

Cluster Membership (Принадлежность к кластеру)
Case (Случай) |
5 Clusters (5 кластеров) |
4 Clusters (4 кластера) |
3 Clusters (3 кластера) |
2 Clusters (2 кластера) |
1:ALBA |
1 |
1 |
1 |
1 |
2:BELG |
2 |
2 |
2 |
1 |
3:BULG |
3 |
2 |
2 |
1 |
4:DAEN 5:DEUT |
2 |
2 |
2 |
1 |
6:DDR |
2 |
2 |
2 |
1 |
7:FINN |
3 |
2 |
-3 |
2 |
8:FRAN |
4 |
3 |
-3 |
2 |
9:GRIE |
4 |
2 |
2 |
1 |
10:iGROS |
2 |
|
2 |
1 |
11:IRLA |
2 |
2 |
2 |
1 |
12:ISLA |
2 |
3 |
о |
2 |
13:ITAL |
4 |
4 |
1 |
1 |
14:JUGO |
5 |
2 |
2 |
1 |
1 5:LUXE |
3 |
2 |
2 |
1 |
16:NIED |
2 |
|
2 |
1 |
17:NORW |
2 |
2 |
2 |
1 |
18:OEST |
3 |
2 |
2 |
1 |
19:POLE |
3 |
2 1 |
1 |
1 |
20:PORT |
1 |
1 |
1 |
1 |
21:RUMA |
1 |
2 |
|
1 |
22:SCHD 23:SCHZ |
2 |
2 |
2 |
1 |
24:SOWJ |
3 |
1 |
i |
2 |
!25:SPAN |
4 |
1 |
|
|
26:TSCH |
3 |
1 |
1 |
1 |
27:TUER 28:UNGA |
1 |
2 |
1 |
1 |
|
|
|
Пример 4. Классификация стран по уровню жизни населения В 53.4 представлены значения следующих шести показателей, характеризующих условия жизни населения двадцати стран в 1994 г.: x1 — потребление мяса и мясопродуктов на душу населения (кг); х2 — смертность населения по причине болезни органов кровообращения на 100 тыс. человек; х3 — оценка валового внутреннего продукта по паритету покупательной способности в 1994 г. на душу населения (в % по отношению к США); x4 — расходы на здравоохранение (в % от ВВП); x5 — потребление фруктов и ягод на душу населения (кг); x6 — потребление хлебопродуктов на душу населения (кг). Провести классификацию стран по уровню жизни населения и дать содержательную интерпретацию полученных результатов. 53.4 Макроэкономические показатели уровня жизни населения (1994 г.) Решение. В условии задачи не оговорены число классов разбиения и вид законов распределения, а также не даны обучающие выборки. В этой связи при классификации использовались методы кластерного анализа. Исходная информация ( 53.4) показывает, что в рассматриваемую совокупность входят страны бывшего СССР, Восточной Европы и промышленно развитые страны. Поэтому можно предположить, что искомое разбиение стран по уровню жизни населения будет состоять из трех или четырех кластеров. Классификация проводилась по различным алгоритмам кластерного анализа, но наилучшими в содержательном плане оказались результаты, полученные при разбиении стран на четыре класса. В первый кластер вошли одиннадцать (n1 =11) стран: Австралия, Австрия, Бельгия, Великобритания, Германия, Греция, Дания, Ирландия, Испания, Италия, Канада. Наиболее удалена от центра этого кластера Италия, которая характеризуется самым высоким для кластера уровнем потребления фруктов (х5) и хлебопродуктов (x6). Во второй кластер вошли четыре (п2 = 4) страны: Россия, Белоруссия, Казахстан и Киргизия. В третий кластер вошли две (n3 = 2) страны: Болгария и Венгрия. В четвертый кластер вошли три (п4 = 3) страны: Азербайджан, Армения и Грузия. Средние значения показателей для четырех кластеров представлены на 53.3 и в 53.5. 53.3. Средние значения показателей для каждого кластера (цифры у кривых соответствуют номерам кластеров) 53.5 Средние значения показателей Кластер S1, в который входят промышленно развитые страны Запада, характеризуется ( 53.3) самыми высокими значениями: ВВП по паритету покупательной способности (x3), расходов на здравоохранение (х4), потребления мяса (x1) и фруктов (х5), а также самым низким значением смертности (х2). Самое высокое потребление хлебопродуктов на душу населения (х6) у стран, входящих в кластеры S2 и S4. В кластер S4 вошли страны, на территории которых происходили в рассматриваемый период вооруженные конфликты. Этот кластер характеризуется самыми низкими средними значениями показателей х3 и х4, а также x1 — среднедушевым потреблением мяса. Заслуживает внимания матрица расстояний между центрами четырех кластеров: Из матрицы следует, что кластеры S2, S3 и S4 примерно одинаково удалены друг от друга. Евклидово расстояние между ними равно соответственно 60,7; 53,0 и 55,5. Наиболее выделяется по уровню жизни населения кластер S1. Расстояния между S1 и кластерами S2, S3 и S4 равны соответственно 126,8; 83,3 и 120,6.
Пример 5
Поясним суть кластерного анализа, не прибегая к строгой терминологии: допустим, Вы провели анкетирование сотрудников и хотите определить, каким образом можно наиболее эффективно управлять персоналом. То есть Вы хотите разделить сотрудников на группы и для каждой из них выделить наиболее эффективные рычаги управления. При этом различия между группами должны быть очевидными, а внутри группы респонденты должны быть максимально похожи. Для решения задачи предлагается использовать иерархический кластерный анализ. В результате мы получим дерево, глядя на которое мы должны определиться на сколько классов (кластеров) мы хотим разбить персонал. Предположим, что мы решили разбить персонал на три группы, тогда для изучения респондентов, попавших в каждый кластер получим табличку примерно следующего содержания:
Кластер |
Муж |
30-50 лет |
>50 лет |
Рук. |
Мед |
Льготы |
з/п |
стаж |
Образов. |
1 |
80% |
90% |
5% |
70% |
10% |
12% |
95% |
30% |
30% |
2 |
40% |
35% |
45% |
13% |
60% |
70% |
60% |
40% |
20% |
3 |
50% |
70% |
10% |
5% |
30% |
20% |
70% |
20% |
50% |
Поясним, как сформирована приведенная выше таблица: В первом столбце расположен номер кластера - группы, данные по которой отражены в строке. Например, первый кластер на 80% составляют мужчины. 90% первого кластера попадают в возрастную категорию от 30 до 50 лет, а 12% респондентов считает, что льготы очень важны. И так далее. Попытаемся составить портреты респондентов каждого кластера. Первая группа - в основном мужчины зрелого возраста, занимающие руководящие позиции. Соцпакет (MED, LGOTI, TIME-своб время) их не интересует. Они предпочитают получать хорошую зарплату, а не помощь от работодателя. Группа два наоборот отдает предпочтение соцпакету. Состоит она, в основном, из людей "в возрасте", занимающих невысокие посты. Зарплата для них безусловно важна, но есть и другие приоритеты. Третья группа наиболее "молодая". В отличие от предыдущих двух, очевиден интерес к возможностям обучения и профессионального роста. У этой категории сотрудников есть хороший шанс в скором времени пополнить первую группу. Таким образом, планируя кампанию по внедрению эффективных методов управления персоналом, очевидно, что в нашей ситуации можно увеличить соцпакет у второй группы в ущерб, к примеру, зарплате. Если говорить о том, каких специалистов следует направлять на обучение, то можно однозначно рекомендовать обратить внимание на третью группу.
Пример 6 (Попов О.А.)
Мы будем классифицировать людей на основе шкал теста FPI. Для примера, попробуем классифицировать выборку из 45-ти человек. В конце процедуры мы узнаем какие существуют типы людей в данной выборке. Не исключено, что некоторые шкалы теста не различают людей, поэтому они будут удалены.
Первое, что нам нужно узнать - сколько типов в выборке целесообразно выделять. Для этого используем метод древовидной классификации.
Метод древовидной классификации – это пошаговый метод разбиения выборки на отдельные группы. Его принцип достаточно прост.
Шаг 1. Каждый человек признаётся единственным представителем своего кластера (типа). Количество типов равно объёму выборки.
Шаг 2. Находится несколько человек, которые наиболее похожи на первого. Теперь эти люди составляют один кластер. Количество кластеров уменьшается.
Шаг 3. Продолжаем искать кластеры, наиболее похожие друг на друга и объединять их. Теперь вся выборка разделена на некоторое количество групп, внутри которых люди очень схожи по своим характеристикам. Это продолжается, пока объединение не закончится и наступит последний шаг.
Шаг 4. Вся выборка объединяется в один кластер. Этот шаг не является информативным, так же как и первый шаг, но неизбежен в связи с процедурой.
Итак, у нас есть данные теста FPI и выборка 45 человек. Отобразим график древовидной классификации. Стрелки и подписи сделаны автором статьи.
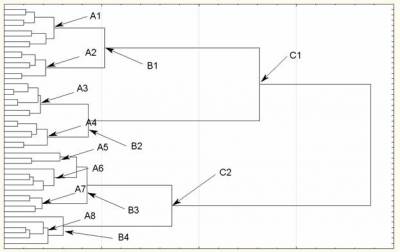
Читаем этот график слева направо. Изначально каждый испытуемый обозначен чертой. Затем происходит объединение по два человека в наиболее похожие группы, затем группы объединяются, пока мы не получаем один общий кластер – нашу выборку.
Сколько же кластеров нам необходимо выделить? Это зависит от наших задач. Мы можем выделить:
Наибольшее количество кластеров (А1-А8)
Среднее количество (В1-В4)
Наименьшее количество кластеров (С1, С2).
Слишком мельчить – значит терять достоверность. 2-5 человек в кластере – это слишком мало. При большом количестве кластеров характеристики людей в них будут слишком размыты, не исключено, что некоторые шкалы теста окажутся одинаковыми для обеих кластеров и тогда мы потеряем эти шкалы. Слишком большое количество кластеров чревато потерей информативности. Мы выбераем средний вариант (В1-В4).
На этом основная функция древовидной классификации окончена. Мы можем узнать сколько людей входит в каждый кластер, и узнать подробности самого процесса разбиения на кластеры. Но главный результат этого метода – количество кластеров.
Когда мы знаем сколько кластеров можно выделить в выборке мы применяем
метод к-средних.
В отличие от древовидной классификации, метод к-средних разбивает всю выборку по заданным признакам на указанное количество кластеров. Таким образом, чтобы использовать этот метод нужно знать или предполагать сколько кластеров мы хотим иметь.
Итак, мы задаём количество кластеров 4 и первым делом смотрим, действительно ли все переменные (шкалы теста) отличаются во всех 4-х кластерах. Эта проверка осуществляется с помощью дисперсионного анализа (F-критерий), результаты которого отражены в следующей таблице.
F р
FPI Невротичность 11,32104 0,000015
FPI Спонтанная агрессивность 17,29933 0,000000
FPI Депрессивность 12,44079 0,000006
FPI Раздражительность 21,78287 0,000000
FPI Общительность 10,04764 0,000043
FPI Уравновешенность 12,79335 0,000005
FPI Реактивная агрессивность 30,89699 0,000000
FPI Застенчивость 16,97276 0,000000
FPI Открытость 10,14094 0,000040
FPI Экстраверс-интроверс 7,21617 0,000536
FPI Эмо. Лабильность 6,40723 0,001163
FPI Маскулинность-феминность 23,27450 0,000000
Уровень значимости для всех шкал теста очень высокий, все значения F-критерия значимы. Таким образом, все шкалы теста являются критериями классификации.
Далее нам необходимо узнать каковы средние арифметические шкал теста для каждого кластера. Это отображено в следующей таблице.
Кластер 1 Кластер 2 Кластер 3 Кластер 4
FPI Невротичность 7,25 4,50 7,00 4,36
FPI Спонтанная агрессивность 7,25 5,50 8,29 3,64
FPI Депрессивность 6,67 4,38 7,57 5,64
FPI Раздражительность 7,08 6,13 8,50 4,45
FPI Общительность 3,67 7,50 4,64 5,64
FPI Уравновешенность 2,75 4,00 5,93 5,45
FPI Реактивная агрессивность 6,75 6,75 8,21 3,82
FPI Застенчивость 6,50 3,00 6,71 5,91
FPI Открытость 5,17 6,63 8,07 4,36
FPI Экстраверс-интроверс 4,17 6,00 6,86 4,91
FPI Эмо. Лабильность 6,67 5,13 6,93 5,55
FPI Маскулинность-феминость 3,08 7,00 6,64 3,82
Для наглядности, отобразим средние арифметические на графике.

Последний и самый важный этап кластерного анализа – узнать кто же конкретно входит в кждый из четырех кластеров, а затем описать их характеристики, основываясь на графике или таблице со средними значениями. После этого блюдо можно подавать на стол под названием «Новая классификация».
Вывод
Кластерный анализ – красивый метод. Но всегда нужно помнить о его недостатках:
Как и факторный анализ, он может давать неустойчивые кластеры. Повторите исследование на других людях и сравните результаты классификации. Скорее всего, они будут отличаться. На сколько – вопрос качества самого исследования.
Он реализует индуктивный метод исследования от частного к общему, что чревато антинаучными выводами. В идеале выборка для классификации должна быть очень большая, неоднородная, желательно подобранная методом стратификации или рандомизации. Наука движется по пути проверки гипотез, поэтому не нужно злоупотреблять кластерным анализом. Лучше всего использовать его для проверки гипотезы о наличии каких-либо типов, а не создавать классификацию на голом месте.
Как и любой метод многомерного шкалирования, кластерный анализ имеет множество особенностей, связанных с внутренними методами. Каков критерий объединения людей в кластеры, метод поиска различий, количество шагов до завершения алгоритма в методе к-средних и т.д. поэтому результаты могут меняться, хоть и несущественно, в зависимости от «настроек» процедуры.