

Функции управление памятью
Рассмотрим функции управления памятью:
· malloc() – предназначена для выделения непрерывной области памяти заданного размера, например, void * malloc(size_t size),
где size_t – тип результата операции sizeof, определяемый в различных объектах-заголовках (stdio.h,stdlib.h,string.h и др.) и соответствующий типу unsigned long; size – размер выделяемой памяти в байтах.
Функция malloc возвращает указатель без типа. Если выделить память не удалось, функция возвращает значение NULL.
При использовании в программах на C++ требуется выполнять явное преобразование типа указателя. Если необходимо создать символьную cтроку в динамической памяти, то сначала надо объявить указатель char *S1, а затем выделить область под символьную строку с помощью функции malloc():
S1=(char*)malloc(V);
где V – выражение, значением которого является целые неотрицательные числа, например, V=10, V=10+7 и т. д.
Далее указатель S1 используется в функциях для работы со строками так же, как если бы строка была объявлена как массив символов или указатель на статическую строку, например:
gets (S1);
scanf ("%s",S1);
printf ("%s",S1);
int n=strlen(S1);
· calloc() – предназначена для выделения памяти под заданное количество объектов, каждый из которых имеет размер size байт, всего n ´ size байт. Возвращает указатель на первый байт выделенной область памяти.
Если выделить память не удалось, функция возвращает значение NULL:
void * calloc(size_t n, size_t size);
· realloc() – предназначена для изменения размера динамически выделенной области, адресуемой указателем ptr, при этом размер области может как увеличиваться, так и уменьшаться:
void* realloc(void* ptr, size_t size);
где ptr – указатель на первоначальную область памяти, size – новый размер области памяти.
Функция возвращает адрес новой области памяти, при этом старая область освобождается. Данные из освобождаемой области копируются в новую, но не более size байт. В некоторых случаях область, адресуемая первоначально указателем ptr, может сохраниться, только изменится ее размер. Если выделить память не удалось, функция возвращает значение NULL.
Лекция 10. Динамические структуры данных.
Динамическая структура данных - структура данных, размер которой может меняться в процессе работы программы.
Классифицировать динамические структуры можно по нескольким признакам:
- по способу хранения:
- структуры с последовательным хранением,
- структуры со связанным хранением;
- по методу доступа к элементам:
- структуры с произвольным доступом,
- структуры с упорядоченным доступом;
- по физической структуре:
- линейные структуры;
- разветвляющиеся структуры;
- произвольные структуры.
В динамических структурах с последовательным хранением элементы хранятся на смежной памяти (в одном непрерывном блоке памяти). В динамических структурах со связанным хранением элементы хранятся в отдельных блоках динамически выделенной памяти, а связь элементов между собой осуществляется посредством ссылок (указателей).
В динамических структурах с произвольным доступом обращение к элементам может быть осуществлено в любой момент времени в любом порядке. В динамических структурах с упорядоченным доступом обращение к элементам осуществляется в определенном строго заданном порядке.
В линейных динамических структурах все элементы организованы в одну цепочку: т.е. каждый элемент имеет два соседних элемента, один из которых называется предыдущим, а другой последующим элементом. Такие динамические структуры называют списочными. К ним относят: списки, стеки, очереди и производные от них.
В разветвляющихся динамических структурах каждый элемент имеет более двух соседних элементов, один из которых называется предком, а остальные потомками. Такие динамические структуры называют деревьями.
В рамках данного курса будут рассматриваться только несколько видов динамических структур, наиболее часто применяемых на практике (в программировании): списки, стеки, очереди и деревья.
Списки с последовательным хранением (хранение на смежной памяти) реализуются в виде одномерного массива расположенного в динамически выделенной памяти. Размер этого массива (списка с последовательным хранением) может меняться путем перевыделения динамической памяти под элементы в соответствии с их количеством.
Для организации такого списка необходимо наличие двух переменных:
указатель на массив (типизированный указатель);
количество элементов (целочисленное значение).
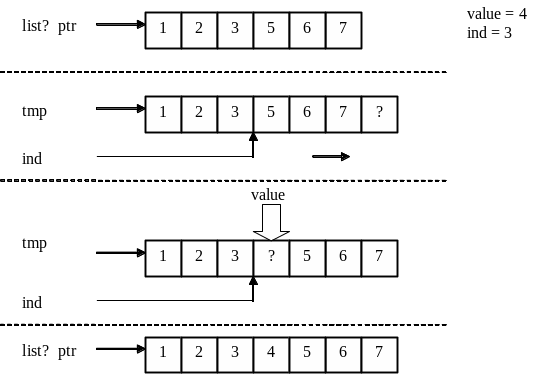
Рисунок 9.1 - Вставка элемента в список с последовательным хранением
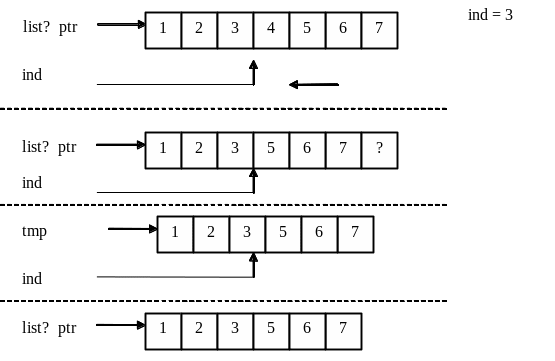
Рисунок 9.2 - Удаление элемента из списка с последовательным хранением
Элементы списков со связанным хранением располагаются в различных блоках динамически выделенной памяти. Для их организации в последовательную (списочную) структуру используются указатели. Поэтому каждый элемент связанного списка, помимо поля данных, содержит одно или два поля - указатели на соседние элементы. Если поле-указатель одно, то список называют однонаправленным и указатель содержит адрес следующего элемента в списке. Если в элементе два поля-указателя, то список называют двунаправленным и эти поля содержат указатели на предыдущий и последующий элементы в списке. Последний элемент в списке в поле-указателе на следующий элемент должен содержать значение NULL, первый элемент в списке (для двунаправленных списков) в поле-указателе на предыдущий элемент также должен содержать значение NULL. На рисунке 9.3 показаны графические схемы реализации однонаправленного и двунаправленного списка.

Рисунок 9.3 - Графическое изображение связанных списков
Как и в случае со списками последовательного хранения (хранения на смежной памяти) дополнительными функциями обработки связных списков являются операции сортировки и поиска. Так как индексированный доступ к элементам связанного списка невозможен, то использовать библиотечные функции для сортировки и поиска нельзя. Также довольно сложно реализовать быстрые алгоритмы сортировки и поиска. Поэтому, на практике, широкое применение для сортировки связанных списков нашли медленные алгоритмы сортировки (алгоритмы вставок и пузырька) и алгоритм линейного поиска.
Рассмотренные ранее списки с последовательным и связанным хранением обладают своими преимуществами и недостатками, которые могут, как ускорить, так и замедлить процесс работы со списками.
Основным преимуществом списков с последовательным хранением является возможность индексированного доступа к элементам списка, что существенно упрощает и ускоряет обработку таких списков. Недостатком же списков с последовательным хранением является необходимость копирования больших объемов данных при добавлении, вставке и удалении элементов из списка, что снижает скорость выполнения программ, в которых количество элементов в списке часто изменяется.
Преимуществом связанных списков является то, что при добавлении, вставке и удалении элементов из списка не требуется копирование больших объемов данных, так как каждый элемент такого списка располагается в своем собственном блоке динамической памяти (необходимо только «связать» новый элемент со списком или «отвязать» удаляемый элемент от списка). Недостатком связанных списков является невозможность обращения к элементу списка по его индексу, а требуется введение специальных операций для перемещения по списку, что может существенно замедлить его обработку.
Для частичного устранения недостатков можно использовать смешанное хранение. Основная идея смешанного хранения заключается в том, что используется список с последовательным хранением, значениями элементов которого являются указатели на данные, которые в свою очередь располагаются в отдельном блоке динамической памяти. Схема такого списка приведена на рисунке 9.6.
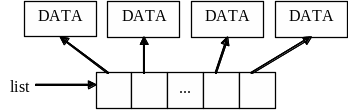
Рисунок 9.6 - Список со смешанным хранением
Для организации такого списка, как и для списка с последовательным хранением, необходимо наличие двух переменных:
указатель на массив указателей (типизированный двойной указатель);
количество элементов (целочисленное значение).
Так как, список со смешанным хранением представляет по своей сути список с последовательным хранением, то для сортировки и поиска данных в списке можно использовать функции сортировки и поиска из библиотеки stdlib.h.
Очередь - динамическая линейная структура данных с упорядоченным доступом к элементам, функционирующая по принципу FIFO: «первый вошел - первый вышел».
Очереди реализуются с использованием списочной структуры с последовательным или связанным хранением. Выбор вида хранения элементов осуществляется исходя из специфики использования очереди. Так, если максимальное количество элементов в очереди известно заранее, то целесообразно использовать последовательное хранение. Если же, количество элементов заранее неизвестно или это значение может меняться в процессе работы программы, то лучше использовать связанное хранение. Далее в этом подпункте будут рассмотрены оба вида реализации очереди.
Для работы с очередью необходимо реализовать следующие операции:
инициализация (создание) очереди;
удаление очереди;
помещение элемента в очередь;
изъятие элемента из очереди.
Для организации очереди с последовательным хранением необходимо наличие следующих переменных:
указатель на массив элементов, образующих очередь (типизированный указатель);
индекс первого элемента в очереди (целочисленный тип);
индекс последнего элемента в очереди (целочисленный тип);
максимальный размер очереди (целочисленный тип);
текущий размер очереди (целочисленный тип).
Стек - динамическая линейная структура данных с упорядоченным доступом к элементам, функционирующая по принципу LIFO: «последний вошел - первый вышел».
Стеки реализуются с использованием списочной структуры с последовательным или связанным хранением. Выбор вида хранения элементов осуществляется исходя из специфики использования стека. Так, если максимальное количество элементов в стеке известно заранее, то целесообразно использовать последовательное хранение. Если же, количество элементов заранее неизвестно или это значение может меняться в процессе работы программы, то лучше использовать связанное хранение. Далее в этом подпункте будут рассмотрены оба вида реализации стека.
Для работы со стеком необходимо реализовать следующие операции:
инициализация (создание) стека;
удаление стека;
помещение элемента в стек;
изъятие элемента из стека.
Для организации стека с последовательным хранением необходимо наличие следующих переменных:
указатель на массив элементов, образующих стек (типизированный указатель);
индекс вершины стека (целочисленный тип);
максимальный размер стека (целочисленный тип).
Дерево - нелинейная (разветвляющаяся) динамическая структура данных, где каждый элемент имеет две и более ссылки на элементы, один из которых называется предком, а остальные дочерними элементами. Элемент, не имеющий предка, должен быть один в дереве и называется корнем дерева. Совокупность элементов от корневого элемента до любого элемента дерева, не имеющего дочерних элементов, называется ветвью дерева. Количество элементов в ветви называется его длиной, а максимальная длина в дереве - высота дерева. Пример дерева приведен на рисунке 9.7.

Рисунок 9.7 - Пример дерева
Бинарным деревом называется дерево, каждый элемент которого содержит ссылки на два дочерних элемента. На рисунке 9.8 приведен пример бинарного дерева.
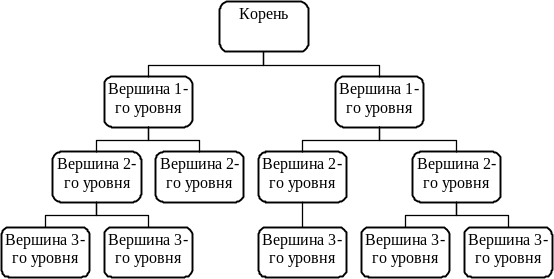
Рисунок 9.8 - Пример бинарного дерева
Для организации дерева необходимо наличие двух переменных:
указатель на корень дерева (типизированный указатель);
указатель на текущий элемент в дереве (типизированный указатель).
Для работы с деревом необходимо реализовать следующие функции:
создание (инициализация) дерева;
перемещение по дереву (вверх - к предку и вниз - к потомку);
помещение элемента в дерево;
удаление элемента из дерева;
удаление всего дерева.