

Лекция 1. ПОНЯТИЕ ОБ ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ.
Интеллектуальные мехатронные системы
Исследования в области искусственного интеллекта (ИИ) развернулись одновременно с началом промышленного использования ЭВМ. Сам термин "искусственный интеллект" впервые появился в конце 60-х гг. Искусственный интеллект (англ. - artificial intelligence) – это искусственные программные системы, созданные человеком на базе ЭВМ и имитирующие решение человеком сложных творческих задач в процессе его жизнедеятельности. По другому аналогичному определению, "искусственный интеллект – это программы для ЭВМ, с помощью которых машина приобретает способность решать нетривиальные задачи и задавать нетривиальные вопросы".
Различают два направления работ, составляющих искусственный интеллект (ИИ). Первое из этих направлений, которое можно условно назвать бионическим, имеет своей целью смоделировать деятельность мозга, его психофизиологические свойства, чтобы попытаться воспроизвести на ЭВМ или с помощью специальных технических устройств искусственный разум (интеллект).
Второе (основное) направление работ в области ИИ, называемое иногда прагматическим, связано с созданием систем автоматического решения сложных (творческих) задач на ЭВМ без учета природы тех процессов, которые происходят в человеческом сознании при решении этих задач. Сравнение при этом осуществляется по эффективности результата, качеству полученных решений. Созданные в рамках этого направления системы ИИ позволяют доказывать математические теоремы, переводить тексты с одного языка на другой, диагностировать болезни, умело играть в шахматы и другие интеллектуальные игры. Новое поколение роботов, наделенных ИИ, обладает такими "интеллектуальными" способностями, как способность обучаться, приспосабливаться к изменениям внешней среды, "осмысленно" имитируя поведение человека.
Несмотря на различия предметной области (т.е. сферы применения) систем ИИ, можно выделить некоторые общие принципы их построения и функционирования. Прежде всего, отметим, что процесс мышления человека обладает рядом характерных особенностей:
1. Существует цель, т.е. тот конечный результат, на который направлены мыслительные процессы человека ("цель заставляет человека думать").
2. Человеческий мозг хранит огромное число фактов и правил их использования. Для достижения определенной цели надо только обратиться к нужным фактам и правилам.
3. Принятие решений всегда осуществляется на основе специального механизма упрощения, позволяющего отбрасывать ненужные (малосущественные) факты и правила, не имеющие отношения к решаемой в данный момент задаче, и, наоборот, выделять главные, наиболее значимые факты и правила, нужные для достижения цели.
4. Достигая цели, человек не только приходит к решению поставленной перед ним задачи, но и одновременно приобретает новые знания. Та часть интеллекта, которая позволяет ему делать соответствующие заключения (выводы) на основании правил, отобранных механизмом упрощения, и генерировать новые факты из уже существующих, называется механизмом (или машиной) вывода (inference machine).
Так, типовая схема решения математической задачи часто выглядит следующим образом. Выбираются неизвестные величины, подлежащие определению. На основании анализа условий (ограничений), содержащихся в исходной формулировке задачи, составляется система уравнений, связывающих указанные неизвестные. Далее, применяя какой-либо из стандартных методов решения полученных уравнений, находим искомое решение задачи. Заметим, что, решив один раз конкретную задачу по описанной схеме, мы решим (и гораздо быстрее) другую подобную (и даже более сложную) задачу, отличающуюся значениями исходных данных, числом неизвестных, формой представления условий и т.д.
Поскольку система ИИ принимает решения аналогично тому, как это делает человек, то она должна включать в себя следующие ключевые элементы – цели, факты и данные, правила, механизмы вывода и упрощения.
Все эти компоненты системы ИИ показаны на рис. 1.1. На этом же рисунке выделена база знаний, которая содержит всю располагаемую информацию о внешнем мире (моделях решаемых задач). Условно она может быть разделена на три части (или области), называемые базой целей, базой правил и базой данных. Первая область содержит информацию о целях, для достижения которых предназначена система ИИ. Вторая область включает в себя сведения, которые отражают закономерности, характерные для решаемого класса задач. Это правила, механизмы упрощения и вывода, которые позволяют не только выводить новые факты, не зафиксированные ранее в базе данных, но и приобретать новые знания в ходе функционирования системы или на этапе ее обучения. В третьей области содержатся в некотором упорядоченном виде качественные данные, необходимые для решения задачи. В силу той особой роли, которую играет база знаний в процессе формирования решений, системы ИИ нередко называют системами, основанными на знаниях (knowledge-based systems).
Взаимодействие системы ИИ с человеком-оператором (пользователем системы) и набором датчиков (сенсоров), поставляющих текущую информацию о состоянии внешней среды, при этом осуществляется с помощью специальных аппаратно-программных средств (интерфейса).
Интерфейс также может выполнять интеллектуальные функции, обеспечивая общение с человеком на естественном языке, восприятие символьной и графической информации, сжатие и предварительную обработку результатов измерений и т.д.

Рис. 1.1. Компоненты системы ИИ
Заметим, что построение универсальной системы ИИ, охватывающей все предметные области, является невозможным, так как это потребует бесконечного числа фактов и правил. Более реальной является задача создания таких систем ИИ, которые предназначены для решения задач в узко очерченной, конкретной проблемной области.
Такие системы, использующие опыт и практические знания экспертов-специалистов в данной предметной области, называются экспертными системами (expert systems). Применение экспертных систем оказывается чрезвычайно эффективным в самых различных областях человеческой деятельности (медицина, геология, электроника, нефтехимия, космические исследования и т.д.). Это объясняется рядом причин:
1) появляется возможность решения ранее не доступных, плохо формализуемых задач с привлечением нового, специально разработанного для этих целей математического аппарата (семантических сетей, фреймов, нечеткой логики и т.д.);
2) создаваемые экспертные системы ориентированы на их эксплуатацию широким кругом специалистов (конечных пользователей), общение с которыми происходит в диалоговом режиме, с использованием понятной им техники рассуждений и терминологии конкретной предметной области;
3) применение экспертной системы позволяет резко повысить эффективность решений, принимаемых рядовыми пользователями, за счет аккумуляции знаний в экспертной системе, в том числе знаний экспертов высшей квалификации.
Суть организации экспертной системы (как человеко-машинной) можно условно показать с помощью представленной на рис. 1.2 структурной схемы. Экспертная система включает базу знаний и подсистемы: общения, объяснения, принятия решений, накопления знаний. Через подсистему общения с экспертной системой связаны: конечный пользователь; эксперт - высококвалифицированный специалист, опыт и знания которого намного превосходят знания и опыт рядового пользователя; инженер по знаниям, знакомый с принципами построения экспертной системы и умеющий работать с экспертами в данной области, владеющий специальными языками описания знаний.
Пользователь обращается к системе за советом по своей конкретной проблеме, сообщая ей имеющиеся в его распоряжении данные и возможные гипотезы (альтернативные варианты решений). Эксперт передает системе свои знания по исследуемой частной проблеме, а также общепринятые факты и правила вывода. Инженер по знаниям действует в данном случае в качестве посредника между экспертом и системой, помогая первому закодировать свои знания и проверяя работу законченной экспертной системы.
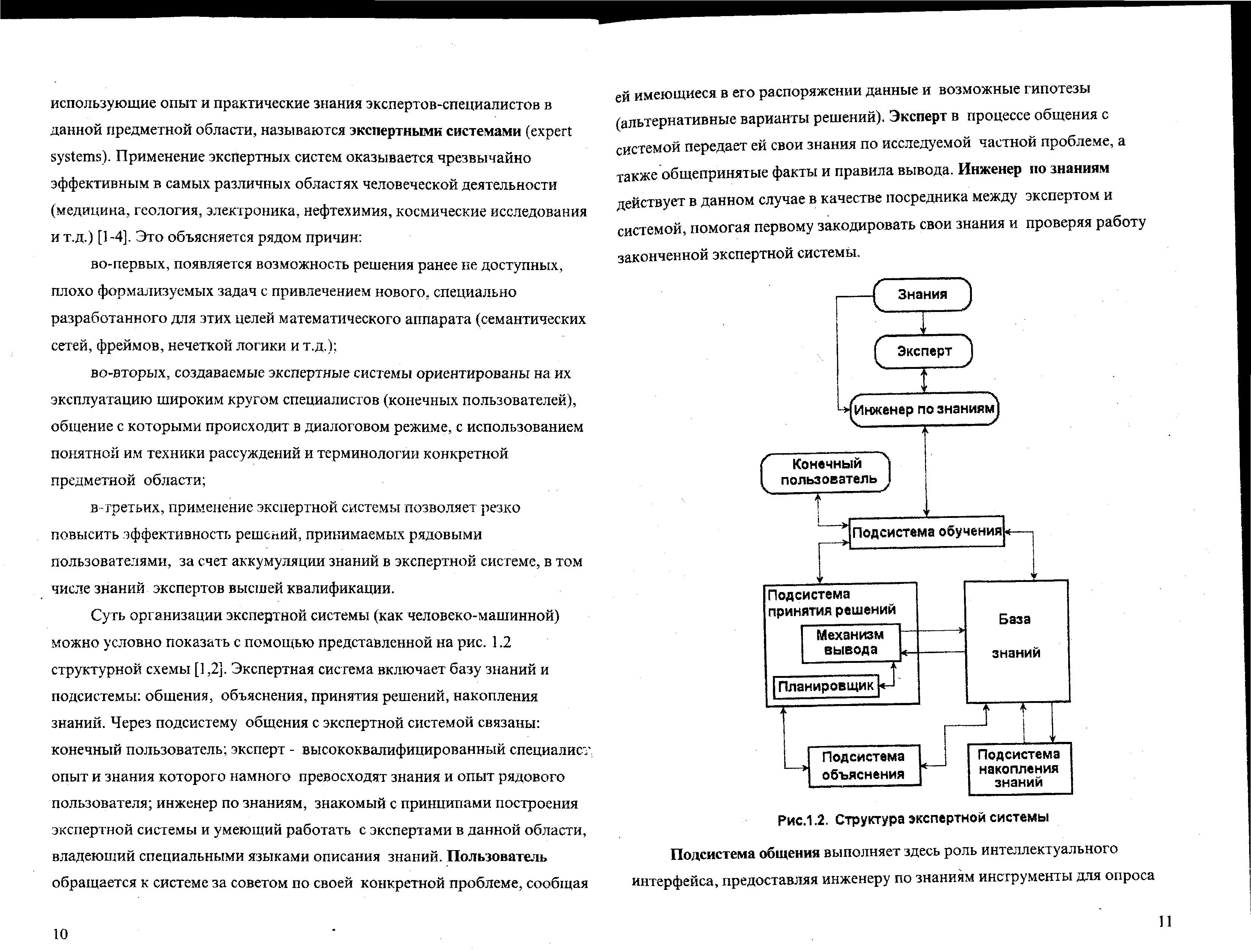
Рис.1.2. Структура экспертной системы
Одна из новых сфер применения экспертных систем – задачи управления сложными техническими объектами и процессами. Заметим, что традиционный подход к проектированию систем автоматического управления (САУ) сводится к выбору таких алгоритмов управления объектом (часто в рамках некоторых стандартных, например, ПИ (ПИД) - законов управления), которые обеспечили бы заданные требования к качеству установившихся и переходных режимов работы в условиях действия возмущений. Математическая модель объекта (процесса) при этом считается известной, что позволяет использовать на стадии синтеза алгоритмов управления (регулятора) хорошо разработанные методы оптимизации. Требования к качеству процессов управления задаются или в виде желаемых значений показателей качества САУ (порядок астатизма, время регулирования, перерегулирование и др.) или же в виде некоторых функционалов качества, подлежащих оптимизации.
В основе данного подхода лежит убеждение в том, что поведение любого объекта и системы можно достаточно точно описать математически, с помощью количественных зависимостей. Даже в тех случаях, когда речь идет о проектировании адаптивной САУ, математическая модель объекта управления, как правило, записывается в виде системы дифференциальных уравнений, включающих в себя, помимо переменных входа, выхода и состояния объекта, также источники «неопределенностей» (т.е. параметрические, сигнальные или структурные возмущения), удовлетворяющие определенным ограничениям. Вместе с тем выбор такой модели нередко производится на основе упрощенных представлений разработчика о функционировании системы, его стремлении подогнать результаты синтеза под имеющиеся модели и инструментальные средства проектирования, получить не "хорошую" систему, а "удобную" процедуру синтеза.
Очевидно, что применение экспертных систем, аккумулирующих знания и опыт экспертов-специалистов в данной предметной области, позволяет существенно повысить качество проектируемых систем управления. Возможны два варианта использования экспертных систем:
1) в качестве "советчика" на этапе проектирования САУ (режим off-line), предлагающего к рассмотрению большое число вариантов (альтернатив) построения регулятора и поясняющего преимущества или недостатки тех или иных решений;
2) включив ее непосредственно в контур управления объектом (процессом) и используя в режиме реального времени (on-line) в качестве "экспертного регулятора" (или "экспертно-управленческой" системы), заменяя, таким образом, традиционные цифровые регуляторы или дополняя их.
Если в первом из этих случаев проблема построения экспертной системы сводится к проблеме "инженерии знаний" (knowledge engineering), т.е. накопления, обобщения знаний экспертов и представления их в наиболее наглядной и удобной для пользователя форме, то цели и функции экспертной системы во втором случае уже совершенно иные.
На "экспертный регулятор" здесь возлагается задача оценки текущего состояния системы на основе информации, поступающей от датчиков, и выбора наиболее подходящей в данный момент стратегии управления, так же, как это делал бы опытный человек-оператор, хорошо представляющий себе особенности управления данным конкретным объектом или процессом. Системы управления 2-го типа, построенные на основе экспертных регуляторов, имитирующих действия человека-оператора в условиях неопределенности характеристик объекта и внешней среды, называются интеллектуальными системами управления (intelligent control systems).
Согласно другому аналогичному определению, интеллектуальной системой управления (ИСУ) является такая, которая обладает способностью понимать, рассуждать и изучать процессы, возмущения и условия функционирования. К изучаемым факторам при этом относятся, главным образом, характеристики процесса (статическое и динамическое поведение, характеристики возмущений, практика эксплуатации оборудования). Желательно, чтобы система сама накапливала эти знания, целенаправленно используя их для улучшения своих качественных характеристик.
Чтобы лучше понять принципы функционирования этих систем, рассмотрим возможную структуру ИСУ (рис. 1.3), предназначенной для управления гибкой производственной системой (ГПС) .
Гибкая производственная система (flexible manufacturing system) – это такой тип системы, которая объединяет совместно функционирующую в едином производственном процессе группу станков (или рабочих станций), управляемых с помощью ЭВМ и легко переналаживаемых под выпуск широкой номенклатуры изделий. Управление ГПС имеет свои особенности – частая смена заказов на выпуск продукции, большой объем перерабатываемой информации, динамически изменяющаяся внешняя среда.
Интеллектуальная система управления (рис.1.3) обеспечивает принятие рациональных, обоснованных решений по управлению ГПС на этапах планирования, выпуска конечной продукции и контроля за ходом производства.
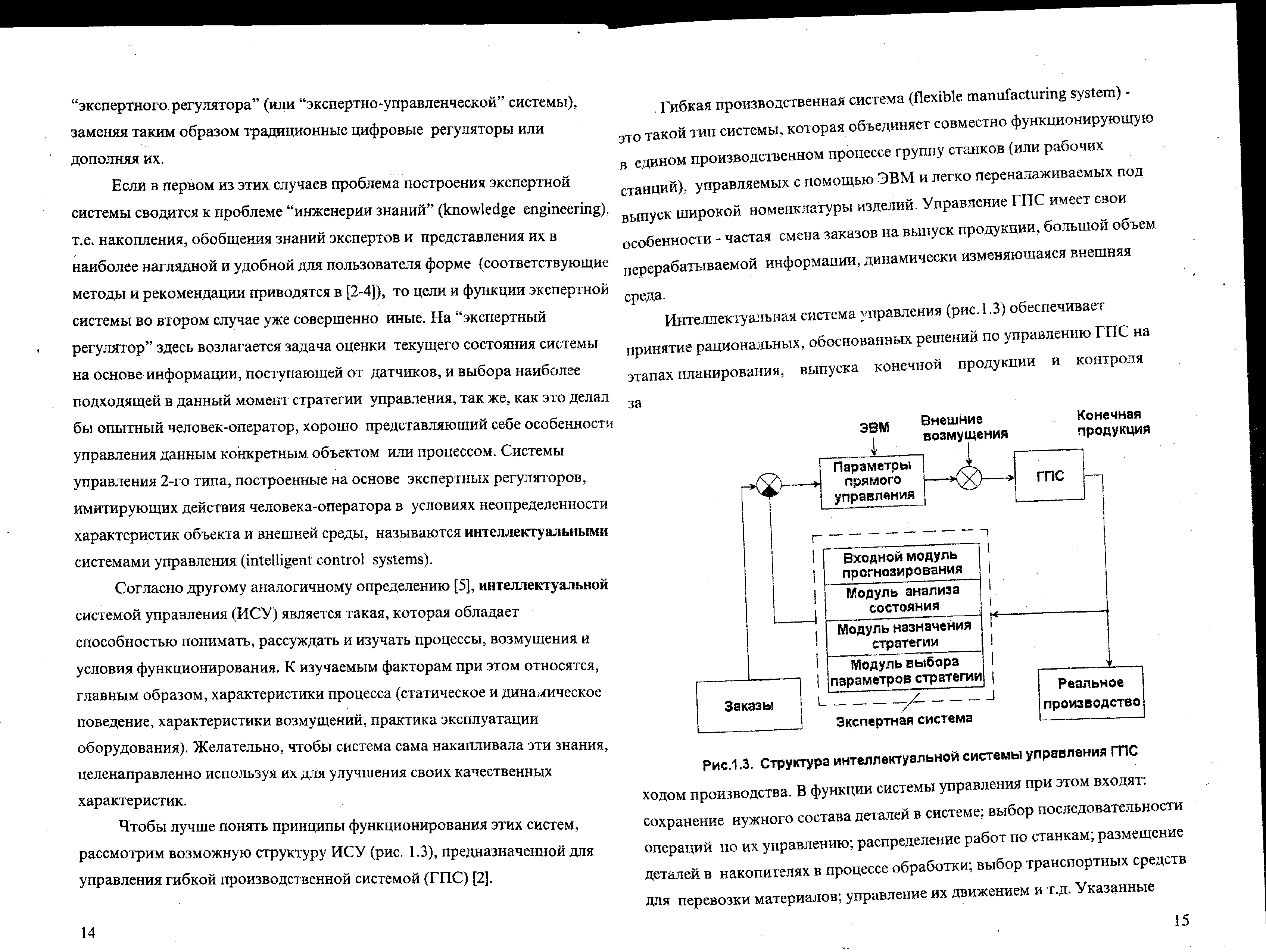
Рис.1.3. Структура интеллектуальной системы управления ГПС
В функции системы управления при этом входят: сохранение нужного состава деталей в системе; выбор последовательности операций по их управлению; распределение работ по станкам; размещение деталей в накопителях в процессе обработки; выбор транспортных средств для перевозки материалов; управление их движением и т.д.
Указанные задачи решаются в режиме прямого цифрового управления (on-line) с помощью специализированной ЭВМ, на которую возлагаются также функции по сбору информации о планируемых заказах, фактическом их исполнении, эффективности функционирования ГПС и по управлению вводом и выводом данных.
Экспертная система играет важную роль в процессе принятия решений, выполняя функции "интеллектуальной" обратной связи. В качестве основных модулей (компонент) в состав экспертной системы входят:
- модуль прогнозирования входных воздействий (МПВ), отвечающих за выполнение прогнозов тех внешних переменных, которые определяют требованиями производства и оказывают непосредственное влияние на график прохождения деталей, использование оборудования и т.д.;
- модуль анализа состояния системы (MAC), обеспечивающий моделирование поведения ГПС на основе входов, предсказанных МПВ, начального состояния системы и фиксированных параметров стратегии (т.е. способа) управления ГПС;
- модуль назначения стратегии (МНС), отвечающий за выбор наиболее пригодных для данной конкретной ситуации альтернатив из имеющегося множества стратегий управления:
- модуль выбора параметров стратегии (МПС), предназначенный для выбора конкретных значений параметров (числовых показателей), определяющих ту или иную стратегию управления.
Взаимодействие перечисленных выше компонент в составе ИСУ показано на рис. 1.4. В процессе работы данной системы используются как; формализованные, математические, методы (временного сглаживания, статистического прогнозирования, распознавания образов, поисковые методы оптимизации и др.), так и специфические, качественные, знания (know-how), полученные путем обработки мнений экспертов и накопленные в базе знаний. Последние включают в себя результаты, касающиеся реакций производственной системы на отдельные комбинации входных воздействий. Для определения частной стратегии управления применяется механизм логического вывода, т.е. набор определенных правил принятия решений с использованием накопленной информации о функционировании ГПС.
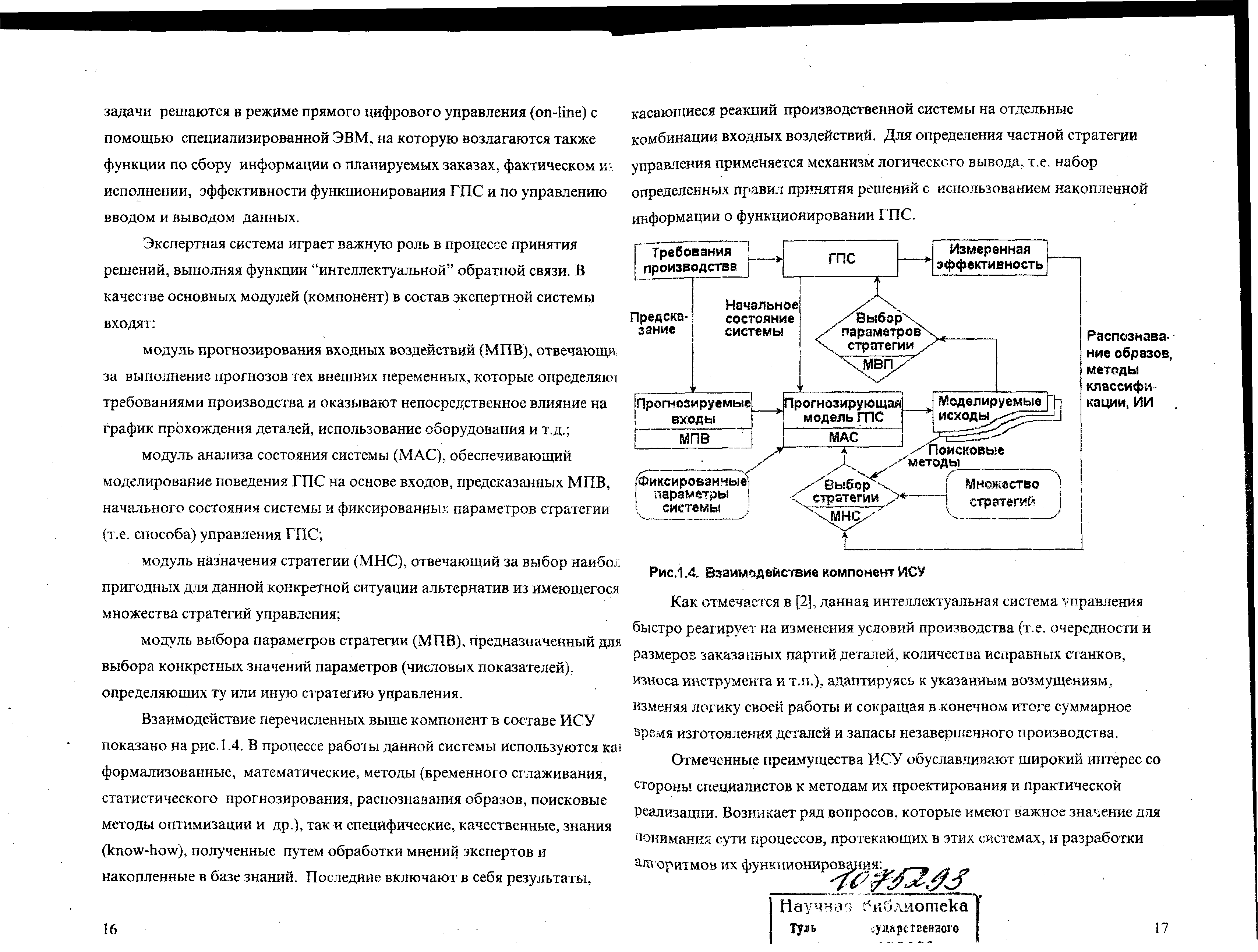
Рис.1.4. Взаимодействие компонент ИСУ
Данная интеллектуальная система управления быстро реагирует на изменения условий производства (очередности и размеров заказанных партий деталей, количества исправных станков, износа инструмента и т.п.), адаптируясь к указанным возмущениям, изменяя логику своей работы и сокращая в конечном итоге суммарное время изготовления деталей и запасы незавершенного производства.
Отмеченные преимущества ИСУ обуславливают широкий интерес со стороны специалистов к методам их проектирования и практической реализации. Возникает ряд вопросов, которые имеют важное значение для понимания сути процессов, протекающих в этих системах, и разработки алгоритмов их функционирования:
1. Существует ли формальный математический аппарат, пригодный для работы с нечеткими, качественными понятиями и суждениями экспертов, сформулированными ими на естественном языке?
2. Возможно ли с помощью данного математического аппарата построение специального механизма логического вывода? Насколько формализованными являются соответствующие процедуры принятия решений, каковы особенности их реализации в задачах управления?
3. К чему сводятся инженерные методики синтеза нетрадиционных алгоритмов управления сложными объектами, основанных на имитации механизмов поведения опытного человека-оператора (эксперта) в сходных ситуациях, в противовес классическим методам, базирующимся на использовании точных математических моделей?
4. Какова область наиболее эффективного применения интеллектуальных систем управления, разработанных с использованием соответствующих методик и алгоритмов? В чем перспектива их развития?
Ответы на эти вопросы даны в следующих лекциях.
Лекция 2. Нечеткая логика: история проблемы, практические приложения
Одним из создателей кибернетики Джоном фон Нейманом было замечено, что стремление получить точную, исчерпывающую модель для достаточно сложного объекта (процесса) не имеет смысла, поскольку сложность такого описания становится соизмеримой со сложностью самого объекта. Следовательно, использование такой модели не позволяет просто и наглядно объяснить механизм его функционирования, воспользоваться какими-либо стандартными математическими процедурами для исследования характеристик объекта и синтеза системы управления им. Это особенно относится к таким объектам управления, как производственные процессы, организационные, транспортные, биологические системы и др.
Известный специалист в области теории систем профессор факультета электротехники и информатики Калифорнийского университета (г. Беркли, США) Лотфи А. Заде сформулировал эту мысль в виде так называемого принципа несовместимости. Согласно этому принципу: "Чем сложнее система, тем менее мы способны дать точные и в то же время имеющие практическое значение суждения об ее поведении.
Для систем, сложность которых превосходит некоторый пороговый уровень, точность и практический смысл становятся почти исключающими друг друга характеристиками. Именно в этом смысле точный качественный анализ поведения гуманистических систем (т.е. систем, в которых участвует человек) не имеет, по-видимому, большого практического значения в реальных социальных, экономических и других задачах, связанных с участием одного человека или группы людей".
В большинстве случаев лица, принимающие решения, не могут формально представить себе этот процесс. И дело здесь не в том, что они плохо понимают то, что делают, а в том, что неопределенность (нечеткость) лежит в самой природе принятия решений.
Выражаясь словами того же Л.А.Заде, "в большинстве основных задач, решаемых человеком, не требуется высокая точность. Человеческий мозг использует допустимость такой неточности, кодируя информацию, "достаточную для задачи" (или "достаточную для решения"), элементами нечетких множеств, которые лишь приближенно описывают исходные данные.
Поток информации, поступающей в мозг через органы зрения, слуха, осязания и др., суживается, таким образом, в тонкую струйку информации, необходимой для решения поставленной задачи с минимальной степенью точности. Способность оперировать нечеткими множествами и вытекающая из нее способность оценивать информацию является одним из наиболее ценных качеств человеческого разума, которое фундаментальным образом отличает человеческий разум от так называемого машинного разума, приписываемого существующим вычислительным машинам. Наш мир состоит не из одних нулей и единиц – нам нужна более гибкая логика для того, чтобы представлять реальные взаимосвязи. Нужны подходы, для которых точность, строгость и математический формализм не являются чем-то абсолютно необходимым и в которых используется методологическая схема, допускающая нечеткости и частичные истины".
Классическая логика развивается с древнейших времен. Ее основоположником считается Аристотель. Логика известна нам как строгая и сугубо теоретическая наука, и большинство ученых (кроме разработчиков последних поколений компьютеров) продолжают придерживаться этого мнения. Вместе с тем классическая или булева логика имеет один существенный недостаток – с ее помощью невозможно описать ассоциативное мышление человека. Классическая логика оперирует только двумя понятиями: ИСТИНА и ЛОЖЬ, и исключая любые промежуточные значения. Аналогично этому булева логика не признает ничего кроме единиц и нулей.
Все это хорошо для вычислительных машин, но попробуйте представить весь окружающий вас мир только в черном и белом цвете, вдобавок исключив из языка любые ответы на вопросы, кроме ДА и НЕТ. В такой ситуации вам можно только посочувствовать.
Решить эту проблему и призвана нечеткая логика. С термином «лингвистическая переменная» можно связать любую физическую величину, для которой нужно иметь больше значений, чем только ДА и НЕТ. В этом случае вы определяете необходимое число термов и каждому из них ставите в соответствие некоторое значение описываемой физической величины. Для этого значения степень принадлежности физической величины к терму будет равна единице, а для всех остальных значений - в зависимости от выбранной функции принадлежности. Например, можно ввести переменную ВОЗРАСТ и определить для нее термы ЮНОШЕСКИЙ, СРЕДНИЙ и ПРЕКЛОННЫЙ. Обсудив с экспертами значения конкретного возраста для каждого терма, вы с полной уверенностью можете избавиться от жестких ограничений логики Аристотеля.
Получившие наибольшее развитие из всех разработок искусственного интеллекта, экспертные системы завоевали устойчивое признание в качестве систем поддержки принятия решений. Подобные системы способны аккумулировать знания, полученные человеком в различных областях деятельности. Посредством экспертных систем удается решить многие современные задачи, в том числе и задачи управления. Однако большинство систем все еще сильно зависит от классической логики.
Одним из основных методов представления знаний в экспертных системах являются продукционные правила, позволяющие приблизиться к стилю мышления человека. Любое правило продукций состоит из посылок и заключения. Возможно наличие нескольких посылок в правиле, в этом случае они объединяются посредством логических связок И, ИЛИ. Обычно продукционное правило записывается в виде:
«ЕСЛИ (посылка) (связка) (посылка)… (посылка) ТО (заключение)».
Главным же недостатком продукционных систем остается то, что для их функционирования требуется наличие полной информации о системе.
Нечеткие системы тоже основаны на правилах продукционного типа, однако в качестве посылки и заключения в правиле используются лингвистические переменные, что позволяет избежать ограничений, присущих классическим продукционным правилам.
Первой работой, заложившей основы нового подхода к анализу сложных систем и процессов принятия решений была опубликованная в 1964 г. статья американского профессора Л.А.Заде. Суть данного подхода, получившего название нечеткой логики (Fuzzy Logic), заключается в следующем: 1) в нем используются так называемые "лингвистические'' переменные вместо обычных числовых переменных или в дополнение к ним; 2) простые отношения между переменными описываются с помощью нечетких высказываний; 3) сложные отношения описываются нечеткими алгоритмами.
Предложенные идеи, в силу своей нацеленности на моделирование процессов принятия решений в условиях неопределенности, нашли много сторонников и получили широкое распространение в качестве инструмента для построения реальных систем ИИ. На вопрос "Что такое нечеткая логика?" дается следующий ответ: "Это технология, которая обеспечивает разработку систем с помощью интуиции и инженерных знаний "know-how". Нечеткая логика использует понятия повседневной речи для определения поведения системы. Она дает возможность построения робастных, отказоустойчивых систем".
Несмотря на огромный поток публикаций в данной области (например, с 1965 г. по 1993 г. опубликовано свыше 30 000 работ по данной теме, с 1978 г. издается журнал "Fuzzy Sets and Systems" – официальный орган Международной ассоциации нечетких систем (IFSA)), идеи нечеткой логики имеют и своих противников.
Так, известный американский математик, специалист в области теории систем Р.Е. Калман (1972) пишет: "Наиболее серьезные возражения против выдвигаемой профессором Заде идеи "нечеткого" анализа систем заключаются в том, что недостаток методов системного анализа вовсе не является принципиальной проблемой в теории систем. Эта проблема должна решаться на основе развития существующих концепций и более глубокого изучения природы систем, возможно, отыскания для них нечто вроде "законов" Ньютона. По моему мнению, предложения Заде не имеют никаких шансов, чтобы способствовать решению этой важной проблемы".
Л.А.Заде считал это сопротивление "принципом молотка": "Если человек держит в руке молоток и это единственный в его распоряжении инструмент, то ему везде видится гвоздь".
Общеизвестно, что практика – критерий истины. Еще в 1983 г. японская фирма «Фуджи Электрик» реализовала на основе нечетких алгоритмов управления установку для обработки питьевой воды. В 1987 г. запущена в производство система управления новым метро в г. Сендаи, около Токио, предложенная на аналогичных принципах фирмой «Хитачи». В 1991 г. Япония экспортировала в общей сложности более чем на 25 млрд. долларов товаров, в которых тем или иным образом использовались компоненты нечеткой логики. Это, в первую очередь, товары культурно-бытового назначения – фотоаппараты, видеокамеры, стиральные машины, холодильники, пылесосы, микроволновые печи и многое другое.
Таким образом, технология, почти не замеченная всем миром, в Японии превратилась в одну из ключевых технологий, что сразу привлекло к себе огромное внимание. Сегодня многие ведущие компании США, Германии, Франции и ряда других стран предлагают самые разнообразные товары и системы с использованием принципов нечеткой логики, осваивая все новые и новые области применения.
Вместе с тем, по оценкам европейских ученых, Япония значительно опережает в развитии своих ближайших конкурентов в этом направлении.
В Калифорнийском университете Л.А.Заде организовал лабораторию, получившую название "Берклийская Инициатива в области гибких вычислений" (Berkley -Initiative in Soft- Computing"), которая также поставила своей целью разработку "нечетких" технологий.
В последнее время нечеткая технология завоевывает все больше сторонников среди разработчиков систем управления. За прошедшее время нечеткая логика прошла путь от почти антинаучной теории, практически отвергнутой в Европе и США, до банальной ситуации конца девяностых годов, когда в Японии в широком ассортименте появились «нечеткие» бритвы, пылесосы, фотокамеры.
Сам термин «fuzzy» так прочно вошел в жизнь, что на многих языках он даже не переводится. В России в качестве примера можно вспомнить рекламу стиральных машин и микроволновых печей фирмы Samsung, обладающих искусственным интеллектом на основе нечеткой логики.
Тем
не менее, столь масштабный скачок в
развитии нечетких систем управления
не случаен. Простота и дешевизна их
разработки заставляет проектировщиков
все чаще п рибегать
к этой технологии. Бурный рост рынка
нечетких систем показан на рис. 1. После
поистине взрывного старта прикладных
нечетких систем в Японии многие
разработчики США и Европы наконец-то
обратили внимание на эту технологию.
Но время было упущено, и мировым лидером
в области нечетких систем стала Страна
восходящего солнца, где к концу 1980-х
годов был налажен выпуск специализированных
нечетких контроллеров, выполненных по
технологии СБИС.
рибегать
к этой технологии. Бурный рост рынка
нечетких систем показан на рис. 1. После
поистине взрывного старта прикладных
нечетких систем в Японии многие
разработчики США и Европы наконец-то
обратили внимание на эту технологию.
Но время было упущено, и мировым лидером
в области нечетких систем стала Страна
восходящего солнца, где к концу 1980-х
годов был налажен выпуск специализированных
нечетких контроллеров, выполненных по
технологии СБИС.
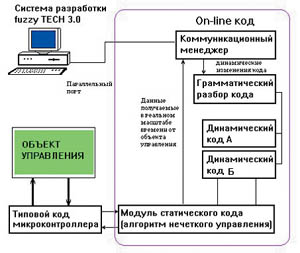
В такой ситуации Intel нашла поистине гениальное решение. Имея большое количество разнообразных контроллеров от MCS-51 до MCS-96, которые на протяжении многих лет успешно использовались во многих приложениях, корпорация решила создать средство разработки приложений на базе этих контроллеров, но с использованием технологии нечеткости. Это позволило избежать значительных затрат на конструирование собственных нечетких контроллеров, а система от Intel, получившая название fuzzy TECH, завоевала огромную популярность не только в США и Европе, но и прорвалась на японский рынок.
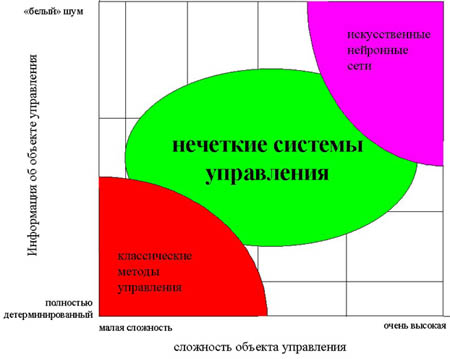
На рис. 2 показаны области наиболее эффективного применения современных технологий управления. Как видно, классические методы управления хорошо работают при полностью детерминированном объекте управления и детерминированной среде, а для систем с неполной информацией и высокой сложностью объекта управления оптимальными являются нечеткие методы управления. В правом верхнем углу рисунка приведена еще одна современная технология управления – с применением искусственных нейронных сетей.
Процесс разработки проекта нечеткой системы управления на fuzzy TECH разбивается, на четыре основных этапа. Все они схематично показаны на рис. 3.
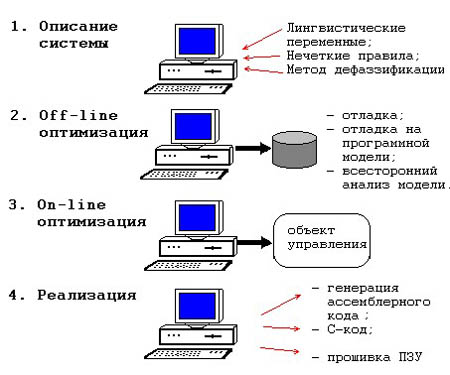
Этап 1. Описание системы
На этом этапе при помощи средств, доступных в fuzzy TECH, задача формализуется. Здесь необходимо описать лингвистические переменные, которые вы будете использовать; их функции принадлежности; описать стратегию управления посредством нечетких правил, которые вы сможете объединить в единую базу правил или знаний о системе. В целом CASE-технология, на основе которой построен пакет, позволяет все эти действия выполнить только посредством общения с экраном ЭВМ, не заглядывая в программный код. Поэтому начальный этап проектирования вы воспримете с легкостью, несмотря на кажущуюся сложность.
Этап 2. Off-line-оптимизация
На этом этапе следует проверить работоспособность созданной системы посредством всех средств fuzzy TECH. Отметим, что можно использовать заранее созданный программный симулятор вашего объекта управления. Для связи системы управления с моделью используется специально разработанный протокол связи fTlink, в основу которого положена концепция обмена сообщениями Windows. Все необходимые средства для установления связи с вашей моделью находятся в исходных текстах программ связи, поставляемых с пакетом.
Этап 3. On-line-оптимизация
На этом шаге разрабатываемая система управления и реальный объект управления соединяются физической линией связи.
Такой вид отладки позволяет наблюдать поведение системы в реальных условиях и при необходимости вносить изменения в систему управления.
Этап 4. Реализация
На этом этапе необходимо получить окончательный вариант кода для конкретного микроконтроллера и, если нужно, связать его с вашей основной программой. Об оптимальности создаваемого fuzzy TECH кода можно судить по данным табл. ниже.
Основу программного кода, генерируемого пакетом fuzzy TECH, составляет аппаратно-ориентированное на конкретный тип процессора ядро. Поставляемое с пакетом fuzzy TECH MCU-96 программное ядро совместимо с такими контроллерами, как 8096BH, 8096-90, 80196KB/KC/KD, 80196 KR, 80196MC, 80196NT/NQ.
Полагая, что приведенные аргументы достаточно убедительно свидетельствуют о практической ценности и перспективах применения данного подхода в самых различных сферах народного хозяйства, перейдем к более подробному изложению математических основ нечеткой логики.
Лекция №3. МАТЕМАТИЧЕСКИЙ АППАРАТ ПРИНЯТИЯ РЕШЕНИЙ НА ОСНОВЕ НЕЧЕТКОЙ ЛОГИКИ.
Нечеткие множества и лингвистические переменные
Термин "нечеткое множество" (fuzzy set) был впервые введен в уже упоминавшейся классической работе Л.А.Заде. Прежде чем дать строгое толкование этого понятия, обратимся к следующему примеру.
Допустим,
что объектом нашего исследования
является множество "взрослых
людей", к которому формально можно
отнести всех людей, достигших
совершеннолетия (18 лет). Если обозначить
через переменную
![]() "возраст
человека", а функцию
"возраст
человека", а функцию
![]() задать
следующим образом:
задать
следующим образом:
![]()
то множество "взрослых людей" А может быть задано с помощью выражения
![]()
где X - множество всех возможных значений .
Другими
словами, множество
А
образуют такие "объекты" ("элементы"),
для которых указанная
выше функция
,
называемая функцией
принадлежности
(membership
function),
принимает значение 1 (см. верхнюю ветвь
графика, выделенного
сплошной линией, на рис.2.1.). Напротив,
те значения
![]() ,
для
которых
,
для
которых
![]() ,
не принадлежат множеству А.
,
не принадлежат множеству А.
В
то же время, очевидно, что двузначная
логика (типа "да" - "нет"),
определяемая
функцией принадлежности
:
![]() ,
не учитывает возможного
разброса мнений различных субъектов
относительно границ исследуемого
множества А,
влияния чисто биологических факторов,
национальных
особенностей и т. д.
,
не учитывает возможного
разброса мнений различных субъектов
относительно границ исследуемого
множества А,
влияния чисто биологических факторов,
национальных
особенностей и т. д.
Поэтому более естественным является задание функции принадлежности в виде некоторой непрерывной зависимости (пунктирная кривая на рис.2.1), определяющей плавный переход

Рис.2.1. Графическое представление множества "взрослых людей"
из одного крайнего состояния в другое (т.е. от принадлежности элементов рассматриваемому множеству до непринадлежности ему).
В данном случае функция принадлежности : ставит в соответствие каждому элементу число из интервала [0;1], описывающее степень принадлежности элемента множеству А. Заданное таким образом множество пар
![]()
называется нечетким (или размытым) множеством.
Перечислим основные свойства нечетких множеств. Будем называть носителем А множество тех его элементов , для которых положительна:
![]()
Точка
перехода А
– это элемент
множества А, для которого
![]() .
.
Срез
![]() нечеткого множества А
– множество элементов
,
для которых
функция принадлежности
принимает значения не меньше заданного
числа
(
нечеткого множества А
– множество элементов
,
для которых
функция принадлежности
принимает значения не меньше заданного
числа
(![]() ):
):
![]()
Высота нечеткого множества А находится как точная верхняя грань (максимум) его функции принадлежности:
![]()
Если
высота нечеткого множества равна 1, то
такое множество называется
нормализованным.
В том случае, когда высота нечеткого
множества
А
меньше 1 (такое множество называется
субнормальным), можно
осуществить переход к нормализованному
множеству путем деления
его функции принадлежности
на
высоту
![]() .
.
Если носитель нечеткого множества А состоит из единственной точки , то такое множество называется одноточечным (singleton). Данное одноточечное множество обычно записывают в виде
![]()
где
![]() -
степень принадлежности х
множеству А.
-
степень принадлежности х
множеству А.
Если носитель А состоит из конечного числа элементов, то для записи такого дискретного множества используется выражение
![]() ,
или
,
или
![]()
где
числа
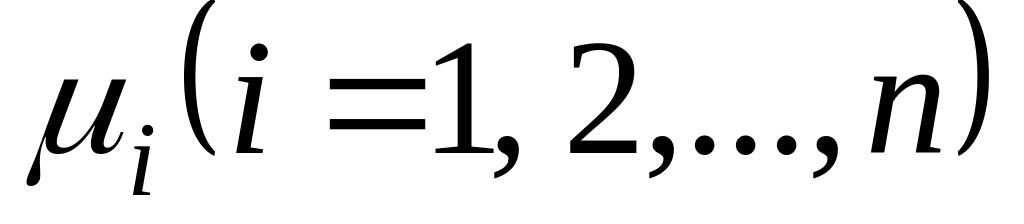 - степени принадлежности элементов
- степени принадлежности элементов
![]() множеству А.
множеству А.
Заметим, что знак "плюс" в (2.6) обозначает объединение, а не арифметическое суммирование. Обычное (четкое) дискретное множество при такой форме записи можно представить в виде
![]() или
или
![]()
Возможен и табличный способ задания нечеткого множества А. Например, таблица

обозначает,
что носитель А
состоит из 5 элементов:
![]()
![]()
![]()
![]()
![]() степени принадлежности которых множеству
А
равны соответственно:
0,1; 0,3; 0,5; 0,8 и 1,0.
степени принадлежности которых множеству
А
равны соответственно:
0,1; 0,3; 0,5; 0,8 и 1,0.
Если
носитель нечеткого множества А
состоит из бесконечного числа точек,
например, представляет собой некоторый
интервал (а,
в)
на числовой
оси х,
то функция принадлежности
![]() обычно задается графически
или в виде аналитической зависимости.
обычно задается графически
или в виде аналитической зависимости.
Рассмотрим
пример.
Допустим, что для косвенного измерения
скорости вращения
вала нагруженного электропривода
используется выходное напряжение
генератора постоянного тока. Известно
значение этого напряжения
![]() .
Кроме того, известно, что ошибка такого
измерения составляет ±1 В. Тогда переход
от четкого значения
.
Кроме того, известно, что ошибка такого
измерения составляет ±1 В. Тогда переход
от четкого значения
![]() к нечеткому множеству
"х
равно приблизительно 5" осуществляется
следующим образом (рис.2.2).
к нечеткому множеству
"х
равно приблизительно 5" осуществляется
следующим образом (рис.2.2).
Функция принадлежности , приведенная на рис.2.2,в, описывается выражением
![]()
Рис.2.2. Построение функции принадлежности
Представленный на рис.2.2, а - в процесс перехода от четкого (т.е. измеренного) значения х = 5 к его "нечеткой" интерпретации х = "приблизительно 5" называется фаззификацией (fuzzyfication).
Вопрос о том, как выбирается (или задается) в каждом конкретном случае функция принадлежности и какой она имеет смысл, остается в значительной степени спорным и мало изученным. Наиболее распространенным является мнение, что может рассматриваться как "субъективная вероятность" или как "коэффициент уверенности" эксперта в том, что элемент х принадлежит множеству А.
Одним из ключевых понятий нечеткой логики является понятие лингвистической переменной. Суть данного понятия состоит в том, что конкретные значения числовой переменной х обычно подвергаются субъективной оценке человеком, причем результат такой оценки выражается на естественном языке.
Так, переменная "Рост (высота) человека" может характеризоваться одним из следующих термов (terms), т.е. сжатых словесных описаний: "маленький", "невысокий", "среднего роста", "высокий". Другая переменная – "Скорость движения автомобиля" – может быть "малой", "средней", "большой" и т.д. Каждый из приведенных здесь термов может рассматриваться как символ некоторого нечеткого подмножества в составе полного множества значений х. Переменные, значениями которых являются термы (слова, фразы, предложения), выраженные на естественном языке, называют лингвистическими переменными (linguistic variables).
Задать
нечеткое подмножество
![]() ,
соответствующее определенному i-му
терму (значению) лингвистической
переменной, – это значит задать область
определения числовой переменной х
и функцию принадлежности элемента
х
подмножеству
.
,
соответствующее определенному i-му
терму (значению) лингвистической
переменной, – это значит задать область
определения числовой переменной х
и функцию принадлежности элемента
х
подмножеству
.
Пример 1. Рассмотрим лингвистическую переменную "Яркость" изображения. Будем полагать, что различные значения физической переменной х яркости (единица измерения кд/м2) могут быть охарактеризованы набором из 5 нечетких подмножеств (значений лингвистической переменной):
{"Очень темно", "Темно", "Средне", "Светло", "Очень светло"}.
На
рис.2.3 показаны функции принадлежности
для каждого из этих подмножеств.
Допустим, что фактическое значение
яркости равно 5,5 кд/м2.
Тогда, в соответствии с рис.2.3, это
значение относится одновременно
к двум термам (подмножествам) - "Средне"
и "Светло" - со степенями
принадлежности
![]() и
и
![]() соответственно.
соответственно.
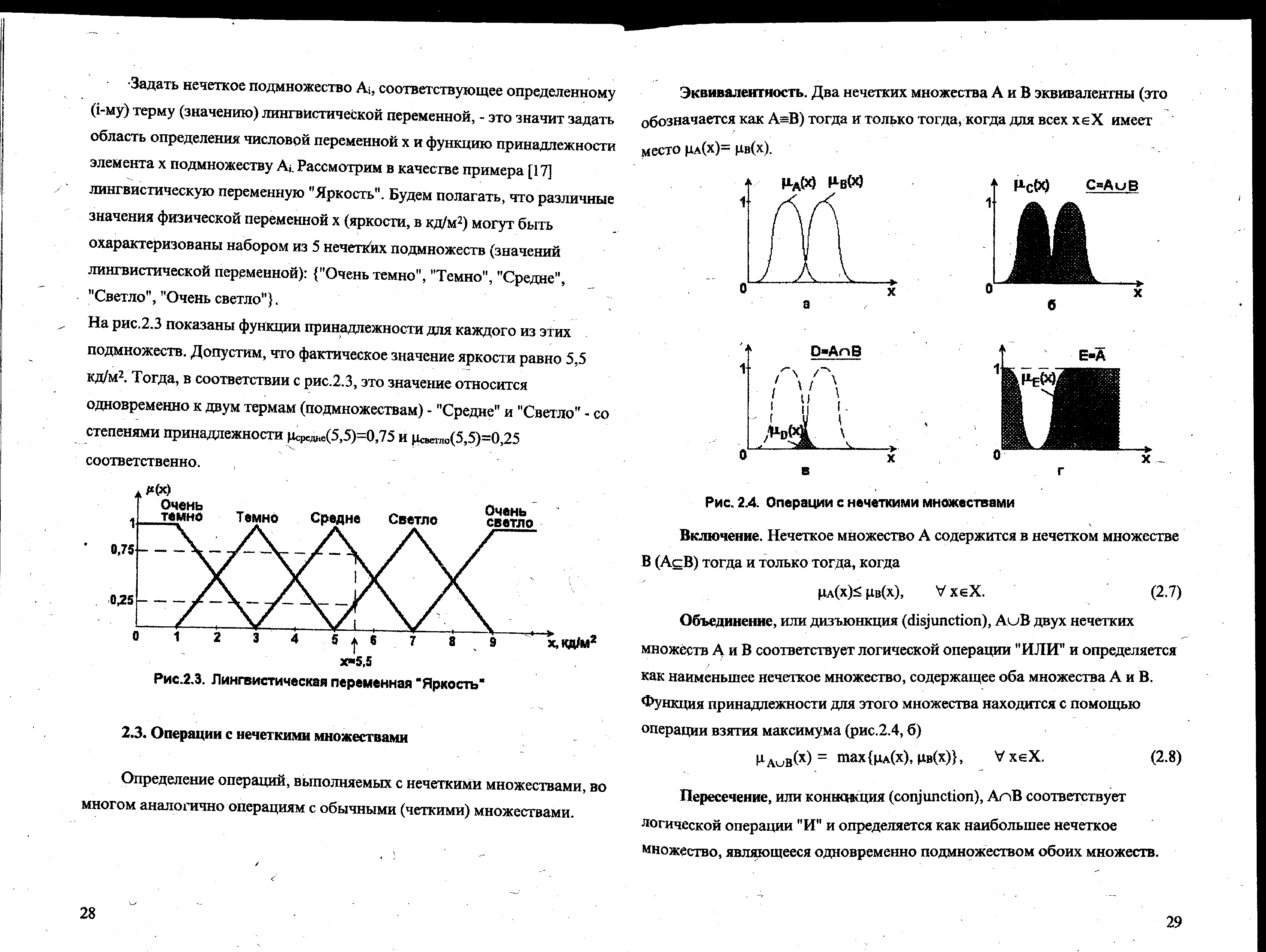
Рис.2.3. Лингвистическая переменная "Яркость"
Пример 2. Рассмотрим процедуру фаззификации (перехода к нечеткости) на примере поставляемой с пакетом fuzzy TECH модели контейнерного крана.
Пусть вам, как маститому крановщику, необходимо перегрузить контейнер с баржи на железнодорожную платформу. Вы управляете мощностью двигателя тележки крана, заставляя ее двигаться быстрее или медленнее. От скорости перемещения тележки, в свою очередь, зависит расстояние до цели и амплитуда колебания контейнера на тросе.
Вследствие того, что стратегия управления краном сильно зависит от положения тележки, применение стандартных контроллеров для этой задачи весьма затруднительно. Вместе с тем математическая модель движения груза, состоящая из нескольких дифференциальных уравнений, может быть составлена довольно легко, но для ее решения при различных исходных данных потребуется довольно много времени. К тому же исполняемый код программы будет большим и не поворотливым.
Нечеткая система справляется с такой задачей очень быстро – несмотря на то, что вместо сложных дифференциальных уравнений движения груза весь процесс движения описывается терминами естественного языка: «больше», «средне», «немного» и т. п. То есть так, будто вы даете указания своему товарищу, сидящему за рычагами управления.
В процессе фаззификации точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения положений теории нечетких множеств, а именно – при помощи определенных функций принадлежности.
В нечеткой логике значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 м. Каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ.
Расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами.
При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины.
В настоящее время сложилось мнение, что для большинства приложений достаточно 3 - 7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
Дадим два совета, которые помогут в определении числа термов:
- исходите из стоящей перед вами задачи и необходимой точности описания, помните, что для большинства приложений вполне достаточно трех термов в переменной;
- составляемые нечеткие правила функционирования системы должны быть понятны, вы не должны испытывать существенных трудностей при их разработке; в противном случае, если не хватает словарного запаса в термах, следует увеличить их число.
Как уже говорилось, принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рис.).
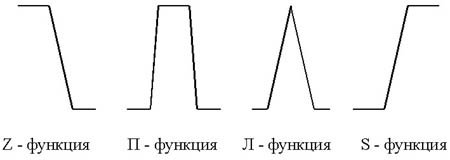
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Подведем некоторый итог этапа фаззификации и дадим некое подобие алгоритма по формализации задачи в терминах нечеткой логики.
Шаг 1. Для каждого терма взятой лингвистической переменной найти числовое значение или диапазон значений, наилучшим образом характеризующих данный терм. Так как это значение или значения являются «прототипом» нашего терма, то для них выбирается единичное значение функции принадлежности.
Шаг 2. После определения значений с единичной принадлежностью необходимо определить значение параметра с принадлежностью «0» к данному терму. Это значение может быть выбрано как значение с принадлежностью «1» к другому терму из числа определенных ранее.
Шаг 3. После определения экстремальных значений нужно определить промежуточные значения. Для них выбираются П- или Л-функции из числа стандартных функций принадлежности.
Шаг 4. Для значений, соответствующих экстремальным значениям параметра, выбираются S- или Z-функции принадлежности.
Лекция № 4. Операции с нечеткими множествами
Определение операций, выполняемых с нечеткими множествами, во многом аналогично операциям с обычными (четкими) множествами.
Эквивалентность.
Два нечетких множества А
и В
эквивалентны (это
обозначается
как
![]() )
тогда и только тогда, когда для всех
имеет место
)
тогда и только тогда, когда для всех
имеет место
![]() .
.
Рис. 2.4. Операции с нечеткими множествами
Включение.
Нечеткое
множество А
содержится в нечетком множестве В
(![]() )
тогда и только тогда, когда
)
тогда и только тогда, когда
![]()
Объединение,
или
дизъюнкция
(disjunction),
![]() двух нечетких множеств А и В соответствует
логической операции "ИЛИ"
и определяется как наименьшее нечеткое
множество, содержащее оба множества А
и В. Функция
принадлежности для этого множества
находится с помощью операции взятия
максимума
(рис.2.4,
б)
двух нечетких множеств А и В соответствует
логической операции "ИЛИ"
и определяется как наименьшее нечеткое
множество, содержащее оба множества А
и В. Функция
принадлежности для этого множества
находится с помощью операции взятия
максимума
(рис.2.4,
б)
![]()
Пересечение,
или конъюнкция
(conjunction),
![]() соответствует логической операции "И"
и определяется как наибольшее нечеткое
множество,
являющееся одновременно подмножеством
обоих множеств.
соответствует логической операции "И"
и определяется как наибольшее нечеткое
множество,
являющееся одновременно подмножеством
обоих множеств.
Функция принадлежности множества выражается с помощью операции нахождения минимума (рис. 2.4,в)
![]()
Дополнение
(complement) нечеткого множества А,
обозначаемое через
![]() (или ¯| А), соответствует логическому
отрицанию "НЕ"
и определяется формулой (рис. 2.4,г)
(или ¯| А), соответствует логическому
отрицанию "НЕ"
и определяется формулой (рис. 2.4,г)
![]()
Легко видеть, что применительно к классическим "четким" множествам, для которых функции принадлежности принимают только 2 значения: 0 или 1, формулы определяют известные операции логического "ИЛИ", "И", "НЕ".
Приведем определения еще двух достаточно распространенных операций над нечеткими множествами – алгебраического произведения и алгебраической суммы нечетких множеств.
Алгебраическое произведение АВ нечетких множеств А и В определяется следующим образом:
![]()
Алгебраическая
сумма
![]() :
:
![]()
Кроме перечисленных имеются и другие операции, которые оказываются полезными при работе с лингвистическими переменными.
Операция
концентрации
(concentration) CON(А) определяется как
алгебраическое произведение нечеткого
множества А
на самого себя:
![]() т.е.
т.е.
![]()
В
результате применения этой операции к
множеству А
уменьшаются степени принадлежности
элементов х
этому множеству, причем если
![]() ,
то это уменьшение относительно мало, а
для элементов с малой степенью
принадлежности - относительно велико.
В естественном языке применение этой
операции к тому или иному значению
лингвистической переменной А соответствует
использованию усиливающего терма
"очень" (например, "очень высокий",
"очень старый" и т.д.).
,
то это уменьшение относительно мало, а
для элементов с малой степенью
принадлежности - относительно велико.
В естественном языке применение этой
операции к тому или иному значению
лингвистической переменной А соответствует
использованию усиливающего терма
"очень" (например, "очень высокий",
"очень старый" и т.д.).
Операция растяжения (dilation) DIL(A) определяется как
DIL(A)=A0,5,
где![]()
Действие этой операции противоположно действию операции концентрации и соответствует неопределенному терму "довольно", выполняющему функцию ослабления следующего за ним (основного) терма А: "довольно высокий", "довольно старый" и т.п.
Можно ввести и другие аналогичные по смыслу операции, позволяющие модифицировать значения лингвистической переменной, увеличивая, таким образом, их количество. Так, терм "более чем" можно определить следующим образом:
![]() ,
,
составной терм "очень-очень":
![]()
Рассмотрим применение указанных операций на следующем наглядном примере. Пусть переменная х характеризует "возраст человека", X - интервал [0,100]. Тогда нечеткие подмножества, описываемые термами "молодой" и "старый", можно представить с помощью функции принадлежности (рис. 2.5).
![]()
![]()
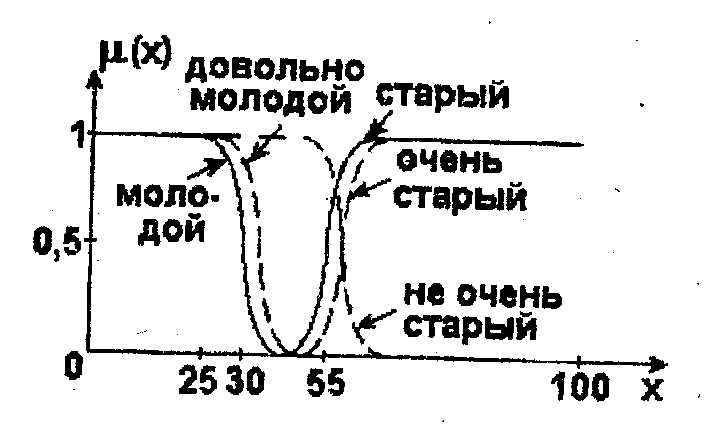
Рис. 2.5. Графическое представление лингвистической переменной “возраст человека"
Тогда, в соответствии с выражением, находим (рис. 2.5)
![]()
Точно так же, используя (2.10) и (2.14), получаем (рис. 2.5)
![]()
![]()
Например, если конкретному человеку исполнилось 55 лет (т.е. х = 55), то в соответствии с данными функциями принадлежности имеем:
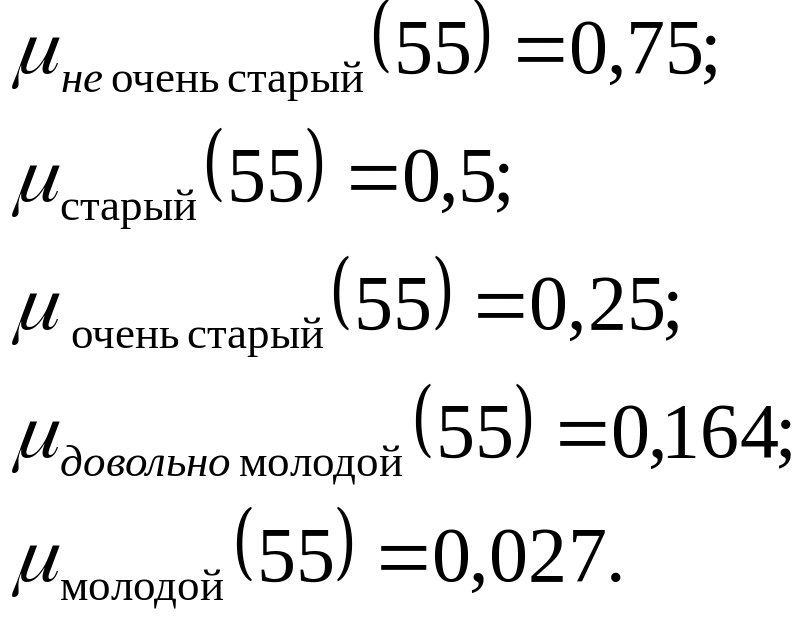
До сих пор предполагалось, что речь идет о единственной переменной , принимающей значения на вещественной числовой оси.
Для
случая двух вещественных переменных
(
и
![]() )
можно говорить о нечетком
отношении
R: X→Y,
которое определяет некоторое соответствие
между элементами множества X и множества
У с помощью двумерной функции принадлежности
μ(х,у):
)
можно говорить о нечетком
отношении
R: X→Y,
которое определяет некоторое соответствие
между элементами множества X и множества
У с помощью двумерной функции принадлежности
μ(х,у):
![]()
Приведем еще один пример.
Допустим, что мы имеем два набора чисел
![]()
и пусть субъективные мнения экспертов о сравнительной величине этих чисел представлены в виде нечетких отношений:
R1(x,y) = "x больше, чем у",
R2(x,y) = "x приблизительно равно у".
Зададим отношение R1 с помощью табл.2.1, а отношение R2 - с помощью табл. 2.2.
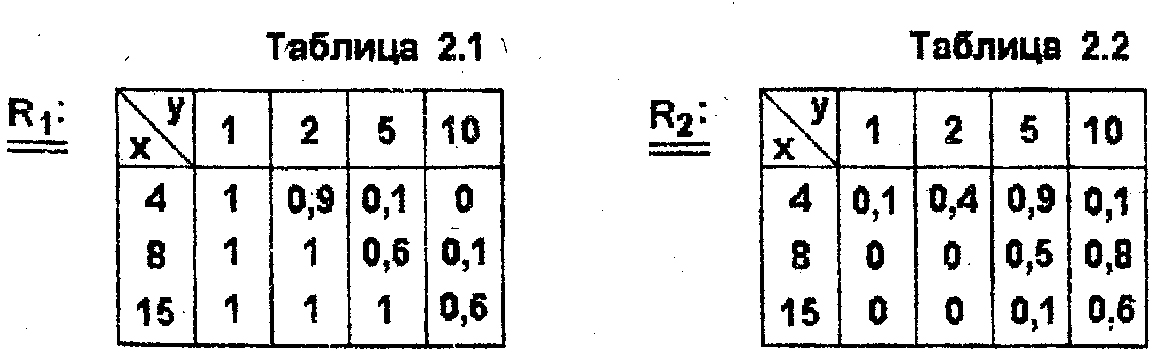
Здесь (i,j) - й элемент таблицы равен значению соответствующей функции принадлежности для i-го значения х и j-гo значения у. Тогда операции объединения и пересечения указанных отношений могут быть интерпретированы как
![]()
Функции
принадлежности
![]() и
и
![]() с помощью операций нахождения максимума
и минимума, и принимают вид табл. 2.3, 2.4.
с помощью операций нахождения максимума
и минимума, и принимают вид табл. 2.3, 2.4.

Лекция № 5. Нечеткие алгоритмы
Понятие нечеткого алгоритма, впервые введенное Л.А. Заде, является важным инструментом для приближенного анализа сложных систем и процессов принятия решений. Под нечетким алгоритмом (fuzzy algorithm) понимается упорядоченное множество нечетких инструкций (правил), в формулировке которых содержатся нечеткие указания (термы).
Например, нечеткие алгоритмы могут включать в себя инструкции типа:
а) "х = очень малое";
б) "х приблизительно равно 5";
в) "слегка увеличить х";
г) "ЕСЛИ х - в интервале [4,9; 5,1], ТО выбрать у в интервале [9,9; 10,1]";
д) "ЕСЛИ х - малое, ТО у - большое, ИНАЧЕ у - не большое". Использованные здесь термы "очень малое", "приблизительно равно", "слегка увеличить", "выбрать в интервале" и т.п. отражают неточность представления исходных данных и неопределенность, присущую самому процессу принятия решений.
Две последние инструкции (г-д) представляют собой правила (или нечеткие высказывания), построенные по схеме логической импликации "ЕСЛИ-ТО", где условие "ЕСЛИ" соответствует принятию лингвистической переменной х некоторого значения А, а вывод (действие) "ТО" означает необходимость выбора значения В для лингвистической переменной у:
(х = А)→(у = В).
Указанные правила получили широкое распространение в технике. Механизм построения правил принятия решений в конкретной задаче выглядит при этом следующим образом. На основе заданной цели (рис.2.6) с помощью механизма упрощения, позволяющего выделить наиболее существенные и отсечь второстепенные факторы, определяется начальное состояние системы, желаемое конечное состояние и правила действий, переводящих систему в желаемое конечное состояние.
Набор таких правил, обеспечивающих получение "хорошего", как правило, приближенного решения поставленной задачи, реализуется с помощью механизма вывода.
Рассмотрим особенности выполнения нечетких правил на следующем простом примере. Допустим, что необходимо регулировать открытие охлаждающего вентиля φвых в зависимости от измеренного значения температуры воздуха Твх.
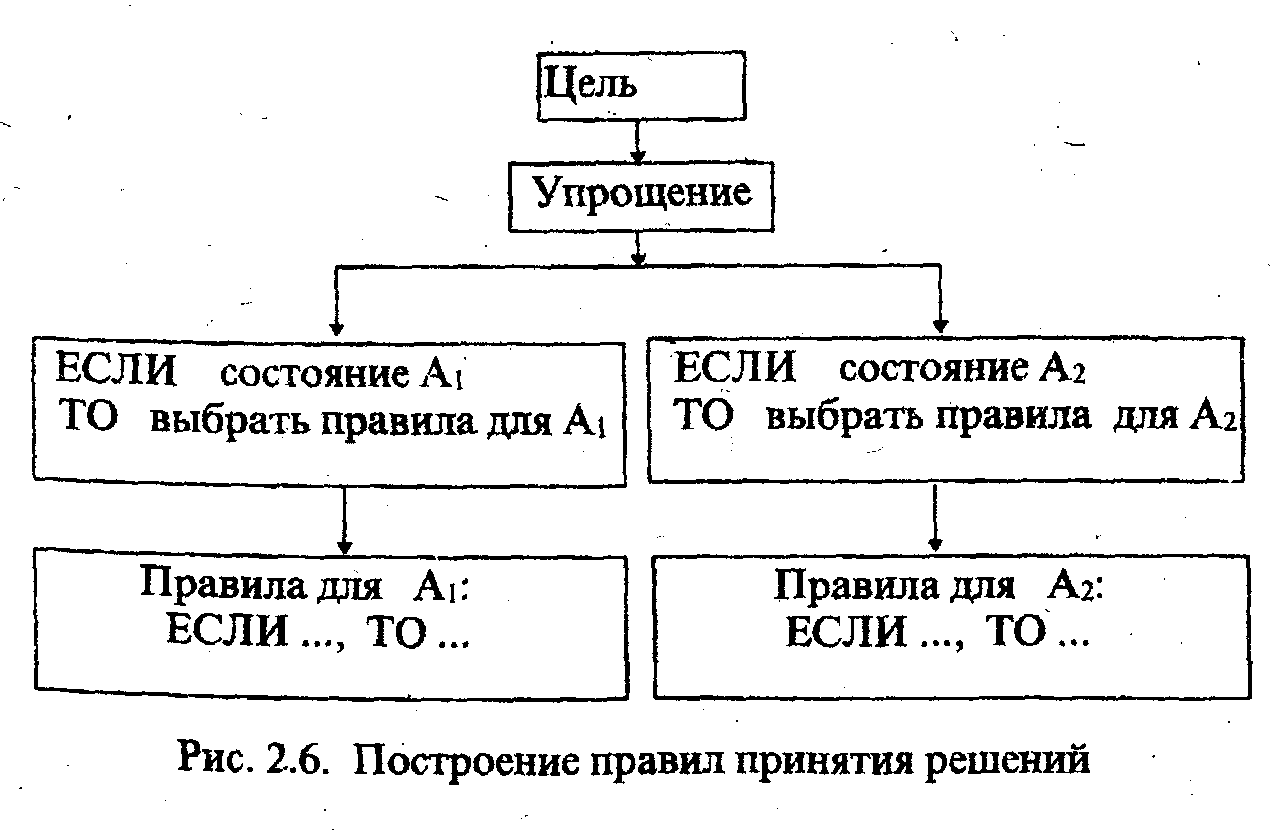
Рис 2.6 Построение правил принятия решений
Воспользуемся для этих целей двумя правилами, записанными в лингвистической форме, 1-е из которых имеет следующий вид:
ПРАВИЛО 1: "ЕСЛИ Температура = низкая, ТО охлаждающий вентиль = полуоткрыт".
Будем полагать, что нечеткие подмножества A1 ("Температура = низкая") и B1 ("Вентиль = полуоткрыт") определяются функциями принадлежности, приведенными на пис.2.7.
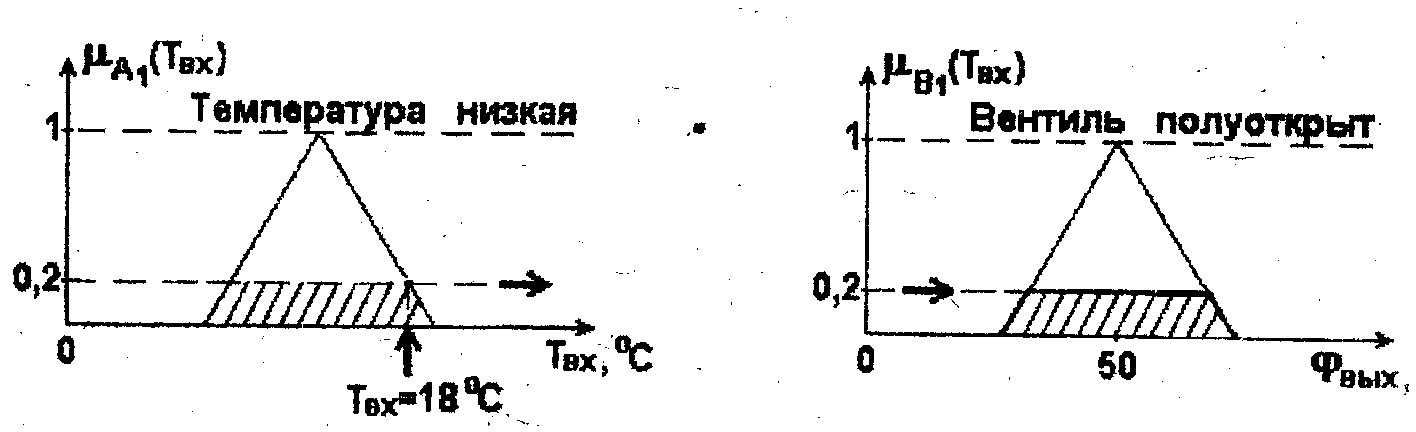
Рис.2.7. Функции принадлежности нечетких подмножеств А1 и В2
Если
измеренное значение температуры Твх
равно, например, 18 °С, то степень
принадлежности этого значения подмножеству
A1
в данном конкретном случае составляет
0,2. Полагая, что меньшее значение степени
выполнения условия "ЕСЛИ" должно
сопровождаться уменьшением значений
функции принадлежности вывода "ТО",
ограничим возможные значения функции
![]() на уровне 0,2, т.е. получим
на уровне 0,2, т.е. получим
![]() (2.18)
(2.18)
(Соответствующая функция выделена в правой половине рис.2.7 заштрихованной площадью).
Сформулируем 2-е лингвистическое правило следующим образом: ПРАВИЛО 2: "ЕСЛИ Температура = средняя, ТО охлаждающий вентиль = почти открыт".
Функции
принадлежности
![]() и
и
![]() ,
где А2
и B2
обозначают соответственно нечеткие
подмножества, содержащиеся в условии
и выводе правила 2, показаны на рис.2.8.
,
где А2
и B2
обозначают соответственно нечеткие
подмножества, содержащиеся в условии
и выводе правила 2, показаны на рис.2.8.
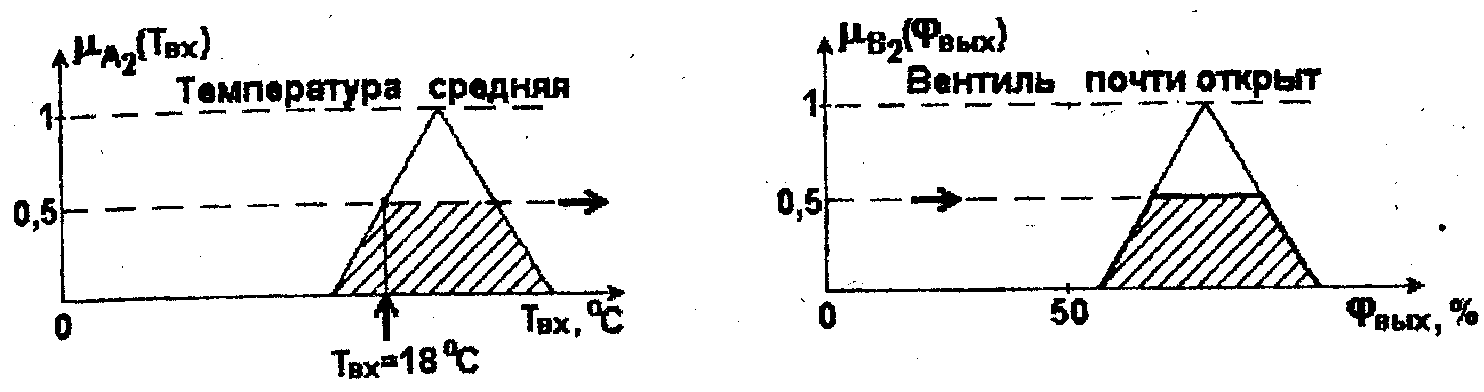
Рис.2.8. Функции принадлежности нечетких подмножеств A1 и В2
Степень принадлежности измеренного значения Твх = 18 °С подмножеству А2 здесь равна уже 0,5. Следуя тому же приему, для функции принадлежности получаем
![]() (2.19)
(2.19)
Заметим, что приведенные выше правила 1 и 2 действуют совместно и связаны друг с другом с помощью союза "ИЛИ", т.е. можно записать: ПРАВИЛО 1: "ЕСЛИ Температура = низкая, ТО охлаждающий вентиль = полуоткрыт" ИЛИ
ПРАВИЛО 2: "ЕСЛИ Температура = средняя, ТО охлаждающий вентиль = почти открыт".
Но
тогда результирующая функция принадлежности
![]() для переменной
для переменной
![]() находится по формуле
находится по формуле
![]() (2.20)
(2.20)
График полученной функции принадлежности представлен на рис. 2.9. Использованный в данном случае механизм логического вывода, выражающийся через операции нахождения минимума и максимума (2.18)-(2.20), получил название метода Максимума-Минимума (MAX-MIN- Inference).
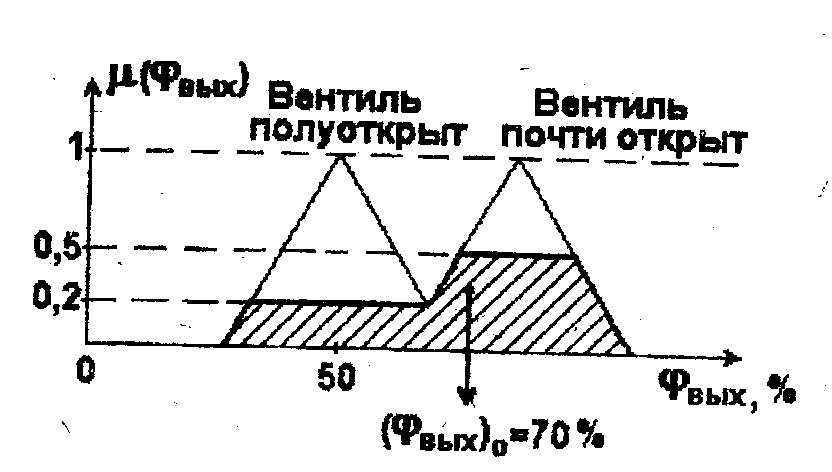
Рис.
2.9. Функция принадлежности нечеткого
множества
![]()
На практике часто используется еще один метод построения функции принадлежности выходного нечеткого множества, получивший название метода Максимума - Произведения (MAX-Product-Inference).
Суть этого метода заключается в следующем. При вычислении функций принадлежности вывода (заключения) "ТО" для каждого из правил осуществляется не ограничение их на уровне выполнения соответствующего условия "ЕСЛИ" (как это делалось в методе Максимума-Минимума), а пропорциональное уменьшение их значений в соответствии с уровнем выполнения указанного условия (рис. 2.10,а) с последующим использованием операции "ИЛИ" (рис. 2.10,6).
Важно
отметить, что при использовании любого
из указанных выше методов вывода (рис.
2.9, 2.10) результатом выполнения правил
1-2 является не конкретное число
,
а некоторое нечеткое множество,
описываемое функцией принадлежности
![]() .
В то же время данное решение не может
считаться окончательным, поскольку
сохраняется неопределенность выбора
значения искомой переменной
внутри рассматриваемого интервала -
носителя нечеткого множества
.
.
В то же время данное решение не может
считаться окончательным, поскольку
сохраняется неопределенность выбора
значения искомой переменной
внутри рассматриваемого интервала -
носителя нечеткого множества
.
Переход от полученного нечеткого множества к единственному четкому значению ( )о, которое и признается затем в качестве решения поставленной задачи, называется дефаззификацией (defuzzyfication).
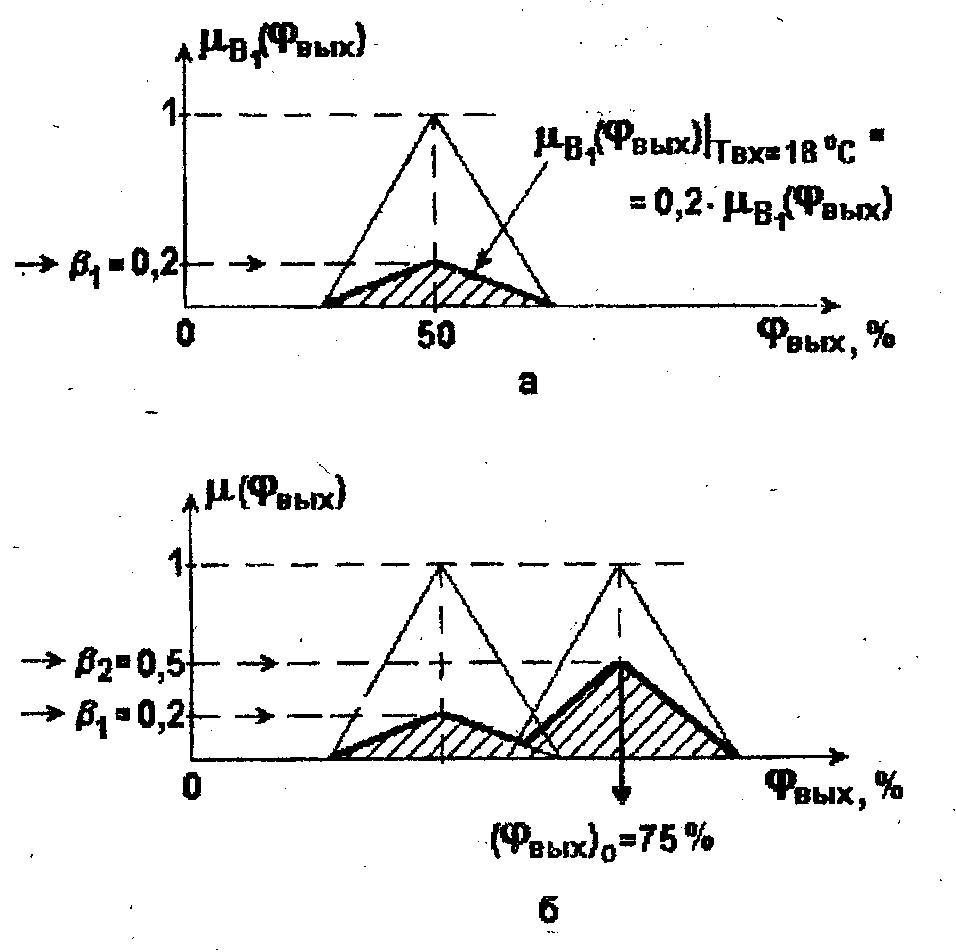
Рис. 2.10. Построение механизма вывода с помощью метода
Максимума- Произведения
Перечислим некоторые из наиболее известных методов дефаззификации:
1. Метод Максимума - выбирается тот элемент нечеткого множества, который имеет наивысшую степень принадлежности этому множеству.
Если
такой элемент не является единственным,
т.е. функция принадлежности
![]() имеет несколько локальных максимумов
y1,
у2,
– ym,
то значениями
имеет несколько локальных максимумов
y1,
у2,
– ym,
то значениями
![]() ,
или если имеется максимальное "плато"
между y1
и уm,
то выбор среди элементов, имеющих
наивысшую степень принадлежности
множеству, осуществляется на основе
определенного критерия.
,
или если имеется максимальное "плато"
между y1
и уm,
то выбор среди элементов, имеющих
наивысшую степень принадлежности
множеству, осуществляется на основе
определенного критерия.
2. Метод левого (правого) максимума - выбирается наименьшее (наибольшее) из чисел y1, у2, – ,ym, имеющих наивысшую степень принадлежности нечеткому множеству.
3.
Метод среднего
из максимумов
- в качестве искомого "четкого"
значения у0
принимается среднее арифметическое
координат локальных максимумов
![]() .
.
4. Метод Центра Тяжести (Center-of-Area) –
в
качестве выходного значения у0
выбирается абсцисса центра тяжести
площади, расположена под функцией
принадлежности
![]() :
:
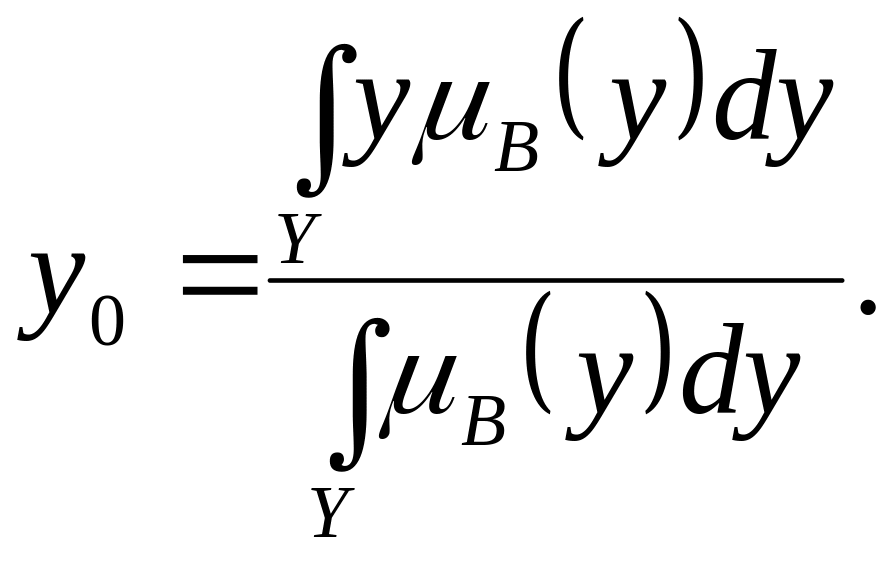 (2.21)
(2.21)
При необходимости вычисления у0 на ЭВМ в реальном времени, с учетом реальных вычислительных затрат, обычно операцию интегрирования в (2.21) заменяют суммированием.
Существует простая возможность использования для этих целей взвешенного среднего значения
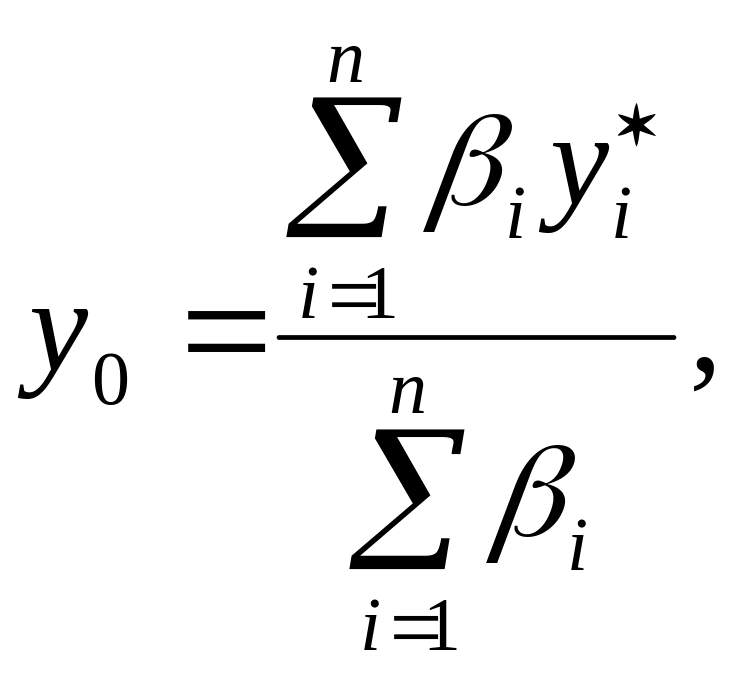 (2.22)
(2.22)
где уi*, (i = l,2,...,n) – центральные значения нечетких подмножеств Вi(у) выходной переменной у; βi – веса, учитывающие уровень выполнения условия "ЕСЛИ" 1-го правила, называемые также уровнями активности соответствующих правил; n - число правил вывода.
5. Модифицированный метод центра тяжести –
интегрирование
(2.21) производится только в тех областях,
где
![]() .
Параметр используется здесь для
подавления шумов, отсеивания влияния
малосущественных для процедуры вывода
факторов (на практике можно применять
α
= 0,05÷0,1).
.
Параметр используется здесь для
подавления шумов, отсеивания влияния
малосущественных для процедуры вывода
факторов (на практике можно применять
α
= 0,05÷0,1).
Проиллюстрируем рассмотренные методы на примере дефаззификации в процессе проектирования контейнерного крана с нечетким регулятором.
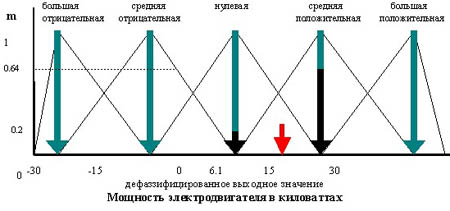
Метод центра максимума (СоМ)
Так как результатом нечеткого логического вывода может быть несколько термов выходной переменной, то правило дефаззификации должно определить, какой из термов выбрать.
Работа правила СоМ показана на рисунке.
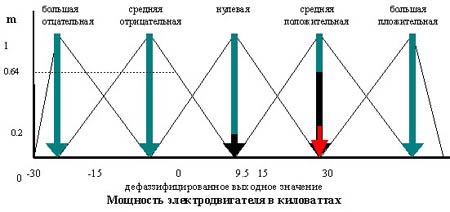
Метод наибольшего значения (МоМ)
При использовании этого метода правило дефаззификации выбирает максимальное из полученных значений выходной переменной. Работа метода ясна из рисунка.
Метод центроида (СоА)
В этом методе окончательное значение определяется как проекция центра тяжести фигуры, ограниченной функциями принадлежности выходной переменной с допустимыми значениями. Работу правила можно видеть на рисунке.
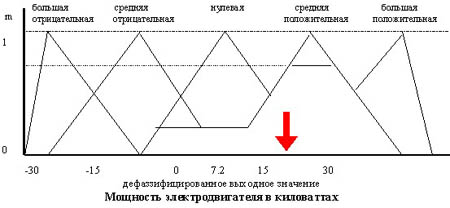
На рисунках жирными стрелками выделены результаты процедуры дефаззификации, полученные соответственно методом центра тяжести и методом максимума. Незначительное различие полученных значений указывает на то, что выбор механизма вывода и метода дефаззификации может быть, вообще говоря, достаточно произвольным и во многом определяется соображениями простоты их вычислительной реализации.
В тех случаях, когда имеется несколько измеряемых входных переменных, механизм вычисления управляющих воздействий в принципе остается неизменным. Так, на рис. 2.11 показан процесс вычисления единственного управляющего воздействия (открытия охлаждающего -вентиля φвых) в зависимости от измеряемых четких значений температуры Твх и относительной влажности воздуха Fвх с помощью метода Максимума- Минимума.
Предполагается, что при этом используются 2 лингвистических правила:
ПРАВИЛО 1: "ЕСЛИ Температура = низкая ИЛИ Влажность = средняя, ТО Вентиль = полуоткрыт".
ПРАВИЛО 2: "ЕСЛИ Температура = низкая И Влажность = высокая, ТО Вентиль = полузакрыт".
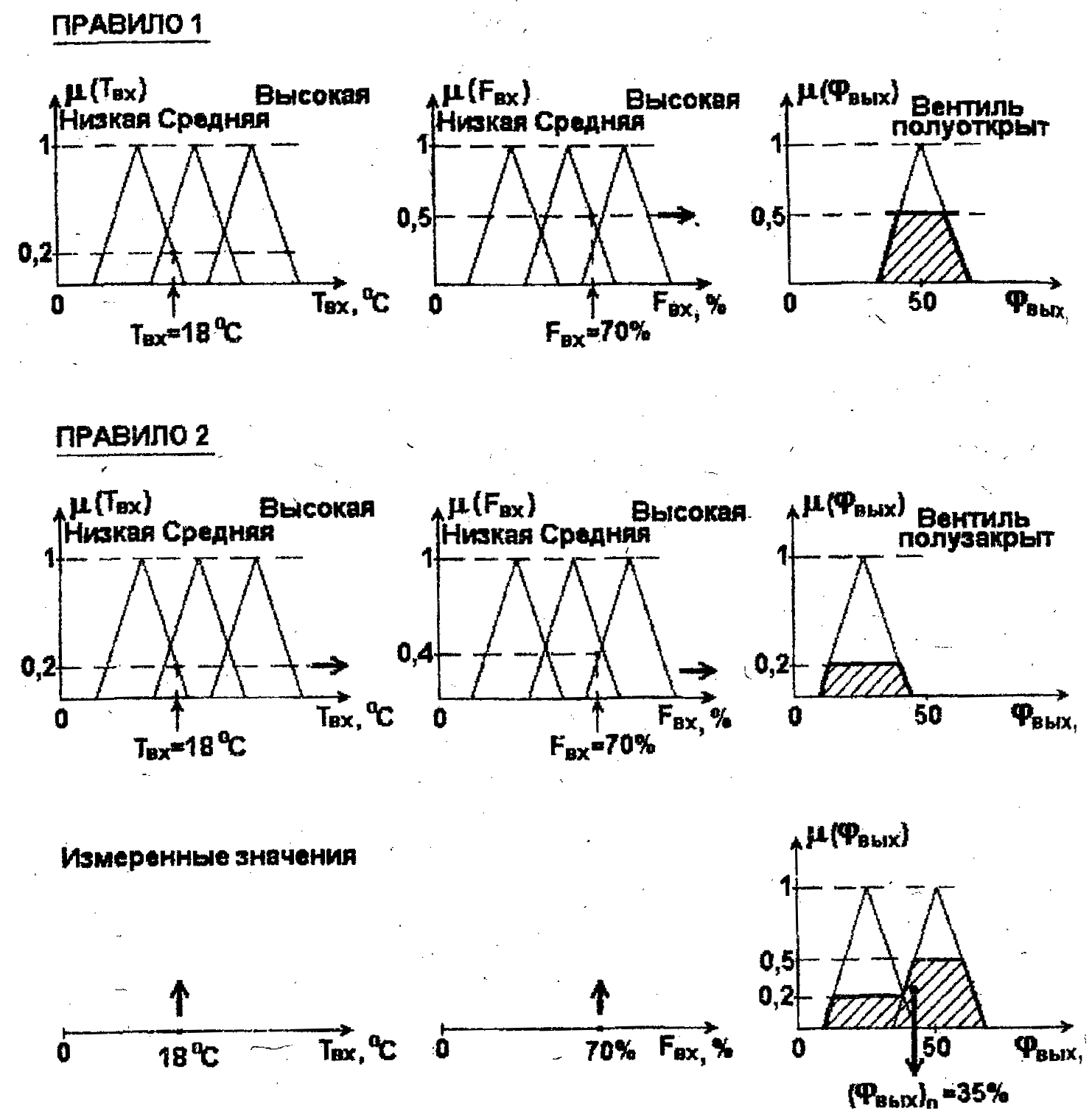
Рис 2.11 Процедура логического вывода
Лекция № 6. ПРОЕКТИРОВАНИЕ НЕЧЕТКИХ АЛГОРИТМОВ УПРАВЛЕНИЯ ДИНАМИЧЕСКИМИ ОБЪЕКТАМИ
Общие принципы построения интеллектуальных систем управления на основе нечеткой логики
Как уже отмечалось выше, применение нечеткой логики обеспечивает принципиально новый подход к проектированию систем управления, "прорыв" в новые информационные технологии, гарантирует возможность решения широкого круга проблем, в которых данные, цели и ограничения являются слишком сложными или плохо определенными и в силу этого не поддаются точному математическому описанию.
Возможны различные ситуации, в которых могут использоваться нечеткие модели динамических систем:
- когда имеется некоторое лингвистическое описание, которое отражает качественное понимание (представление) процесса и позволяет непосредственно построить множество нечетких логических правил;
- имеются известные уравнения, которые (хотя бы грубо) описывают поведение управляемого процесса, но параметры этих уравнений не могут быть точно идентифицированы;
- известные уравнения, описывающие процесс, являются слишком сложными, но они могут быть интерпретированы нечетким образом для построения лингвистической модели;
- с помощью входных/выходных данных оцениваются нечеткие логические правила поведения системы.
Первые результаты практического применения алгоритмов нечеткой логики к управлению реальными техническими объектами были опубликованы в 1974 г. в работах профессора Лондонского Королевского колледжа Э.Х. Мамдани, посвященных проблеме регулирования парогенератора для электростанции. В этих работах была предложена ставшая сегодня классической структурная схема системы нечеткого управления (рис. 3.1).
Под нечетким управлением (Fuzzy Control) в данном, случае понимается стратегия управления, основанная на эмпирически приобретенных знаниях относительно функционирования объекта (процесса), представленных в лингвистической форме в виде некоторой совокупности правил.

Рис. 5.1. Структурная схема системы нечеткого управления
На
рис. 3.1 ДФ - динамический фильтр, выделяющий,
помимо сигналов ошибок управления
x1=r1-y1
и х3=r2-у2,
производные от этих сигналов
![]() и
и
![]() ;
;
РНЛ - регулятор на основе нечеткой логики ("нечеткий регулятор”, включающий в себя базу знаний (конкретнее - базу правил) и механизм логического вывода;
![]() -
-
соответственно векторы задающих воздействий (уставок), входов и выходов РНЛ, а также выходов объекта управления (т.е. парогенератора); т - операция транспонирования вектора.
В качестве входов и выходов РНЛ выступают:
![]() -
отклонение давления в паровом котле
(y1)
по отношению к и требуемому (номинальному)
значению (r1);
-
отклонение давления в паровом котле
(y1)
по отношению к и требуемому (номинальному)
значению (r1);
![]() -
скорость изменения РЕ;
-
скорость изменения РЕ;
![]() -
отклонение скорости изменения давления
(у2)
по отношению к его заданному значению
(r2);
-
отклонение скорости изменения давления
(у2)
по отношению к его заданному значению
(r2);
![]() -
скорость изменения SE;
-
скорость изменения SE;
u1=Hc – изменение степени подогрева пара;
U2=: Тс - изменение положения дросселя.
Мамдани предложил рассматривать эти величины как лингвистические переменные, каждая из которых может принимать одно из следующих значений из множества
L= {NB,NM,NS,NO,PO,PS,PM,PB}.
Здесь 1-я буква в обозначении указывает знак числовой переменной и соответствует английскому слову Negative ("отрицательное") или Positive ("положительное"), 2-я буква говорит об абсолютном значении переменной: Big ("большое"), Middle ("среднее"), Small ("малое") или О ("близкое к нулю"). Например, символ NS означает "отрицательное малое".
В процессе работы ИСУ в каждый момент времени используется один из двух нечетких алгоритмов: по первому из них осуществляется регулирование давления в котле путем изменения подогрева пара Нc, по второму поддерживается требуемая скорость изменения давления с помощью изменения положения регулирующего дросселя Тс. Каждый из алгоритмов состоит из ряда правил – высказываний, записанных на естественном языке, типа:
"Если отклонение давления в котле большое, отрицательного знака и если это отклонение не убывает с большой или средней по величине скоростью, то степень подогрева пара необходимо сильно увеличить".
Или:
"Если скорость изменения давления чуть ниже нормы и в то же время эта скорость резко растет, то следует изменить положение дросселя на положительную, достаточно малую, величину".
Используя введенные выше обозначения, можно переписать эти правила в следующем виде:
"ЕСЛИ (PE=NB И CPE=HE (NB ИЛИ NM), ТО НС=РВ";
"ЕСЛИ (SE=NO И CSE=PB), TO TC=PS".
Реализация предложенных алгоритмов нечеткого управления при этом принципиально отличается от классических ("жестких") алгоритмов, построенных на основе концепции обратной связи (Feed-back Control) и, по существу, просто воспроизводящих некоторую заданную функциональную зависимость или дифференциальное уравнение.
Нечеткий регулятор берет на себя те функции, которые обычно выполняются опытным и умелым обслуживающим персоналом. Эти функции связаны с качественной оценкой поведения системы, анализом текущей меняющейся ситуации и выбором наиболее подходящего для данной ситуации способа управления объектом. Данная концепция управления получила название опережающего (или упреждающего) управления (Feed-Forward Control).
Используя образное сравнение, можно сказать, что примерно так действует опытный теннисист, каждый раз варьируя свой удар, чтобы мяч летел по определенной, выбранной им траектории, тогда как теннисный автомат работает по жестко заданной программе, подавая мяч всегда в одну и ту же точку, по одной и той же траектории.
Блок - схема нечеткого регулятора в общем случае принимает вид, изображенный на рис. 3.2.
Как видно из данной схемы, формирование управляющих воздействий u1,u2,...,um включает в себя следующие этапы:
а) получение отклонений управляемых координат и скоростей их изменения – х1,x2,...,хn;
б) "фаззификация" этих данных, т.е. преобразование полученных значений к нечеткому виду, в форме лингвистических переменных;
в) определение нечетких (качественных) значений выходных переменных u1,u2,...,um (в виде функций их принадлежности соответствующим нечетким подмножествам) на основе заранее формулированных правил логического вывода, записанных в базе правил;
г) "дефаззификация", т.е. вычисление реальных числовых значений выходов u1,u2,...,um, используемых для управления объектом.
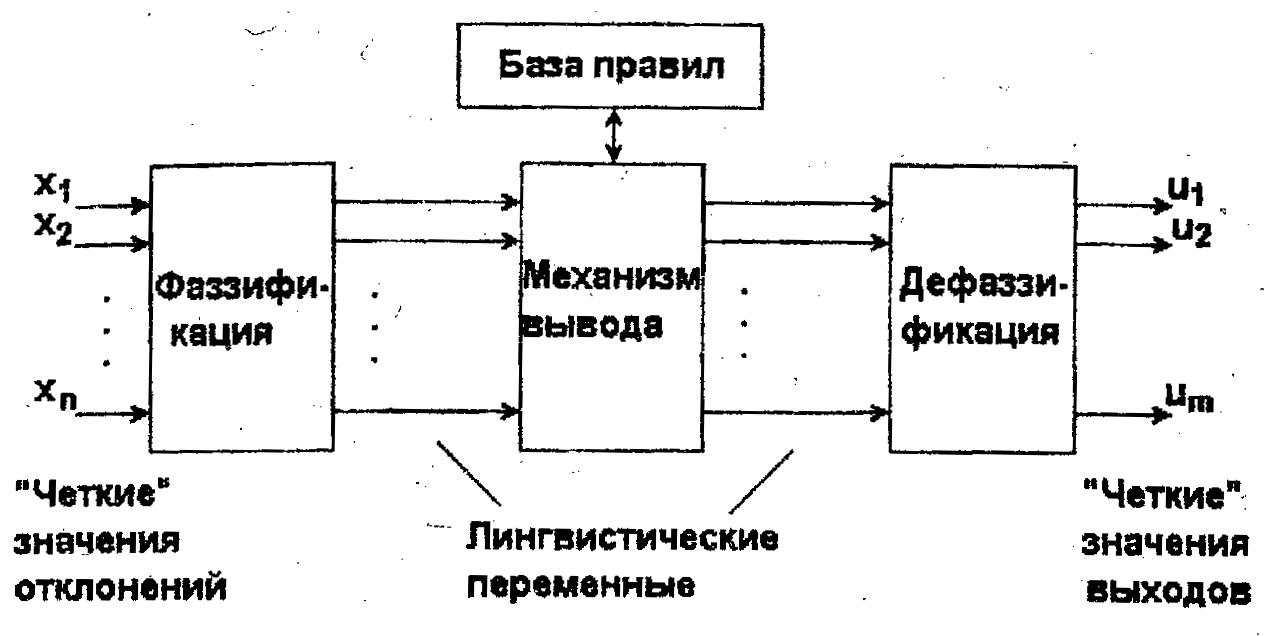
Рис. 3.2. Блок-схема нечеткого регулятора
Помимо представленного на рис. 3.1 варианта "чистого" использования нечеткого управления, существуют и другие варианты построения ИСУ с нечеткими регуляторами. Так, в классической теории регулирования широкое распространение получило использование ПИД - регулятора, выходной сигнал которого вычисляется по формуле
![]() (3.1)
(3.1)
где параметры Кп, Ки и Кд характеризуют удельный вес соответственно пропорциональной, интегральной и дифференциальной составляющей и, должны выбираться исходя из заданных показателей качества регулирования (время регулирования, перерегулирование, затухание переходных процессов).
Возможное использование нечеткого регулятора (НР) для автоматической настройки (адаптации) указанных параметров ПИД - регулятора показано на рис. 3.3,а. Другие варианты применения HP – формирование уставок обычных регуляторов (рис. 3.3,6); подключение параллельно ПИД - регулятору (рис. 3.3, в); управление с предварительной оценкой характеристик сигналов (ОХС), получаемых с датчиков, на основе интерпретации их значимости, выделения обобщенных показателей качества и т. п. с последующей обработкой с помощью алгоритмов нечеткой логики (рис. 3.3,г).
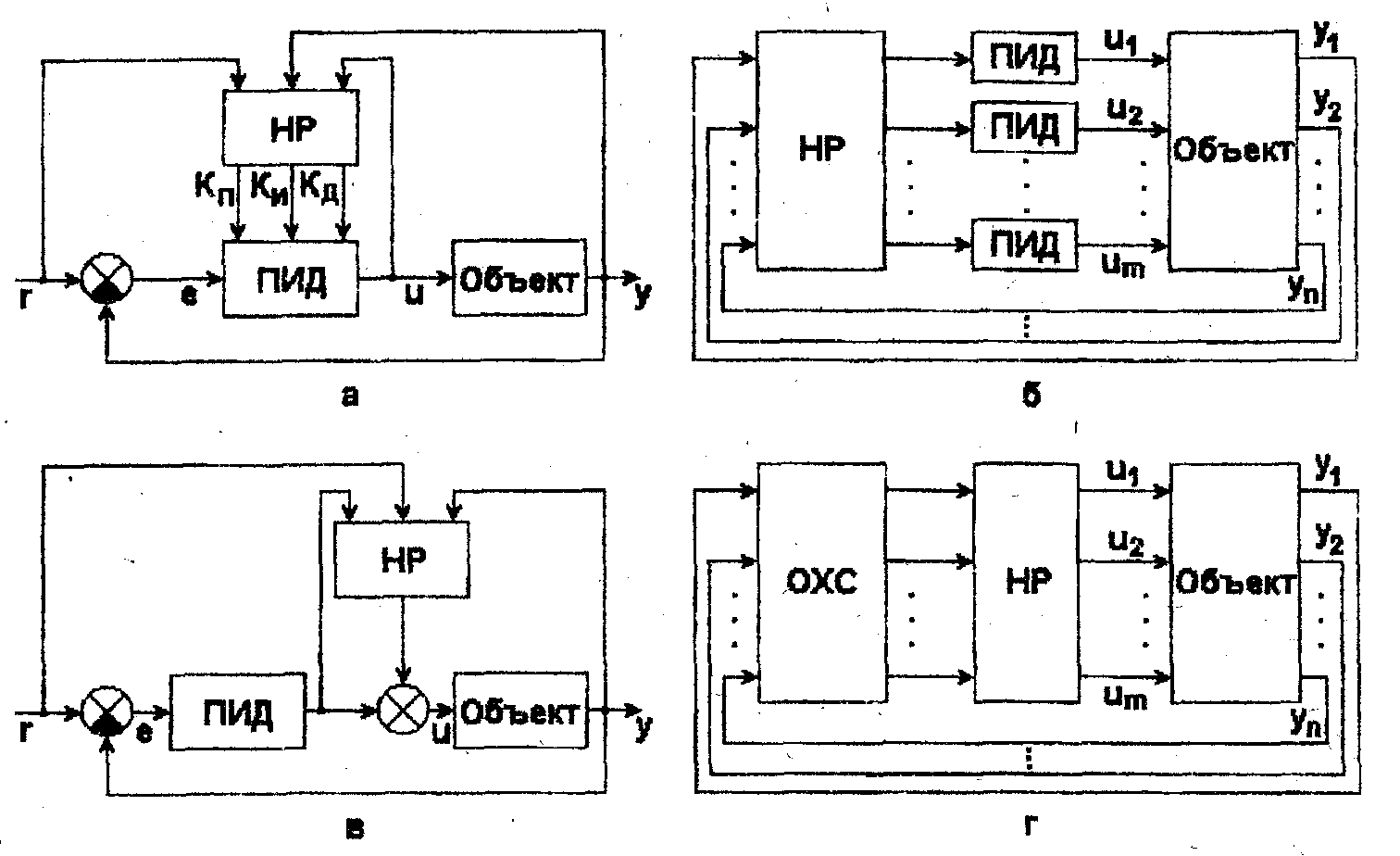
Рис. 3.3. Структуры ИСУ с нечеткими регуляторами
В качестве предпосылок к применению нечетких регуляторов обычно называются:
- большое число входных параметров, подлежащих анализу (оценке);
- большое число управляющих воздействий (многомерность);
- сильные возмущения;
- нелинейности;
- неточности математических моделей программы регулирования;
- возможность использования технических знаний "know - how".
Подводя итог сказанному, отметим еще раз те области применения, в которых использование нечетких регуляторов оказывается более эффективным по сравнению с традиционными алгоритмами управления. Это:
1) приложения, которые пока были не связаны с автоматизацией, требующие применения "know - how", например, пивоварение (где можно воспользоваться знаниями экспертов с целью повышения качества продукции), подъемные краны (для повышения производительности рабочего персонала) и т. п.;
2) приложения, в которых математические методы не работоспособны. Это очень сложные процессы, не поддающиеся математическому описанию, для управления которыми можно использовать, наряду с эмпирическими знаниями, также полученную измерительную информацию (например, о ходе химических процессов);
3) приложения, в которых стандартные регуляторы достаточно хорошо работают; однако управление на основе нечеткой логики предлагает в данном случае альтернативный способ решения задач регулирования, возможность работы с лингвистическими переменными, более широкие возможности для оптимизации.
Лекция № 7. Синтез нечетких регуляторов
Обобщенная процедура синтеза нечетких алгоритмов управления
Обобщенная процедура синтеза нечетких алгоритмов управления может быть сформулирована следующим образом:
1. Определяется множество целей, которые ставятся перед системой. (Какие конечные результаты преследует создание системы?)
2. Уточняются множества входных и выходных переменных регулятора. (какие координаты объекта должны наблюдаться и какие управляющие воздействия должны изменяться, для того чтобы достичь поставленных целей?)
3. Перечисляются возможные ситуации в работе системы. (как должны выбираться лингвистические переменные и какие значения (терм они могут принимать?)
4. Формируется база правил. (Какой набор правил отражает желаемые изменения состояния системы?)
5. Производится выбор метода фаззификации.
6. Конкретизируются механизм вывода и методы дефаззификации. (по каким зависимостям входы нечеткого регулятора должны преобразовываться в его управляющие воздействия ?).
Рассмотрим особенности применения данной процедуры на следующем примере, представляющем прежде всего методический интерес. Пусть структурная схема ИСУ соответствует рис. 3.1, т. е. нечеткий регулятор используется для непосредственного (прямого) управления объектом. Тогда:
Цель синтеза - создание "хорошего" регулятора, обеспечивающего малое перерегулирование, высокое быстродействие и слабую колебательность (т. е. быстрое затухание) переходных процессов.
Входные величины регулятора - сигнал ошибки е = r-у и сигнал ее производной ce=de(t)/dt.
Выход - управляющее воздействие – u.
Для того чтобы выработать стратегию управления, обратимся к рис. 3.4, на котором показан график переходной функции системы y(t), т. е. ее реакции на единичное ступенчатое воздействие r(t).
Разобьем график y(t) на следующие характерные участки:
I - "Начало переходного процесса":
ошибка
еk
велика, скачок скорости ее изменения
сеk;
резко увеличить управляющее воздействие
![]() ;
;
II - "Продолжать движение":
ошибка ек велика, но убывает; поддерживать управление uk на прежнем уровне или слегка уменьшить;

Рис. 3.4. График переходной функции системы
III, V, VII - "Достигли уровня уставки":
ошибка еk около нуля, скорость ее изменения достаточно мала; сохранить управление uk;
IV ,VI - "Достигли локального максимума (минимума)":
ошибка еk невелика, скорость ее изменения сеk около нуля; незначительно уменьшить (или увеличить) uk;
VIII - "Достигли установившегося состояния":
ошибка ek и скорость ее изменения cek около нуля; сохранить управление uk
Здесь ek, cek, uk - значения сигнала ошибки, скорости ее изменения и управляющего воздействия в k-й момент времени tk (k=0,1,2,...); .
4°. Введем следующие обозначения:
LP - "большое положительное" (large positive);
SP - "малое положительное" (small positive);
Z - "около нуля" (zero);
SN - "малое отрицательное"(small negative);
LN - "большое отрицательное" (1аrgе negative);
Тогда правила формирования сигнала управления можно записать в следующем виде (см. соответствующие пояснения на рис. 3.4)
ПРАВИЛО
I:
"ЕСЛИ
![]() ,
ТО
,
ТО
![]() ";
";
ПРАВИЛО
II:
"ЕСЛИ
![]() ,
ТО
,
ТО
![]() ";
ИЛИ "ЕСЛИ
";
ИЛИ "ЕСЛИ
![]() ,
ТО
,
ТО
![]() ";
";
ПРАВИЛО
III:
"ЕСЛИ
![]() ,
ТО
";
,
ТО
";
ПРАВИЛО
IV:
"ЕСЛИ
![]() ,
ТО
";
,
ТО
";
ПРАВИЛО
V:
"ЕСЛИ
![]() ,
ТО
";
,
ТО
";
ПРАВИЛО
VI:
"ЕСЛИ
![]() ,
ТО
,
ТО
![]() ";
";
ПРАВИЛО
VIII:
"ЕСЛИ
![]() ,
ТО
".
,
ТО
".
(Правило
VII
отсутствует в данном перечне, т.к. номер
правила здесь совпадает с номером
участка кривой переходного процесса
на рис. 3.4, а лингвистические переменные
![]() ,
,
![]() и
и
![]() на участке VII
принимают те же значения, что и на участке
III).
на участке VII
принимают те же значения, что и на участке
III).
Как видно, приведенный алгоритм управления представляет собой нечеткий, "расписанный по шагам" вариант реализации ПИД - алгоритма.
Для рассматриваемого случая, когда нечеткий регулятор имеет 2 входа и 1 выход, удобно представить данный алгоритм управления с помощью так называемой таблицы решений (decision table) (табл. 3.1).

Данная таблица заполняется следующим образом.
На
пересечении i-й
строки и j-ro
столбца записывается требуемое значение
выходной переменной
![]() соответствующее i-му
значению (терму)
соответствующее i-му
значению (терму)
![]() и j-му
значению
и j-му
значению
![]() .
.
Анализ полученной таблицы решений показывает, что предложенный выше набор правил I - VIII не является функционально полным (таблица содержит большое число пустых клеток). Для заполнения недостающих клеток необходимо проанализировать большое число ситуаций управления. Например, возможен "инвертированный" вариант реализации Правила II:
"ЕСЛИ
![]() ,
ТО
"
ИЛИ "ЕСЛИ
,
ТО
"
ИЛИ "ЕСЛИ
![]() ,
ТО
",
,
ТО
",
что позволяет внести в таблицу решений 2 дополнительных элемента (обведены в табл. 3.1 пунктирными окружностями).
Очевидно, что увеличение размерности таблицы решений приводит не только к определенным трудностям с точки зрения пополнения (доопределения) системы правил принятия решений, но и связано с возрастанием вычислительных затрат при работе регулятора.
Поэтому на практике рекомендуется принимать число значении (уровней квантования) каждой лингвистической переменной равным 3 - 7.