

5.6. Многомерные массивы
Многомерные матрицы широко используются в математических моделях физического мира, и многомерные массивы появились в языках программирования начиная с языка Fortran. Фактически есть два способа определения многомерных массивов: прямой и в качестве сложной структуры. Мы ограничимся обсуждением двумерных массивов; обобщение для большей размерности делается аналогично.
Прямое определение двумерного массива в языке Ada можно дать, указав два индексных типа, разделяемых запятой:
type Two is
Ada |
T:Two('A'..'Z', 1 ..10); I: Integer;
C: Character;
T('XM*3):=T(C,6);
Как показывает пример, две размерности не обязательно должны быть одного и того же типа. Элемент массива выбирают, задавая оба индекса.
Второй метод определения двумерного массива состоит в том, чтобы определить тип, который является массивом массивов:
Ada |
type Array_of_Array is array (Character range <>) of l_Array;
T:Array_of_Array('A1..>ZI);
I: Integer;
С: Character;
T('X')(I*3):=T(C)(6);
Преимущество этого метода в том, что можно получить доступ к элементам второй размерности (которые сами являются массивами), используя одну операцию индексации:
Ada |
Т('Х') :=T('Y'); -- Присвоить массив из 10 элементов
Недостаток же в том, что для элементов второй размерности должны быть заданы
ограничения до того, как эти элементы будут использоваться для определения первой размерности.
В языке С доступен только второй метод и, конечно, только для целочисленных индексов:
C |
а[1] = а[2]; /* Присвоить массив из 20 элементов */
Язык Pascal не делает различий между двумерным массивом и массивом массивов; так как границы считаются частью типа массива, это не вызывает никаких проблем.
5.7. Реализация массивов
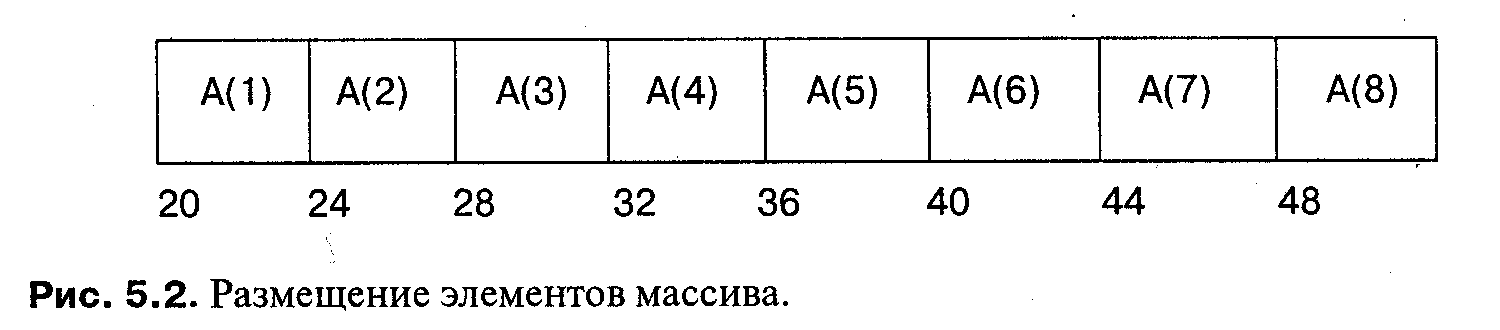
При реализации элементы массива размещаются в памяти последовательно. Если задан массив А, то адрес его элемента A(l) есть (см. рис. 5.2.):
addr (А) + size (element) * (/ - A.'First)
Например: адрес А(4) равен 20 + 4 * (4 - 1) = 32.
Сгенерированный машинный код будет выглядеть так:
L
oad R1,l Получить индекс
sub R1,A'First Вычесть нижнюю границу
multi R1 ,size Умножить на размер — > смещение
add R1 ,&А Добавить адрес массива — > адрес элемента
load R2,(R1) Загрузить содержимое
Вы, возможно, удивитесь, узнав, что для каждого доступа к массиву нужно столько команд! Существует много вариантов оптимизации, которые могут улучшить этот код. Сначала отметим, что если A'First — ноль, то нам не нужно вычитать индекс первого элемента; это объясняет, почему разработчики языка С сделали так, что индексы всегда начинаются с нуля. Даже если A'First — не ноль, но известен на этапе компиляции, можно преобразовать вычисление адреса следующим образом:
(addr (А) - size (element) * A'First) + (size (element) * i)
Первое выражение в круглых скобках можно вычислить при компиляции, экономя на вычитании во время выполнения. Это выражение будет известно во время компиляции при обычных обращениях к массиву:
Ada |
A(I):=A(J);
но не в том случае, когда массив является параметром:
procedure Sort(A: A_Type) is
Ada |
…
A(A'First+1):=A(J);
…
end Sort;
Основное препятствие для эффективных операций с массивом — умножение на размер элемента массива. К счастью, большинство массивов имеют простые типы данных, такие как символы или целые числа, и размеры их элементов представляют собой степень двойки. В этом случае дорогостоящая операция умножения может быть заменена эффективным сдвигом, так как сдвиг влево на n эквивалентен умножению на 2". В случае массива записей можно повысить эффективность (за счет дополнительной памяти), дополняя записи так, чтобы их размер был кратен степени двойки. Обратите внимание, что на переносимость программы это не влияет, но само улучшение эффективности не является переносимым: другой компилятор может скомпоновать запись по-другому.
Программисты, работающие на С, могут иногда повышать эффективность обработки массивов, явно программируя доступ к элементам массива с помощью указателей вместо индексов. Следующие определения:
typedef struct {
C |
int field;
} Rec;
Rec a[100];
могут оказаться более эффективными (в зависимости от качества оптимизаций в компиляторе) при обращении к элементам массива по указателю:
Rec* ptr;
-
C
for (ptr = &а; ptr < &a+100*sizeof(Rec); ptr += sizeof(Rec))
...ptr-> field...;
чем при помощи индексирования:
for(i=0; i<100;i++)
…a[i].field…
Однако такой стиль программирования чреват множеством ошибок; кроме того, такие программы тяжело читать, поэтому его следует применять только в исключительных случаях.
В языке С возможен и такой способ копирования строк:
C |
while (*s1++ = *s2++)
в котором перед точкой с запятой стоит пустой оператор. Если компьютер поддерживает команды блочного копирования, которые перемещают содержимое блока ячеек памяти по другому адресу, то эффективнее будет язык типа Ada, который допускает присваивание массива. Вообще, тем, кто программирует на С, следует использовать библиотечные функции, которые, скорее всего, реализованы более эффективно, чем примитивный способ, показанный выше.
Многомерные массивы могут быть очень неэффективными, потому что каждая лишняя размерность требует дополнительного умножения при вычислении индекса. При работе с многомерными массивами нужно также понимать, как размещены данные. За исключением языка Fortran, все языки хранят двумерные массивы как последовательности строк. Размещение
Ada |
type T is array( 1 ..3, 1 ..5) of Integer;
показано на рис. 5.3. Такое размещение вполне естественно, поскольку сохраняет идентичность двумерного массива и массива массивов. Если в вычислении перебираются все элементы двумерного массива, проследите, чтобы последний индекс продвигался во внутреннем цикле:

intmatrix[100][200];
C |
for(i = 0;i<100;i++)
for (j = 0; j < 200; j++)
m[i][j]=…;
Причина в том, что операционные системы, использующие разбиение на страницы, работают намного эффективнее, когда адреса, по которым происходят обращения, находятся близко друг к другу.
Если вы хотите выжать из С-программы максимальную производительность, можно игнорировать двумерную структуру массива и имитировать одномерный массив:
C |
m[]0[i]=…;
Само собой разумеется, что применять такие приемы не рекомендуется, а в случае использования их следует тщательно задокументировать.
Контроль соответствия типов для массива требует, чтобы попадание индекса в границы проверялось перед каждым доступом к массиву. Издержки этой проверки велики: два сравнения и переходы. Компиляторам для языков типа Ada приходится проделывать значительную работу, чтобы оптимизировать команды обработки массива. Основной технический прием — использование доступной информации. В следующем примере:
Ada |
if A(I) = Key then ...
индекс I примет только допустимые для массива значения, так что никакая проверка не нужна. Вообще, оптимизатор лучше всего будет работать, если все переменные объявлены с максимально жесткими ограничениями.
Когда массивы передаются как параметры на языке с контролем соответствия типов:
Ada |
procedure Sort(A: A_Type) is ...
границы также неявно должны передаваться в структуре данных, называемой дескриптором массива (dope vector) (рис. 5.4). Дескриптор массива содержит
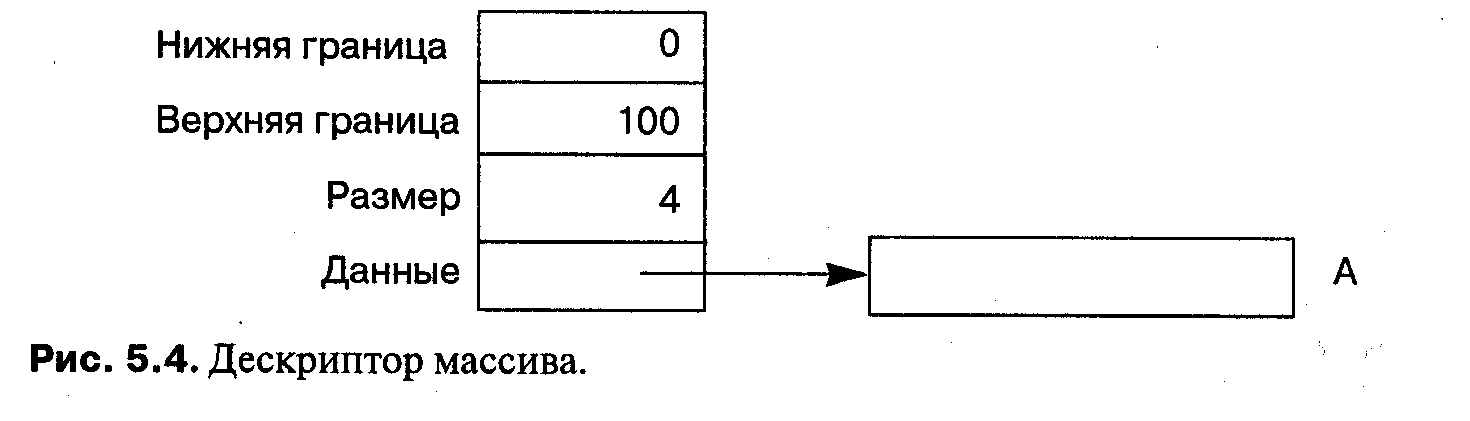
верхнюю и нижнюю границы, размер элемента и адрес начала массива. Как мы видели, это именно та информация, которая нужна для вычисления адресов при индексации массива.