

Етапи розробки програми
1. Постановка завдання - складання точного і зрозумілого словесного опису того, як повинна працювати майбутня програма, що має робити користувач в процесі її роботи. 2. Розробка інтерфейсу (інтерфейс - спосіб спілкування) - створення екранної форми (вікна програми). 3. Складання алгоритму. 4. Програмування - створення програмного коду на мові програмування. 5. Налагодження програми - усунення помилок. 6. Тестування програми - перевірка правильності її роботи. 7. Створення документації, допомоги.
Перша ЕОМ
З кінця 1948 року С. А. Лебедєв працював над розробкою перша в СРСР і континентальній Європі ЕОМ, котра мала назву - мала електронна лічильна машина (МЕЛМ)
Спочатку МЕЛМ замислювалася як макет або модель Великої електронної лічильної машини , перший час буква «М» у назві означала «модель» Робота над машиною носила дослідний характер, з метою експериментальної перевірки принципів побудови універсальних цифрових ЕОМ. Після перших успіхів та з метою задоволення великих потреб в обчислювальній техніці, було прийнято рішення доробити макет до повноцінної машини, здатної вирішувати реальні завдання. Історія створення та експлуатації До кінця 1949 року - розроблена архітектура машини, а також принципові схеми окремих блоків. У 1950 р. машина була змонтована в двоповерховій будівлі колишнього монастиря в Феофанії (під Києвом). 6 листопада 1950 - виконаний пробний пуск машини 4 січня 1951 - вирішені перші завдання: обчислення суми непарного ряду факторіала числа; зведення в ступінь
25 грудня 1951 - після успішного проведення випробувань, було розпочата регулярна експлуатація машини. Експлуатувалася до 1957 р., після чого була передана в КПІ для навчальних цілей: «Машину розрізали на шматки, організували ряд стендів, а потім ... викинули»
Базові параметри еом
Система числення — двійкова з фіксованою комою перед старшим розрядом;
Розрядність — 16 (+1 на знак);
Запам'ятовуючий пристрій — тригери; можливе використання магнітного барабану;
Ємність оперативного запам'ятовуючого пристрою — 31 для чисел та 63 для команд;
Ємність постійного (штекерного) запам'ятовуючого пристрою — 31 для чисел та 63 для команд;
Основні команди: додавання, віднімання, множення, ділення, зсув, порівняння з врахуванням знаку, порівняння за абсолютним значенням, передача управління, передача даних з магнітного барабану, складання команд, зупинка;
Система команд — триадресна, команди довжиною 20 двійкових розрядів (з них 4 розряди — код операції);
Арифметичний пристрій — один, універсальний, паралельної дії, на тригерах;
Обмін між арифметичним та запам'ятовуючим пристроями — послідовний;
Швидкодія — близько 50 оп/с;
Робоча частота — 5 КГц;
Введення вихідних даних — з перфокарт або безпосереднім набором кодів на штекерному комутаторі;
Вивід результатів — фотографування або за допомогою електромеханічного друкуючого пристрою;
Контроль — системою програмування;
Пошук несправностей — спеціальні тести та переведення на ручну або напівавтоматичну роботу;
Площа приміщення — 60 м²;
Кількість електронних ламп-тріодів — біля 3500, ламп-діодів — 2500;
Енергоспоживання — 25 КВт.
Структура даних - програмна одиниця, що дозволяє зберігати і обробляти безліч однотипних або логічно пов'язаних даних в обчислювальній техніці. Для додавання, пошуку, зміни та видалення даних структура даних надає деякий набір функцій, що становлять її інтерфейс. Структура даних часто є реалізацією будь-якого абстрактного типу даних. При розробці програмного забезпечення велику роль грає проектування сховища даних і представлення всіх даних у вигляді безлічі пов'язаних структур даних. Добре спроектована сховище даних оптимізує використання ресурсів (таких як час виконання операцій, що використовується обсяг оперативної пам'яті, число звернень до дискових накопичувачів), необхідних для виконання найбільш критичних операцій. Структури даних формуються за допомогою типів даних, посилань та операцій над ними в обраному мові програмування. Різні види структур даних підходять для різних додатків; деякі з них мають вузьку спеціалізацію для певних завдань. Наприклад, B-дерева зазвичай підходять для створення баз даних, в той час як хеш-таблиці використовуються повсюдно для створення різного роду словників, наприклад, для відображення доменних імен в інтернет-адреси комп'ютерів. При розробці програмного забезпечення складність реалізації і якість роботи програм істотно залежить від правильного вибору структур даних. Це розуміння дало початок формальним методам розробки та мов програмування, в яких саме структури даних, а не алгоритми, є наріжним архітектури програмного засобу.Велика частина таких мов володіє певним типом модульності, що дозволяє структурам даних безпечно переіспользоваться в різних додатках. Об'єктно-орієнтовані мови, такі як Java, C # і C + +, є прикладами такого підходу. Багато класичні структури даних представлені в стандартних бібліотеках мов програмування або безпосередньо вбудовані в мови програмування. Наприклад, структура даних хеш-таблиця вбудована в мови програмування Lua, Perl, Python, Ruby, Tcl та ін Широко використовується стандартна бібліотека шаблонів STL мови C + +. Фундаментальними будівельними блоками для більшої частини структур даних є масиви, записи (див. конструкцію struct в мові Сі і конструкцію record в мові Паскаль), розмічені об'єднання (див. конструкцію union в мові Сі) та посилання.Наприклад, структура даних двусвязний список, може бути побудована за допомогою записів і зануляемие посилань, а саме, кожен запис буде надавати блок даних (вузол, node), що містить посилання на «лівий» і «правий» вузли, а також самі збережені дані.
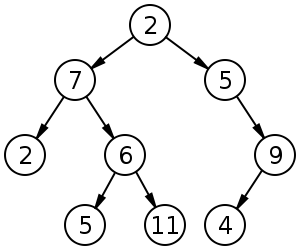 Бінарне дерево,
простий приклад ветвящейся зв'язковий структури даних.
Бінарне дерево,
простий приклад ветвящейся зв'язковий структури даних.
Алгоритм Евкліда (також називається евклідів алгоритм) — ефективний метод обчислення найбільшого спільного дільника (НСД). Названий на честь грецького математика Евкліда, котрий описав його в книгах VII та X Начал.[1]
Найбільший спільний дільник двох чисел це найбільше число, що ділить обидва дані числа без залишку. Алгоритм Евкліда оснований на тому, що НСД не змінюється, якщо від більшого числа відняти менше. Наприклад, 21 є НСД чисел 252 та 105 (252 = 21 × 12; 105 = 21 × 5); оскільки 252 − 105 = 147, НСД 147 та 105 також 21. Оскільки більше з двох чисел постійно зменшується, повторне виконання цього кроку дає все менші числа, поки одне з них не дорівнюватиме нулю. Коли одне з чисел дорівнюватиме нулю, те, що залишилось, і є НСД. Обертаючи кроки алгоритму Евкліда в зворотній порядок, НСД можна виразити як лінійну комбінацію даних чисел помножених на цілі коефіцієнти, наприклад 21 = 5 × 105 + (−2) × 252. Ця важлива властивість відома як лема Безо.
Найдавніший опис алгоритму знаходиться в Началах Евкліда (біля 300 до н. е.), що робить його найдавнішим чисельним алгоритмом, яким користуються і нині. Оригінальний варіант алгоритму описував роботу лише з натуральними числами та геометричними довжинами (дійсними числами), алгоритм було узагальнено в XIX столітті на роботу з іншими типами чисел, такими як Гаусові цілі таполіноми з однією змінною. Це призвело до появи сучасних алгебраїчних понять, таких як Евклідові класи. Алгоритм Евкліда було узагальнено ще далі для роботи з іншими математичними структурами, такими як вузли та поліноми від багатьох змінних.
Алгоритм евкліда має багато застосувань на практиці, та в теорії. З його допомогою можна згенерувати практично всі найважливіші музичні ритми різних культур у всьому світі.[2] Алгоритм Евкліда відіграє ключову роль в алгоритмі RSA, поширеному методі криптографії з відкритим ключем. Його також використовують для пошуку розв'язків Діофантових рівнянь, наприклад, пошук чисел, що задовільняють декільком умовам (Китайська теорема про залишки) або зворотні числа в скінченному полі. Алгоритм Евкліда також застосовують для побудови ланцюгових дробів в методі Штурмадля пошуку дійсних коренів полінома, та в сучасних методах факторизації цілих. Нарешті, він виступає простим інструментом для доведення теорем в теорії чисел, таких, як теорема Лагранжа про чотири квадрата та основної теореми арифметики.
Алгоритм Евкліда ефективно обчислює НСД великих чисел, оскільки виконує операцій не більше, ніж вп'ятеро більше кількості цифр меншого числа (в десятковій системі). Цю властивість було доведено Ґабріелєм Ламі (англ. Gabriel Lamé) в 1844 році, що позначило початок теорії складності обчислень. Методи підвищення ефективності алгоритму були розроблені в XX столітті.
ОСНОВНЫ ВИМОГИ ДО ОФОРМЛЕННЯ БЛОК СХЕМ
Блок-схема - це послідовність блоків, розпорядчих виконання певних операцій, і зв'язків між цими блоками. Усередині блоків вказується інформація про операції, що підлягають виконанню. Конфігурація і розміри блоків, а також порядок графічного оформлення блок-схем регламентовані ГОСТ 19002-80 і ГОСТ 19003-80 "Схеми алгоритмів і програм". У табл. 1 наведені найбільш часто використовувані блоки, зображені елементи зв'язків між ними і дано коротке пояснення до них. Блоки й елементи зв'язків називають елементами блок-схем. Представлених в таблиці елементів цілком достатньо для зображення алгоритмів, які необхідні при виконанні студентських робіт. При з'єднанні блоків слід використовувати тільки вертикальні і горизонтальні лінії потоків. Горизонтальні потоки, які мають напрямок справа наліво, і вертикальні потоки, які мають напрямок знизу вгору, повинні бути обов'язково позначені стрілками. Інші потоки можуть бути помічені або залишені непоміченими. Лінії потоків повинні бути паралельні лініям зовнішньої рамки або кордонів листа Відстань між паралельними лініями потоків повинно бути не менше 3 мм, між іншими елементами схеми - не менше 5 мм. Горизонтальний і вертикальний розміри блоку повинні бути кратні 5 мм (ділитися на 5 без остачі). Ставлення горизонтального і вертикального розмірів блоку b / а = 1.5 є основним. При ручному виконанні блоку допустимо відношення b / а = 2. Блоки "Початок", "Кінець" і "З'єднувач" мають висоту а / 2, т. е. вдвічі менше основної висоти блоків. Для розміщення блоків рекомендується поле листа розбивати на горизонтальні і вертикальні (для розгалужувалось схем) зони. Для зручності опису блок-схеми кожен її блок слід пронумерувати. Зручно використовувати наскрізну нумерацію блоків. Номер блоку розташовують у розриві в лівій верхній частині рамки блоку.
ВИКОРИСТАННЯ ХЕШУВАННЯ
Наприклад, під час запису текстових полів в базі даних може розраховуватися їх хеш код і дані можуть поміщатися в розділ, що відповідає цьому хеш-коду. Тоді при пошуку даних треба буде спочатку обчислити хеш-код тексту і відразу стане відомо, в якому розділі їх треба шукати, тобто, шукати треба буде не по всій базі, а тільки по одному її розділу (це сильно прискорює пошук).
Побутовим аналогом хешування в даному випадку може служити розміщення слів у словнику за алфавітом. Перша буква слова є його хеш-кодом, і при пошуку ми переглядаємо не весь словник, а тільки потрібну букву.
По́шук у ширину́ — алгоритм пошуку на графі.
Якщо задано граф G = (V, E) та початкову вершину s, алгоритм пошуку в ширину систематично обходить всі досяжні із s вершини. На першому кроці вершина s позначається, як пройдена, а в список додаються всі вершини, досяжні з s без відвідування проміжних вершин. На кожному наступному кроці всі поточні вершини списку відмічаються, як пройдені, а новий список формується із вершин, котрі є ще не пройденими сусідами поточних вершин списку. Для реалізації списку вершин найчастіше використовується черга. Виконання алгоритму продовжується до досягнення шуканої вершини або до того часу, коли на певному кроці в список не включається жодна вершина. Другий випадок означає, що всі вершини, доступні з початкової, уже відмічені, як пройдені, а шлях до цільової вершини не знайдений.
Алгоритм має назву пошуку в ширину, оскільки «фронт» пошуку (між пройденими та непройденими вершинами) одноманітно розширюється вздовж всієї своєї ширини. Тобто, алгоритм проходить всі вершини на відстані k перед тим як пройти вершини на відстані k+1.
Алгори́тм пошуку́ в глибину́ (англ. Depth-first search, DFS) — алгоритм для обходу дерева, структури подібної до дерева, або графа. Робота алгоритма починається з кореня дерева (або іншої обраної вершини в графі) і здійснюється обхід в максимально можливу глибину до переходу на наступну вершину.
ДІЯЛЬНІСТЬ ГЛУШКОВА