

Анализ и интерпретация его результатов
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров (примечание 1). Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами (примечание 1; примечание 2). Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К.) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку. Такая методика предлагается Олдендерфером и Блэшфилдом (примечание 1).
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости: 1) кофенетическая корреляция — не рекомендуется и ограниченна в использовании; 2) тесты значимости (дисперсионный анализ) — всегда дают значимый результат; 3) методика повторных (случайных) выборок, что, тем не менее, не доказывает обоснованность решения; 4) тесты значимости для внешних признаков пригодны только для повторных измерений; 5) методы Монте-Карло очень сложны и доступны только опытным математикам (примечание 1).
Пример 1.
Источник — «http://ru.science.wikia.com/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7»
|
|
В прикладных социологических исследованиях, относящихся к классу количественных, в качестве единицы анализа практически всегда выступает некоторая социальная группа, выделенная по классифицирующим признакам. Набор таких признаков позволяет объяснить различия в социальном поведении человека. В качестве наиболее значимых показателей, определяющих социальное поведение, традиционно рассматриваются такие признаки, как «пол», «возраст», «образование» и «род занятий». Однако, классификация респондентов, принявших участие, например, в исследовании «Концепция устойчивого развития Волгограда. Стартовые условия (Компонент «Качество жизни населения»)» [1], по признакам «пол», «возраст», «образование», «род занятий» позволяет выделить в населении Волгограда 43 демографические группы.
Такое большое количество выделенных групп (43) вносит определенные трудности в процессе анализа данных. Главным образом, эти трудности заключаются в снижении наглядности результатов. Поэтому для удобства осуществления аналитических процедур представляется целесообразным проводить дополнительную классификацию выделенных групп. Сделать это можно на основании принятия гипотезы о наличии сходства между отдельными группами по их отношению к социальной реальности. В рамках упомянутого исследования ключевыми параметрами этого отношения выступили оценки состояния городской среды и динамики этого состояния.
Основным инструментом автоматического построения оптимальных классификаций являются методы кластерного анализа (см. рис.). Дерево классификации позволяет проанализировать степень близости между социально–демографическими группами по средним оценкам ситуации и ее динамики в экономической, экологической и социальной сферах Волгограда. Так, например, анализируя диаграмму, можно сделать вывод о том, что группы работающих мужчин со средним образованием в возрасте 45-54 года и старше 55 лет весьма сходны между собой по восприятию городской среды. Каждый «узел» на диаграмме соответствует объединению наиболее «близких» групп или кластеров.
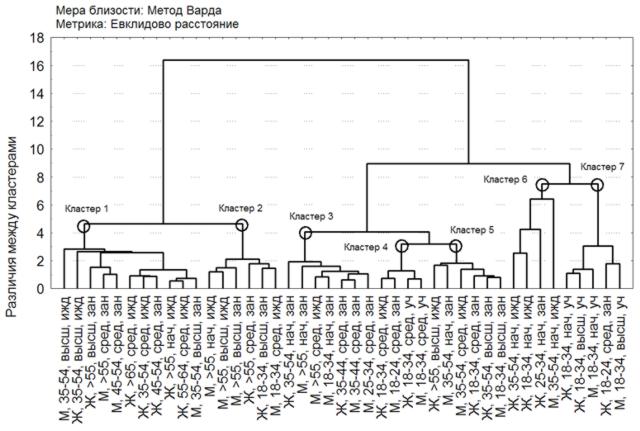

Рис. Схема классификации социально–демографических групп по близости оценок сфер городской среды
Таким образом, в населении Волгограда можно выделить семь укрупненных групп, различающихся между собой по характеристикам восприятия городской среды :
Кластер 1 – «Средний и старший возраст». В кластере представлены преимущественно женские группы; образование горожан, входящих в данный кластер – среднее и высшее; занятых и иждивенцев – примерно поровну.
Кластер 2 – «Высокообразованный старший возраст». Интересно, что к этому кластеру примкнули две группы респондентов младшей возрастной категории («18 34 года»).
Кластер 3 – «Работающее население разных возрастов». Образование респондентов, входящих в этот кластер, – среднее и начальное, преимущественно мужчины.
Кластер 4 – «Молодежь со средним образованием». В кластер входят и мужские и женские группы всех родов занятий.
Кластер 5 – «Работающие: молодежь и средний возраст». От кластера 3 данная группа населения отличается более высоким уровнем образования.
Кластер 6 – «Иждивенцы с низким уровнем образования». В данную группу входят безработные и домохозяйки молодого и среднего возраста.
Кластер 7 – «Учащаяся молодежь». Кластер объединяет респондентов, получавших на момент проведения исследования среднее специальное или высшее образование.
Доля в населении Волгограда выделенных социальных групп (кластеров) представлена в таблице.
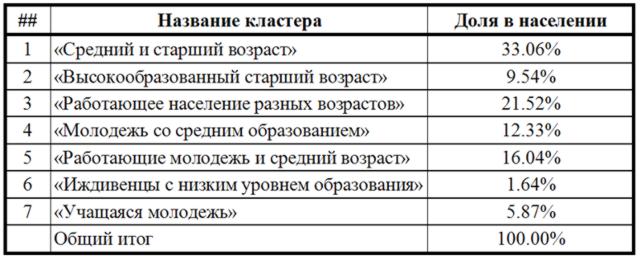
В ходе дальнейшего анализа данных, полученных в ходе прикладного исследования, могут быть использованы как укрупненные, более наглядные (7 кластеров), так и исходные (43 группы) социально–демографические группы, отражающие структуру населения города.
![]()
[1] N=1719. Для такого объема выборочной совокупности максимальная статистическая погрешность выборки при доверительном уровне 0.95 равна 2.4%. Опрос проводился по месту жительства респондентов, квотируемые признаки «пол», «возраст», «образование». Исследование выполнено по заказу Администрации Волгограда.
Пример 2.