

Існують різні виробники, і різні СУБД, існує різноманітні архітектури.
1. Однобазовая архітектура - застосовується у великих СУБД (Oracle і т.д.). перевага такої БД - управління та контролювання БД відбувається з одного сервера. Недолік у тому, що з плином часу, БД стає все більше і більше. Ускладнюються проблеми з резервним копіюванням і т.д.
2. Многобазовая архітектура - основна перевага такої архітектури в тому, що спрощується проектування. Для кожної програми можна фактично створити свою базу даних. СУБД як програмне забезпечення може керувати великим набором баз даних - InterBase, SQL-server - десятки тисяч СУБД можуть підтримуватися одним сервером, а баз як файлів м.б. багато - головне, щоб сервер їх бачив. Недоліком таких СУБД є те, що при записі даних організацій в різні БД, вважати дані з них представляє проблему.
3. Каталогова архітектура - Desktop'овскіе СУБД. Базою даних є окремий каталог: таблиці - окремий файл, індекс - окремий файл. Все розташоване в окремому каталозі, яких може бути багато. Є цікаві рішення в MS Access в одному файлі таблиці, індекси, запити знаходяться в одному файлі. Є свої плюси і мінуси. Важко налаштовувати ПО сторонній - він повинен сидіти в цій БД. Не кожна організація дасть копію своєї бази даних.
Такі однобазовие архітектури, як в Oracle, дозволяють створювати БД, що зберігаються в кількох фізичних файлах. Для того, щоб назвати базою даних щось, що складається з декількох файлів, вводять поняття табличного простору, який може покривати декілька файлів. Зараз, середні СУБД (SQL-сервер, наприклад) починають підтримувати такого роду табличні простору.
Інформація про певну предметної області представлена в базі даних моделями декількох рівнів. За кількістю рівнів в архітектурі розрізняють однорівневі, дворівневі, трирівневі системи. На різних рівнях архітектури СУБД підтримується різний рівень абстракції даних. В даний час найбільш поширеною є запропонована американським комітетом по стандартизації ANSI (American National Standards Institute) трирівнева система організації БД. При проектуванні баз даних виділяють три рівні: концептуальний,
внутрішній
і зовнішній.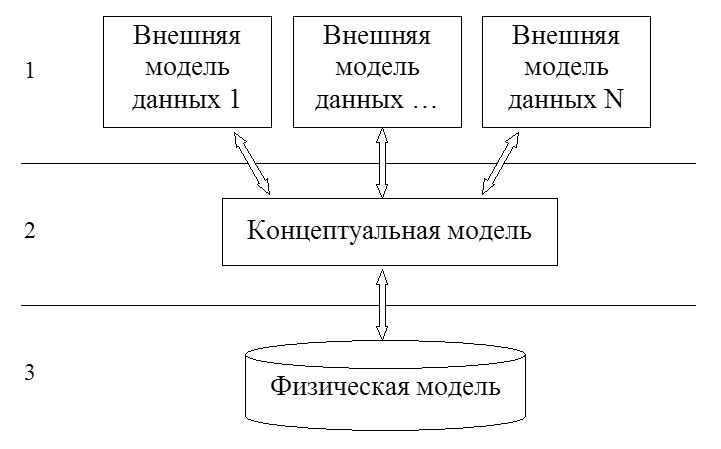
1. Рівень зовнішніх моделей - самий верхній рівень, де кожна модель має своє «бачення» даних. Цей рівень визначає точку зору на БД окремих додатків. Кожна програма бачить і обробляє лише ті дані, які необхідні саме цьому додатком. Наприклад, система розподілу робіт використовує відомості про кваліфікацію співробітника, але її не цікавлять відомості про окладі, домашню адресу і телефон співробітника, і навпаки, саме ці відомості використовуються в підсистемі відділу кадрів.
2. Концептуальний рівень - центральний управляючий ланка. Тут база даних представлена в найбільш загальному вигляді, який об'єднує дані, які використовуються усіма додатками, що працюють з даною базою даних. Фактично, концептуальний рівень відображає узагальнену логічну модель предметної області, для якої створювалася база даних. Як будь-яка модель, концептуальна модель відображає тільки істотні, з точки зору обробки, особливості об'єктів предметної області. Концептуальна модель є моделлю логічного рівня і не залежить від особливостей використовуваної СУБД. Виділення концептуального рівня дозволило розробити апарат централізованого управління базою даних.
3. Фізичний рівень - власне дані, розташовані в файлах або в сторінкових структурах, розташованих на зовнішніх носіях інформації. Фізичне представлення БД відноситься до внутрішнього рівня. Він описує способи організації даних на зовнішніх носіях інформації (у вигляді файлових або сторінкових структур) і призначений для досягнення оптимальної продуктивності та ефективності використання ресурсів обчислювальної системи. Опис фізичної структури БД називається схемою зберігання, а відповідний етап проектування БД - фізичним проектуванням.
Проектування бази даних складається з двох основних фаз: логічного і фізичного моделювання. Під час фази логічного моделювання розробник збирає вимоги до розроблюваної БД, становить опис предметної області та розробляє модель, не залежну від конкретної СУБД. Під час фази фізичного моделювання розробник створює модель, оптимізовану для СУБД і конкретних програм користувачів. В даний час внутрішній рівень практично повністю забезпечується СУБД. Основний акцент при проектуванні БД переноситься на створення моделі концептуального рівня. Така архітектура дозволяє забезпечувати логічну (між рівнями 1 і 2) і фізичну (між рівнями 2 і 3) незалежність при роботі з даними.
Логічна незалежність передбачає можливість зміни однієї програми без коригування інших додатків, що працюють з цією ж базою даних, і реорганізації механізму доступу до фізичних даних.
Фізична незалежність припускає можливість перенесення збереженої інформації з одних носіїв на інші при збереженні працездатності всіх додатків, що працюють з базою даних.
озданние модель, оптимізовану для СУБД і конкретних програм користувачів. В даний час внутрішній рівень практично повністю забезпечується СУБД. Основний акцент при проектуванні БД переноситься на створення моделі концептуального рівня. Така архітектура дозволяє забезпечувати логічну (між рівнями 1 і 2) і фізичну (між рівнями 2 і 3) незалежність при роботі з даними.
Логічна незалежність передбачає можливість зміни однієї програми без коригування інших додатків, що працюють з цією ж базою даних, і реорганізації механізму доступу до фізичних даних.
Фізична незалежність припускає можливість перенесення збереженої інформації з одних носіїв на інші при збереженні працездатності всіх додатків, що працюють з базою данних. носіях інформації (у вигляді файлових або сторінкових структур) і призначений для досягнення оптимальної продуктивності та ефективності використання ресурсів обчислювальної системи. Опис фізичної структури БД називається схемою зберігання, а відповідний етап проектування БД - фізичним проектуванням.
Проектування бази даних складається з двох основних фаз: логічного і фізичного моделювання. Під час фази логічного моделювання розробник збирає вимоги до розроблюваної БД, становить опис предметної області та розробляє модель, не залежну від конкретної СУБД. Під час фази фізичного моделювання розробник створює модель, оптимізовану для СУБД і конкретних програм користувачів. В даний час внутрішній рівень практично повністю забезпечується СУБД. Основний акцент при проектуванні БД переноситься на створення моделі концептуального рівня. Така архітектура дозволяє забезпечувати логічну (між рівнями 1 і 2) і фізичну (між рівнями 2 і 3) незалежність при роботі з даними.
Логічна незалежність передбачає можливість зміни однієї програми без коригування інших додатків, що працюють з цією ж базою даних, і реорганізації механізму доступу до фізичних даних.
Фізична незалежність припускає можливість перенесення збереженої інформації з одних носіїв на інші при збереженні працездатності всіх додатків, що працюють з базою даних.
У
комп'ютерних технологіях трирівнева
архітектура, синонім трехзвенная
архітектура (англ. three-tier або Multitier
architecture) передбачає наявність наступних
компонентів програми: клієнтський
додаток (зазвичай говорять «тонкий
клієнт» або термінал), підключений до
сервера додатків, який в свою чергу
підключений до серверу бази даних.
Клієнт - це інтерфейсний (зазвичай графічний) компонент, який представляє перший рівень, власне додаток для кінцевого користувача. Перший рівень не повинен мати прямих зв'язків з базою даних (за вимогами безпеки), бути навантаженим основний бізнес-логікою (по требованияммасштабируемости) і зберігати стан додатки (за вимогами надійності). На перший рівень може бути винесена і зазвичай виноситься найпростіша бізнес-логіка: інтерфейс авторизації, алгоритми шифрування, перевірка вводяться значень на допустимість і відповідність формату, нескладні операції (сортування, групування, підрахунок значень) з даними, вже завантаженими на термінал.
Сервер додатків розташовується на другому рівні. На другому рівні зосереджена велика частина бізнес-логіки. Поза його залишаються фрагменти, що експортуються на термінали а також занурені в третій рівень збережені процедури і тригери.
Сервер бази даних забезпечує зберігання даних і виноситься на третій рівень. Зазвичай це стандартна реляційна або об'єктно-оріентірованнаяСУБД. Якщо третій рівень являє собою базу даних разом з збереженими процедурами, тригерами і схемою, яка описує додаток в термінах реляційної моделі, то другий рівень будується як програмний інтерфейс, що зв'язує клієнтські компоненти з прикладної логікою бази даних.
У простій конфігурації фізично сервер додатків може бути поєднаний з сервером бази даних на одному комп'ютері, до якого по мережі підключається один або кілька терміналів.
У «правильної» (з точки зору безпеки, надійності, масштабування) конфігурації сервер бази даних знаходиться на виділеному комп'ютері (або кластері), до якого по мережі підключені один або кілька серверів додатків, до яких, в свою чергу, по мережі підключаються термінали.
Багаторівнева архітектура або N-рівнева архітектура
З розвитком інтернет додатків на тлі загального підвищення кількості користувачів основна трирівнева клієнт-серверна модель була розширена шляхом введення додаткових рівнів. Такі архітектури називають «" багаторівневі », зазвичай вони складаються з чотирьох рівнів (рисунок 3), де в мережі сервер відповідає за обробку з'єднання між клієнтом браузером і сервером додатків. Вигода полягає в тому, що кілька веб-серверів можуть підключатися до одного сервера додатків , тим самим, збільшуючи обробку більшого числа одночасно підключених користувачів.
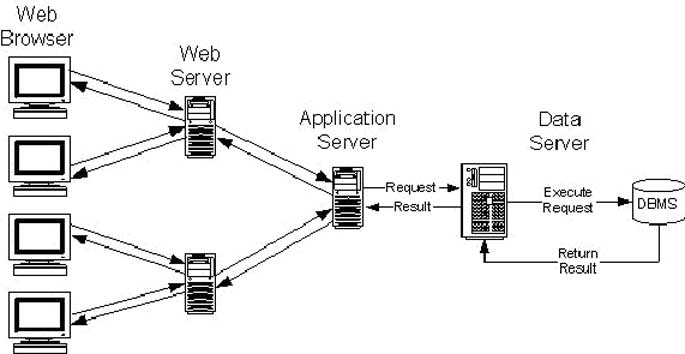
Архітектура схеми
До сих пір ми обговорювали функцію обробки даних в термінах DBMS, маючи одну єдину схему для опису постійних даних системи бази даних. Це корисне спрощення, але насправді справи йдуть трохи складніше. Архітектура схеми12, яку ми зараз описуємо, дозволяє аналізувати цю складність і пов'язати її з перевагами, які можна отримати завдяки підходу, заснованого на використанні бази даних. Архітектура обговорюваної нами схеми показана на рис. 2.10.
Перш за все, зауважте, що різні суцільні лінії на рис. 2.10 показують, що певні компоненти в даній архітектурі пов'язані один з одним способом, який буде коротко розглянуто далі. Зокрема, зверніть увагу, що ці лінії не призначені для того, щоб вказувати потік обробки даних. Як можна бачити, наше спрощення однієї схеми замінено трьома видами схем: логічної схемою, схемою зберігання і схемою користувачів (userschema). Пізніше ми пояснимо, чим викликана ця заміна. У верхню частину діаграми ми також включили різні користувальницькі процеси. Термін "користувальницький процес" (user process) вводиться для того, щоб дозволити доступ до системи бази даних за допомогою будь-якого виду програмного забезпечення від імені користувача. А тепер ми більш детально досліджуємо ці концепції.
Логічна схема (logical schema) - це одиночне, центральне опис логічних властивостей даних в конкретній базі даних. Логічна схема більше описує якими є дані, ніж те, як їх можна зберігати і як отримати до них доступ. Для будь даної системи баз даних є одна логічна схема. Вона є описом властивостей типів даних, які потім визначають властивості екземплярів даних в базі даних. Вона описується формальною мовою, який може бути оброблений комп'ютером. Ця мова іноді називають мовою опису даних логічної схеми (logical schema data definition language або logical schema DDL).
На цьому етапі природно виникає питання: як має виглядати реляційна логічна схема. Докладний відповідь на це питання наведено в Книгах 2 і 4, де ви дізнаєтеся про мови опису даних логічної схеми для реляційної бази даних. Простіше кажучи, ефект створення реляційної схеми полягає в створенні різних заголовків таблиць, які включають приватну систему реляційної бази даних. Так, реляційна схема університету буде складатися з визначень заголовків таблиць, які складають реляційну базу даних університету, наприклад, заголовки двох таблиць на рис. 2.8. Важливо відзначити, що визначення цих заголовків буде включати обмеження щодо примірників даних, які можуть з'явитися під цими заголовками. В якості ілюстрації зауважимо, що визначення колонки СтудентІд (StudentId) в таблиці Студент (Student) гарантує, що тільки достовірні однозначні ідентифікаційні номери студентів можуть з'явитися як екземпляри в даній колонці (на відміну від, скажімо, імен студентів). Заголовки колонок таблиці Студент (Student) є "властивостями типів даних", в той час як індивідуальні рядки є екземплярами даних, які узгоджуються з властивостями даних.
Схема користувачів (userschema) - це визначення логічних властивостей даних, які користувальницький процес повинен відсилати тому користувачеві, якому необхідні ці дані. Як і логічна схема, схема користувачів є визначення властивостей типів даних і вони визначаються у формі, яка може бути оброблена комп'ютером. Так як, зазвичай, база даних необхідна кільком користувачам, то існує багато схем користувачів, кожна з яких заснована на одній і тій же єдиною логічною схемою. Тільки через налаштовувану схему користувач може отримати доступ до бази даних. Користувальницький процес може використовувати тільки одну схему користувача. Зазвичай, кілька користувальницьких процесів можуть зажадати одну і ту ж схему користувачів - перегляд даних - і тому можуть спільно використовувати одну й ту ж схему користувачів.
В будь-якій даній системі бази даних структура схеми користувачів може відрізнятися від логічної схеми. Наприклад, в термінах реляційного підходу, схема користувачів може пропустити певні таблиці, які описуються в цій схемі або може пропустити колонки з цих таблиць. Вона може описувати таблицю, яка складена з даних, що знаходяться в більш, ніж однієї таблиці, визначеної у схемі. Отже, схема розподілу (mapping) визначає як дані, що описуються схемою користувачів, можуть бути отримані з даних, що описуються логічної схемою. Кожна схема користувачів має відповідну схему розподілу.
На рис. 2.11 дан приклад реляційної схеми користувачів з показом деяких екземплярів даних.
-
Студенти і консультанти (StudentsWithCounsellors)
Итендифікаційний номер студента (StudentId)
Имя (Name)
Час регістрації, (Registered)
Имя консультанта (CounsellorName)
Регіон (Region)
s01
Akeroyd
1988
Jennings
3
s02
Thompson
1993
Heathcote
4
s05
Ellis
1992
Heathcote
4
s07
Gillies
1991
Jennings
3
s09
Reeves
1993
Heathcote
4
s10
Urbach
1992
Heathcote
4
Рисунок 2.11 Реляційна схема користувачів
Схема користувачів, яка складається тільки з однієї таблиці з назвою Студенти та консультанти (StudentsWithCounsellors), задовольняє потреби (гіпотетичної) групи користувачів, яким необхідні дані про студентів, але яких більше цікавить ім'я консультанта студента, а не його кадровий номер. Тому таблицю (схему користувачів) Студенти та консультанти (StudentsWithCounsellors) виводять з двох базових таблиць (схем) Студент (Student) і Персонал (Staff). Оскільки Студенти та консультанти (StudentsWithCounsellors) - це таблиця, її виведення з таблиць Студент (Student) і Персонал (Staff) - складання схеми розподілу - можна описувати в термінах тверджень (операторів) в реляційному DML (мові управління даними) 13. DBMS не буде зберігати дані, визначені в такій таблиці, як Студенти та консультанти (StudentsWithCounsellors), а виведе необхідні дані шляхом складання схеми распределенія14
Кожен користувальницький процес включає опис (мовою DML) деякого маніпулювання даними, визначеними схемою користувачів, до якої звертається користувальницький процес. Це маніпулювання досягається за допомогою тверджень (операторів), які описують введення, видалення, зміна і пошук даних, викликаних для користувача процесом. Ці оператори діють відповідно до даних, визначених схемою користувачів, а складання схеми розподілу для схеми користувачів можна розглядати як переклад цих операторів в дії з даними, визначеними базової логічної схемою. Хоча користувальницький процес не включає релевантну схему користувачів, він включає структури даних, що відповідають структурам схеми користувачів, які дозволяють передавати дані в і з схеми користувачів. Це необхідно для того, щоб користувальницький процес компонував (ассембліровал) нові дані і перевіряв зберігаються дані.
Схема зберігання - це визначення того, як зберігати і отримувати доступ до даних, визначених у логічній схемі. Визначення відбувається за допомогою мови, яка іноді називають мовою опису даних схеми зберігання (storage schema data definition language (або storage schema DDL). Для наших цілей існує одна схема зберігання для даної системи бази даних, точно так само як існує одна логічна схема. Детальний розгляд структур, визначених у схемі зберігання, не входить в завдання даного курса15, але ви повинні уявляти собі зберігання файлів, структури файлів і методи доступу. Дані в кожній таблиці, описані в логічній схемі, необхідно якось фізично зберігати. Це здійснюється шляхом розміщення даних кожної таблиці в запам'ятовуючому файлі (stored file), який управляється операційною системою комп'ютера. Кожен зберігається файл зберігається у відповідності зі структурою (організацією) файлу (file organization) (впорядкованої, індексного або хешірованное), що підтримує метод доступу (access method), з допомогою якого збережені записи (stored records), що складають даних файл, можуть бути збережені і витягнуті. Таким чином, схема зберігання застосовує методи з технології масової пам'яті (запам'ятовує великої ємності), використовуваної в обчислювальних системах.
Інша схема розподілу описує те, як дані, визначені в логічній системі, реалізуються структурами зберігання і доступу в схемі зберігання.
На рис. 2.10 показані дві ламані лінії: одна, що проходить через користувальницькі процеси, і інша, проведена між схемою зберігання та збереженої базою даних. Ці ламані лінії вказують межі між різними схемами та іншими компонентами в системі бази даних.
Верхня ламана лінія, що проходить через користувальницькі процеси, показує, що вони не є частиною архітектури схеми повністю. Той факт, що вони використовують оператори, які діють відповідно до даних, описаними схемами, і включають структури даних, які відповідають схемі користувачів, означає, що вони є частиною архітектури схеми. Однак, той факт, що користувальницький процес включає багато того, що не відноситься безпосередньо до архітектури схеми - обчислення за даними перед і після будь-якого доступу до бази даних і механізми для введення або виведення користувачем - означає, що вони не повністю є частиною архітектури схеми.
Нижня ламана лінія - між схемою зберігання та збереженої базою даних, вказує, що примірники даних в збереженої базі даних не є частиною архітектури схеми. Як уже підкреслювалося, різні схеми - це визначення в термінах типів, тоді як зберігається база даних є просто сукупністю екземплярів і не є визначенням в тому сенсі, в якому ми використовуємо цей термін.
Важливо оцінити вихідну роль логічної схеми в архітектурі схеми. Логічна схема - це центральне визначення структури та семантики даних в збереженої базі даних; це база для забезпечення різних схем користувачів. Вона визначає типи даних, відповідно до яких, в кінцевому рахунку, оператори будуть діяти в користувальницьких процесах. Крім того, вона визначає типи даних, які, в кінцевому рахунку, будуть зберігатися в базі даних у відповідності зі структурами зберігання і доступу, визначеними у схемі зберігання.
Переваги даної архітектури:
Спільне використання даних додатками. Компонент архітектури схеми користувачів забезпечує кожен додаток поданням відповідних даних, в той час як асоційована схема розподілу між схемою користувачів і логічною схемою визначає як це подання постійних даних, орієнтоване на додаток, пов'язано з даними, описаними логічної схемою. Більше того, може бути введена керована надмірність. На реляційної схемою користувачів, наведеною на рис. 2.11, повторюється ім'я консультанта (у вигляді значення Ім'я консультанта (CounsellorName)) для кожного студента цього консультанта. Однак, ця надмірність контролюється в тому сенсі, що кожне повторення значення Ім'я консультанта є повтором значення Ім'я (Name), яке зберігається тільки один раз в основний таблиці Персонал (Staff) (логічної схеми), як це показано на рис. 2.8. За умови, що на будь-яку зміну імені консультанта впливає зміна значення Ім'я (Name) в основній таблиці Персонал (Staff), схема розподілу гарантує, що ця зміна буде передано всім копій.
Краща розробка додатків. При обговоренні методу бази даних в розділі 2.1.2 стверджувалося, що краща розробка додатків можлива, якщо обмеження будуть перебувати під жорстким контролем DBMS. Дана архітектура дозволяє це зробити. Обмеження виражені централізовано в логічній схемі, з складанням схеми розподілу між схемою користувачів і схемою, яка гарантує, що обмеження є ефективним для даних, якими маніпулює користувальницький процес.
Можливість реагувати на зміни. Тепер оцінимо, як можна мінімізувати вплив змін користувацького процесу на структуру даних. У розділі 2.1.2 ми описали стан справ при файловому підході, коли зміна в структурі даних вимагає зміни в програмному коді програми. Ця ситуація відома під назвою залежність від даних (data dependence), коли відомості про повну логічну структуру даних, їх фізичного зберігання і доступу до них вбудовуються в логіку або код програм-додатків. І навпаки, архітектура схеми показує, що DBMS може забезпечити незалежність даних (data independence) двома шляхами: фізичну незалежність даних і логічну незалежність даних.
Фізична незалежність даних: зміни у фізичному зберіганні даних або в методах доступу до даних необов'язково призводять до необхідності зміни програм-додатків.
Фізична незалежність даних є результатом відділення логічної схеми від схеми зберігання. Будь-яка зміна в методі фізичного зберігання або методі доступу є зміною схеми зберігання. Логічна схема ізольована від змін у схемі зберігання в силу складання схеми розподілу між двома схемами, тому вимагати зміни може схема розподілу, а не логічна схема. Якщо логічна схема не змінюється, то відсутня необхідність у зміні прикладних програм.
Логічна незалежність даних: зміни у логічній структурі необов'язково повинні привести до необхідності ізмененіясуществующіх прикладних програм.
Логічна незалежність даних є результатом відділення схеми користувачів від логічної схеми. Зміна в логічній структурі є зміною в логічній схемі, яке виникає або в результаті нової програми, що вимагає нових структур даних, або через необхідність модифікації існуючих структур даних у зв'язку з тим, що наявне додаток змінює свої вимоги до даних. Однак, схеми користувачів інших існуючих прикладних програм ізольовані від змін в логічній схемі в силу складання схеми розподілу між двома схемами, тому вимагати зміни може схема розподілу, а не схема користувачів. Якщо існуюча схема користувачів не змінюється, то відсутня необхідність у зміні наявних прикладних програм.
Централізований контроль. Централізоване положення DBMS обумовлено роллю, яку відіграють логічна схема та архітектура схеми. Обмеження і механізми контролю доступу, виражені у схемі, застосовні як до збережених даних (що описано у схемі зберігання), так і до використання даних додатками (что описано в схеме пользователей).
Архітектура обробки
Перед тим, як описувати архітектуру обробки (даних), необхідно ввести поняття системи контролю базами даних (database control system) (або DBCS). Система управління базами даних є частиною DBMS (DBMS), яка надає і контролює доступ до бази даних. Багато функцій, які ми привели в розділі 2.2.1 забезпечуються додатковими компонентами DBMS, яка в свою чергу використовує DBCS. DBCS отримує всі запити про доступ або маніпулює даними в базі даних. Більш детальну оцінку природи і ролі DBCS можна отримати з розгляду архітектури обробки.
Спрощений аспект архітектури обробки полягає в тому, що використання DBMS включає два різних етапи. Перший етап стосується створення схем, другий етап стосується використання бази даних для пошуку та оновлення (даних).
Перший етап охоплює визначення бази даних, виходячи з вимог до даних, що показано на рис. 2.12. Цей етап починається зі специфікації (на відповідній мові DDL) різних схем і відповідних схем розподілу. Визначення схеми, тобто вихідна схема, потім повинна бути оброблена модулем DBMS, який створює збережену форму схеми. Модуль забезпечує функцію визначення даних DBMS і його називають процесором схеми (schema processor). Процесор схеми контролює синтаксис і несуперечність визначень і, якщо вони є прийнятними, створює кодовану форму, яка називається об'єктної схемою (object schema). Об'єктна схема необхідна для постійного використання, так що процесор схеми використовує DBCS для зберігання цієї форми схеми. Схема об'єкта, що зберігається, складається зі схеми користувачів, логічної схеми, схеми зберігання і відповідних схем розподілу.
Другий етап архітектури обробки, показаний на рис. 2.13, охоплює доступ до бази даних для пошуку та оновлення даних різними типами користувачів. Тільки два методи доступу до бази даних розглядають на цьому етапі моделі: доступ за допомогою прикладних програм і доступ за допомогою мови запитів.
Взагалі, може бути будь-яка кількість прикладних програм, які можуть мати доступ до приватної базі даних, кожна для конкретної мети. Нас не цікавлять подробиці написання цих програм; досить знати, що вбудованими всередину кожної програми є запити на доступ до деякої частини бази даних, визначених схемою користувачів. Ці запити виражені за допомогою мови маніпулювання даними (DML), і якщо він застосовується з метою обробки моделі, то його називають вбудованим мовою (embedded language). Оператори DML вбудовуються в оператори, написані на мові програмування, що використовується для даної прикладної програми. Кажуть, що мова програмування виконує роль ведучого вузла (host) щодо DML. Коли виконується оператор вбудованої мови прикладної програми, то DBCS запускається на виконання необхідного доступу до бази даних. Для наших цілей ми можемо відзначити три чинники, що стосуються цього методу обробки. Перший: користувач прикладної програми не видає запити DBCS. Користувач тільки надає дані, до певної міри задовольняють потреби користувача, а запити до DBCS видає прикладна програма, виходячи з даних, введених користувачем. Другий: користувач не отримує дані безпосередньо від DBCS. Швидше користувач отримує дані, в деякій мірі, задовольняють його потреби, від прикладної програми (яка, звичайно ж, отримує їх від DBCS). Третійфактор: кожна прикладна програма створюється для конкретної мети.
Альтернативним способом отримання доступу до бази даних, як показано на рис. 2.13, є використання мови запитів (query language). Незважаючи на підтекст у назві, мови запитів можна використовувати для пошуку або оновлення бази даних. Користувачі можуть використовувати мову запитів через процесор запитів (query processor) 16 - програми, яка взаємодіє з користувачами, щоб обробити їх оператори запитів, що запитують доступ до бази даних. Оператори запитів виражені в термінах DML і видаються безпосередньо користувачем. Користувач мови запитів може направити будь-який оператор запиту процесору запитів і оператор буде виконаний викликаної DBCS, щоб дати необхідний доступ до бази даних з відповіддю, який повернеться прямо до користувача. Процесор запитів пишеться для використання з конкретною DBMS, але він є універсальною програмою, яку можна використовувати для доступу до певної бази даних, використовуючи DDL для цієї DBMS (на відміну від прикладної програми, яка написана для доступу до конкретної бази даних за допомогою заданого методу) .
Доступ до бази даних за допомогою прикладних програм або процесора запитів контролюється DBCS. DBCS - це інша універсальна програма, яку можна використовувати для будь-якої бази даних, описаної відповідним DDL. Метод, за допомогою якого вона обробляє будь-який запит на доступ до бази даних, визначається описами бази даних, наведених в об'єктної схемою. Отже, будь-який доступ до бази даних вимагає відповідної збереженої об'єктної схеми (тобто збереженої схеми користувачів, логічної схеми, схеми зберігання та схеми розподілу) доступною для DBCS.
По-перше, в архітектурі не враховано той факт, що раз обробляється вихідна схема, то необхідно створити відповідні структури фізичного зберігання до того, щоб можна було користуватися базою даних - ці структури є, по суті, контейнерами, в яких можуть зберігатися дані. Даний процес може послідувати автоматично за обробкою схеми або може бути частиною процесу, який включає завантаження існуючих файлів даних у базу даних.
По-друге, операційна система, хоча вона і не включена в архітектуру, формує частину середовища бази даних і відіграє певну роль в обробці бази даних. Роль операційної системи полягає в забезпеченні функцій введення і виведення, яких потребує DBMS, щоб розмістити дані на дисках, що використовуються для зберігання. Мають місце суттєві відмінності в цих функціях для різних операційних систем і в методах, за допомогою яких різні DBMS використовують їх. Це призводить до численних відмінностей в ролі і специфікації схем зберігання, які ми не будемо розглядати в даному курсі. Однак, варто навести загальні принципи і тому в наступному підрозділі ми кілька конкретизуємо частина архітектури обробки, щоб показати використання операційної системи і простий архітектури для зберігання.
Архітектура для зберігання
Операційна система комп'ютера зберігає дані для DBMS, використовуючи файли, якими вона управляє. Взагалі, ці файли зберігаються на жорстких дисках великої ємкості (багато мільйонів байт), але ті ж принципи застосовні і до файлів на гнучких дисках (дискетах). Дані передаються на диск і з диска в блоці (який також називають сторінкою), який має заданий розмір, наприклад, 1 або 4 кілобайт. Блоки повинні бути організовані таким чином, щоб окремі блоки можна було зберігати і знаходити на вимогу. Роль операційної системи в обробці блоків даних представлена на рис. 2.14.
На рис. 2.14 показаний тільки спосіб, за допомогою якого DBCS використовує операційну систему, але слід пам'ятати, що DBCS сама потребує схемах. Саме схема зберігання разом з деталями реалізації конкретної DBMS визначає фактичну форму даних, які DBMS надає операційній системі як збережену запис. Збережена запис містить дані з однієї або більше логічних записів разом з різними типами додаткових даних, пов'язаних із зберіганням та пошуком, наприклад, мітку DBMS для відповідної логічної запису (записів), її розміщенні в блоці і покажчики на будь-які інші збережені записи, з якими вона може бути пов'язана.
Коли операційна система отримує збережену запис, вона зберігається у відповідності з деякою організацією (структурою) файлу, а пізніше може бути знайдена за допомогою методу доступу. Операційна система може забезпечити ряд структур файлу, якими буде користуватися DBMS; для кожного типу запису структура файлу або визначається в межах схеми зберігання, або автоматично вибирається DBMS. Структура файлу забезпечує засоби розміщення збережених записів на диску, а один чи більше відповідних методів доступу забезпечують спосіб пошуку таких записів
Общая модель РСУБД, концептуальная архитектура РСУБД
Вважається, що РСУБД можуть обслуговувати як локальні, так і глобальні мережі. Вузли в локальній мережі можуть мати шинну, кільцеву або зоряну конфігурацію. Всі лінії локальних мереж мають досить велику швидкість і невеликий відсоток помилок. У глобальній мережі використовується або повністю пов'язана конфігурація при невеликому числі вузлів, або частково пов'язану конфігурацію.
На кожному вузлі РСУБД запускається диспетчер транзакцій, який обробляє транзакції цього вузла, планувальник, який забезпечує планування обробки запитів з інших вузлів, а також диспетчер даних, який по командам планувальника запускає роботу.
Виділяють однорідні і неоднорідні розподілені бази даних:
• Неоднорідні - на окремих вузлах РСУБД функціонують СУБД від різних постачальників або однотипні СУБД функціонують на різних платформах.
• Однорідні - однакові операційні системи, однакові СУБД і так далі - все просто.
Концептуальна архітектура РСУБД
Як
для централізованих СУБД, так і для
нецентралізованих СУБД, типовим рішенням
є трирівнева архітектура ANSI -
SPARC. Концептуальна
архітектура РСУБД
Концептуальна
архітектура РСУБД
Схема фрагментації описує, які частини бази даних де знаходяться.
Незалежно від того, як побудована концептуальна модель, компонентна модель повинна включати наступні компоненти:
1) Локальна СУБД на кожному локальному вузлі з локальним каталогом;
2) Компонент передачі даних;
3) Глобальний системний каталог - інформація про те, де знаходяться інші частини бази даних;
4) Розподілена СУБД - набір додаткового програмного забезпечення, надбудова над локальної СУБД, яка забезпечує об'єднану роботу локальних вузлів.
ODBC
Припустимо, є клієнт, написаний наприклад на Visual C, є база даних (ORACLE, MS SQL) і ціла купа різних Desktops БД (Access, dBase, Paradox, Excel і т.д.). Як же відбувається взаємодія? Перш за все, в системі встановлюється Microsoft Driver Manager (odbc32.dll). Ця dll-ка взаємодіє іноді з odbcint.ini і odbc.ini. Для роботи з цією dll-кою є адміністратор, який дозволяє підключати драйвери (те що ми бачимо в панелі керування).
Є
ODBC Administrator - це ніщо інше, як odbcad32.exe,
odbccp32.dll і odbccp32.cpl - бачимо в панелі
управління. За допомогою цих коштів ми
запускаємо адміністратор (через
піктограму odbccp32.cpl), і там можна
встановлювати ім'я бази, підключати
драйвери, псевдоніми давати баз даних
і т.д. і т.д. Для кожної бази даних в
системі повинен бути відповідний
драйвер. Наприклад, ODBC driver для ORACLE (як
правило, є в системі); драйвер для MS SQL
Server - теж є; драйвер, який найчастіше
інтегрований, оскільки це бази все
простенькі, - odbcjt32.dll - для різних
Desktop-вських СУБД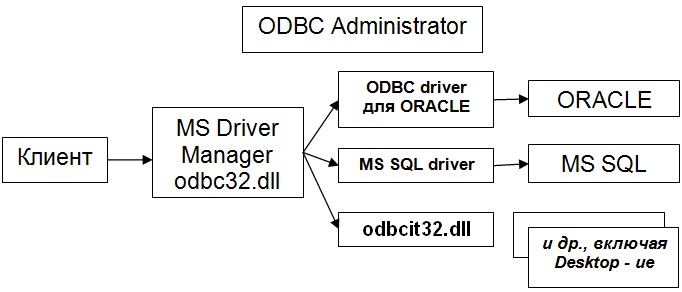 Рис.
Архитектура ODBC
Рис.
Архитектура ODBC
Таким чином, проміжне програмне забезпечення досить велика. Клієнт в ручному режимі налаштовує псевдонім і вказує шлях для бази даних, вибирає драйвер. Коли клієнт звертається, то він звертається до driver managerу, бере потрібний драйвер, а потрібний драйвер буває часто записаний в цих файлах, а останнім часом в реєстрі Windows (лізе в реєстр Windows і знаходить драйвер, підключає цей драйвер і звертається до БД).
ODBC API
ODBC API включає близько 56 функцій. Це було створено в 92 році, тому вона реалізована на рівні функцій, тобто має функціональне подання.
Трохи пізніше був розроблений BDE, який фактично умовно вважається об'єктно-орієнтованим, але об'єктно-орієнтованого там мало, все одно там є теж функції. BDE краще забезпечує доступ до Desktop-ким СУБД, оскільки у Borland - а більше такі прості бази даних. Там можна настроювати різні мови. Але зараз це правда нікому не потрібно, тому що всі драйвери універсальні стали робити, їм все одно. Драйвери пропускають просто дані незалежно від мови. В результаті вийшло так, що для використання BDE треба інсталювати 17мб і не ясно, що з них «можна викинути", у той час як реалізація конкретного доступу на ODBC зажадає менше мегабайта.
JDBC
Стандарт JDBC спочатку розроблений, щоб мати доступ до БД за такою ж архітектурі спершу включав в себе міст JDBC / ODBC Bridge, а далі підключалися ODBC-шні драйвера. Але з плином часу навчилися робити і свої драйвери більш прямі, і природно тут, як мовиться, багаторазове перетворення, а там вийшло одне перетворення «і стали більш швидкими».
OCI
Стандарт OCI призначений тільки для доступу до баз даних ORACLE. На відміну від Microsoft пропонує трохи інший драйвер. Тобто є: клієнт, sqloci32.dll, який з'єднується з NET8.
Драйвер NET8 завжди є в базі даних ORACLE. Microsoft, у свою чергу, підключається до ORACLE, минаючи NET8 з будь операційною системою, якщо ви встановлюєте Office, то там цей драйвер є. Однак сам ORACLE для себе робить більш маленьку dll-ку, тому що у нього завжди є драйвер NET8 добре налагоджений.
OLE DB і ADO
З плином часу чисто функціональний підхід до створення проміжного програмного забезпечення став трошки входити в дисонанс з об'єктно-орієнтованими середовищами розробки, і було розроблено два нових стандарту OLE DB і ADO.
Що
собою фактично представляють OLE DB і ADO?
Загальна більш сучасна структура доступу
від додатки до БД на думку Microsoft на
сьогодні виглядає наступним чином: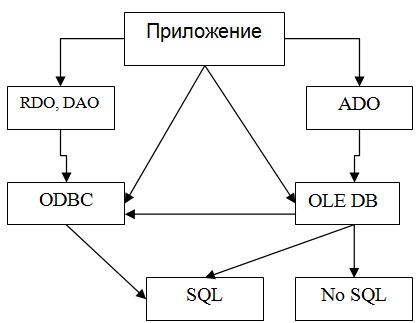 Рис.
Сучасна структура доступу від додатки
до БД
Рис.
Сучасна структура доступу від додатки
до БД
Є додаток або клієнт, драйвери OLE DB або постачальники, є ADO. Ось як за структурою від Microsoft може бути реалізований доступ до SQL - їм даним і до не SQLскім даними (наприклад, до якихось текстовим даними, теж є драйвери). OLE DB провайдери чисто об'єктно-орієнтовані: там є класи, об'єкти, методи. Однак оскільки OLE DB сам стандарт досить важкий, «такі книги по ньому», то для спрощення доступу зроблений простий інтерфейс ADO, за допомогою якого з багатьох середовищ таких як Visual Basic, Delphi, та ін можна по-простому звертатися ось таким чином. ODBC нікуди не зник, тому що OLE DB провайдери. Microsoft зробив тільки сім провайдерів: для «себе коханого», для ORACLE, для ODBC для всіх інших баз даних, для текстових і т.д. всього їх 7 штук. Бажаючих далі розробляти цей провайдер не виявилося, і ця система ось так от і залишилася. Якщо є прямий провайдер до MS SQL і ORACLE то можна напряму (1).
ADO
дозволяє мати доступ: або ось так (2),
якщо провайдера немає, і (3), якщо провайдер
є. Рис.
Набір об'єктів ADO
Рис.
Набір об'єктів ADO
connection - організовує з'єднання бази даних, тобто інкапсулює всі відомості про з'єднання: ім'я бази даних і т.д. і т.д.
command - об'єкт має методи для виконання команд.
streams - робота з потоками.
fields - для роботи з полями.
Така архітектура ADO для доступу баз даних, тобто це невеликий комплект об'єктів, у якого є певний набір методів, за допомогою яких зчитувати записи безпосередньо через потоки, якщо з файлів зчитувати і т.д.
Таким чином на сьогодні сформовано цілий напрям проміжного програмного забезпечення (ODBC, JDBC, ADO, OLE DB, BDE, OCI), призначення якого дати можливість розробляти клієнтські програми на різних мовах і підключатися до існуючих баз даних. Для цього потрібні тільки драйвери і ось це проміжне ПО, яке може працювати з цими драйверами. Тим самим «був розв'язаний вузол» між постачальниками баз банних і постачальників мов, вони звичайно поставляли мови але кошти були дуже і дуже обмежені
Базу даних можна уявити як людинозорієнтовану і комп'ютерозорієнтова-ну модель даних, кожна з яких визначає своє середовище збереження даних. Людинозорієнтована модель бази даних відображається в паперових документах і в пам'яті людини, а компютерозорієнтоваиа - на фізичних носіях ЕОМ. Кожний рівень даних характеризується своїм описом (сприйняттям) елементів даних - зовнішній (інфологічний), концептуальний (даталогічний) і внутрішній (фізичний) рівень. Ці рівні формують трирівневу архітектуру баз даних.
Опис, виконаний із використанням природної мови, математичних формул, таблиць, графіків та інших засобів, зрозумілий людям, які працюють над проектуванням бази даних, називають інфологічною моделлю даних. Основними конструктивними елементами іифологічної моделі є сутності, зв'язки між ними та їхні властивості. Сутність - це будь-який об'єкт, інформацію про який потрібно зберігати в базі даних. Сутностями можуть бути товари, виробники товарів, банківські рахунки тощо. Властивість - піменована характеристика сутності (поточний рахунок, фірма "Світоч" тощо). Для прискорення пошуку конкретних атрибутів бази даних використовують ключі. Ключ - мінімальний набір атрибутів, за значенням яких можна однозначно знайти необхідний примірник сутності. Наприклад, для сутності Розклад_занять ключем є атрибут №_групи або набір: Дмс-ципліна, Час і Лектор.
Одна з основних вимог до організації бази даних - це забезпечення можливостей знаходження одних інформаційних об'єктів за значенням інших, для цього необхідно встановити між ними певні зв'язки. Оскільки в реальних базах даних нерідко зберігаються сотні і навіть тисячі сутностей, то теоретично між ними може бути встановлено більше, ніж мільйон зв'язків. Наявність такої множини зв'язків і визначає складність інфологічних моделей.
Під час побудови інфологічних моделей, як правило, використовують мову ER-діаграм (від англ. Entity-Relationship - сутність-зв'язок). У них сутності відображаються прямокутниками, асоціації - ромбами або шестикутниками, атрибути - овалами, а зв'язки між ними - неналравленими ребрами, над якими можуть проставлятися ступені зв'язку (1 або буква, яка заміняє слово "багато") і необхідні пояснення. Між двома сутностями, наприклад А і В, можливі чотири типи зв'язків.
Перший тип - зв'язок "один-до-одного" (1:1): у кожний момент часу кожному представникові сутності А відповідає 1 або 0 представників сутності В.
Другий тип - зв'язок "один-до-багатьох" (1:М): одному представникові сутності А відповідає 0,1 або кілька представників сутності В.
Між двома сутностями можливі зв'язки в обох напрямках, тому існують ще два типи зв'язків "багато-до-одного" (м:1) і "багато-до-бага-тьох" (м:n).
Побудова хорошої інфологічної моделі - досить складний процес. Досвід побудови таких моделей десятиліттями формували провідні спеціалісти у сфері обробки даних.
Інфологічна модель даних є основою для розробки концептуальної моделі даних (даталогічноі). Концептуальний рівень описує дані, які мають зберігатись на машинних носіях, а також зв'язки, які існують між ними, і містить логічну структуру всієї бази даних. На цьому рівні описуються типи даних, здійснюється їх нормалізація, визначається перелік файлів бази даних.
Організація обробки даних у СУБД
База даних, як правило, містить дані, що потрібні багатьом користувачам. Отримання одночасного доступу кількох користувачів до спільної бази даних можливе в разі встановлення СУБД у локальній мережі персональних комп'ютерів і створення бази даних для багатьох користувачів (рис. 2.20).
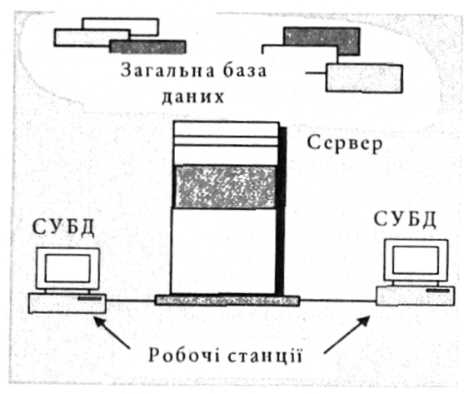
. СУБД у багатокористувацькій системі
Організація обробки даних залежить від способу їх розподілу. Існують централізований, децентралізований і мішаний способи розподілу даних.
Централізована організація даних є найпростішою для реалізації
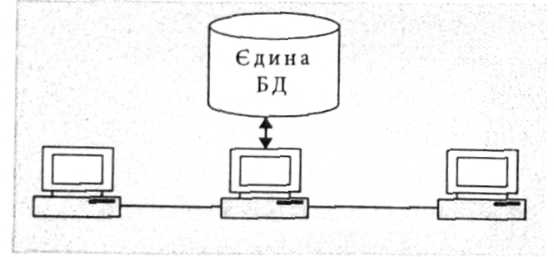
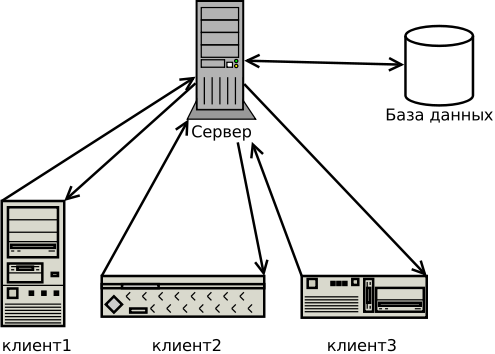
Централізована організація даних
На одному сервері є єдина копія бази даних. Усі операції з базою даних забезпечує сервер. Доступ до даних здійснюється за допомогою віддаленого запиту, або трансакції. Перевагою такого способу є легка підтримка бази даних в актуальному стані, недоліком - обмеження розміру бази ємністю зовнішньої пам'яті сервера, усі запити направляються до одного сервера, що зумовлює затримку зв'язку і, відповідно, обробки.
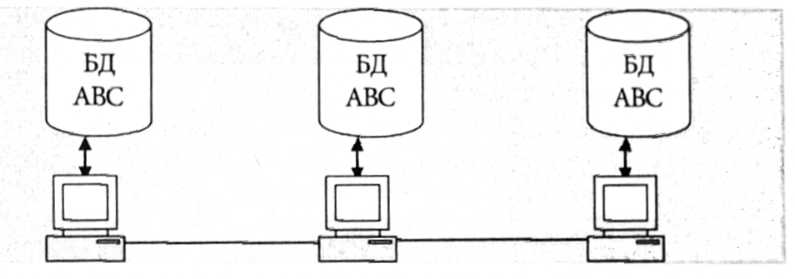
Децентралізована організація даних передбачає поділ інформаційної бази на кілька фізично поділених. Кожний клієнт використовує свою базу даних, яка може бути або частиною загальної інформаційної бази (рис. 2.22), або її копією (рис. 2.23).
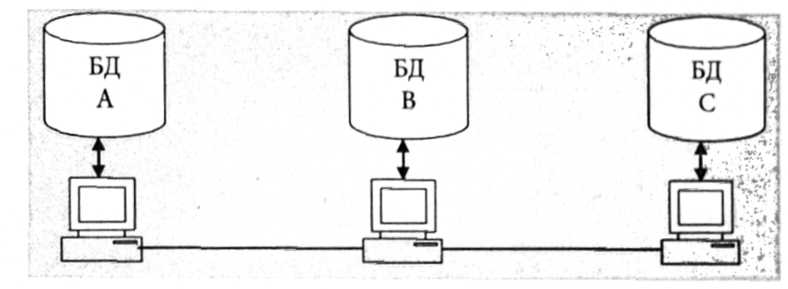
. Децентралізована організація даних засобом поділу
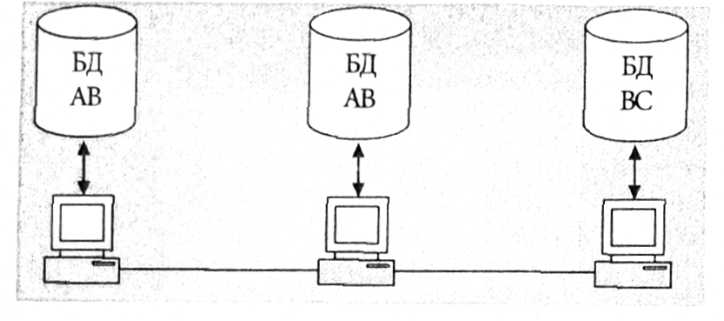
Децентралізована організація даних засобом дублювання
Переваги цього методу: користувацькі запити надходять до локальних баз, що скорочує час відповіді; збільшується надійність зберігання; вартість запитів знижується тощо.
Недоліки системи - підвищення вимог до ємності зовнішньої пам'яті, ускладнення в редагуванні баз даних, оскільки потрібна синхронізація для узгодження копій.
Така система організації даних передбачає наявність інформації про її розташування, тобто має бути керуюча програма, за допомогою якої здійснюється пошук потрібних даних.
У базі з централізованою організацією даних головну роль виконує сервер бази даних. Він забезпечує реалізацію багатокористувацького інтерфейсу (доступ користувачів до всіх файлів). Файлові сервери здійснюють переміщення повних копій файлів від сервера до робочої станції і у зворотному напрямку.
Можлива і мішана організація даних, яка об'єднує два способи -поділ і дублювання, набуваючи при цьому і переваг, і недоліків обох способів (рис. 2.24).
Мішана організація даних
У мережі СУБД стежить за розмежуванням доступу різних користувачів до спільної бази даних і забезпечує захист даних за одночасної роботи користувачів зі спільними даними.
У мережі з файловим сервером база даних може розміщуватися на сервері. При цьому СУБД завантажується і здійснює обробку даних бази на робочих станціях користувачів.
Концепція файлового сервера в локальній мережі забезпечується низкою мережевих операційних систем (Microsoft Windows NT, Novell NetWare тощо)
У мережі, що підтримує концепцію "клієнт/сервер", використовується сервер баз даних, який розміщується на потужній машині, виконує обробку даних, що розміщені на сервері, і відповідає за їхню цілісність і збереження. Для управління базою даних на сервері використовується мова структурованих запитів SQL (Structured Queries Language).
На робочих станціях-клієнтах працює СУБД-клієнт. Користувачі можуть взаємодіяти не лише зі своїми локальними базами, а й з даними, що розташовані на сервері. СУБД-клієнт, в якій підтримується SQL, у повному обсязі може надсилати на сервер запити SQL, отримувати потрібні дані, а також надсилати поновлені дані. При цьому зі спільною базою даних можуть працювати СУБД різного типу, що встановлені на робочих станціях, якщо в них підтримується SQL.
Системна архітектура “клієнт-сервер”
Система розбивається на дві частини, які можуть виконуватися в різних вузлах мережі, - клієнтську й серверну частини. Прикладна програма або кінцевий користувач взаємодіють із клієнтською частиною системи, що у найпростішому випадку забезпечує просто надмережний інтерфейс. Клієнтська частина системи при потребі звертається по мережі до серверної частини. Помітимо, що в розвинених системах мережне звертання до серверної частини може й не знадобитися, якщо система може вгадувати потреби користувача, і в клієнтській частині втримуються дані, здатні задовольнити його наступний запит.
Інтерфейс серверної частини визначений і фіксований. Тому можливо створення нових клієнтських частин існуючої системи (приклад інтероперабельності на системному рівні).
Основною проблемою систем, заснованих на архітектурі “клієнт-сервер”, є те, що відповідно до концепції відкритих систем від них потрібна мобільність у якомога більшому широкому класі апаратно-програмних рішень відкритих систем. Навіть якщо обмежитися UNIX-орієнтованими локальними мережами, у різних мережах застосовується різна апаратура й протоколи зв'язку. Спроби створення систем, що підтримують всі можливі протоколи, приводить до їхнього перевантаження та шкоду функціональності.
Ще більш складний аспект цієї проблеми пов'язаний з можливістю використання різних подань даних у різних вузлах неоднорідної локальної мережі. У різних комп'ютерах може існувати різна адресація, подання чисел, кодування символів і т.д. Це особливо істотно для серверів високого рівня: телекомунікаційних, обчислювальних, баз даних.
Загальним рішенням проблеми мобільності систем, заснованих на архітектурі “клієнт-сервер” є опора на програмні пакети, що реалізують протоколи вилученого виклику процедур (RPC - Remote Procedure Call). При використанні таких засобів звертання до сервісу у вилученому вузлі виглядає як звичайний виклик процедури. Засоби RPC, у яких, природно, утримується вся інформація про специфіку апаратур локальної мережі й мережних протоколів, переводить виклик у послідовність мережних взаємодій. Тим самим, специфіка мережного середовища й протоколів схована від прикладного програміста.
При виклику вилученої процедури програми RPC роблять перетворення форматів даних клієнта в проміжні машинно-незалежні формати й потім перетворення у формати даних сервера. При передачі відповідних параметрів виробляються аналогічні перетворення.
Якщо система реалізована на основі стандартного пакета RPC, вона може бути легко перенесена в будь-яке відкрите середовище.
Технологія “клієнт-сервер” стосовно до СУБД зводиться до поділу системи на дві частини - додаток-клієнт (front-end) і сервер бази даних (back-end). Ця архітектура сполучає кращі риси обробки даних на мэйнфреймах і технології “файл-сервер”. Від мэйнфреймов технологія “клієнт-сервер” запозичила такі риси, як централізоване адміністрування, безпека, надійність. Від технології “файл-сервер” успадковані низька вартість і можливість розподіленої обробки даних, використовуючи ресурси комп'ютерів-клієнтів. Зараз графічний інтерфейс користувача став стандартом для систем “клієнт-сервер”. Крім того, архітектура “клієнт-сервер” значно спрощує й прискорює розробку додатків за рахунок того, що правила перевірки цілісності даних перебувають на сервері. Неправильно працюючий клієнтський додаток не може привести до втрати або перекручування даних. Всі ці можливості, раніше властиві тільки складній і дорогій системам, зараз доступні навіть невеликим організаціям. Вартість устаткування, програмного забезпечення й обслуговування для персональних комп'ютерів у десятки разів нижче, ніж для мейнфреймів.
Особливості обробки даних у різних архитектурах показані на Рисунку 1.
Рисунок 1. Обробка даних у різних архітектурах
Локальний комп'ютер


Локальний додаток
 СУБД
СУБД

Дані
Архітектура “файл-сервер”

 Клієнт
Клієнт
 Файл-сервер
Файл-сервер


 Мережевий
додаток
Мережевий
додаток
Дані
СУБД

 Клієнт
Клієнт
Мережевий додаток

Пересилання даних
СУБД
Архітектура “клієнт-сервер”


 Сервер
БД
Сервер
БД
 Клієнтський
додаток
Клієнтський
додаток

Дані
Клієнтський додаток

 пересилання
запитів
пересилання
запитів
і результатів