

Методы выбора записей из исходной таблицы
1. Чтение всех записей таблицы и их фильтрация.
Схематично эту операцию (TableScan + Filter) можно представить в следующем виде (Рис. 1 .7, нижние индексы в обозначениях таблиц и условий поиска будем пока опускать).
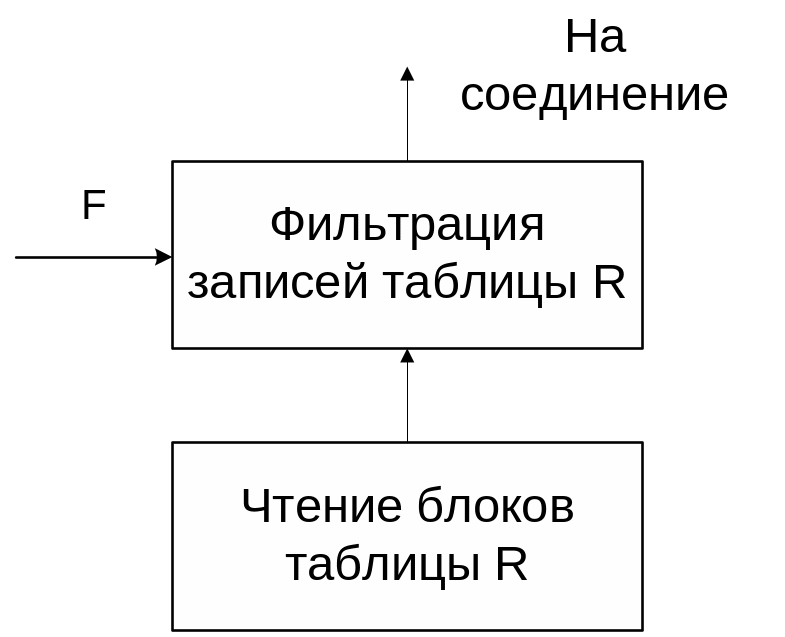
Рис. 1.7. Чтение всех записей.
Стоимость работы процессора и дискового ввода-вывода рассчитывается по формулам:
CCPU = T(R) · Cfilter , (5.4)
CI/O = B(R) · CB ,
где
T(R) – число кортежей (записей) в исходной таблице R;
B(R) – число физических блоков таблицы R;
Сfilter – время фильтрации одной записи в ОП;
CB – время чтения/записи одного блока на диск.
2. Чтение записей с помощью индекса и их фильтрация.
Схема операции (IndexScan + Filter) представлена на Рис. 1 .8.
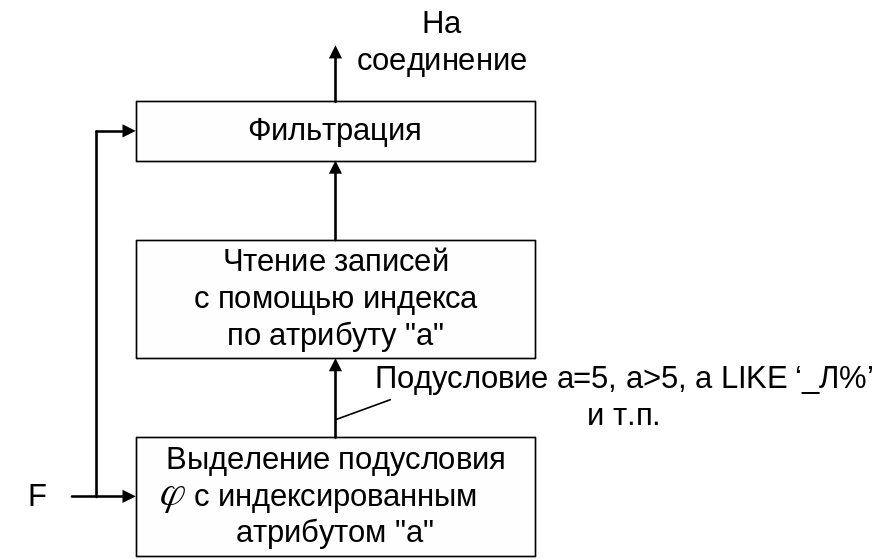
Рис. 1.8. Чтение записей с помощью индекса.
Стоимость работы процессора и подсистемы ввода-вывода определяются следующими выражениями:
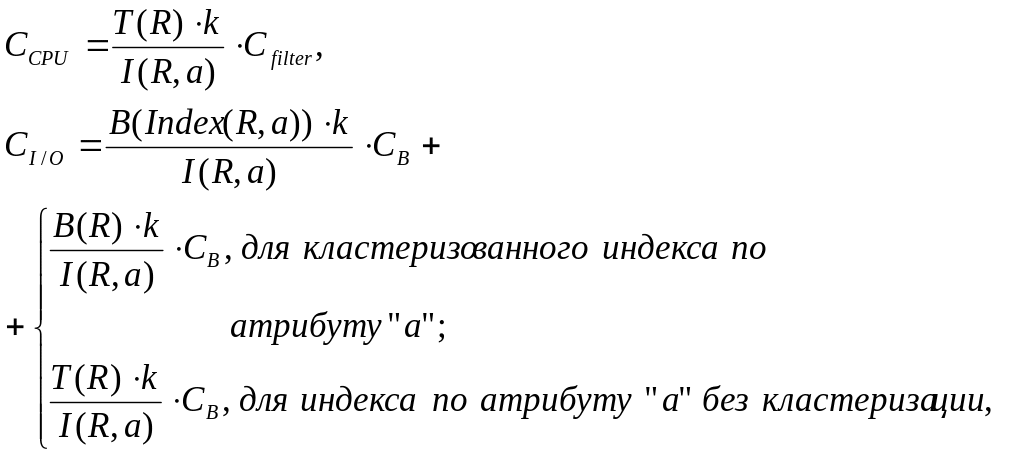 (5.5)
(5.5)
где
T(R) – число записей в таблице R;
B(R) – число блоков таблицы R;
I(R,a) – мощность атрибута "а" в таблице R (число различных значений);
B(Index(R,a)) – число блоков на листовом уровне индекса по атрибуту "а";
Сfilter – время фильтрации одной записи в ОП;
CB – время чтения/записи одного блока на диск;
k – мощность атрибута "а" в запросе (число различных значений, указанных в подзапросе φ).
Индекс по атрибуту является кластеризованным, если порядок записей в блоках таблицы такой же, как и в листовых блоках индекса.
Мощность атрибута в запросе (параметр k) можно оценить с помощью следующих выражений:
![]() (5.6)
(5.6)
Величину
![]() в формулах (5.5) можно интерпретировать
как вероятность, что запись таблицы R
удовлетворяет условию φ
по атрибуту "а".
в формулах (5.5) можно интерпретировать
как вероятность, что запись таблицы R
удовлетворяет условию φ
по атрибуту "а".
Оценка числа кортежей в промежуточной таблице q
Число кортежей оценивается с помощью следующей формулы:
T(Q) = T(R)·p , (5.7)
где
Q=F(R) – промежуточной таблица, соответствующая подзапросу Q,
T(Q) – оценка числа кортежей в промежуточной таблице Q,
T(R) – общее число кортежей в исходной таблице R,
p – вероятность того, что кортеж из R удовлетворяет условию поиска F.
Для расчета вероятности p можно воспользоваться следующими рекурсивными выражениями:
1. Пусть F = f1 AND f2 . Тогда
p = p1p2 ,
где pi – вероятность того, что запись из R удовлетворяет подусловию fi (i=1,2).
2. Пусть F = f1 OR f2 . Тогда
p = p1 + p2 – p1p2 .
3. Пусть F = NOT f1 . В этом случае
p = 1 – p1 .
Если в приведенных выше случаях 1–3 fi – подусловие по какому-либо атрибуту "а", то вероятность pi рассчитывается по следующей формуле:
![]() ,
,
где k – мощность атрибута в подзапросе (см. формулу (5.6)),
I(R,a) – мощность атрибута "а" в таблице R.
Ниже приведён пример расчёта числа кортежей в промежуточной таблице.
Пусть таблица R включает атрибуты (a, b, c). Число кортежей T(R) = 1000. Мощности атрибутов: I(R,a) = 5, I(R,b) = 10, I(R,c) = 2. Для простоты полагаем, что a, b, c – натуральные положительные числа.
Пусть задано условие выбора записей таблицы R:
F = (a < 3 OR b 5) AND c = 2
f1
f2
f4
f3
Требуется оценить число записей, удовлетворяющих условию F.
Решение.
1. f3 = f1 OR f2
![]()
2. F = f3 AND f4
![]() – вероятность
того, что запись из R
удовлетворяет условию F.
– вероятность
того, что запись из R
удовлетворяет условию F.
3. T(Q) = T(R)·p = 1000·0,38 = 380 – оценка числа записей, удовлетворяющих условию F.