

Алгоритм "1‑правило" построения правил классификации.
Рассмотрим простейший алгоритм формирования правил для классификации объектов. Алгоритм строит правила по значению одной независимой переменной, поэтому в литературе его часто называют "1‑правило" (1-rule) или кратко 1R-алгоритм
Идея алгоритма очень проста. Для любого возможного значения каждой независимой переменной формируется правило, которое классифицирует объекты из обучающей выборки. При этом в заключительной части правила указывается значение зависимой переменной, которое наиболее часто встречается у объектов с выбранным значением независимой переменной. В этом случае ошибкой правила является частота встречаемости в обучающей выборке объектов, имеющих то же значение рассматриваемой переменной, но не относящихся к выбранному классу. Таким образом, для каждого значения независимой переменной будет получено правило. Оценив степень ошибки каждого правила, выбираются правила с наименьшей ошибкой.
Последнее правило интуитивно выглядит странно, но следует из табл. 4.9.
Проблемой для рассматриваемого алгоритма являются численные значения переменных. Очевидно, что если переменная имеет вещественный тип, то количество возможных значений может быть бесконечно. Для решения этой проблемы используют квантование, т. е. всю область значений такой переменной разбивают на интервалы таким образом, чтобы каждый из них соответствовал определенному классу в обучающей выборке. В результате будет получен набор дискретных значений, с которыми может работать данный алгоритм.
В заключение отметим, что алгоритм 1R, несмотря на свою простоту, во многих случаях на практике оказывается достаточно эффективным. Это объясняется тем, что многие объекты действительно можно классифицировать лишь по одному атрибуту. Кроме того, немногочисленность формируемых правил позволяет легко понять и использовать полученные результаты.
Байесовская классификация. "Наивно"-байесовский подход.
Сначала вспомним теорему Байеса (Thomas Bayes)
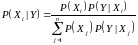 . 101\* MERGEFORMAT (.)
. 101\* MERGEFORMAT (.)
Формула 01 означает,
что известна априорная
(известная до опыта) вероятность
 .
Произведен опыт, в результате которого
наблюдалось событие
.
Произведен опыт, в результате которого
наблюдалось событие
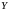 .
Апостериорная
(после опыта) вероятность
.
Апостериорная
(после опыта) вероятность
 показывает, как изменилась вероятность
события
показывает, как изменилась вероятность
события
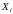 в связи с появлением события
.
Вероятность
в связи с появлением события
.
Вероятность
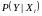 иногда называют правдоподобием
при заданном
.
Апостериорная вероятность события
прямо пропорциональна его правдоподобию.
Вероятность
иногда называют правдоподобием
при заданном
.
Апостериорная вероятность события
прямо пропорциональна его правдоподобию.
Вероятность
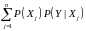 играет роль нормировочной константы.
играет роль нормировочной константы.
Поясним смысл
апостериорной вероятности
в контексте задачи классификации. Пусть
имеется некоторое множество гипотез
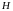 о
принадлежности объектов некоторым
классам и множество данных
о
принадлежности объектов некоторым
классам и множество данных
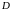 для обучения. Цель классификации –
найти гипотезу, которая была бы наиболее
вероятной при имеющихся данных.
Математически это формулируется
следующим образом. Гипотеза
для обучения. Цель классификации –
найти гипотезу, которая была бы наиболее
вероятной при имеющихся данных.
Математически это формулируется
следующим образом. Гипотеза
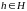 называется максимальной
апостериорной гипотезой
(MAP
– maximum
a
posteriori
hypothesis),
если
называется максимальной
апостериорной гипотезой
(MAP
– maximum
a
posteriori
hypothesis),
если
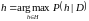 ,
202\* MERGEFORMAT (.)
,
202\* MERGEFORMAT (.)
т. е.
является аргументом, при котором
 достигает максимум.
достигает максимум.
Перепишем 02 по теореме Байеса
 ,
303\* MERGEFORMAT (.)
,
303\* MERGEFORMAT (.)
потому
что
 не зависит от
не зависит от
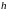 .
.
Оценить вероятность
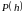 по обучающей выборке несложно. Оценить
вероятность
по обучающей выборке несложно. Оценить
вероятность
 очень сложно, так как потребуется каждую
из возможных комбинаций атрибутов
пронаблюдать несколько раз. Проблема
решается при использовании наивного
байесовского алгоритма
(Naive
Bayes)
[4]. Название
naive
(наивный) происходит от упрощающего
предположения, что все
рассматриваемые переменные независимы
друг от друга.
В действительности это не всегда так,
но данный алгоритм показывает
неплохие практические результаты даже
при несоблюдении условия статистической
независимости.
очень сложно, так как потребуется каждую
из возможных комбинаций атрибутов
пронаблюдать несколько раз. Проблема
решается при использовании наивного
байесовского алгоритма
(Naive
Bayes)
[4]. Название
naive
(наивный) происходит от упрощающего
предположения, что все
рассматриваемые переменные независимы
друг от друга.
В действительности это не всегда так,
но данный алгоритм показывает
неплохие практические результаты даже
при несоблюдении условия статистической
независимости.
Вероятность
того, что некоторый объект относится к
классу
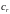 (т. е.
(т. е.
 ),
обозначим
как
),
обозначим
как
 .
Событие,
соответствующее равенству независимых
переменных определенным значениям,
обозначим как
.
Событие,
соответствующее равенству независимых
переменных определенным значениям,
обозначим как
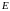 ,
а
вероятность его наступления обозначим
как
,
а
вероятность его наступления обозначим
как
 .
Идея
алгоритма заключается в расчете условной
вероятности
.
Идея
алгоритма заключается в расчете условной
вероятности
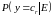 принадлежности объекта к
при
равенстве его независимых переменных
определенным значениям
.
Эту вероятность можно вычислить по
формуле
Байеса
принадлежности объекта к
при
равенстве его независимых переменных
определенным значениям
.
Эту вероятность можно вычислить по
формуле
Байеса
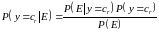 , 404\* MERGEFORMAT (.)
, 404\* MERGEFORMAT (.)
где
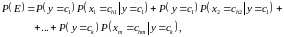 505\* MERGEFORMAT (.)
505\* MERGEFORMAT (.)
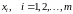 – независимые
переменные,
– независимые
переменные,
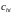 – значения независимых переменных.
– значения независимых переменных.
Предполагая,
что независимые переменные принимают
значения независимо друг от друга,
выразим вероятность
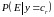 через произведение вероятностей для
каждой независимой переменной
через произведение вероятностей для
каждой независимой переменной
 606\* MERGEFORMAT (.)
606\* MERGEFORMAT (.)
В
06 в качестве примера взяты значения:
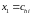 ,
,
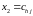 ,
…
,
…
По определению условной вероятности
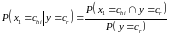 , 707\* MERGEFORMAT (.)
, 707\* MERGEFORMAT (.)
где
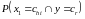 – вероятность того, что одновременно
и
.
– вероятность того, что одновременно
и
.
Тогда
вероятности вида
 можно оценить как отношение количества
объектов в обучающей выборке, у которых
можно оценить как отношение количества
объектов в обучающей выборке, у которых
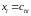 и одновременно
к количеству объектов, относящихся
к классу
(для оценки вероятностей, входящих в
формулу 07, необходимо разделить
указанные количества на число элементов
в выборке, которое при подстановке в
07 сократиться).
и одновременно
к количеству объектов, относящихся
к классу
(для оценки вероятностей, входящих в
формулу 07, необходимо разделить
указанные количества на число элементов
в выборке, которое при подстановке в
07 сократиться).
Если независимые переменные имеют вещественный тип, то используется квантование.
28.Понятие дерева решений
Деревья решений (decision trees) – это способ представления правил в иерархической, последовательной структуре. Обычно каждый узел дерева включает проверку одного атрибута (независимой переменной). Иногда в узле две независимые переменные сравниваются друг с другом или вычисляется некоторая функция от одной или нескольких переменных.
Если в узле проверяется категориальная переменная (принимающая качественные значения), то каждому возможному значению переменной соответствует ветвь, выходящая из узла. Если проверяется числовая переменная, то проверяется, больше или меньше это значение некоторой константы. Можно применить квантование числовой переменной (разбить область числовой переменной на несколько интервалов) и проверять попадание числовой переменной в один из интервалов.
Листья (конечные узлы дерева) соответствуют зависимой переменной, т. е. классам. Объект принадлежит определенному классу, если значения его независимых переменных удовлетворяют условиям, записанным в узлах дерева на пути от корня к листу, соответствующему этому классу.
Введем некоторые понятия из теории деревьев решений [1, 4]. Дерево – граф, в котором нет циклов даже без учета направления ребер. Объект – пример, шаблон, наблюдение. Атрибут – признак, независимая переменная, свойство. Метка класса – зависимая переменная, целевая переменная, признак, определяющий класс объекта. Узел – внутренний узел дерева, узел проверки. Лист – конечный узел дерева, узел решения. Проверка – условие в узле. Правило – логическая конструкция, представленная в виде "если … то …".
Структура дерева решений показана на рис. 4.7.
