

Нерекурсивный предиктивный анализ
Нерекурсивный предиктивный синтаксич анализатор можно построить с помощью явного использования стека. Основная проблема предиктивного анализа заключается в определении продукции, которую следует применить к нетерминалу. Нерекурсивный синтаксич анализатор, представленный на рис, ищет необходимую для анализа продукцию в таблице разбора.
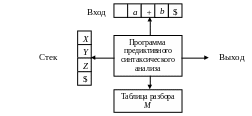
Предиктивный синтаксический анализатор включает в себя:
управляющую программу, входной буфер, стек, таблицу разбора и выходной поток. Входн буфер содержит анализируемую строку с маркером ее правого конца — специальным символом. Стек содержит послед-ность символов грамматики с символом $ на дне. Изначально стек содержит стартовый символ грамматики непосредственно над символом $. Таблица разбора представляет собой двухмерный массив М[А, а], где А — нетерминал, а а — терминал или символ $.
Синтаксич анализатор управляется программой, которая работает след образом. Программа рассматривает X — символ на вершине стека, и а, текущий входной символ. Эти два символа определяют действия синтаксического анализатора. Имеется три варианта:
Если Х=а=$, синтаксический анализатор прекращает работу и сообщает об успешном завершении разбора.
Если Х=а≠$, синтаксический анализатор снимает со стека X и перемещает указатель входного потока к следующему символу.
Если X представляет собой нетерминал, программа рассматривает запись M[Х, а] таблицы разбора М. Эта запись представляет собой либо X-продукцию грамматики, либо запись об ошибке. Если, например, М[Х, а] = {X → UVW}, синтаксический анализатор замещает X на вершине стека на WVU (с U на вершине стека). В качестве выхода синтаксический анализатор просто выводит использованную продукцию. Если M[Х, а] = error, синтаксический анализатор вызывает программу восстановления после ошибки.
Поведение синтаксического анализатора может описываться его конфигурациями, которые дают содержимое стека и оставшийся входной поток.
Множества first и follow
При
построении предиктивного синтаксич
анализатора необходимо построить два
множества связанные
с грамматикой G,
— FIRST
и FOLLOW,
которые обеспечивают заполнение таблицы
предиктивного анализа грамматики G.
Если α
— произвольная строка
символов грамматики, то определим
FIRST(a)
как множество
терминалов, с которых начинаются строки,
выводимые из а.
Если
а![]() λ,
то λ
входит в FIRST(a).
λ,
то λ
входит в FIRST(a).
FOLLOW(A) для нетерминала А определяется как множ-во терминалов а, кот могут располагаться непосредственно справа от А в некоторой сентенциальной форме, т.е. множество терминалов а, таких, что существуют порождения вида S αAaβ для некоторых α и β. В процессе приведения между А и а могут появиться символы, но они порождают λ и в конечном счете исчезают. Если А может оказаться крайним справа символом некоторой сентенциальной формы, то $ входит в FOLLOW(A).
Построение таблиц предиктивного анализа
Для построения таблицы предиктивного анализа данной грамматики G используется следующий алгоритм.
Для каждой продукции грамматики А → α выполняем шаги 2 и 3.
Для каждого терминала α из FIRST(А) добавляем А → α в ячейку М[А, а].
Если в FIRST(А) входит λ , для каждого терминала т b из FOLLOW(A) добавим А →b в ячейку М[А, b]. Если λ входит в FIRST(α), а $ — в FOLLOW(A), добавим А → α ячейку М[А, $].
Каждая неопределенная ячейка таблицы М указывает на ошибку [3].
Синтаксический анализатор находит ошибку в тот момент, когда терминал на вершине стека не соответствует очередному входному символу или на вершине стека находится нетерминал А, очередной входной символ — а, а ячейка таблицы синтаксического анализа М[А, а] пуста.
LL(1)-грамматики
Грамматика, таблица анализа которой не имеет множественных записей, называется LL(1). Первое "L" означает просмотр входного потока слева направо, второе "L" — левое порождение, а "1"— просмотр одного символа из входного потока на каждом шаге для принятия решения о дальнейших действиях.
Для некоторых грамматик таблица разбора М может иметь несколько записей в одной ячейке таблицы. Например, если грамматика G — леворекурсивная или неоднозначная, то таблица разбора М будет иметь как минимум одну ячейку с несколькими записями.
LL(1)-грамматики имеют ряд отличительных свойств. Такая грамматика не может быть неоднозначной или леворекурсивной. Можно показать, что грамматика G является LL(1)-грамматикой тогда и только тогда, когда для любых двух различных ее продукций А→α | β выполняются следующие условия.
Не существует такого терминала а, для которого и α, и β порождают строку, начинающуюся c а.
Пустую строку может порождать только одна из продукций α или β.
Если β=> λ, то а не порождает ни одну строку, начинающуюся с терминала из FOLLOW(A).
Грамматика для арифметических выражений является LL(1)-грамматикой. Грамматика, моделирующая инструкции if-then-else, таковой не является.
Если таблица анализа имеет ячейки с несколькими записями, выход состоит в преобразовании грамматики, устраняющем левую рекурсию, и левой факторизации, чтобы получить грамматику, в таблице анализа которой отсутствуют ячейки с несколькими записями. К сожалению, имеются грамматики, никакие изменения которых не приведут к LL(1)-грамматике. Не существует универсальных правил, с помощью которых ячейки с несколькими записями можно превратить в однозначно определенные без воздействия на язык, распознаваемый синтаксическим анализатором.
Общие алгоритмы синтаксического анализа: методы восходящего синтаксического анализа, табличные методы синтаксического анализа, формальное определение алгоритма разбора типа "перенос-свертка", определение LR(k)-грамматики, алгоритм разбора для LR(k)-грамматик, алгоритм построения управляющей таблицы, преимущества класса LR(k)-грамматик перед другими методами синтаксического анализа.
Основной метод восходящего синтаксического анализа - синтаксический анализ типа "перенос/свертка" или сокращенно ПС-анализ. В процессе ПС-анализа дерево разбора для входной строки строится начиная с листа (снизу) и работая по направлению к корню дерева (вверх).
Основа строки — это подстрока, которая совпадает с правой частью продукции и свертка которой в левую часть продукции представляет собой один шаг обращенного правого порождения.
Основа правосентенциальной формы γ является продукцией A → β и позицией строки β в γ, такими, что β может быть заменена нетерминалом А для получения предыдущей правосентенциальной формы в правом порождении γ.
Стековая реализация ПС-анализа
Изначально стек пуст, а входной буфер содержит строку w$.
Стек Вход
$ w$
Синтаксический анализатор работает путем переноса нуля или нескольких символов в стек до тех пор, пока на вершине стека не окажется основа β. Затем он свертывает β левой части соответствующей продукции. Синтаксический анализатор повторяет этот цикл, пока не будет обнаружена ошибка или он не придет в конфигурацию, когда в стеке находится только стартовый символ, а входной буфер пуст:
Стек Вход
$S $
Попав в эту конфигурацию, синтаксический анализатор прекращает работу и сообщает об успешном разборе входной строки.
Основными операциями синтаксического анализатора являются перенос и свертка, но на самом деле ПС-анализатор может выполнять четыре действия: (1) перенос, (2) свертка, (3) допуск, (4) ошибка.
При переносе очередной входной символ переносится на вершину стека.
При свертке синтаксический анализатор распознает правый конец основы на вершине стека, после чего он должен найти левый конец основы и принять решение о том, каким нетерминалом заменить основу.
При допуске синтаксический анализатор сообщает об успешном разборе входной строки.
При ошибке синтаксический анализатор обнаруживает ошибку во входном потоке и вызывает программу восстановления после ошибок.
LR-анализаторы
LR-анализатор состоит из входного потока, выхода, стека, управляющей программы и таблицы синтаксического анализа, состоящей из двух частей (действие (action) и переход (goto)).
Программа синтаксического анализа считывает символы из входного буфера по одному и использует стек для хранения строк вида s0X1s1X2s2 …Xmsm (sm находится на вершине стека). Каждый символ X, является символом грамматики, а каждый si — символом состоянием.
Таблица синтаксического анализа состоит из двух частей — функции действий синтаксического анализа action и функции переходов goto. Управляющая программа LR-анализатора функционирует следующим образом. Она определяет sm, текущее состояние на вершине стека, и ai текущий входной символ. Затем программа обращается к асtion[sm, аi], ячейке таблицы действий синтаксического анализа, определяемой состоянием sm и символом аi, которая может иметь одно из четырех значений:
1) перенос s, где s — состояние; 2) свертка в соответствии с продукцией А →β; 3) допуск; 4) ошибка.
Функция goto получает в качестве аргументов состояние и символ грамматики и возвращает новое состояние.
Конфигурация LR-анализатора представляет собой пару, первый компонент которой — содержимое стека, а второй — непросмотренная часть входного потока: (s0Xls)X2s2 …Xmsm,aiai+1 …an$).
Следующий шаг синтаксического анализатора определяется текущим входным символом а, и состоянием на вершине стека sm в соответствии со значением ячейки таблицы action[sm, аi]. Конфигурации, получаемые после каждого из четырех типов действий, следующие.
1. Если action[sm, аi] = "перенос s", синтаксический анализатор выполняет перенос, переходя в конфигурацию (s0Xls1X2s2 …Xmsmais,aiai+1 …an$). Синтаксический анализатор переносит в стек текущий входной символ аi, и очередное состояние s, определяемое значением action[sm, аi]; текущим входным символом становится ai+1.
2. Если action[sm, аi] = "свертка А → β”, то синтаксический анализатор выполняет свертку, переходя в конфигурацию (s0Xls1X2s2 …Xm-rsm-rAs,aiai+1 …an$), где s = goto[sm-r,A], а r — длина β, правой части продукции. Здесь синтаксический анализатор вначале снимает со стека 2r - символов (r символов состояний и r символов грамматики), выводя на вершину стека состояние sm-r. Затем он вносит в стек А (левую часть продукции) и s, запись из ячейки
goto[sm-r, А]. Текущий входной символ при этом не изменяется. Последовательность снимаемых со стека символов грамматики Xm-r+1 … Хт всегда соответствует правой части продукции свертки.
3. Если action[sm, ai] = "допуск", синтаксический анализ завершает свою работу.
4. Если action[sm, ai] = "ошибка", синтаксический анализатор обнаружил ошибку и вызывает подпрограмму восстановления после нее.
Основная идея SLR-метода состоит в том, чтобы вначале построить на базе грамматики детерминированный конечный автомат для распознавания активных префиксов. Группируем пункты в множества, которые приводят к состояниям SLR-анализатора. Пункты могут рассматриваться как состояния недетерминированного конечного автомата, распознающего активные префиксы. Система LR(0)-пунктов, которая называется канонической, обеспечивает основу для построения SLR-анализаторов.
Для построения канонической LR(0)-системы грамматики необходимо определить расширенную грамматику и две функции — closure и goto.
Если G — грамматика со стартовым символом S, то G', расширенная грамматика грамматики G, представляет собой G с новым стартовым символом S' и продукцией S' → S.
Алгоритм построение таблицы SLR-анализа
Вход. Расширенная грамматика G’.
Выход. Функции action и goto таблицы SLR-анализа для грамматики G’.
Метод.
1. Построим С = {I0,I1,...,In} — систему множеств LR(0)-пунктов для грамматики G’.
2. Состояние i строится на основе Ii. Действия синтаксического анализа для состояния i определяются следующим образом:
a) если [А → α•aβ]є Ii, и goto(Ii, a)=Ij , то определить action[i, а] как "перенос j"; здесь а – терминальный символ;
b) если [А → α•]є Ii , то определить action[i, а] как "свертка А → α " для всех а из FOLLOW(A); здесь А не должно быть S’;
c) если [S’→ S•] є Ii, то определить action[i, $] как "допуск".
Если по этим правилам генерируются конфликтующие действия, то грамматика не является SLR(l). Алгоритм не в состоянии построить синтаксический анализатор для нее.
3. Переходы goto для состояния i и всех нетерминалов А строятся по правилу: если goto(Ii , A)= Ij, то goto[i, A]=j.
4. Все записи, не определенные по правилам (2) и (3), указываются как "ошибка".
5. Начальное состояние синтаксического анализатора представляет собой состояние, построенное из множества пунктов, содержащего [S’→ S•].
Преимущества LR:
- могут быть созданы практически для всех конструкций ЯП, для кот. сущ-ет КС-грамматика;
- наиболее общий и эффективный;
- могут обнаруживать ошибки сразу, как только это становится возможным при сканировании входного потока.
Общие принципы генерации кода: формальные методы описания перевода, внутренние формы программы: польская инверсная запись, представление основных конструкций языков программирования в польской инверсной записи, тетрады, триады, представление основных конструкций языков программирования с использованием тетрад и триад, косвенные триады, синтаксические деревья, ассемблерный код, особенности всех форм представления, их сравнительный анализ.
Общие принципы генерации кода.
Генерация объектного кода – это перевод компилятором внутреннего представления исходной программы в цепочку символов выходного языка. Генерация объектного кода порождает результирующую объектную программу на языке машинных команд. Внутреннее представление программы может иметь любую структуру в зависимости от реализации компилятора, в то время как результирующая программа всегда представляет собой линейную последовательность команд. Поэтому генерация объектного кода (объектной программы) в любом случае должна выполнять действия, связанные с преобразованием сложных синтаксических структур в линейные цепочки.
В идеале компилятор должен выполнить синтаксический разбор всей входной программы, затем выполнить семантический анализ, после чего приступить к подготовке генерации и непосредственно к генерации кода. Однако такая схема работы компилятора практически почти никогда не применяется. В общем случае ни один семантический анализатор и ни один компилятор не способны проанализировать и оценить смысл всей входной программы в целом. Формальные методы анализа семантики применимы только к очень незначительной части возможных программ. Поэтому у компилятора нет практической возможности порождать эквивалентную выходную программу на основании всей входной программы.
Как правило, компилятор выполняет генерацию результирующего кода поэтапно, на основе законченных синтаксических конструкций входной программы:
компилятор выделяет законченную синтаксическую конструкцию из текста входной программы,
порождает для нее фрагмент результирующего кода и помещает его в текст выходной программы.
Затем он переходит к следующей синтаксической конструкции.
Смысл (семантику) каждой такой синтаксической конструкции входного языка можно определить, исходя из ее типа, а тип определяется синтаксическим анализатором на основании грамматики входного языка. Примерами типов синтаксических конструкций могут служить операторы цикла, условные операторы, операторы выбор и т.д. одни и те же типы синтаксических конструкций характерны для различных языков программирования, при этом они различаются синтаксисом (который задается грамматикой языка), но имеют сложный смысл (который определяется семантикой). В зависимости от типа синтаксической конструкции выполняется генерация кода результирующей программы, соответствующего данной синтаксической конструкции. Для семантически схожих конструкций различных входных языков может порождаться типовой результирующий код.