор
Директива отменяет действие текущего определения #define для указанного идентификатора. Пример: #undef MAX
Эти директивы отменяют определение именованной константы WIDTH и макроопределения MAX.
Условные директивы препроцессора.
Заголовочный файл также может содержать директивы #include. Поэтому некоторые заголовочные файлы могут оказаться включенными несколько раз. Избежать этого позволяют условные директивы препроцессора. Пример:
Д анный
проект состоит из трех файлов main.cpp —
основной, fm.h — содержащий прототип
функции fm (поиск минимума двух целых
чисел), fm.cpp — содержащий определение
функции fm.
анный
проект состоит из трех файлов main.cpp —
основной, fm.h — содержащий прототип
функции fm (поиск минимума двух целых
чисел), fm.cpp — содержащий определение
функции fm.
В файле fm.h условная директива #ifndef проверяет, не было ли значение __FM_H определено ранее. (__FM_H – это константа препроцессора; такие константы принято писать заглавными буквами.) Препроцессор обрабатывает следующие строки вплоть до директивы #endif. В противном случае он пропускает строки от #ifndef до #endif.
#if - условная директива, проверяющая один или несколько символов на получение значения true. При вычислении значения true компилятор вычисляет весь код межу #if и ближайшей директивой #endif.
#elif позволяет создать составную условную директиву
#else позволяет создать сложную условную директиву, так чтобы при отсутствии выражений в предшествующих директивах#if или (необязательно) #elif со значением true, компилятор анализировал весь код между #else и последующей директивой #endif.
19. Объектно-ориентированный подход к программированию. Классы.
Ключевыми понятиями в ООП являются объекты и классы.
В языке Си++ программист имеет возможность вводить собственные типы данных и определять операции над ними с помощью классов.
В определении нового типа основная идея — отделить несущественные подробности реализации (например, формат данных, которые используются для хранения объекта типа) от тех качеств, которые существенны для его правильного использования (например, полный список функций, которые имеют доступ к данным). Такое разделение
можно описать так, что работа со структурой данных и внутренними административными подпрограммами осуществляется через специальный интерфейс (канализуется).
Классы
Класс- произвольный структурированный тип, введенный программистом на основе уже существующих типов.
эти функции должны быть единственными для доступа к объектам.
Экземпляр класса или объект – переменная типа данного класса.
Класс можно определить с помощью конструкции: class имя_класса {список_компонентов};
где список_компонентов – определения и описания типизированных данных и принадледжащий к классу функций.
Обращаться к компонентам класса можно:
с помощью «квалификационных» имен: имя_объекта.имя_класса::имя_компонента или имя_объекта.имя_класса
Для функции: имя_объекта.обращение_к_компонентной _функции
с помощью явного использования указателя на объект класса в операции косвенного выбора компонента (->):
указатель_на_объект_класса -> имя_элемента
Инициализация статистического компонента:
тип имя_класса::имя_компонента инициализатор;
int goods::percent = 12;
Все компоненты класса называются членами класса, а приналежащие классу функции – методами класса (компонентными функциями).
В определение класса программа должна включать прототип функции, который указывает имя функции, тип возвращаемого значения и типы параметров.
Для определения функции вне определения класса ваша программа должна предварять определение функции именем класса и оператором глобального разрешения, как показано ниже:
class_name::function_name(parameters)
{ // Операторы }
Класс отличается от обычного структурного типа возможностью включения компонентных функций.
class date {
int month, day, year;
public:
void set(int, int, int);
void get(int*, int*, int*);
void next();
void print();
};
Метка public делит тело класса на две части. Имена в первой, закрытой части, могут использоваться только функциями членами. Вторая, открытая часть, составляет интерфейс к объекту класса. Struct — это просто class, у которого все члены общие, поэтому функции члены определяются и используются точно так же, как в предыдущем случае.
Однако функции не члены отгорожены от использования закрытых членов класса date.
Объектно-ориентированный подход к программированию. Инициализация и разрушение объектов. Конструкторы и деструкторы.
Инициализация
Для инифиализации объектов класса в его определение можно явно включать спец. компонентную функцию - конструктор. Конструктор имеет то же имя, что и сам класс.
Формат определения конструктора в теле класса может быть таким:
имя_класса(список_формальных_параметров) {операторы_тела_конструктора};
К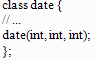 онструктор
автоматически вызывается
при создании объекта. Если для
конструктора нужны параметры, они
должны быть указаны:
онструктор
автоматически вызывается
при создании объекта. Если для
конструктора нужны параметры, они
должны быть указаны:
date today = date(23,6,1983);
date my_burthday; // недопустимо, опущена инициализация
Часто необходимо обеспечить несколько способов инициализации объекта класса. Это можно сделать, задав несколько конструкторов. Например:
Е сли
конструкторы существенно различаются
по типам своих параметров, то компилятор
при каждом использовании может выбрать
правильный:
сли
конструкторы существенно различаются
по типам своих параметров, то компилятор
при каждом использовании может выбрать
правильный:
date today(4);
date july4("Июль 4, 1983");
date guy("5 Ноя");
date now; // инициализируется по умолчанию
В данном примере можно сократить кол-во конструкторов используя параметры по умолчанию.
В
случае date для каждого параметра можно
задать значение по у молчанию,
интерпретируемое как «по умолчанию
принимать: today» (сегодня).
молчанию,
интерпретируемое как «по умолчанию
принимать: today» (сегодня).
В конструткоре необходимо провести проверку на правильность даты, и если она не правильная, можно инициалищировать сегодняшним или каким-либо константным выражением.
Объект класса без конструкторов можно инициализировать путем присваивания ему другого объекта этого класса. date a(1,1,2010); date b=a;
Это возможно, т.к. в объекте имеется неявный конструктор копирования по умолчанию. Он осуществляет побитовое копирование объекта. Для класса X его прототип выглядит так: X(X&).
Если он определен, то вызывается всякий раз, когда один объект инициализируется другим объектом того же класса.
Динамическое выделение памяти для объектов какого-либо класса создает необходимость в освобождении этой памяти при уничтожении объекта. Желательно, чтобы освобождение памяти происходило автоматически и не требовало вмешательства программистаю Такую возможность обеспечиват спец. компонент класса- деструктор. Его формат:
~имя_класса() {операторы_тела_деструктора};
У деструктора не может быть параметров и возвращаемого значения. Вызов деструктора выполняется автоматически,
как только объект класса уничтожается. При удалении объекта, все разрушительные действия должны выполняться в порядке, строго противоположном, порядку конструирования.
Например:
сlass stroka
{
private:
char *ch;; // указатель на текстовую строку
int len; // длина строки
public:
stroka(int N=80) // Конструктор класса stroka
{
ch = new char[N+1]; //выделяется память для массива
ch[0]=’\0’
}
;
~stroka() {delete []ch}; // Деструктор класса stroka
};
21. Объектно-ориентированный подход к программированию. Ограничения доступа к членам класса. Друзья класса.
Ограничение доступа к членам задается с помощью секций тела класса, помеченных ключевыми словами public, private и protected — спецификаторами доступа. Члены, объявленные в секции public, называются открытыми, а объявленные в секциях private и protected соответственно закрытыми или защищенными.
открытый член доступен из любого места программы. Класс, скрывающий информацию, оставляет открытыми только функции-члены, определяющие операции, с помощью которых внешняя программа может манипулировать его объектами;
закрытый член доступен только функциям-членам и друзьям класса. Класс, который хочет скрыть информацию, объявляет свои данные-члены закрытыми;
защищенный член ведет себя как открытый по отношению к производному классу и как закрытый по отношению к остальной части программы.
В теле класса может быть несколько секций public, protected и private. Каждая секция продолжается либо до метки следующей секции, либо до закрывающей фигурной скобки. Если спецификатор доступа не указан, то секция, непосредственно следующая за открывающей скобкой, по умолчанию считается private.
Друзья
Предположим, вы определили два класса, vector и matrix (вектор и матрица). Каждый скрывает свое представление и предоставляет полный набор действий для манипуляции объектами его типа. Теперь определим функцию, умножающую матрицу на вектор.
Для простоты допустим, что в векторе четыре элемента, которые индексируются 0...3, и что матрица состоит из четырех векторов, индексированных 0...3. Допустим также, что доступ к элементам вектора осуществляется через функцию elem(), которая осуществляет проверку индекса, и что в matrix имеется аналогичная функция. Один подход состоит в определении глобальной функции multiply() (перемножить) примерно следующим образом:
vector multiply(matrix& m, vector& v);
{
vector r;
for (int i = 0; i<3; i++) { // r[i] = m[i] * v;
r.elem(i) = 0;
for (int j = 0; j<3; j++)
r.elem(i) += m.elem(i,j) * v.elem(j);
}
return r;
}
Это своего рода «естественный» способ, но он очень неэффективен. При каждом обращении к multiply() elem() будет вызываться 4*(1+4*3) раза. Теперь, если мы сделаем multiply() членом класса vector, мы сможем обойтись без проверки индексов при обращении к элементу вектора, а если мы сделаем multiply() членом класса matrix, то мы сможем обойтись без проверки индексов при обращении к элементу матрицы. Однако членом двух классов функция быть не может. Нам нужно средство языка, предоставляющее функции право доступа к закрытой части класса. Функция не член, получившая право доступа к закрытой части класса, называется другом класса (friend). Функция становится другом класса после описания как friend. Например:
class vector {
float v[4];
// ...
friend vector multiply(matrix&, vector&);
};
112
112
class matrix {
vector v[4];
// ...
friend vector multiply(matrix&, vector&);
};
Функция друг не имеет никаких особенностей, помимо права доступа к закрытой части класса. В частности, friend функция не имеет указателя this (если только она не является полноправным членом функцией). Описание friend — настоящее описание. Оно вводит имя функции в самой внешней области видимости программы и сопоставляется с
другими описаниями этого имени. Описание друга может располагаться или в закрытой, или в открытой части описания класса; где именно, значения не имеет.
Теперь можно написать функцию умножения, которая использует элементы векторов и матрицы непосредственно:
vector multiply(matrix& m, vector& v);
{ vector r;
for (int i = 0; i<3; i++) { // r[i] = m[i] * v;
r.v[i] = 0;
for (int j = 0; j<3; j++)
r.v[i] += m.v[i][j] * v.v[j];}
return r;
}
Объектно-ориентированный подход к программированию. Наследование.
Наследование — один из основополагающих принципов объектно-ориентированного программирования. Под наследованием понимают возможность объявления производных типов на основе ранее объявленных типов.
Прежде всего, следует различать наследование и встраивание. Встраивание предполагает возможность объявления в классе отдельных членов класса на основе ранее объявленных классов. В классе можно объявлять как данные-члены основных типов, так и данные-члены ранее объявленных производных типов.
В случае же наследования новый класс в буквальном смысле создается на основе ранее объявленного класса, НАСЛЕДУЕТ, а возможно и модифицирует его данные и функции. Объявленный класс может служить основой (базовым классом) для новых производных классов. Производный класс наследуют данные и функции своих базовых классов и добавляют собственные компоненты.
В C++ количество непосредственных «предков»
производного класса не ограничено.
Класс может быть порожден от одного
или более классов. В последнем случае
говорят о множественном наследовании.
Наследование в C++ реализовано таким
образом, что наследуемые компоненты
не перемещаются в производный класс,
а остаются в базовом
C++ количество непосредственных «предков»
производного класса не ограничено.
Класс может быть порожден от одного
или более классов. В последнем случае
говорят о множественном наследовании.
Наследование в C++ реализовано таким
образом, что наследуемые компоненты
не перемещаются в производный класс,
а остаются в базовом
классе. Производный класс может переопределять и доопределять функции-члены базовых классов.
class A{ //базовый класс
};
class B : public A{ //public наследование
}
Перед нами пример простого наследования., т.е каждый производный класс при объявлении наследует свойства лишь одного базового класса. Слово public перед именем базового класса означает, что все поля и методы класса-родителя, объявленные как public или protected, в производном классе будут открыты. Если public отсутствует, то все члены класса-родителя в производном классе закрыты.
В C++ различаются непосредственные и косвенные базовые классы. //Непосредственный базовый класс упоминается в списке баз производного класса. Косвенным базовым классом для производного класса считается класс, который является базовым классом для одного из классов, упомянутых в списке баз данного производного класса.
Так для класса C непосредственным базовым классом является B, косвенным — A.
Объявление C MyObj приводит к созданию объекта сложной структуры, собранного на основе нескольких классов. Вначале вызываются конструкторы базовых классов, т.е при выполнении этой строки происходит вывод A,B,C. Следом вызываются конструкторы производных классов.
О бъект
имеет возможность обращаться к
компонентам своим, а также прямых и
косвенных базовых классов.
бъект
имеет возможность обращаться к
компонентам своим, а также прямых и
косвенных базовых классов.
При разрушении объекта деструкторы вызываются в обратном порядке: ~C~B~A
Частичное разрушение объекта не разрешается, т.е. базовые деструкторы не наследуются.
Запись MyObj.~B(); невозможна.
Поля, методы |
A |
B |
C |
x0 |
одинаково |
||
x1 |
------------ |
новая |
новая |
x2 |
------------ |
новая |
новая |
x3 |
------------ |
------------ |
|
f0 |
одинаково |
||
f1 |
------------ |
новая |
новая |
f2 |
------------ |
та же |
|
f3 |
------------ |
------------ |
новая |
xx |
------------ |
та же |
|
//В дополнение к общим (public) (доступным всем) и частным (private) (доступным методам класса) элементам C++ предоставляет защищенные (protected) элементы, которые доступны базовому и производному классам.
Для разрешения конфликта имен между элементами базового и производного классов ваша программа может использовать оператор глобального разрешения, указывая перед ним имя базового или производного класса.
23. Перегрузка операций.
Программист может определять смысл операций при их применении к объектам определенного класса. Кроме арифметических, можно определять еще и логические операции, операции сравнения, вызова () и индексирования [], а также можно переопределять присваивание и инициализацию. Можно определить явное и неявное преобразование
между определяемыми пользователем и основными типами.
Классы дают средство спецификации в C++ представления неэлементарных объектов вместе с множеством действий, которые могут над этими объектами выполняться. Иногда определение того, как действуют операции на объекты классов, позволяет программисту обеспечить более общепринятую и удобную запись для манипуляции объектами классов, чем та, которую можно достичь используя лишь основную функциональную запись. Например:
о пределяет
простую реализацию понятия комплексного
числа, в которой число представляется
парой чисел с плавающей точкой двойной
точности, работа с которыми осуществляется
посредством операций + и * (и только).
Программист задает смысл операций + и
* с помощью определения функций с именами
operator+
и operator*.
Если, например, даны b
и c
типа complex,
то b+c
означает (по определению) operator+(b,c).
пределяет
простую реализацию понятия комплексного
числа, в которой число представляется
парой чисел с плавающей точкой двойной
точности, работа с которыми осуществляется
посредством операций + и * (и только).
Программист задает смысл операций + и
* с помощью определения функций с именами
operator+
и operator*.
Если, например, даны b
и c
типа complex,
то b+c
означает (по определению) operator+(b,c).
Теперь есть возможность приблизить общепринятую интерпретацию комплексных выражений. Например:
complex a = complex(1, 3.1);
complex b = complex(1.2, 2);
118
118
complex c = b;
a = b+c;
b = b+c*a;
c = a*b+complex(1,2);
Выполняются обычные правила приоритетов, поэтому второй оператор означает
b=b+(c*a), а не b=(b+c)*a.
Можно описывать функции, определяющие значения следующих операций: + - * / % ^ & | ~ ! = < > += -= *= /= %= ^= &= |= << >> >>= <<= == != <= >= && || ++ -- [] () new delete
Изменить приоритеты перечисленных операций невозможно, как невозможно изменить
и синтаксис выражений. Нельзя, например, определить унарную операцию % или бинарную !. Невозможно определить новые лексические символы операций. Имя функции операции есть ключевое слово operator (то есть, операция), за которым следует сама операция, например, operator<<. Функция операция описывается и может вызываться так же, как любая другая функция. Использование операции — это лишь сокращенная запись явного вызова функции операции. Например:
complex c = a + b; // сокращенная запись
complex d = operator+(a,b); // явный вызов
При наличии предыдущего описания complex оба инициализатора являются синонимами.
Бинарная операция может быть определена или как функция член, получающая один параметр, или как функция друг, получающая два параметра. Таким образом, для любой бинарной операции @ aa@bb может интерпретироваться или как aa.operator@(bb), или как operator@(aa,bb). Если определены обе, то aa@bb является ошибкой. Унарная операция, префиксная или постфиксная, может быть определена или как функция член, не получающая параметров, или как функция друг, получающая один параметр. Таким образом, для любой унарной операции @ aa@ или @aa может интерпретироваться или как aa.operator@(), или как operator@(aa). Если определено и то, и другое, то и aa@ и
@aa являются ошибками. Рассмотрим следующие примеры:
К огда
операции ++ и -- перегружены, префиксное
использование и постфиксное различить
невозможно.
огда
операции ++ и -- перегружены, префиксное
использование и постфиксное различить
невозможно.
Организация ввода-вывода на языке С++. Потоки ввода-вывода.
Поток - посл-ть байтов(символов) и с точки зрения программы не зависит от тех конкретных устройств(клавиатура), с которыми ведется обмен данными. В буфер потока помещаются выводимые программой данные перед тем, как они будут переданы внешнему устройству. При воде данных они сначала помещаются в буфер и только затем передаются в область памяти выполняемой программы. Различают потоки:
входные, с которых читается информация;
выходные, в которые вводятся данные;
двунаправленные, допускающие как чтение, так и запись.
При использовании потоков ввода/вывода можно перегружать операторы >> и <<, определяя формат вывода для собственных типов. Кроме того, нет нужды заботиться о должном формате ввода и вывода для каждого объекта.
//Потоки обеспечивают:
буферизацию при обменах с внешними устройствами;
независимость программы от файловой системы конкретной ОС;
контроль типов передаваемых данных;
возможность удобного обмена для типов, определенных пользователем.
Стандартный ввод/вывод
С++ предоставляет четыре предварительно определенных потоковых объекта:
cin стандартный ввод;
cout стандартный вывод;
cerr стандартный вывод ошибок;
clog полностью буферизованная версия cerr;
Есть возможность перенаправить эти стандартные потоки из и на другие устройства и файлы.
Необходимо подключить заголовочный файл iostream, в котором и содержатся стандартные потоки ввода/вывода: #include<iostream>.
Оператор поразрядного сдвига влево <<, применительно к операциям с потоками, называется оператором вставки или оператором «поместить в», а оператор поразрядного сдвига вправо >> — называется оператором извлечения или оператором «прочитать из».
Класс istream включает перекрываемые определения для оператора >>, используемого со стандартными типами [int, long, double, float, char*(строка)]. Таким образом, предложение cin >> x; вызывает соответствующую функцию оператора >> для istream cin, определенного в iostream.h и использует ее для направления этого входного потока в
позицию памяти, представляемую переменной х. Аналогично, класс ostream имеет перекрываемые определения для оператора <<, который разрешает с помощью предложения cout << x; посылать значение x в ostream cout для вывода.
Эти функции оператора возвращают ссылку на соответствующий классовый тип потока (например, ostream&) наряду с перемещением данных. Это позволяет расположить в цепочку несколько таких операторов для ввода и вывода последовательности символов:
int i=0, x=243; double d=0;
cout << "Значение x равно " << x << '\n';
cin >> i >> d; //ввод с клавиатуры int, пробел, затем double
Вторая строка будет выводить на дисплей: «Значение x равно 243», а затем будет идти новая строка. Следующее пред-ложение будет игнорировать пробел, читать и преобразовывать клавишные символы в целое число и помещать его в i, игнорировать следующий пробел, читать и преобразовывать следующие клавишные символы в double и помещать их в d.
Ввод/вывод для типов данных, определенных пользователем
Реальное преимущество потоков С++ заключается в легкости, с которой можно совместить >> и << для управления вводом/выводом пользовательских типов данных. Рассмотрим простую структуру данных, которую можно объявить:
Ч тобы
совместить << для вывода объектов
типа emp,
необходимо следующее определение:
тобы
совместить << для вывода объектов
типа emp,
необходимо следующее определение:
ostream& operator << (ostream& str, emp& e)
{
str << setw(25) << e.name << ": Отдел " << setw(6) << e.dept << tab <<
"З.П. " << e.sales << " р." << '\n';
return str;
}
Функция-оператор << должна возвращать ostream&, ссылку на ostream, так что можно подсоединить новую функцию << подобно предварительно определенному оператору вставки. Теперь можно вывести объекты типа emp следующим образом:
#include <iostream.h>
#include <iomanip.h>
...
emp jones = {"Иванов", 25, 1000};
cout << jones;
получив вывод на дисплей
Иванов: Отдел 25 З.П. 1000 р.
Манипулятор tab в определении << определен пользователем:
ostream& tab(ostream& str)
{
return str << '\t';}
Шаблоны функций.
Цель введения шаблонов функций – автоматизация создания функций, которые могут обрабатывать разнотипные данные. Шаблон функции определяется один раз, но это определение параметризуется. При задании конкретного типа данных строится специальная синтаксическая конструкция, называемая списком параметров шаблона функции. Объявление функции, которому предшествует список параметров
шаблона, называется шаблоном функции.
Объявление и определение шаблона функции начинается ключевым словом template, за которым следует заключенный в угловые скобки и разделенный запятыми непустой список параметров шаблона. Эта часть объявления или определения обычно называется заголовком шаблона. Каждый параметр шаблона состоит из служебного слова class, за которым следует уникальный идентификатор.
template <список_параметров_шаблона>
Следом за заголовком шаблона располагается прототип или определение функции. Все идентификаторы из заголовка шаблона обязаны входить в список параметров функции и играть роль спецификаторов типа. Объявления параметров, у которых в качестве спецификатора типа используется идентификатор из списка параметров шаблона, называется шаблонным параметром. Наряду с шаблонными параметрами в список параметров функции могут также входить параметры основных и производных типов.
Шаблон функции служит инструкцией для транслятора. По этой инструкции транслятор изменяет исходный текст подпрограммы, генерируя нужное количество функций, отличающиеся лишь типами данных.
Видимость параметров шаблона ограничивается шаблонной функцией.
template <class Type>
Type minimum (Type a, Type b)
{return a<b?a:b;}
Имя параметра шаблона в определяемой функции используется в качестве имени типа. С его помощью специализируются формальные параметры и тип возвращаемого значения. Если в глобальной области видимости существуют объекты с тем же именем, что и параметр шаблона, то эти объекты скрываются.
Шаблоны классов.
Шаблоны, которые называют параметризированными типами, позволяют создавать семейства родственных функций и классов.
template <список_параметров_шаблона> определение_класса
Имя класса, входящего в шаблон, не является именем отдельного класса, а параметризированным именем семейства классов.
Предположим, что нам нужно определить класс, поддерживающий механизм очереди.
Очередь – это структура данных для хранения коллекции объектов; они помещаются в
конец очереди, а извлекаются из ее начала. Поведение очереди описывают аббревиату-
рой FIFO — «первым пришел, первым ушел».
Тогда объявление класса Queue будет выглядеть примерно так:
В опрос
в том, какой тип использовать вместо
Type? Предположим, что мы решили реа-
опрос
в том, какой тип использовать вместо
Type? Предположим, что мы решили реа-
лизовать класс Queue, заменив Type на int. Тогда Queue может управлять коллекциями
объектов типа int. Если бы понадобилось поместить в очередь объект другого типа, то
е го
пришлось бы преобразовать в тип int, если
же это невозможно, компилятор выдаст
го
пришлось бы преобразовать в тип int, если
же это невозможно, компилятор выдаст
сообщение об ошибке.
Конечно, эту проблему можно решить, создав копию класса Queue для работы с типом
double, затем для работы с комплексными числами, затем со строками и т.д. А поскольку
имена классов перегружать нельзя, каждой реализации придется дать уникальное имя:
IntQueue, DoubleQueue, ComplexQueue, StringQueue. При необходимости работать с другим
классом придется снова копировать, модифицировать и переименовывать.
Механизм шаблонов C++ позволяет автоматически генерировать такие типы. Шаблон
класса можно использовать при создании Queue для очереди объектов любого типа. Оп-
ределение шаблона этого класса могло бы выглядеть следующим образом:
Чтобы создать классы Queue, способные хранить целые числа, комплексные числа и
строки, программисту достаточно написать:
Queue<int> qi;
Queue<complex> qc;
Queue<string> qs;
Пример: Реализация шаблона класса CStack — стек на основе динамического массива.
// Файл CStack.h
#ifndef _CStack_H
#define _CStack_H
#include <iostream.h>
#include <stdlib.h>
template <class Type>
class CStack {
private:
Type *data;//Массив для хранения стека
int top; //Индекс вершины стека
int size; //Макс. размер стека
public:
CStack(int); //Конструктор – передается максимальное количество элементов
~CStack() {free(data);}
void push(Type); //Добавление эл-та
int pop(Type &); //Выталкивание эл-та. Возвращает 0, если стек пуст
int isempty() {return !top;}
void print(); //Вывод содержимого стека
};
template <class Type>
CStack<Type>::CStack(int sz)
{
data=(Type*) calloc(sz, sizeof(Type));
top=0;
size=sz;
}
template <class Type>
void CStack<Type>::push(Type Item)
{
if (top==size)
{ //Если массив заполнен - расширить
size+=8;
data=(Type*)realloc(data, size*sizeof(Type));
}
data[top++]=Item;
}
template <class Type>
int CStack<Type>::pop(Type &Item)
{
if (!isempty())
{
Item=data[--top];
return 1;
}
else return 0;
}
template <class Type>
void CStack<Type>::print()
{
for (int i=top-1; i>=0; i--)
cout << data[i] << ' ' ;
cout << endl ;
}
#endif
//Тестирующая программа
#include <stdio.h>
#include <math.h>
#include "CStack.h"
int main(int argc, char* argv[])
{
printf("Int\n");
CStack <int> ti(2);
for (int i=0; i<4; i++)
ti.push(i);
ti.print();
int k;
for (int i=0; i<7; i++)
if (ti.pop(k)) printf("%d\n",k);
else printf("Empty\n");
printf("Double\n");
CStack <double> td(2);
for (int i=10; i<14; i++)
td.push(sqrt((double)i));
td.print();
double f;
for (int i=0; i<7; i++)
if (td.pop(f)) printf("%lf\n",f);
else printf("Empty\n");
getchar();
return 0;
}
Результаты работы программы:
Int
3 2 1 0
3
2
1
0
Empty
Empty
Empty
Double
3.60555 3.4641 3.31662 3.16228
3.605551
3.464102
3.316625
3.162278
Empty
Empty
Empty
Библиотека STL. Другие библиотеки контейнерных классов.
Четыре основных компонента составляют структуру STL(Standard Template Library):
· итераторы — специальные указатели, позволяющие алгоритмам перемещаться по данным контейнера;
· алгоритмы — вычислительные процедуры;
· контейнеры — блоки хранения данных и управления ими;
· функциональные объекты — объекты, содержащие функции для исп-я другими объектами.
Итераторы
Итератор — это некий обобщенный указатель. Обычные указатели языка Cи++ являются частным случаем итераторов. Любой алгоритм , принимая в качестве параметров итераторы, при их обработке не задумывается о типе данных, на которые итераторы ссылаются.
Итераторы бывают пяти видов:
· входные (input) - для чтения адресуемых данных;
· выходные (output) – для записи адресуемых данных;
· однонаправленные (forward) - обладают всеми свойствами входных и выходных, а также могут перемещаться от начала последовательности адресуемых данных в конец;
· двунаправленные (bidirectional) -способны перемещаться в любом направлении по цепочке данных: как вперед, так и назад;
· произвольного доступа (random access) – содержат функции всех четырех других итераторов.
Библиотека STL построена так, что итератор более старшего типа может быть подставлен вместо младшего.
Алгоритмы
Это группа функций, выполняющих некоторые стандартные действия, например поиск, преобразование, сортировку, копирование и т. д.. Параметрами для алгоритмов обычно служат итераторы.
Алгоритм equal: сравнивает две цепочки данных, адресуемых входными итераторами:
template <class InputIterator1, class InputIterator2>
bool equal(InputIterator1 first1, InputIterator1 last1, InputIterator2 first2);
Первый параметр first1 — входной итератор, указывающий на первую цепочку сравниваемых данных. last1 адресует индикатор конца диапазона данных. first2— вторая цепочка сравниваемых данных.
Контейнеры
Контейнеры — это объекты, хранящие в себе другие объекты. В STL таких контейнеров десять:
vector — массив с произвольным доступом, чаще всего применяемый в тех случаях, когда надо последовательно добавлять данные в конец цепочки;
list — список;
queue — очередь;
stack — стек;
deque — двусторонняя очередь;
priority queue — приоритетная очередь.
set — набор уникальных элементов, отсортированных в определенном порядке (множество);
multiset — множество, которое может содержать повторяющиеся копии;
map — обеспечивает доступ к значениям по ключам;
multimap — то же, что и map, но допускающий повторяющиеся ключи;
Функциональные объекты
Функциональные объекты — это объекты, у которых задан перегруженный оператор вызова функции "operator ()()".
Функциональными объектами являются все арифметические операторы: сложения (plus), вычитания (addition), умножения (times), деления (divides), взятия остатка (modulus) и обращения знака (negate). Имеются функциональные объекты для вычисления равенства (equal_to), неравенства (not_equal_to), операции "больше" (greater), операции "меньше" (less), операции "больше или равно" (greater_equal), операции "меньше или равно" (less_equal). Для логических операторов имеются свои функциональные объекты: логическое "и" (logical_and), логическое "или" (logical_or) и логическое "не" (logical_not).
Обработка исключительных ситуаций.
Существует категория ошибок, которые не способны выявить препроцессоры, трансляторы и программы сборки. К их числу относятся так называемые ошибки времени выполнения. Эти ошибки проявляются в ходе выполнения программы.
Ошибки времени выполнения, возникающие непосредственно в ходе выполнения программы, в терминах объектно-ориентированного программирования называются исключительными ситуациями. Исключительные ситуации — это события, которые прерывают нормальный ход выполнения программы.
Различают синхронные и асинхронные исключительные ситуации.
Синхронная ИС возникает непосредственно в ходе выполнения программы, ее причина заключается непосредственно в действиях, выполняемых самой программой (деление на нуль, невозможность преобразования типа, работа с индексами и адресами).
Асинхронные ИС непосредственно не связаны с выполнением программы. Их причинами могут служить аппаратно возбуждаемые прерывания (например, сигналы от таймера), сообщения, поступающие от внешних устройств или да-
же от локальной сети.
Реакция на исключительную ситуацию называется исключением.
Заметим, что ИС можно предусмотреть заранее.
Например, функция записывает значения в массив по заданному индексу и возвращает единицу в случае успешного размещения значения и нуль в случае недопустимого индекса.
Существует целый ряд проблем, связанных с подобным способом организации программного кода.
Структура вызывающей функции определяется множеством значений, которые может возвратить вызываемая функция. Каждое возвращаемое значение, как правило, сопровождается определенной реакцией.
В случае большого кол-ва вариантов возвращаемых значений:
размер кода обработки становится слишком большим и закрывает основную логику программы;
конструктор и деструктор не возвращают никаких значений, поэтому о своих проблемах стандартным образом сообщить не могут.
В C++ имеются встроенные средства для их возбуждения и обработки. Они обеспечивают механизм, позволяющий двум несвязанным фрагментам программы обмениваться информацией об исключении.
При возникновении ИС, та часть программы, которая ее обнаружила, может сгенерировать, или возбудить, исключение.Для этого используется операция throw. Выполнение за пределами контролируемого блока приводит к завершению работы программы.
Операция throw может иметь аргумент, которым является выражение произвольного типа.
Операцию throw вместе с аргументом называют генератором операции исключения. А его
место расположения в программе - точкой генерации. throw NULL;
Обычно генератор исключения используется в сочетании с try-блоком (контролируемым блоком). Их взаимодействие обеспечивается через стек вызова. Поэтому контролируемый блок располагают в вызывающей функции, а точка генерации исключения должна располагаться в теле функции, непосредственно или косвенно вызываемой из множества операторов данного try-блока.
try
{
Оператор;
Оператор;
}
СписокРеакций
Список операторов в {} представляет собой критический код, выполнение которого может привести к возникновению ошибки времени выполнения.
Далее следует список реакций со блоками перехвата. Каждый блок перехвата начинается с ключевого слова catch, за ко-
торым в круглых скобках следует объявление ситуации. Синтаксис объявления
ситуации напоминает объявление параметра в прототипе функции.
Catch-блок содержит код обработки данной ситуации.
catch ( объявление)
{
обработка;
}
Catch-блок вида catch(…) перехватывает все, ранее не перехваченные исключения.
catch (...)
{
cout<<"unknown exception"<<endl;
}