

65. Формальные языки и грамматики: универсальное множество цепочек над конечным алфавитом, формальный язык как множество цепочек, операции над языками, определение формального языка и формальной грамматики, теория формальных грамматик как математический аппарат для изучения синтаксиса языков программирования, классификация формальных языков и грамматик по порождающей способности.
Цепочка символов – это произвольная последовательность символов, записанных один за другим. Язык - это заданный набор символов и правил, устанавливающих способы комбинации этих символов между собой для записи осмысленных текстов. Алфавит (V)-это счетное множество допустимых символов языка. Цепочка символов является цепочкой над алфавитом V: (V),если в нее входят только символы, принадлежащие множеству символов V. Языком L над алфавитом V: L(V) называется некоторое счетное подмножество цепочек конечной длины из множ-ва всех цепочек над алфавитом V.
Операции:
Объединение L и M – L
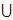 M -> L
M {s | sЄL
или sЄМ}
M -> L
M {s | sЄL
или sЄМ}Конкатенация L и M – LM -> L M {s | sЄL и sЄМ}
Итерация L – L* -> L* - обозначает “нуль или более конкатенаций L”
Позитивное замыкание L – L+ -> L+ - обозначает “одна или более конкатенаций L”
Определение формальной грамматики и формального языка.
Грамматика - это описание способа построения предложений некоторого языка.
(генератор цепочек языка). Правило (или продукция) - это упорядоченная пара цепочек символов (,) - →. Язык, заданный грамматикой G, обозначается как L(G).
Формально грамматика G определяется как четверка G(T,N,P,S), где: Множество V=N T - полный алфавит грамматики G. Множество терминальных символов T содержит символы, которые входят в алфавит языка, порождаемого грамматикой. Множ-во нетерминальных символов N содержит символы, которые определяют слова, понятия, конструкции языка. N T= Ø ; S - это всегда нетерминальный символ. P – множество правил (продукций) грамматики вида →, где V⁺ . V*.
Классификация формальных грамматик.
Форм грамм-ки классифиц-ся по стр-ре их правил. По классиф-ии Хомского выделяют 4 типа грам-к.
Тип 0: грамматики с фразовой структурой никаких ограничений (общий тип грамматик, попадают все грамматики): для грамматики вида G(T,N,P,S), V= NT правила имеют вид:, где V+,V*.
Тип 1: контекстно-зависимые (КЗ) и неукорачивающие грамматики
Контекстно-зависимые грамматики G(T,N,P,S),V=NT имеют правила вида: ₁A₂₁₂, где ₁, 2V*,AN,V+. При построении предложений заданного ими языка один и тот же нетерминальный символ может быть заменен на ту или иную цепочку символов в зависимости от того контекста, в котором он встречается.
Неукорачивающие грамматики G(T,N,P,S), V=NT имеют правила вида: , где ,V+,| | ≥||. Неукорачивающие грамматики имеют такую структуру правил, что при построении предложений языка, заданного грамматикой, любая цепочка символов может быть заменена на цепочку символов не меньшей длины. Эти грамм. эквив-ны.
Тип 2: контекстно-свободные (КС) грамматики
Контекстно-свободные (КС) грамматики G(T,N,P,S); V=NT имеют правила вида: A, где AN, V+. Широко используются.
Тип 3: регулярные грамматики
Леволинейные грамматики G(T,N,P,S), V=NT могут иметь правила двух видов: AB или A, где A, BN , VT*. Праволинейные грамматики G(T,N,P,S), V=NT могут иметь правила тоже двух видов:AB или A, где A, BN, VT*.Эти два класса грамматик эквивалентны и относятся к типу регулярных грамматик. Регулярные грамматики используются при описании простейших конструкций языков программирования: идентификаторов, констант, строк, комментариев и т.д.
Классификация языков по порождающей способности. Связь между классами языков и проблемой распознавания.
Сложность языка убывает с возрастанием номера классификационного типа языка.
Тип 0: языки с фразовой структурой (для вычисления машина Тьюринга, самые сложные, пример – естественный язык общения людей)
Тип 1: контекстно-зависимые (КЗ) языки (Линейно – ограниченные автоматы)
применяются в анализе и переводе текстов на естественных языках. Распознаватели, построенные на их основе, позволяют анализировать тексты с учетом контекстной зависимости в предложениях входного языка (но они не учитывают содержание текста). В компиляторах КЗ - языки не используются.
Тип 2: контекстно-свободные (КС) языки (для вычис необход автомат с машинной памятью) лежат в основе синтаксических конструкций большинства современных языков программирования, на их основе функционируют некоторые довольно сложные командные процессоры, допускающие управляющие команды цикла и условия.
Тип 3: регулярные языки – самый простой тип языков. Время на распознавание предложений регулярного языка линейно зависит от длины исходной цепочки символов (для вычисления необход. КА).
66. Лексический анализ: роль лексического анализатора, взаимосвязь лексического и синтаксического анализаторов, принципы построения и функции лексического анализатора, связь лексического анализа, автоматных грамматик и конечных автоматов, конечные автоматы и распознаватели, недетерминированные и детерминированные конечные автоматы, преобразования конечных автоматов, цель этих преобразований.
Лексич. анализ представляет собой 1-ую фазу компиляции. Его осн задача состоит в чтении новых символов и выдачи последовательности лексем, используемых синтаксическим анализатором в своей работе. Лексической единицей языка является лексема.
Лексема — это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка.
Лексемами естественного языка общения между людьми являются слова. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т.п. Состав возможных лексем каждого конкретного языка программир-я определяется синтаксисом этого языка.
Цели лексического анализа:
1) перевод исходной программы на внутренний язык компилятора, в котором ключевые слова, идентификаторы, метки и константы приведены к одному формату и заменены условными кодами: числовыми или символьными, которые называются дескрипторами. Каждый дескриптор состоит из двух частей: класса-типа лексемы и указателя на адрес в памяти, где хранится информация о конкретной лексеме. Эта информация организуется в виде таблиц.
2) лексический контроль – выявление в программе недопустимых слов.
Лексический анализатор (или сканер) — это часть компилятора, которая читает исходную программу и выделяет в ее тексте лексемы входного языка.
На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
С теоретической точки зрения лексический анализатор не является обязательной частью компилятора. Все его функции могут выполняться на этапе синтаксического разбора.
Основные функции лексического анализатора:
1) исключение из текста исходной программы комментариев;
2) исключение из текста исходной программы незначащих пробелов, символов-табуляций и перевода строки;
3) выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых, констант, ключевых (служебных) слов входного языка, знаков операций и разделителей.
В простейшем случае фазы лексического и синтаксического анализа могут выполняться компилятором последовательно. Но для многих языков программирования на этапе лексического анализа может быть недостаточно информации для однозначного определения типа и границ очередной лексемы.
Поэтому в большинстве компиляторов лексический и синтаксический анализаторы - это взаимосвязанные части. Возможны два метода организации взаимосвязи лексического анализа и синтаксического разбора:
последовательный;
параллельный.
При последовательном варианте лексический анализатор просматривает весь текст исходной программы от начала до конца один раз и преобразует его в структурированный набор данных. Этот набор данных называют также таблицей лексем. В таблице лексем ключевые слова языка, идентификаторы и константы, как правило, заменятся на специально оговоренные коды, им соответствующие (конкретная кодировка определяется разработчиком при реализации компилятора). Таблица лексем строится полностью вся сразу, и больше к ней компилятор не возвращается. Всю дальнейшую обработку выполняют следующие фазы компиляции.
При параллельном варианте лексический анализ исходного текста выполняется поэтапно так, что синтаксический анализатор, выполнив разбор очередной конструкции языка, обращается к сканеру за следующей лексемой. При этом он может сообщить информацию о том, какую лексему следует ожидать. В процессе разбора при возникновении ошибки может происходить «откат назад», чтобы попытаться выполнить анализ текста на другой основе. И только, после того, как синтаксический анализатор успешно выполнит разбор очередной конструкции языка, лексический анализатор помещает найденные лексемы в таблицу лексем и таблицу идентификаторов и продолжает разбор дальше в том же порядке.