

Алгоритмы арбитража
Статические приоритеты
Каждое устройство в системе получает уникальный приоритет, – при одновременном запросе нескольких устройств на передачу доступ к шине предоставляется устройству с наивысшим приоритетом
Динамические приоритеты
Устройства получают уникальные приоритеты, однако в отличие от него эти приоритеты непостоянны во времени. Приоритеты динамически изменяются, предоставляя устройствам более или менее равные шансы получения доступа к шине.
Фиксированные временные интервалы
Все устройства по порядку получают одинаковые временные интервалы для осуществления передачи. Если устройство не имеет данных для передачи, то интервал тем не менее следующему устройству не предоставляется.
Очередь FIFO
Создается очередь запросов «первый пришел – первый ушел», однако сохраняется проблема арбитража между почти одновременными запросами, а также возникает необходимость поддержания очереди запросов достаточной длины. Преимуществом данного алгоритма является возможность достижения максимальной пропускной способности шины.
П ростые коммутаторы с пространственным разделением. Особенности реализации шин
Простые коммутаторы с пространственным разделением позволяют одновременно соединять любой вход с любым одним выходом (ординарные) или несколькими выходами (неординарные). Такие коммутаторы представляют собой совокупность мультиплексоров, количество которых соответствует количеству выходов коммутатора, при этом каждый вход коммутатора должен быть заведен на все мультиплексоры.
Особенности реализации шин
Внутри микросхем шины используются для объединения функциональных блоков микропроцессоров, микросхем памяти, микроконтроллеров. Шины используются для объединения устройств на печатных платах и печатных плат в блоках.
Шины, объединяющие устройства, из которых состоит вычислительная система, являются критическим ресурсом, отказ которого может привести к отказу всей системы. Шины обладают также рядом принципиальных ограничений. Возможность масштабируемости шинных структур ограничивается временем, затрачиваемым на арбитраж, и количеством устройств, подключенных к шине. При этом чем больше подключенных устройств, тем больше времени затрачивается на арбитраж. Время арбитража ограничивает и пропускную способность шины. Кроме того, в каждый момент времени шина используется для передачи только одним устройством, что становится узким местом при увеличении количества подключенных устройств. пропускная способность шины ограничивается ее шириной – количеством проводников, используемых для передачи данных, – и тактовой частотой ее работы. Данные величины имеют физические ограничения.
Составные коммутаторы. Коммутатор Клоза. Баньян-сети
Составные коммутаторы, обычно строящиеся из простых в виде многокаскадных схем с помощью линий «точка-точка».
Составные коммутаторы имеют задержку, пропорциональную количеству простых коммутаторов, через которые проходит сигнал от входа до выхода, т.е. числу каскадов. Однако объем оборудования составного коммутатора меньше, чем простого с тем же количеством входов и выходов.
Чаще всего составные коммутаторы строятся из прямоугольных коммутаторов 2х2 с двумя входами и выходами. Они имеют два состояния: прямое пропускание входов на соответствующие выходы и перекрестное пропускание. Коммутатор 2х2 состоит из собственно блока коммутации данных и блока управления.
Коммутатор Клоза
К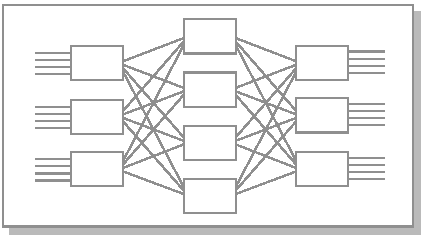 оммутатор
Клоза может быть построен в качестве
альтернативы для прямоугольного
коммутатора с (m x d) входами и (m x d) выходами.
Он формируется из трех каскадов
коммутаторов: m коммутаторов (d x d) во
входном каскаде, m коммутаторов (d x d) в
выходном и d промежуточных коммутаторов
(m x m).
оммутатор
Клоза может быть построен в качестве
альтернативы для прямоугольного
коммутатора с (m x d) входами и (m x d) выходами.
Он формируется из трех каскадов
коммутаторов: m коммутаторов (d x d) во
входном каскаде, m коммутаторов (d x d) в
выходном и d промежуточных коммутаторов
(m x m).
Данный тип составных коммутаторов позволяет соединять любой вход с любым выходом, однако при установленных соединениях добавление нового соединения может потребовать разрыва и переустановления всех соединений.
Баньян-сети
Коммутаторы этого типа строятся на базе прямоугольных коммутаторов таким образом, что существует только один путь от каждого входа к каждому выходу.
Наиболее важной разновидностью баньян-сетей является дельта-сеть. Она формируется из прямоугольных коммутаторов (a x b) и представляет собой n-каскадный коммутатор с an входами и bn выходами. Составляющие коммутаторы соединены так, что для соединения любого входа и выхода образуется единственный путь одинаковой для всех пар входов и выходов длины.