

Реляционной.
Relation – отношения (таблицы). Понятие реляционной модели связано с разработками известного американского специалиста в области СУБД Эдварда Кодда.
Достоинства:
Простая структура;
Данные связаны логически;
Группа записей обрабатывается одной командой;
Удобные для пользователя таблицы представления;
Возможность использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Недостатки:
Не всегда применима для сложных иерархических и сетевых данных.
Также БД классифицируются по способу обработки данных: централизованные и распределённые. Централизованные – на одном компьютере. Распределённые – части на разных компьютерах. По способу доступа к данным: с локальным доступом и с сетевым или удалённым доступом.
Структуры хранения в базе данных Таблицы и индексы баз данных обычно хранятся на жестком диске в одной из многочисленных форм, в пронумерованных / ненумерованных ненумерованных Flat-файлах, ISAM, «Кучах», Hash-корзинах или B+ деревьях. Они имеют разные преимущества и недостатки.
По признаку метода доступа БД делятся на локальные, сетевые и распределённые. К локальным базам доступа возможен только с того компьютера на котором они расположены. Сетевые базы призваны обеспечить работу с данными с других компьютеров по средствам локальной сети или Интернета. Распределённые БД - это, по сути, подвиг сетевых баз с той лишь разницей, что различные части информации находятся на множестве разных компьютерах.
9. Последовательный файл, файл с указателем, индексирование по одному элементу.
Последовательные файлы — файлы, хранящие информацию в неструктурированном (для поиска и обращения) виде. Поиск в таких файлах осуществляется последовательным считыванием файла с начала и сравнением "всего" с искомым. Так же и обращение к определённому участку файла каждый раз требует "чтения с начала".
Примером последовательных файлов являются текстовые файлы (*.txt)
Последовательные файлы выигрывают у файлов с произвольным доступом по компактности, но проигрывают по скорости доступа.
Файлы с произвольным доступом — файлы, хранящие информацию в структурированном (для поиска и обращения) виде. Поиск в таких файлах осуществляется в области адресов (ключей) и завершается обращением непосредственно к искомому участку. Дисковое пространство, занимаемое таким файлом, поделено на одинаковые участки (записи), имеющие одинаковую структуру полей. Так, под первое поле каждой записи может быть отведено 128 бит, а под второе 1024 бита. И это место в файле будет выделено под эти поля каждой записи независимо от наличия и объёма данных в этих полях.
Примером файлов с произвольным доступом могут служить файлы DBF (*.dbf)
10. Инвертированная организация файлов.
Инвертированным файлом называют такую организацию или структуру файла, которая обеспечивает быстрый поиск по запросам, включающих спецификацию значений вторичного ключа. Он состоит из многоуровневого индекса и набора списков указателей доступа, обеспечивающих доступ к записям данных в соответствии с определенным критерием ключевого значения. Вторичные ключи могут иметь не уникальные значения. Допускается изменение значений вторичных ключей при этом системой автоматически будут корректироваться соответствующие инвертированные файлы. Каждому "инвертированному" полю файла данных соответствует статья в индексе. Статья включает в себя имя поля, его значение и адрес записи. После начальной загрузки данных происходит упорядочение статей по имени поля, а групп статей с общим именем поля - по значению поля. Для каждого имени поля можно построить отдельный индекс. Записи с одним и тем же значением поля группируются, а общее значение для всех записей группы используется в качестве указателя этой группы. По мере добавления новых записей создаются статьи в соответствующих индексах для соответствующих значений. При исключении записей статьи индекса в соответствующих индексах для соответствующих значений уничтожаются. Каждому инвертированному полю соответствует статья в индексе (файл 1 уровня). Статья обычно включает в себя имя поля, его значение и адрес записи. Если предполагается поиск по другому атрибуту, то необходимо построить отдельный индекс, т. е. инвертировать файл относительно этого поля. Использование инвертированного файла позволяет существенно сократить время реакции на запросы пользователей. Инвертированные файлы занимают существенно меньшие объемы памяти и поэтому обрабатываются быстро. Система при частых обращениях к инвертированным файлам размещает их целиком (или значительную часть) в оперативной памяти, существенно повышая эффективность обработки информации.
11. Списковые структуры (списки).
Под термином «списковая структура» обычно понимается такая организация данных, при которой объекты (данные) связаны в последовательную цепочку посредством указателей. Данное определение подразумевает динамическую природу списка – т.е. не заданное заранее количество и, иногда, тип элементов.
Различают одно- и двунаправленные, одно- и многосвязные списки. Списки легко обобщаются до понятия графа.
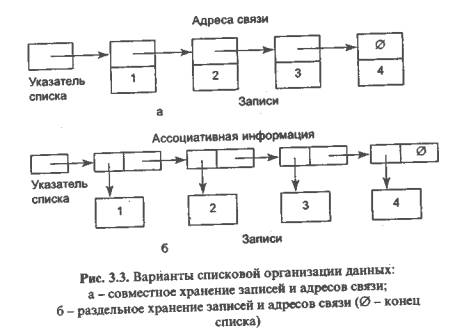
Списком называется множество записей, занимающих произвольные участки памяти, последовательность обработки которых задается с помощью адресов связи. Адресом связи некоторой записи называется атрибут, в котором хранится начальный адрес или номер записи, обрабатываемой после этой записи. Обычная последовательность обработки записей в списке определяется возрастанием значений ключа в записях.
В списке выделяется собственная информация (записи с содержательными сведениями) и ассоциативная информация, т. е. все адреса связи.
Описание записей списка на языке программирования (например, Паскаль) может быть произведено двумя способами.
Определение адресов связи как начальных адресов записей.
Определение адресов связи, как номеров записей.
Второй вариант является более практичным, особенно если требуется хранить список на внешнем запоминающем устройстве.
Возможны два способа организации списка - совместное размещение собственной и ассоциативной информации, когда запись и ее адрес связи образуют одно целое, и раздельное, когда имеется списковая организация адресов связи и последовательное хранение собственной информации.
При списковой организации данных необходим специальный атрибут, называемый указателем списка, который содержит начальный адрес или номер первой в порядке обработки записи списка. Кроме того, адрес связи последней записи списка должен содержать специальное значение, называемое концом списка и отмечающее, что последующих записей у данной записи нет. Обычно конец списка отмечается нулем.
При формировании упорядоченного списка записей возможны два варианта:
• вновь поступающие записи вставлять так, чтобы не нарушать упорядоченность по ключу;
• создать сначала неупорядоченный список, а затем отсортировать его.
Учитывая, что для сортировки можно использовать метод слияния, второй вариант следует признать более целесообразным. Односвязные и двусвязные списки:
12 Хэш-адресация.
Бинарные деревья, B+деревья и их использование в СУБД. Объектно-ориентированное визуальное проектирование приложений в объектно-ориентированных СУБД. Понятие транзакции. Управление доступом, привилегии.
Хэш-адресация заключается в использовании значения, возвращаемого хэш-функцией, в качестве адреса ячейки из некоторого массива данных. Тогда размер массива данных должен соответствовать области значений используемой хэш-функции. Следовательно, в реальном компиляторе область значений хэш-функции никак не должна превышать размер доступного адресного пространства компьютера. Метод организации таблиц идентификаторов, основанный на использовании хэш-адресации, заключается в помещении каждого элемента таблицы в ячейку, адрес которой возвращает хэш-функция, вычисленная для этого элемента. Тогда в идеальном случае для помещения любого элемента в таблицу идентификаторов достаточно только вычислить его хэш-функцию и обратиться к нужной ячейке массива данных. Для поиска элемента в таблице также необходимо вычислить хэш-функцию для искомого элемента и проверить, не является ли заданная ею ячейка массива пустой (если она не пуста — элемент найден, если пуста — не найден). Первоначально таблица идентификаторов должна быть заполнена информацией, которая позволила бы говорить о том, что все ее ячейки являются пустыми. Этот метод весьма эффективен, поскольку как время размещения элемента в таблице, так и время его поиска определяются только временем, затрачиваемым на вычисление хэш-функции, которое в общем случае несопоставимо меньше времени, необходимого для многократных сравнений элементов таблицы. Метод имеет два очевидных недостатка. Первый из них — неэффективное использование объема памяти под таблицу идентификаторов: размер массива для ее хранения должен соответствовать всей области значений хэш-функции, в то время как реально хранимых в таблице идентификаторов может быть существенно меньше. Второй недостаток — необходимость соответствующего разумного выбора хэш-функции. Этот недостаток является настолько существенным, что не позволяет непосредственно использовать хэш-адресацию для организации таблиц идентификаторов.
Бинарное (двоичное) дерево (binary tree) - это упорядоченное дерево, каждая вершина которого имеет не более двух поддеревьев, причем для каждого узла выполняется правило: в левом поддереве содержатся только ключи, имеющие значения, меньшие, чем значение данного узла, а в правом поддереве содержатся только ключи, имеющие значения, большие, чем значение данного узла. Бинарное дерево является рекурсивной структурой, поскольку каждое его поддерево само является бинарным деревом и, следовательно, каждый его узел в свою очередь является корнем дерева. Узел дерева, не имеющий потомков, называется листом. Схематичное изображение бинарного дерева:

Бинарное дерево может представлять собой пустое множество.
Организация данных с помощью бинарных деревьев часто позволяет значительно сократить время поиска нужного элемента. Поиск элемента в линейных структурах данных обычно осуществляется путем последовательного перебора всех элементов, присутствующих в данной структуре. Поиск по дереву не требует перебора всех элементов, поэтому занимает значительно меньше времени. Максимальное число шагов при поиске по дереву равно высоте данного дерева, т.е. количеству уровней в иерархической структуре дерева.
B+ дерево — структура данных, представляет собой сбалансированное дерево поиска. Является модификацией B-дерева, истинные значения ключей которого содержатся только в листьях, а во внутренних узлах — ключи-разделители, содержащие диапазон изменения ключей для поддеревьев.
При построении B+ дерева, его временами приходится перестраивать. Это связано с тем, что количество ключей в каждом узле (кроме корня) должно быть от k, до 2k, где k — степень дерева. При попытке вставить в узел (2k+1)-й ключ возникает необходимость разделить этот узел. В качестве ключа-разделителя сформированных ветвей выступает (k+1)-й ключ, который помещается на соседний ярус дерева. Особым же случаем является разделение корня, так как в этом случае увеличивается число ярусов дерева. Особенностью разделения листа B+ дерева является то, что он делится на неравные части. При разделении внутреннего узла или корня возникают узлы с равным числом ключей k. Разделение листа может вызвать «цепную реакцию» деления узлов, заканчивающуюся в корне.
В B+ дереве легко реализуется независимость программы от структуры информационной записи.
Поиск обязательно заканчивается в листе.
Удаление ключа имеет преимущество — удаление всегда происходит из листа.
Другие операции выполняются аналогично B-деревьям.
B+ деревья требуют больше памяти чем B-деревья для представления.
B+ деревья имеют возможность последовательного доступа к ключам.
Транзакция – набор команд на SQL языке, выполняемых единым блоком, который выполняется по принципу все или ничего.
Транза́кция — группа последовательных операций, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций.
Средства управления доступом являются одним из наиболее трудных для описания аспектов функционирования СУБД, так как в этой части рассматриваемые нами СУБД при обеспечении в принципе эквивалентных возможностей используют различные подходы и различную терминологию.
Доступ к данным и возможностям СУБД персонифицирован. Для каждого действия, выполняемого в системе, определено, каким пользователем оно выполняется. Пользователь (user) - это некоторое имя, определенное в базе данных и связанное с некоторым субъектом, который может соединяться с базой данных и выполнять доступ к ее объектам.
Логически пользователь понимается рассматриваемыми СУБД одинаково, хотя с принципиально различными реализациями этого понятия.
Процедура аутентификации (authentication) состоит в представлении пользователя системе при установлении соединения с базой данных и подтверждении его подлинности. Подтверждение подлинности выполняется паролем (password) . Процедура аутентификации выполняется при запуске пользователем приложения.
Привилегия - некоторый поддерживаемый системой признак, который определяет, разрешение не выполнение какой-либо конкретной операции (общей или относящейся к конкретному объекту). Каждое действие, выполняемое пользователем в базе данных, сопровождается процедурой авторизации (authorization), которая заключается в проверке того, может ли данный пользователь выполнять запрошенное действие над данным объектом, т.е., имеет ли данный пользователь данную привилегию. По результатам авторизации запрос на доступ выполняется или отклоняется.
Методы аутентификации
Для аутентификации могут использоваться внутренние или внешние методы.
При применении внутренних методов данные аутентификации пользователи являются объектами базы данных и их имена и пароли хранятся в СУБД.
При применении внешних методов аутентификация пользователя при соединении с базой данных производится по тому же имени и паролю, которые используются для его аутентификации в операционной системе или сетевых службах. В этом случае явная аутентификация при соединении с базой данных может и не требоваться - для нее используются результаты аутентификации пользователя при начале его сеанса в операционной системе/сети.
13. Функциональные зависимости. Алгоритм проверки функциональной зависимости satisfies.
Функциональная зависимость атрибутов – это такая зависимость, при которой одному значению ключа соответствует только одно значение неключевого атрибута.
Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально зависит от первичного ключа.
Случай составного ключа, и каждый неключевой атрибут функционально полно зависят от составного ключа.
Функционально полная зависимость означает, что любой неключевой атрибут находится в функциональной зависимости от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.
Для приведения схемы в корректный вид используется замена одного множества отношений другим, сохраняющим ее эквивалентность. Такое преобразование составляет суть процесса нормализации. В результате исходное небольшое число больших таблиц, обладающее непривлекательными свойствами, заменяется большим числом меньших таблиц, этими свойствами не обладающих.
Согласно определению отношения, все его атрибуты атомарны, то есть не могут быть разделены семантически на более мелкие элементы. Отношение, обладающее этим свойством, называется нормализованным или, что то же самое, находящимся в первой нормальной форме (1НФ). Нормальные формы, в которых находятся отношения, составляют иерархию, в которой формы с большими номерами не обладают некоторыми нежелательными свойствами, характерными для форм с меньшими номерами. В теории нормальных форм для реляционных БД рассматривается шесть уровней нормализации: 1НФ – 5НФ и форма Бойса-Кодда (промежуточная между 3НФ и 4НФ). Каждый из следующих уровней ограничивает типы допустимых функциональных зависимостей отношения. Функциональные зависимости отношения составляют его семантику. Уровень нормализации зависит от семантики отношения.
Отношения, не находящиеся в нормальных формах, не всегда удобны при модификации базы данных, то есть, у них существуют аномалии модификации. Различают аномалии добавления, изменения и удаления.
14. 1-ая нормальная форма. Примеры.
Отношение (relation) – это формальный аппарат приведения отношений к такому виду чтобы данные в них не дублировались и не были противоречивы.
Коддом введены три нормальные формы и предложен механизм, позволяющий любое отношение привести к третьей нормальной форме.
Первая нормальная форма
Отношение называется нормализованным, то есть приведённым к первой нормальной форме если все его атрибуты просты и далее не делимы.
Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа.
Например, отношение «Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа)» находится в первой нормальной форме.
15. 2-ая нормальная форма. Примеры.
Чтобы рассмотреть вопрос приведения отношений ко второй нормальной форме, необходимо дать пояснения к таким понятиям, как функциональная зависимость и полная функциональная зависимость.
Описательные реквизиты информационного объекта логически связаны с общим для них ключом, эта связь носит характер функциональной зависимости реквизитов.
Функциональная зависимость реквизитов — зависимость, при которой экземпляре информационного объекта определенному значению ключевого реквизита соответствует только одно значение описательного реквизита.
Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты.
В случае составного ключа вводится понятие функционально полной зависимости.
Понятие функциональной зависимости атрибутов:
В отношении R атрибут B функционально зависит от A если в каждый момент времени, каждому значению атрибута A соответствует не более одного атрибута B.
Вторая нормальная форма
Отношение задано во второй нормальной форме если оно является отношением в первой нормальной форме и каждый не ключевой атрибут зависит от первичного ключа.
В случаи составного ключа вводится понятие полной функциональной зависимости.
Атрибут B из отношения R называется полностью зависимым от набора атрибутов A если B
функционально зависит от всего множества A но не зависит ни от какого подмножества A.
Отношение задано во второй нормальной форме если оно является отношением в первой нормальной форме и каждый не ключевой атрибут функционально полно зависит от первичного ключа.
Пример
Пример приведения отношения ко второй нормальной форме
Пусть в следующем отношении первичный ключ образует пара атрибутов {Сотрудник, Должность}:
Сотрудник |
Должность |
Зарплата |
Наличие компьютера |
Гришин |
Кладовщик |
20000 |
Нет |
Васильев |
Программист |
40000 |
Есть |
Иванов |
Кладовщик |
25000 |
Нет |
Зарплату сотруднику каждый начальник устанавливает сам (хотя её границы зависят от должности). Наличие же компьютера у сотрудника зависит только от должности, то есть зависимость от первичного ключа неполная.
В результате приведения к 2NF получаются два отношения:
Сотрудник |
Должность |
Зарплата |
Гришин |
Кладовщик |
20000 |
Васильев |
Программист |
40000 |
Иванов |
Кладовщик |
25000 |
Должность |
Наличие компьютера |
Кладовщик |
Нет |
Программист |
Есть |
16. Транзитивная зависимость. 3-я нормальная форма. Примеры
Назначение языка баз данных SQL. Основные принципы языка.
Пусть А, В и С атрибуты некоторого отношения R. Если в отношение R В функционально зависит от А, а С от В, а обратное соответствие не однозначно, то С транзитивно зависит от А.
Отношение находится в 3-ей нормальной форме, если оно соответствует определению 2-ой нормальной форме, и каждый и каждый не ключевой атрибут не транзитивно зависит от первичного ключа.
Транзитивная зависимость:
Если в отношении R, B функционально зависит от A, а C функционально зависит от B, а обратное соответствие не верно, то говорят что C транзитивно зависит от A.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита. Для устранения транзитивной зависимости описательных реквизитов необходимо провести «расщепление» исходного информационного объекта. В результате расщепления часть реквизитов удаляется из исходного информационного объекта и включается в состав других (возможно, вновь созданных) информационных объектов.
3Я нормальная форма:
Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости.
Отношение задано в 3 нормальной форме, если оно задано во второй нормальной форме и каждый не ключевой атрибут не транзитивно зависит от каждого возможного ключа.
Пример
Рассмотрим в качестве примера следующее отношение:
R1 |
||
Сотрудник |
Отдел |
Телефон |
Гришин |
Бухгалтерия |
11-22-33 |
Васильев |
Бухгалтерия |
11-22-33 |
Петров |
Снабжение |
44-55-66 |
В отношении атрибут «Сотрудник» является первичным ключом. Личных телефонов у сотрудников нет, и телефон сотрудника зависит исключительно от отдела.
Таким образом, в отношении существуют следующие функциональные зависимости: Сотрудник → Отдел, Отдел → Телефон, Сотрудник → Телефон.
Зависимость Сотрудник → Телефон является транзитивной, следовательно, отношение не находится в 3NF.
В результате декомпозиции отношения R1 получаются два отношения, находящиеся в 3NF:
R2 |
|
Отдел |
Телефон |
Бухгалтерия |
11-22-33 |
Снабжение |
44-55-66 |
R3 |
|
Сотрудник |
Отдел |
Гришин |
Бухгалтерия |
Васильев |
Бухгалтерия |
Петров |
Снабжение |
Исходное отношение R1 при необходимости легко получается в результате операции соединения отношений R2 и R3.
SQL ("Язык структурированных запросов") - универсальный язык, применяемый для создания, модификации и управления данными в реляционных (удаленных) базах данных.
SQL является информационно-логическим языком, предназначенным для полного взаимодействия с реляционными базами данных.
SQL - непроцедурный язык. В SQL не записываются шаг за шагом все инструкции, а просто говорится, что нужно сделать.
Язык SQL предназначен только для взаимодействия с базой данных. Средств разработки законченных программ (организации красивых экранных форм, печати отчетов и т.п.) в нем нет.
 БДиЗ
БДиЗ